基于深度卷積神經網絡的α-Fe晶界能預測
2022-03-05 01:47:26李六六時靖誼
原子與分子物理學報 2022年3期
陳 村, 李六六, 彭 蕾, 時靖誼
(1.中國科學技術大學 核探測與核電子學國家重點實驗室, 合肥 230026;2. 中國科學技術大學 核科學技術學院, 合肥 230027)
1 引 言
先進核反應堆結構材料鐵素體/馬氏體(F/M)鋼在受到中子輻照后會產生大量的氦原子. 這些氦原子容易在結構鋼中的晶界處聚集形成氦泡,從而導致材料脆化. 不同的晶界對氦泡誘導脆化的敏感程度是不同的[1]. “晶界工程”[2]通過控制和設計晶界來改進材料性能,首先需要獲知結構鋼中各晶界的性質. 晶界能作為晶界的主要特性之一,可在一定程度上衡量晶界的性質[3]. 獲取晶界能的方法主要有理論推導、實驗測量和模擬計算. 著名的Read-Shockley公式[4]基于理論推導得到了晶界能和取向差角之間的關系,但僅適用于小角度晶界. Hasson和Goux[5]通過實驗測定了Al<100>和<110>對稱傾斜晶界的晶界能隨取向差角的變化規律,但該方法受到測量條件的限制,難以大范圍運用. 因此,若能快速準確地獲取晶界能,將為“晶界工程”提供便利,提高實驗效率.
隨著材料模擬技術的發展,更多地是基于分子動力學來研究晶界結構和晶界能,主要有考慮周期性邊界條件的塊狀模型[6]和考慮非周期性邊界的球形模型[7]. 分子動力學方法所要消耗的計算資源較大,并隨晶界體系的增大而增加,難以滿足“晶界工程”中計算大量晶界的需求. 因此,有少數研究者[8-10]嘗試從數據科學的角度出發,在分子動力學模擬的基礎上構造出合適的特征,并通過機器學習模型[11]對Al的晶界性能進行預測,但該方法的準確性受限于人為構造的特征,特征的好壞將直接影響預測效果. 由于模型信息量大,特征復雜,人工提取合適特征的難度較大,較難在大的傾斜角范圍內得到應用.
近年來,深度學習[12]以更深層次的網絡結構實現了自動提取特征的能力,在圖像、語音、自然語言處理等方面均取得了非凡的成績,也有研究者將其應用于生物蛋白質[13]、超高碳鋼[14]和復合材料[15]中. 因此,本文主要針對F/M鋼模擬α-Fe中常見的對稱傾斜晶界,以中心對稱參數和原子密度信息構建積累中心參數,并通過具有高效提取空間信息能力的深度卷積神經網絡算法(CNN, Convolutional Neural Networks)[12]進行晶界能預測.
2 對稱傾斜晶界庫
針對α-Fe中常見的晶界,本文挑選出其中的具有一定傾斜軸(<100>和<110>)和傾斜角θ的對稱傾斜晶界,利用LAMMPS軟件[16]構造出穩定晶界構型并計算相應的晶界能. 先按重合位置點陣(CSL, Coincident Site Lattice)模型[17]建立兩個具有一定取向的α-Fe晶粒,將其拼接后得到初步的雙晶結構,兩者交界面即為晶界平面. 同時為避免周期性邊界條件導致的雙晶界互相影響,遵循兩晶界在晶界法向上間距大于12 nm的原則. 再應用晶界平面內平移(In-plane Translations) 和原子刪除判據(Atom Deletion Criteria) 理論[18]枚舉出大量可能的晶界構型. 然后在0 K下對每一個晶界構型進行靜力學弛豫并對晶界附近原子進行微小的調整,篩選出能量最低的構型作為晶界結構. 其中鐵原子間的相互作用通過Ackland等[19]發展的鐵鐵勢函數Ackland04描述. 最后通過以下公式計算各晶界的晶界能大小:
(1)
其中γgb代表晶界能,Egb是含對稱傾斜晶界雙晶系統的勢能,E1和E2分別是上下兩個晶粒單獨存在時的勢能,A為晶界平面的大小.
結果如表1所示,一共構建了92個具有最低能量構型的α-Fe對稱傾斜晶界,其中包括傾斜軸<100>的晶界結構32個和傾斜軸<110>的晶界結構60個.
3 深度學習模型與設計
預測晶界能的深度學習模型的整體流程如圖1所示,在前一節建立的對稱傾斜晶界庫上以原子坐標為基礎構建晶界特征參數(中心對稱參數、積累中心對稱參數). 再對完成特征構建的樣本庫進行分層抽樣,劃分為訓練集和測試集. 通過卷積神經網絡模型在數據增強后的訓練集上進行學習、驗證,并以測試集上預測的晶界能和模擬得到的晶界能間的相對差值來評估模型的真實預測效果.
3.1 特征參數構建
晶界平面附近的原子空間分布并不均勻,直接以空間結構進行學習的有效性極低. 考慮到塊狀晶界模型的周期性邊界條件,本文以晶界原子的中心對稱參數(CS, Centro-symmetry Parameter)[20]分布替代晶界結構達到了簡化模型的作用. CS常用來衡量原子周圍局部晶格的紊亂程度,在晶界處有較大的正值. 在對稱傾斜晶界模型中,CS值僅與晶界平面法線方向(下文以y軸代表該方向)上的相對距離相關,相同的晶界在y軸上具有相同的CS相對分布. 因此,通過該參數可以將三維的空間信息簡化到二維的相對分布,從而降低計算復雜度,相比于傳統機器學習方法構造的特征也更為簡便,其計算公式[20]如下:
(2)
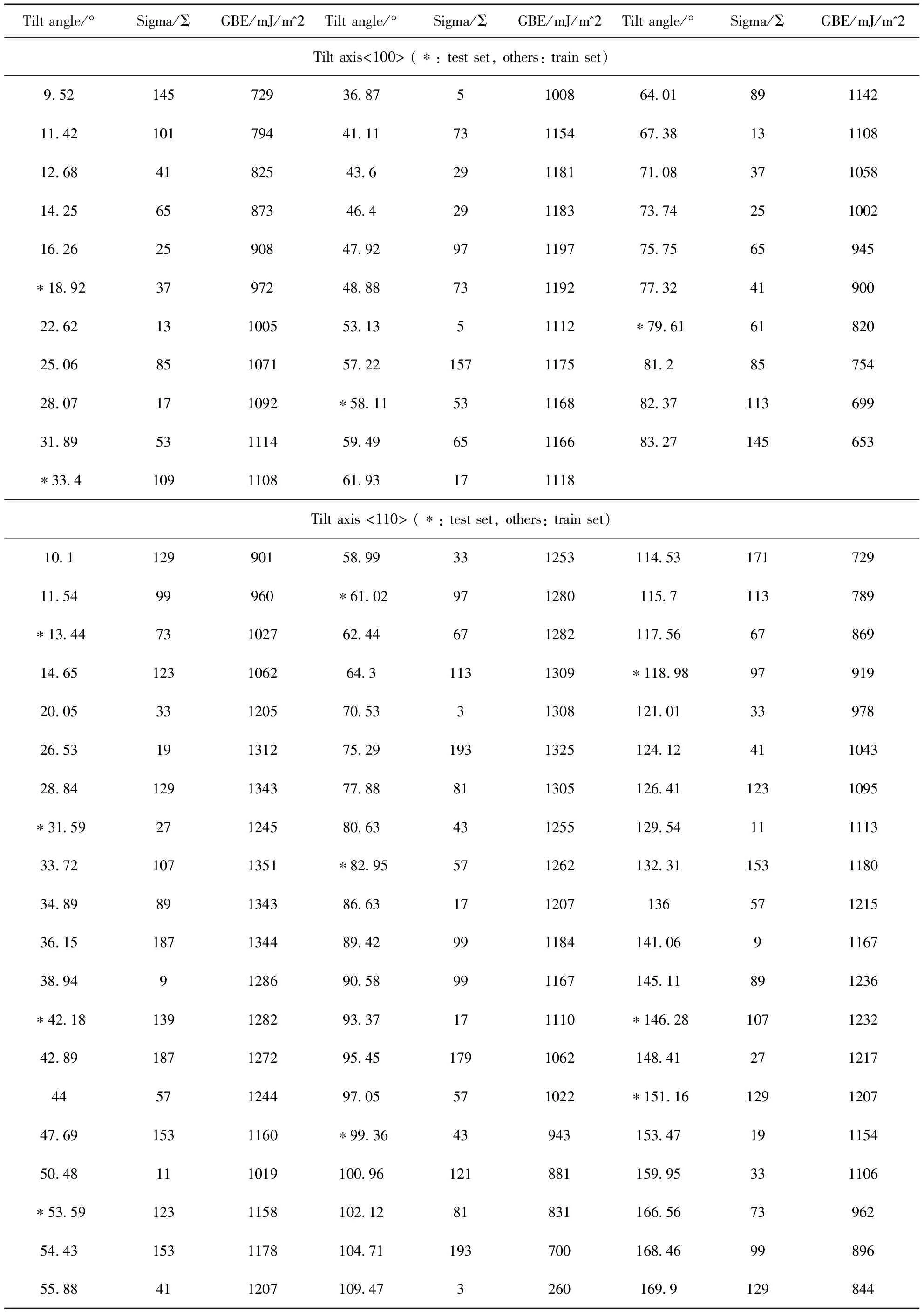
表1 α-Fe對稱傾斜晶界各晶界參數
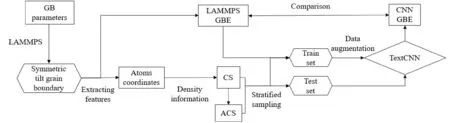
圖1 預測晶界能流程圖Fig. 1 Flow chart of grain boundary energy prediction
同時,考慮到不同傾斜角的晶界在y方向上的原子密度是不同的,本文利用伊番科尼可夫核函數(Epanechnikov Kernel)融合進原子密度信息構造了積累中心對稱參數(ACS, 如圖2綠色線所示). 最終對(-20 ?, 20 ?)區間內的CS和ACS分布分別等間隔地取401個值作為模型的輸入特征.
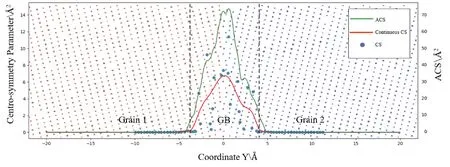
圖2 <110>傾斜軸的Σ9對稱傾斜晶界上中心對稱參數、連續的中心對稱參數以及積累中心對稱參數隨y軸坐標的分布圖Fig. 2 For a Σ9 symmetric tilt grain boundary with a tilt axis of <110>, the distribution of centro-symmetry parameter, continuous centro-symmetry parameter and accumulate centro-symmetry parameter along Y coordinate
3.2 卷積神經網絡模型
本文以適合一維卷積的TextCNN模型[21]為基礎,通過PYTORCH 1.5.1搭建了卷積神經網絡模型,整個模型的參數量在1.7*105左右. 如圖3所示,模型主要由卷積層、池化層(Pooling)和兩層全連接層(FCN)組成. 卷積層通過卷積核的滑動進行卷積計算,本文使用了多個不同尺寸的卷積核,單個尺寸卷積核設置為k(50、100、150、200)個,卷積計算后通過修正線性單元(ReLU)[11]引入非線性. 池化層作為一種下采樣操作主要用于降維,對每一組特征采用最大值池化中的Chunk-Max-Pooling[21]篩選出局部最大的4個值. 最后將池化層輸出的特征按序拼接后展平輸入隱藏層單元為(64,16)的全連接層,并以0.5的概率暫時丟棄一定數量的神經元,防止網絡出現過擬合現象. 使該模型在訓練集上循環訓練1000個周期,并通過平滑的L1損失[11]更新模型的參數. 參數的更新算法采用Adam算法[22],參數更新的學習率對于ACS特征設置為3 e-4,對于CS特征前100個周期設置為1 e-4,之后為1 e-5.
4 預測結果與分析
依據表1的對稱傾斜晶界庫統計了晶界能隨傾斜角的分布,如圖4所示. 這與Yasushi S等[23]構建的體心立方晶體對稱傾斜晶界的晶界能隨傾斜角的分布相接近. 從圖中可見,相鄰傾斜角的晶界能較為接近,因此,本文通過按傾斜角分層抽樣的方法劃分了訓練集和測試集. 首先,統計晶界在各傾斜角區間的樣本個數,盡可能地保留稀疏區間的樣本作為訓練集,最終以28個<100>傾斜軸晶界和50個<110>傾斜軸晶界分別作為原始訓練集.
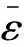
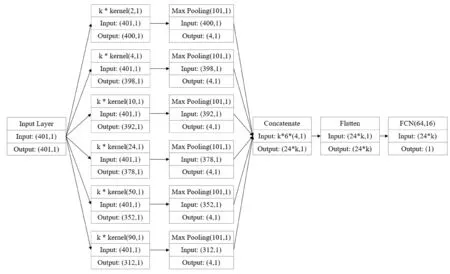
圖3 卷積神經網絡模型框架圖Fig. 3 Illustration of convolutional neural networks framework
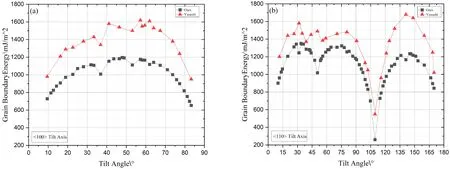
圖4 α-Fe中傾斜軸為(a)<100>和(b)<110>的對稱傾斜晶界傾斜角與晶界能關系圖Fig. 4 Grain boundary energies of the symmetric tilt boundaries in α-Fe as a function of tilt angle for the tilt axes of (a) <100> and (b) <110>
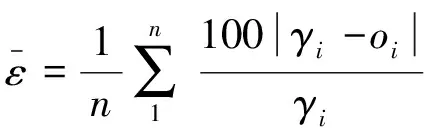
(3)
式中γi為分子動力學計算的目標晶界能,oi為預測晶界能,n為測試樣本數.
4.1 晶界能預測結果
不同卷積核尺寸的模型預測晶界能的平均相對誤差隨訓練周期的變化如圖5(a)所示,這里同尺寸卷積核的個數設置為100個. 可以看到,平均相對誤差隨循環周期增加逐漸下降,在1000個周期時均能趨于平穩,并未出現再次上升的情況,這說明模型未出現過擬合現象. 其中ACS特征在參數更新的學習率高于CS特征的情況下誤差下降趨勢仍更緩慢,這在一定程度上反映了ACS特征相比于CS特征更加地復雜,難以學習. 在所有模型中,ACS特征在卷積核尺寸為(2,4,10,24,50,90)的網絡中取得了最低的平均相對誤差1.74%,而同模型CS特征的平均相對誤差僅為4.17%,增大了2.43%. 在其余同卷積核尺寸模型中,ACS特征模型的平均相對誤差均低于CS特征模型. 進一步分析同特征在不同尺寸卷積核模型上的表現:ACS特征在(2,4)、(2,4,10,24)、(2,4,10,24,50,90)卷積核模型上的平均相對誤差依次為5.08%、3.90%和1.74%,CS特征為6.31%、5.94%和4.17%. 通過比較差值發現,無論是ACS特征還是CS特征,更大尺寸的卷積核使模型平均相對誤差下降更明顯. 而由于輸入參數規模的限制,進一步設置更大尺寸的卷積核較為困難,通過增加同尺寸卷積核的個數亦能得到更大規模的卷積網絡模型,因此在圖5(b)中以卷積核尺寸為(2,4,10,24,50,90)的模型作為基礎模型,通過改變單個尺寸卷積核的個數,比較了更大規模網絡的平均相對誤差. 結果表明,在單尺寸卷積核個數為100的模型上平均相對誤差是最低的,穩定在2%左右,最低可達到1.74%.
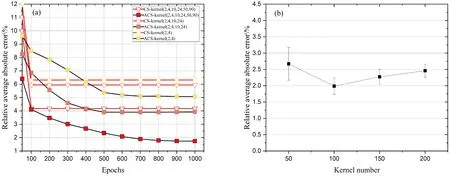
圖5 (a)不同模型預測晶界能的平均相對誤差隨循環周期變化 (b) 平均相對誤差隨卷積核個數的變化Fig. 5 (a)Relative average absolute errors (%) of predicted grain boundary energies of the different CNNs. (b) Relative average absolute errors (%) of the different convolutional kernel numbers
針對具有最低平均相對誤差的卷積核尺寸為(2,4,10,24,50,90)、同尺寸卷積核個數為100的模型,比較了分子動力學計算的晶界能和模型預測的晶界能間的差距. 如圖6(a-b)所示,CS特征模型在測試集上的平均相對誤差(4.17%)高于ACS特征模型(1.74%),樣本分布更為離散,出現較大相對誤差的可能性也更大. 經圖6(c-d)統計,測試集上,ACS特征模型的最大相對誤差小于6%,而CS特征模型則達到了10%. 由于測試集樣本較少,在圖中一并統計了原始訓練集上的相對誤差樣本分布,可見ACS特征模型上的分布也更為集中. 綜合以上結果,ACS特征模型相比于CS特征模型在預測晶界能的任務中有更大的優勢. 相比于文獻8以機器學習方法在Al的非對稱傾斜晶界上預測晶界能取得的結果(晶界能在200至600 mJ/m2范圍內的平均絕對值誤差為11.35 mJ/m2),本文在更廣傾斜角范圍的對稱傾斜晶界上取得了相當的結果.
通過輸出TextCNN最后一層網絡的權值可以得到經該模型加工后的16維晶界特征(vi)和晶界能(GBE)間的定量關系:
GBE=0.23v1-0.28v2+0.19v3+0.28v4-
0.26v5+0.27v6+0.14v7-0.14v8-
0.15v9-0.12v10-0.21v11-0.30v12-
0.16v13+0.19v14-0.13v15+0.21v16
(4)

圖6 (a-b)所有樣本集上原始晶界能和預測晶界能對比圖,(c-d)預測結果統計分布圖.Fig. 6 (a-b) The original GB energies are compared with the predicted GB energies in the whole set; (c-d) Statistical result of network prediction
4.2 分層抽樣和數據增強的影響
為了進一步確認按傾斜角分層抽樣對模型預測能力的影響是正向的,在部分的數據集上分別以CS和ACS作為晶界特征在同樣的模型上比較了三種抽樣方式(按傾斜軸分層抽樣、隨機抽樣、不均勻抽樣)對模型預測能力的影響. 其中,不均勻抽樣是只選擇了傾斜角較大的樣本. 在同樣的測試集上計算了晶界能的平均相對誤差,結果如圖7所示,不論是ACS特征還是CS特征,分層抽樣得到的平均相對誤差均是最小的,隨機抽樣次之,不均勻抽樣最大. 這表明了不同傾斜角的對稱傾斜晶界的晶界結構是有一定的差異的,僅使用一定傾斜角范圍內的晶界將導致樣本在特征空間分布不均勻,易發生過擬合的情況,在更大傾斜角范圍內的晶界上預測結果較差. 因而通過按傾斜角分層抽樣的途徑,能讓訓練樣本空間分布得更加均勻,使模型在測試集晶界上能有更準確的預測結果.
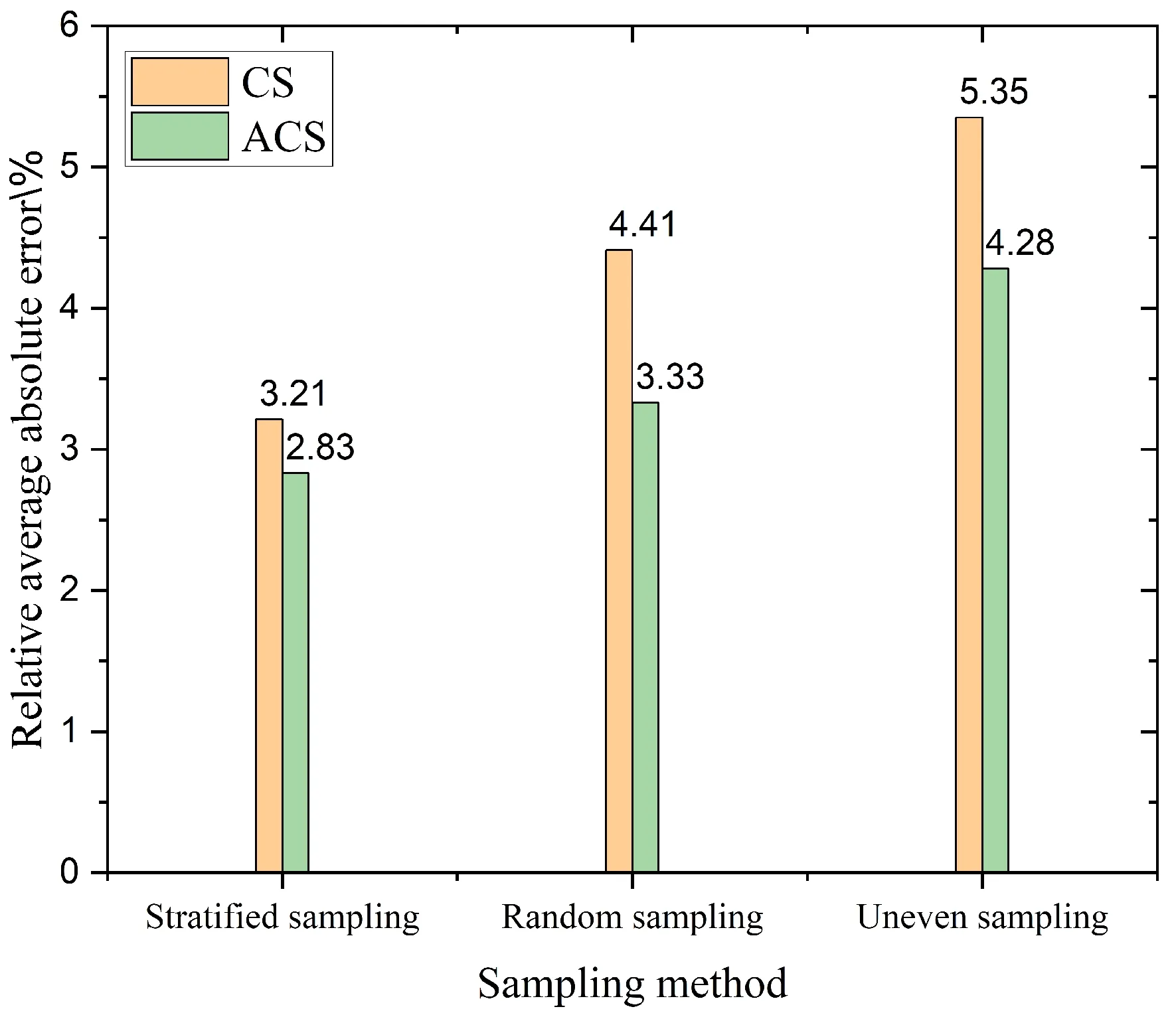
圖7 不同訓練集采樣方法在CNN模型上預測晶界能平均相對誤差的變化Fig. 7 Relative average absolute errors (%) of predicted grain boundary energies of the CNN varies with the different sampling methods
如圖8所示,以同一模型為基礎,對同一訓練集進行數據增強,通過改變增強樣本的個數在相同測試集上比較了平均相對誤差的變化. 結果表明,相較于未進行數據增強的模型,合理引入增強樣本能夠降低模型預測晶界能的平均相對誤差,而隨著增強樣本個數的增多,平均相對誤差在增強樣本個數為65左右時達到了最低點,隨后出現了一定的上升. 以此可見,數據增強在一定范圍內能夠合理地增加訓練集的個數,提高模型的魯棒性,但隨著平移尺度的加大和增強樣本個數的增多,對模型引入了一些負面的噪聲,改變了訓練數據的主要特征分布,導致模型的預測精度產生了一定的下降,類似的結論在文獻[25]中也有體現. 因此,選擇合適的增強尺度和增強樣本個數對提升模型的預測性能是十分重要的.
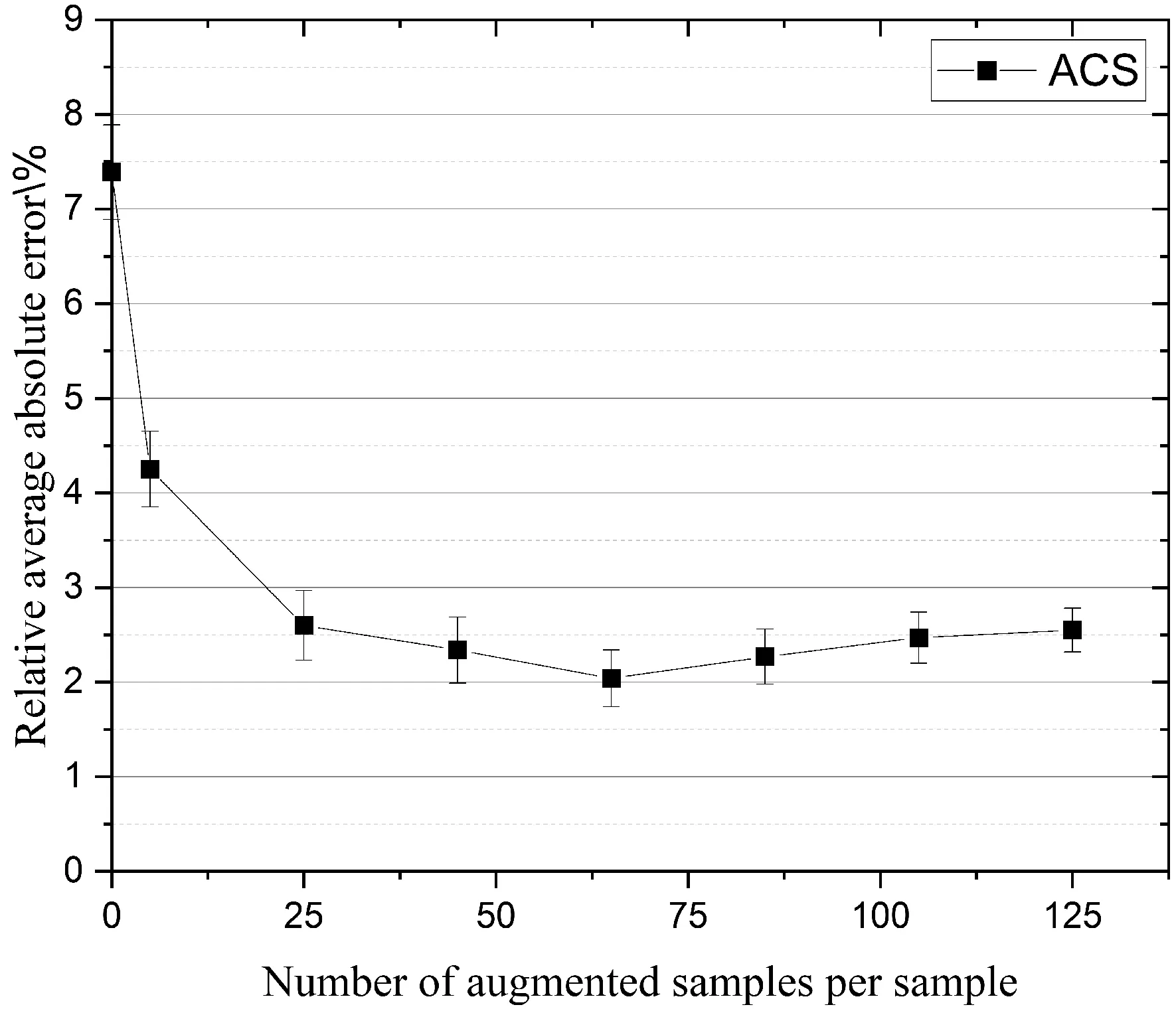
圖8 不同數據增強樣本個數下預測晶界能平均相對誤差的變化Fig. 8 Relative average absolute errors (%) of predicted grain boundary energies varies with the augmented sample numbers
5 結 論
本文基于卷積神經網絡TextCNN結構,在α-Fe的<100>和<110>傾斜軸的對稱傾斜晶界上建立了晶界能預測模型. 以融合原子密度信息的積累中心對稱參數作為晶界特征,通過按傾斜角分層抽樣和“翻轉平移”的數據增強方法進一步提升了模型的效果. 測試集結果表明,該方法預測晶界能的平均相對誤差小于1.75%. 通過該方法,本文在深度學習的模型基礎上建立了晶界結構和晶界能之間的連接,這種連接方法同樣可用于預測其他晶界性能,為進一步研究F/M鋼晶界工程提供了支撐.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
