小波分解和改進(jìn)卷積神經(jīng)網(wǎng)絡(luò)相融合的水聲目標(biāo)識(shí)別方法
2022-03-11 05:34:56黃擎曾向陽(yáng)
哈爾濱工程大學(xué)學(xué)報(bào) 2022年2期
黃擎, 曾向陽(yáng)
(西北工業(yè)大學(xué) 航海學(xué)院,陜西 西安 710072)
水聲目標(biāo)分類識(shí)別技術(shù)是水聲探測(cè)領(lǐng)域的關(guān)鍵技術(shù),也是水聲信號(hào)處理中的重點(diǎn)和難點(diǎn)[1]。通常將水聲目標(biāo)識(shí)別過程分為特征提取和分類決策2個(gè)相對(duì)獨(dú)立的部分。針對(duì)這2部分均已開展了大量的研究,提出的各種算法的有效性也得到了證明。但分步處理的方法未考慮提取的特征與分類器之間的“耦合”作用,因而構(gòu)建的識(shí)別系統(tǒng)性能難以達(dá)到最優(yōu)。
近年來,深度學(xué)習(xí)[2-3]在機(jī)器學(xué)習(xí)領(lǐng)域異軍突起,與傳統(tǒng)方法不同,深度學(xué)習(xí)只需要輸入含有豐富目標(biāo)特性的信息,通過逐層學(xué)習(xí)挖掘,從而可通過自動(dòng)提取出最具有鑒別力的抽象信息進(jìn)行識(shí)別。從系統(tǒng)連接的角度看,深度學(xué)習(xí)中的特征提取和模式識(shí)別是一個(gè)整體,避免了傳統(tǒng)方法由于分步執(zhí)行特征提取和模式識(shí)別導(dǎo)致的系統(tǒng)“耦合”作用,能進(jìn)一步提升識(shí)別系統(tǒng)的性能。目前,最常見的深度學(xué)習(xí)算法-卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks, CNN)已開始在水聲信號(hào)處理[4]和水聲圖像處理[5-6]方面得到廣泛地應(yīng)用。CNN可通過結(jié)合局部感知區(qū)域、共享權(quán)重、空間或時(shí)間上的池化降采樣3大特點(diǎn)來充分利用數(shù)據(jù)本身包含的局部性等特征在保證一定程度上的位移不變性[7]的基礎(chǔ)上來優(yōu)化網(wǎng)絡(luò)結(jié)構(gòu),這使得CNN可用于水聲目標(biāo)識(shí)別。本文針對(duì)深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程中會(huì)產(chǎn)生內(nèi)部協(xié)方差偏移(internal covariate shift,ICS)以及隨機(jī)梯度算法在局部極值附近的擺動(dòng)幅度較大、優(yōu)化速度較慢的問題,引入批量標(biāo)準(zhǔn)化層(batch normalization,BN)和自適應(yīng)力矩估計(jì)(adaptive moment estimation,Adam)梯度優(yōu)化算法對(duì)CNN進(jìn)行改進(jìn)。
CNN可直接輸入信號(hào)的波形或頻譜,考慮到小波分析在非平穩(wěn)信號(hào)處理中的優(yōu)勢(shì),本文將其與改進(jìn)CNN算法融合,提出一種名為WAVEDEC_CNN的水聲目標(biāo)識(shí)別方法。該方法首先將原始信號(hào)用小波分解進(jìn)行預(yù)處理(不同于傳統(tǒng)的基于小波分解的小波去噪方法,本文提出的方法不對(duì)分解后的小波系數(shù)進(jìn)行任何處理);再輸入改進(jìn)的CNN對(duì)目標(biāo)進(jìn)行識(shí)別。在實(shí)驗(yàn)驗(yàn)證階段,先將本文提出的方法與MFCC特征提取+SVM分類器方法進(jìn)行對(duì)比;然后與無(wú)預(yù)處理的卷積神經(jīng)網(wǎng)絡(luò)(NO_CNN)、小波包分解預(yù)處理結(jié)合卷積神經(jīng)網(wǎng)絡(luò)(WPDEC_CNN)以及經(jīng)驗(yàn)?zāi)B(tài)分解預(yù)處理結(jié)合卷積神經(jīng)網(wǎng)絡(luò)(EMD_CNN)的方法進(jìn)行對(duì)比。
1 WAVEDEC_CNN識(shí)別方法
本文提出一種名為WAVEDEC_CNN的水聲目標(biāo)識(shí)別方法。該方法將小波分解和基于梯度優(yōu)化和層批量歸一化改進(jìn)的CNN算法融合。
1.1 改進(jìn)的卷積神經(jīng)網(wǎng)絡(luò)
與深度學(xué)習(xí)中的傳統(tǒng)框架相比,卷積神經(jīng)網(wǎng)絡(luò)是局部連接并且權(quán)值共享,大大減小了網(wǎng)絡(luò)參數(shù),同時(shí)池化層下采樣通過減少網(wǎng)絡(luò)節(jié)點(diǎn)數(shù),可進(jìn)一步減小參數(shù)數(shù)量。這對(duì)于高維輸入數(shù)據(jù)尤為重要。同時(shí),CNN利用卷積層進(jìn)行信號(hào)的增強(qiáng),并利用池化層獲得具有位移、時(shí)移或旋轉(zhuǎn)不變的特征,最后通過全連接神經(jīng)網(wǎng)絡(luò)進(jìn)行分類。從整體上看,卷積層和池化層的交替使用可以使模型具有良好的穩(wěn)健特性。
與傳統(tǒng)的CNN不同,本文提出的模型在卷積和池化層之間引入了批量標(biāo)準(zhǔn)化層。由于CNN 每層的輸入都受到前面所有層參數(shù)的影響,網(wǎng)絡(luò)參數(shù)的微小變化會(huì)隨著網(wǎng)絡(luò)的深化而放大,這使得訓(xùn)練變得復(fù)雜。為解決這一問題,本文采用自適應(yīng)力矩估計(jì)對(duì)梯度進(jìn)行優(yōu)化。該方法易于實(shí)現(xiàn),計(jì)算效率高,對(duì)內(nèi)存的需求小,不受梯度的對(duì)角調(diào)整的影響,可用于數(shù)據(jù)和/或參數(shù)很大的問題。
1.1.1 參數(shù)優(yōu)化方法
白化輸入可以加快網(wǎng)絡(luò)收斂速度,在此基礎(chǔ)上Loffe[8]提出可以在網(wǎng)絡(luò)任意隱層加入BN層來減小訓(xùn)練過程中的內(nèi)部協(xié)方差偏移,從而防止梯度消失,同時(shí),該模型允許使用更大的學(xué)習(xí)率,從而加快網(wǎng)絡(luò)收斂速度。
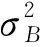
(1)
(2)
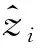
(3)
式中:yi為標(biāo)準(zhǔn)化后的輸出,γ和β為與BN層高斯分布有關(guān)的可學(xué)習(xí)的超參數(shù)。參數(shù)更新:
(4)
(5)
根據(jù)均值和方差的梯度可以獲得反向傳播過程中BN層輸出結(jié)果的梯度:
(6)
BN層與高斯分布有關(guān)的超參數(shù)梯度:
(7)
由于識(shí)別過程中,無(wú)法直接獲得測(cè)試樣本的均值和方差。因此識(shí)別過程BN層使用訓(xùn)練過程中各批量的均值E[x]和方差Var[x]的無(wú)偏估計(jì),參數(shù)設(shè)置為:
(8)
識(shí)別過程中高斯分布超參數(shù)設(shè)置為:
(9)
識(shí)別過程中測(cè)試樣本更新公式為:
y=γ′·zi+β′
(10)
1.1.2 Adam梯度優(yōu)化方法
Kingma[9]提出Adam梯度優(yōu)化算法。該方法將動(dòng)量法和均方根傳播算法相結(jié)合,優(yōu)化了隨機(jī)梯度算法在局部極值附近的擺動(dòng)幅度較大和優(yōu)化速度較慢的問題。
Adam梯度下降過程中動(dòng)量法和均方根傳播算法中權(quán)重和偏差初始值均設(shè)為0。vdw和vdb表示動(dòng)量法中權(quán)重和偏差一階矩指數(shù)加權(quán)平均數(shù),sdw和sdb表示均方根傳播算法中權(quán)重和偏差二階矩指數(shù)加權(quán)平均數(shù)。初始化方法為:
(11)
Adam梯度下降過程動(dòng)量法vdw和vdb參數(shù)更新為:
(12)
式中β1表示一階矩累加的指數(shù)。
Adam梯度下降過程均方根傳播算法sdw和sdb參數(shù)更新公式為:
(13)
式中β2表示二階矩累加的指數(shù)。
Adam算法權(quán)重W和b更新公式為:
(14)
式中α表示學(xué)習(xí)率。
1.2 小波分解和改進(jìn)神經(jīng)卷積神經(jīng)網(wǎng)絡(luò)融合方法
CNN已開始在水聲目標(biāo)識(shí)別方面得到廣泛地應(yīng)用,考慮到小波分析在非平穩(wěn)信號(hào)處理中的優(yōu)勢(shì),本文將其與改進(jìn)的CNN算法融合,提出了一種名為WAVEDEC_CNN的水聲目標(biāo)識(shí)別方法。
小波分析與加固定窗的短時(shí)傅里葉分析方法不同,可以用不同形狀的窗函數(shù)(小波基函數(shù))分析處理信號(hào),從而實(shí)現(xiàn)低頻處獲取較高的頻率分辨力、高頻處獲取較高的時(shí)間分辨力。
小波基函數(shù)定義為:
(15)
式中φ(t)為基小波或者母小波函數(shù),經(jīng)過尺度因子a和平移因子b變換后的φa,b(t)統(tǒng)稱為小波。
對(duì)于離散情況:
φj,k(t)=2-j/2φ(2-j/t-k)j,k∈Z
(16)
采用離散小波變換(DWT)表示分解原始時(shí)域波形信號(hào),得到原始信號(hào)的近似(低頻)成分和細(xì)節(jié)(高頻)成分。小波分解表示將原始信號(hào)經(jīng)過DWT變換后的低頻成分再進(jìn)行DWT變換,循環(huán)次數(shù)由分解層數(shù)決定。
多層小波分解預(yù)處理后,將每層小波系數(shù)拼接作為CNN網(wǎng)絡(luò)的輸入。由此得到的WAVEDEC_CNN方法原理圖如圖1所示。
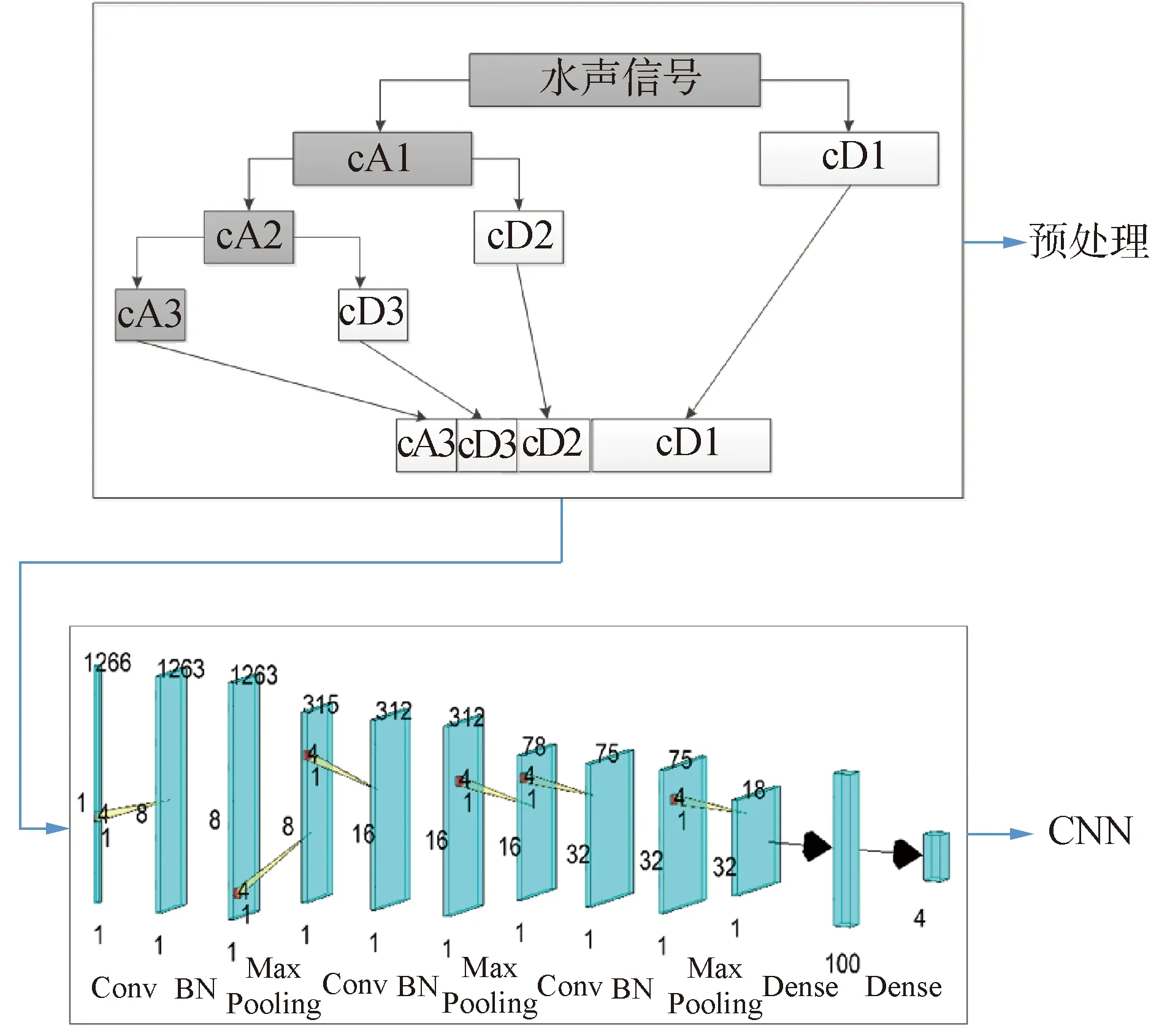
圖1 WAVEDEC_CNN原理Fig.1 Schematic diagram of the WAVEDEC_CNN
圖1上半部分表示以3層小波分解為例,對(duì)時(shí)域信號(hào)進(jìn)行預(yù)處理。其中cA1、cA2和cA3表示的是每層分解的低頻近似信息;cD1、cD2和cD3表示的是每層分解的高頻細(xì)節(jié)信息。下半部分表示的是卷積神經(jīng)網(wǎng)絡(luò)模型,每層數(shù)字表示該層尺寸,相鄰層連接線的數(shù)字表示濾波器尺寸。
pre_wavedec=[cA3,cD3,cD2,cD1]
(17)
小波分解重構(gòu)誤差由下面公式給出:
(18)
式中:norm2表示求向量的2范數(shù)。datareci表示每層小波系數(shù)重構(gòu)的時(shí)域信號(hào)。
以3層小波分解預(yù)處理為例,原始信號(hào)、小波分解重構(gòu)信號(hào)和本文使用卷積神經(jīng)網(wǎng)絡(luò)輸入如圖2所示。
圖2從上至下分別表示原始信號(hào)、重構(gòu)信號(hào)和由式(17)得到的卷積神經(jīng)網(wǎng)絡(luò)輸入樣本。原始信號(hào)和重構(gòu)信號(hào)經(jīng)式(18)計(jì)算的重構(gòu)誤差為1.7×10-11。說明小波分解沒有丟失信息。從最下面的圖可以看出能量主要集中在該樣本的前部分。這是因?yàn)樵夹盘?hào)是某段民船輻射噪聲信號(hào),民船輻射噪聲信號(hào)主要集中在低頻部分,而由式(17)可以看出該樣本的前部分主要表示的是原始信號(hào)的低頻信息cA3。
圖3為原始信號(hào)3層小波分解的cA3、cD1、cD2和cD3系數(shù)圖。
圖3分別表示第3層分解的低頻信息和逐層分解的高頻信息。其中低頻信息整體幅度最大,這是因?yàn)樵夹盘?hào)能量主要集中在低頻部分。這與圖2中樣本結(jié)果一致。
結(jié)合圖2和圖3,小波分解預(yù)處理不僅不會(huì)丟失信息,同時(shí)將原始信號(hào)自動(dòng)按頻帶劃分,與原始信號(hào)比較,更能凸顯信號(hào)特點(diǎn)。這對(duì)目標(biāo)識(shí)別是有利的。

圖2 信號(hào)小波分解預(yù)處理結(jié)果Fig.2 Result diagram of the signal with the wavelet decomposition preprocessing
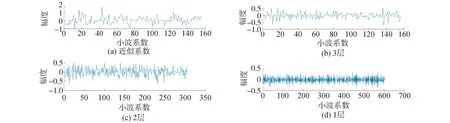
圖3 3層小波分解系數(shù)Fig.3 Coefficient diagram of 3-layer wavelet decomposition
最后在改進(jìn)的卷積神經(jīng)網(wǎng)絡(luò)訓(xùn)練階段,聯(lián)合優(yōu)化交叉熵?fù)p失函數(shù)J:
(19)
式中:y(i)表示第i類真實(shí)標(biāo)簽;xwdec(i)表示經(jīng)過離散小波變換預(yù)處理的輸入樣本;fnet(·)表示本文改進(jìn)的卷積神經(jīng)網(wǎng)絡(luò)。
2 實(shí)測(cè)數(shù)據(jù)實(shí)驗(yàn)
本文實(shí)驗(yàn)數(shù)據(jù)集來自課題組在丹江口水庫(kù)湖試獲取的數(shù)據(jù)。數(shù)據(jù)包含4個(gè)水面目標(biāo):鐵皮船1、快艇2、快艇3和快艇4。湖底布放2個(gè)8元線列陣,采樣頻率為48 kHz。每艘船繞行2個(gè)陣列3圈,每圈截取21段(每段10 s)數(shù)據(jù),共4×3×21×10=2 520 s。每圈取14段作為訓(xùn)練集,剩余7段作為測(cè)試集。將每段信號(hào)按0.1 s分幀,每幀為1個(gè)樣本,因此,訓(xùn)練集樣本總數(shù)為16 800,測(cè)試集樣本總數(shù)為8 400。
超參數(shù)設(shè)置:學(xué)習(xí)率0.01;每次實(shí)驗(yàn)訓(xùn)練30輪,每輪采用批量梯度下降法求梯度,每個(gè)批量為100。重復(fù)實(shí)驗(yàn)50次,每次實(shí)驗(yàn)都隨機(jī)初始化權(quán)重。梯度優(yōu)化算法為adam算法,一階矩估計(jì)的指數(shù)衰減率為0.9;二階矩估計(jì)的指數(shù)衰減率為0.999。L2正則項(xiàng)為10-4。CNN隱藏層設(shè)置3個(gè)卷積層、池化層和一個(gè)全連接層。卷積層濾波器為1×4,步長(zhǎng)為1。濾波器數(shù)目分別為16,32和64。池化層為1×4,采用最大池化,步長(zhǎng)為4。
圖4~7為實(shí)驗(yàn)結(jié)果。其中圖4表示的是重復(fù)實(shí)驗(yàn)50次,每次的識(shí)別結(jié)果。圖5表示從湖試數(shù)據(jù)截取的84段聲音文件的識(shí)別結(jié)果。圖6表示每艘船的識(shí)別結(jié)果。圖7表示的是本文所用的各種深度學(xué)習(xí)方法識(shí)別結(jié)果的混淆矩陣結(jié)果圖。表1是實(shí)驗(yàn)結(jié)果和運(yùn)行時(shí)間,包括從湖試截取的聲音文件構(gòu)建樣本集用的時(shí)間和用卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行訓(xùn)練和識(shí)別的時(shí)間。

圖4 識(shí)別結(jié)果對(duì)比Fig.4 Comparison diagram of the recognition results
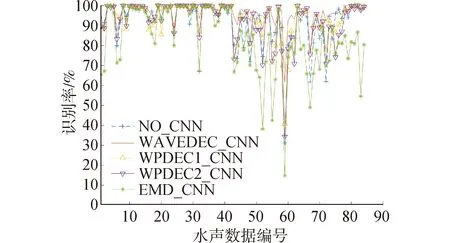
圖5 不同水聲數(shù)據(jù)識(shí)別結(jié)果對(duì)比Fig.5 Comparison diagram of different underwater acoustic

圖6 不同船識(shí)別結(jié)果對(duì)比Fig.6 Comparison diagram of different ships recognition results
結(jié)合圖4和表1可以看出,本文提出的WAVEDEC_CNN方法識(shí)別效果最優(yōu)。識(shí)別率較NO_CNN、WPDEC1_CNN和EMD_CNN等方法分別提升了4.41%、3.23%和12.81%。其中WPDEC1_CNN方法和WPDEC2_CNN分別執(zhí)行了10層和4層小波包分解。雖然小波分解預(yù)處理耗費(fèi)了一定時(shí)間,但是總的運(yùn)行時(shí)間反而最短。
與WAVEDEC_CNN對(duì)比,雖然WPDEC_CNN的頻帶劃分更為精細(xì),但是相同的分解層數(shù)條件下,執(zhí)行DWT的次數(shù)遠(yuǎn)高于WAVEDEC_CNN。以分解層數(shù)N=10為例,WAVEDEC_CNN執(zhí)行了10次DWT運(yùn)算,WPDEC1_CNN執(zhí)行了210-1=1 023次DWT運(yùn)算。因此構(gòu)建樣本集時(shí)WPDEC1_CNN方法花費(fèi)大量時(shí)間,從表1可得約為WAVEDEC_CNN方法的118.5倍。同時(shí)WPDEC1_CNN方法表示的信號(hào)維度較大,用CNN進(jìn)行訓(xùn)練消耗更多時(shí)間,約為WAVEDEC_CNN方法的6.99倍,大約需要9.46 h。雖然WPDEC_CNN方法和WAVEDEC_CNN方法重構(gòu)誤差都是小量級(jí)的(以某一樣本為例,重構(gòu)誤差量級(jí)為10-12),但是預(yù)處理后數(shù)據(jù)的維度大大提升,信息過于分散,識(shí)別率反而下降3.23%。因此,設(shè)置另外一組對(duì)比實(shí)驗(yàn),設(shè)置N=4,記為WPDEC2_CNN。在此分解層數(shù)下,WPDEC2_CNN方法執(zhí)行DWT運(yùn)算為15次,構(gòu)建樣本集時(shí)間僅為WAVEDEC_CNN方法的3.33倍,約為原來的2.8%。實(shí)驗(yàn)結(jié)果表明其識(shí)別率較N=10時(shí)下降了0.75%,比WAVEDEC_CNN方法下降了3.98%。這說明較低的分解層數(shù),雖然可以大幅度降低WPDEC_CNN的運(yùn)行時(shí)間,甚至和WAVEDEC_CNN方法相媲美,但是分解層數(shù)較低時(shí),其對(duì)低頻的劃分反而不如WAVEDEC_CNN方法精細(xì),識(shí)別率低于本文提出的方法。NO_CNN運(yùn)行時(shí)間也較短,但是識(shí)別率相比WPDEC_CNN方法下降4.41%。
從實(shí)驗(yàn)結(jié)果可以看出,EMD_CNN方法識(shí)別效果最差。雖然經(jīng)驗(yàn)?zāi)B(tài)分解后的殘余信號(hào)分量較少,重構(gòu)誤差也較低,但是EMD_CNN方法沒有明確的基函數(shù),分解過程存在模態(tài)混疊效應(yīng)[10]。表現(xiàn)為對(duì)于不同的樣本,其每階模態(tài)表示的信號(hào)瞬時(shí)頻率的頻帶范圍可能不一樣,導(dǎo)致識(shí)別結(jié)果最差。
圖7表示的是每種方法某次實(shí)驗(yàn)結(jié)果的混淆矩陣。因?yàn)楸?深度學(xué)習(xí)識(shí)別結(jié)果是50次實(shí)驗(yàn)的平均值而且方差均較小,所以這些混淆矩陣也是具有代表性的。混淆矩陣右下角結(jié)果表示的是準(zhǔn)確率。混淆矩陣中最下面1行前4列結(jié)果分別表示每類目標(biāo)的召回率,最右邊1列前4行中數(shù)字表示每類目標(biāo)的精確率。混淆矩陣行表示的是預(yù)測(cè)為行數(shù)對(duì)應(yīng)類別的數(shù)目。每一列表示的是當(dāng)前預(yù)測(cè)結(jié)果真實(shí)類標(biāo)為對(duì)應(yīng)列數(shù)。對(duì)角線上前4個(gè)結(jié)果分別表示每類預(yù)測(cè)正確的樣本數(shù)。
圖7(a)到(c)可以看出,WPDEC1_CNN和WPDEC2_CNN方法相比WAVEDEC_CNN方法,在第3類和第4類目標(biāo)上存在明顯的錯(cuò)分問題,其精確率均較低。對(duì)于第3類,WPDEC1_CNN和WPDEC2_CNN方法分別把80和172個(gè)樣本錯(cuò)分為第4類,WAVEDEC_CNN方法僅為27個(gè)。對(duì)于第4類,WPDEC1_CNN和WPDEC2_CNN方法分別把127和112個(gè)樣本錯(cuò)分為第3類,WAVEDEC_CNN方法僅為18個(gè)。說明本文提出的WPDEC1_CNN方法增加了第3類和第4類之間的區(qū)分度。
圖7(d)可以看出,對(duì)于EMD_CNN方法,由于存在模態(tài)混疊效應(yīng),其各類精確率均最低。特別是第3類和第4類,存在嚴(yán)重的錯(cuò)分問題。對(duì)于第3類,將323個(gè)樣本錯(cuò)分為第4類,占第3類樣本數(shù)323/2 100=15.3%。對(duì)于第4類,將396個(gè)樣本錯(cuò)分為第3類,占第4類樣本數(shù)396/2 100=18.9%。
從圖6可以看出,除了EMD_CNN方法外,其他方法對(duì)于船1不同圈的識(shí)別效果都較好,分別為95.65%、96.60%、95.49%和95.75%,本文提出的框架效果最好,對(duì)比其他方法識(shí)別率至少提升0.95%。這是因?yàn)榇?為鐵皮船,船2到船4為不同型號(hào)的快艇,鐵皮船和快艇目標(biāo)特性差異較大。從圖5可以看出,對(duì)于第59段聲音樣本幾種方法識(shí)別率差別較大,因此,對(duì)其專門進(jìn)行分析。圖8(a)為第59段聲音文件,它來自船3第3圈。各方法識(shí)別結(jié)果分別為31.14%、61.74%、40.70%、34.32%。圖8(b)為第60段聲音文件,同樣來自船3第3圈。各方法識(shí)別結(jié)果分別為80.22%、92.42%、67.76%、78.42%。每段聲音文件長(zhǎng)度為10 s。
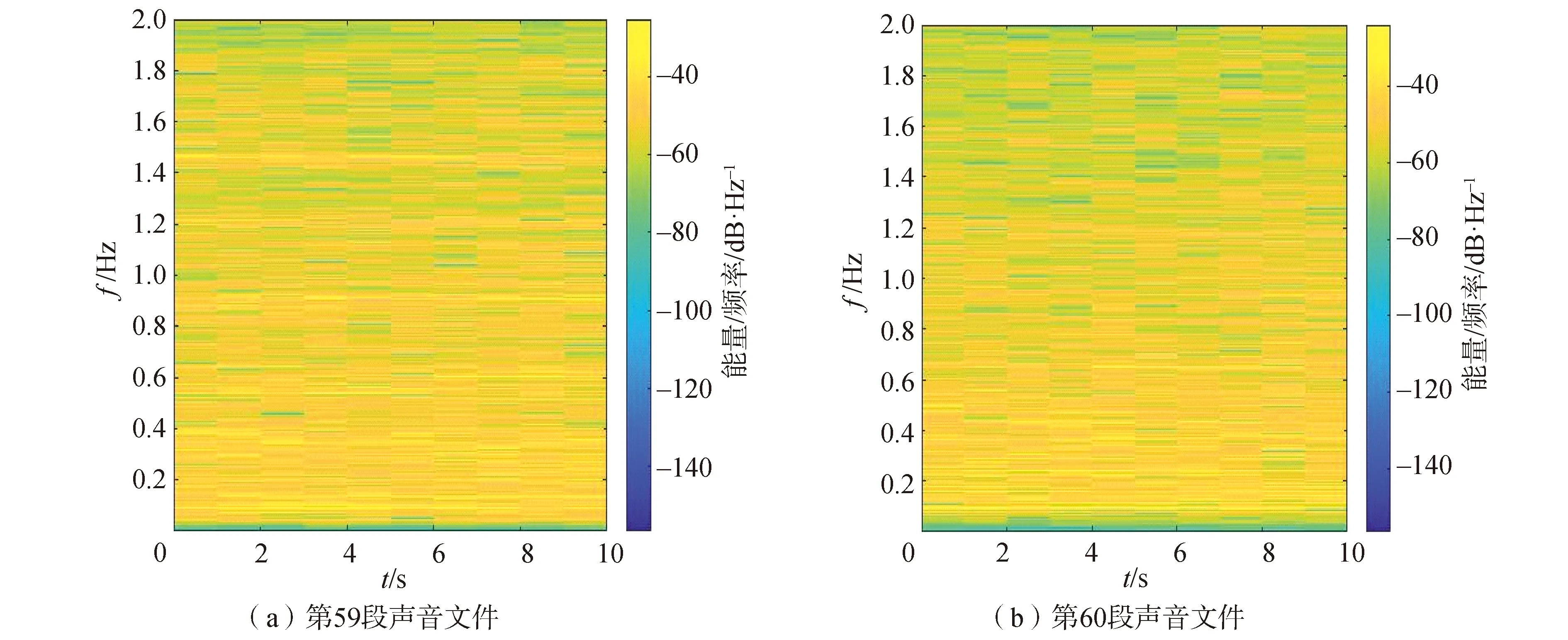
圖8 第59段和第60段聲音文件STFT圖Fig.8 STFT diagram of the 59th segment and 60th segment of underwater data
對(duì)比圖8(a)和圖8(b)可以看出,第59段和60段聲音在1 000 Hz以內(nèi)時(shí)頻分布基本一致。但是第59段聲音文件在1.465 kHz處存在干擾,大約持續(xù)7 s。這可能是其他方法在第59段聲音處識(shí)別效果較差的原因。這也說明本文提出的WAVEDEC_CNN抗干擾能力較強(qiáng)。
3 結(jié)論
1)與NO_CNN、WPDEC_CNN和EMD_CNN相比,本文提出的識(shí)別框架的識(shí)別率有明顯的提升。
2)WPDEC_CNN方法雖然重構(gòu)誤差較低,但預(yù)處理和網(wǎng)絡(luò)訓(xùn)練需要花費(fèi)大量時(shí)間。EMD_CNN由于存在模態(tài)混疊反而效果最差。但是這些方法識(shí)別性能都優(yōu)于傳統(tǒng)的識(shí)別方法。
因?yàn)椴煌〔ɑ鶚?gòu)造的小波濾波器性能可能不一樣,同時(shí)較高的分解層數(shù),可以獲得較為精細(xì)的頻帶劃分,能否更好的區(qū)分干擾和目標(biāo),因此下一步將更加深入的研究不同小波基和不同的分解層數(shù)對(duì)識(shí)別結(jié)果的影響。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評(píng)價(jià)·高一版(2020年6期)2020-11-02 02:45:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
中國(guó)生殖健康(2019年3期)2019-02-01 06:12:26
Coco薇(2016年2期)2016-03-22 02:42:52
鑿巖機(jī)械氣動(dòng)工具(2016年3期)2016-03-01 04:00:25
海軍航空大學(xué)學(xué)報(bào)(2015年3期)2015-11-11 17:20:00
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
