基于深度學習的虛假域名檢測
2022-03-14 11:36:56劉子雁王云霄孔漢章
濟南大學學報(自然科學版) 2022年2期
劉子雁,李 寧,張 丞,崔 博,王云霄,孔漢章
(國網山東省電力公司信息通信公司,山東 濟南 250021)
互聯網信息技術的普及為社會提供了極大的便利,但是開放的網絡和標準化的軟、硬件設施也給人們帶來了諸多潛在的安全威脅。比較常見的惡意程序,如病毒、蠕蟲和木馬等,會竊取個人用戶數據,破壞系統程序,攻擊網絡設備[1]。惡意程序進入目標系統后,通過感染大量設備形成僵尸網絡,利用域名生成算法(domain generation algorithm,DGA)隨機產生一系列虛假域名。僵尸網絡通過不斷查詢虛假域名,接受來自指揮和控制中心的進一步破壞指令,對個人和企業的信息安全構成嚴重威脅。虛假域名檢測是在眾多域名中識別出用于僵尸網絡與控制中心通信的虛假域名,通過對虛假域名進行檢測和有針對性的防御,切斷惡意程序與控制中心的連接,阻止惡意程序對系統的進一步破壞。隨著機器學習以及深度學習技術的不斷發展,通過數據挖掘的方法進行虛假域名檢測成為近年來的研究熱點[2-6]。現有基于深度學習的虛假域名檢測方法大多直接將域名字符序列輸入到相應模型中,沒有充分挖掘域名字符序列中的局部和全局特征,導致虛假域名檢測率不高,虛假域名無法被有效識別等問題。
為了實現基于深度學習的虛假域名檢測,提高虛域名檢測的準確性,本文中提出一種基于一維卷積神經網絡和自注意力機制的虛假域名檢測模型。該模型將輸入域名拆分成字符序列,通過字符嵌入層將字符編碼序列轉換為字符向量序列;將字符向量序列分別輸入到一維卷積神經網絡和注意力機制網絡中,分別提取字符向量序列的局部特征和全局特征;將局部和全局特征向量拼接,輸入到多層感知機當中,得到該域名屬于不同虛假域名種類的概率分布向量,最終實現虛假域名的多分類檢測。
1 虛假域名檢測
虛假域名檢測已成為當前的研究熱點。根據所用方法和技術的不同,現有檢測方法大致可分為2類,即基于特征工程的機器學習方法和基于深度學習的字符序列建模方法。
1.1 基于特征工程的虛假域名檢測
文獻[7]中從域名系統(domain name system,DNS)數據中提取時間相關特征、DNS響應特征、生存時間(time to live,TTL)特征、域名文本特征等19種特征,并基于J48決策樹構建了一種域名分類檢測模型。文獻[8]中通過對Alexa數據集中的10萬個正常域名進行詞法模式和發音規則分析,提取了字符分布模板、字符結構模板和單詞發音等相關特征,隨后基于隨機森林實現對虛假域名的檢測。與上述2種方法不同的是,文獻[9]在以上構建的特征基礎上,借助谷歌搜索引擎另外構建了網絡搜索相關特征,將域名作為請求地址在谷歌瀏覽器中執行,統計前50個搜索結果中出現該域名的個數,并根據構建的詞法特征和網絡檢索特征,構建以隨機森林為基礎的域名檢測模型。文獻[10]中詳細分析了虛假域名和合法域名在字符分布上的不同,提出了多種字符特征提取規則,包括Kullback-Leibler(KL)距離、Jaccard指數(JI)和Edit距離,根據提取的特征,訓練基于邏輯回歸算法的域名分類器,實現對虛假域名的識別和檢測。除了使用虛假域名的統計學特征,研究人員嘗試通過引入輔助信息,如域名查詢服務特征(WHOIS features)[11]、域名存在狀態特征等,將這些特征作為補充信息輸入到分類器中以優化域名檢測算法的性能。
1.2 基于深度學習的虛假域名檢測
近年來,深度學習算法在眾多領域取得了突破性的進展。相比于基于特征工程的域名檢測算法,深度學習算法能夠自動地實現域名特征提取,避免了人為選擇特征對檢測結果的擾動,因此,眾多學者嘗試將深度學習算法引入到虛假域名檢測模型中,例如文獻[12]中提出將長短期記憶神經網絡(long short-term memory networks, LSTM)應用到域名檢測中。通過對域名進行字符級別的分詞、嵌入,將域名中的字符轉換成稠密向量,之后將字符向量序列輸入到LSTM當中,得到域名表示向量,最后通過全連接層得到輸出概率,以此概率值實現虛假域名檢測,實驗結果表明,LSTM算法在域名檢測任務中取得了較好的結果。進一步地,文獻[13]中將注意力機制應用到LSTM輸出序列上,用來判斷域名中的各個字符對檢測結果的影響程度,實驗結果表明,相對于單純LSTM模型,LSTM和注意力機制相結合的深度模型檢測結果更好。除了LSTM,一維卷積神經網絡(1-dimensional convolutional neural network, Conv1D)以其強大的序列局部特征提取能力,在虛假域名檢測任務中得到了廣泛應用,例如文獻[14]中提出一種基于一維卷積神經網絡的域名檢測模型,在特定數據集上,一維卷積神經網絡檢測算法取得了較好的實驗效果。按照域名生成策略的不同,虛假域名分為不同的種類。相比于字符隨機組合生成的域名(如iagoeama.com、adfmgnn.com),基于單詞隨機組合策略生成的域名(如yeahduck.com、lifthiddenlook.com)具有更強的欺騙性,檢測難度更大,因此文獻[15]中提出一種LSTM和一維卷積神經網絡相結合的深度學習模型,提高了基于單詞隨機組合策略生成的虛假域名的檢測性能。除此之外,其他形式的深度學習算法也被用于虛假域名檢測[16-18]。
2 模型設計
本文中提出的基于深度學習的虛假域名檢測模型如圖1所示。該模型是一種端到端的深度學習模型,主要包含輸入、數據預處理、字符嵌入、一維卷積神經網絡、自注意力機制、多層感知機及輸出共7個模塊。其中一維卷積神經網絡模塊用來提取域名字符序列中的局部特征,自注意力機制模塊用來提取域名字符序列中的全局特征。將兩者拼接之后輸入到多層感知機中,得到最終的預測概率值。

圖1 基于深度學習的虛假域名檢測模型
2.1 輸入模塊
模型輸入為待檢測域名字符串,例如合法域名www.baidu.com、www.tencent.com以及虛假域名jbaafin.com、ychxrucxi.info。
2.2 數據預處理模塊
數據預處理模塊將域名字符串處理成模型要求輸入的形式。具體地,首先將域名字符串拆分成字符序列;然后根據構建的字符-索引字典,將字符序列轉換成字符的索引序列;最后通過填充操作,將變長序列的相應位置填補成0。數據預處理之后的字符序列可表示為X={x0,x1,x2,…,xN},xi表示字符序列中的第i(0≤i≤N)個字符,N表示字符序列的最大長度。
2.3 字符嵌入模塊
根據字符-索引字典,構建字符嵌入表(character embedding table)。通過查表的方式將以上字符序列表示為字符嵌入向量序列X=(x0,x1,x2,…,xN),xi∈D,其中D為字符嵌入向量特征維度。
2.4 一維卷積神經網絡模塊
該模塊利用一維卷積神經網絡實現域名字符序列局部特征提取。具體地,對X=(x0,x1,x2,…,xN)∈N×D進行卷積操作,
ci=f(W·Xi∶i+h-1+b),
(1)
式中:ci為特征值;f為sigmoid激活函數;W∈d×h為卷積核,其中該卷積核的寬度為d,高度為h;Xi∶i+h-1為第i個滑動窗口內的字符向量序列,i∶i+h-1表示字符向量序列的索引范圍;b為偏置項。
經過卷積核的不斷滑動,得到該卷積核下的特征映射向量c=(c0,c1,…,cn-h+1)。將該特征映射向量c輸入到最大池化層,提取特征映射向量中的最大值,以保留顯著特征,具體表示如下:
cmax=MaxPooling(c),
(2)
式中cmax為使用卷積核W提取到的字符序列中的最顯著特征值,MaxPooling為最大池化操作。
為了提取字符序列中更加豐富多樣的特征,本文中設計了如表1所示的一維卷積神經網絡結構。利用不同高度h的卷積核,提取字符序列中不同的局部特征。通過將不同卷積核最大池化層輸出特征拼接在一起,得到該卷積核尺寸下的輸出向量oh。

表1 一維卷積神經網絡結構
最后,將不同卷積核尺寸下的輸出向量拼接在一起,得到最終的一維卷積神經網絡輸出向量oconv,
oconv=o2?o3?o4?o5,
(3)
式中?表示向量拼接符號。
2.5 自注意力機制模塊
基于卷積神經網絡的序列編碼是一種局部的編碼方式,只是對輸入信息的局部依賴關系進行建模。雖然循環網絡理論上可以建立長距離依賴關系;但是,由于存在信息傳遞的容量以及梯度消失問題,因此只能建立短距離依賴關系。自注意力機制用來計算輸入序列中各個元素之間的注意力權重,然后根據該權重值的大小確定序列中其他元素對該元素表示的貢獻大小,為此,本文中提出利用自注意力機制實現字符序列的全局特征提取。
為了提高模型性能,自注意力模型采用查詢-鍵-值(query-key-value, QKV)模式進行注意力得分計算。與局部特征提取相同的是,全局特征提取模塊輸入序列也為X=(x0,x1,x2,…,xN)。對于該輸入序列X,通過不同方式可將其映射到不同的向量空間中,即
Q=WqX∈Dq×N,
(4)
K=WkX∈Dk×N,
(5)
V=WvX∈Dv×N,
(6)
式中:Wq∈Dq×D、Wk∈Dk×D、Wv∈Dv×D分別為查詢-鍵-值的線性映射參數矩陣,Dq、Dk、Dv為對應矩陣的維度;Q=(q0,q1,…,qN)、K=(k0,k1,…,kN)、V=(v0,v1,…,vN)分別為由查詢向量、鍵向量和值向量組成的矩陣。
對于每一個查詢向量qt∈Q,利用公式可得到對應的輸出向量,即
(7)
式中:αti為注意力權重;hi∈H為基于注意力權重的加權輸出向量;s(·)為注意力得分函數,本文中采用縮放點積的形式計算注意力得分,即
(8)
其中H=(h0,h1,…,hN)為自注意力機制輸出向量序列。
將以上輸出序列中的所有向量進行拼接,得到最終的自注意力神經網絡輸出向量osa,即
osa=h0?h1?…?hN。
(9)
2.6 多層感知機模塊
將一維卷積神經網絡的局部特征輸出向量oconv和自注意力神經網絡的全局特征輸出向量osa進行拼接,得到聚合特征向量oagg=oconv?osa。將該聚合特征向量輸入到多層感知機中,最終得到對應類別的概率分布。多層感知機模塊結構如圖2所示,該模塊由輸入層、第1層、第2層、第3層、輸出層組成,其中第1層、第2層、第3層的神經元個數分別為512、256、64,各層神經元的激活函數是Sigmoid函數。經過多層感知機模塊之后,得到待檢測域名的輸出向量。

表示向量oagg中的第i個元素值;yi表示該輸入域名對應第i個域名類別的概率值。
2.7 輸出模塊
本文中提出的虛假域名檢測模型是一種多分類模型,需要將待檢測的域名分類到對應類別中,因此多層感知機中的輸出層神經元個數與數據集中的域名類別個數是相同的。通過softmax激活函數,使輸出層中的各個神經元輸出值對應輸入域名屬于某一類別域名的概率分布。
3 實驗
3.1 數據集
實驗所用數據集來源于公開數據集。該數據集包含合法域名和虛假域名2個部分。合法域名來源于Alexa網站,該網站提供了互聯網常用的域名列表,本文中從中抽取數據。虛假域名包含20種不同的類別(如nymaim、gameover、symmi等)。表2給出了部分合法域名和虛假域名的示例,其中合法域名共包含832 271個數據,虛假域名包含603 387個數據,數據集總量為1 435 658個。本文中提出的虛假域名檢測模型可以將虛假域名分類到具體類別中。
表2 合法域名和虛假域名示例
實驗中設置訓練集、驗證集和測試集的分割比例為8∶1∶1,訓練集用來進行模型訓練,驗證集用來選擇模型超參數,測試集用來對模型的檢測性能進行測試。
3.2 評價指標
虛假域名檢測屬于多分類任務,需要將待檢測域名分類成對應的類別。針對該多分類任務,采用表示被分為正例的樣本中實際為正例比例的精確率P、表示預測出的正例占所有正例比例的召回率R以及用于綜合衡量模型整體性能的精確率與召回率的加權調和平均值F1等指標來評價模型的性能。
式中:TP為真陽性,表示預測為正例,實際也為正例;FP為假陽性,表示預測為正例,實際為負例;FN為假陰性,表示預測為負例,實際為正例。
此外,在不考慮各個類別的數據量不平衡的情況下,采用宏平均對不同類別的評價指標進行算術平均。與宏平均不同的是,加權平均考慮了數據集中各個類別數據的不均衡問題,該指標更能反映出模型在數據不平衡情況下的模型性能。
3.3 實驗設置
實驗的運行環境如下:操作系統為Ubuntu 18.04.3 LTS;隨機存儲器(RAM)為128 GB DDR4@3200MHz;中央處理器(CPU)為Intel(R)Core(TM)i9-9980XE CPU@3.00 GHz;圖形處理器(GPU)為2*NVIDIA TITAN RTX;主要環境庫為Scikit-learn 0.22、TensorFlow 2.2.0。
實驗的主要超參數包括訓練批數、字符向量嵌入維度、模型迭代次數、模型學習率以及自注意力神經網絡神經元個數,具體數值如表3所示。

表3 實驗超參數設置
3.4 結果分析
實驗選擇常用的雙向LSTM和多層感知機與本文所提出的模型(簡稱本文模型)進行對比。模型訓練過程中的損失函數值變化如圖3所示。可以看出,當模型訓練達到37輪的時候,損失函數值達到最小,此時的模型測試結果如表4所示。從實驗結果可以看出,由于多層感知機無法有效獲取序列中的相互依賴特征,因此實驗效果最差。雙向LSTM理論上能夠捕獲序列中的依賴特征;但是,由于信息傳遞的容量以及梯度消失問題,對于虛假域名檢測任務下的長字符序列而言,雙向LSTM無法有效捕獲序列中的長期依賴信息,因此實驗效果次之。本文模型融合了一維卷積神經網絡和自注意力機制在捕獲局部及全局特征時的優點,因此整體上優于多層感知機和雙向LSTM。本文模型的精確率、召回率和F1值的宏平均值分別為0.847、0.795和0.805,加權平均值分別為0.962、0.964和0.961,檢測性能明顯提升。
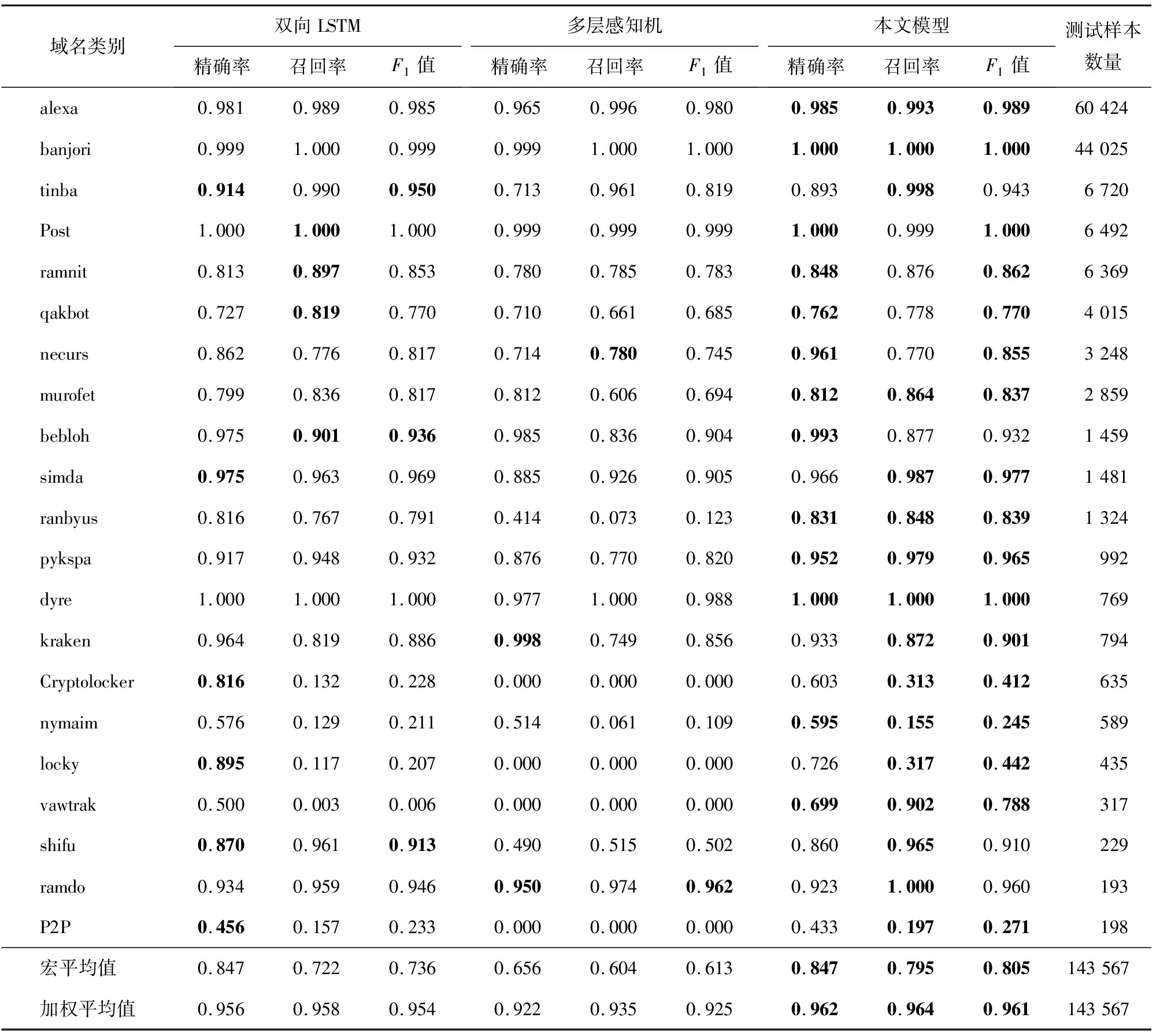
表4 不同模型的域名檢測實驗結果

圖3 本文模型訓練損失值變化曲線
4 結語
為了提高虛假域名檢測的準確性,本文中提出了一種基于深度學習的虛假域名檢測模型。該模型主要包含一維卷積神經網絡模塊和自注意力機制模塊,其中一維卷積神經網絡模塊用于捕獲字符序列中的局部特征,自注意力機制用于捕獲字符序列中的全局特征。通過將2種特征進行融合,輸入到多層感知機中,最終得到待檢測域名對應各個類別的概率分布向量。實驗結果表明,相比于常用的多層感知機和雙向LSTM算法,本文模型具有較好的虛假域名檢測性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
