基于生成式對抗網絡的圖像修復研究進展
2022-03-16 03:58:34楊元英王安志何淋艷任春洪歐衛華
計算機技術與發展 2022年2期
楊元英,王安志,何淋艷,任春洪,歐衛華
(貴州師范大學 大數據與計算機科學學院,貴州 貴陽 550025)
0 引 言
圖像修復是數字圖像處理和計算機視覺領域中的一個重要研究方向,主要通過計算機視覺等技術達到修復圖像中缺失信息的目的。許多計算機視覺任務都要基于完整、清晰的圖像進行分析、處理,而圖像在采集和存儲等過程中易受多種因素影響,造成圖像信息的丟失和損壞,給這些視覺任務的實現帶來嚴重影響。因此,對圖像修復展開研究具有極其重要的意義和應用價值。
鑒于此,文章對圖像修復展開了系統的調研,大致可分為四類:基于結構的圖像修復、基于紋理的圖像修復、基于稀疏表示的圖像修復和基于深度學習的圖像修復。其中,基于結構的修復采用偏微分方程實現,此類算法健壯性較差,修復后存在模糊等問題。基于紋理的方法利用已知區域的紋理構造缺失信息,可有效避免修復區域的模糊問題,但無法獲取高層語義信息,在處理紋理復雜等挑戰性圖像時性能較差。基于稀疏表達的方法可有效地表示圖像的已知信息,但修復區域較大時,該方法受已知信息有限的制約,修復效果仍不理想。
隨著深度學習理論在計算機視覺等領域取得突破性進展,生成式對抗網絡(generative adversarial network,GAN)在圖像修復等領域取得了良好效果。GAN良好的特征表示能力可捕獲高層語義特征,有效保持圖像內容以及語義上的一致性,能有效避免修復圖像出現模糊等失真問題。文章對基于GAN的圖像修復方法進行全面的總結,首先對GAN的原理和圖像修復問題進行闡述,然后對傳統圖像修復方法和基于GAN的修復方法進行深入分析,并總結了主流的公開數據集以及評估方法,最后進行了總結和展望。
1 生成式對抗網絡的基本原理
GAN包括兩個子網絡:生成器G
學習訓練樣本的概率分布,并生成與真實圖像概率分布盡可能一致的生成圖像;判別器D
對G
的生成圖像和真實圖像進行判別。GAN本質上是從訓練樣本數據中學習概率分布,并根據所學習的概率分布生成新的樣本數據。其基本結構如圖1所示,通過讓G
和D
進行對抗學習,相互提升,從而得到具有良好生成能力的G
。首先,G
接收一個隨機噪聲z
作為輸入,z
服從P
(z
)分布,生成器通過學習其分布概率生成樣本數據G
(z
),生成樣本服從P
()(G
(z
))分布。D
接收真實數據x
,D
(x
)表示x
通過D
的判別結果,x
也服從P
(x
)分布,D
(G
(z
))代表輸入數據G
(z
)是真實樣本的概率。G
和D
同時進行對抗訓練,直到D
無法區分生成數據和真實數據時訓練結束。GAN的訓練過程可看作是目標函數V
(D
,G
) 最大化-最小化交替的過程:
E
~()[log(1-D
(G
(z
)))](1)

圖1 生成式對抗網絡基本結構
G
主要采用兩種方法構造:一類是深度卷積網絡,另一類是自編碼網絡。原始的自編碼器構造的G
無法學習深層次的特征,生成樣本與原圖相似性較差。隨后涌現了兩類改進方法:(1)對單一自編碼網絡進行改進;(2)兩個編碼網絡級聯或嵌套。單一自編碼器網絡主要在特征提取、融合和傳遞等方面進行改進。其中Yan等人引入跳躍連接,增加編碼層和解碼層之間的特征傳遞,使重構層生成的圖像可保留更多的細節信息。Lizuka等將擴張卷積引入標準編碼器網絡中,減少網絡訓練參數并增大感受野。現有判別器D
主要分為全局判別器、局部判別器和多尺度判別器。局部判別器對生成的缺失域樣本數據進行判定,但無法保持缺失域的邊緣語義、內容一致性和全局一致性。而全局判別器通過對修復區域和整體圖像像素的上下文結構語義進行判定,促進生成器恢復局部和全局語義更一致的樣本特征數據。多尺度判別器被引入來獲取細節信息更豐富的樣本數據。通過對真實樣本和生成樣本分別進行下采樣,分別在兩個不同尺度上區分真實圖和生成樣本圖,可更有效促進圖像修復網絡性能。2 基于人工特征的傳統圖像修復算法
在圖像采集中,由于光線、運動、遮擋物等噪聲的影響,圖像產生模糊、不清晰等問題。針對以上圖像缺損問題,需要根據圖像修復的不同需求,采用適宜的圖像修復技術對缺損區域進行修復。如圖2,a到c行分別為缺損圖像、采取圖像修復技術處理的效果和真實場景圖。從圖2可知,現有圖像修復技術的效果與真實圖差別不大,但仍存在信息丟失等失真問題。

圖2 圖像修復實例效果
2.1 基于結構的圖像修復
基于結構的圖像修復方法主要基于偏微分方程PDE實現,又稱為基于擴散的圖像修復方法。Bertalmio等人首次提出基于PDE方程的方法,也稱為BSCB模型圖像修復方法。該方法以像素為單位,修復效率較低,沒有考慮圖像缺損區域和全局圖像的整體協調性,僅適合缺失區域較小的圖像修復任務。在BSCB模型的基礎上,Chan等人提出利用梯度下降流計算的全變分(TV)模型,修復速度大幅度提高,但沒有考慮圖像的幾何特征,修復邊緣易出現斷層。隨后又提出采用曲率驅動擴散(CDD)的修復模型,處理缺損區域更大的圖像修復問題。Tai等人提出基于四階偏微分方程的TV-Stokes模型,在處理紋理缺損圖像上表現出顯著修復效果。此外,基于PDE的改進方法還有Euler’s Elastica模型、Mumford-Shah-Euler模型、Mumford-Shah模型和改進TV的模型等方法。這些方法對于細微裂痕、小污點等小缺損區域的圖像有較好的修復效果,但缺乏更高層次的條件約束,對于較大區域的修復通常會出現紋理錯位等圖像失真問題。
2.2 基于紋理的圖像修復
基于紋理的圖像修復技術搜索已知像素中的最優紋理像素,并將最優像素用于缺損區域的修復,可以較好地保存圖像的紋理和結構信息。Criminisi等提出一種基于圖像塊的Criminisi算法,通過搜索周圍信息最豐富且最優的目標像素塊,使修復的速度得到了大幅度提升。但在受損面積大且有重要區域缺失,例如嘴巴、眼睛等重要語義信息時,修復效果較差。Tang F等人在Criminisi的基礎上,提出一種利用CBLS的方法,采取縮小最優匹配塊的檢索進行修復,提升修復效率,但該方法降低了修復效果。Zhang等人通過采取局部搜索代替全局搜索的方法,減少非相近塊的匹配,進而提升圖像的修復效果。這些基于紋理的改進方法在一定程度上改進了修復的效果,但大多數方法受真實場景不同紋理結構以及復雜性不同等因素的影響,修復的效果不夠理想。
2.3 基于稀疏表示的圖像修復
基于稀疏表示的方法可更加有效地表達已知信息,Guleryuz等人在稀疏重構算法中加入了自適應技術,得到缺損區域的最佳估計。Fadili等人將稀疏表示應用在圖像插值中,提高了圖像修復的效果。Shen等人通過顯示字典提高了算法的處理效率,Xu等人提出的圖像稀疏度修復算法,采用稀疏度選擇修復的優先級,在修復圖像的結構信息上表現良好。Zhao等人通過迅速稀疏算法可快速地修復小區域缺損圖像,更快速地實現圖像的修復。
3 基于生成式對抗網絡的圖像修復算法
GAN一經提出就引起了廣泛關注,在圖像修復領域也取得了諸多優秀成果,推動了圖像修復的發展。因此,該文借鑒相關研究,對基于GAN的圖像修復方法進行深入的總結。
3.1 基于深度卷積生成對抗網絡的修復算法
基于傳統GAN的圖像修復方法存在訓練不穩定、模型不易收斂等問題,因此,產生了一系列改進原始GAN的方法。其中,Radford等人提出深度卷積生成對抗網絡DCGAN,通過將卷積神經網絡CNN和GAN進行結合,實現更有效的圖像修復。文獻[27-28]在傳統GAN的基礎上用步長卷積代替池化層,優化了生成式對抗網絡的學習表征性能,還將部分池化層采用轉置卷積代替,使整個GAN網絡可進行微分,另外引入批量歸一化以提高模型性能。基于DCGAN進行改進的方法,可以有效地減少計算量,大幅提高DCGAN的性能,其G
結構如圖3所示。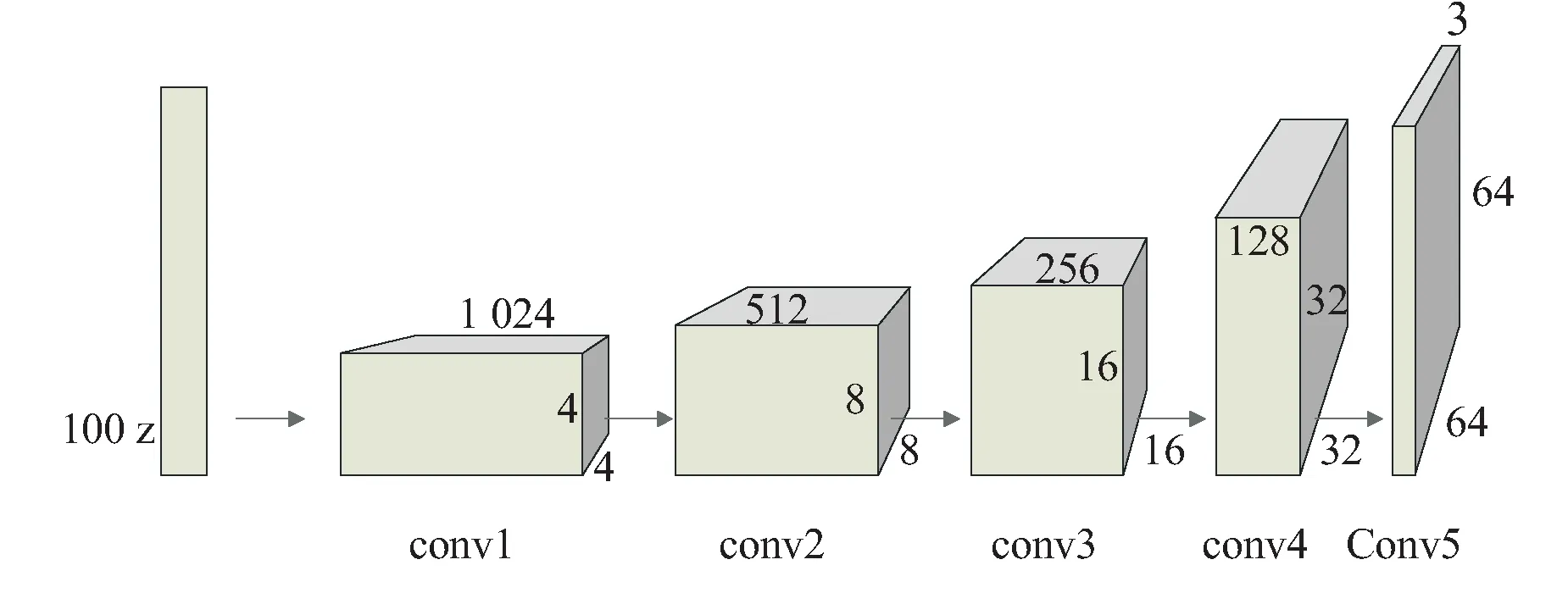
圖3 DCGAN網絡生成器結構
3.2 基于Wasserstein生成式對抗網絡的修復方法
基于DCGAN的修復方法在處理缺損區域較大時,G
學習生成的樣本數據與原始真實圖的相似度非常小,D
無法提供有效的梯度,G
無法根據梯度生成有效的樣本數據,從而產生梯度彌散,甚至梯度消失、訓練崩潰等問題。因此,Ishaan Gulrajani等人在GAN的基礎上提出將Wasserstein距離引入到GAN中的WGAN算法,原始GAN采用KL散度以及JS散度衡量生成樣本和真實圖之間的差距,WGAN將差距度量替換成Wasserstein距離,為G
提供更有效的梯度,從而使得圖像修復效果進一步提升。WGAN相較于原始GAN,去掉了輸出層的sigmoid函數,其目標函數改進為:
E
~()[D
(G
(z
))](2)
通過給判別網絡添加約束函數L
,從而防止判別器性能過于優越而限制生成器的性能優化。WGAN顯著降低了GAN訓練不穩定、梯度消失的問題,使圖像修復的質量得到顯著提升。3.3 基于CBEGAN邊界均衡生成網絡的修復算法
針對GAN模型訓練難度大,G
和D
的損失函數無法高效提升模型訓練速度的問題,A.Marzouk等人基于BEGAN提出條件邊界平衡生成對抗網絡(CBEGAN)。傳統GAN的損失函數主要度量生成樣本和真實數據的距離,盡可能提高生成樣本和真實圖的一致性。CBEGAN受Wasserstein 距離的啟發,利用D
重構生成樣本的重構誤差,不斷減小重構誤差,使模型有效收斂,提高了修復質量。基于CBEGAN的方法在處理高分辨率缺損圖像時具有顯著的優勢,其網絡架構如圖4所示。
圖4 CBEGAN網絡的生成品/判別器結構
3.4 基于條件生成對抗網絡的修復算法
條件生成對抗網絡也稱CGAN,通過在輸入數據上添加模糊圖像、語義、邊緣信息等條件,附加條件可以指導G
從輸入的隨機噪聲中學習到更深層次的特征信息。相較于原始GAN,基于CGAN的方法提高了訓練模型的收斂能力,從而一定程度避免了梯度消失等問題。CGAN的目標函數改進為: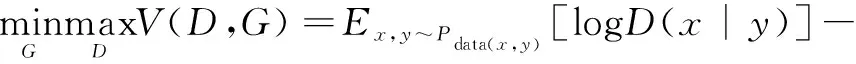
E
~()[log(1-D
(G
(z
)))](3)
式中,z
是隨機噪聲,y
是輸入的約束條件,x
是目標圖像。CGAN的結構見圖5。
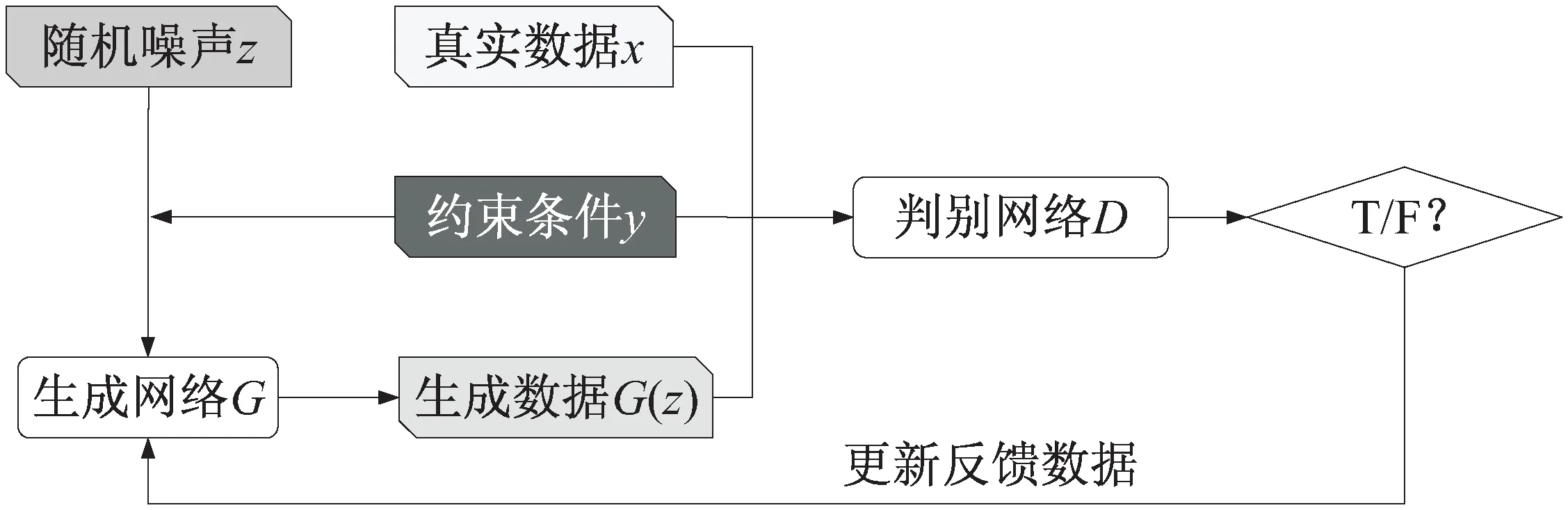
圖5 CGAN網絡結構
文章對以上幾種常見的修復方法進行對比實驗,結果見圖6,其中a至f分別為待修復的圖像、sparse方法、TV方法、GCA方法在CelebA人臉數據集上測試的結果以及真實場景原圖像。基于稀疏表示的方法[b,c,d]處理后的缺損區域與已知區域存在明顯語義不一致性,基于語義注意力機制的GCA方法[e]修復后的色調與周圍像素更協調,語義上更接近于真實圖[f],但模型泛化能力較弱,在處理真實場景時,效果遠遠不達理想目標。基于深度學習的方法處理訓練數據集中的數據時,效果比較理想,尤其是增加條件時,但對真實場景,處理性能往往較差。

a[input] b[sparse] c[TV] d[LR] e[GCA] f[GT]
4 公開測試數據集與算法評估方法
4.1 公開測試數據集
基于深度學習的修復方法需要大量的訓練數據進行學習,基于GAN的方法也是需要大量數據對G
進行訓練,生成網絡需要學習圖像的更深層次特征,并生成與真實數據盡可能一致的樣本數據。數據集的大小、數據標注的質量高低均會影響模型的性能,因此,該文對常用的圖像修復數據集進行梳理。細節見表1。
表1 圖像修復常用數據集
從表1可知,目前常用的數據集是CelebA和Place2以及它們的子集,這兩個數據集是圖像修復領域較全面的、適用最廣泛的數據集,因此,該文選取其作為基準測試數據集,對圖像修復算法進行評估對比。
4.2 算法性能評估方法
修復算法性能的評價方法主要分為兩類:主觀評價和客觀評價。主觀評價是人眼根據所觀察的修復結果進行對比的直觀感受,而客觀評價是根據修復后圖像的亮度、結構、像素等信息進行合理的數學建模,建立合理的數學公式進行客觀上的評價。目前圖像修復領域使用的最廣泛的評價指標主要有以下幾種:結構相似度(SSIM)、峰值信噪比(PSNR)、均方誤差(MSE)等,這幾種評價方式的具體信息見表2。

表2 圖像修復常用評價指標
該文還針對不同方法做了定性比較,分別在CelebA、CelebA-HQ、place2、ImageNet和Paris StreetView數據集上利用各種圖像修復方法計算PSNR值和SSIM值并進行對比,結果見表3。可知,基于GAN 的圖像修復方法在這幾個數據集上都取得了較好的結果,但仍然具有很大的改進空間,基于GAN 的圖像修復改進方法仍需要深入研究。

表3 各類修復方法指標
5 結束語
現有最先進的圖像修復方法大多基于深度學習,一部分基于CNN實現,大部分都基于GAN實現。實驗表明,基于GAN的修復方法具有明顯的優越性,修復效果更好。這類方法借助生成器和判別器之間的對抗訓練,實現圖像自動修復。基于GAN的修復方法雖然取得了明顯的性能提升,但還存在以下兩個問題:第一,對結構復雜、圖像缺損區域大的圖像進行修復時,未能達到令人滿意的修復效果。第二,基于GAN的修復需要大量數據進行學習,但缺乏真實場景的訓練數據集,在實際應用時模型性能仍不能滿足需求。深度學習技術仍將作為圖像修復領域的主流方法,尤其是基于GAN的修復方法有待進一步探討。具體地,圖像修復研究將朝兩個方面發展:第一,與其他技術結合,包括神經架構搜索和圖卷積網絡等,提出更健壯、修復效果更好的網絡模型;第二,更加注重對真實場景圖像修復的研究,實際解決行業中的技術瓶頸。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
