基于深度自編碼器網絡的壓蓋缺陷檢測
2022-03-16 03:36:50張洪波隋文濤李長安逯海濱
計算機技術與發展 2022年2期
關鍵詞:檢測
張洪波,隋文濤,袁 林,李長安,逯海濱
(山東理工大學 機械工程學院,山東 淄博 255000)
0 引 言
口服液是一種中藥制劑,在國內得到了眾多消費者的青睞,有巨大的消費市場。由于口服液產品在生產中設計多道工序,受生產工藝的影響,不可避免地會產生一些缺陷產品。如果這些缺陷產品在生產環節未能檢測出來,不僅會影響產品質量,更有甚者會嚴重危害消費者身體健康,其中,壓蓋質量尤為重要。在口服液灌封過程中,藥液灌入口服液瓶中,由壓蓋機自動貼合至瓶口,由于存在機械系統不穩定等因素,壓蓋過程會出現一定偏差,造成壓蓋不良等情況,瓶蓋可能會出現劃痕、刮花、表面卷曲、壓蓋破損等缺陷,因此需要將它們檢測出來并剔除。現如今,口服液生產廠家使用的口服液瓶蓋一般為鋁塑撕開蓋,整體分為兩個部分,上部分為塑料材質的撕開蓋,下部分為鋁制的壓蓋部分。如圖1所示,圖(a)為正常壓蓋圖像,圖(b)為劃痕缺陷,圖(c)為壓蓋卷曲缺陷,圖(d)為壓蓋破損缺陷,圖(e)為壓蓋不良缺陷,圖(f)為完全未壓蓋缺陷。

圖1 缺陷示意圖
最傳統檢測方法一般采用人工檢測,但隨著傳統機器視覺檢測方法的迅猛發展,很快被淘汰。因機器視覺檢測具有成本低、效率高等優點而被廣泛應用于口服液生產檢測環節。近些年,一些國外、國內公司生產的燈檢機大多也基于傳統機器視覺檢測。湖南大學劉學兵基于傳統機器視覺檢測方法,提出了一種基于水平截距投影的方法提取瓶蓋下邊緣點作為缺陷檢測信息,并提出了邊緣點均值和方差兩種數據特征作為缺陷判斷數據。雖然傳統機器視覺檢測雖說已經取得了不錯的檢測成果,但只能針對特定的一類產品,若企業更新包裝則需重新編寫特定程序。近幾年,深度學習在計算機視覺、自然語言處理、語音識別等領域都取得了較好的成果,在缺陷檢測領域,基于深度學習的檢測方法也在迅猛發展,Allen Zhang等人使用深度學習網絡在瀝青表面自動進行像素級路面裂縫檢測;CV Dung等人提出了基于深度學習技術的基于視覺的混凝土表面裂縫自動檢測。這些深度學習檢測方法雖然在檢測方面很有效,但其都需要人工進行數據標注。在工業生產中,一是缺陷產生具有不確定性,二是缺陷產品相比于正常產品比例極低。因此,異常檢測中的無監督檢測逐漸受到關注。
Bergmann P提出了一種基于結構相似性與自編碼器結合的無監督缺陷分割,用于織物缺陷檢測,經驗證該方法可以有效地檢測織物缺陷;合肥工業大學羅月童等提出了一種卷積去噪自編碼器檢測芯片表面弱缺陷,實驗驗證了該方法在芯片表面弱缺陷檢測中有良好效果。綜上所述,深度學習在缺陷檢測方面取得了良好的效果,但還未有基于無監督學習的檢測方法應用在口服液瓶壓蓋質量檢測中,另外口服液壓蓋缺陷具有缺陷與背景對比度低、缺陷較小等特點,又給傳統檢測方法帶來了挑戰。因此,該文設計一種無監督學習的深度卷積去噪自編碼器網絡模型用于口服液瓶壓蓋質量檢測,為口服液壓蓋質量檢測提出一種新思路、新方法。
1 方法概述
1.1 自動編碼器原理
自編碼器(Autoencoder,AE)是一種無監督學習方法。所謂無監督學習,就是不需要對目標提前標注的深度學習方式。自編碼器是通過訓練來達到重構數據自身的一種人工神經網絡,即一種典型的輸入等于輸出的無監督神經網絡模型。自編碼器通常包含三個部分:編碼器(Encoder)、隱藏層、解碼器(Decoder)。在自編碼器的訓練過程中,輸入經過編碼這一過程后,編碼器對輸入數據進行編碼壓縮,并且將輸入數據壓縮映射為一特征向量,該特征向量雖然維度較低,但其包含著輸入數據的隱藏特征信息,解碼器會根據特征向量重構出輸入數據,先編碼再解碼這一過程即可學習到輸入數據的密集表征。在自編碼器三個部分中,隱藏層是最重要的部分,因為數據的密集表征遠比輸入數據維度低,相當于用更少的特征去表達輸入數據,這使得自編碼器可以用于降維壓縮,這在圖像分類上有重要意義,其原理圖如圖2所示。

圖2 自編碼器原理圖
編碼過程就是編碼器通過函數f
將原始輸入數據x
=[x
,x
,…,x
]映射到隱含層h
,解碼過程是解碼器通過解碼函數g
將隱含層作為輸入,得到重構數據z
=[z
,z
,…,z
],其公式表達如下:h
=f
(W
x
+b
)(1)
z
=g
(W
h
+b
)(2)
式中,W
和b
分別是編碼器的權重和偏置,W
和b
是解碼器的權重和偏置。自編碼器在訓練過程中,使得重構數據與原始輸入盡量逼近,從而表明隱含層學到了原始數據另外一種潛在的表達方式。因此,給定一個數據集x
=[x
,x
,…,x
],自編碼器通過最小化以下函數來優化模型參數θ
:
(3)
其中,L
為重構函數,一般使用平方誤差損失函數或者交叉熵損失函數。1.2 模型介紹
上文介紹了簡單的自編碼器的原理,該文使用卷積去噪自編碼器進行口服液壓蓋質量檢測。卷積去噪自編碼器(convolutional denoising autoencoder,CDAE)中的去噪就是在自編碼器的基礎上,在編碼器與解碼器中使用卷積神經網絡并人為添加噪聲對輸入數據進行訓練。其中輸入數據為x
=[x
,x
,…,x
],首先對輸入數據引入噪聲:
(4)


(5)
式中,L
為重構函數,通常情況下,一般為逐像素誤差測量函數,如L
損失函數,其具體公式如下:
(6)
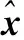
L
損失函數計算的是兩幅圖像之間的像素距離,其缺陷十分明顯,當重建圖像中,目標物體的邊緣具有定位誤差時,原始圖像與重構圖像之間的像素距離增大,計算兩者之間的殘差圖時,會出現大量殘差,但此時重構圖像中目標物體結構特征與原始圖像中目標物體相同。針對上述問題,該文提出使用基于結構相似性(structural similarity,SSIM)作為優化模型的損失函數。SSIM通過比較兩幅圖像之間的三個參數進行計算,包括:亮度(Luminance)、對比度(Contrast)和結構(Structure),三個參數計算公式如下:
(7)
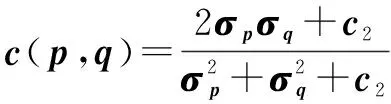
(8)
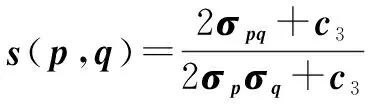
(9)
式中,p
和q
為兩個大小為M
×N
的圖像塊,μ
為p
的均值,μ
為q
的均值,σ
為p
的方差,σ
為q
的方差,σ
為p
和q
的協方差,c
與c
為兩個常數,避免公式作除零運算,一般取c
=c
/
2。每次計算的時候都從圖片上取一個M
×N
的窗口,然后不斷滑動窗口進行計算,最后取平均值作為全局的SSIM。SSIM(p
,q
)=[l
(p
,q
)·c
(p
,q
)·s
(p
,q
)](10)將α
,β
,γ
設置為1時,可得到:
(11)
SSIM通過考慮亮度、對比度和結構信息,而不是簡單地比較單個像素值,相對于L
函數,在重建過程中對小的定位誤差不太敏感,并且SSIM函數作為損失函數,檢測出的缺陷表現在目標物體結構的變化,而不是像素強度之間的差異。卷積去噪自編碼器結合了卷積神經網絡中的卷積層池化層操作來進行特征提取,能夠很好地保留圖像的空間信息,又能夠進行無監督式學習,訓練速度更快。該文使用基于卷積神經網絡(CNN)和多層感知器(MLP)組合的去噪自編碼器碼器,其結構如圖3所示。

圖3 模型結構
模型具體參數如下:
(1)輸入為128×128×1像素單通道PNG格式灰度圖像。
(2)編碼器:包含4個卷積層、4個最大池化層和4個多層感知器。池化層統一為最大池化層,可以最大限度保留瓶蓋上的缺陷。編碼器具體結構見表1。

表1 編碼器結構信息
(3)解碼器:解碼器與編碼器的相反版本。包含4個多層感知器、4個上采樣層和4個卷積層。4個卷積層中,卷積核Kernel都設為3×3。
(4)輸出為128×128×1像素單通道PNG灰度圖像。
在編碼器與解碼器中,除了解碼器最后一層Conv4-Deconder使用Sigmoid作為激活函數,其余卷積層與MLP層皆使用Relu函數作為激活函數。另外在訓練中,為防止過擬合,分別在編碼器Conv2與Conv4后,以及解碼器Conv1與Conv3后,增加Dropout層,其值設置為0.15。
模型超參數設置如表2所示,Epoch設置為250,Batch size設置為64。經多次試驗發現,當優化器設置為Adam,學習率為0.002,每次參數更新后學習率衰減值設置為0.000 01時,訓練效果最好。

表2 模型超參數信息
2 實驗結果與分析
2.1 數據集及處理
2.1.1 實驗數據集
本次實驗在采集圖像過程中,每個樣品每旋轉30°采集一張圖像。如圖4所示,總計采集5 700幅圖片,其中4 700幅合格產品圖片,1 000幅次品圖片。后期給出了圖片的樣例,所提供測試的圖片包含了常見的缺陷,如:劃痕、刮花、表面卷曲、壓蓋破損等,測試圖像為專業人員挑選,確保涵蓋壓蓋過程中常見缺陷,具有代表性。如圖4所示,前兩行為合格產品,后兩行為缺陷產品,從左往右依次為壓蓋不良、劃痕、壓蓋破損、壓蓋卷曲缺陷。

圖4 數據集圖像
2.1.2 數據增強
使用數據增強從現有的數據集中生成更多的訓練數據,包括隨機水平翻轉,在0~30范圍內隨機旋轉,隨機添加噪聲、隨機錯切角度等,將數據集擴充到10 000幅圖像,包括8 000幅合格產品圖像,2 000幅缺陷圖像。
2.1.3 圖像預處理
該文采取常用圖像預處理方式對數據集進行預處理,流程如圖5所示。原始圖像使用高速相機拍攝的產品照片,為1 600×1 200像素24位彩色圖像,首先對其進行圖像預處理。為了提高算法運算速度,將圖片轉化為灰度圖,對圖像進行高斯濾波,以消除圖像采集過程中不可避免的噪聲,然后經尺寸變換轉換為像素值128×128×1的灰度圖像。經檢驗,瓶蓋圖像在128×128×1像素時,圖像不失真且能最大程度保留缺陷信息。
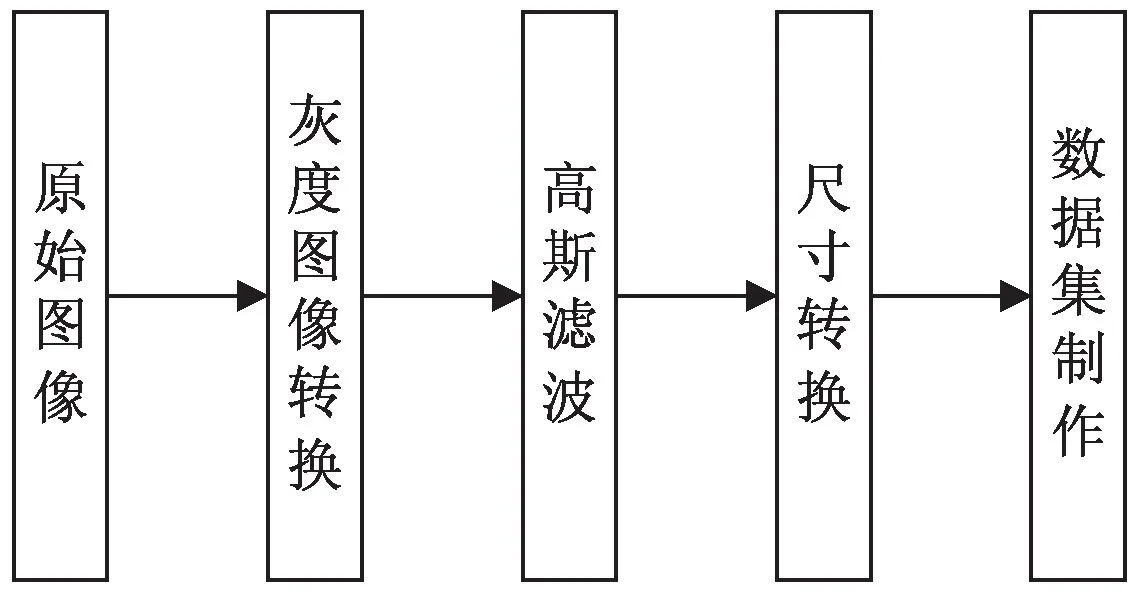
圖5 圖像預處理流程
2.1.4 網絡訓練
在網絡訓練階段用于訓練的圖像全部為合格產品圖像,在去噪自編碼器中隨機添加高斯噪聲,并將輸入的像素值部分隨機設為零。經多次實驗驗證發現高斯噪音幅度為0.15時效果較好。添加對比試驗組,使用標注后的數據集對卷積神經網絡模型進行訓練。
2.2 結果分析
2.2.1 損失函數對比試驗
如表1介紹的去噪自編碼器,該文在此分別使用SSIM函數及L
函數作為卷積去噪自編碼器的優化模型損失函數,通過在數據集上進行性能比較,結果如圖6所示。
圖6 ROC曲線
圖中展示了SSIM與L
的CDAE模型在壓蓋數據集上ROC曲線及其各自的AUC值,使用SSIM作為損失函數比使用L
作為損失函數的自編碼器性能要好。僅通過改變損失函數,在壓蓋圖像數據集上,實現的AUC從0.873提高到0.966。2.2.2 實驗對比
本次實驗采用VGG16卷積神經網絡與卷積去噪自編碼器CDAE進行對比實驗。卷積神經網絡與卷積去噪卷積自編碼器在驗證集上的準確率對比如圖7所示。

圖7 CDAE與VGG16準確率對比
在VGG16卷積神經網絡進行訓練時,在訓練集中的表現為:30次迭代之前,正確率提升明顯,在160次迭代時,準確率達到89.6%。在驗證集中的表現為:在30次迭代附近,準確率迅速提高,隨后趨于穩定。卷積去噪自編碼器在訓練集上的表現為:在30次迭代前,準確率提升較快,在120次迭代準確率達到95.2%,相較于卷積神經網絡準確率提升5.6%,且收斂速度更快。
2.2.3 重構圖像殘差圖
經卷積去噪自編碼器重構的缺陷圖片輸出后已不包含缺陷,與輸入圖片相減,即可得到壓蓋缺陷殘差圖。如圖8所示,第一列為輸入圖像,為壓蓋缺陷圖像,第二列為殘差圖與輸入圖像疊加圖像(標注區域為其對應缺陷區域),第三列為缺陷殘差圖。

圖8 重構圖像及殘差圖
3 結束語
針對口服液瓶蓋壓蓋質量檢測,該文提出了一種卷積去噪自編碼方法代替卷積神經網絡方法對壓蓋中產生的缺陷進行識別與定位,通過實驗對比分析得出以下結論:
基于SSIM的卷積去噪自編碼器網絡在口服液小瓶壓蓋質量圖像數據集上的準確率達到95.2%,相比于卷積神經網絡提升了5.6個百分點,且收斂性更好。同時,卷積去噪自編碼器模型可以應用在更多不同的領域,且魯棒性更強,可以嘗試將該方法應用在其他缺陷檢測領域。
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
