基于小波包的回放語音檢測算法*
2022-03-17 10:16:46張二華唐振民
計算機與數字工程 2022年2期
湯 爽 張二華 唐振民
(南京理工大學計算機科學與工程學院 南京 210094)
1 引言
聲紋識別作為語音識別的一個重要分支,因其自身安全性能較高、使用方便、成本低廉等優點,已經在金融交易、司法取證、門禁系統等領域得到了廣泛的使用。
隨著聲紋技術的發展,語音技術的不斷提高,各種高保真錄音及播放設備的普及化,以及各種音頻處理軟件的廣泛推廣和使用,使得說話人識別系統面臨嚴峻的挑戰。說話人識別系統主要面臨以下三個方面的挑戰;1)模仿攻擊[1],假冒者通過模仿合法說話人的聲音特征來進行攻擊;2)回放語音攻擊[2],假冒者利用高保真設備通過獲取合法說話人的回放語音進行攻擊;3)合成手段攻擊[3],通過音頻處理軟件,并利用專業手段來合成合法說話人的語音進行攻擊。對于模仿攻擊手段,需要模仿者高超的模仿手段,且攻擊效率并不高。而語音合成則需要較高的專業手段,實現難度較大。回放語音攻擊,實現起來較為方便,并且有較高的攻擊性。本文主要針對于回放語音攻擊的方法進行研究。
目前,國內外關于回放語音的檢測還處于研究階段。張利鵬等[4]提出使用MFCC作為信道信息的特征進行建模,提出了一種基于語音靜音段的回放語音檢測算法。但靜音段較易受到噪聲干擾,因此具有一定的局限性。王茂蓉等[5]通過改進的MFCC的特征進行語音靜音段進行建模,此方法有效提高了回放語音的檢測效果。此外,國外的研究如Shang 等[6]利用語音產生的隨機性提出一種檢測待測語音和合法語音在峰值圖上的相似度的算法,但此方法只能夠應用于文本相關的聲紋認證系統。Todisco 等[7]在2016 年提出一種基于常Q 變換的常Q 倒譜系數(Constant Q Cepstral Coefficients,CQCC)特征。CQCC使用常Q變換代替傳統的傅里葉變換,相比傳統傅里葉變換,常Q 變換在低頻處有更高的頻率分辨率,在高頻部分有更高的時間分辨率的,對回放語音的檢測具有較高的精度。
語音信號屬于一種非平穩信號,通過傳統的傅里葉變換來獲取和分析語音信號的有關特性并不能得到較好的效果。首先本文使用小波包分解及重構獲取語音信號各子頻帶的分量信號;然后通過傅里葉變換來估計該頻帶的主頻率;最后利用各子頻帶的主頻率分布量來分析原始語音和回放語音在頻域中的差別。結果表明,回放語音與真實語音相比在低頻帶和高頻帶都在有很明顯的衰減,同時中頻帶的主頻率分布量會增高。基于此,本文利用小波包分解及重構提取的多頻帶語音特征作為鑒別特征,實驗表明,該方法對回放語音有較好的檢測效果。
2 小波包分解與重構的頻率幅值估計
2.1 小波包分解與重構
小波包分解,將頻率進行多層次的劃分,使小波變換中沒有細分的高頻部分進行進一步分解,根據語音信號的實際情況,自動調節時頻窗口,從而提高了時頻分辨率[8]。小波包分解過程,以一個五層小波包的分解為例,可用圖1表示。

圖1 信號的五層小波包分解
由圖1 可知,信號經過小波包的五層分解得到32個節點,其中S0,0為原始的語音信號,S1,0和S1,1分別是原始語音信號經過一層小波包分解后低頻部分和高頻部分的子頻帶信號,類似的S1,0進一步分解成S2,0和S2,1,后面逐層分解。語音信號S0,0經過M層分解后可表示成:

2.2 單分量信號的主頻率幅值估計
語音信號可看作是短時平穩的多分量信號[11],因此利用小波包的分解及重構后,將信號分解成多個單分量信號。圖2 是語音波形圖及單幀頻譜曲線,圖2(a)是語音波形圖,圖2(b)表示該語音第32幀的頻譜曲線。圖3 是第32 幀語音信號經過小波包分解及重構后32 個頻帶中部分頻帶的頻譜曲線,每個頻帶的帶寬大約為250Hz,圖3(a)、圖3(b)、圖3(c)分別表示第32 幀第2、3、4 頻帶頻譜曲線,對應的頻帶范圍分別為250Hz~500Hz、500Hz~750Hz、750Hz~1000Hz。根據圖3 可以看出,在一幀中任一頻帶只有一個較明顯的波峰,故在一幀中不同頻帶的主頻率幅值可通過此頻帶波峰的峰值進行估計。

圖2 語音波形圖及單幀頻譜曲線

圖3 小波包重構后頻譜曲線圖
對于單分量信號來說,其主頻率靠近或重合于時頻峰值[12]。所以單分量信號的主頻率幅值可以通過下面方式獲取:

其中,短時傅里葉變換:

其中j,i分別為幀號和頻帶號。
將得到頻率分布量繪制成灰度圖,如圖4 所示,圖4(a)是ASVspoof 2017[13~14]數據集中“我的聲音就是我的密碼”英文原始語音的頻率分布圖,圖4(b)、圖4(c)、圖4(d)分別是同一個人同一段話不同情況下的回放語音,圖中淺色部分表示頻率分布量高,深色部分則相反。相比較于真實現場說話語音,回放語音在低頻部分(圖中白色標記處)和高頻部分(圖中灰色標記處)都有較為明顯的損失,在高頻部分損失尤為突出,在文獻[15]中也提出語音的高頻區域在語音的重放檢測中至關重要,所以在本文的檢測方法中同時利用語音的各個頻段,包括高頻部分進行特征提取。

圖4 真實語音及回放語音頻率分布圖
3 特征提取
本文利用小波包分解及重構后各頻帶的頻譜來進行進一步的特征提取,特征提取的過程如圖5所示。
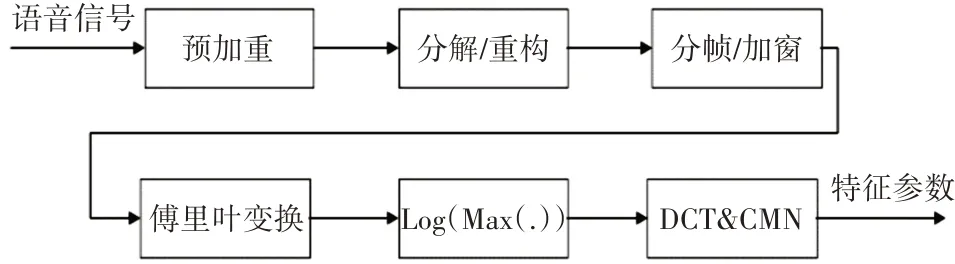
圖5 特征提取流程圖
算法流程如下:
1)輸入的語音信號通過一個預加重濾波器進行濾波,該濾波器平衡低頻和高頻信號,平坦幅度譜[16]。預加重傳遞函數:
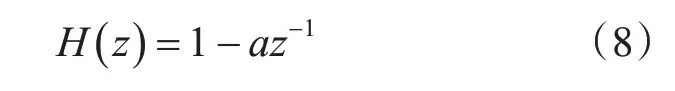
其中a 為預加重系數,取值范圍為0.9<a<1.0,一般取值為0.98。
2)利用小波包對預加重后的語音進行分解和重構,小波包分解是利用低通濾波器以及高通濾波器進行多層分解,將分解后的小波系數進行重構,得到重構后的信號Sj,i(u),j,i分別表示第j層和第i個節點,u為原始語音長度。
3)將重構后每一個頻帶的信號進行分幀加窗,然后對每一幀信號Sn( )m作短時離散傅里葉變換來計算此幀的頻譜Xn(k)。

由于所求的靜態特征沒有反映出幀間信息,因此通過求取特征的一階差分來代表幀間的動態變化信息,并且在最終測試的時候利用靜態特征加上動態特征共64維組成。
4 檢測算法
利用訓練集訓練鑒別模型時,首先提取語音特征,然后訓練GMM 模型作為鑒別模型。訓練數據分兩個子集,一個原始語音集,一個回放語音集。分別利用這兩個子集進行原始語音模型和回放語音模型的建立,其中原始語音模型記作λt,回放語音模型記作λf。利用測試集進行測試的時候,分別提取測試集中每條未知語音的特征,然后計算他們在λt和λf中的后驗概率。最終判斷該語音是真實語音還是回放語音是基于Log-Likelihood Ratio(LLR)[17]來進行判斷的。
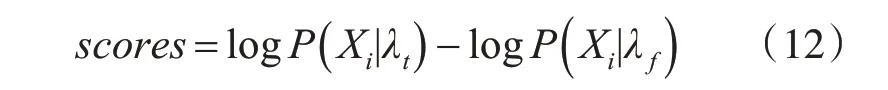
其中P(X|λt)和P(X|λf)分別是特征向量X 在真實模型下和回放模型下的得分。從式(12)中可知,最終得分是特征向量在原始語音模型下的后驗概率與在回放模型下的后驗概率的似然比,如果scores>θ則代表真實語音,反之則為回放語音。整個回放語音檢測過程可用圖6表示。
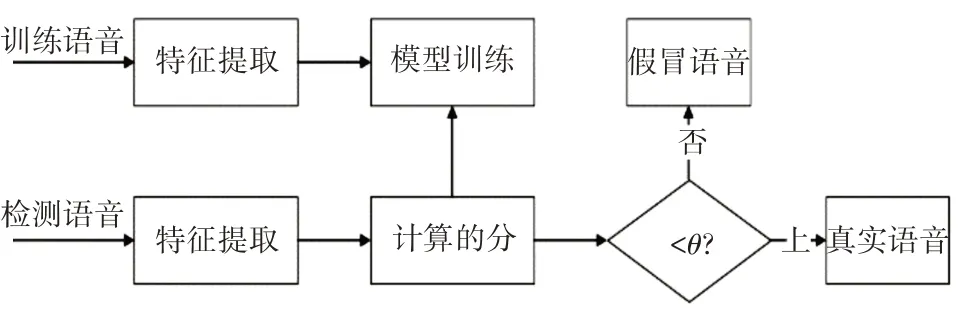
圖6 回放語音檢測流程圖
5 實驗對比
5.1 數據集介紹
為了檢驗本文算法的有效性,在回放語音檢測的數據集方面采用了ASVspoof 2017[13~14]提供的V2數據集。數據集中使用的是RedDots 語料庫中的10 個短語,通過不同的設備進行偷錄和回放,語音庫詳情見表1所示。
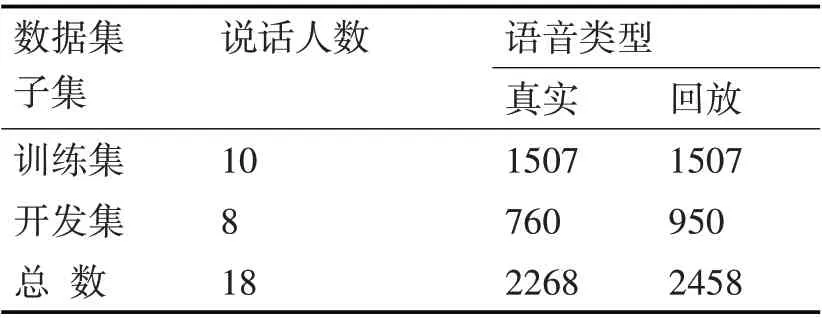
表1 ASVspoof 2017_V2語音庫詳情表
另外,此數據集是使用多種設備和環境進行語料收集。在訓練集中有2 種不同的錄音環境,1 種錄音設備,3種回放設備;在開發集種有4種不同的錄音環境,7 種錄音設備,6 種回放設備。本文算法將利用訓練集進行模型訓練,用開發集作為測試數據集。
5.2 在不同小波基下的實驗對比
傅里葉分析方法是將信號利用一系列不同頻率的正弦函數進行疊加,而小波則是利用一系列不同的小波基函數進行分析,因此應用不同的小波基函數得到的結果也是不一樣的,所以利用小波包對語音信號進行分解和重構,小波基函數的選取對提取特征的效果有直接的影響。在本文實驗中選取了幾種常見的小波基函數來進行前期的語音信號處理。表2 列出在使用不同的小波基函數后所提取的特征在開發集上的效果,且在分解時都采用的是6層分解。
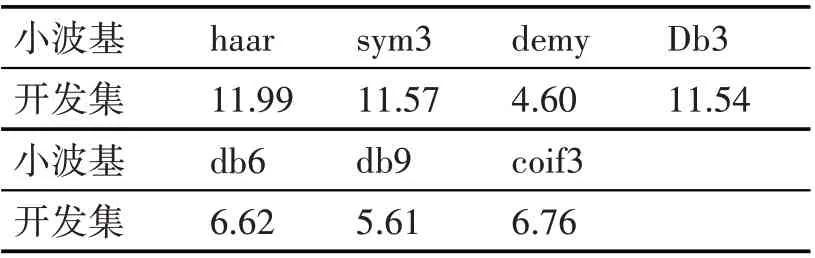
表2 不同小波基下的EER%對比
由表2 可以看出,在使用不同的小波基函數情況下,得到的特征在鑒別效果上也有所不同,其中Demy 小波基效果最好,因此在本文的特征提取中也以此作為最優小波基的選取。
5.3 在不同的分解層數下的對比
在小波包分解過程中,需要考慮到小波包分解的層數對結果的影響。層數選取過小,會導致分解后的波形有多分量信號的干擾,最后提取的特征將會造成信息遺漏,導致最后的整體效果不佳;層數選取過大,則會導致特征維度的增加,以及部分層數的信息冗余。所以需選取合適層數,這樣既能保證特征對語音信號中信息的保留,也避免了特征維度的過大情況。下面通過幾組不同的特征層數的對比來查看小波分解過程中分解層數對最終效果的影響。
由表3 可以看出,不同階數的高斯混合模型以及不同的分解層數都會影響最終結果。另外,階數越高需要對比計算的次數也就越多,分解層數越多特征的維度也就越高,所以在一定階數和分解層數下保持特征的有效性尤為重要。由表3 可知當高斯函數為256,分解層數為5 層時,效果最好,所以本文采用256 個高斯函數,5 層小波包分解作為最終的參數選擇。
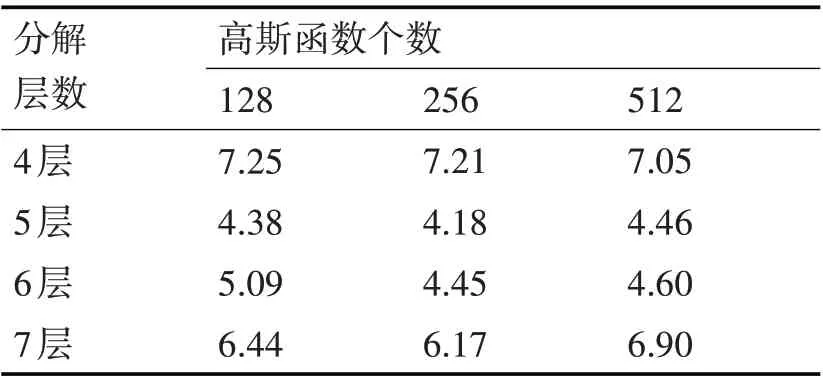
表3 不同分解層數提取特征的EER%
5.4 不同特征的對比實驗結果
由于本次使用的檢測模型與基線模型GMM模型保持一致,那么在本文的對比實驗中,GMM 模型的階數為256,利用不同的特征進行對比,觀察不同特征在相同數據集下的表現力。
在本文的不同特征的對比實驗中,采用文獻[6]提出的CQCC 算法,以及MFCC 和LFCC 算法與本文所介紹的算法進行對比。CQCC 算法是一種基于常量Q變換的倒譜特征,該特征是先將語音信號進行常量Q 變換,得到語音信號的能量譜后取對數,然后進行均勻重采樣后經過離散余弦變換得到CQCC特征。得到的實驗結果如表4所示。

表4 不同特征在不同特征集下的EER%
6 結語
本文通過小波包的分解和重構,將語音信號分為多個頻帶進行分析,通過提取每個頻帶的頻譜分布量來觀察真實說話人語音和假冒說話人語音之間的區別,說明真實說話人語音和假冒說話人語音之間在高頻和低頻部分的分布量有明顯的區別,并基于此提取的假冒語音鑒別特征。通過在ASVspoof 2017 數據庫上與常用的語音特征進行對比,發現有一定程度上的提高。然而,科技的發展以及音頻設備的不斷更新,使得回放語音檢測在聲紋識別領域仍然有很大的挑戰,因此在如何在多環境,多設備下能更有效地檢測出回放語音需要進一步的研究。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
