基于PyEcharts的數據可視化
2022-03-19 00:38:35張玉葉
電腦知識與技術 2022年2期
關鍵詞:圖表
張玉葉


摘要:圖表的應用不但可使得數據的顯示更加清晰、直觀,而且可大大增強Web頁面的功能和顯示效果。針對目前大數據時代背景下如何將數據進行合理有效的可視化展示,從而快速獲取數據中所包含的關鍵信息這一廣泛需求,文章通過對一商品銷售數據分析介紹了如何利用Python的第三方擴展庫PyEcharts來對數據進行合理有效的可視化展示,給出了具體實現方法和代碼。
關鍵詞:數據可視化;PyEcharts;Python;圖表
中圖分類號:TP311.1 ? ? ?文獻標識碼:A
文章編號:1009-3044(2022)02-0024-04
在信息時代飛速發展的今天,每天都在產生海量數據,如何從這些海量數據中快速發現和獲取有用信息,最常用的方法就是數據的可視化。數據可視化是傳達數據分析結果的重要環節,是對所獲取信息、知識、模式的圖形化展現,其核心目的是清晰、美觀、有效地傳達與溝通信息[1]。數據可視化的方案有很多,可根據實際使用場景來選擇。本文使用的是Python的第三方擴展庫PyEcharts。PyEcharts 是一個用于生成 Echarts 圖表的JS類庫,Echarts 是百度開源的一個數據可視化工具包。利用PyEcharts,通過編寫少量代碼就可方便快捷地生成Echarts風格的各種圖表,是大數據時代進行數據可視化的常用方案[2]。
本文通過餅圖、柱狀圖、玫瑰圖等不同形式圖表多角度地解讀示例數據,通過此例來展示如何將數據合理有效地可視化,從而快速獲取我們所需要的關鍵信息。
1 數據集
在此以一個商品在全國各地的銷量及損壞量的數據集作為示例數據,要分析的數據集中部分數據如表1所示(在此只顯示了整個數據集中的前10行數據)。
表1中各字段含義:date(銷售日期)、sales(商品銷量)、destroy(商品損壞量)、area(銷售地區)。
2 開發環境
本文示例所采用的開發工具及相應擴展庫的版本:Python3.6、Pandas1.0.3、PyEcharts1.7.1。所有代碼在Jupyter notebook中實現。
要在Python中使用PyEcharts,首先需要安裝PyEcharts,使用命令pip install pyecharts進行PyEcharts庫的安裝[3] 。
3 數據可視化
使用PyEcharts繪制圖表的大體過程可分為以下步驟:
1)導入相應的包;
2)準備繪制圖表所需要的數據;
3)生成圖表;
4)對圖表進行相應的設置;
5)渲染圖片。
3.1 各大區銷量分布情況
假設要想查看商品在全國各大區的銷量分布占比情況,可采用餅圖來展示。具體繪制過程如下:
1)導入相應的包
利用PyEcharts繪制餅圖,需要導入兩個包,一個是用于繪制餅圖的Pie包,另一個是用于進行系列配置和全局配置的options包。
對應代碼如下:
from pyecharts.charts import Pie ? ? ?# 用于繪制餅圖的Pie包
from pyecharts import options as opts ?# 用于進行設置的options包
2)準備繪制圖表所需要的數據
繪制餅圖需要的數據是類似[[‘華東,3000],[‘華北,2800]]這種形式的數據,要顯示商品在各大區的銷售分布情況,因此需要各大區及其所對應的商品銷售總量。數據集中給出的是每天不同地區的銷售量,因此需要先將地區轉換成所屬的大區,然后按大區對商品銷量進行分組匯總,即可得到各大區的商品總銷量。
首先定義一個將地區轉換成大區的函數,代碼如圖1所示。
然后讀取數據集,對數據集進行相應的處理,分組統計各大區的銷量,將統計結果轉換成繪制餅圖所需要的數據格式,代碼如下:
data = pd.read_csv('data/商品銷售情況表.csv') ? ? ? ?# 讀取數據集
data['zone'] = data['area'].apply(zone) ? ? ? ? ? ? ? ?# 將地區轉換成大區
grp_data = data.groupby('zone')['sales'].sum() ? ? ? ? ?# 分組匯總
pie_data = [[i,v] for i,v in zip(grp_data.index,grp_data)] ?# 數據格式轉換
3)生成圖表
首先調用Pie()方法生成一個餅圖對象,然后調用其add()方法添加數據。
PyEcharts支持鏈式調用,因此兩個方法可連續書寫,對應代碼如下:
pie_ ?= ?Pie().add('',pie_data)
4)圖表設置
圖表設置通常包括系列設置和全局設置。
系列設置中最常用的是餅圖上是否要顯示數據標簽,默認設置為不顯示,如果要想顯示,可通過如下代碼進行設置:
pie_.set_series_opts(label_opts = opts.LabelOpts(formatter = '{b}:g0gggggg%'))
全局設置中通常需要設置的是圖表的標題。設置代碼如下:
pie_.set_global_opts(title_opts = opts.TitleOpts(title = '各大區銷量分布情況'))
5)渲染圖片
生成的圖片可直接放到HTML文件中,也可直接在notebook中顯示。
如要將圖片放到HTML文件中,可使用代碼:
pie_.render('各大區商品銷量分布情況.html')
如要直接在notebook中顯示圖片,則使用如下代碼:
pie_.render_notebook()
全國各大區商品銷量分布餅圖繪制完整代碼如圖2所示:
運行上述代碼,會生成相應的HTML文件“各大區商品銷量分布情況.html”,用瀏覽器打開該HTML文件,結果如圖3所示。
當鼠標停留在餅圖的某部分上時,會突出顯示此部分,并顯示相應的銷量信息,效果如圖4所示。
通過餅圖,可清晰地看到商品在不同大區的銷量分布占比情況,同時也可方便快速地查看指定大區的銷量情況。
上面繪制的是商品在不同大區的總銷售量,用同樣方法也可繪制商品在不同大區的損壞數量等,只需要將所需數據源替換一下即可。類似這種需要分布占比情況數據的可視化,用餅圖都是一個不錯的選擇,所以餅圖通常用于展示各部分的占比情況。
3.2 商品銷量前10的地區
想要查看商品在哪些地區的銷量最好,可采用柱狀圖來展示。在此顯示銷量最高的前10個地區。
1)導入相應的包
from pyecharts.charts import Bar
from pyecharts import options as opts
2)準備繪制圖表所需要的數據
要想獲取商品銷量前10的地區,需將數據集先按地區分組統計總銷量,然后按總銷量降序排列,最后取其前10個即可,對應代碼如下:
data = pd.read_csv('data/商品銷售情況表.csv') ? ? ? ? ? ? ? ? # 讀取數據集
area_data = data.groupby(by='area',as_index=False).sum() ? ? ? ?# 按地區分組匯總
bar_data = area_data.sort_values(by='sales',ascending=False)[:10] ?# 銷量前10地區
3)繪制相應的柱狀圖及設置相應的配置
柱狀圖的繪制相對比較簡單,只需分別指定X軸和Y軸的數據,配置項通常只需設置圖表標題,在此將圖表繪制及配置項設置直接采用鏈式寫法,相應代碼如下:
bar = (
Bar()
.add_xaxis(bar_data['area'].tolist()) ? ? # x軸為地區名稱
.add_yaxis('', bar_data['sales'].tolist()) ? # y軸為商品銷量
.set_global_opts(title_opts=opts.TitleOpts(title= '商品銷量前10地區') #設置標題
)
4)渲染圖片
在此直接利用代碼:bar.render_notebook()在notebook中渲染圖片。
完整的代碼如圖5所示。
運行上述代碼,結果如圖6所示。
3.3 商品損壞量前10地區
商品在運輸或儲存過程中會有相應的損壞,數據集中存放有商品在不同地區的損壞量。如果要想查看各大區的商品損壞量,可以利用前面介紹的餅圖來展示;如果要查看商品損壞量前10地區,可以利用柱狀圖來要展示。如果是除了想查看商品損壞量最高的前10地區外,還想看看各地區商品損壞量在這10個地區中商品總損壞量中的占比情況,這時更好的可視化圖表是南丁格爾玫瑰圖。南丁格爾玫瑰圖實際上就是一種特殊的餅圖。
1)導入相應的包
from pyecharts.charts import Pie
from pyecharts import options as opts
2)準備繪制圖表所需要的數據
要想獲取商品損壞量前10的地區,需將數據集先按地區分組統計各地區商品損壞總量,然后按商品損壞總量降序排列,最后取前10個即可,對應代碼如下:
data = pd.read_csv('data/商品銷售情況表.csv') ? ? ? ? ? ? # 讀取數據集
area_data = data.groupby(by='area',as_index=False).sum() ? ?# 按地區分組匯總
destroy_data = area_data[['area','destroy']].sort_values(by='destroy',ascending=False).values[:10]
3)繪制圖表
繪制南丁格爾玫瑰圖時除了設置普通餅圖所需要的系列名稱和數據外,通常還需要設置內外半徑和圓心位置及玫瑰圖的模式。玫瑰圖有兩種模式:radius和area。radius模式是通過半徑區分數值大小,角度大小表示占比。area模式是角度都相同,通過面積而表示數值大小。可根據情況自行選擇,在此采用area模式,對應代碼如下:
pie = Pie().add(series_name = "商品損壞數量", ? # 系列名稱
data_pair = destroy_data, ? ? ? ? # 數據
radius = ["20%", "80%"], ? ? ? ? # 設置內半徑和外半徑
center = ["60%", "60%"], ? ? ? ? # 設置圓心位置
rosetype = "area" ? ? ? ? ? ? ? ?# 玫瑰圖模式
)
4)配置項設置
將圖表中的標簽文字形式設為:“地區:占比(%)”的形式,通過設置系列配置項來完成,代碼如下:
pie.set_series_opts(label_opts = opts.LabelOpts(formatter="{b} : g0gggggg%"))
然后設置圖表標題及位置、圖例及位置,通過全局配置項來完成,代碼如下:
pie.set_global_opts(title_opts = opts.TitleOpts(title="商品損壞量前10地區",
pos_right = '40%'),
legend_opts = opts.LegendOpts( orient='vertical',
pos_right="85%",
pos_top="15%")
)
5)渲染圖片
在此直接利用代碼:pie.render_notebook()在notebook中渲染圖片。
完整的代碼如圖7所示。
運行上述代碼,結果如圖8所示。
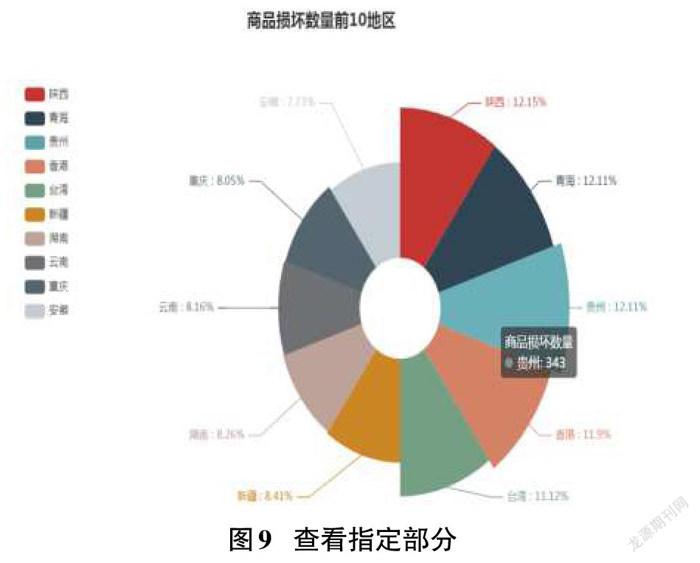
將鼠標移動到某部分上,可顯示其對應的具體數據,效果如圖9所示。
4 結束語
通常,使用自然語言、數字等形式表達的概念是枯燥的、不易懂的,而可視化的技術可增加數據的生動性[4],因而人類通過視覺獲取數據比任何其他形式的獲取方式更好[5]。圖表的應用不但可使得數據的顯示更加清晰、直觀,而且大大增強了Web頁面的功能和顯示效果。本文介紹的利用Python的第三方擴展庫PyEcharts繪制圖表的方法,其實現簡單方便,在目前大數據時代背景下有著廣泛的應用領域和良好的使用前景。讀者可參考其實現思路稍微改動一下即可實現更多類似的數據可視化效果,從而提高數據可視化處理能力。
參考文獻:
[1] 張延松,徐新哲.數據分析與數據可視化實戰[M].北京:電子工業出版社,2020.
[2] 零一.Python 3爬蟲、數據清洗與可視化實戰[M].北京:電子工業出版社,2018.
[3] 董付國.Python數據分析、挖掘與可視化[M].北京:人民郵電出版社,2019.
[4] 吳振宇,李春忠,李建鋒.Phthon數據處理與挖掘[M].北京:人民郵電出版社,2020.
[5] 柳毅.Python數據分析與實踐[M].北京:清華大學出版社,2019.
【通聯編輯:謝媛媛】
猜你喜歡
方圓(2016年22期)2016-12-06 19:27:28
足球周刊(2016年14期)2016-11-02 10:54:56
足球周刊(2016年15期)2016-11-02 10:54:16
足球周刊(2016年11期)2016-10-09 11:53:25
足球周刊(2016年10期)2016-10-08 18:30:55
世界博覽(2016年16期)2016-09-27 18:25:26
