基于NSGA-Ⅲ算法的泳池式低溫供熱堆最優(yōu)臨界棒位搜索方法
2022-03-26 04:07:26胡彬和劉興民柯國土
原子能科學技術(shù) 2022年3期
胡彬和,劉興民,孫 征,柯國土
(中國原子能科學研究院,北京 102413)
中國原子能科學研究院于2016年開始400 MW“燕龍”泳池式低溫供熱堆的研發(fā)工作,該方案將堆芯放在足夠深的水池底部,利用水層的靜壓力提高堆芯出口水溫(~100 ℃),從而使向熱網(wǎng)供水的溫度(~90 ℃)達到熱網(wǎng)需求[1]。2017年在49-2游泳池式反應堆(簡稱49-2堆)上進行了供熱演示,驗證了49-2堆用于城市低溫供熱的固有安全性[2]。但49-2堆作為研究堆其熱工參數(shù)較低,對熱工設計要求不高。“燕龍”泳池式低溫供熱堆為取得較好的經(jīng)濟性,其熱工參數(shù)相對較高,對熱點因子和焓升因子限值要求較為嚴格[3]。
“燕龍”泳池式低溫供熱堆為無硼控堆芯,堆芯的主要反應性控制手段僅能依靠可燃毒物和控制棒束。為提高堆芯組件平均卸料燃耗,盡管采用了多批換料制,但仍有較大的剩余反應性需由多組控制棒束調(diào)節(jié),因此循環(huán)初(BOC)控制棒束插入堆芯較深,引起堆芯功率畸變,對穩(wěn)態(tài)熱工極為不利,故而進行最優(yōu)臨界棒位搜索以降低熱點因子和焓升因子十分重要。本文探討使用多目標優(yōu)化遺傳算法NSGA-Ⅲ實現(xiàn)無硼控堆芯最優(yōu)臨界棒位搜索的一般方法。
1 數(shù)學模型和算法設計
以“燕龍”泳池式低溫供熱堆為例,堆芯裝載69盒CF3S燃料組件,布置57束控制棒束,其中首爐循環(huán)以C4、C7、C8為燃耗補償棒束,控制棒行程210 cm,控制棒步長1 cm。
1.1 問題的抽象模型
考慮反應堆堆芯有n個控制棒組作為燃耗補償棒,第i個棒組的控制棒位置為xi,則各棒組的控制棒位置可用向量x=(x1,x2,…,xn)表示。針對每個x=(x1,x2,…,xn)進行堆芯三維計算,可得到臨界偏離度(y1,定義為|keff(x)-1|)、核焓升因子(y2)、核熱點因子(y3)。已知有效增殖因數(shù)數(shù)值上不會超過平均裂變中子數(shù)[4](熱中子堆一般為2.45),核焓升因子和核熱點因子均大于1.0。取臨界偏離度|keff(x)-1|為目標函數(shù)之一是因為只有在臨界狀態(tài)附近計算所得的核焓升因子和核熱點因子才具有實際意義,同時該目標函數(shù)可自然地歸結(jié)到極小值問題。
需保證在臨界狀態(tài)附近,在核焓升因子和核熱點因子滿足熱工限值的條件下,使核焓升因子和核熱點因子盡量取得極小值。因此,可將其歸納為如下數(shù)學問題:
已知x=(x1,x2,…,xn),且
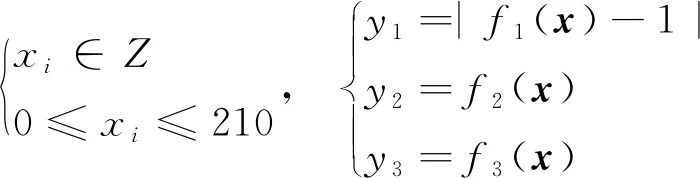
上述3個目標函數(shù)表達式未知,但由相應輸入可算得其具體函數(shù)值。目標函數(shù)值域如下:
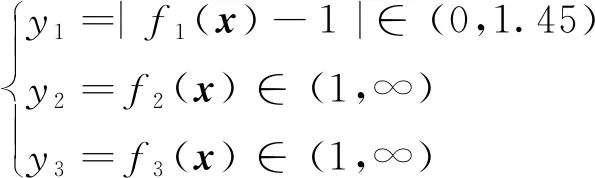
求:搜索x=(x1,x2,…,xn)使y1、y2和y3取得極小值。
這是一個無約束多目標優(yōu)化問題,一般的遺傳算法只能解決單目標優(yōu)化問題[5]。在多目標優(yōu)化問題中,各目標之間相互制約,可能使得一個目標性能的改善往往是以損失其他目標性能為代價,很可能不存在一個使所有目標性能都達到最優(yōu)的解。在眾多的多目標優(yōu)化遺傳算法中,NSGA-Ⅲ算法因其優(yōu)越性是應用最廣泛的一種算法,目前已成為多目標優(yōu)化問題中的基本算法之一[6-7]。
1.2 算法具體實現(xiàn)
NSGA-Ⅲ算法的具體實現(xiàn)過程如下。
1) 生成初始種群:隨機生成個體x=(x1,x2,…,xn)(即每個堆芯三維計算case的棒組棒位,xi取值范圍為[0,210]),種群大小為N。
2) 計算目標函數(shù)值:對種群的每個個體進行堆芯三維計算,獲得|keff-1|、Fdh、FQ3個目標函數(shù)值。
3) 目標函數(shù)值懲罰:偏離臨界狀態(tài)過遠,即使焓升因子和熱點因子均能取得極小值,也應在下一代種群中以較大的概率將其舍棄。為此提出附加懲罰函數(shù):當個體的臨界偏離度超過10-2時,該個體的核焓升因子和核熱點因子均分別額外加上當代種群所有個體的核焓升因子和核熱點因子的標準差,以使這些個體以更大的概率在下一代種群中被舍棄。
4) 交叉和變異:交叉算符選擇模擬二值交叉(SBX),模擬二值交叉綜合了二進制編碼和實數(shù)編碼的優(yōu)勢,可在實數(shù)編碼上模擬二進制編碼的搜索特點。變異算符選擇多項式變異。
5) 快速非支配排序:經(jīng)過交叉和變異產(chǎn)生子代種群后,合并父代和子代種群,采用快速非支配排序算法[8]對合并種群進行分層,選出前Fl層最優(yōu)個體。
6) 自適應歸一化:由于需將每個解和參考點相互聯(lián)系從而維持多樣性,參考點又是均勻分布在目標空間中的[9],而每個解的各目標函數(shù)值尺度不同,導致解的偏向性不同,那么在聯(lián)系解和參考點時,各目標函數(shù)的作用就會不“公平”,因此需對目標函數(shù)值進行自適應歸一化[6]。
7) 聯(lián)系個體和參考點:建立個體到參考點聯(lián)系,根據(jù)最小生境數(shù)選擇剩余個體,并與之前選擇的前Fl層個體共同組成新一代種群(種群大小為N),重復上述過程直至達到收斂代數(shù)。最后得到1個優(yōu)化搜索解集。
算法流程如圖1所示。另外,針對算法中最為耗時的堆芯三維計算,設計了并行計算程序[10]。
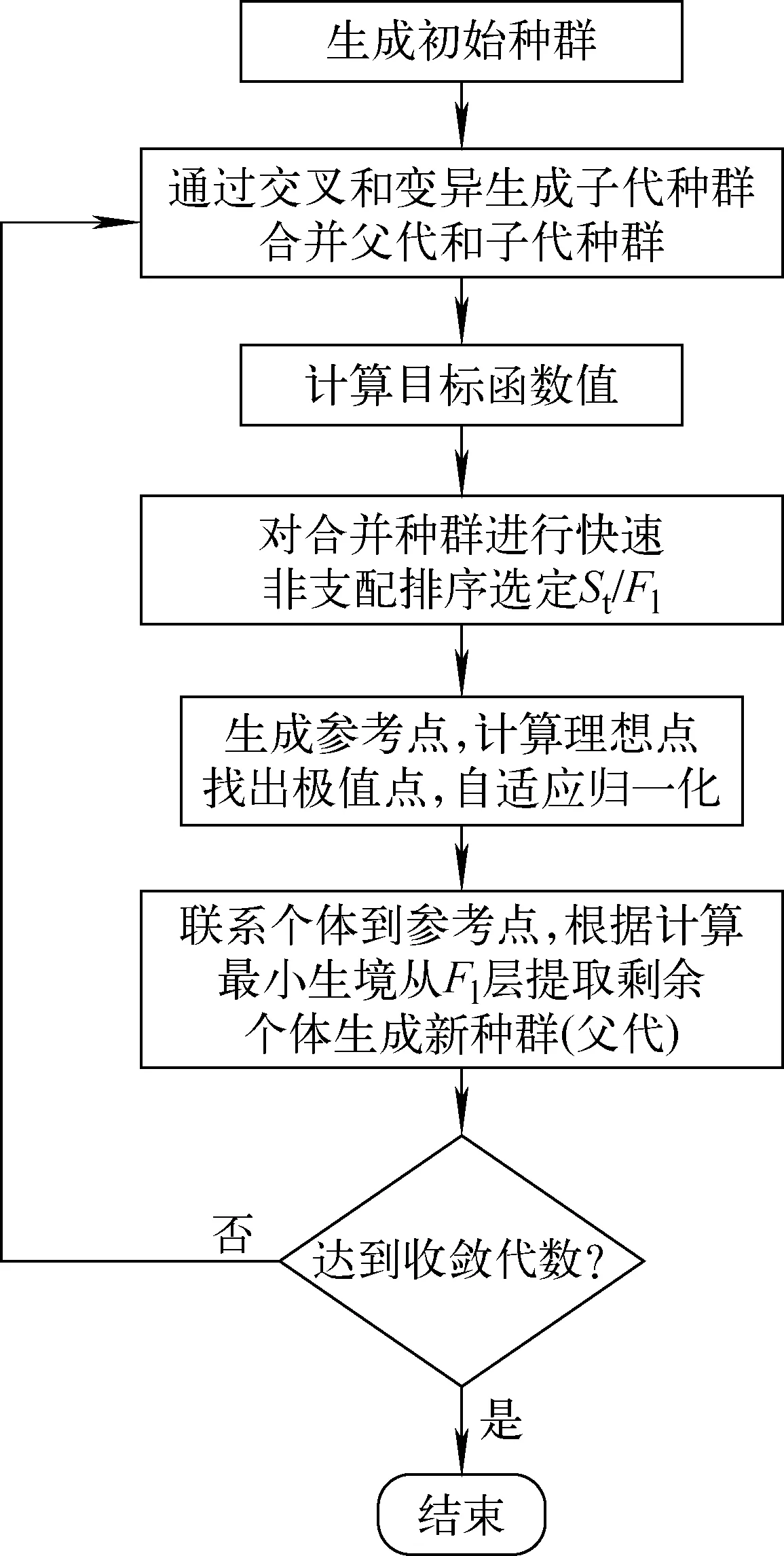
圖1 NSGA-Ⅲ算法流程圖Fig.1 Algorithm flow chart for NSGA-Ⅲ
2 算例分析和驗證
“燕龍”泳池式低溫供熱堆遼源示范工程69盒CF3S組件400 MW堆芯方案已完成了從首爐循環(huán)到平衡循環(huán)的堆芯初步核設計。相關(guān)計算表明該方案能滿足熱工和安全設計準則,且具有較大的設計余量。為驗證NSGA-Ⅲ算法在最優(yōu)臨界棒位搜索中的有效性,針對該方案的首爐堆芯進行算法驗證。
為展平功率并提高平均卸料燃耗,首爐堆芯按組件富集度分3區(qū)裝載,采用外內(nèi)式的裝載方案和3批換料制[11],裝載方案如圖2所示。全堆布置控制棒57束,其中8束緊急停堆棒束(C5、C6)組成第2停堆系統(tǒng);調(diào)節(jié)棒束和補償棒束組成第1停堆系統(tǒng),其中1束調(diào)節(jié)棒束(C0)作為調(diào)節(jié)棒組;其余48束控制棒作為燃耗和功率補償棒束,如圖3所示。其中C4、C7、C8作為首循環(huán)的燃耗補償棒。
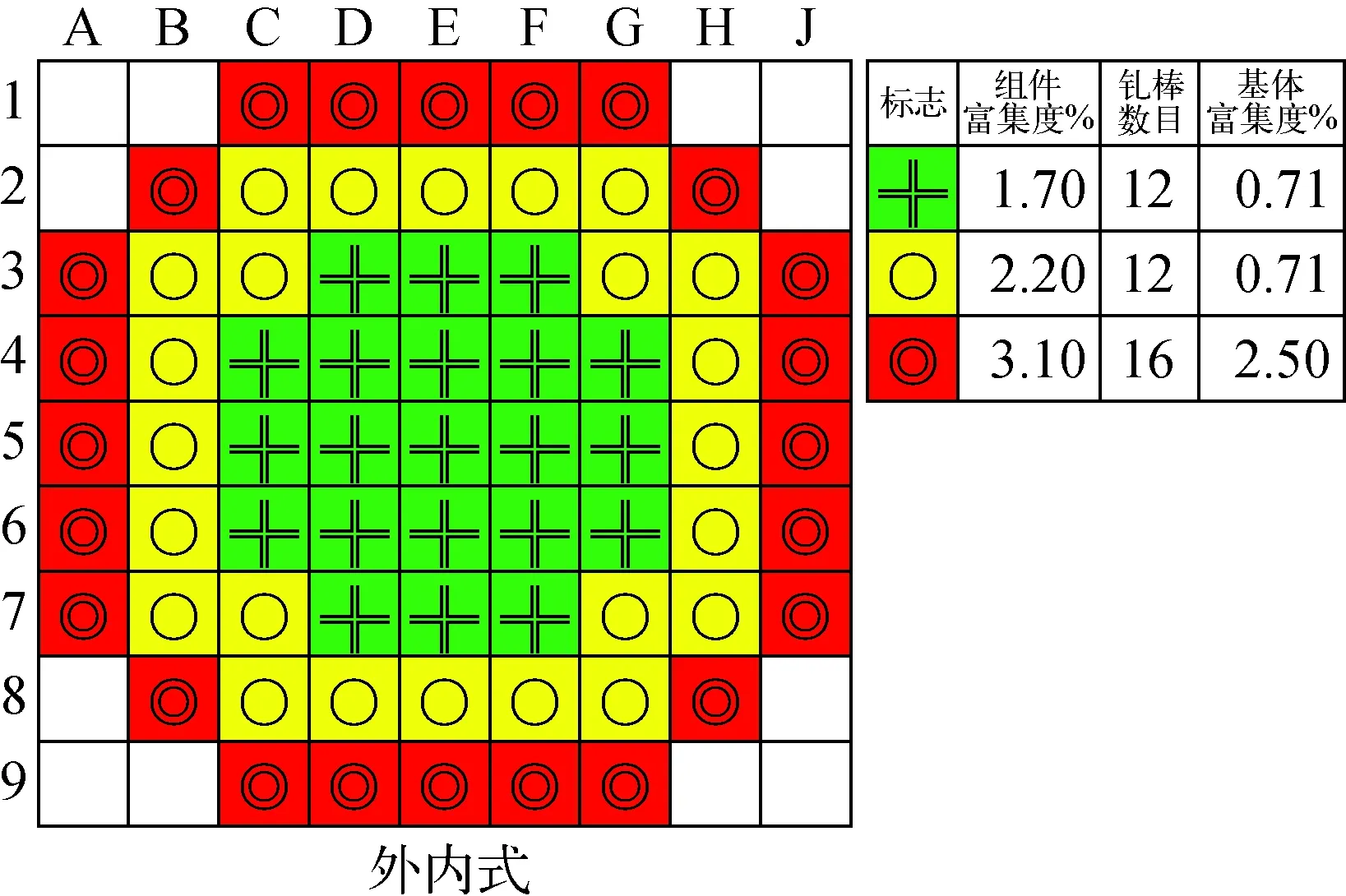
圖2 供熱堆首爐堆芯裝載Fig.2 Load pattern of the first cycle for heating reactor

圖3 遼源泳池式低溫供熱堆堆芯控制棒組布置Fig.3 Layout of control rod cluster for Liaoyuan pool-type low temperature heating reactor core
在采用最優(yōu)臨界棒位搜索算法之前,堆芯循環(huán)初的臨界棒位是依靠人工手動嘗試搜索的。經(jīng)過大量人工手動嘗試和修正,得到首爐堆芯450個等效滿功率天(EFPD)各燃耗步的臨界棒位如圖4所示。
由圖4可見,循環(huán)初手動搜索到的符合設計要求的臨界棒位為[0,100,32],依次對應的控制棒組為C4、C7、C8。相應的有關(guān)熱工參數(shù)列于表1。
由表1可見,在循環(huán)初熱態(tài)滿功率零燃耗臨界棒位狀態(tài)下,堆芯的焓升因子為1.567,熱點因子為3.477,均能滿足熱工和安全設計要求。

圖4 遼源泳池式低溫供熱堆首循環(huán)提棒順序Fig.4 Rod withdraw sequence of the first cycle for Liaoyuan pool-type low temperature heating reactor
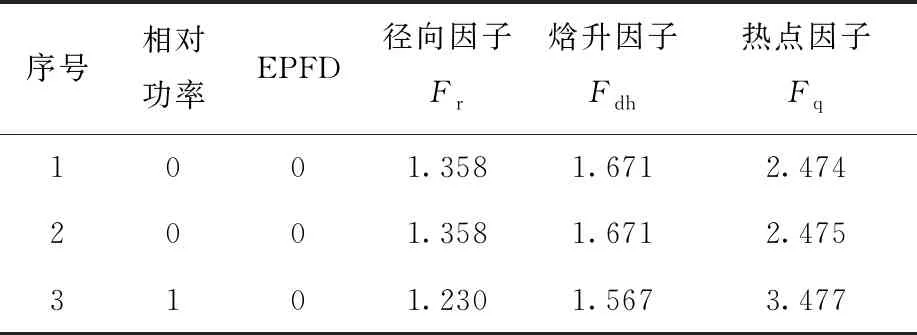
表1 69盒400 MW堆芯方案首爐循環(huán)初熱工因子Table 1 Thermal factor at BOC in first cycle for 400 MW-69 assemblies core scheme
采用NSGA-Ⅲ算法對循環(huán)初熱態(tài)滿功率零燃耗狀態(tài)下進行最優(yōu)臨界棒位搜索,設置種群數(shù)為200,遺傳代數(shù)為100代,變異概率為10%,交叉和變異參數(shù)均設為20,并采用目標函數(shù)值懲罰策略,最終得到第1代和第100代的優(yōu)化結(jié)果列于表2、3。

表2 初始種群Table 2 Initial population
由上述第1代和第100代的優(yōu)秀種群個體列表可看出,第1代隨機產(chǎn)生的控制棒組棒位沒有1個解可滿足熱工和安全設計要求,而采用NSGA-Ⅲ算法經(jīng)過100代種群迭代以后,產(chǎn)生了4個能滿足設計要求的解,并且這4個解中有兩對均趨向于同一種解,顯示了NSGA-Ⅲ算法較強的搜索能力。同時可看到,優(yōu)化解之一[0,99,34]非常接近手動搜索的解[0,100,32],自然給出的核焓升因子和核熱點因子[1.562,3.500]也與手動搜索解[1.567,3.477]非常接近。
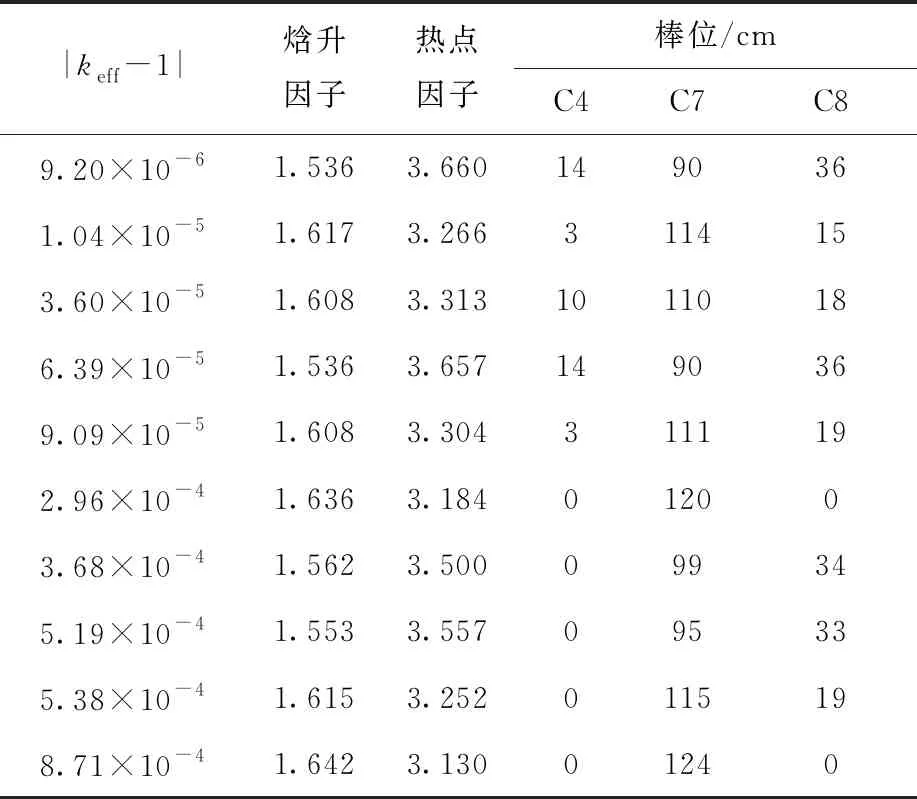
表3 經(jīng)過100代后的優(yōu)化解集Table 3 Optional solution set after 100 generations
在計算效率上,人工手動嘗試和修正所耗費時間無法準確估計,但基本以天計。而上述算例(200個體×100代)在16核32線程計算機上使用NSGA-Ⅲ算法搜索僅需3 h即能得到優(yōu)化解集(多個解),并且隨著問題規(guī)模的增大,優(yōu)化搜索算法的優(yōu)勢會更加明顯。
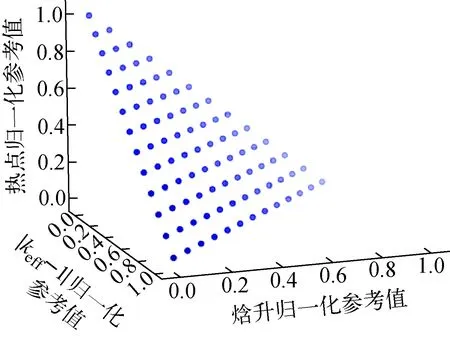
圖5 一致性參考點分布Fig.5 Distribution of reference point
圖5為歸一化目標函數(shù)參考點(又稱一致性參考點)分布,其分布非常均勻,保證了搜索空間的廣泛性和均勻性。圖6為第100代優(yōu)化解集的種群個體分布。
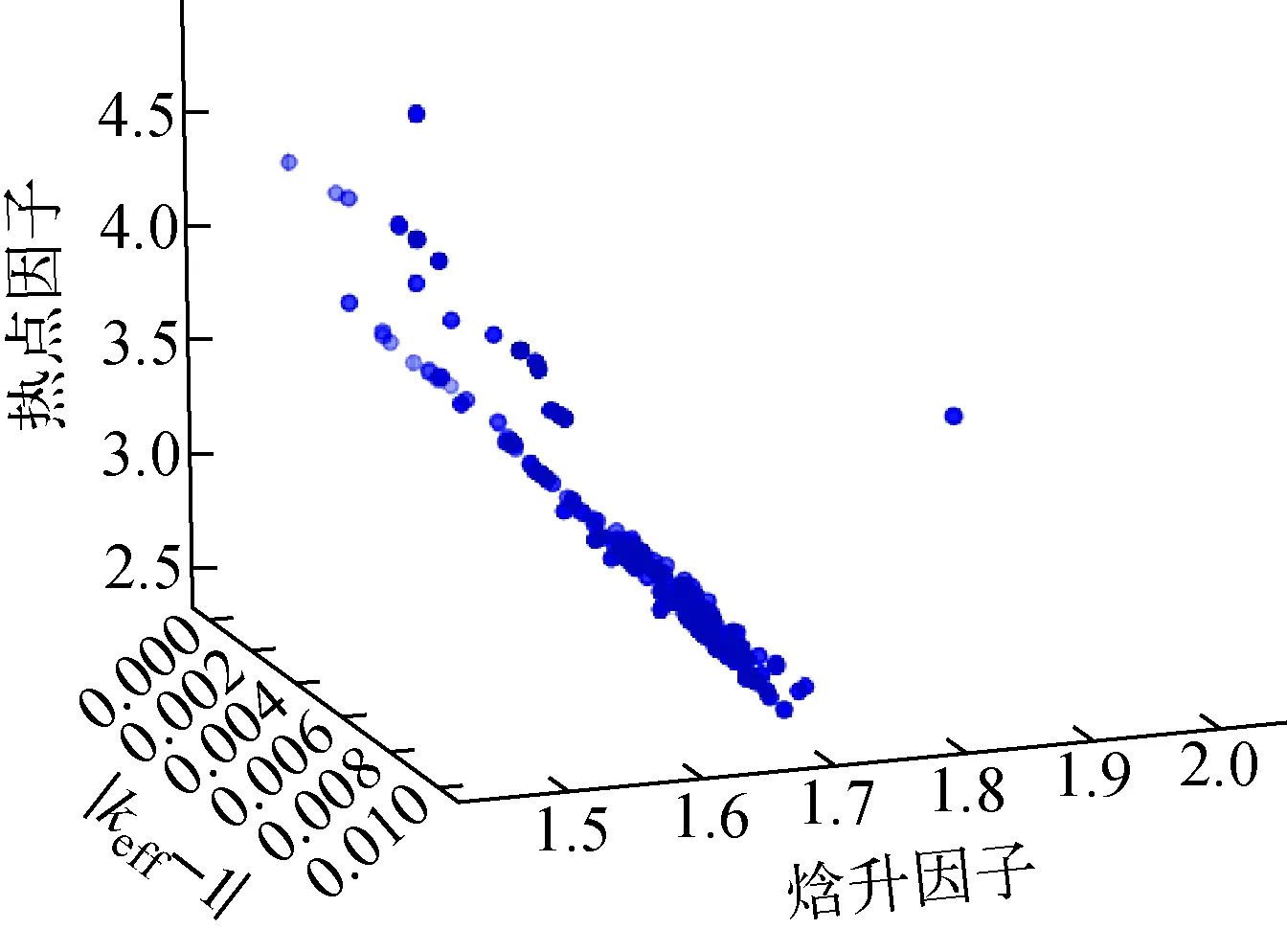
圖6 第100代后的優(yōu)化解集Fig.6 Optional solution set after 100 generations
為檢驗上述搜索結(jié)果是否具有隨機性,增加了一次優(yōu)化搜索,其第1代和第100代的搜索結(jié)果分別列于表4、5。
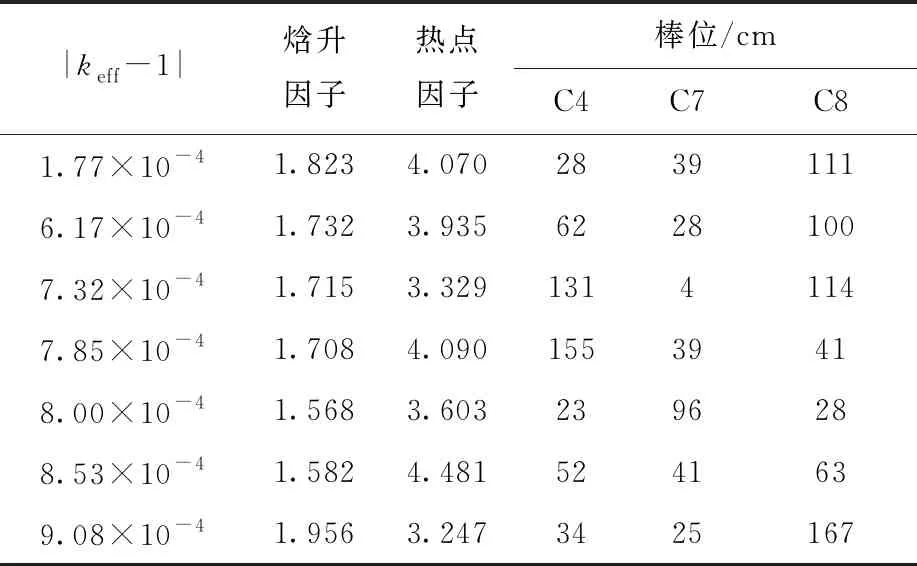
表4 第1代隨機產(chǎn)生的初始種群及其目標函數(shù)值Table 4 Initial population and its target function value randomly generated by the first generation

表5 第100代生成的種群中占優(yōu)的個體及其目標值Table 5 The 100th generation population pareto point and its target value
由表4、5可見,在第1代中隨機生成了1個較好的滿足熱工要求的解。經(jīng)過100代種群迭代后,仍搜索到與第1次搜索十分接近的結(jié)果,表明NSGA-Ⅲ算法具有較強的收斂性,證明了其優(yōu)化解的搜索能力不是隨機的。同時,也證明了該算法對于保留和改善初始較優(yōu)解的能力。
3 結(jié)論
采用NSGA-Ⅲ算法解決了“燕龍”泳池式低溫供熱堆最優(yōu)臨界棒位搜索問題,并通過“燕龍”泳池式低溫供熱堆首循環(huán)算例驗證了算法的有效性,為泳池式低溫供熱堆提供了完全基于數(shù)學過程的搜索方法,該方法可推廣到無硼控堆芯最優(yōu)臨界棒位搜索。
