基于深度強化學習的智能網聯車匝道合并策略
2022-04-02 16:32:19陳廣福
電腦知識與技術 2022年33期
陳廣福

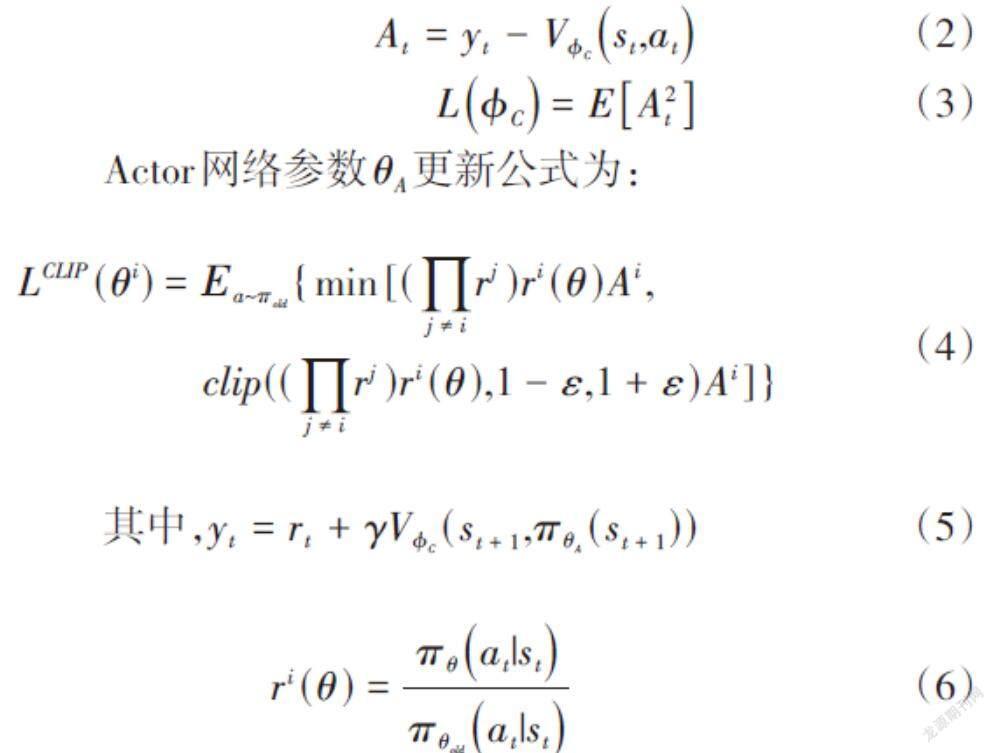
摘要:針對高速公路智能網聯汽車(CAV)匝道合并時的協同決策問題,提出了一種基于近端策略優化(PPO)改進的協作深度強化學習算法(C-PPO)。首先,基于強化學習構建CAV匝道合并場景下的馬爾科夫決策過程(MDP)模型,接著設計了一個新穎的協作機制,即在策略更新過程中的多個時期動態考慮匝道附近CAV的策略更新信息,這一過程可以協調地調整優勢值以實現匝道合并車輛之間的協作。實驗結果表明,與傳統的PPO算法相比,C-PPO算法在匝道合并問題中的效果顯著優于基于PPO和ACKTR等主流算法。
關鍵詞: 深度強化學習; 智能網聯車;匝道合并; 近端策略優化; 馬爾科夫決策過程
中圖分類號:TP391? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)33-0001-03
1 概述
據估計,全球機動車數量已經超過了10億輛,而這一數字可能會在二十年內翻一番[1]。密集的交通活動會導致各種問題,包括速度故障和交通匯聚段的擁堵等,其中匝道合并場景是高速公路上最具挑戰性的場景之一,它涉及車速的調整和變道控制[2]。近年來,一些學者研究了CAV是如何安全有效地通過匝道合并區,并提出了一些CAV的控制策略,可分為傳統基于數學模型和基于人工智能強化學習方法兩大類。前者主要包含基于規則和基于優化的方法來解決匝道的合并問題[3]。其中基于規則的方法采用啟發式和硬編碼規則來指導CAV進行駕駛決策。雖然這類方法在某些確定性場景下取得了較好的效果,甚至有些技術已經在大型科技公司實現了商業化[4]。然而,這些方法在面對交通流量較為復雜的匝道合并場景時很快變得不切實際[5]。
在智能交通領域,基于DRL的無人駕駛智能決策是一個新興領域[6],受到了諸多關注。LIN等[7]設計了一個多目標獎勵函數,利用DDPG算法來解決匝道合并問題;EL等[8]將RL算法與駕駛員意圖預測結合起來,提高CAV匝道合并的安全性能。但是,這些基于DRL的決策方法局限于單智能車的設計,很少考慮匝道合并過程中智能車之間的協同決策機制。
針對上述存在的不足,提出一種基于DRL的CAVs匝道合并模型。使用改進的PPO算法構建匝道合并場景下的強化學習模型,通過考慮匝道附近其他車輛的策略更新信息,以在CAVs之間協調適應步長來實現匝道合并過程中的協作。最后進行仿真實驗,表明所提算法可以取得更高的回報,在保證安全的情況下以更快的速度完成匝道合并,驗證了其優越性。
2 方法
2.1 強化學習問題描述
在混合交通場景中基于DRL決策的匝道合并環境建模為一個馬爾可夫模型,定義如下:
狀態空間定義為[N×F]的維度矩陣,[N]為鄰居車輛加上自身的車輛數量,在兩車道場景中,相鄰車輛包括同車道前后車輛、相鄰車道前后車輛。[F]用于表示車輛狀態的特征數,其為一個五元組:(是否能觀測到車輛,縱向位置,橫向位置,縱向速度,橫向速度)。
動作空間描述采用五元組(左轉、右轉、勻速、加速和減速)來描述。
獎勵函數從安全性、速度穩定性、時間進度以及匝道合并成本四個維度進行設置:
[ri,t=w1r1+w2r2+w3r3+w4r4]
其中[w1、w2、w3、w4]分別對應前述四個維度的權重,而其四個維度對應的獎勵分別[r1、r2、r3、r4]。當發生交通事故時[r1=-1],此外[r1=0]。[r2=min(1,(vt-vmin)/(vmax-vmin))],其中[rt]、[rmin]、[rmax]分別為當前速度、最小速度和最大速度。[r3=loge(d/(thvt))],其中d是距離進展,[th]是預定義的時間進展閾值。[r4=-exp(-(x-L)2/10L)],其中x為CAV在匝道上導航的距離,L為匝道合并區的長度,隨著CAV更接近合并端終點,懲罰增加以避免死鎖[9]。
2.1 C-PPO算法
C-PPO算法是一種將原始的PPO擴展到多智能體環境中的算法。其關鍵思想在于,在CAV策略更新過程中,引入匝道附近車輛的策略更新信息以便在多個CAV之間協調適應步長, 這一過程可以協調地調整優勢值,進而促使匝道合并附近的車輛實現協同。在基于策略的方法中,適當限制策略更新的步長被證明在單智能體設置中是有效的[10]。在存在多個策略的情況下,每個智能體在調整自己的步長時考慮到其他智能體的更新也很重要[11]。基于這一見解,提出了C-PPO算法,C-PPO算法的基本結構如圖1所示。
圖1中的環境為汽車(即環境車)和無人駕駛車輛CAV的混合交通場景,C-PPO訓練兩個獨立的神經網絡:一個是網絡參數為[θA]的Actor行動者網絡,另一個是網絡參數為[?C]的Critic評論家網絡。Critic網絡可表示為[V?],執行[S→R]的映射,Actor網絡可表示為[πθ],將智能體當前的狀態映射到離散動作空間中動作的分類分布,或在連續動作空間中對一個動作進行采樣的多元高斯分布的均值和標準差向量,從該分布中采樣一個動作。
Actor網絡生成策略,Critic網絡通過估計優勢函數[At]來評估并改進當前策略[π],二者都是根據策略梯度進行優化。其中Critic網絡參數[?C]的更新公式為:
[At=yt-V?Cst,at]? ? ? ? ? ? ? ? ? ? ?(2)
[L?C=EA2t]? ? ? ? ? ? ? ? ? ? ?(3)
Actor網絡參數[θA]更新公式為:
[LCLIP(θi)=Εa~πold{min[(j≠irj)ri(θ)Ai,clip((j≠irj)ri(θ),1-ε,1+ε)Ai]}] ? ? ? ? ? ?(4)
其中,[yt=rt+γV?C(st+1,πθA(st+1))] ? ? ? ? ? ? (5)
[ri(θ)=πθat|stπθoldat|st] ? ? ? ? ? ? ? ? ? ? ?(6) 式中的[yt]是由貝爾曼方程計算得出的目標價值,[V?C(st,at)]表示一個智能體的Critic網絡的輸出值,[γ]為衰減系數,[ε]為超參數,[ri(θ)]為概率比,[θi]是第[i]個智能體策略的參數,[Ai]則為第[i]個智能體的優勢函數。
算法中每個智能體都有兩個結構相同的[Actor]行動者網絡,其中一個[πθAold(at|st)]用于收集數據,另一個用于生成待優化的策略[πθA(at|st)],新策略通過重要性抽樣來估計。在存在多個智能體的情況下,每個智能體在調整自己的步長時考慮到周圍其他智能體的更新,協調地調整優勢值來直接協調智能體的策略,C-PPO核心優化公式為(4),該損失函數限制了[πθA(at|st)]的更新幅度,確保新舊策略之間的偏離程度不會太大。其中[clip(·)]截斷函數可以防止聯合概率比超過[[1-ε,1+ε]],從而近似地限制了聯合策略的變異散度。
3 實驗分析
3.1 實驗環境和數據集設置
本文實驗環境是在基于Gym構建的highway-env[12]環境上進行修改構建的匝道合并仿真環境,使用PyTorch構建Actor網絡和Critic網絡。主道路長度為520m,合并車道入口為320m,合并車道長度L為100m,在道路上將隨機出現1~3輛環境車以及CAV。
將C-PPO與兩種主流的RL算法進行了比較,這兩種對比算法分別由單智能體算法PPO、ACKTR擴展到多智能體環境中,將其分別表示為MAPPO以及MAACKTR。從平均獎勵值、平均速度、安全性三個方面進行評價。實驗中C-PPO算法使用的Actor和Critic網絡都是由多層神經網絡構建,Actor和Critic網絡的隱藏層均使用了Softmax函數。
3.2 實驗結果與分析
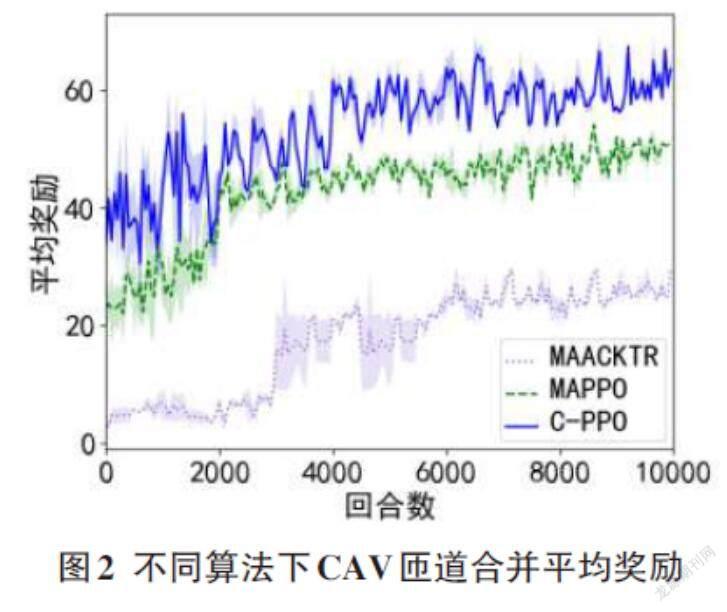
分別使用三種算法訓練環境中的CAV來進行匝道合并,場景進行10000回合的訓練,每回合步長100步,共100萬步。由圖2可以看出,在經過100萬步的訓練后, C-PPO算法能夠收斂到比MAPPO以及MAACKTR算法更高的平均獎勵值,說明這三種算法中,有協作的C-PPO算法能夠取得更好的性能,獲得更高的獎勵回報。
圖3、圖4分別表示在匝道合并過程中,CAV的平均速度以及每個回合能否安全完成匝道合并任務。圖3顯示MAACKTR算法控制下的車輛能夠具有更高的速度,但是結合圖4可知,在一個回合中,MAACKTR算法并沒有走完一個回合中的100步,即在該匝道合并過程中出現了交通事故,例如碰撞等導致提前結束該回合,這也是導致其平均獎勵較低的原因。而C-PPO算法在早期會出現提前結束回合的情況,這是因為車輛在初步階段還處于探索學習過程,與環境交互進行試錯,大概1000回合后,C-PPO算法都能完整跑完一個回合,保證其安全性,匝道合并成功率穩定且高于其余兩種算法,其平均速度也快于MAPPO算法。故C-PPO算法能夠在安全的前提下以較快的速度完成匝道合并,具有更好的性能。
4 結論
本文提出了一種適用于高速公路環境下CAVs匝道合并的協作深度強化學習算法C-PPO。首先構建了CAV匝道合并場景下的馬爾科夫決策模型,接著設計了一個新穎的協作機制,即在CAV的策略更新中考慮了匝道附近其他CAV的策略更新信息以調整優勢值來實現車輛之間的協作。與其他主流的RL算法進行了比較,C-PPO算法可以取得更高的回報,以更快的速度完成匝道合并且安全性更好。實驗結果驗證了本文所提算法的優越性。下一步考慮將具有明確協同機制的傳統控制領域方法與RL進行結合,進一步加強車輛之間的協作。
參考文獻:
[1] Jia D Y,Lu K J,Wang J P,et al.A survey on platoon-based vehicular cyber-physical systems[J].Communications Surveys & Tutorials,2016,18(1):263-284.
[2] Wang H J,Wang W S,Yuan S H,et al.On social interactions of merging behaviors at highway on-ramps in congested traffic[J]. IEEE Transactions on Intelligent Transportation Systems, 2021.
[3] Jackeline R T,Malikopoulos A A.A survey on the coordination of connected and automated vehicles at intersections and merging at highway on-ramps[J].IEEE Transactions on Intelligent Transportation Systems,2017,18(5):1066-1077.
[4] Dong C, Dolan J M, Litkouhi B. Intention estimation for ramp merging control in autonomous driving[C]//2017 IEEE intelligent vehicles symposium (IV). IEEE, 2017: 1584-1589.
[5] Cao W, Mukai M, Kawabe T, et al. Cooperative vehicle path generation during merging using model predictive control with real-time optimization[J]. Control Engineering Practice, 2015(34): 98-105.
[6] Haydari A,Yilmaz Y.Deep reinforcement learning for intelligent transportation systems:a survey[J].IEEE Transactions on Intelligent Transportation Systems,2020,(99).
[7] Lin Y,McPhee J,Azad N L.Anti-jerk on-ramp merging using deep reinforcement learning[C]//2020 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2020: 7-14.
[8] el abidine Kherroubi Z, Aknine S, Bacha R. Leveraging on Deep Reinforcement Learning for Autonomous Safe Decision-Making in Highway On-ramp Merging (Student Abstract)[C]//Proceedings of the AAAI Conference on Artificial Intelligence,2021, 35(18): 15815-15816.
[9] Bouton M,Nakhaei A,Fujimura K,et al.Cooperation-aware reinforcement learning for merging in dense traffic C]//2019 IEEE Intelligent Transportation Systems Conference (ITSC). IEEE, 2019: 3441-3447.
[10] Schulman J,Levine S,Moritz P,et al.Trust region policy optimization[C]//International conference on machine learning. PMLR, 2015: 1889-1897.
[11]Wu Z F,Yu C,Ye D H,et al.Coordinated proximal policy optimization Advances in Neural Information Processing Systems, 2021(34).
[12] Leurent E. An environment for autonomous driving decision-making[J]. GitHub, 2018.
【通聯編輯:唐一東】
