融合語義增強的中文短文本分類方法研究*
2022-04-07 03:43:00潘袁湘牛新征
計算機與數字工程 2022年3期
潘袁湘 黃 林 牛新征
(1.電子科技大學信息與軟件工程學院 成都 610000)(2.國網四川省電力公司信息通信公司 成都 610015)(3.電子科技大學計算機科學與工程學院 成都 610000)
1 引言
網絡上的微博等短文本具有內容短,語義依賴性強的特點,如何對短文本進行高效準確的分類是自然語言處理領域的學者們探索的熱點。
中文短文本分類的本質是提取已知類型標簽的短文本特征,預測未知的待分類文本的歸屬類型。目前,短文本分類的主要方法有樸素貝葉斯[1]、支持向量機[2~3]以及神經網絡[4~5]等。本文采用前沿的深度神經網絡來研究中文短文本分類。
相較于傳統的語言模型,基于神經網絡的語言模型具有有效共享上下文語義信息的特點,模型泛化能力強。例如word2vec[6]、glove[7]等模型可以學習到良好的向量表示作為特征,以便用于后續的分類任務。但word2vec 無法使一詞多義的問題得以解決。基于該現狀,Peters[8]等提出了一種高級新型語言模型(Embeddings from Language Models,ELMo),該模型生成的詞向量既可以對詞匯語法與語義進行表征,又可以隨語境進行多義詞動態變換。2018 年12 月,Google[9]提出的Bert(Bidirectional Encoder Representations from Transformers)語言模型可以捕捉更深層次的語義信息,其突破了多項自然語言處理任務,有力地推動了自然語言模型的發展。
人工神經網絡分類法因其學習能力強的優點,在實際分類任務中得以廣泛應用。針對循環神經網絡(Recurrent Neural Network,RNN)存在“梯度消失”或“梯度爆炸”[10]的問題,Hochreiter[11]等認為長短期記憶網絡(Long Short-Term Memory,LSTM),通過引入“門控”機制改善了上述問題。Cho K[12]等改進了LSTM 的結構,形成“雙門控”的門控循環單元(Gated Recurrent Unit,GRU)。Wang[13]等提出構建雙向LSTM 網絡模型提取文本序列化的上下文信息,并引入注意力機制強化重要的文本特征表達,使短文本分類性能得到進一步提升。
論文從改善傳統詞向量語義表達問題和從特征稀疏的短文本中提取重要特征的問題著手,提出融合語義增強的短文本分類方法。該方法使用預訓練語言模型Bert進行語義向量增強,同時在雙向GRU 的基礎上引入多頭注意力機制獲取短文本內部依賴關系。經驗證,本文提出的方法改善了短文本語義表達的問題,使短文本的分類精確率得到提升。
2 相關工作
2.1 語言模型Bert
Bert 語言模型是由多個Transformer 的Encoder部分進行疊加組合而成的高級新型網絡。Transformer 的Encoder 能夠一次性雙向讀取完整的文本序列信息。這個特征使得模型能夠基于單詞的粒度進行上下文語義學習。在訓練語言模型時,Bert為了克服一種固有地限制語境學習的方向性的挑戰,創新性提出Masked LM[9]和Next Sentence Prediction[9]的無監督預測任務來預訓練Bert。
2.2 雙向門控循環單元Bi-GRU
雙向門控循環單元網絡(Bidirectional Gated Recurrent Unit,Bi-GRU)[14]是GRU 的一種雙向結構,相較于GRU,Bi-GRU 結構能更好地捕捉雙向語義依賴。它當前時間步的隱狀態信息由前后兩個時間步共同決定。隱狀態輸出的公式如式(1)所示:

其中,表示前向傳播隱狀態,表示后向傳播隱狀態。
2.3 多頭注意力機制
不同于普通注意力機制,Google 團隊提出了多頭注意力機制[15](MultiHead Attention)。
多頭注意力機制通過“復制”和“拆分”自注意力機制的權重矩陣,形成新的加權計算模式,以便學習到多個不同子空間的語義信息。公式如下所示:
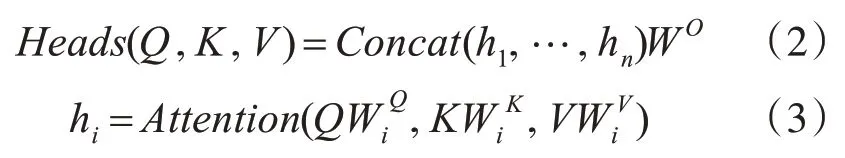
3 融合語義增強的中文短文本分類方法
為解決中文短文本特征稀疏和上下文依賴性強的問題,以有效提高短文本分類準確率,論文提出了融合語義增強的中文短文本分類模型。模型結構由語義向量表示層、特征抽取層和輸出層組成。首先將預處理后的短文本通過Bert 預訓練語言模型生成的語義向量。然后輸入到Bi-GRU 神經網絡中并結合多頭注意力機制提取文本全局特征。最后進行多分類輸出。
3.1 語義向量表示層
語義向量表示層是文本輸入的第一層,采用預訓練語言模型Bert進行短文本語義向量表示。
以“股票的突破形態股票”為例。輸入表示流程圖如圖1 所示。首先按照“[CLS]股票的突破
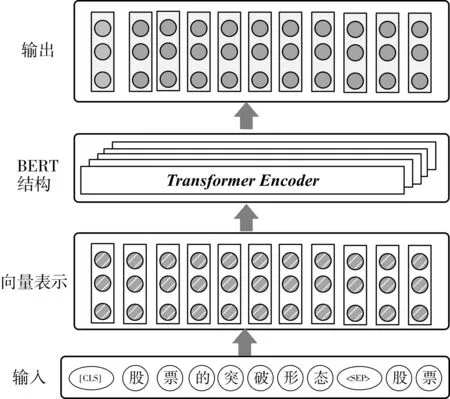
圖1 輸入表示層流程圖
3.2 融合語義增強的特征抽取層
特征抽取層將Bert 預訓練語言模型生成的語義向量輸送到Bi-GRU 網絡中,同時結合多頭注意力機制提取文本全局特征。特征抽取層的結構示意圖如圖2所示。

圖2 特征提取結構示意圖
Bi-GRU網絡結構的“雙門”可以控制時序信息的記憶程度,不但使其保留全局時序的最優特征,而且又可以充分提取當前時間步的前后時間步的隱狀態信息。因此本文構建了Bi-GRU 網絡以充分提取短文本上下文語義信息。
輸入單元為Bert 預訓練語言模型生成的語義向量集合,即X={x1,x2,…xi,…,xt},其中,xi(i=1,2,…,t)表示字向量。隱藏層包含前后兩個方向的傳播層。本文使用h→t表示前向傳播隱狀態,h←t表示后向傳播隱狀態。
論文采用數量大小為h 的隱藏單元構建網絡。在進行網絡前向推斷過程中,已知小批量輸入為xt,上一個時間步隱狀態為ht-1。Bi-GRU 網絡的內部子結構GRU 在時間步t時,通過式(4)和式(5)計算重置門和更新門的狀態。
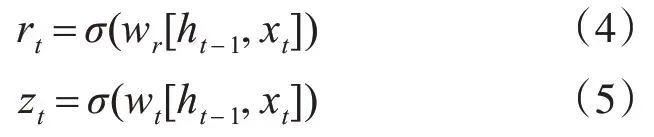
其中,wr和wt為權重參數,σ為激活函數,其取值范圍在0~1之間。
候選隱狀態的作用是輔助控制當前時間步t的隱狀態的計算,計算公式如式(6)所示:
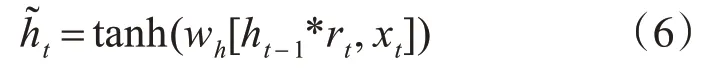
其中,wh為權重參數,tanh 為激活函數,其取值范圍在-1~1之間。
至此,通過式(7)可計算出前向單元的隱狀態輸出。
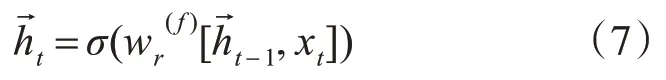
通過式(8)可計算出后向單元的隱狀態輸出。
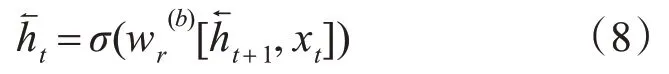
綜上,當前時間步t 的前后隱狀態輸出拼接組成了綜合隱狀態輸出,其公式如式(9)所示:

由Bi-GRU 網絡中進一步得到融合語義的向量集合O={o1,o2,…,oi,…,ot},其中,oi(i=1,2,…,t)表示語義特征向量。此時,論文采用多頭注意力機制在獲取強化語義的同時并進行權重調整。
多頭注意力機制是由N 個自注意力機制堆疊而成,如圖3 所示。通過“復制”和“拆分”自注意力機制的權重矩陣,構成了多頭注意力機制的計算模式,如式(10)所示,這使得學習到多個不同子空間的語義信息。
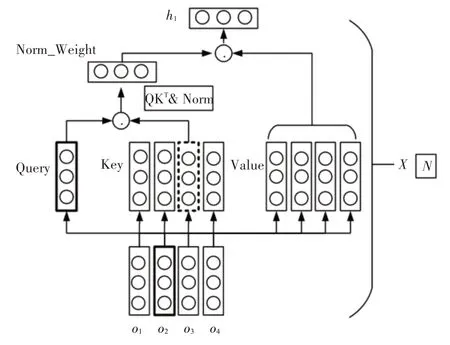
圖3 MultiHead-Attention更新權重計算
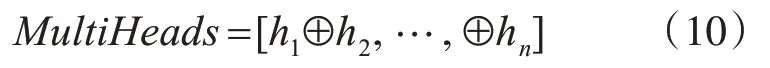
自注意力機制堆疊復制了8 次,形成了8 頭自注意力機制。通過平分這8 個Attention 形成了詞向量,然后通過矩陣交互計算,從而得到了多頭注意力的權值。
3.3 輸出層
輸出層對每個樣本所屬的標簽進行概率統計預測。在分類問題中,輸出層常用Softmax 層映射為條件概率。將輸入的樣本劃分為類別j的概率公式如式(11)所示:
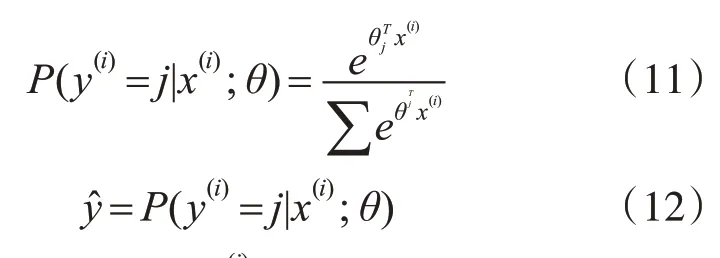
x(i)表示訓練樣本,y(i)∈{1,2,…,k}表示標簽,y?則表示其預測值。
4 實驗
4.1 數據集
實驗數據來自今日頭條公開新聞數據集。數據集由38 萬余篇中文新聞文本標題組成,其中包含房產、軍事、股票等總共15 個主題類別。本文選取其中的子集進行實驗,每個類別選取5000 條數據,按照8∶1∶1 的比例進行訓練集、測試集和驗證集的劃分。
4.2 實驗結果與分析
實驗采用精確率(Precision,P)、召回率(Recall,R)和F1 值(F1-Measure,F)作為標準的評價指標[16]。實驗環境為Linux Ubuntu16.04系統,顯卡型號GTX1070,實驗中涉及到的算法均采用Python3.6 編寫以及Tensorflow1.12 深度學習框架實現。
本實驗將目前在短文本分類任務中優秀的算法[9,14]作為基準算法,與本論文算法在相同數據集上進行兩組對比實驗。
1)第一組實驗
為驗證Bert 預訓練語言模型生成的語義向量比Word2Vec 的表征能力強,以使得分類準確率更高。將Word2Vec-GRU 及其改進模型與Bert-BiGRU模型進行第一組分類實驗。
本組實驗相關參數設置如下。
模型訓練的超參數包括:學習率lr 為0.001,隱層單元數hidden_units 為128,批處理量batch_size為32,網絡節點丟棄率dropout 為0.25。具體實驗結果記錄表如表1所示。
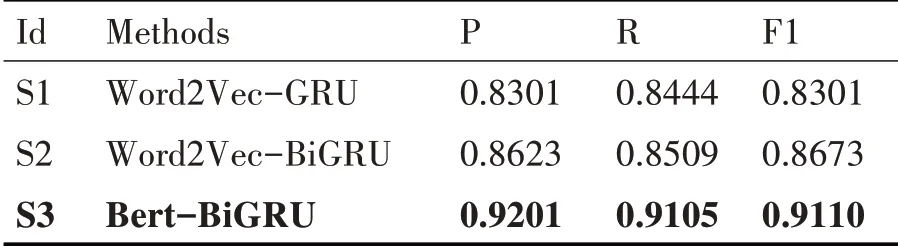
表1 實驗結果記錄表
2)第二組實驗
為驗證本論文提出的模型比主流的引入傳統向量表示或者引入注意力機制的神經網絡分類模型的準確率高,本論文進行第二組分類實驗。
本組實驗的模型超參數設置為學習率lr 為0.0005,隱層單元數hidden_units 為128,批處理量batch_size為32,網絡節點丟棄率dropout為0.1。具體實驗結果記錄表如表2所示。
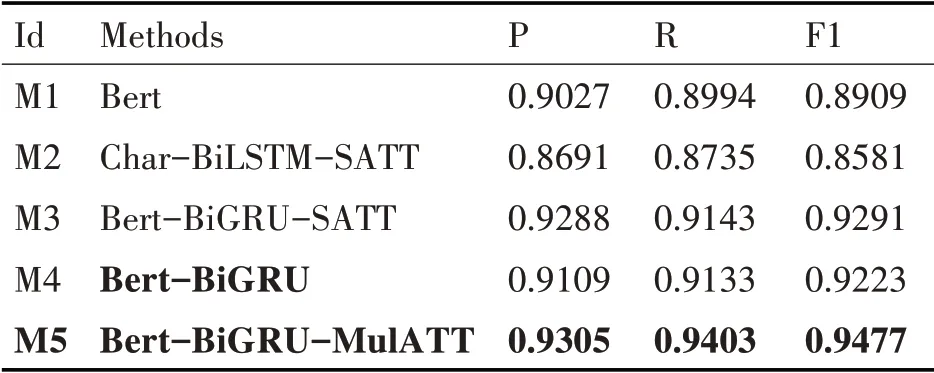
表2 實驗結果記錄表
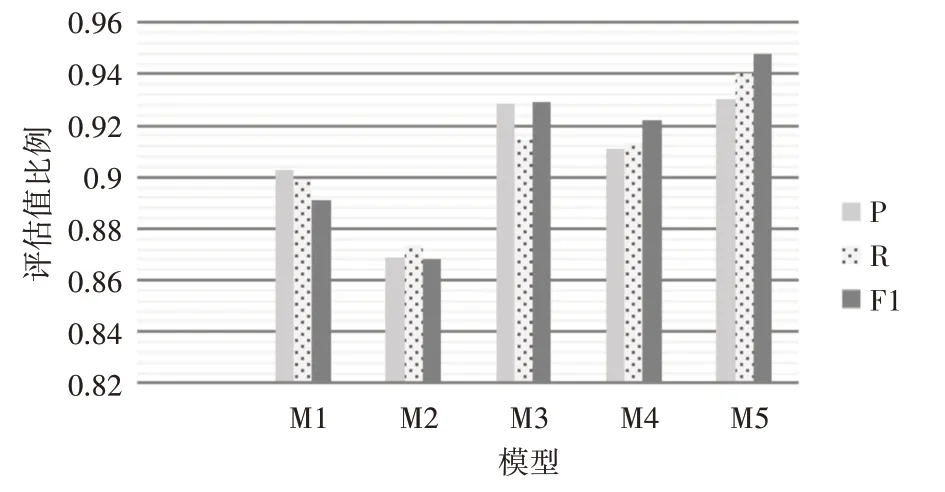
圖4 實驗二分類效果對比圖
本論文進行了兩組對比實驗,具體分析如下。
由實驗一的結果記錄表可知,通過對比引入Word2Vec 的S1、S2 兩個方法和引入Bert 的S3 方法的實驗結果,發現S3方法相較S2方法的精確率、召回率和F1 值分別提升了5.78%、5.96%、4.37%。說明了加入Bert 生成的向量表示法能表達豐富的上下文語義信息,有利于后續分類準確率的提高。
由實驗二的結果記錄表可知,通過對比M1、M2 和M3 方法,發現Bert無論在語義向量表征能力上還是分類準確率上均表現優越。通過對比M3和M5 方法的結果,發現引入多頭注意力機制比自注意力機制的分類效果更顯著。
通過對比實驗一分類準確率最高的S3(M4)與本論文提出M5方法的實驗結果發現,模型精確率、召回率和F1 值分別提升了1.96%、2.7%、2.54%,證明本論文提出的方法在Bert-BiGRU 的基礎上,利用多頭注意力機制能充分捕捉到局部關鍵特征,進一步增強短文本上下文語境。綜上兩組實驗可以證明本論文提出的融合語義增強的短文本分類方法的優越性。
5 結語
針對中文短文本具有內容特征稀疏,上下文依賴程度強的問題,結合目前主流的基于詞向量的雙向循環神經網絡的優點,提出融合語義增強的中文短文本分類方法進一步改善分類效果。該方法引入Bert生成融合字、文本以及位置向量的語義向量作為訓練文本的詞表征。采用Bi-GRU 網絡提取上下文關系特征,并通過多頭注意力機制調整權值強化重要特征表達。實驗結果表明該方法應用于短文本分類問題的準確性和優越性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年21期)2018-11-09 01:23:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
中國衛生(2015年9期)2015-11-10 03:11:12
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中國衛生(2014年3期)2014-11-12 13:18:12
