基于BERT-CRF 模型的電子病歷實體識別研究*
2022-04-07 03:43:08聞英友
計算機與數字工程 2022年3期
何 濤 陳 劍 聞英友
(1.東北大學東軟研究院 沈陽 110169)(2.遼寧省工業控制安全工程技術研究中心 沈陽 110169)
1 引言
隨著醫療領域信息化的發展,電子病歷記錄了患者就診、檢驗、診斷、治療、預后、隨訪等完整的就醫過程,包含了豐富的醫學知識,如何從海量的電子病歷文本中挖掘出有價值的關鍵信息,成為智慧醫療領域的重要課題。醫療命名實體識別(Named Entity Recognition,NER)技術可以從電子病歷中提取重要的實體信息[1],對后續構建醫療實體關系[2]、分析電子病歷句法[3]、構建疾病知識圖譜[4]等發揮重要作用。但基于中文文本不像英文等語言在詞與詞之間存在分隔符,并且實體描述沒有統一的規范,使中文醫療命名實體識別具有很大的挑戰性。
語義規則和詞典是NER 領域較早使用的技術,采用語言學專家手工構造規則模板,但這些規則往往依賴于具體語言、領域和文本風格,通用性不強。在語料大數據發展的基礎上,命名實體識別問題更多地采用機器學習算法,較為常用的算法如支持向量機[5]、基于統計模型的隱馬爾科夫模型[6]、求解約束最優化的最大熵模型[7]、無向圖模型條件隨機場(Conditional Random Field,CRF)[8]等。隨著神經網絡及深度學習的發展,循環神經網絡和卷積神經網絡等方法,逐漸成為實體識別領域的主流方法。
Hammerto[9]提出將長短時記憶網絡模型用于命名實體識別,取得不錯的效果。Yang 等[10]提出了一種對抗網絡模型的方法,為構建中文實體識別系統提供了一條新思路。Huang 等[11]提出在雙向長短時記憶網絡模型上,通過條件隨機場進一步對命名實體進行約束。在序列標注問題上,Ma 等[12]提出將循環神經網絡、深層卷積神經網絡和條件隨機場結合使用。Strubell 等[13]提出迭代膨脹卷積神經網絡(Iterated Dilated Convolutional Neural Networks,IDCNN),利用空洞卷積處理文本序列問題。Vaswani 等[14]提出Transformer 模型,該模型使用多頭自注意力機制,提取文本特征能力得到極大增 強。2018 年,Zhang 等[15]提 出 了 一 種Lattice LSTM(Long Short-Term Memory)模型,在字符作為輸入的基礎上,加上了分詞信息,將詞語信息輸入到基于字向量的模型中去。預訓練的語言表征模型BERT(Bidirectional Encoder Representation from Transformers)[16]發布后,在NLP領域橫掃了11項任務的最優結果,完成該領域的重要突破。
中文電子病歷與普通文本有很大的區別:通常包含大量的醫學術語,構詞十分復雜,實體常常存在嵌套現象并且實體邊界模糊;醫學實體描述具有多樣性,沒有固定規則;隨著醫學技術的發展,新的實體不斷涌現;公開的醫療領域命名實體標注數據集較少,人工標注價格昂貴,運用深度學習技術缺乏足夠的訓練數據。這些特點進一步加大了醫療實體識別的難度,使醫療領域的實體識別性能難以達到可用的程度。
針對以上問題,本文引入預訓練的語言表征BERT 模型,該模型并非采用傳統的單向語言模型或者把兩個單向語言模型進行淺層拼接的方法進行預訓練,而是采用新的masked language model(MLM)對雙向的Transformers 進行預訓練,生成深度的雙向語言表征,最終生成能融合上下文信息的深層雙向語言表征。
因此,本文提出一種BERT+CRF的電子病歷實體識別模型,首先使用標注數據對BERT 進行微調,將得到的序列狀態分數經條件隨機場層對序列狀態轉移做出約束優化,通過實驗結果可知,該模型對比BiLSTM(Bi-directional LSTM)+CRF模型,F1分數可提高6.5%左右。
2 創建語料庫
為完成模型的訓練,首先要構建標注語料庫,所用病歷語料均來自三甲公立醫院的真實病歷,為保護患者隱私,數據經過嚴格脫敏,不涉及任何個人敏感信息,搜集到的電子病歷總數量達到1 萬份。電子病歷文本實體提取問題,根據醫生在醫療過程中感興趣的信息創建實體類別,每個實體類別對應一個標簽。需要定義實體標簽集,標簽集包括的實體類型有就診科室、性別、年齡、主訴、身體部位、癥狀、體格檢查、專科檢查、心電圖、診斷依據、診斷名稱、治療計劃、不良嗜好、現病史、既往史、家族史等共16類實體。
把數據集隨機分為訓練集、驗證集和測試集,用訓練集訓練模型,用驗證集驗證模型、調整超參數,用測試集評估最終的模型,三個數據集的數據分布如表1所示。
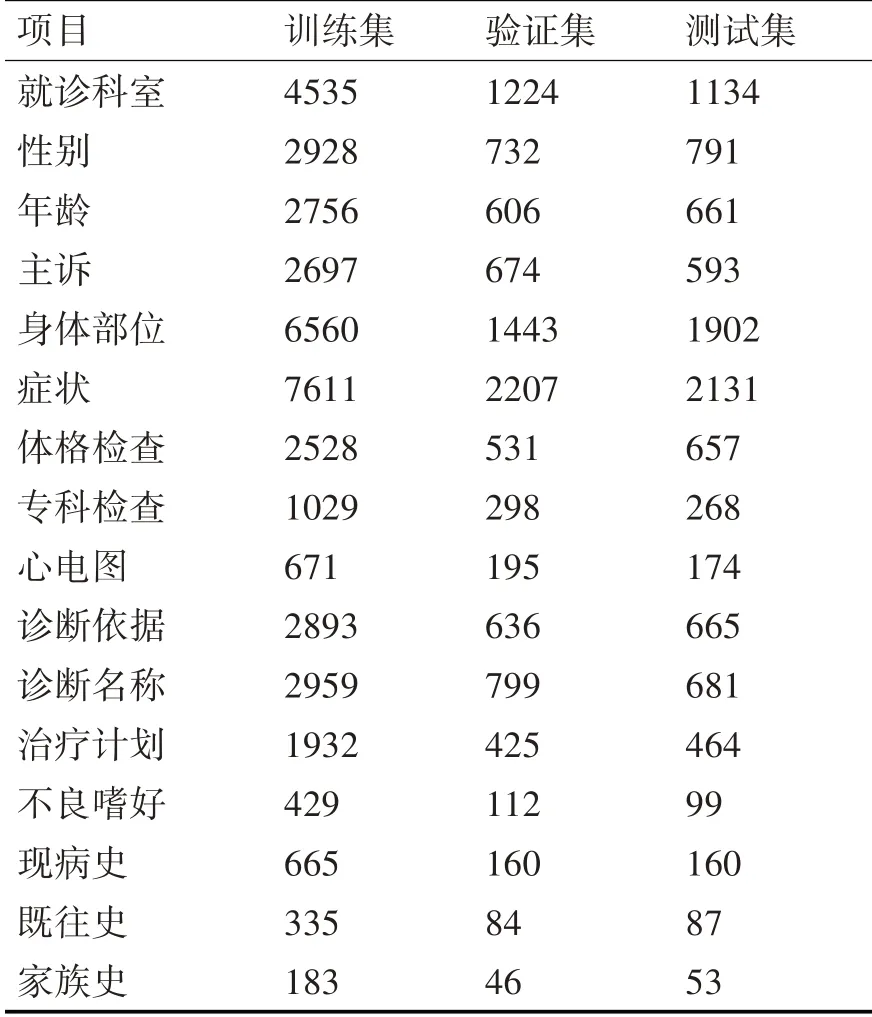
表1 命名實體樣本分布
本實驗選用3000 份電子病歷,在自行開發的文本標注系統上由相關專業醫生完成標注工作,標注內容詳實準確。
標注方法采用目前最通用的BIOES[17]標注體系,B 表示該字符處于一個實體的開始(begin),I表示該字符處于一個實體的內部(inside),O 表示該字符處于一個實體的外部(outside),E 表示該字符處于一個實體的結束(end),S表示該字符本身為一個實體(single)。
3 構建電子病歷實體識別模型
BERT-CRF模型的整體結構如圖1所示,兩層結構分別是:1)使用預訓練BERT 模型對標注數據進行訓練和編碼,獲取準確的字符語義表示;2)CRF對上層的輸出結果進行狀態轉移約束。
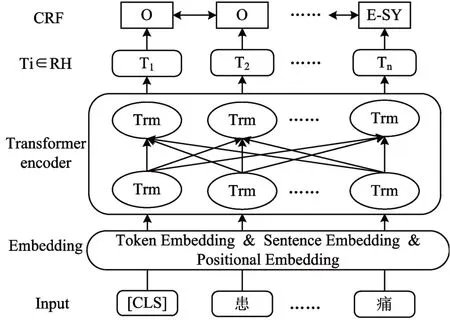
圖1 BERT-CRF模型整體架構
3.1 BERT預訓練模型
與ELMO[18]、GPT 等模型相比,BERT 的模型的實現基于多層雙向Transformer 編碼器。Transformer使用了雙向自注意力機制,該機制打破了單向融合上下文信息的限制,采用新的masked language model(MLM)進行預訓練并采用深層的雙向Transformer 組件構建模型,從而生成融合上下文信息的深層雙向語言表征。
模型的輸入表示能夠在一個標記序列中清楚地表示連續文本,序列是指輸入到BERT 的標記序列,BERT模型的輸入表征如圖2所示。
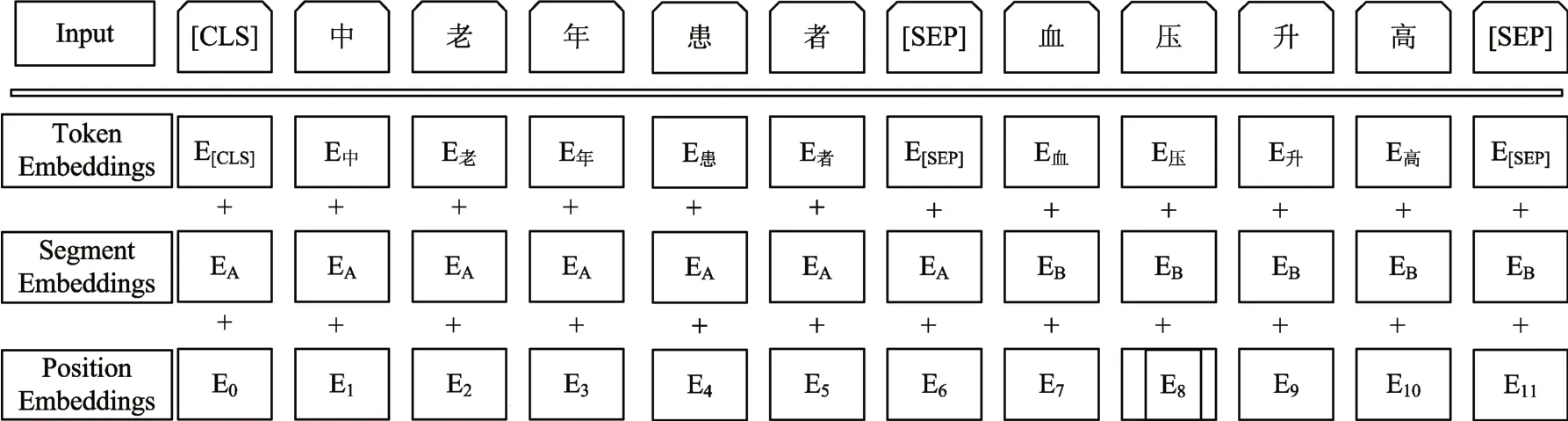
圖2 BERT模型的輸入表征
BERT 的輸入數據分別是字符向量token embeddings、段向量segmentation embeddings 和位置向量position embeddings 的加和。字符向量是模型中關于字符最主要的信息;段向量用于提供文本的全局語義信息,句子末尾使用[SEP]作為結尾符,句子開頭使用[CLS]標識符;位置向量可以向Transformer 模型提供時序信息,反映不同位置的字符代表的語義差異。對于序列標注任務,BERT 模型利用文本中每個字符對應的輸出向量對該字符進行標注。
3.2 CRF層
CRF是一個序列化標注算法,接收一個輸入序列X,輸出目標序列Y,在線性鏈條件隨機場中,兩個相鄰的節點構成一個最大團,并滿足公式:
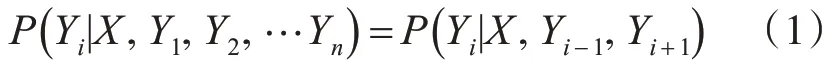
使用CRF對給定的觀測序列X求解,可得狀態序列Y的概率公式為
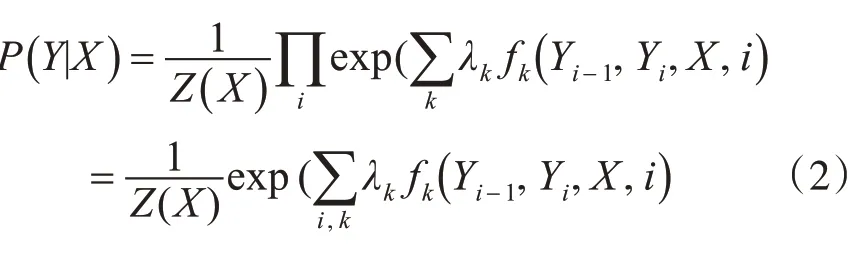
因為相鄰的狀態序列之間具有限定關系,并依賴觀測序列數據,在此應用兩類特征函數,狀態特征s與轉移特征t,代入建模公式可得:
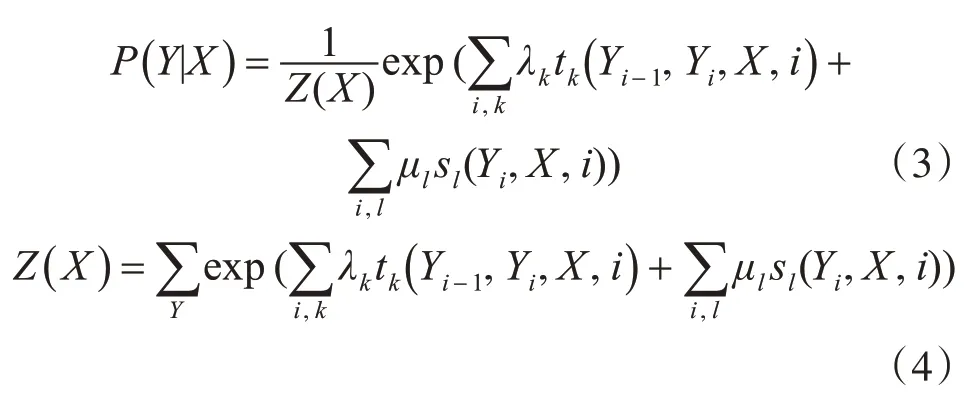
其中歸一化函數為Z(X),轉移狀態函數為tk,tk權重為λk,狀態特征函數sl,sl權重為μl,k和l表示轉移狀態函數和狀態特征函數的個數。
tk和sl的取值為1、0,以tk為例,公式為
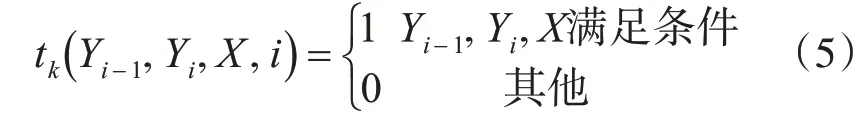
命名實體識別標記序列的依賴分布特點,有利于CRF擬合訓練數據,降低標簽序列預測中非法序列出現的概率。
4 實驗結果分析
4.1 訓練模型
本文實驗的硬件環境是Dell R740 服務器,掛載2 塊NVIDIA Tesla P40 的GPU 卡;深度學習框架使用TensorFlow 1.12.0 版本。BERT 模型使用base版本,該版本網絡層數為12,隱藏層神經單元數量為768,自注意力頭的數量為12,位置信息編碼的最大長度為512,字典大小為21128;根據模型配置參數加載BERT 模型,BERT 首先將輸入文本轉化為符合其輸入格式的數據,經過運算以后,將模型輸出結果連同真實標簽、狀態轉移矩陣輸入到CRF層,CRF 使用viterbi 算法,代替softmax 分類器做出分類。
4.2 結果對比
本實驗采用精度P、召回率R、F1分數三個指標評價模型性能,其計算公式為:
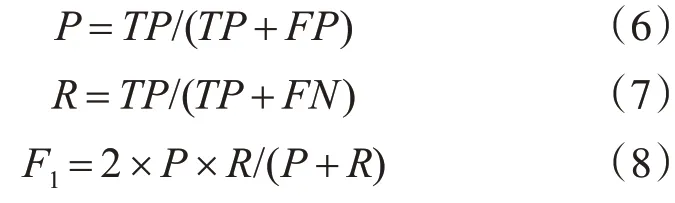
對比目前應用最為廣泛的IDCNN+CRF模型和BiLSTM+CRF 模型,在相同的硬件環境下和相似的參數設置下,對三個模型在相同的數據集上進行測試。
訓練過程中,設置三種模型的epoch 最大值為50,訓練結束后,分別選擇在驗證集上實體識別的總F1分數加和性能最優的模型,使用該模型在測試集上獲得各類實例的性能指標,其性能指標結果如表2所示。
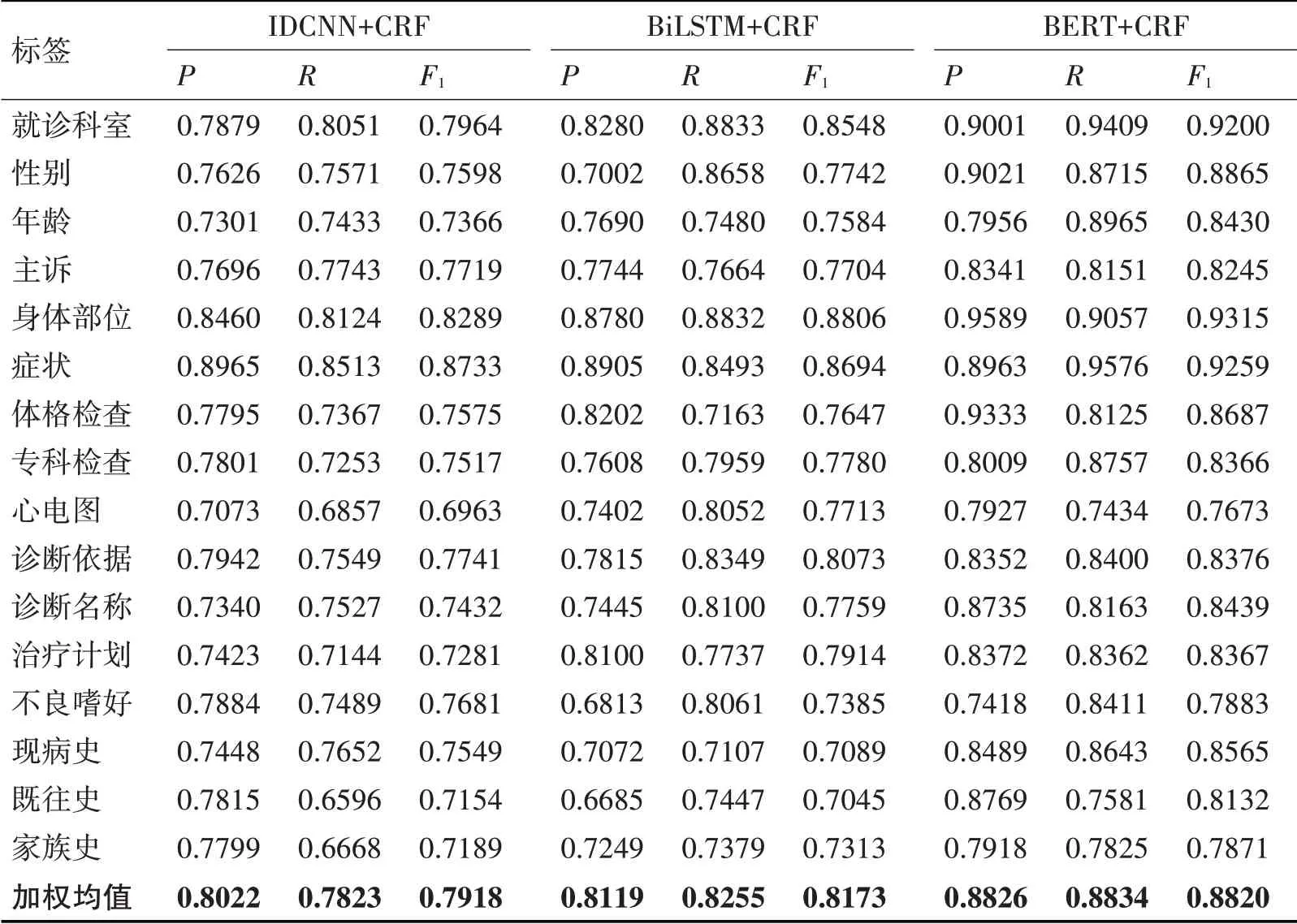
表2 不同模型在測試集上實體識別性能
同一模型在各個實體類型上的得分會有較大的差異,比如BERT+CRF 模型的得分,“家族史”的F1分數只有0.8356,其原因是該類型實體在電子病歷中實體樣本數量較少,模型學習得不夠充分。
本文對上面序列標注問題廣泛使用的兩個模型和BERT+CRF 模型的性能指標進行統計對比,IDCNN+CRF 模型的F1分數達到0.7918,BiLSTM+CRF 模型的F1分數達到0.8173,相差不明顯。本文提出的BERT+CRF 模型,其F1分數為0.882,比BiLSTM+CRF模型提高6.5%,錯誤率下降30%,性能有了明顯的提升。
5 結語
本文針對中文電子病歷的特點,提出一種BERT+CRF 的命名實體識別方法,第一層的BERT模型使用預訓練的BERT-Large 版本,在語料庫上進行微調,第二層的CRF的對標簽集狀態轉移進行約束優化,相比目前常用的實體識別模型,在性能上得到較大的提升,驗證了BERT 模型在中文序列標注問題的優越性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
