中國企業“走出去”的技術進步效應影響因素
——基于修正的多指標面板數據模糊聚類
2022-04-12 09:05:50陳曄婷劉洪穎
重慶文理學院學報(社會科學版) 2022年2期
陳曄婷,劉洪穎
(云南師范大學 經濟與管理學院, 云南 昆明 650500)
一、 引言
在經濟全球化背景下, 通過對外直接投資渠道獲取的國外研發資本能夠顯著提升一國的創新績效,特別是對于發展中國家更能起到縮短研發周期、節約研發成本的目的。 企業通過對外直接投資能夠提升具有比較優勢的產品和技術的市場發展潛力,參考國外在技術層面和企業管理層面的經驗發展,并結合企業自身特點提升綜合市場競爭力。 發展中國家企業的研究和發展(R&D)活動在全國經濟增長和發展中越來越重要,而世界經濟的全球化為促進知識創造活動提供了更多機會。
雖然“一帶一路”倡議推動著中國企業對外直接投資的發展,但從目前的發展狀況來說,中國企業對外直接投資發展歷程較短,當前仍處于摸索建設初級階段,在發展規模、資本積累、技術研發和創新、人才培養等方面處于弱勢領域。 此外,目前“走出去”的企業中雖然不乏通過對外直接投資成功推動企業創新的企業,如聯想成功并購IBM 的PC 業務,海爾集團在海外建立了8 個研發中心,北汽成功收購瑞典薩博汽車的知識產權等。 這些企業通過并購和綠地投資等方式,使自己在技術、產品等方面有了較大提高,快速增強了海外影響力和競爭力。然而不得不承認,有很多企業“走出去”卻沒能實現提高研發實力的目的。 如TCL 作為海外投資的先行者,但創新績效沒有得到顯著的提升。 “走出去”是趨勢和訴求,但沒有達到預期目標的企業也比比皆是。 在這種背景下,我們應當盡可能從企業內部挖掘影響技術進步效應的因素,避免更多的企業盲目“走出去”,促使適合的企業更好地“走出去”,這也有助于中國對外直接投資取得更好的經濟成效。
學者們對知識轉移現象的影響因素進行了較為廣泛的研究,最早對企業所處的外部環境作為主要的影響因素。 李梅[1]通過中國省際數據實證檢驗了對外直接投資的逆向技術溢出效應。 結果表明,對外直接投資的逆向技術溢出存在明顯的地區差異,并存在門檻效應。 并從經濟發展、技術差距、金融發展和對外開放程度等方面測算了引發積極逆向技術溢出效應的門限水平。尹東東[2]在此基礎上進一步檢驗了表征各因素對逆向技術溢出效應的影響,結果發現國內經濟發展水平、對外開放程度、基礎設施、金融發展規模對于OFDI 逆向技術溢出效應的實現起到了積極的促進作用。 隨后學者們研究影響因素的重點逐漸從外部環境轉向了企業本身,目前的研究主要從企業母公司自身特征出發。沙文兵[3]通過實證研究發現自主研發投入水平的不同會導致對外直接投資逆向技術溢出的吸收程度不同。 李梅[4]考慮了企業的管理者背景,認為企業高管政治緊密,則逆向技術溢出越顯著,高管政治聯系正向調節技術溢出對創新的影響。林莎[5]從進入東道國的戰略出發,認為跨國并購和綠地投資兩種不同對外投資方式在績效上呈現出差異性。 Piperopoulos[6]以對外直接投資的目標國家為研究對象,認為對外直接投資對中國企業創新績效有正向影響,當目標國為發達國家時,該作用更為顯著。Hsu[7]從對外直接投資經驗的視角, 考察研發國際化對創新的作用, 將國際化經驗作為調節變量來考慮。Nair[8]認為子公司所處的網絡、知識復雜性以及東道國的競爭指數都會影響跨國公司的知識轉移。 通過對文獻的梳理發現,學界對企業對外直接投資與創新績效的影響因素研究還并不完善,雖然已經有學者從母公司異質性特征的視角,如企業的研發投入、所在行業、社會資源等,也有學者從子公司進入東道國的模式出發,以并購或者綠地投資作為研究視角進行初步的探討。
通過對文獻的梳理還發現,影響創新績效的企業特征因素往往被直接用作“走出去”企業技術進步效應的控制變量,對控制變量也缺乏進一步的分析,這顯然存在著不足。 由于跨國投資的難度加大,對企業自身也提出了更高的要求。雖然目前越來越多的企業試圖通過對外直接投資的方式學習和獲取境外的先進技術,但失敗的企業數量是不容小覷的。除了外部環境因素,每個企業的特征各不相同,探討企業特征對技術進步的影響有助于幫助企業進行對外直接投資決策。 基于上述論述,本文意圖從企業的特征入手,對企業面板數據進行實證分析。由于現有論文中大多采用回歸的方法,將文中要測算的變量常被用作控制變量。 也就是說,學者們普遍認為企業的規模、企業成立時間等基本特征對“走出去”企業的技術進步效應有正向影響,為了對這種固有思維進行驗證,本文采用聚類的方法對數據進行挖掘。 但是,目前面板數據聚類方法的研究還相對欠缺,面板數據的主要作用仍然是對數據的基本形式進行刻畫,在不同領域不同分析方法中,仍然以研究數據的因變量模型為主要內容[9]。
朱建平[10]最早對面板數據做了統計描述,用面板數據的聚類分析進行實證檢驗證明方法的有效性,某種意義上為后續學者進行研究奠定了一定的理論基礎。 二維截面數據聚類分析的理論基礎已經很成熟,因此,一般面板數據聚類個體間的相似度問題是將基本的聚類分析用于面板數據時唯一需要考慮的問題。 部分學者也正是這樣進行實證檢驗的。 李因果[11]認為在經濟管理問題中,必須考慮根據研究對象構建相似的共識進行測度,根據面板數據的特性提出了反映面板數據樣本間絕對量差異、增速差異、波動性差異的距離統計量,之后結合改進的距離公式給出了面板數據ward 聚類法的聚類步驟。 李崢[12]定義了包含三個維度的“歐式時空距離”,在此基礎上對面板數據進行聚類分析,將數據進行分類,再利用面板數據的變系數模型進行實證檢驗。 劉兵[13]則考慮了時間序列的特征,研究了具有水平趨勢、非水平趨勢、線性趨勢的面板數據,以樣品指標序列的趨勢特征來設置統計量,但論文中還未探討其他形式時間序列的聚類問題。
基于上述論述,本文利用wind 數據庫中上市公司的財務報表數據與商務部發布的《對外直接投資名錄》進行匹配,結合修正的多指標面板數據模糊聚類方法驗證“走出去”企業技術進步效應的內在影響因素。 主要貢獻體現在兩個方面:一是從企業內部特征的視角發現,與被廣泛認同的企業特征不同,并不是企業規模越大,成立時間越長,就會通過對外直接投資提高創新能力,反而是與“蹬羚企業”具有相似特征的中小規模企業更能在對外直接投資過程中獲取技術;二是在方法上修正面板數據的聚類方法,由于面板數據的聚類方法(灰色關聯度、降維)相對欠缺并存在聚類方法復雜、不便于使用、聚類數無法評價等問題,因此提出一種多指標面板數據的模糊聚類及評價方法。 該方法能夠有效地對多指標面板數據進行聚類。
二、研究設計
當前針對多指標面板數據的聚類方法,主要集中在一些學者將傳統的灰色關聯分析方法進行改良,并應用在面板數據相似性的分析上。 劉震[14]在其研究的基礎上,將面板數據在三維空間的數據點看作網格狀結構的節點,將網格拆分,從而構建了灰色網格的關聯度模型。 吳利豐[15]則基于面板數據的凸性構建了三維灰色凸關聯度、指標隨時間變化的速度和指標發展的協調水平。 錢吳永[16]將灰色關聯度的應用范圍由一維向量拓展到二維矩陣。 多指標面板數據聚類分析的最大困難在于其數據結構的特殊性,其聚類分析理論的構建實際上是傳統多元分析方法應用拓展到高維數據的重要突破。
目前,許多學者在聚類時用預處理的手段對多指標面板數據進行降維。 徐華鋒[17]等通過數據線性組合的方式對數據進行降維,之后采用動態聚類的方法對投影向量進行了聚類。 任娟[18]通過因子分析的方式達到降維的目的,又依據Fisher 的最優分割法提出了多指標面板數據的有序聚類方法。 王雙英[19]將面板數據的指標分為因變量指標與自變量指標進行降維,再利用自組織競爭神經網絡進行聚類。
通過上述文獻梳理發現,基于灰色關聯度進行聚類分析的過程是非常復雜的,并且降維數據會造成數據源的不完整。 本文針對上述問題,提出一種易于實現的、快速的、能夠自評價的多指標面板數據聚類方法。
(一)模型設計
常見面板數據的存儲方式是按照樣本進行劃分,每個樣本內部形成“時間-指標”矩陣。 也就是每個樣本一張表,該表每一列為一期,每一行為一個指標。 這種方式的存儲是對面板數據最直觀的表達方式,結構簡單、直觀,便于研究者對樣本進行數據分析[20-21]。
但是,這種存儲方式不易于聚類分析。 面板數據聚類分析的目的是發現樣本之間的相似性,因此每個樣本應該對應著該樣本的特征向量。 面板數據難于聚類的主要原因就在于特征向量不易表達。 如果直接使用面板數據是無法進行表達的,當前采用最多、最易于實現的方式是將面板數據表示為如表1 所示的面板數據二維表示法。 每一行代表一個樣本,每一列可以作為樣本的特征向量,通過這種變換每一行就能夠作為該樣本的特征向量,從而進行聚類。

表1 面板數據二維表示法
其中,Dij(t)表示第i 個樣本的第j 個指標在第t 期的值,i∈[1,N],j∈[1,m],t∈[1,n]。 將樣本按照時間進行對齊的方式就能夠對每個樣本的特征進行刻畫,從而進行聚類分析。
若將樣本數據使用一個矩陣△x∈RN×M進行表達,則△x(k,l)與Dij(t)具有如下關系:
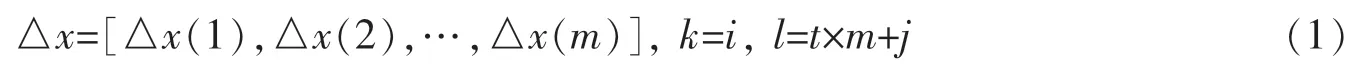
其中,k∈[1,N], l∈[1,M]。
特征向量間的相似性主要通過向量間距離進行計算。 常用的計算距離方法包括歐氏距離、曼哈頓距離、余弦距離等。 這些距離應用場景不同,各有利弊,其中應用最廣泛的是余弦距離。 本文也使用余弦距離計算兩個特征向量間的相似性:

其中,‖Vx(i)‖和‖Vx(j)‖分別為向量Vx(i)和Vx(j)的范數,為歸一化向量。
為了有效地發現樣本之間的相似性,首先利用一種典型的模糊聚類方法——模糊C 均值聚類算法FCM(Fuzzy C-Means)[22]來確定樣板數據的聚類中心與隸屬度矩陣。 該隸屬度矩陣和聚類中心為下一節的劃分和確定奠定了基礎,具體的獲取方法敘述如下。
算法1:隸屬度矩陣與聚類中心獲取算法。
步驟一:輸入由事件構建所得特征矩陣△x,其中第i 行即為該條事件的特征向量△x(i);
步驟二:對于活動數C(2≤C≤N),當滿足閾值ε 或者達到最大迭代次數K 時迭代停止,記錄下取C 時所對應的隸屬度矩陣和聚類中心;
步驟三:輸出所有聚類數C 所構建的隸屬度矩陣集合MU和聚類中心集合Center[22]。
定義1(Hpal 熵)[23]:

定義2(平均模糊熵):給定聚類數為C,通過算法1 求得的對應隸屬度矩陣為U,則平均模糊熵定義為

其中,μij表示樣本j 屬于第i 類的程度。
通過定義2 可知,針對不同C 的平均模糊熵H(C)也不同,在所有的聚類數C(2≤C≤N)中,存在一個聚類數m 使得平均模糊熵H(m)達到最小值,此時所對應的聚類數m 即為最佳聚類結果,對應的隸屬度矩陣和聚類中心分別記為Um 和CTm。 具體如算法2 所示[24]。
算法2:聚類結果確定及結果關聯。
步驟一: 根據聚類數C 和相應的隸屬度矩陣UC 依次計算每個聚類數C 所對應的模糊熵,得到模糊熵集合Entropy={entropy1,…,entropyC};
步驟二:對模糊熵集合歸一化,得到歸一化的模糊熵集合Entropy′={entropy1/e1-1/c,…,entropyC/e1-1/c};
步驟三:得到Ci=argminentropyi′及Ci所對應的聚類中心Centeri、隸屬度矩陣Ui;
步驟四:根據隸屬度閾值δ,聚類中心Centeri、隸屬度矩陣Ui得到當前每個樣本的聚類集合也就是聚類結果A,以及A 與各個樣本的關聯關系集R;
步驟五:輸出聚類結果A以及A 與各個樣本的關聯關系集R。
(二)模型優勢
多指標面板數據不僅能夠用于表達包含時間維度與空間維度的橫截面數據,還是一種重要的數據結構。 這種數據結構與當前聚類方法所采用的特征向量二維矩陣稍有不同,所以本文考慮通過對面板數據稍加變換即可作為企業的特征向量來表征企業。 該方式從數據結構的層面與當前面板數據復雜的表達方式不同。 在方法層面,本文主要通過FCM 聚類對多指標面板數據進行聚類。 已有的面板數據聚類往往是硬化分(例如朱建平[10]和李因果[11]采用的層次聚類方法),由于模糊聚類得到的樣本屬于各個類別的不確定性程度,表達了樣本類屬性的中介性,即建立起樣本對于類別的不確定性描述,更能客觀地反映實際事物。 同時,本文提出一種基于模糊熵的聚類評價方法, 通過計算每種聚類結果對應的熵值來評判聚類結果的優劣,從而確定聚類數。
三、 實證分析
(一)數據來源及說明
本文采用研發效率作為企業技術進步效應的替代變量。 先通過將《對外直接投資名錄》和wind 數據庫進行匹配,將對外直接投資時長超過10 年并且基本信息公布較為全面(主要是研發投入的數據)的企業篩選出來,其次對這些企業的研發效率逐個計算(研發效率的計算公式:RDratioti=Pti/RD(t-1)i,其中創新投入指標為R&D 經費,專利申請量P 是衡量技術創新產出的一個重要指標。 考慮到研發產出的滯后性,產出比投入滯后一期),保留研發效率呈上升趨勢的企業共11 家,這些企業組成A 組數據。 另外一組由進行對外直接投資時間較短的企業組成,由于大部分企業是在2014 年左右才開始進行對外直接投資的,這些企業“走出去”的時間較短,研發效率的趨勢并不穩定,因此隨機從這些企業中抽取了報表中財務數據較為全面的企業共39 家,這些公司包括四川長虹電器股份有限公司、孚日集團股份有限公司、云南白藥集團股份有限公司等,這些企業組成一個組,設為B 組。 A 組中企業數量有11 個,B 組中企業數量有39 個。 通過企業特征變量將這兩個組的企業放在一起并進行模糊聚類,進行模糊聚類的企業成為C 組,觀察C 組的聚類結果。 如果B 組中有企業能夠和A 組企業聚在一起,說明這些企業具有相似性。 那么B 組企業在未來也有隨著對外直接投資的進程,研發效率顯著提升的可能性。 分析這些企業的特征,為企業進行對外直接投資決策提供可能的參考。 通過梳理已有文獻,總結可能影響研發效率的因素,并且考慮到數據的可獲取性,最終選擇考察的指標包括:資本密集度(固定資產/員工數)、企業規模(從業人員對數)、資本流動性(流動資本-流動負債)/總資產、企業年齡(被調查年份-創辦年份+1)、是否研發、資本勞動比、是否高新技術企業,時間周期從2011—2017 年,共7 期。
實驗步驟設計為六步:a.對樣本數據Data 進行預處理;b.將數據轉化為二維特征矩陣;c.利用FCM 方法獲得聚類數和聚類中心;d.通過本文提出的基于Hpal 熵的方法遍歷聚類數,計算每種聚類數下的模糊熵;e.記錄模糊熵值最小時的分布;f.多次重復實驗步驟c、d、e,取多次重復且出現次數最多的聚類數為最終結果。
因為FCM 聚類每次聚類的結果可能不同,所以我們在實驗方案中考慮通過多次計算(本實驗計算50 次)選取多次中出現最頻繁的聚類結果為最終結果。
(二)實驗結果與分析
通過實驗得到的結果如圖1、圖2 和圖3 所示。 其中圖1 為聚類數從1 變化到39 對應的平均模糊熵的變化情況。 從圖1 中可以看出,當聚類數為7 時,對應的平均模糊熵達到最小值0.24,因此實驗數據對應的聚類數為7。在該聚類數下,每個樣本所屬的聚類編號(從1 到7,共7 類)如圖2 所示,每類包含的樣本數統計結果如圖3 所示。 從圖2、圖3 可以發現:第一類包含的樣本數最多達到12 個;第3 類和第5 類包含的樣本數最少,均只有1 個。
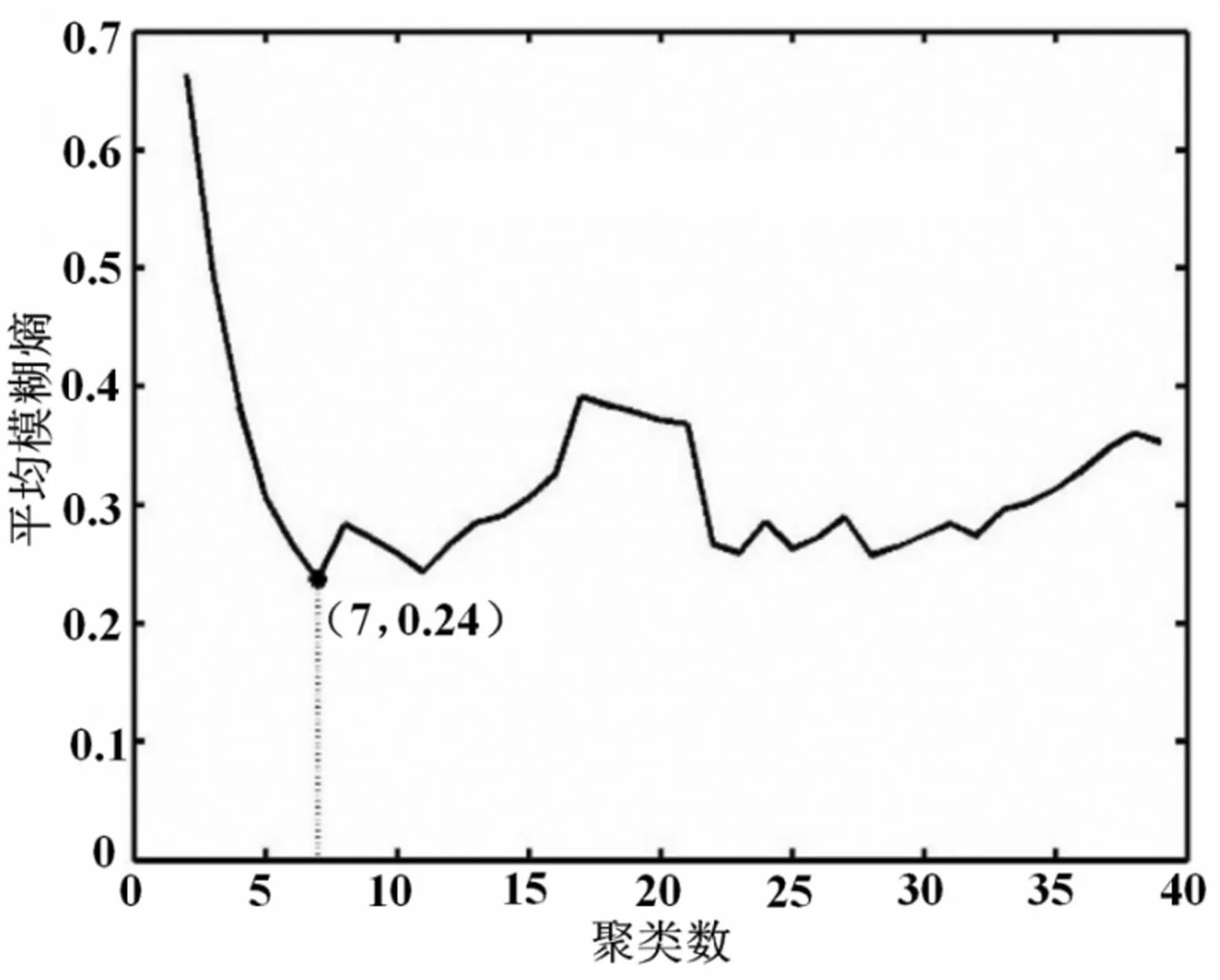
圖1 平均模糊熵隨聚類數變化

圖2 聚類結果下每個樣本所屬類別
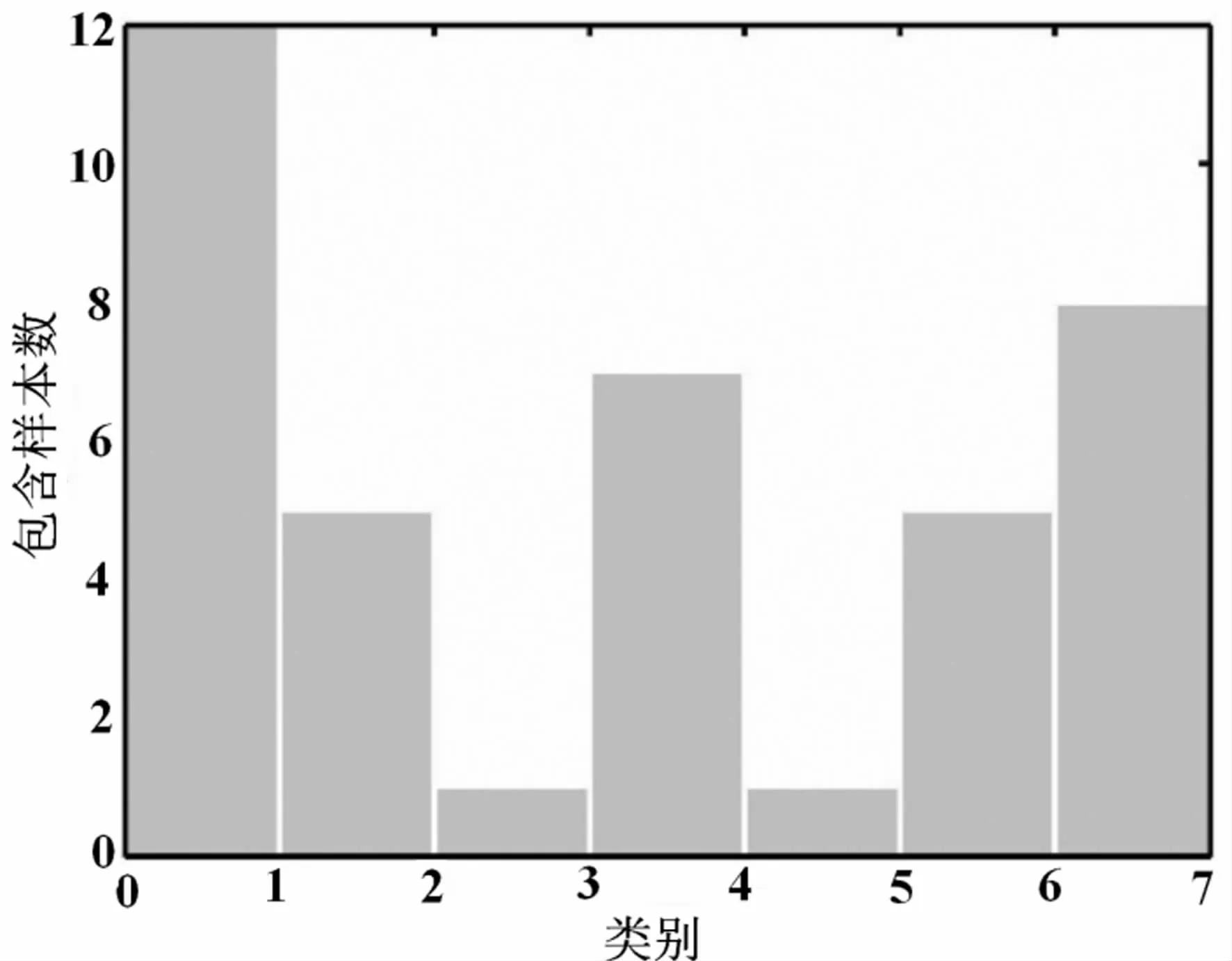
圖3 聚類結果下各個聚類類別包含樣本統計
通過聚類企業分類的結果如圖4 所示。 第一類樣本包括四川長虹電器股份有限公司、浙江新安化工集團股份有限公司、江蘇銀河電子股份有限公司、濟南輕騎摩托車股份有限公司、株洲時代新材料科技股份有限公司、云南白藥集團股份有限公司、博深工具股份有限公司、江蘇聯發紡織股份有限公司、深圳市大族激光科技股份有限公司、重慶華邦制藥股份有限公司、北京福星曉程電子科技股份有限公司、歌爾聲學股份有限公司(共12 家);第二類樣本包括:浙江久立特材科技股份有限公司、陽光電源股份有限公司、中國南玻集團股份有限公司、新疆金風科技股份有限公司、四川海特高新技術股份有限公司(共5 家);第三類樣本包括蘇州勝利精密制造科技股份有限公司(共1 家);第四類樣本包括廣西柳工集團有限公司、亞普汽車部件股份有限公司、中信重工機械股份有限公司、浙江萬豐奧威汽輪股份有限公司、中國長城計算機深圳股份有限公司、京東方科技集團股份有限公司、江蘇金智科技股份有限公司(共7家);第五類樣本包括雙錢集團股份有限公司(共1 家);第六類樣本包括江西銅業股份有限公司、杭州海康威視數字技術股份有限公司、孚日集團股份有限公司、金發科技股份有限公司、貴州鋼繩股份有限公司(共5 家);第七類樣本包括:濰柴動力股份有限公司、煙臺冰輪股份有限公司、建研科技股份有限公司、浙江正泰電器股份有限公司、上海電氣集團股份有限公司、北汽福田汽車股份有限公司、江漢石油鉆頭股份有限公司、武漢高德紅外股份有限公司(共8 家)。
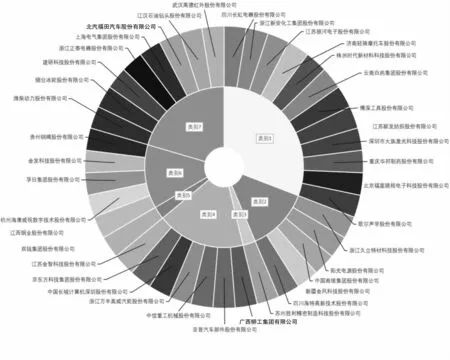
圖4 企業分類結果
圖4 展示了每類企業都有哪些家。 第一類企業共有12 家,第二類企業共有5 家,第四類企業共7 家,第六類企業共5 家,第七類企業共8 家,共有5 個組。 第三類和第五類各有1 家企業,因此不再考慮。 每一組企業的具體特征均值如表2 至表6 所示。
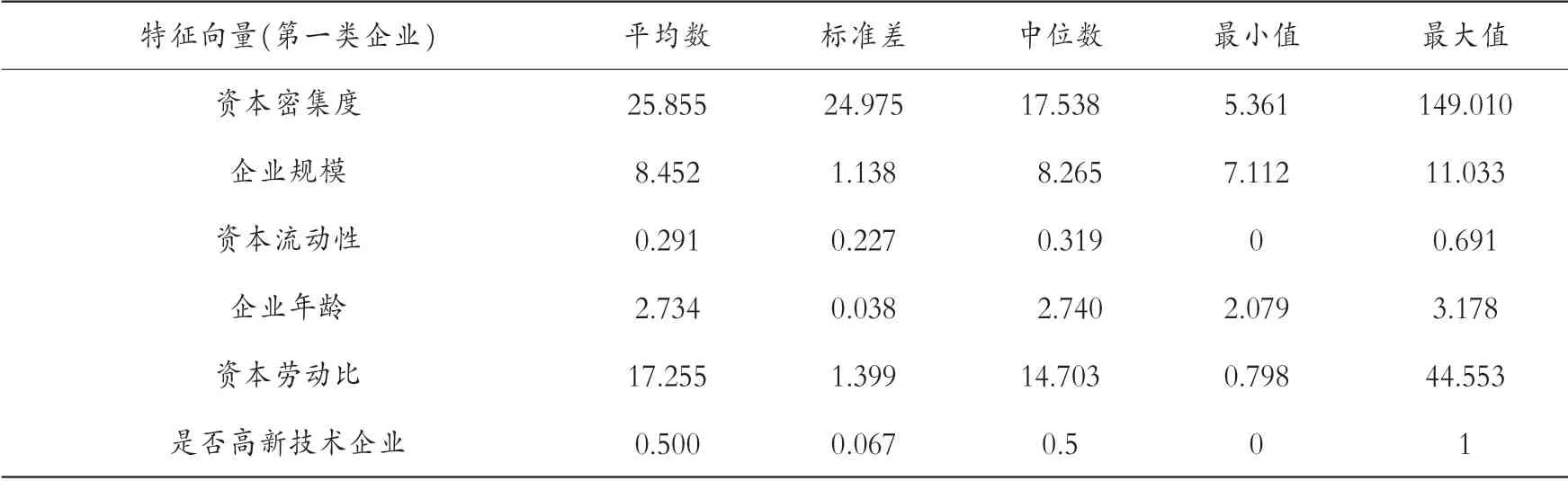
表2 第一組企業的描述性分析
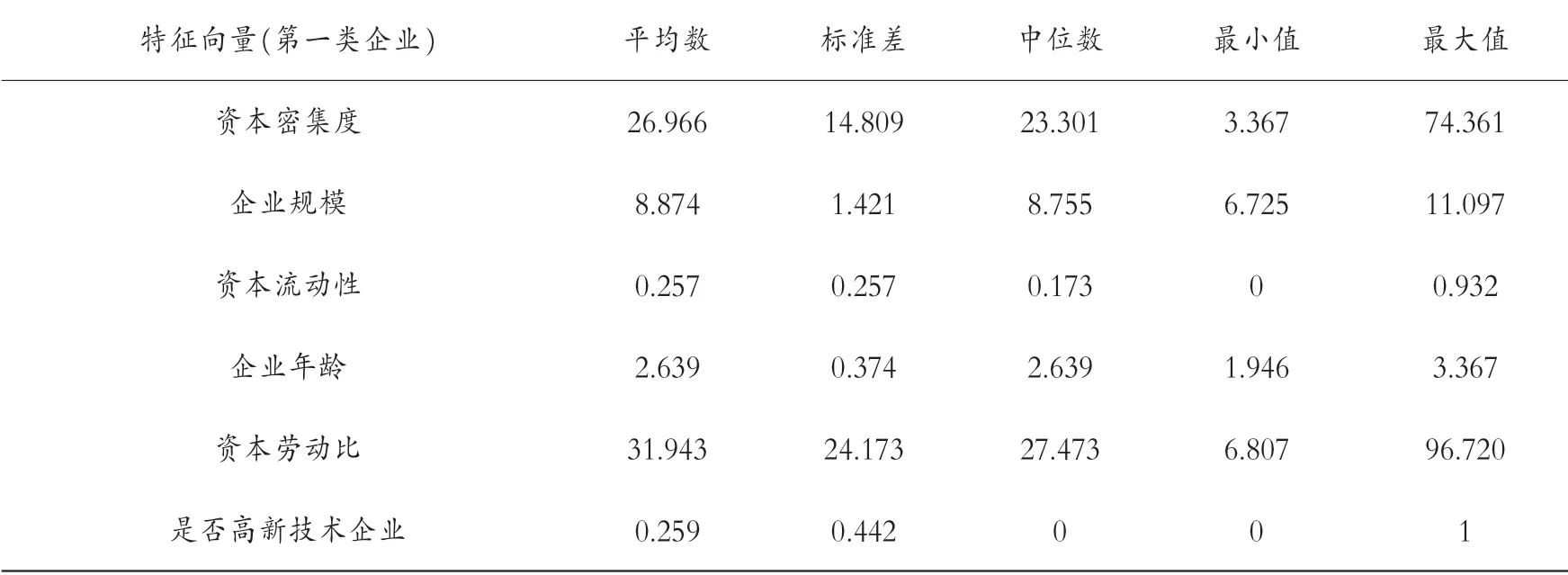
表6 第七組企業的描述性分析
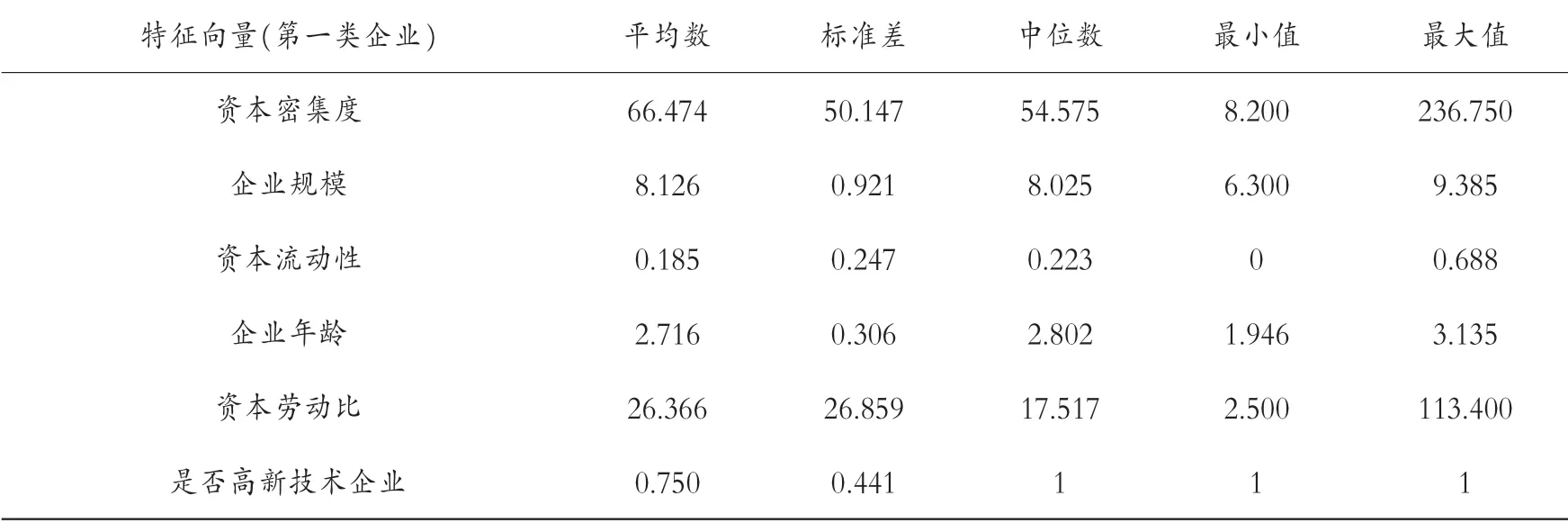
表3 第二組企業的描述性分析
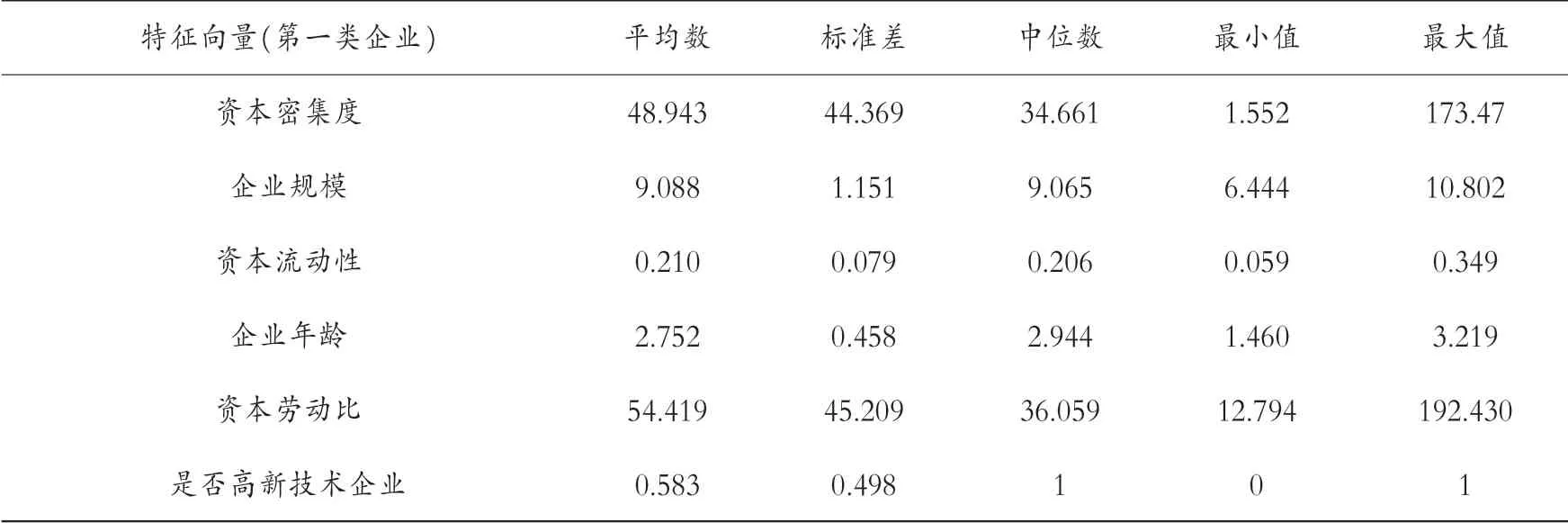
表4 第四組企業的描述性分析
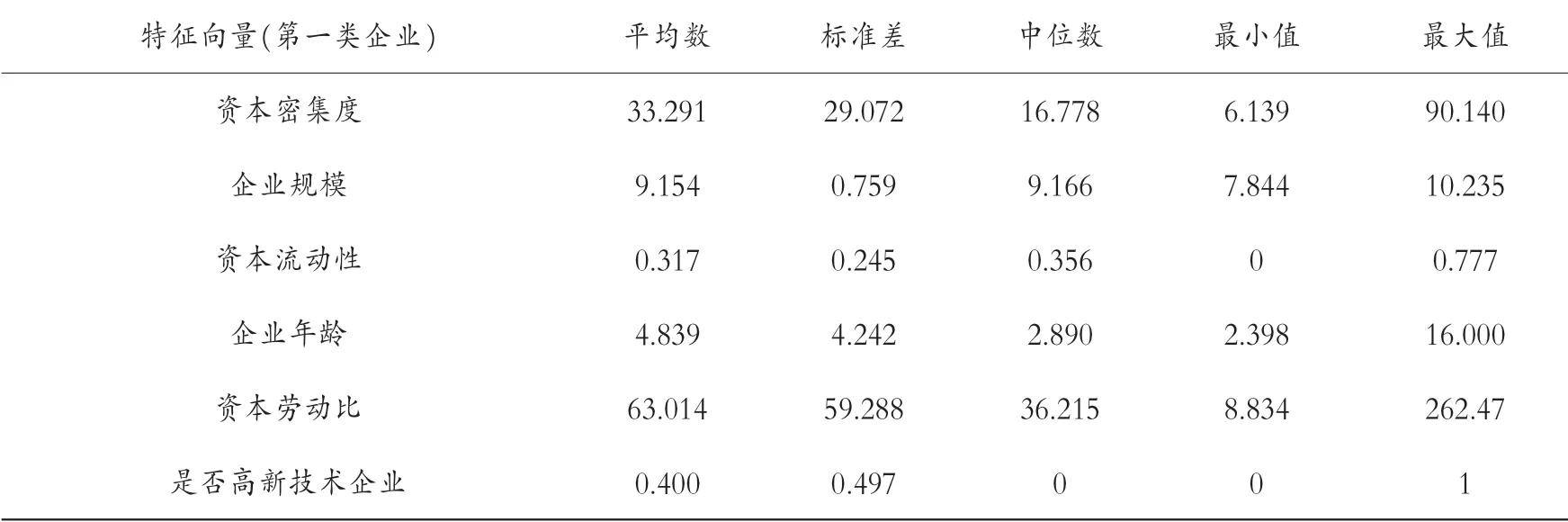
表5 第六組企業的描述性分析
幾組數據中平均數都大于標準差,表示數據中沒有極端值,并且將各組的特征分別進行排序。 資本密集度:第二組(66.474)>第四組(48.943)>第六組(33.291)>第七組(26.966)>第一組(25.855)。 企業規模:第六組(9.154)>第四組(9.088)>第七組(8.874)>第一組(8.452)>第二組(8.126)。 資產流動性:第六組(0.317)>第一組(0.291)>第七組(0.257)>第四組(0.210)>第二組(0.185)。 企業年齡:第六組(4.839)>第四組(2.752)>第一組(2.734)>第二組(2.716)>第七組(2.639)。 資本勞動比:第六組(63.014)>第四組(54.419)>第七組(31.943)>第二組(26.366)>第一組(17.255)。 是否高新技術企業:第二組(0.750)>第四組(0.583)>第一組(0.500)>第六組(0.400)>第七組(0.259)。 再次聚類,可以發現具有哪些特征的企業能夠與長期進行對外直接投資的企業聚在一類。
(三)發現與結論
進行對外直接投資的企業達到十年及以上的,企業數據完整且研發效率呈增長趨勢的企業分別是:深圳遠望谷信息技術股份有限公司、深圳信隆實業股份有限公司、國光電器股份有限公司、寧波韻升股份有限公司、浙江海亮股份有限公司、橫店東磁集團股份有限公司、杭州士蘭微電子股份有限公司、江蘇恒瑞醫藥股份有限公司、中國軟件與技術服務股份有限公司、威海華東數控股份有限公司、青島金王應用化學股份有限公司。 影響研發效率的企業特征如表7 所示。
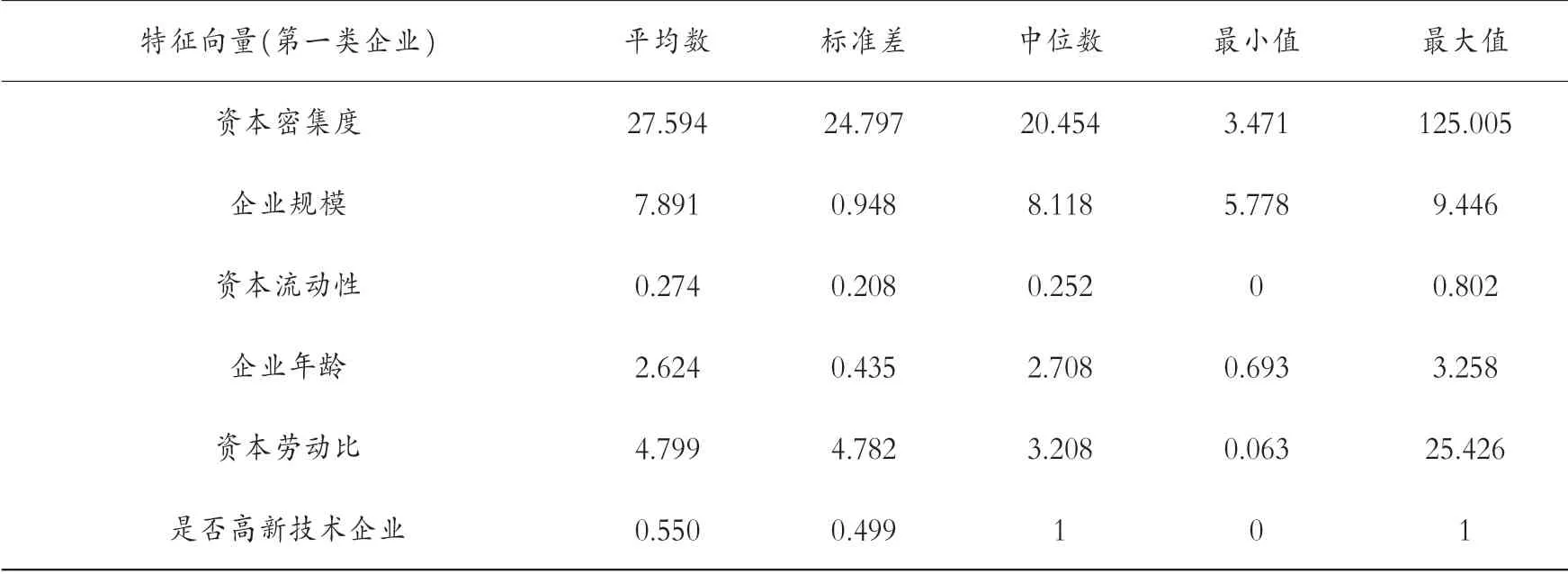
表7 影響研發效率的企業特征的描述性分析
將這11 家企業影響研發效率的特征與前文提到的39 家企業合在一起共50 家企業進行聚類,聚類結果如圖5 所示。50 家企業共聚成兩類,其中前11 家企業有10 家都在同一個類別中(類2),說明這10 家企業的特征都具有相似性。 因此推斷在企業進行對外直接投資的過程中,技術進步顯著的企業可能擁有表6 中描述的那些特征。 類2 中其余的企業共11 家,分別是歌爾聲學股份有限公司、蘇州勝利精密制造科技股份有限公司、雙錢集團股份有限公司、四川海特高新科技股份有限公司、江蘇聯發紡織股份有限公司、中信重工機械股份有限公司、新疆金風科技股份有限公司、中國南玻集團股份有限公司、陽光電源股份有限公司、浙江久立特材料科技股份有限公司、浙江新安化工集團股份有限公司。 這些企業能與前面10 家企業聚為一類,說明他們的企業特征具有相似性;而將這些企業的研發效率進行測算,發現這些企業確實在對外直接投資期間研發效率呈增長態勢。
圖5 兩組企業聚合分類結果
將上述11 家企業與分組企業對照發現, 第二類樣本的5 家企業全都涵蓋在這11 家之中。 這類企業的特點是規模較其他組的企業小,資產流動性較低,企業也比較年輕,但都是高新技術企業并且資本密集度明顯高于其他組企業。 除了第二類的5 家企業,第一類有3 家、第四類有1 家,第三類有1 家和第五類有1 家也都在第二類分組里。 這些企業的影響因素特征的描述性分析如表8 所示。
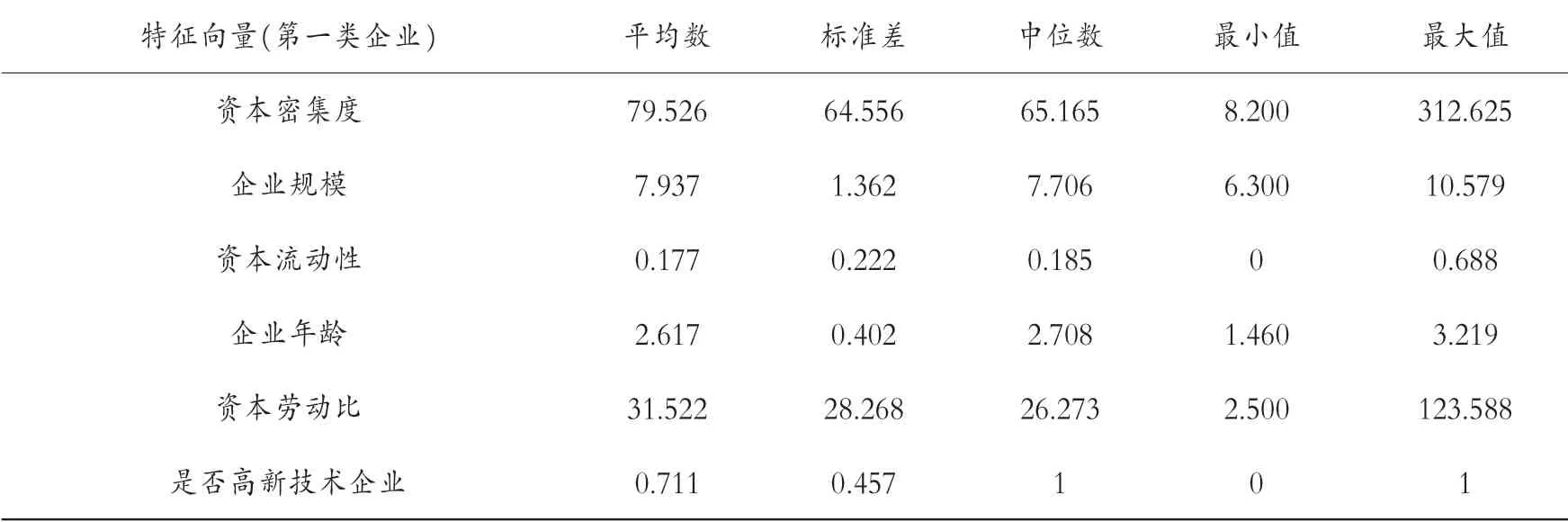
表8 企業影響因素特征的描述性分析
與第二類數據的特征相似,這11 家企業的平均資本密集度更高,企業規模更小也更為年輕,并且同樣是高新技術企業較多。 因而可以得出這樣的結論,對于近期進行對外直接投資或者未來將要進行對外直接的企業,并不是全部的制造業都可以通過對外直接投資方式提高創新能力,而具有如下特征的企業更能夠通過對外直接投資行為實現技術進步:年輕的高新技術企業、規模相對較小且資本密集度遠超出普通制造業的企業。
四、結語
在經濟全球化的今天,國家與國家之間競爭的核心就是生產力的競爭。 新形勢下如何有效提升科技進步對經濟增長的貢獻率成為一個值得研究和深思的問題[25]。 在當前開放經濟條件下,如何有效發揮企業對外直接投資渠道從而提升創新績效,對于作為世界第二大對外直接投資國的中國企業而言,形成自身競爭優勢具有重要的現實意義。 關于制造業“走出去”的技術進步效應的影響因素,學者們已經展開了較為廣泛的討論,關注的重點也逐漸從外部環境的影響轉移到企業自身,但由于方法的限制等原因,企業的特征因素往往得不到深入的挖掘。基于此,本文提出一種多指標面板數據的模糊聚類及評價方法。該方法首先將多指標面板數據從三維橫截面數據轉化為二維特征矩陣表示方式,其次利用改進的FCM 方法對特征向量進行聚類,再次提出一種基于Hpal 熵的模糊聚類自評價方法,最后通過遍歷聚類數并計算當前聚類模糊熵進而確定最終聚類結果。 在此方法的基礎上,將近期進行對外直接投資企業和已經對外直接投資超過10 年的企業面板數據分別進行多次聚類, 用以分析什么樣的企業特征能夠在長期的對外直接投資中實現研發效率的提升。 結果發現,近期進行對外直接投資的39 家企業中,有11 家企業與能夠提高研發效率的企業聚為一類。 這些企業的特征包括:成立時間并不長,員工人數不多并且多為高技術企業。 這些企業由于資本密集度較高,因此資本流動性較低。
我國企業進行對外直接投資之前,除了進行海外市場的調研,了解海外高端技術行情以外,還應從企業自身的特征出發,考慮是否適合進行“技術獲取型”的對外直接投資。 研究結果顯示,高新技術企業進行對外直接投資相比于普通的制造業企業,更易于通過對外直接投資的方式提高創新能力。 對于普通的制造業企業來說,通過對外直接投資的方式直接提高創新能力的結果并不是很理想,因此普通的制造業企業應先拉近與高端技術的距離,逐漸提升自己的學習能力,然后再向更尖端的技術靠攏,這樣才能將研發資金更有效地加以利用并有利于培養自身的核心競爭力。 在此之前可以考慮其他的途徑提高自身的創新能力而不是跟風走出國門。 此外,結果顯示,并不是成立時間較長的規模較大的企業能夠通過對外直接投資來提高創新能力,反而是成立時間不長、規模也不大但資本密集度高的企業能夠在技術獲取型的對外直接投資中脫穎而出。 可能的原因是技術的提高除了需要大量研發資金和研發人員的投入外,更需要企業自身的設備作為支撐。 特別是中美貿易戰之后,發達國家對中國的技術封鎖越發嚴格(如華為被無理制裁),中國企業特別是高新技術企業通過對外直接投資的方式直接獲取顯性知識變得愈發困難。 在這種背景下,企業可以通過與海外子公司以及海外技術人員溝通交流來獲取有益于創新的隱性知識,進而轉化為顯性知識來提高創新能力。 由于直接將專利和新產品反哺母國企業的趨勢變緩了,因此只有結合自身的高端機械設備并結合發達國家的經驗及技能,才能有效地通過“走出去”的方式提高中國企業的技術水平。 此外,年輕的企業可能更注重產品的創新研發,因此鼓勵年輕的、規模不大但資本密集度高的高新技術企業“走出去”,就能夠在未來獲得更為顯著的技術進步效應。
猜你喜歡
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
云南畫報(2020年9期)2020-10-27 02:03:26
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
