人工智能與未來教育評價
2022-04-12 00:00:00馬克·約翰遜金俞崔新孫波
中國教育信息化 2022年7期



摘" "要:人工智能算法如何才能準確把握人與人之間交流時傳遞的深層次思想,是人工智能教育評價系統(tǒng)面臨的最大挑戰(zhàn)之一。這需要相關(guān)工作者對人工智能、動態(tài)對話以及統(tǒng)計分析有著更加深入的了解。在醫(yī)學應(yīng)用中,人工智能決策判斷的有效性主要由“敏感性”和“特異性”兩個統(tǒng)計指標進行衡量。雖然這些統(tǒng)計數(shù)據(jù)有助于了解總體情況,但卻忽略了一個事實,即無論如何增加機器學習的訓練數(shù)據(jù),都無法消除判斷的不確定性。因此,在教育應(yīng)用中,必須考慮人與機器如何協(xié)同工作,以提高未來教育評價的效率,并為對話教育創(chuàng)造更多空間。文章著重分析機器學習、貝葉斯統(tǒng)計方法對改變基于人工智能的教育評價的可能性,強調(diào)未來教育評價最基本的問題是明晰人與機器所擅長的領(lǐng)域各不相同,人工智能在教學過程中提供自動、高效和準確的反饋,可以幫助學生實現(xiàn)自主學習和自我評價;而對于機器無法確定的決策判斷,則需要教師的參與和干預(yù)。據(jù)此提出,將當前人工智能在醫(yī)學診斷等領(lǐng)域的成功應(yīng)用,拓展到教育評價中,是未來教育改革的必然趨勢,將帶來人(教師和學生)與機器之間的密切合作。其中,信任是這個過程中最重要的因素,要增強人們對人工智能教育評價的信任,就需對機器學習過程進行更全面的檢測,并用更豐富的信息來判斷特定結(jié)果的準確度。而準確度可能是未來教育評價技術(shù)中最為重要一個部分,其能夠引發(fā)新的學校教育實踐,并更有效地利用教師專業(yè)知識,同時也能促進自主學習、師生對話和互動。
關(guān)鍵詞:人工智能;數(shù)據(jù)統(tǒng)計;教育評價;人機協(xié)同
中圖分類號:G434 " " " " "文獻標志碼:A" " " " "文章編號:1673-8454(2022)07-0003-07
一、從醫(yī)學診斷到教育評價
在過去五年里,人工智能在醫(yī)療領(lǐng)域的應(yīng)用,特別是提供自動診斷的能力有了突飛猛進的提升。越來越多的證據(jù)表明,機器的性能在很多方面已經(jīng)超過了人類專家的判斷。這主要由于一些關(guān)鍵計算機技術(shù)突破所帶來的變化,如卷積神經(jīng)網(wǎng)絡(luò)(CNN)、語言模型(GPT-3),以及由斯比格爾特(Spiegelhalter)等人率先采用的復(fù)雜貝葉斯統(tǒng)計方法[1]。其中,復(fù)雜貝葉斯統(tǒng)計方法和人工智能的結(jié)合,為醫(yī)療領(lǐng)域提供了更有效的診斷方案。
一直以來,醫(yī)療診斷領(lǐng)域面臨著信任和預(yù)測準確性的挑戰(zhàn)。其一是信任問題,如果臨床醫(yī)生不信任機器診斷的結(jié)果,那么人工智能所提供的診斷方案就很難被醫(yī)生采用。在教育領(lǐng)域,自動化評價還處于起步階段[2-4],但是很可能會面臨與醫(yī)療領(lǐng)域類似的信任問題。教育對人工智能提出了更大的挑戰(zhàn),最近圍繞人工智能考核評分中出現(xiàn)的一些負面爭議,動搖了人們對機器學習算法的信任[5-8]。其二是與信任密切相關(guān)的機器預(yù)測準確性問題。和醫(yī)療診斷一樣,在教育評價中,對預(yù)測性能的評估與人工智能技術(shù)的發(fā)展同等重要。
基于此,本文討論了運用貝葉斯統(tǒng)計方法,改變基于人工智能的教育評價的可能性:人工智能不是用于預(yù)測學生的成績,而是評估這個“預(yù)測”的準確度。由此不僅給教育評價帶來了新的機會,而且也為教學模式變革、個性化學習和開放對話提供了更大的可能性。這種可能性為對話教育,以及更有效地管理教育資源(包括教師和學生)提供了新的方式,這對未來教育的發(fā)展尤為重要。
二、預(yù)測未來和未來的預(yù)測
為了訓練人工智能模型,需要將數(shù)千個案例組成一個“訓練集”,而后建立有效的模型。機器學習意義上的“模型”,可以根據(jù)其對訓練數(shù)據(jù)的標注,自動對新數(shù)據(jù)進行分類。訓練數(shù)據(jù)中具有明顯相似性的元素會被歸為同類,訓練過程就是識別這些相似性,從而將元素按照不同的類別進行區(qū)分。隨著Kaggle[9]等公共數(shù)據(jù)集的廣泛使用,訓練過程變得更加簡單,而且模型生成技術(shù)也已經(jīng)普及。機器學習通過處理大量數(shù)據(jù)來確定一組數(shù)據(jù)的“特征”,這些特征可以泛化到新數(shù)據(jù)中進行分類。
教育數(shù)據(jù)比醫(yī)學數(shù)據(jù)更難分類。教育數(shù)據(jù)的類型非常復(fù)雜且差異很大(如論文、考試答案、圖表、視頻等)。通常,借助教師的評分結(jié)果,可以得到重要且較為可靠的數(shù)據(jù),并以此來衡量論文和考卷的相對質(zhì)量。基于這樣的判斷,很容易區(qū)分一些高質(zhì)量或低質(zhì)量的論文和作品。因此,機器學習可以很容易自動確定,明顯高分或低分的論文和作品。但對于處于“高分”或“低分”臨界點的論文或作品來說,機器很難為其評分。這就是說,人工智能預(yù)測的可靠性與其說概括為“一般”可靠性(通常由敏感性、特異性等統(tǒng)計數(shù)據(jù)決定),不如說是根據(jù)特定數(shù)據(jù)的特征,對正確預(yù)測可能性的預(yù)測。
在傳統(tǒng)的評估方法中,教師給學生分配任務(wù),并期望給予學生同等關(guān)注度,然而所有教師都知道,有些學生需要更多的時間才能完成任務(wù)。因此,教師需要對每個學生的作業(yè)進行評判,這既不能有效地利用教師智慧,也不會給學生有效的反饋。例如,如果有學生提交了不符合要求的作業(yè),最好是立即給他反饋,告訴他“這不夠好”,進而給出改進作業(yè)的思路。但受到傳統(tǒng)評估方法、學生數(shù)量的限制,教師無法實現(xiàn)這樣的即時反饋。相對地,人工智能系統(tǒng)可以進行自動評估。人工智能系統(tǒng)審閱一件作品,能夠立即識別出它的特征,從而判斷作品質(zhì)量的好壞。除了給出評價,它還能夠預(yù)測這個判斷的可靠程度。可靠性高的判斷不需要教師干預(yù),可以進行自動反饋。例如,一些系統(tǒng)可以直接提示學生如何改進作業(yè),并及時有效地與學生互動,學生也可以嘗試在沒有教師干預(yù)的情況下修改作業(yè)。而可靠性低的機器判斷則需要教師的介入。總之,人工智能教育評估相對傳統(tǒng)評估方法,能夠降低教師的低效重復(fù)勞動,提升教學效率。
三、心理物理學和差異科學
教育評價從根本上來說是一種確定差異的方式。質(zhì)量即等級,是一個絕對的衡量標準,而差異是一個相對的衡量標準。通過確定學生作業(yè)之間的差異,就有可能得出一個評分的標準:如果已知所有作業(yè)之間的差異,則可以在差異最大和差異最小之間,按照順序進行排列。在19世紀,統(tǒng)計學和心理學的研究提出一個觀點,即人類的區(qū)分能力可以用“最小差異”的基本極限來衡量。“心理物理學”這一概念最初由韋伯(Weber)提出[10],而后由費希納(Fechner)完善,后來成為一門可以從統(tǒng)計學上檢驗不同類型刺激(如不同類型的學生作業(yè))心理效應(yīng)的學科。
隨后,瑟斯通(Thurstone)提出了利用最小差異確定元素排名的想法[11]。瑟斯通對費希納的工作進行了擴展,研究了人們感知一組物品之間差異的方式。瑟斯通認為,對一對物品之間差異的識別,與對每個物品的假定絕對判斷之間的關(guān)系有關(guān)(瑟斯通稱之為“區(qū)別分散”)。所以如果給人們看兩件作品,并要求他們對每件作品給出相應(yīng)的判斷,所有人的判斷都會形成一個高斯分布,因此差異就是兩個高斯分布之間的差異。這就是瑟斯通的比較判斷法則,一種對數(shù)據(jù)(如學生作業(yè))進行排序的方法,即在多個標記之間進行多個成對比較[12] 。
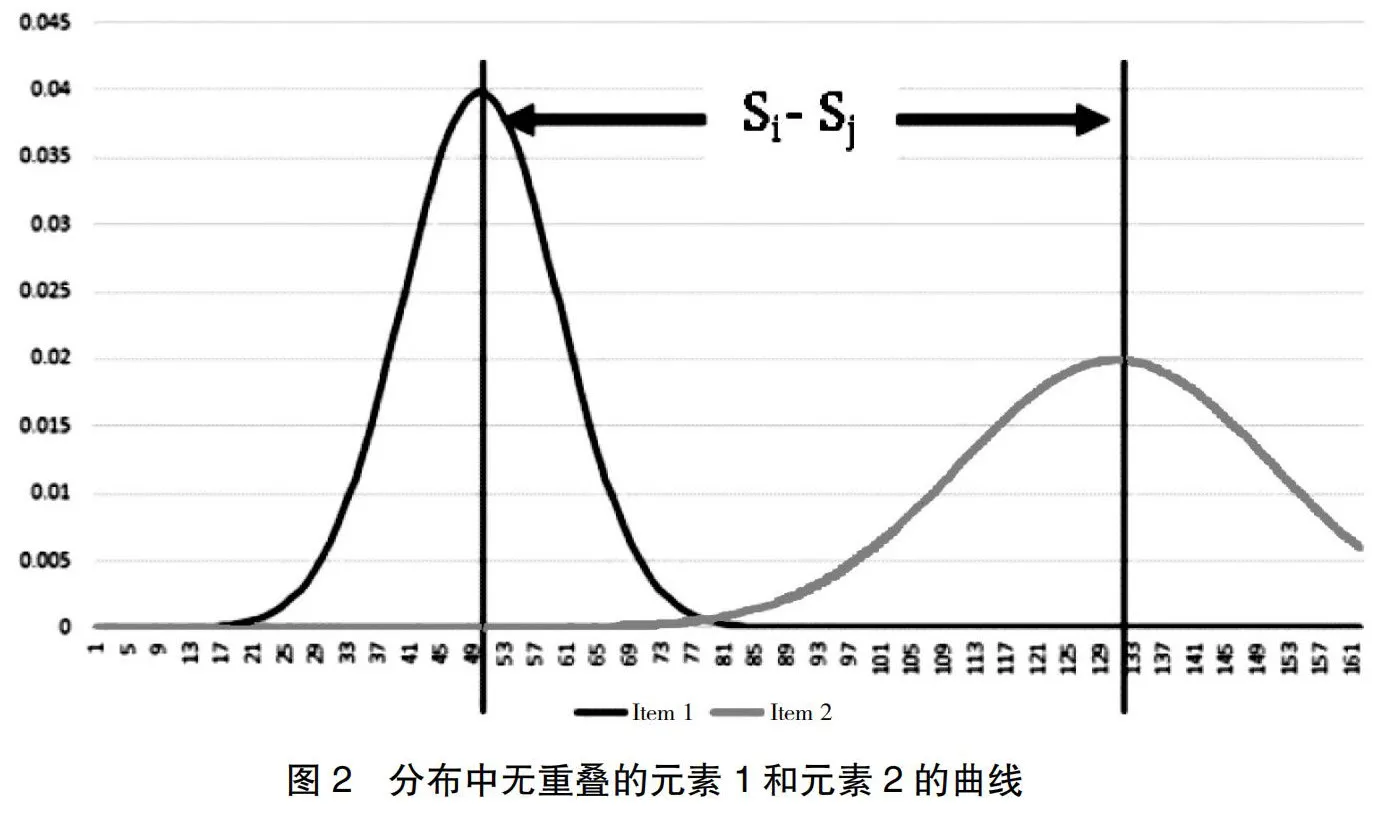
瑟斯通法則[11]啟發(fā)了許多統(tǒng)計方法。例如,利用層次分析法(Analytic Hierarchy Process, AHP)的相關(guān)技術(shù),在教育[12]和管理決策[13]中進行判斷。在最基本的層面上,適應(yīng)性比較評判(Adaptive Comparative Judgement, ACJ)方法向人類展示一個域中一個對象的兩個示例,并詢問“哪個更好”。計算機記錄判斷結(jié)果,更新數(shù)據(jù)項的內(nèi)部排名表,并向用戶提供一對新的數(shù)據(jù)項。在多次迭代中使用此技術(shù),可以根據(jù)簡單的標準(如更好、更差)建立數(shù)據(jù)項的排名。瑟斯通提出了一個公式,將元素對之間的比較次數(shù),與該元素可能被不同評估者判斷正確的可能性概率聯(lián)系起來。對于任何一個數(shù)據(jù)元素,瑟斯通認為,對該元素的判斷存在一個正態(tài)統(tǒng)計分布,正態(tài)曲線的峰值代表正確的判斷。給定兩個元素,就有兩個相關(guān)的正態(tài)分布。這兩個元素之間比較判斷的相對距離可以用圖1表示。其中,比較判斷之間的距離Si-Sj與比較次數(shù)Sigt;Sj、Si和Sj絕對判斷的分布,以及減去兩個分布之間的重疊部分有關(guān)。
分布之間的重疊以及分布的相對大小,都是Sj大于Si可能性的一個因素。如圖2所示,隨著重疊的減少,Si與Sj混淆的可能性就越小。同樣,分布中的標準差越小,正態(tài)分布曲線越尖銳,就越有可能做出正確的比較選擇。
更準確地說,所做的比較選擇、相對判斷的標準偏差、判斷之間的重疊、所做選擇的數(shù)量之間的關(guān)系可以用以下公式表示:
Si-Sj=xij(1)
其中,Si-Sj表示兩個數(shù)據(jù)元素之間的相對判斷,xij表示Si大于Sj的比較次數(shù),σ2
i+σ2
j-2rijσiσj表示根據(jù)方差(σ2)和重疊對兩條正態(tài)曲線進行的計算。
在沒有重疊的情況下,圖2中的情況意味著2rijσiσj這個項消失了,因此公式變得簡單:
Si-Sj=xij或者xij=(2)
這意味著,在該種情況下,決定一個排名所需的比較次數(shù)與排名中的相對距離,以及每個元素方差之和的平方根之間的比率成正比。
通過使用這個公式,計算機可以將判斷任務(wù)分配給多位評估者,確保在數(shù)據(jù)集的不同元素之間進行有效的判斷分配。由于某些“比較”相對容易(通常,在有序列表中,相距較遠的比相距較近的“比較”更容易),不同能力的人可以參與這個過程,而通過這些能力記錄告知機器,之后按照能力分配比較元素。
上述方法有很多優(yōu)點。在教育評價中,該技術(shù)已經(jīng)開始得到應(yīng)用和探索,如比較傳統(tǒng)評估中的“高風險”判斷、適應(yīng)性比較評判的“低風險”比較。在高風險的判斷中,甚至有些專家意見也是不一致的:心理物理因素在絕對判斷中會產(chǎn)生不一致。這意味著,在醫(yī)學等關(guān)鍵應(yīng)用中,判斷往往需要提交仲裁。在適應(yīng)性比較評判中,“低風險”也意味著,可能導(dǎo)致錯誤的心理物理因素在減少:“低風險”意味著更低的皮質(zhì)醇(壓力)。也就是說,通過廣泛的兩兩比較,判斷可以形成一個準確的排名,沒有高壓力參與絕對判斷。以成對比較進行排序的一個主要缺點是,在大型數(shù)據(jù)集上,包含很多元素的列表需要許多人進行大量的比較。出現(xiàn)這個問題的部分原因是,對于任何要評分的新元素,人們無法確切地知道它在一開始的排名中所處的位置,只能通過適應(yīng)性比較評判算法的迭代來建立,并且可能需要非常多的迭代,才能確定項目適合的排序位置。顯然,在排名中對某個元素的位置,進行初始“第一次猜測”的技術(shù)是非常可取的。筆者認為,此時機器學習在排名中作出的批判性判斷非常重要。此外,機器學習識別排名關(guān)鍵部分的能力,是一種識別特定元素存在不確定性的方式,也是一種協(xié)調(diào)人類關(guān)于排名過程對話的方式。
機器學習的使用與典型的自動評分方法有很大不同。自動評分會對一件作品進行判斷并提供“答案”。相反地,結(jié)合了機器學習的適應(yīng)性比較評判方法,可以有效地處理爭議較小的“簡單”比較,從而將人的精力集中于處理難度更大的比較。換句話說,機器學習方法提供了一種協(xié)調(diào)人的活動和機器活動的新方法,可以直接協(xié)助人對困難的比較做出判斷。
四、似然的組織排序
從樣本均值和標準差能夠很容易地得到高斯分布總體情況,因此,利用高斯分布進行統(tǒng)計推斷會更便捷。例如,讓一個群體對A和B的大小進行判斷,如果這種判斷被視為機器學習的“訓練集”,該“訓練集”就存在對應(yīng)的高斯分布。機器學習的目標是,當遇到一個尚未出現(xiàn)過的元素,機器學習模型將其置于正態(tài)分布的什么位置(即預(yù)測新元素的值)。那么,如果簡化上述過程,預(yù)測新元素值準確的可能性(Likelihood)有多高。
舉例來說,如果人工智能被訓練用于比較成對的數(shù)據(jù),人工智能會對新數(shù)據(jù)進行多次預(yù)測后排序(Ranking),并生成“預(yù)測”的結(jié)果。那么,預(yù)測結(jié)果正確的可能性有多高?而從比較中得到的任意排序,都需要通過一定閾值。例如,一篇論文被判斷為“通過”或“未通過”,僅使用了最為簡單的規(guī)則:距離閾值越近,作出正確判斷的可靠性越低;距離閾值越遠,作出正確判斷的可能性越高。
這種概率能夠采用貝葉斯統(tǒng)計方法進行計算。貝葉斯方法類似瑟斯通比較判斷法則,它使機器學習能夠預(yù)測判斷結(jié)果落入特定類別的可能性。取似然值的自然對數(shù)后,對其進行加減運算,并采用比率進行整體評估,該比率一端是閾值,另一端是事件。例如,一部分屬于一個類別,如“通過”;而另一部分屬于另一個類別,如“未通過”。這些似然值對應(yīng)于高斯分布的重疊。例如,任何一個遠離閾值的結(jié)果,都會有一個很大的正值或負值。在高斯分布的重疊中,似然值將會是一個較小的正值或負值。
較小的似然值意味著機器學習得到的結(jié)果不夠可靠,而較高似然值則表示結(jié)果高度可靠。因此,較小的似然值需要人的介入判斷,而當似然值較大時,人的判斷和機器判斷的結(jié)論很可能一致。除了能夠更有效地利用人的干預(yù),貝葉斯方法同樣提供了基于訓練集評估機器學習預(yù)測準確性的方式。原因在于,較高正似然值會將結(jié)果至于排序的頂端,而較低似然值會將其置于排序的底端,不同結(jié)果根據(jù)似然值的大小排序,排序位置能夠與訓練集數(shù)據(jù)已知的位置進行比較。通過使用該技術(shù)可以發(fā)現(xiàn),機器學習犯錯的大多數(shù)情況都是在閾值附近。
五、 對話教育、人工智能和人類
教育人工智能面臨的眾多挑戰(zhàn)之一,是人工智能在群體學習中的角色,特別是“學習共同體的學習”[14][15]。基于機器學習的評價和機器學習本身帶來一個更基本的問題:“共同”的真正含義是什么?物理空間中的“面對面”學習很好想象,但人們能夠看到的“共同”還包括:社交媒體、線上游戲、作者已經(jīng)逝世很久的書籍、藝術(shù)、戲劇或音樂。
“共同”的本質(zhì)和已有對其的理解中,對話的角色正在受到機器學習的挑戰(zhàn)。例如,機器學習擴散模型利用文字提示,產(chǎn)生原創(chuàng)藝術(shù)作品的能力,已經(jīng)引發(fā)藝術(shù)家在網(wǎng)絡(luò)上的廣泛討論。這些藝術(shù)家似乎既與人工智能對話,產(chǎn)出藝術(shù)作品,又與他們的線上同僚進行對話。同大多數(shù)機器學習模型一樣,擴散模型“吸收”了互聯(lián)網(wǎng)中的百萬幅圖片,分析它們的模式,進而能夠模仿繪制出具有相似審美特征的作品。機器學習了藝術(shù)家原創(chuàng)作品的模式,并能夠數(shù)字化地、更大范圍內(nèi)產(chǎn)出作品。
如果將這樣的對話視為藝術(shù)家之間的交流,就會發(fā)現(xiàn),機器學習正在揭示更深層的東西,即人與人之間有意義的對話有一定模式,并且這種模式能夠被分析,機器學習模型能夠表征這種模式并且復(fù)制它。當人們與人工智能互動,就是在參與(或者說在強化)這種模式。逐步揭示過去30年網(wǎng)絡(luò)中人們的對話模式,可以發(fā)現(xiàn),其創(chuàng)造力和原創(chuàng)性是令人震驚的。
從生態(tài)效度的觀點來看對話,同樣對評估有所啟示。如果將評價過程按照貝葉斯方法的方式理解,專家觀點是一個正態(tài)分布,而評價過程則是將學生理解與專家觀點進行擬合。如果通過編碼專家對話,人工智能能夠識別專業(yè)性判斷的模式,那么,學生參與人工智能評價就是與機器進行對話?人類專家或教師在其中的角色又應(yīng)該是怎樣的?
上述問題恰好集中在人類通過協(xié)商解決不確定性問題的能力。對思想、觀點和情緒的生理反應(yīng)是機器無法擁有的能力。親密感、信任等能夠觸及人類思想和對話中的深度不確定性,然而機器目前還不具備這樣的能力。而深度理解這些可能需要更深層的微觀進化(Cellular Evolution),并結(jié)合表觀遺傳學、量子力學等學科的發(fā)展。技術(shù)的最大貢獻,可能是解鎖人類生物技術(shù)的潛能,用于深入研究現(xiàn)有的各種科學謎團。
六、結(jié)論
將當前人工智能在醫(yī)學診斷等領(lǐng)域的成功應(yīng)用,拓展到教育評價中,是未來教育改革的必然趨勢,將帶來人(教師和學生)與機器之間的密切合作。其中,信任是這個過程中最重要的因素,要增強人們對人工智能教育評價的信任,就需對機器學習過程進行更全面的檢測,并用更豐富的信息來判斷特定結(jié)果的準確度。而準確度可能是未來教育評價技術(shù)中最為重要一個部分,其能夠引發(fā)新的學校教育實踐,并更有效地利用教師專業(yè)知識,同時也能促進自主學習、師生對話和互動。
自動化教育評價被視為人工智能預(yù)測在現(xiàn)實社會中應(yīng)用的一個例子。長期以來,這種預(yù)測方法既吸引了哲學家和社會學家的興趣,也讓他們感到擔憂。但是,機器學習不會認為世界以一種確定的方式運行。貝葉斯統(tǒng)計方法專注于預(yù)測結(jié)果是否準確,表明更深層的應(yīng)用是組織重建,而不是僅僅將事物進行分類。無論是教育、政治、醫(yī)療,還是法律領(lǐng)域,人類面臨的問題都是一樣的,即如何最有效地利用各種技術(shù)提高自身的生存能力,這也是每個教師和學生都必須面對的重要問題。
參考文獻:
[1]SPIEGELHALTER D J, BEST N G, CARLIN B P, et al. Bayesian measures of model complexity and fit[J]. Journal of the royal statistical society: Series b (statistical methodology), 2002,64:583-639.
[2]JACKSON D, USHER M. Grading student programs using ASSYST[C]. Grading student programs using ASSYST[C]. Proceedings of the 28th SIGCSE Technical Symposium on Computer Science Education, 1997, San Jose, California, USA, February 27-March 1, 1997.
[3]NAZARETSKY T, CUKUROVA M, ARIELY M, et al. Teachers’ trust in AI-powered educational technology and a professional development program to improve it[J]. British journal of educational technology, 2022(1):1-18.
[4]VANLEHN K. The relative effectiveness of human tutoring, intelligent tutoring systems, and other tutoring systems[J]. Educational psychologist, 2011(46):197-221.
[5]SMITH H. Algorithmic bias: should students pay the price?[J]. AI amp; society, 2020(35):1077-1078.
[6]KIZILCEC R F. How much Information? effects of transparency on trust in an algorithmic interface[C]. New York: In Proceedings of the 2016 CHI conference on human factors in computing systems, 2016.
[7]KELLY A. A tale of two algorithms: the appeal and repeal of calculated grades systems in england and ireland in 2020[J]. British Educational Research Journal, 2021(47):725-741.
[8]OVETZ R. The algorithmic university: on-line education, learning management systems, and the struggle over academic labor[J]. Critical Sociology, 2021(47):1065-1084.
[9]Kaggle: Your Home for Data Science[DB/OL].[2022-5-30]. https://www.kaggle.com/.
[10]HELEN E R, DAVID J M, ROSS H E, et al. Weber on the tactile senses[C]. London: Psychology Press, 2018.
[11]THURSTONE L L. The method of paired comparisons for social values[J]. The Journal of Abnormal and Social Psychology, 1927(21):384.
[12]POLLITT A. The method of adaptive comparative judgement[J]. Assessment in Education: principles, policy amp; practice, 2012(19):281-300.
[13]SAATY T L. Decision making with the analytic hierarchy process[J]. International Iournal of Services Sciences, 2008(1):83-98.
[14]WEGERIF R. Dialogic education and technology: Expanding the space of learning[M]. New York: Springer Science amp; Business Media, 2007.
[15]YANG Y, WEGERIF R, DRAGON T, et al. Learning how to learn together(L2L2) : developing tools to support an essential complex competence for the Internet Age[J]. International Society of the Learning Sciences, 2013(2):193-196.
作者簡介:
馬克·約翰遜(Mark Johnson), 丹麥哥本哈根大學教育數(shù)字化高級研究員,利物浦大學視力與視覺科學系特聘教授,主要研究方向為機器學習在醫(yī)療、教育中的創(chuàng)新實踐與應(yīng)用等,郵箱:mj@ind.ku.dk;
金俞, 北京師范大學未來教育學院講師,共同第一作者、同等貢獻者,主要研究方向為統(tǒng)計分析、學習分析,郵箱:jinyu@bnu.edu.cn;
崔新,北京師范大學未來教育學院講師,主要研究方向為語言和閱讀發(fā)展的認知神經(jīng)機制,郵箱:xincui@bnu.edu.cn;
孫波,北京師范大學珠海校區(qū)副教務(wù)長、未來教育學院副院長、人工智能與未來網(wǎng)絡(luò)研究院教授,通訊作者,主要研究方向為機器學習、情感計算和計算機教育應(yīng)用,郵箱:tosunbo@bnu.edu.cn。
Artificial Intelligence and the Future of Education Assessment
Mark JOHNSON1,2?, Yu JIN1?, Xin CUI1, Bo SUN1*
(1.College of Education for the Future, Beijing Normal University, Zhuhai Guangdong 519087;2.Department of Science Education, University of Copenhagen, Copenhagen 1165, Denmark)
Abstract: One of the big challenges in using Artificial Intelligence (AI) for education assessment system is how to capture and represent the deep thoughts developed through communication between people engaged in learning. This requires a deep understanding of artificial intelligence, statistical analysis, and rich dynamic dialogue data. The effectiveness of AI judgement- particularly in medical applications-is typically measured as percentages of “sensitivity” and “specificity”. While these statistics are helpful in understanding the overall picture, they ignore the fact that machines have a high degree of certainty about decisions far from the threshold, but less certainty about decisions near the threshold. Furthermore, no amount of training data for machine learning can eliminate the uncertainty of judgment. Therefore, in educational applications, it is necessary to consider how humans and machines work together to improve the efficiency of future education assessments and create more space for dialogue in education. This paper focuses on the possibility of machine learning and Bayesian statistical methods to change the education assessment by the development of AI. It emphasizes that one of the key issues of future education assessment is to clarify that people and machines are good at different problem areas. AI can provide automatic, efficient, and accurate feedback to help students achieve self-directed learning and self-assessment, while the decision-making that cannot be determined by machines, teachers’ participation and intervention are required. Based on this, it proposed that the currently successful application of artificial intelligence in medical diagnosis and other fields to be extended to assessment in education. It is inevitable that future education reform will need to bring close cooperation between people (teachers and students) and machines. Among them, trust is the most important factor in this process. To enhance trust in AI education assessment, it is necessary to conduct more comprehensive inspections for the machine learning process and use more abundant information to assess the accuracy of specific results. One of the most important aspects of future education assessment technology is that it can lead to innovative teaching and learning practices, make more effective use of teachers’ expertise, and also promote self-regulated learning and the dialogue and interaction among teachers and students.
Keywords: Artificial intelligence; Statistics; Assessment; Human-machine collaboration
編輯:王曉明" " 校對:李曉萍
