大數據下基于決策樹算法的企業客戶關系管理研究
2022-04-19 14:13:26賴錦柏
經濟研究導刊 2022年9期
賴錦柏


摘 要:1980年,在阿爾文·托夫勒的著作《第三次浪潮》中作出了如下的預測:未來的世界是被數據信息包圍的世界。他將大數據形容成“第三次浪潮的華彩樂章”,全新的、將永久改變人類思路、生存方式的革新將圍繞數據資源展開。正如其所言,時至今日大數據的時代已經到來,伴隨著大數據一起到來的是機器學習、數據挖掘和商業智能在各個領域的運用。同時,大數據時代的社會輿情又與傳統的社會輿論有所區別。在這一背景下,當企業面臨各類客戶時,如何進行客戶關系管理成了當下的重點研究課題。在數據挖掘的各類算法中,決策樹算法是比較優秀的一種,通過決策樹算法,能夠幫助企業更快地定位相關客戶群體,從而進行更優決策。
關鍵詞:大數據;數據挖掘;決策樹算法;客戶關系管理
中圖分類號:F272? ? ? ? 文獻標志碼:A? ? ? 文章編號:1673-291X(2022)09-0008-03
一、研究綜述
(一)大數據的定義
1980年,阿爾文·托夫勒在《第三次浪潮》一書里預測未來的生活是被數據信息包圍著的全球,將大數據形容成“第三次浪潮的華彩協奏曲”,人們將緊緊圍繞公共數據進行新一輪的技術革命。而隨著大數據應用的發展趨勢,大數據的內涵又有新的論述。Wiki百科對大數據的表述就是指所涉及的數據規模極大到沒法根據現階段流行工具軟件,在有效時間內采擷、管理方法、解決和梳理有關商業資訊,進而合理地協助公司完成運營管理決策提升的總體目標。海外學者Tien James認為大數據便是一個專業名詞,適用于數據集,其規模在現階段除能用專用工具計量檢定的能力以外,對數據信息開展搜集、瀏覽、剖析或程序流程運用都可以調控在有效的時間段內。
(二)大數據時代輿論的特征
隨著大數據時代的到來而產生的網絡輿情與傳統的輿情有所不同,但又有著一些相似之處,網絡輿情的形成大致有“沉默的螺旋”“蝴蝶效應”“滾雪球”“群體極化”等幾種傳播學經典理論。根據“沉默螺旋”理論,大多數人都是受大眾心理的驅使,盡量避免孤立自己獨特的觀點來面對網絡主流的、即使是未必正確的輿論。“蝴蝶效應”的理論則是傳統蝴蝶效應的延伸,認為網絡上一些微不足道的輿情都有可能發展成公眾關注的熱點與焦點。“滾雪球”理論指出,根據網民的“好奇心”和“關注”,一些問題會從地區問題轉變為產業問題,甚至向國際問題轉變。群體極化理論的觀點是網民在遇到話題時會代入自身的主觀感情從而對問題的看法有所偏頗,而在其他群體成員的認同下,導致了其輿論向極端發展,進而構成了輿論的非理性,最終影響了整個群體的輿論。
(三)數據挖掘的內涵
數據挖掘也叫作資料勘探,其內涵是從極其龐雜的數據中將埋藏在內的具有某些特定關系的相關內容進行自動化檢索的進程。數據挖掘是以一個全新的角度為立足點,將各種信息技術性開展合理結合,同時結合發展趨勢而成的能夠對大量的業務流程數據信息開展較為系統的剖析和篩選的合理專用工具,主要是協助企業從不斷更替并累積起來的數據信息中挑選對企業本身有效的信息,數據挖掘將企業制定的業務流程總體目標為根據,對全部商業服務大環境中的海量信息開展數據分析,從而篩選出對本身有使用價值的數據信息,為企業能夠更好地開展商業服務、管理決策提出合理的根據。
運用數據挖掘對海量數據信息開展挖掘的分析方法有很多,主要是歸類、多元回歸分析、聚類算法、關聯規則、特征分析、轉變和誤差值剖析、Web網頁挖掘等,不同的分析方法可以從多角度對數據信息開展挖掘,使結果更加精準。
(四)決策樹算法
決策樹算法是一種依據已知的概率,即樣品數據具有不同的特性,形成可以用于分析對象的一種算法。數據分類算法家族中,決策樹算法都是用于確定決策的經典算法。首先,所有數據特性都被視為包含所有特性的樹木節點。統計的如果是一個橫向特性,關于分點數據的信息被記錄為純度的基礎,以便將節點劃分。第二,比較已登記數據的特點,確定最佳特點,并找出將數據集從樣本中隔開的分界點。最后,決策樹按照這些規則建立。
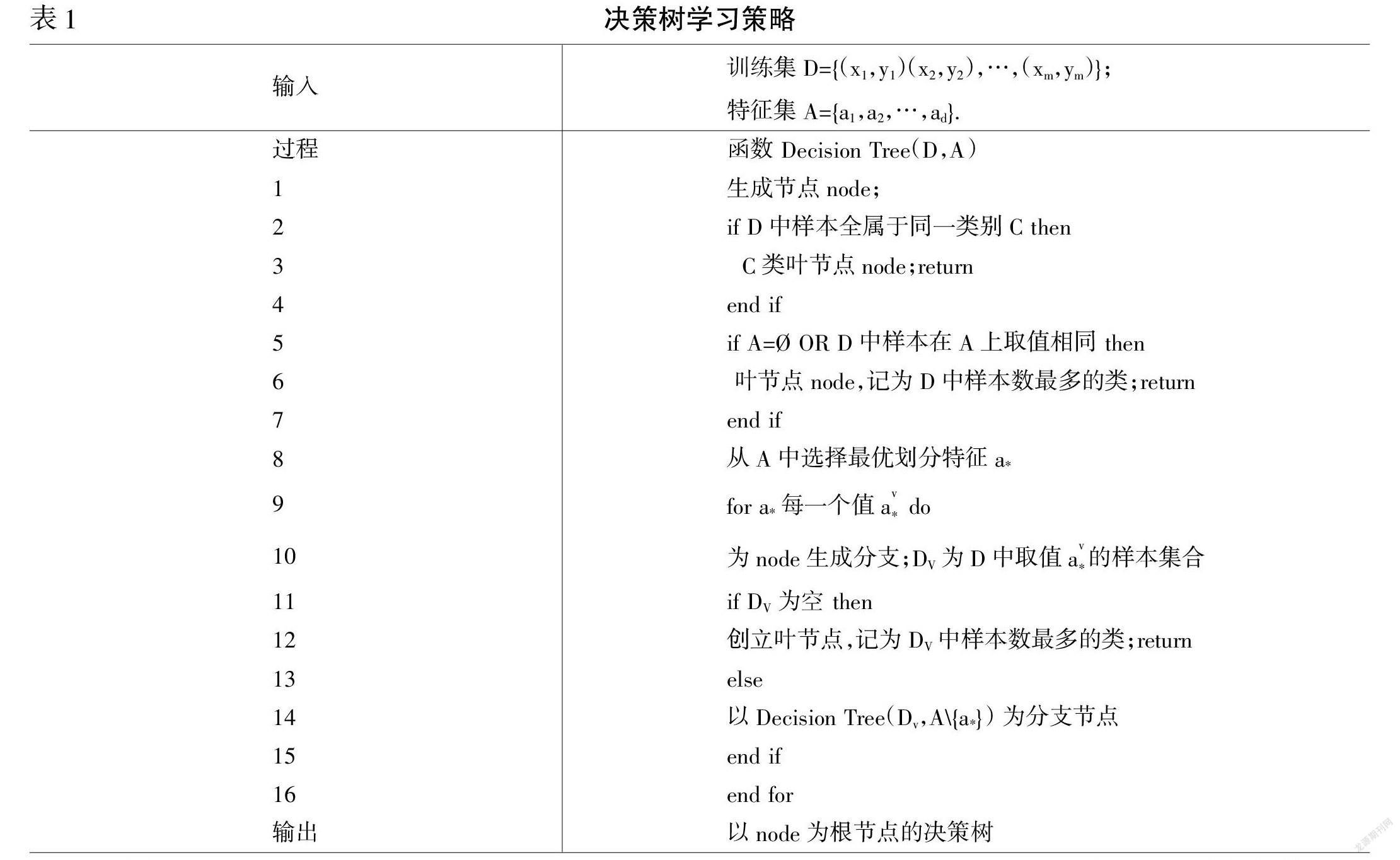
決策樹算法的基本思想是利用屬性選擇度量(ASM)來確保屬性是決策節點,并將數據集分割成更小的子集,使數據集被分割成更小的子集,思想是選擇最好的屬性來劃分。通過遞歸,對每一個子集重復這個過程,就滿足了其中一個條件,可以開始構建樹形結構,直到用來劃分數據的屬性選擇度量的最佳分割標準集合,它是一種啟發式算法,也稱為分割規則。這是因為它有助于確定給定節點上元組的斷點,其過程如圖1所示。
用決策樹學習的核心問題之一是特征的區分。經典的三種情況可以得出三種有代表性的決策樹算法。
同時,決策樹算法可以較好地應對過擬合的風險,可通過“剪枝”來一定程度避免因決策分支過多,以至于把訓練集自身的一些特點當作所有數據都具有的一般性質而導致的過擬合,進而提高決策樹的泛化能力,而“剪枝”又可以分為先剪枝和后剪枝兩種方案。
二、模型構建
(一)指標選擇
以消費者為對象,對其采用問卷調查的形式,針對影響消費者對品牌好感度的因素分析,選定的評價指標應力求全面反映消費者對品牌的好感。對品牌評價進行決策樹分析,最終將指標分為:K1,即商品價格;K2,即商品使用壽命;K3,即商品售后;K4,即網絡上該商品的普遍評價;K5,即對該商品的感受。并對10種商品進行商品體驗。其中將K1分為5級:A為0~100元;B為100~300元;C為300~500元;D為500~1 000元;E為1 000元以上;將其他四個評價等級也分為5級,分別為:A為優秀(90—100);B為良好(80—90);C為中等(70—80);D為合格(60—70);E為不合格(<60);獲得10種商品評價如表4所示。
(二)模型構建
通過表4所示的評價結果,利用ID3算法構成決策樹,部分程序代碼如下:
Print(Start training)
Tree=train(train_features,train_labels,list(range(feature_len)))
Time_3=time.time()
Print(training cost %f second'%(time_3—time_2))
Print(Start predicting)
Tests_predict=predicting(test_features,tree)time_4= time.time()
Print(predicting cost %f second'%(time_4—time_ 3))
根據表4中獲得的質量評價結果和建立的決策樹,確定樣本期望信息熵為:
I(S)=-log2()-log2()-log2()=1.25775996
對于商品價格K1,存在有Values(K1)=(A,B,C),SA={6,8},|SA|=2,SB={1,2,3,5,9,10},|SB|=6,SC={4,7},|SC|=2,計算獲得商品價格K1條件期望信息,可得到E(K1)=0.758。
比較樣本的信息熵有:Gain(K1)=I(S)-E(K1)=0.503,同理可得到其他屬性的信息熵分別為Gain(K2)=0.607,Gain(K3)=0.476,Gain(K4)=0.432。
比較樣本的信息熵有:Gain(K2)>Gain(K1)>Gain(K3)>Gain(K4)。可以看出,樣本中商品使用壽命屬性信息增益具有做大值,因此選擇教學內容K2作為根節點測試屬性,在每個值根節點創建分支,并基于ID3從根節點進行進一步細分。若根節點到當前節點路徑包含了所有樣本的全部屬性,或屬于同一訓練樣本層,則算法完成,根據教學內容K2測試屬性建立的決策樹形圖如圖1所示。
(三)決策結果
根據已建立的決策樹可以確定知識的表述形式為:
if(K2=A),then K5=優秀;
If(K2=B),then K5=良好;
根據分析可知,商品使用壽命,即耐用程度K2在商品評價中占主導地位,若商品使用壽命為優秀時,獲得的商品評價為優秀;若商品使用壽命為良好,則商品評價為良好。因此對商品評價中,商品的質量應作為主要的考慮因素,同時兼顧售后等其他樣本。
結語
大數據時代對企業的生存帶來了新機遇,也帶來了很多的挑戰,如何迎合客戶喜好、如何進行更好的售后服務等等,都是企業要考慮的問題,但企業應將顧客對商品耐用程度的需求放在首位,應從如何提高商品壽命,降低次品率考慮。
數據挖掘對于現代企業而言是一種可以用于分類客戶、進行產品定位等功能的重要輔助工具,其應用領域仍然有很大的開發空間。因此,研究人員應不斷深入挖掘數據挖掘這一實用工具的應用潛力。
參考文獻:
[1]? 毛國軍,段立娟,王實.數據挖掘原理與算法[M].北京:清華大學出版社,2005.
[2]? 王玨,周志華,周傲英.機器學習及其應用[M].北京:清華大學出版社,2006.
[3]? 閆友彪,陳元琰.機器學習的主要策略綜述[J].計算機應用研究,2004,(7):4-10.
[4]? 王愛平,張功營,劉方.EM算法研究與應用[J].計算機技術與發展,2009,(9):108-110.
[5]? 孫志軍,薛磊,許陽明,等.深度學習研究綜述[J].計算機應用研究,2012,(8):2806-2810.
[6]? 李旭然,丁曉紅.機器學習的五大類別及其主要算法綜述[J].軟件導刊,2019,(7):4-9.
[7]? 吳玉軒.機器學習算法在金融市場風險預測中的應用[J].信息系統工程,2019,(2).
[8]? 李赟妮.神經網絡模型在銀行互聯網金融反欺詐中的應用探索[J].金融科技時代,2018,(8):24-28.
[9]? 王雅靜.銀行個人客戶信用評分模型研究——基于決策樹算法[J].現代商貿工業,2015,(19):6465.
[10]? 嚴蔚敏,李冬梅,吳偉民.數據結構:C語言版[M].北京:人民郵電出版社,2011.
[11]? West D.Neural network credit scoring models[J].Computers & Operations Research,2000,(11-12): 1131-1152.
[12]? Domingosp.The master algorithm:how the quest for the ultimate? learning machine will remake our world[M].England:Reed Business Information Ltd.,2015.
[13]? Sun H.N.,HU X.G.Attribute Selection for Decision Tree Learning with Class Constraint[J].Chemometrics and Intelligent Laboratory Systems,2017,(163):16-23.
[14]? KE G.L.,Meng Q.,Finley T.,et al.Light GBM: A Highly Efficient Gradient Boosting Decision Tree//Guyon I,Luxburg U V,Bengio S,et al.,eds.Advances in Neural Information Processing Systems 30.Cambridge,USA:The MIT Press,2017:3149-3157.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
新聞世界(2016年10期)2016-10-11 20:13:53
科技視界(2016年20期)2016-09-29 10:53:22
中國記者(2016年6期)2016-08-26 12:36:20
信息通信技術(2015年6期)2015-12-26 01:16:46
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
