基于多模態(tài)生成模型的半監(jiān)督學(xué)習(xí)
2022-04-21 03:03:08陳亞瑞張芝慧楊劍寧王浩楠
天津科技大學(xué)學(xué)報(bào) 2022年2期
陳亞瑞,張芝慧,楊劍寧,王浩楠
(天津科技大學(xué)人工智能學(xué)院,天津300457)
在過(guò)去很長(zhǎng)時(shí)間里,研究者的注意力主要集中在監(jiān)督學(xué)習(xí)的問(wèn)題上,換句話說(shuō),研究者主要基于標(biāo)記數(shù)據(jù)訓(xùn)練分類(lèi)器.隨著大數(shù)據(jù)時(shí)代的到來(lái),數(shù)據(jù)呈現(xiàn)爆炸式增長(zhǎng),從海量數(shù)據(jù)中獲得每個(gè)數(shù)據(jù)的標(biāo)簽是比較困難的.“標(biāo)記數(shù)據(jù)少,而未標(biāo)記數(shù)據(jù)多”在大數(shù)據(jù)時(shí)代是越來(lái)越普遍的現(xiàn)象.
若利用監(jiān)督學(xué)習(xí)方法,僅使用已有的少量有標(biāo)記樣本,不僅模型的泛化能力較差,而且浪費(fèi)了大量未標(biāo)記樣本中的信息.半監(jiān)督學(xué)習(xí)是一種介于監(jiān)督學(xué)習(xí)和無(wú)監(jiān)督學(xué)習(xí)之間的機(jī)器學(xué)習(xí)方法[1].半監(jiān)督學(xué)習(xí)是充分利用樣本中“廉價(jià)”的未標(biāo)記樣本,讓學(xué)習(xí)器不依賴(lài)外界交互、自動(dòng)地利用未標(biāo)記樣本提升學(xué)習(xí)性能[2].
在各類(lèi)半監(jiān)督學(xué)習(xí)方法中,基于生成方法(generative method)的半監(jiān)督學(xué)習(xí)受到了研究者的極大關(guān)注[3].生成方法是基于生成模型(generative model)的一類(lèi)方法,該類(lèi)方法假設(shè)數(shù)據(jù)是由潛在的模型“生成”的.這個(gè)假設(shè)能通過(guò)潛在模型的參數(shù)將未標(biāo)記數(shù)據(jù)與學(xué)習(xí)目標(biāo)聯(lián)系起來(lái),其中未標(biāo)記數(shù)據(jù)的標(biāo)記可看作模型的缺失參數(shù).深度生成模型[4-5],如變分自編碼(variational auto-encoding,VAE)模型、生成對(duì)抗網(wǎng)絡(luò)(generative adversarial network,GAN)等,通過(guò)將生成模型與多層神經(jīng)網(wǎng)絡(luò)相結(jié)合提高模型的表示能力,同時(shí)實(shí)現(xiàn)對(duì)圖像的自動(dòng)生成,在圖像、視頻處理方面有著重要的應(yīng)用.
VAE是當(dāng)前機(jī)器學(xué)習(xí)領(lǐng)域經(jīng)典的深度生成模型之一,該模型于2013年由Kingma等[6]提出.該模型主要由推理模型和生成模型兩部分組成,推理模型的作用是通過(guò)變分推理模型將高維數(shù)據(jù)降到低維特征空間中,生成模型的作用是從低維特征中重構(gòu)出原始高維數(shù)據(jù).VAE可以對(duì)原數(shù)據(jù)進(jìn)行重構(gòu),同時(shí)可以利用其生成模型生成新的數(shù)據(jù)樣本,但該模型很難生成特定的圖像樣本.
Sohn等[7]在VAE模型基礎(chǔ)上提出了條件變分自編碼(conditional variational auto-encoding,CVAE)模型. 該模型是一種監(jiān)督學(xué)習(xí)方式,通過(guò)分別在VAE推理模型和生成模型的輸入變量中加入標(biāo)簽變量的方式,實(shí)現(xiàn)生成特定圖像.這種做法不僅豐富了特征空間的結(jié)構(gòu),而且還使得模型可以生成指定樣本.Kingma等[8]提出基于深度生成模型的半監(jiān)督學(xué)習(xí)模型(semi-supervised learning with deep generative models,SS-DGM).該模型將CVAE拓展到半監(jiān)督學(xué)習(xí)領(lǐng)域,訓(xùn)練過(guò)程中充分利用少量標(biāo)記樣本與大量無(wú)標(biāo)記樣本.該模型在處理標(biāo)記樣本時(shí),對(duì)于推理模型部分,以樣本與標(biāo)簽連接作為輸入,以連續(xù)隱向量作為輸出;對(duì)于生成模型部分,以隱變量和標(biāo)簽連接作為輸入,此時(shí)輸出為重構(gòu)樣本.該模型在處理無(wú)標(biāo)記樣本時(shí),將標(biāo)簽看作隱向量,對(duì)于推理模型部分,以樣本作為輸入,以連續(xù)隱變量和標(biāo)簽隱變量作為輸出;對(duì)于生成模型部分,以推理模型的輸出作為生成模型的輸入,此時(shí)輸出重構(gòu)樣本.
相比條件變分自編碼方法,本文提出一種基于多模態(tài)生成模型的半監(jiān)督學(xué)習(xí)(semi-supervised learning based on multimodal generating model,SS-MGM)算法.模型將樣本看作數(shù)據(jù)的一種模態(tài),將樣本和標(biāo)簽聯(lián)合在一起的形式稱(chēng)之為多模態(tài)信息,在生成模型中生成樣本及其標(biāo)簽.
對(duì)模態(tài)的理解不僅僅限于以上定義,在生活中,人類(lèi)無(wú)時(shí)無(wú)刻不在與各種信息互動(dòng),而每一種信息的來(lái)源或者形式都可以被稱(chēng)為一種模態(tài),也就是人們的感官即觸感、聽(tīng)覺(jué)、視覺(jué)和嗅覺(jué)都可以定義為模態(tài).而多模態(tài)是指對(duì)兩種或兩種以上感官的融合進(jìn)行信息處理[9].SS-MGM模型在處理標(biāo)記樣本時(shí),對(duì)于推理模型部分,以樣本和標(biāo)簽作為輸入,以連續(xù)隱變量作為輸出;對(duì)于生成模型部分,以上述連續(xù)隱變量作為輸入,同時(shí)輸出重構(gòu)樣本及重構(gòu)標(biāo)簽.SSMGM模型在處理無(wú)標(biāo)記樣本時(shí),對(duì)于推理模型部分,以樣本作為輸入,以連續(xù)隱變量和標(biāo)簽隱變量為輸出;對(duì)于生成模型部分,以隱變量作為輸入,輸出重構(gòu)樣本及重構(gòu)標(biāo)簽.SS-MGM模型不僅在推理模型可以得到標(biāo)簽,在生成模型也可以得到標(biāo)簽概率.最后在MNIST數(shù)據(jù)集和FASHION_MNIST數(shù)據(jù)集上通過(guò)對(duì)比實(shí)驗(yàn),驗(yàn)證SS-MGM模型有效提高了預(yù)測(cè)標(biāo)簽精度.
1 變分自編碼
變分自編碼(VAE)一經(jīng)問(wèn)世就備受人們的關(guān)注與討論,模型創(chuàng)新性地結(jié)合了變分生成模型和深度神經(jīng)網(wǎng)絡(luò),形成了深度生成式網(wǎng)絡(luò)結(jié)構(gòu)[6].模型用大量樣本對(duì)模型進(jìn)行訓(xùn)練,之后只需使用模型的生成器部分,可以自動(dòng)生成大量訓(xùn)練樣本.變分自編碼作為深度生成模型的典型代表之一,在圖像生成和數(shù)據(jù)生成等方面有著重大影響,具有重要的研究?jī)r(jià)值.
對(duì)于變分自編碼模型,令x表示觀測(cè)變量或樣本,z表示連續(xù)隱變量,p(x,z)表示模型的聯(lián)合概率分布.聯(lián)合概率分布可以表示為生成模型形式:其中p(z)是隱變量先驗(yàn)分布,是條件概率分布,θ是模型的參數(shù).生成過(guò)程的概率圖模型如圖1所示,圖中白色圓圈代表隱變量z,灰色圓圈代表觀測(cè)變量x,圓圈之間的黑色實(shí)線表示生成過(guò)程,箭頭代表生成方向.
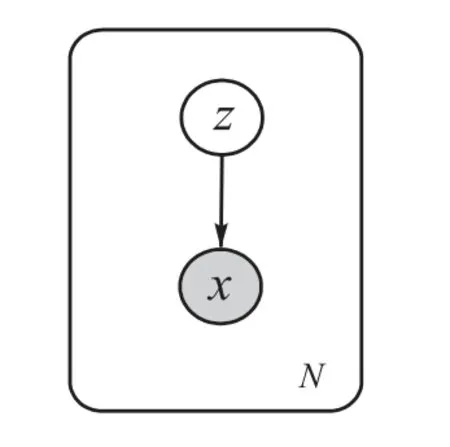
圖1 VAE概率圖模型Fig. 1 Probability graphical model of VAE
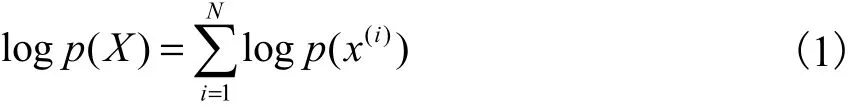

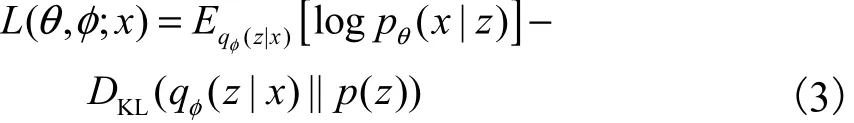
Kingma等[6]提出一種重參數(shù)化方法求解變分下界的優(yōu)化問(wèn)題.對(duì)于隱變量z通過(guò)引入標(biāo)準(zhǔn)多維高斯分布進(jìn)行重參數(shù)化,即
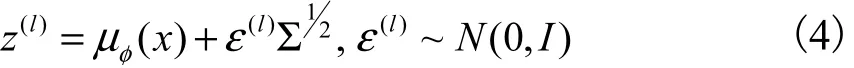
基于重參數(shù)化的變分下界的表示形式為
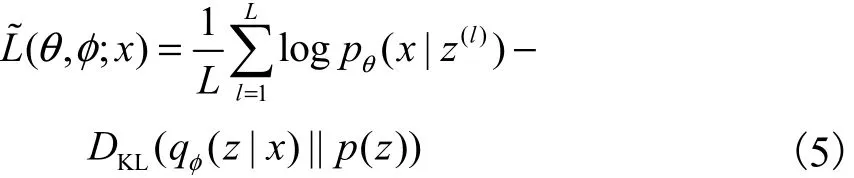
最后選用隨機(jī)梯度下降方法[11]對(duì)模型的參數(shù)進(jìn)行優(yōu)化更新.
2 條件變分自編碼
VAE是一種無(wú)監(jiān)督學(xué)習(xí)方法,無(wú)法生成特定類(lèi)別的數(shù)據(jù),基于這個(gè)研究需求,Sohn等[7]提出條件變分自編碼(CVAE),該模型在VAE[6]的基礎(chǔ)上對(duì)推理過(guò)程和生成過(guò)程都加入標(biāo)簽變量y.CVAE包含3種變量,為觀測(cè)變量x、連續(xù)隱變量z和離散類(lèi)變量y,聯(lián)合概率分布為
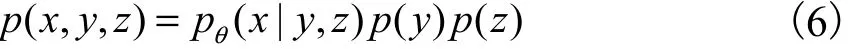
其中:p(z)為隱變量的先驗(yàn)分布,p(y)為標(biāo)簽變量先驗(yàn)分布, pθ( x|y,z)為條件概率分布,θ為模型參數(shù).生成過(guò)程的概率圖模型如圖2所示.
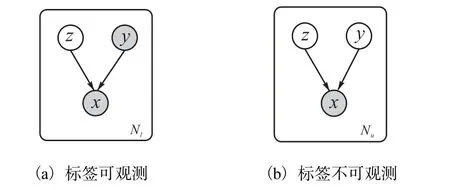
圖2 CVAE概率圖模型Fig. 2 CVAE probability graph model
與VAE原理類(lèi)似,CVAE通過(guò)最大化變分下界實(shí)現(xiàn)最大化對(duì)數(shù)邊際似然.在標(biāo)簽可觀測(cè)的情況下,引入變分推理模型,模型的變分下界為
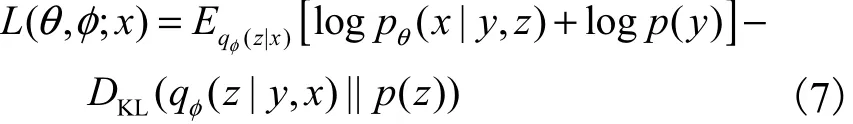
模型參數(shù){θ,}φ的優(yōu)化同樣使用重參數(shù)化技巧[6],即
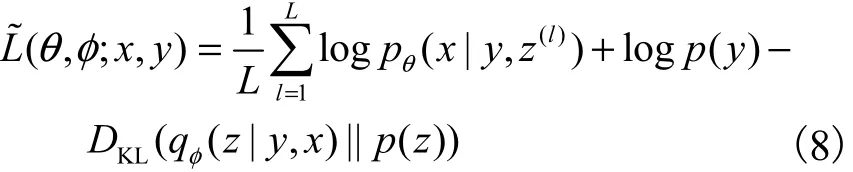
在標(biāo)簽不可觀測(cè)的情況下,y視為隱變量,將變分推理模型分解為得到變分下界為
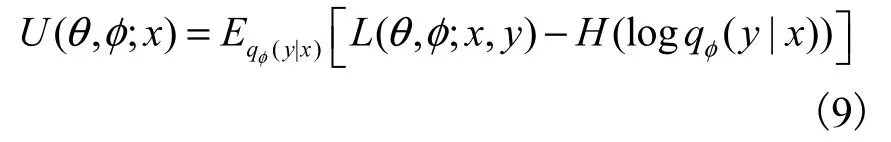
重參數(shù)后的變分下界為
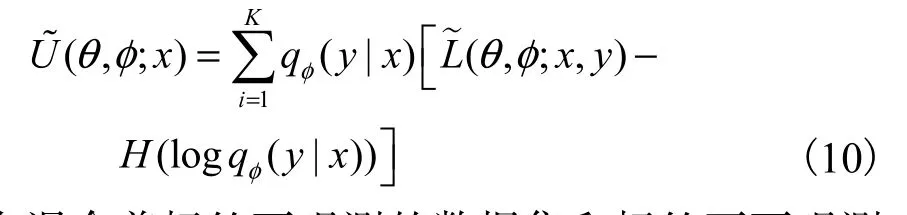
在混合著標(biāo)簽可觀測(cè)的數(shù)據(jù)集和標(biāo)簽不可觀測(cè)的數(shù)據(jù)集中,由于變分推理模型qφ( y|x)只在標(biāo)簽不可觀測(cè)的數(shù)據(jù)集上訓(xùn)練,所以在最終優(yōu)化目標(biāo)中添加交叉熵?fù)p失.此時(shí)CVAE的變分下界為
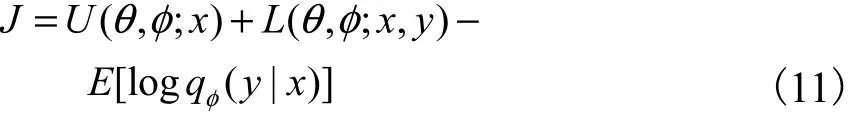
最終通過(guò)隨機(jī)梯度下降算法求解優(yōu)化問(wèn)題.
3 本文算法的構(gòu)建
本文提出一種基于多模態(tài)生成[9]的半監(jiān)督學(xué)習(xí)模型.首先給出多模態(tài)生成模型表示形式,然后分別分析相應(yīng)的監(jiān)督學(xué)習(xí)及無(wú)監(jiān)督學(xué)習(xí)過(guò)程,最后提出多模態(tài)半監(jiān)督深度模型.對(duì)于少量“有標(biāo)記樣本集”lD及 大 量“未 標(biāo) 記 樣 本 集” Du,令,其中l(wèi)表示標(biāo)記樣本個(gè)數(shù),,其中u表示未標(biāo)記樣本個(gè)數(shù),并且l?u.
多模態(tài)概率生成模型的聯(lián)合概率分布為
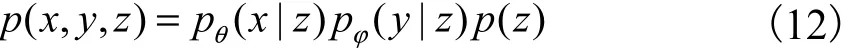
其中:p(z)表示隱變量z的先驗(yàn)概率分布,通常選擇標(biāo)準(zhǔn)高斯分布,即表示標(biāo)記的類(lèi)條件分布,即是它的參數(shù)表示圖像的條件概率分布,θ是模型的參數(shù).生成過(guò)程的概率為
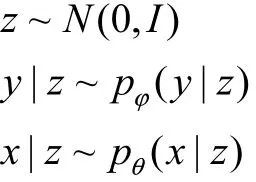
3.1 基于多模態(tài)生成的監(jiān)督學(xué)習(xí)
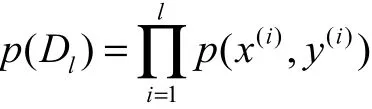
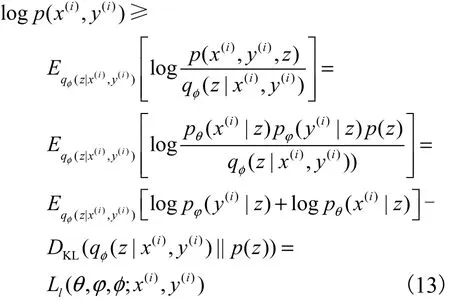
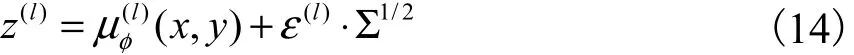
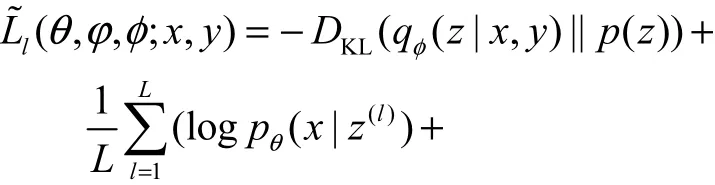
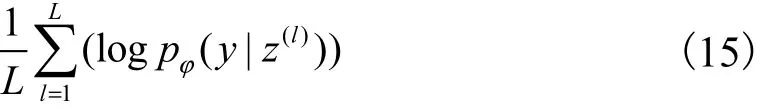
圖3為SS-MGM對(duì)帶標(biāo)記的樣本學(xué)習(xí)的概率圖模型,實(shí)線表示生成過(guò)程,虛線表示推理過(guò)程.

圖3 SS-MGM在監(jiān)督學(xué)習(xí)下的概率圖模型Fig. 3 Probabilistic graph model of SS-MGM under supervised learning
整個(gè)標(biāo)記數(shù)據(jù)集lD的變分下界可以采用批處理方法完成.即從數(shù)據(jù)集lD中隨機(jī)取K個(gè)樣本數(shù)據(jù)作為一個(gè)批次,構(gòu)造基于一個(gè)批次的完整數(shù)據(jù)集的變分下界
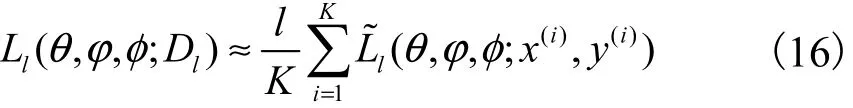
具體算法如算法1所示.
算法1:基于多模態(tài)生成的監(jiān)督深度模型學(xué)習(xí)過(guò)程.
輸入:數(shù)據(jù)集lD,K=1000,L取值為1.
輸出:模型參數(shù){θ,?}φ, .
隨機(jī)初始化參數(shù)θ,?φ,.
REPEAT:
DO{
將lD隨機(jī)打亂,從中取出K個(gè)樣本作為一個(gè)批次.
DO{
1. 將一批次樣本輸入到推理模型,得到隱變量的均值μ和方差Σ.
2. 從噪聲的高斯分布中采樣出ε(l).
3. 根據(jù)重參數(shù)化公式,對(duì)均值μ和方差Σ進(jìn)行重參數(shù)化技巧采樣.
4. 重參數(shù)化后的隱變量,輸入到兩個(gè)生成模型分別生成數(shù)據(jù)和標(biāo)簽概率.
5. 計(jì)算變分下界.
6. 對(duì)變分下界取負(fù)值后得到損失函數(shù).
7. 結(jié)合Adam Optimizer優(yōu)化器最小化損失函數(shù).
8. 更新推理模型和生成模型的參數(shù){θ,?}φ, .
}WHILE(數(shù)據(jù)集全部取完).
}WHILE(參數(shù){θ,?}φ, 收斂).
終止算法.
RETURN參數(shù){θ,φ,φ}.
3.2 基于多模態(tài)生成的無(wú)監(jiān)督學(xué)習(xí)
對(duì)于大量未標(biāo)記數(shù)據(jù)集uD,由于標(biāo)簽變量y是未知的,將其視為離散隱變量,此時(shí)模型中有z和y兩個(gè)隱變量,后驗(yàn)分布形式為.精確求出后驗(yàn)分布具有一定難度,所以引入變分推理模型.通常變分推理模型分解為.?dāng)?shù)據(jù)x的變下界為

其中H(.)是熵.變分下界 Lu(θ,?,φ;x)的優(yōu)化需要近似qφ( y|x)的期望,所以選擇對(duì)y的可能值進(jìn)行求和.圖4為SS-MGM算法在無(wú)監(jiān)督學(xué)習(xí)下的概率圖模型.
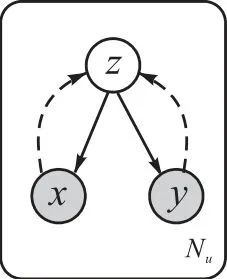
圖4 SS-MGM算法在無(wú)監(jiān)督學(xué)習(xí)下的概率圖模型Fig. 4 Probabilistic graph model of SS-MGM algorithm under unsupervised learning
重參數(shù)化后的變分下界為
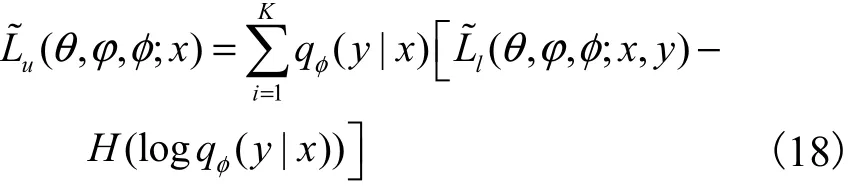
數(shù)據(jù)集uD可以采用批處理的方法構(gòu)造邊緣似然函數(shù),從包含u個(gè)數(shù)據(jù)點(diǎn)的數(shù)據(jù)集中隨機(jī)取出K個(gè)數(shù)據(jù)作為一個(gè)批次,構(gòu)造基于一個(gè)批次的完整數(shù)據(jù)集的變分下界
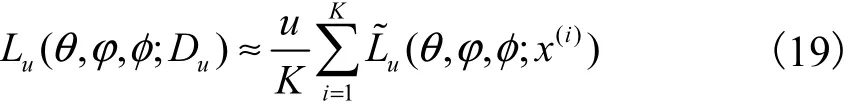
述如算法2所示.
算法2:基于多模態(tài)生成的無(wú)監(jiān)督深度模型學(xué)習(xí)過(guò)程.
輸入:無(wú)標(biāo)簽數(shù)據(jù)集uD,K=1000,L取值為1.
輸出:模型參數(shù){θ,?}φ, .
隨機(jī)初始化參數(shù)θ,?φ,.
REPEAT:
DO{
將uD隨機(jī)打亂,從中取K個(gè)樣本作為一批次.
DO{
1. 一批次樣本輸入到分類(lèi)器qφ( y|x)預(yù)測(cè)得到標(biāo)簽y,將樣本與預(yù)測(cè)的標(biāo)簽相連接輸入到推理模型得到隱變量的均值μ和方差Σ.
2. 從噪聲的高斯分布中采樣出ε(l),對(duì)均值μ和方差Σ進(jìn)行重參數(shù)化技巧采樣.
3. 重參數(shù)化后的隱變量z,輸入到兩個(gè)生成模型分別生成數(shù)據(jù)x和標(biāo)簽概率y.
4. 計(jì)算變分下界.
5. 對(duì)變分下界取負(fù)值后得到損失函數(shù).
6. 結(jié)合Adam Optimizer優(yōu)化器最小化損失函數(shù).
7. 更新推理模型和生成模型的參數(shù){θ,?}φ, .
}WHILE(數(shù)據(jù)集全部取完).
}WHILE(參數(shù){θ,?}φ, 收斂).
終止算法.
RETURN參數(shù){θ,φ,φ}.
3.3 本文算法
對(duì) 于 少 量“有 標(biāo) 記 樣 本 集” Dl={( x(1), y(1)),( x(2), y(2)),… ,( x(l), y(l))}及 大 量“未 標(biāo) 記 樣 本 集”Du={x(l+1), x(l+2),… , x(l+u)},整個(gè)數(shù)據(jù)集 Dl∪Du的目標(biāo)函數(shù)可視為兩個(gè)樣本集的目標(biāo)函數(shù)之和,即
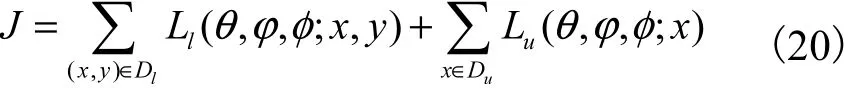
由于推理模型 qφ( z|y,x)在整個(gè)數(shù)據(jù)集下訓(xùn)練,而推理模型qφ( y|x)只在沒(méi)有標(biāo)記的數(shù)據(jù)中訓(xùn)練,這樣不利于學(xué)習(xí)網(wǎng)絡(luò)參數(shù),所以在標(biāo)記數(shù)據(jù)中增加訓(xùn)練qφ( y|x).重參數(shù)化后的統(tǒng)一目標(biāo)函數(shù)為
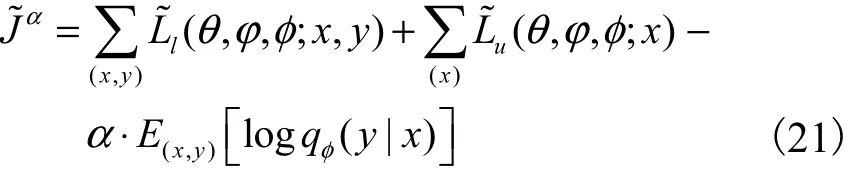
其中α 是控制標(biāo)簽數(shù)據(jù)集在總數(shù)據(jù)集中的權(quán)重,在實(shí)驗(yàn)中設(shè)置α=0.1N.
設(shè)H1個(gè)標(biāo)記數(shù)據(jù)和H2個(gè)沒(méi)有標(biāo)記數(shù)據(jù)為一個(gè)批次,構(gòu)造基于一個(gè)批次的完整數(shù)據(jù)集的變分下界為
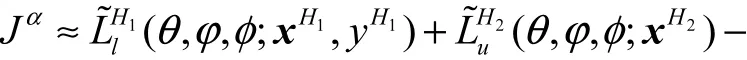
算法3:基于多模態(tài)生成的半監(jiān)督深度模型學(xué)習(xí)過(guò)程.
輸出:模型參數(shù){θ,φ,φ}.
隨機(jī)初始化參數(shù)θ,φ,φ.
REPEAT:
DO{
將 Dl∪Du隨機(jī)打亂,從中取1個(gè)樣本.
將uD隨機(jī)打亂,從中取99個(gè)樣本,將這100個(gè)樣本作為一個(gè)批次.
DO{
1. 標(biāo)記樣本輸入到推理模型得到隱變量的均值μ和方差Σ.
2. 從噪聲的高斯分布中采樣出 ε(l),對(duì)均值μ和方差Σ進(jìn)行重參數(shù)化技巧采樣.
3. 重參數(shù)化后的隱變量z,輸入到兩個(gè)生成模型分別生成數(shù)據(jù)x和標(biāo)簽概率y.
4. 同時(shí)無(wú)標(biāo)記樣本輸入到分類(lèi)器qφ( y|x)預(yù)測(cè)得到標(biāo)簽y,將樣本與預(yù)測(cè)的標(biāo)簽相連接通過(guò)推理模型得到隱變量的均值μ和方差Σ.
5. 從噪聲的高斯分布中采樣出 ε(l),對(duì)均值μ和方差Σ進(jìn)行重參數(shù)化技巧采樣.
6. 重參數(shù)化后的隱變量z,經(jīng)過(guò)兩個(gè)生成模型生成數(shù)據(jù)x和標(biāo)簽概率y.
7. 對(duì)標(biāo)記樣本和無(wú)標(biāo)記樣本計(jì)算變分下界.
8. 對(duì)變分下界取負(fù)值后得到損失函數(shù).
9. 結(jié)合Adam Optimizer優(yōu)化器最小化損失函數(shù).
10. 更新推理模型和生成模型的參數(shù){θ,?}φ, .
}WHILE(數(shù)據(jù)集全部取完).
}WHILE(參數(shù){θ,?}φ, 收斂).
終止算法.
RETURN 參數(shù){θ,?}φ, .
4 實(shí) 驗(yàn)
實(shí)驗(yàn)采用MNIST數(shù)據(jù)集和FASHION_MNIST數(shù)據(jù)集進(jìn)行驗(yàn)證.MNIST數(shù)據(jù)集是一種手寫(xiě)字體識(shí)別數(shù)據(jù)集,包含60000張訓(xùn)練圖片和標(biāo)簽以及10000張測(cè)試圖片和標(biāo)簽.每張圖片由28×28=784個(gè)像素點(diǎn)組成,通常用一個(gè)數(shù)字?jǐn)?shù)組表示這張圖片.標(biāo)簽是介于0~9的數(shù)字,標(biāo)簽數(shù)據(jù)用“one-hot vectors”的形式表示.
FASHION_MNIST數(shù)據(jù)集是一種時(shí)尚產(chǎn)品圖像數(shù)據(jù)集,包含10種類(lèi)別,一共70000張物品的圖片.它的大小、格式以及訓(xùn)練集、測(cè)試集的劃分與MNIST數(shù)據(jù)集完全一致.
4.1 生成圖像效果實(shí)驗(yàn)
通過(guò)SS-MGM模型與CVAE模型[7]在生成圖像方面的對(duì)比,驗(yàn)證SS-MGM模型在生成圖像方面的有效性.首先數(shù)據(jù)集中有50000個(gè)樣本,將其分為50個(gè)批次,一個(gè)批次共有1000個(gè)樣本輸入到模型中,即K=1000.其次選用多層全連接神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)模型參數(shù),其中變分推理模型和生成模型都采用4層神經(jīng)網(wǎng)絡(luò),每層網(wǎng)絡(luò)有500個(gè)隱藏節(jié)點(diǎn).最后隱變量的維度選擇z=50,激活函數(shù)選用softplus函數(shù).
在實(shí)驗(yàn)中,數(shù)據(jù)x的維度是784維,而標(biāo)簽y的維度是10維.當(dāng)它們直接連接輸入到推理模型進(jìn)行降維處理時(shí),由于兩者維度相差較大,隱變量z的結(jié)構(gòu)中包含標(biāo)簽y的信息較少,這種連接方式會(huì)影響模型的精度.所以將不同維度的數(shù)據(jù)和標(biāo)簽分別經(jīng)過(guò)不同的神經(jīng)網(wǎng)絡(luò)處理到相同的256維,之后兩者再連接輸入到推理模型.
(1)當(dāng)z的維度設(shè)為50時(shí),訓(xùn)練50000個(gè)全帶標(biāo)簽的MNIST數(shù)據(jù)集和FASHION_MNIST數(shù)據(jù)集,任意取10個(gè)z值,給定標(biāo)簽0~9,CVAE生成的10張圖片分別如圖5和圖6所示.

圖5 MNIST數(shù)據(jù)集下CVAE生成的圖片F(xiàn)ig. 5 Images generated by CVAE under MNIST datasets

圖6 FASHION_MNIST數(shù)據(jù)集下CVAE生成的圖片F(xiàn)ig. 6 Images generated by CVAE under FASHION_MNIST datasets
(2)當(dāng)z的維度設(shè)為50時(shí),分別訓(xùn)練50000個(gè)全帶標(biāo)簽的MNIST數(shù)據(jù)集和FASHION_MNIST數(shù)據(jù)集,任意取10個(gè)z值,SS-MGM模型生成10張圖片以及對(duì)應(yīng)生成圖片標(biāo)簽的概率,如圖7、圖8和表1、表2所示.
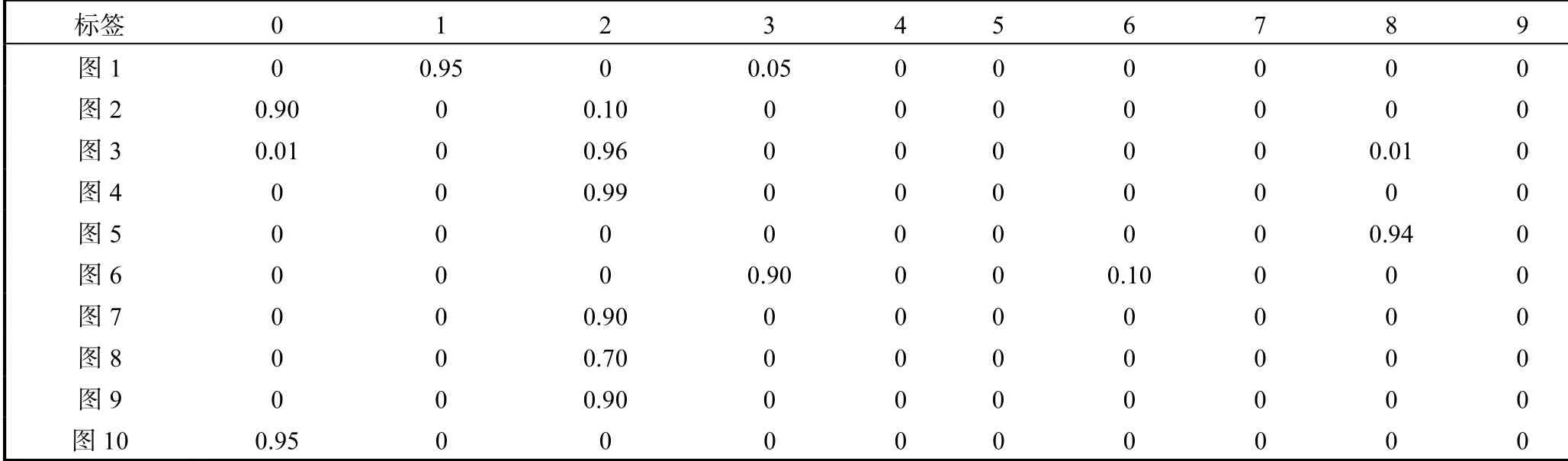
表2 FASHION_MNIST數(shù)據(jù)集下SS-MGM模型生成的圖片對(duì)應(yīng)概率Tab. 2 Corresponding probability of images generated by SS-MGM under FASHION_MNIST datasets
從上述兩組對(duì)比實(shí)驗(yàn)可以看出,SS-MGM模型與CVAE模型[7]相比,SS-MGM模型在生成圖像方面有著不錯(cuò)的清晰度,并且SS-MGM模型生成的標(biāo)簽有著較準(zhǔn)確的概率,同時(shí)可以看出SS-MGM模型生成標(biāo)簽概率的作用.例如對(duì)于圖7中的第2張圖片,由于圖片看著既像數(shù)字8又像數(shù)字1,容易造成失誤,但是通過(guò)查看SS-MGM模型輸出的對(duì)應(yīng)圖片的標(biāo)簽概率可以避免這個(gè)失誤,見(jiàn)表1中的第2行概率,這張圖片是數(shù)字8的概率是0.70,是數(shù)字1的概率為0.30.
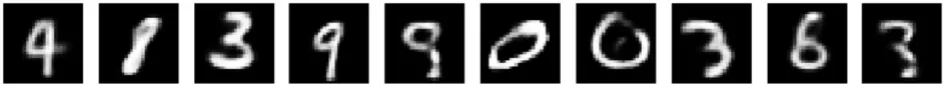
圖7 MNIST數(shù)據(jù)集下SS-MGM模型生成的圖片F(xiàn)ig. 7 Images generated by SS-MGM under MNIST datasets

圖8FASHION_MNIST數(shù)據(jù)集下SS-MGM模型生成的圖片F(xiàn)ig. 8 Images generated by SS-MGM under FASHION_MNIST datasets
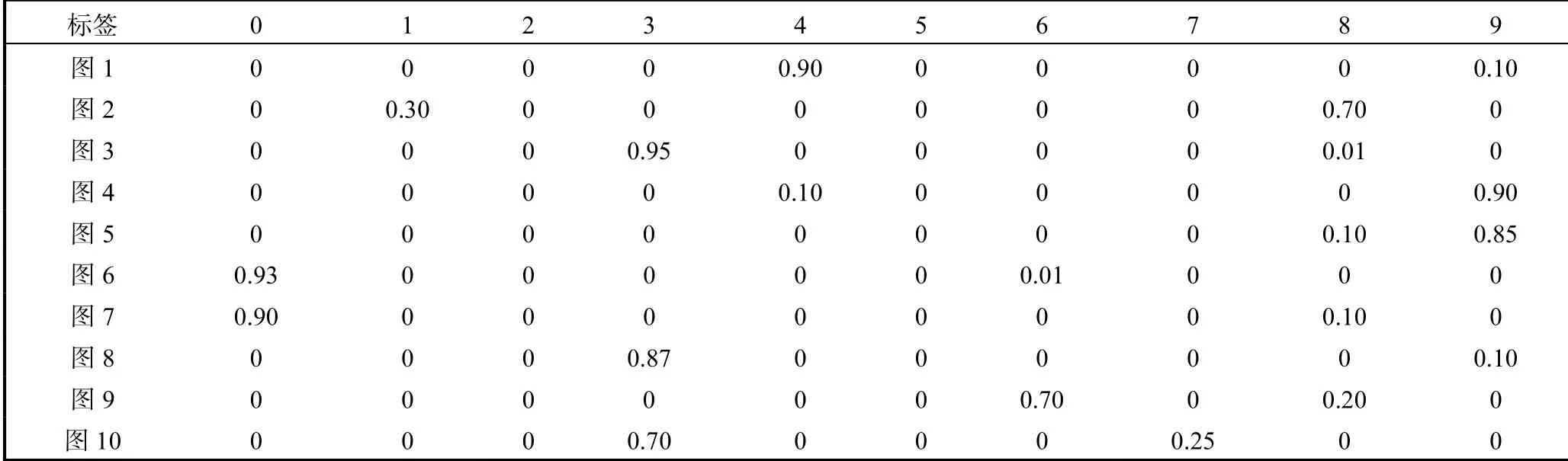
表1 MNIST數(shù)據(jù)集下SS-MGM模型生成的圖片對(duì)應(yīng)概率Tab. 1 Corresponding probability of images generated by SS-MGM under MNIST datasets
4.2 半監(jiān)督精度對(duì)比實(shí)驗(yàn)
為了驗(yàn)證SS-MGM模型具有較高的預(yù)測(cè)精度,選擇與SS-DGM模型[8]進(jìn)行對(duì)比預(yù)測(cè).選用多層全連接神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)網(wǎng)絡(luò)參數(shù),其中變分推理模型和生成模型都采用4層神經(jīng)網(wǎng)絡(luò),每層網(wǎng)絡(luò)有500個(gè)隱藏點(diǎn).本實(shí)驗(yàn)選擇激活函數(shù)為tanh,兩個(gè)模型分別在標(biāo)簽數(shù)為100、600、1000和3000以及隱變量維度分別為100、50和16的環(huán)境下進(jìn)行預(yù)測(cè)標(biāo)簽精度對(duì)比,在MNIST數(shù)據(jù)集和FASHION_MNIST數(shù)據(jù)集的具體情況見(jiàn)表3和表4.
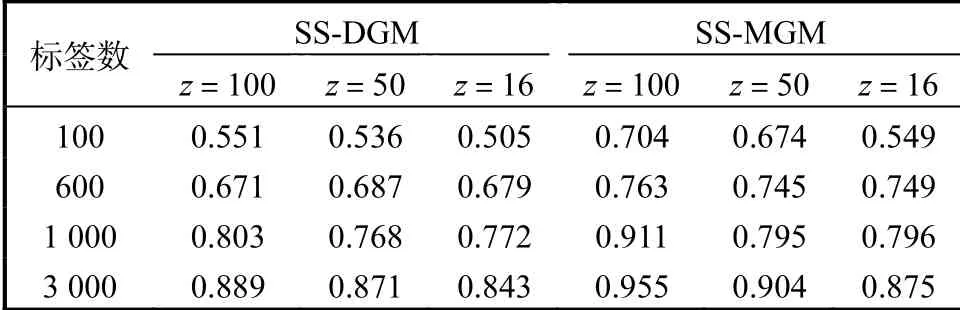
表3 MNIST數(shù)據(jù)集下兩種模型預(yù)測(cè)標(biāo)簽精度對(duì)比Tab. 3 Comparison of prediction label accuracy of two models in MNIST datasets
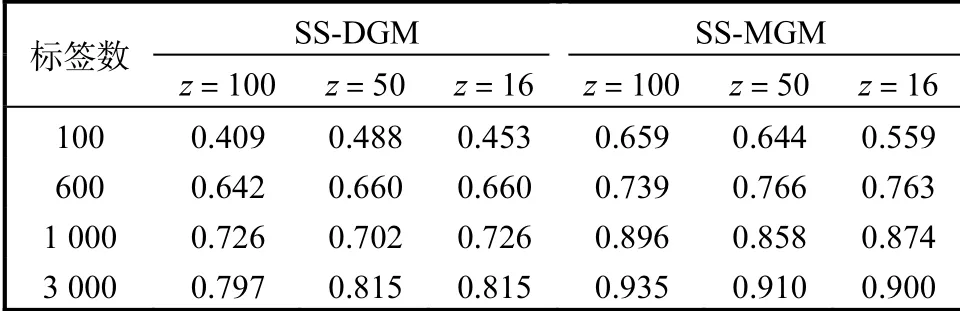
表4 FASHION_MNIST數(shù)據(jù)集下兩種模型預(yù)測(cè)標(biāo)簽精度對(duì)比Tab. 4 Comparison of prediction label accuracy of two models in FASHION_MNIST datasets
在MNIST數(shù)據(jù)集和FANSHION_MNIST數(shù)據(jù)集上,SS-MGM模型比SS-DGM模型[8]具有更好的預(yù)測(cè)標(biāo)簽?zāi)芰Γ⑶铱梢钥吹筋A(yù)測(cè)的精度隨著標(biāo)簽數(shù)據(jù)量的增大、隱變量維度的增加而提高.
5 結(jié) 語(yǔ)
本文提出一種基于多模態(tài)生成模型的半監(jiān)督學(xué)習(xí)算法.模型在處理標(biāo)記樣本時(shí),標(biāo)記樣本和標(biāo)簽作為推理模型的輸入,輸出隱變量,隱變量作為生成模型的輸入,輸出樣本和對(duì)應(yīng)標(biāo)簽概率.處理無(wú)標(biāo)記樣本時(shí),標(biāo)簽看作是離散隱變量,推理模型的輸入是樣本,輸出為隱變量和標(biāo)簽.隱變量作為生成模型的輸入,輸出樣本和對(duì)應(yīng)標(biāo)簽概率.可以看出:基于多模態(tài)概率生成模型的半監(jiān)督學(xué)習(xí)模型不僅可以給出模型標(biāo)簽,同時(shí)可以給出該標(biāo)簽的概率.并且,經(jīng)過(guò)實(shí)驗(yàn)證明該模型有效提高了預(yù)測(cè)標(biāo)簽的精度.另外,雖然在標(biāo)記樣本量較少(如100個(gè))的情況下,SS-MGM模型預(yù)測(cè)標(biāo)簽的精度高于SS-DGM模型的預(yù)測(cè)精度,但是SS-MGM模型在標(biāo)簽量極少情況下預(yù)測(cè)的精度還是較低,不能體現(xiàn)出半監(jiān)督學(xué)習(xí)的能力.因此,如何在極少量標(biāo)記樣本集中提高預(yù)測(cè)能力是后續(xù)研究的方向.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
廣西科技大學(xué)學(xué)報(bào)(2016年1期)2016-06-22 13:10:37
湖北經(jīng)濟(jì)學(xué)院學(xué)報(bào)·人文社科版(2015年8期)2015-12-29 05:53:07
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
航空學(xué)報(bào)(2015年4期)2015-05-07 06:43:35
上海電機(jī)學(xué)院學(xué)報(bào)(2015年4期)2015-02-28 14:30:00
計(jì)算物理(2014年2期)2014-03-11 17:01:39
