基于數據挖掘的我國檔案服務創新主題發現及演化研究
2022-04-24 03:14:04齊夢珂羅子江楊云帆楊秀璋
現代計算機 2022年4期
齊夢珂,羅子江,趙 凱,楊云帆,楊秀璋
(貴州財經大學信息學院,貴陽 550025)
0 引言
數據挖掘(data mining)又稱數據庫中的知識發現,是從大量的、不完全的、隨機的實際應用數據中,提取隱含在其中的、事先不為人所知但潛在有用的信息和知識的過程,常用的文本處理模型包括分詞模型、TF-IDF 模型、LDA模型、詞向量模型等。隨著信息化時代和大數據時代的到來,數據挖掘技術也被運用至檔案事業中,《全國檔案事業發展“十三五”規劃綱要》提出,檔案服務領域要采用大數據、智慧管理、智能樓宇管理等技術,推動檔案利用服務模式的創新。在此背景下,諸多學者以數據挖掘等技術為切入點,以高校、企業、政府等為研究主體,開展我國檔案服務創新的思考與探索。但是科研工作者閱讀、分析、利用文獻的速度遠遠低于文獻發表的速度。
1 相關研究概述
王青介紹了全媒體背景下高校檔案服務社會創新的主要應用和重點難點,并從豐富檔案服務內容、打造檔案信息服務平臺、建立雙向反饋機制的角度提出了全媒體環境下高校檔案服務社會創新的對策。王向女和姚婧從技術、公眾、機構改革三方面探討催生檔案公共服務變革的動因,提出檔案公共服務創新實踐的路徑,包括多方參與擴充資源基礎、多元協同拓展服務空間、以人為本提供精細化服務三個層面。李財富和靳文君深入分析VR 技術創新檔案利用服務的優勢、劣勢、機會和風險,從檔案服務宏觀戰略與機遇層面、VR 技術突破和檔案資源融合層面、VR 檔案服務平臺構建和倫理維護層面提出解決策略,認為應該從構建VR 檔案創新服務體系、突破VR 軟硬件技術瓶頸、制定VR+檔案服務相關標準等方面推動檔案利用服務創新發展。黃霄羽等研究檔案館應用社交媒體創新檔案服務的方式。許新華等研究民生檔案服務創新STOF 模型設計及應用。蘇錫云和蔡旭兵分析了大數據管理模式下的業務檔案公共服務創新研究。陳燕萍和曹航從建立跨館利用、為檔案弱勢群體提供個性化服務、積極與媒體合作、采用先進技術四個方面來探討近十年我國檔案利用服務創新的新舉措。田偉和韓海濤分析了當前大學檔案館用戶需求的變化趨勢,進而提出了大數據時代檔案館服務創新策略:構建用戶需求感知引擎、拓展深化檔案數據服務內涵、推進檔案個性化服務實施。
科學知識圖譜是一種可視化的描述人類隨時間擁有的知識資源及載體、科學知識間關聯度的方法。在國外相關研究中,Price作為科學知識圖譜的早期開拓者,為科學知識圖譜的發現與發展做出了重大貢獻;德國著名科學計量學家Kretschmer有關三維空間模型的研究為科學知識圖譜的進一步發展奠定了堅實的基礎。國內研究中,陳悅和劉則淵于2005 年將科學知識圖譜的概念引入國內,這為我國科學知識圖譜的相關研究奠定基礎;侯海燕利用詞頻分析法發現了科學知識圖譜研究熱點領域為借助作者共引分析,最終揭示出科學計量學合作網絡將形成全球性國際合作網絡的趨勢;譚春輝和熊夢媛從數據方向的理論和應用兩個維度來研究該領域的熱點以及主題演化趨勢,進而為比較國內外數據挖掘領域熱點問題的演化過程提供了新思路;白敬毅和顏瑞武等通過將主題模型和曲線擬合趨勢預測方法相結合對科技文獻進行主題劃分,并據此繪制相應的主題分布矩陣,最終預測新興主題未來發展趨勢;方倩和竇永香等使用Cite Space 和UCINET 等科學知識圖譜軟件,從關鍵詞和共被引文獻角度出發,構建該領域下聚類視圖和關鍵詞共現的知識圖譜,對該領域的研究熱點和社會發現演化路徑進行了可視化分析,為后續的研究提供了可參考的數據;陳悅等從引文分析和信息可視化的角度來分析科學知識圖譜的演變過程,揭示了科學知識圖譜領域的發展越發趨向科學學科的可視化,也證明了科學知識圖譜是科學計量學具有前景的研究方向。
基于此,本文借鑒數據挖掘技術,從主題發現與主題演化兩方面分析我國檔案服務創新相關文獻的研究熱點及研究趨勢。針對文本數據中存在同義詞和多義詞、詞語之間存在語法關系和相似性等問題,本文采用基于LDA 和加權Word2vec 的科學知識圖譜構建方法。該方法首先利用LDA 模型抽取主題及每個主題下的關鍵詞,再用Word2vec 獲取每個主題下關鍵詞的詞向量,通過加權計算詞向量得到主題向量,進而計算主題相似度與重要度,最后以可視化方法構建主題共現圖譜和主題演化圖譜,從而達到從語義層面揭示領域發展變化的目標。
2 相關技術介紹
2.1 潛在狄利克雷分布(latent Dirichlet allocation,LDA)
LDA 是一種無監督的概率主題生成模型,包含了詞、主題和文檔三層結構,它將文檔庫中每篇文檔的主題以概率分布的方式展現,是在pLSA(probabilistic latent semantic analysis)模型的基礎上增加貝葉斯架構模塊所形成的,具體模型如圖1所示。
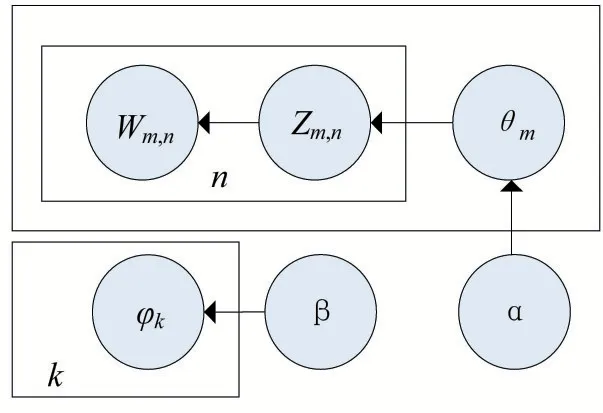
圖1 LDA文檔主題生成模型
2.2 Word2vec
Word2vec 是一款用于詞向量計算的開源工具,它根據上下文信息將輸入的特征詞訓練為詞向量并且有兩種語言模型,分別是連續詞袋模型(CBOW,continuous bag of words)模型和跳字模型(skip-gram)。CBOW 旨在通過上下文來預測當前詞的概率,其結構如圖2 所示;skipgram 則利用當前詞的特征向量來預測上下文,其結構如圖3所示。除此之外,CBOW 較適用于較小的詞庫,而skip-gram 卻在大型的語料庫上表現得比較好。兩種模型雖然在輸入輸出的內容上完全相反,但在模型的訓練過程中是相同的。
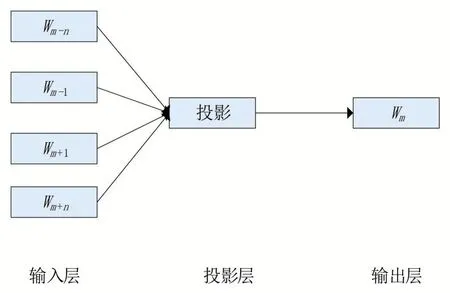
圖2 CBOW模型

圖3 Skip-gram 模型
3 基于LDA和加權Word2vec的主題發現及演化研究
本文旨在從語義層面來揭示領域變化情況,以中國知網期刊題目、摘要、關鍵詞等作為基礎數據,利用LDA 和Word2vec 模型分別抽取主題、關鍵詞,并進行詞向量模型的構建和轉化,通過加權計算得到主題向量,最終構建主題共現和演化知識圖譜。具體流程如圖4所示。

圖4 基于LDA和加權Word2vec的主題發現及演化研究
3.1 數據來源與數據預處理
以中國知網導出的文獻標題、摘要以及關鍵詞為基礎數據。數據預處理階段包括中文分詞、去停用詞以及關鍵詞過濾。中文分詞算法中jieba 分詞使用廣泛、理論成熟,故分詞階段采用的是Python 語言環境下結巴(Jieba)分詞來完成;為了提高文本主題提取的準確性,去停用詞階段使用的是哈工大停用詞表;為了更好地反映主題信息,關鍵詞篩選方面以TF-IDF 算法為依據,以計算出的各主題關鍵詞的TF-IDF值確定關鍵詞集合。
3.2 利用LDA主題概率生成模型抽取主題
LDA 主題模型在分析文本語義方面具有良好的效果并且可以有效地分析大規模非結構化文檔集。本文通過調用Python 環境下的pyLDAvis 包來確定主題數量,因視距圖在直觀展現各主題間聯系和主題下的關鍵詞詞頻方面都表現良好,即以此為基礎對各個主題的分布情況和每個主題下的關鍵詞頻率展開深層次的研究。
3.3 利用Word2vec獲取關鍵詞詞向量
在抽取主題之后,為了避免LDA 主題模型在語義提取和高維稀疏向量方面存在的問題,該研究采用Word2vec 來研究詞的上下文語義信息并高效地將詞語表達成向量,其主要思想是把文本內容的處理簡化為向量間的運算。本文用Word2vec 中的CBOW 模型進行文檔的訓練,利用詞的前后個詞去預測當前詞,最后得到包含上下文語義的特征詞向量,為后續自然語言處理領域相關研究的發展奠定了基礎。
3.4 加權主題向量計算
在提取關鍵詞詞向量之后,為分析主題之間的關聯程度及獲取主題信息,需將主題轉化為由關鍵詞及其權重表示的向量。而在以往研究中沒有考慮到詞頻問題,只是采用主題內所有關鍵詞詞向量的均值來表示該主題向量,因此本文采用TF-IDF 加權平均法給予主題內不同關鍵詞以不同權重,計算公式如式(1)所示。
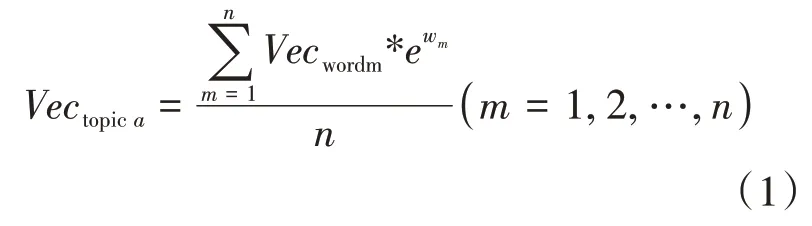
式(1)中,表示主題的主題向量;為 關 鍵詞的 詞向量;w為 關鍵詞的TF-IDF值;為主題中關鍵詞數量。
3.5 主題相似度與重要度計算
對任意主題利用關鍵詞詞向量計算關鍵詞的相似度,進而聚合成主題相似度(resemblance,Res),它反映了主題間的關聯性和隨時間的演化趨勢。據此,公式(2)在傳統的余弦公式上進行了一定的優化,考慮了關鍵詞語義之間的相似度,最終值表示不同主題之間的語義相似度和主題間的關聯性,具體計算公式如(2)所示。
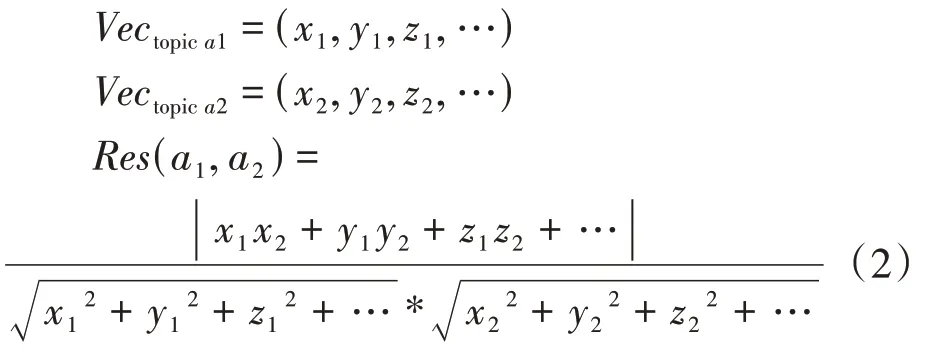
式(2)中,Vec是根據式(1)計算得到的加權主題向量;(,,,…)表示主題向量各個維度的數值;(,)表示主題與主題間的主題相似度。
主題重要度(imporantance,Imp)是本文反映主題在所屬領域內重要性的具體數值,其值越大就表示主題在該領域中越重要。主題重要度依據各主題下關鍵詞TF-IDF 的均值確定,在表示研究領域內主題隨時間不斷變化方面具有良好表現,具體計算公式如式(3)所示。
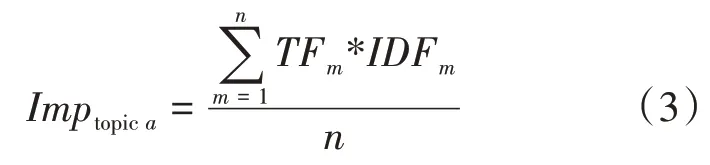
式(3)中,topic表示主題;為主題中關鍵詞個數;TF與IDF分別表示關鍵詞的文本頻率與逆文檔頻率指數。
3.6 科學知識圖譜構建
科學知識圖譜將復雜的科學知識領域通過數據挖掘、信息處理等方式繪制成圖形,并以可視化方式展現科學知識的發展與結構關系,也展現了其演化的規律。目前基于分析方面的學知識圖譜可視化研究方法已成為研究熱點,本文所繪制的知識圖譜包含關鍵詞共現和主題演化圖譜兩種,主要展現學科主題、主題重要度、主題相似度等三個方面的信息。
(1)主題。一個圓即代表一個主題,各個圓圈的距離情況也展現出提取主題的效果良好情況,即主題間的差異度。同樣,在主題演化圖譜中結合了時間橫軸展現不同時間段主題信息的演變情況。
(2)主題重要度。通過計算TF-IDF 值,并作歸一化處理,以歸一化結果確定圓形的半徑大小,利用圓的大小表現主題重要度。
(3)主題相似度。根據各主題特征向量計算主題之間的相似度,通過歸一化確定主體之間連線的寬度,連線的寬度與主題間相似度成正比。
本文認為關鍵詞共現和主題演化知識圖譜的構建能很好的展現關鍵詞詞頻和主題隨時間演變的趨向,也能更加直觀的分析出在檔案服務創新領域中主要的研究熱點和方向。
4 實證研究結果
本文數據來源于中國知網期刊數據庫,檢索方式為“SU=‘檔案服務創新’+‘檔案創新’”,主要包含期刊題目、摘要和關鍵詞,涉及7512 篇期刊論文,時間節點截取2001—2020年,共20 年。研究將整體數據分為兩種形式,第一種是將20 年數據依據每5 年一個階段劃分為4部分,在此基礎上繪制主題演化圖譜以研究近20 年主題演化趨勢;另外一種是將總數據進行整體分析,所得結果作為主題共現圖譜繪制依據,借此探討研究熱點。
4.1 主題提取結果
本文通過調用pyLDAvis 繪制視距圖以確定合理的主題數量,因篇幅限制僅展示總數據主題1 的關鍵詞,如圖5 所示,3 個圓圈表示3 個主題,基本沒有重疊,表示提取效果良好,右邊為關鍵詞詞頻。另外總年段數據的主題提取結果如表1所示,各年段數據的主題提取結果如表2所示。

表1 2001—2020年總數據各主題關鍵詞
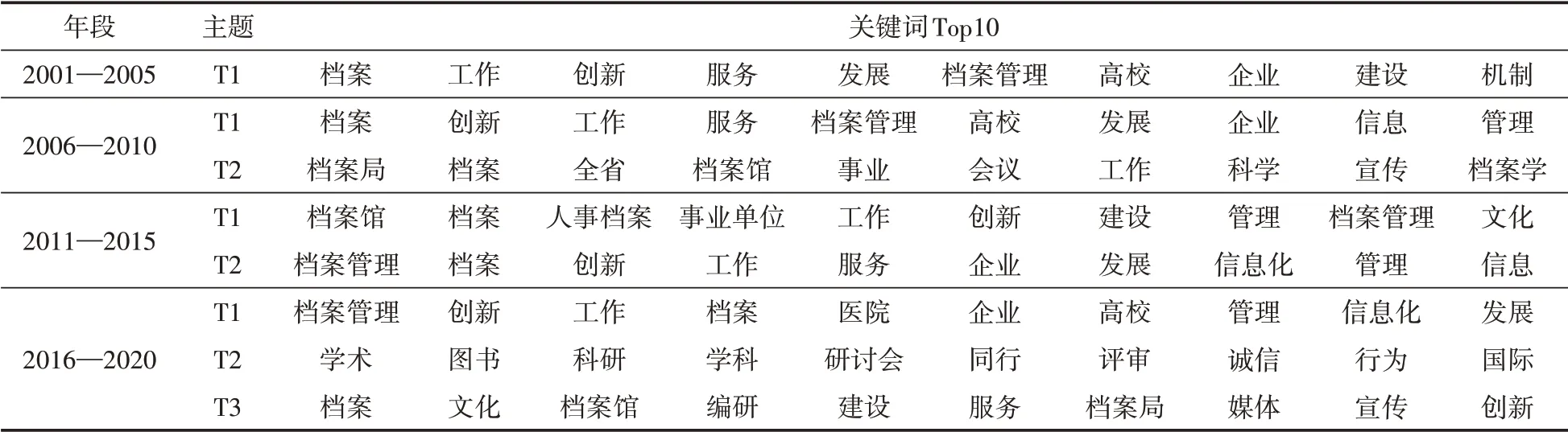
表2 2001—2020年各年段主題關鍵詞
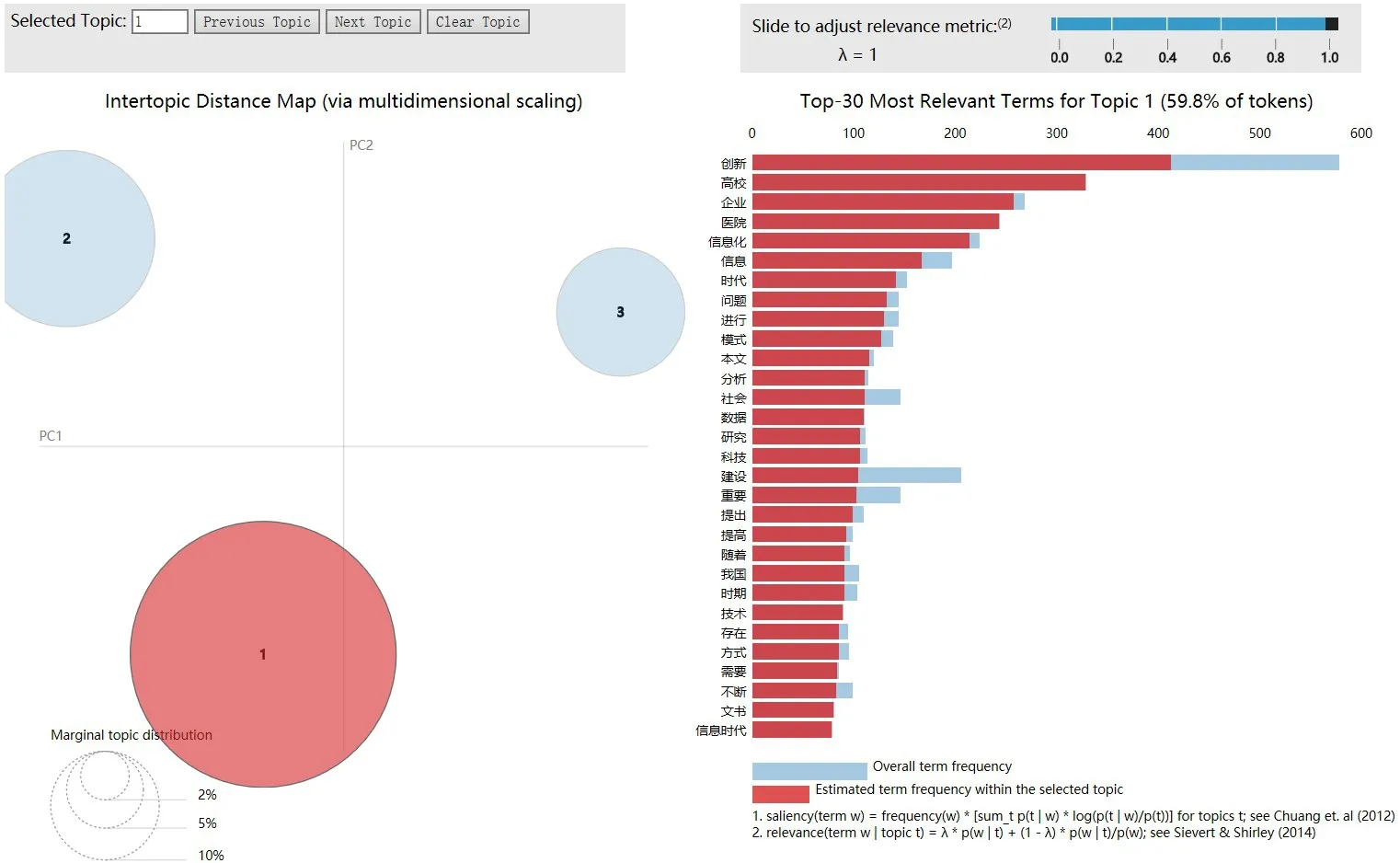
圖5 總數據視距
4.2 主題相似度與主題重要度計算
主題相似度計算:利用式(2)計算總數據不同主題間的相似度,舉例來講就是分別計算出主題1 與主題2、3 主題2 與主題3 之間的相似度。
主題重要度計算:主題重要度主要依據主題關鍵詞的TF-IDF 值,按式(3)計算,基于以上兩種條件,計算出總數據與各年段下每一個主題的主題重要度。總數據主題重要度與相似度如表3所示,由于篇幅原因,分年度數據不做贅述。

表3 總數據主題重要度與相似度
4.3 科學知識圖譜構建
主題共現圖譜結果如圖6所示。

圖6 主題共現圖譜
從圖中可見:
(1)近20年,我國檔案服務創新主要的研究方向為:高校企業醫院的信息化創新、國家檔案部門的文化建設創新與事業單位的人事檔案改革工作。以上研究方向的共同點均是對檔案事業發展進行改革與創新;不同點是:信息化創新依托大數據、數據分析等科技與技術,多在高校、企業、醫院發展,而文化建設創新與人事檔案改革工作多發生在國家檔案部門、事業單位與行政機關。總而言之,部分產業依托技術創新完善檔案服務工作,政府部門依托人文與制度創新進行優化和改革。
(2)從主題重要度來講,近20年間信息化創新在檔案服務創新方向的研究是一大熱點,高校、企業、醫院的檔案信息資源來源廣泛、種類眾多、數據量龐大,在當今數據時代背景下,單一、被動且缺乏創新性的服務模式已無法適應當前用戶的需求。建立信息化與數字化的檔案服務模式是檔案事業發展的必經之路,數字化檔案系統、網絡檔案公眾號等數字資源能夠更好地為用戶提供個性化服務。
(3)從主題關聯度來講,國家檔案部門的文化建設創新與事業單位的人事檔案改革工作兩個主題之間關聯度最大。《全國檔案事業發展“十三五”規劃綱要》對于我國檔案事業破解發展難題、厚植發展優勢具有重大意義,綱要中提到文化建設是檔案改革的必要前提,人文建設是當前社會發展主旋律,檔案部門的文化建設創新可以推進我國檔案事業的改革與發展。
主題演化圖譜如圖7 所示,結合圖7 和表2可以看出:
(1)各年段研究側重點不同。2001—2005年段的研究主題為高校與企業的檔案服務創新工作(圖7 2001—2005 年T1),如關鍵詞“檔案”“創新”“服務”“高校”“企業”等。2006—2010 年與2011—2015 年兩個年段的研究主題均為高校與企業的檔案服務信息化創新、國家檔案部門的建設管理與文化創新。2016—2020 年段主要包含的研究主題為:高校企業醫院的檔案服務信息化創新(圖7 2016—2020 年T1)、相關學術科研(圖7 2016—2020 年T2)、國家檔案部門的文化創新(圖7 2016—2020 年T3)。不難發現,我國關于檔案服務創新的研究層次越來越豐富,現階段的學術科研行為增多,高校、醫院、企業的檔案工作逐漸往信息化發展,國家檔案部門也越來越重視文化建設。
(2)從主題關聯度來看,20 年間主要存在兩條關鍵主題演化路徑(圖7 中兩種顏色不同的路徑),分別是高校企業醫院的檔案服務信息化創新與國家檔案部門的建設管理和文化創新。而且各路徑不僅會出現新的研究內容,也會伴隨著舊研究內容的消失。高校企業醫院的檔案服務信息化創新這一演化路徑貫穿了近20 年的文獻主題,2006—2010 年段開始出現關鍵詞“信息”,表明檔案工作逐漸往信息化發展,2016—2020年段第一次出現關鍵詞“醫院”,表明醫院檔案部門也開始加入數字化時代的浪潮。國家檔案部門的建設管理和文化創新這一演化路徑從2006—2010 年段產生,關鍵詞“文化”“宣傳”“創新”在后兩個年段逐漸涌現,表明文化建設與文化創新是當前國家檔案部門的工作主旋律。
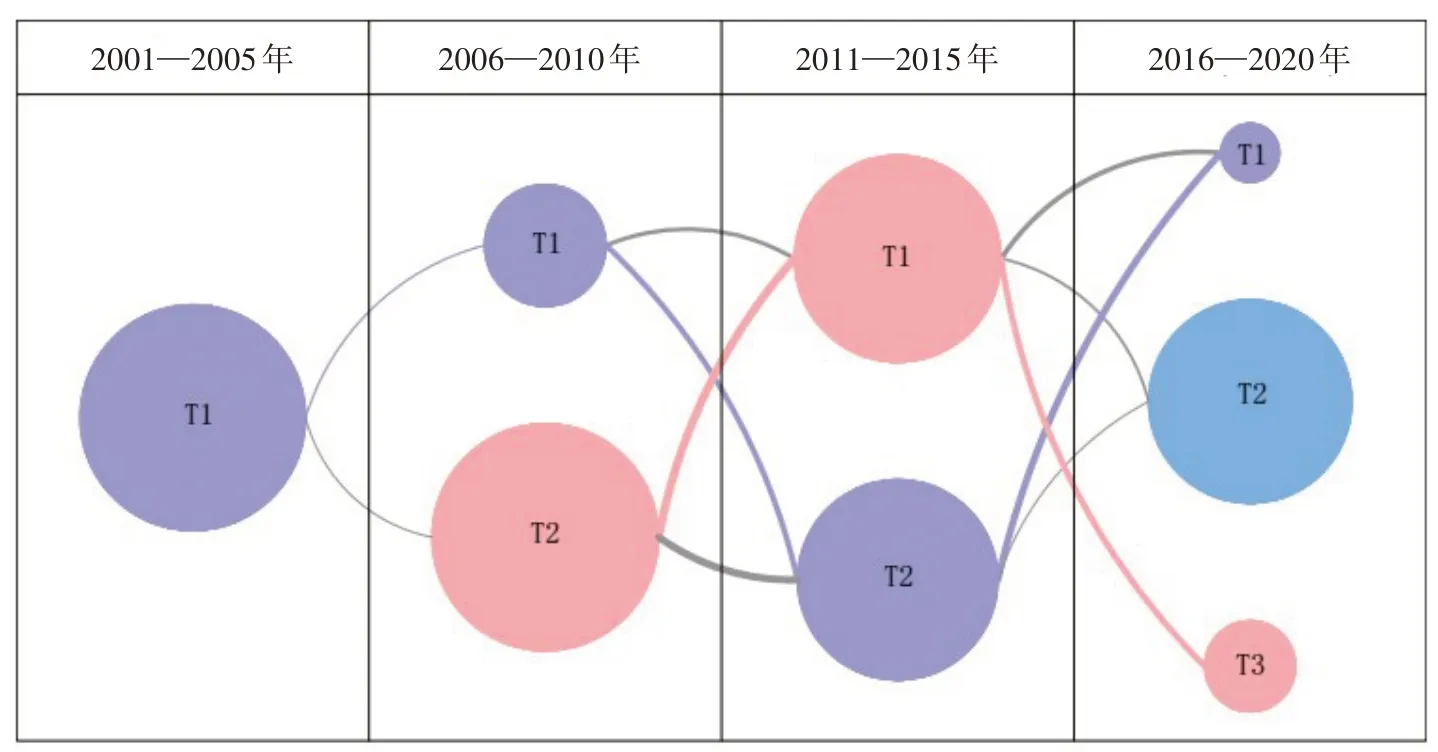
圖7 主題演化圖譜
(3)從主題重要度來看,現階段(2016—2020年段)高校企業醫院的檔案服務信息化創新與國家檔案部門的建設管理和文化創新這兩個主題的重要度降低,相關學術科研主題(圖7 2016—2020 年T2)開始產生并占據較大重要度。關鍵詞“學術”“科研”“學科”“研討會”等均表明關于檔案服務創新的學術科研開始得到重視并逐漸增多,對于促進我國檔案事業的發展與創新是一大助力。
5 結語
我國關于檔案服務創新的研究成果大量問世,但是科研工作者閱讀、分析、利用文獻的速度遠低于文獻發表的速度。本文利用數據挖掘技術,從主題發現與主題演化兩方面分析我國檔案服務創新相關文獻的研究熱點與研究趨勢。首先研究以中國知網檔案服務創新相關期刊數據為分析對象,經過數據預處理后,利用LDA 模型抽取主題及每個主題下的關鍵詞,再采用Word2vec獲取每個主題下關鍵詞的詞向量,通過加權計算詞向量得到主題向量,進而計算主題相似度與重要度,最后以可視化方法構建主題共現圖譜,分析了現階段的研究方向、研究熱點與其關聯性,同時構建主題演化圖譜,揭示了領域內各階段研究側重點,挖掘出關鍵主題演化路徑與其發展趨勢。主要研究結論如下:
(1)主題共現結果表明,近20 年部分產業依托技術創新完善檔案服務工作,信息化創新是一大熱點,政府部門依托人文與制度創新進行優化和改革。
(2)主題演化結果表明,我國關于檔案服務創新的研究層次越來越豐富,現階段學術科研開始得到重視并逐漸增多,20 年間主要存在兩條關鍵主題演化路徑,分別是高校企業醫院的檔案服務信息化創新與國家檔案部門的建設管理和文化創新。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
今日農業(2019年12期)2019-08-15 00:56:32
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
