一種基于深度學習的移動端隱寫方法
2022-05-06 06:06:24廖鑫黎懿熠歐陽軍林周江盟戴湘桃秦拯
湖南大學學報(自然科學版) 2022年4期
廖鑫,黎懿熠,,歐陽軍林,周江盟,戴湘桃,秦拯?
(1.湖南大學信息科學與工程學院,湖南長沙 410082;2.湖南科技大學計算機科學與工程學院,湖南湘潭 411201;3.中南大學物理與電子學院,湖南長沙 410083;4.長城信息股份有限公司,湖南長沙 410199)
信息時代下,數(shù)據(jù)背后的價值被挖掘顯現(xiàn),人們逐漸意識到信息安全的重要性,并對其提出了更高的要求.在眾多信息保護方法中,隱寫技術(shù)[1]不僅能保障信息本身的安全性,也使得秘密信息的傳遞過程不易被感知.通過隱寫技術(shù),秘密信息被嵌入圖像、音頻和視頻等多媒體載體[2-3].這些多媒體內(nèi)容在嵌密前后幾乎無異,人類無法感知其間細微的變化.如此,秘密信息即可隨著圖像音頻等介質(zhì)一并傳播,實現(xiàn)隱蔽且安全的傳輸.
隱寫兼具安全性和隱蔽性的雙重特性,逐漸成為信息安全領(lǐng)域中的一大研究熱點[4-8].目前已經(jīng)出現(xiàn)了許多圍繞隱寫開展的研究[9],然而其中鮮有針對移動端設(shè)計的隱寫方法.近年來,深度學習技術(shù)被廣泛應(yīng)用于隱寫領(lǐng)域,為進一步挖掘數(shù)據(jù)潛力,模型被設(shè)計得愈發(fā)復雜多變,其訓練和使用需占用更多計算資源.這些大型網(wǎng)絡(luò)難以被應(yīng)用于移動設(shè)備.另外,應(yīng)用市場中的隱寫應(yīng)用大多是基于早期方法的簡單實踐[10],譬如基于LSB 算 法的PocketStego 和Steganography_M.這些應(yīng)用的安全性較低,難以抵抗最常見的攻擊,且極易被偵破,亟須發(fā)展針對移動平臺的高可用性隱寫技術(shù).
隱寫技術(shù)常用于隱蔽通信,而移動設(shè)備則是當今社會中最常用的通信設(shè)備,二者的結(jié)合研究顯得理所當然.早期移動設(shè)備算力的不足阻礙了相關(guān)研究的開展,直到現(xiàn)在硬件技術(shù)的大幅度提升才為這一思路提供了可行平臺.本文提出了一種基于生成對抗網(wǎng)絡(luò)[11]的移動端隱寫方法,通過對抗訓練的方式逐步提高模型的隱寫效果,能將秘密信息嵌入自然圖像中,輸出包含秘密信息的載密圖像.
本文的主要貢獻如下.
1)基于對抗的思想,設(shè)計由編碼器、解碼器和判別器構(gòu)成的整體模型框架,三者在對抗訓練中相互博弈,通過合理的損失函數(shù)進行約束,最終呈螺旋上升式進步,編碼器生成圖像質(zhì)量提升,同時解碼器能更準確地提取并還原秘密信息.
2)以有效和精簡為原則進行網(wǎng)絡(luò)模型設(shè)計,在性能和輕量之間取得較好的折中,減少編碼器和解碼器網(wǎng)絡(luò)層數(shù),同時使用深度可分離卷積進一步減少模型的計算量.與現(xiàn)有的其他深度學習隱寫方法相比,所提出的方法資源占用量更低,且能維持較好的性能.
3)以實用性為出發(fā)點,對所提出的方法進行落地實現(xiàn),并在實際應(yīng)用場景中進行真機測試.對于跨平臺算子改變造成的模型性能下降問題,結(jié)合BCH糾錯碼提高解碼正確率,保障了信息的可靠傳輸,驗證了基于深度學習的隱寫算法在移動端平臺的可行性.
1 相關(guān)工作
1.1 生成對抗網(wǎng)絡(luò)
Goodfellow 提出的生成對抗網(wǎng)絡(luò)(Generative Ad?versarial Networks,GAN)[11],是深度學習中的一種重要算法.一個典型的GAN 模型通常包含生成器和判別器.生成器的目的在于使得生成圖像的分布與自然圖像盡可能類似,讓人無法用肉眼辨別.而判別器的任務(wù)則是辨別輸入圖像是否為生成圖像,其目標和利益恰好與生成器相反.這二者交替進行訓練,其中一方或會率先取得進步,但不久后另一方便會追趕上來.二者的進步迭代交叉,呈螺旋上升的趨勢.
1.2 傳統(tǒng)隱寫與深度學習隱寫
傳統(tǒng)隱寫技術(shù)可以分為自適應(yīng)和非自適應(yīng)兩類.一些非自適應(yīng)的隱寫方法利用信道編碼中的技術(shù)實現(xiàn)矩陣嵌入,譬如一些基于漢明碼和基于方向編碼的矩陣嵌入方法.此外還存在修改區(qū)域可選的矩陣嵌入方法,如濕紙碼[12].與非自適應(yīng)隱寫方法不同,自適應(yīng)隱寫方法會依據(jù)圖像內(nèi)容,有針對性地選擇紋理豐富度更高的區(qū)域進行嵌密.自適應(yīng)隱寫方法常依靠最小失真框架實現(xiàn),譬如經(jīng)典的HUGO[13]和UNIWARD[14]等.嵌入失真代價函數(shù)和STC[15]構(gòu)成了該框架的主要組成部分.
近年來,深度學習興起并進入了快速發(fā)展的階段[16–18],其相關(guān)技術(shù)被引入隱寫領(lǐng)域,與傳統(tǒng)隱寫方法碰撞出一些新的研究方法.Hayes 等人結(jié)合深度學習,提出包含Alice、Bob 和Eve 三個子網(wǎng)絡(luò)的隱寫模型[19],輸出的載密圖像與原始圖像具有較高相似性.Zhu 等人側(cè)重考慮魯棒性,在所提出的HiDDeN[20]中增加噪聲層,用以模擬JPEG 壓縮和各類噪聲,從而提升魯棒性,但其存在嵌密量較低的缺點.Bernard等人提出的方法中[21],隱寫方可以使用對抗樣本和動態(tài)STC 等工具用以嵌密,而隱寫分析方則擁有許多分析方法,雙方模擬對抗游戲,使得模型收斂并獲得一種高效的隱寫算法,充分挖掘了經(jīng)典隱寫方法的安全性.
1.3 移動端隱寫應(yīng)用
目前的研究中,針對移動設(shè)備的較少,且現(xiàn)有的移動端應(yīng)用大多是基于傳統(tǒng)方法的實踐[10],譬如LSB 算法及其變型和F5 算法等.這些移動端隱寫方法不足以抵擋現(xiàn)在的隱寫分析技術(shù),存在安全性較低的問題.在自適應(yīng)隱寫上,Su 等人[22]提出了基于J-UNIWARD 的移動端隱寫,其安全性有所提高.近年來出現(xiàn)的基于深度學習的隱寫方法大多存在體量較大的問題.盡管隨著硬件設(shè)備的發(fā)展,移動設(shè)備的算力提升且內(nèi)存增加,但這些大體量的隱寫方法仍會占用設(shè)備的大量資源,無法滿足移動端及時響應(yīng)的需求.
2 基于GAN的移動端隱寫方法
2.1 模型結(jié)構(gòu)
隱寫分析是與隱寫對立的技術(shù),可用于分析圖像中是否包含秘密信息[23].隱寫與隱寫分析之間的對抗和GAN 中生成器與判別器之間的對抗十分相似,因此GAN 能被自然地運用到隱寫任務(wù)中.所提出的移動端圖像隱寫方法綜合考慮了發(fā)送者和接收者的應(yīng)用需求,由生成器、解碼器和判別器三個部分組成,如圖1 所示.向生成器輸入載體圖像IC和待嵌入信息,經(jīng)處理后即可輸出載密圖像IS.解碼器的目的則是從載密圖像IS中提取并還原秘密信息.判別器則發(fā)揮著隱寫分析的作用.

圖1 基于GAN的移動端隱寫方法整體結(jié)構(gòu)Fig.1 Structure of mobile steganography based on GAN
拍攝的原始圖像和秘密信息需經(jīng)歷一番轉(zhuǎn)換才能輸入生成器.首先將秘密信息按ASCII 碼轉(zhuǎn)換為01 串,然后將其變形為三維矩陣并擴展為與載體圖像相同長寬的形狀,這樣便能在通道維度將二者拼接為一個整體.此處的擴展操作通過反卷積實現(xiàn),而非全連接,這樣可以很大程度上減少計算量.生成器對該整體提取特征,從而獲得載密圖像.生成器的網(wǎng)絡(luò)結(jié)構(gòu)啟發(fā)自U-Net[24],先利用卷積進行下采樣,逐步縮小特征圖大小,并獲得多尺度特征;而后進行反卷積上采樣,同時級聯(lián)之前獲得的特征,輸出特征圖逐漸恢復為原始大小,并在最后作為殘差圖像輸出.將殘差圖像與載體圖像相加,即可得到載密圖像.該模型較好地結(jié)合了淺層、深層信息,有利于更好地感知圖像信息,從而生成圖像質(zhì)量更好的載密圖像.考慮到應(yīng)用場景是移動端,在部署模型時,可將模型中的標準卷積更換為深度可分離卷積,從而減小網(wǎng)絡(luò)計算量.不同嵌密量的生成器網(wǎng)絡(luò)有著微小的區(qū)別,在圖2中可以看到20 000 bit嵌密量下的生成器結(jié)構(gòu).
解碼器網(wǎng)絡(luò)是類似漏斗形的結(jié)構(gòu),它由多層卷積組成,每層輸出特征圖大小逐漸減小,提取關(guān)鍵特征以還原秘密信息,并期望最后解碼的信息與原始秘密信息M盡可能一致,如圖2 所示.在訓練階段本文使用隨機01 串模擬秘密信息,在部署運用時則結(jié)合BCH糾錯碼以提高解碼正確率.
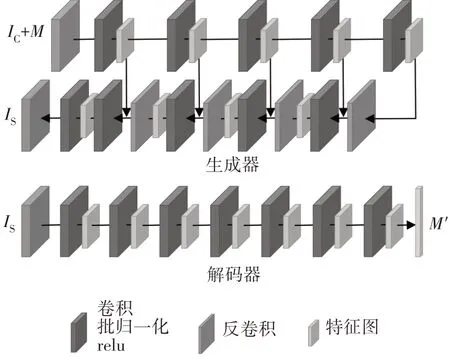
圖2 生成器和解碼器的網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Generator and decoder networks
判別器作為一個二分類器,發(fā)揮了類似隱寫分析器的作用,目的是督促生成器輸出圖像質(zhì)量更好的載密圖像,提高安全性.在本工作中,使用Ye-Net[25]作為判別器.Ye-Net 是2017 年由Ye 等人提出的基于深度學習的隱寫分析器,它是現(xiàn)在最先進的隱寫分析方法之一.
2.2 損失函數(shù)
生成器與解碼器作為一個小整體,與判別器交替進行訓練,二者相互促進,直到達到納什均衡點.判別器的損失函數(shù)設(shè)計如下:

式中:IS表示載密圖像,Ye-Net(IS)表示載密圖像通過Ye-Net 后得到的評判結(jié)果.解碼器使用交叉熵損失函數(shù)進行約束,損失函數(shù)表示如式(2).

式中:Mi表示秘密信息,表示提取的秘密信息,CrossEntropy 是交叉熵損失計算.生成器的損失函數(shù)包括圖像損失和安全性評估,如式(3)~式(5).


式中:IC表示載體圖像,PSNR(IC,IS)和SSIM(IC,IS)分別表示載體圖像與載密圖像之間的峰值信噪比和結(jié)構(gòu)相似性,τ、α以及β是計算參數(shù),數(shù)值分別為0.01、1和0.5.
通過損失函數(shù)約束,生成器網(wǎng)絡(luò)逐步趨向于輸出質(zhì)量更好的載密圖像,它與載體圖像在肉眼觀察中難以進行區(qū)分,且不易被隱寫分析器檢測出來.同時,解碼器的解碼能力亦趨向于提升.
2.3 輕量化處理
本工作的應(yīng)用場景為移動端,這要求網(wǎng)絡(luò)模型在滿足精度的同時,盡可能輕量化.本文嘗試利用所提出的隱寫方法構(gòu)建安卓應(yīng)用,所得到的APK 安裝包大小約20.9 MB.以同樣的方法嘗試對Stega?Stamp[26]和Hayes 等人的方法[19]進行構(gòu)建,獲得了大小分別為400 MB 和848 MB 的APK 安裝包.由此可以直觀地感受到所提出的模型具有較高的輕巧性.
此外,本文還針對資源不足的設(shè)備,提出了進一步的輕量化改進方法.實驗中將標準卷積替換為深度可分離卷積,以期減少模型計算量.深度可分離卷積采用先分后合的結(jié)構(gòu),首先按單個通道分別進行卷積,這樣能大大減少所需的參數(shù)量;而后將這些輸出合并再執(zhí)行1×1 卷積.后者可在通道維度上進行學習,彌補了單通道卷積的不足.
優(yōu)化后的模型可以從文件大小上直觀感受到模型體量明顯下降.包含有生成器與解碼器的模型文件由原先的4 087 kB縮小到了2 122 kB,APK文件則從20.9 MB 縮小到14.7 MB.進一步地,對模型的計算復雜度進行量化評估.對于深度可分離卷積,其計算量可以表示為式(6).

式中:m和n分別表示輸入和輸出特征圖的通道數(shù),Lk和Lout分別是卷積核和輸出特征圖的邊長.輕量化后的隱寫方法體量明顯降低,且計算量減少到原本的19.24%.在低算力的移動設(shè)備上,可以選擇部署輕量化后的隱寫模型,這將有益于減少設(shè)備的計算壓力,且將性能維持在較好的水平;而對于資源豐富的設(shè)備,可以選擇使用原始隱寫模型以獲得更佳的性能體驗.
3 實驗
3.1 實驗設(shè)置
考慮到移動端相機獲取的圖像大多數(shù)是JPEG格式,所以本方法中沒有使用隱寫任務(wù)常用的無損圖像數(shù)據(jù)庫,而是使用mirflickr25k數(shù)據(jù)集.該數(shù)據(jù)集由25 000 張JPEG 格式的圖像組成,囊括多種分類標簽,比如clouds、male和food等.本文的實驗中將數(shù)據(jù)集分為兩部分,其中20 000 張圖作為訓練集,5 000張圖作為測試集.模型訓練在NVDIA GeForce RTX 2080 Ti GPU 上完成,并使用了Adam 優(yōu)化器幫助收斂.
3.2 隱寫圖像質(zhì)量和解碼準確率
將所提出的隱寫方法與兩個基準方法Stega?Stamp[26]和ReDMark[27]進行對比,其結(jié)果如表1所示.本文方法在圖像質(zhì)量指標SSIM 和PSNR 上均優(yōu)于其他方法,表現(xiàn)出較好的性能.解碼準確率也更高,達到了99.37%.在體量方面,模型文件大小與模型計算參數(shù)量相關(guān).本文方法可對400×400 像素的圖像進行信息嵌入,與StegaStamp 方法的輸入圖像大小一致.在此同一量級的對比中,本文模型更輕巧,模型文件大小僅為StegaStamp 方法的五分之一.而相較于處理圖像僅為32×32 像素的ReDMark 方法,盡管本文方法處理的圖像更大,但模型中的輕量化處理使參數(shù)量大大減少,本文模型文件甚至更小一些.

表1 StegaStamp[26]、ReDMark[27]與本文方法的對比Tab.1 Comparison with StegaStamp[26]and ReDMark[27]
這里可以對上述結(jié)果作進一步的解釋說明.StegaStamp方法中使用噪聲層模擬各類噪聲、壓縮和色彩失真攻擊,從而獲得較高的魯棒性.但噪聲層的引入會導致一定程度的圖像質(zhì)量下降.相較于Stega?Stamp,本文的方法更注重于移動端的通信能力,選擇將重點放在提升圖像質(zhì)量與嵌密量上.因此所提出的方案剔除了噪聲層的干擾,從而使圖像在視覺效果上更為清晰.文中引入PSNR 和SSIM 對圖像質(zhì)量進行評估.其中,PSNR 表示信號最大值與背景噪聲之間的比例大小,當噪聲大幅度降低后,該指標獲得顯著提升.而在結(jié)構(gòu)相似性方面,由于隱寫任務(wù)對圖像結(jié)構(gòu)的改變較少,該項指標的提高不甚明顯.此外,在模型體量上,本文舍棄了全連接層,結(jié)構(gòu)層次也更淺,因此模型更為輕巧,甚至在提升嵌密量后亦能保持較低的模型體量.體量上的優(yōu)勢將有益于模型在移動端的部署,同時也有助于取得更快的響應(yīng)速度.
對于深度學習方法,模型嵌密量的改變意味著模型結(jié)構(gòu)的變動和性能的下降.為了維持方法原有的優(yōu)良特性,同時盡可能公平地進行性能對比,本文在后續(xù)實驗中將ReDMark 處理的數(shù)據(jù)進行拼接處理.將多個32×32像素的處理圖像拼接為384×384像素的圖像,從而與處理圖像為400×400 像素的Stega?Stamp 和本文方法構(gòu)成同一量級.在嵌密量指標上,經(jīng)過拼接處理的ReDMark方法可達到6 912 bit.根據(jù)圖像質(zhì)量、魯棒性和嵌密量三指標平衡規(guī)律,信息隱藏方法的嵌密量越高,其另外兩項指標將更難以提升.本文方法的嵌密量高于對比方法,在此“劣勢”中進行對比,更可顯現(xiàn)本文方法在圖像質(zhì)量和輕量性質(zhì)中的優(yōu)越性.
訓練完畢并通過初步測試的模型可以借助支持庫部署在移動端.首先將模型轉(zhuǎn)換輸出獲得pb 格式的模型文件,再結(jié)合從TensorFlow 源碼編譯的libten?sorflow_inference.so 和libandroid_inference.jar 庫 文件,即可在安卓端進行模型調(diào)用.在安卓工程的使用中,圖像的讀入讀出會帶來一定程度的圖像質(zhì)量損失,這一問題主要表現(xiàn)為解碼準確率下降.為了緩解這一問題,本文在安卓工程中引入了BCH糾錯碼.輸入圖像類型仍是JPEG 格式,而輸出類型則選用PNG格式,以盡可能降低錯誤率.結(jié)合BCH 的糾錯能力,隱寫應(yīng)用能基本正確地還原秘密信息,且圖像質(zhì)量良好,見圖3.

圖3 移動端隱寫應(yīng)用中載體圖像和載密圖像的對比Fig.3 Comparison between stego and cover in proposed mobile steganography APP
3.3 模型運行時間測試
模型運行的速度與內(nèi)存大小、CPU 等硬件設(shè)備相關(guān),且不同的耗電狀態(tài)和系統(tǒng)資源管理策略也會對計算速度帶來不同程度的影響.本文通過改變安卓模擬器的CPU 核數(shù)和內(nèi)存大小,來模擬不同的CPU性能和內(nèi)存狀態(tài),如表2所示.作為對比,實驗中公平地將對比模型打包并轉(zhuǎn)換,然后結(jié)合編譯獲得的支持庫,以類似的安卓代碼部署在移動端.在同等條件下,本文方法展現(xiàn)了更佳的反應(yīng)速度.尤其在內(nèi)存資源較為匱乏的情況下,這種優(yōu)越性更為明顯.在僅使用1 核CPU 和2G 內(nèi)存的情況下,所提出的方法比StegaStamp 用時少了32.4%,且遠小于ReDMark 用時.而在1 G 的內(nèi)存下,StegaStamp 模型甚至會無法正常運行,提示內(nèi)存不足然后閃退.ReDMark 方法所處理的圖像較小,單次運行負擔較小,但這同時帶來了更多頻次的處理,總體用時反而較長.

表2 在不同情況下的模型運行時間Tab.2 Model runtime in different situation
模型的運行速度受許多因素的影響,而其中影響較大的因素是CPU 的性能.如表2 所示,在同等CPU 核數(shù)下,1 G、2 G 和4 G 內(nèi)存之間的運行時間差距較小,而在不同核數(shù)下的差異較大.為進一步探討CPU 性能與模型運行時間之間的關(guān)系,本文將模擬器的內(nèi)存固定為4 G,同時改變模擬器的CPU核數(shù)進行實驗,如圖4 所示.在不同CPU 核數(shù)下,本文方法運行用時均小于StegaStamp.當CPU 核數(shù)低于4 核時,移動端算力不足,執(zhí)行并發(fā)度較低,因此運行用時在很大程度上受模型計算量的影響.此狀態(tài)下,計算量更低的本文方法可占據(jù)較大的優(yōu)勢.當CPU 核數(shù)上升到4 核后,設(shè)備資源相對充裕,兩者的模型均能在較短時間內(nèi)完成運算,因此差異較小.此狀態(tài)下,兩個模型的運行耗時都趨于穩(wěn)定平緩.而在該穩(wěn)定狀態(tài)下,本文方法仍保有一定的優(yōu)勢.

圖4 不同CPU核數(shù)下運行模型所需時間Fig.4 Model runtime with different CPU cores
3.4 運行模型的內(nèi)存占用情況
除了運行時間外,本文對模型的內(nèi)存占用情況進行了實驗和記錄.為了便于觀察,本文固定在同一環(huán)境下進行多次內(nèi)存占用測試.所用的安卓模擬器被設(shè)置為1 核CPU 且內(nèi)存為4 G.受設(shè)備狀態(tài)和內(nèi)存回收機制等因素的影響,測試結(jié)果常會上下浮動.在多次模型調(diào)用的過程中,內(nèi)存占用往往先上升至一個峰值,然后再陡然下降并最終趨于平緩,且平緩時內(nèi)存占用值比模型調(diào)用前更高一些.基于這一觀察,在實驗中分別統(tǒng)計了調(diào)用模型時的內(nèi)存占用峰值和內(nèi)存占用穩(wěn)定值作為結(jié)果,見表3.在移動場景下,不論是內(nèi)存占用峰值還是穩(wěn)定值,本文方法對內(nèi)存資源的消耗均遠低于StegaStamp.其內(nèi)存占用穩(wěn)定值平均為37.87 MB,完全可以滿足移動設(shè)備的使用要求,甚至能在低內(nèi)存的設(shè)備上正常使用.這將有助于在更輕巧的設(shè)備上部署該模型,如小型相機等.

表3 運行模型占用的內(nèi)存Tab.3 Memory occupation when running models
3.5 真機測試
在實際應(yīng)用場景下,本文選用了三種常見的智能移動設(shè)備進行真機測試,包括榮耀30、小米10 Lite和榮耀9.三個移動設(shè)備的狀態(tài)各不相同,其中前兩者使用時長不超過一年,而榮耀9 使用了近四年.真機實驗測試的內(nèi)容包括模型運行時間和解碼正確率,如表4 所示.其中,本文將圖像讀寫帶來的損失納入考察范圍,測試重載入圖像的解碼正確率,并記為重載入.實驗表明,所提出的隱寫模型在真機實驗中亦具有較好的性能,響應(yīng)及時.即便是使用近四年的舊機型也能在1.7 s 內(nèi)輸出結(jié)果,具有較高的使用普適性.

表4 真機運行模型的用時及正確率Tab.4 Runtime and accuracy test on real devices
4 結(jié)論
本文針對移動端展開研究,結(jié)合深度學習設(shè)計了一種輕量化的隱寫模型.具體工作中結(jié)合生成對抗網(wǎng)絡(luò)的思想,直接由網(wǎng)絡(luò)輸出載密圖像.針對移動端的使用,對網(wǎng)絡(luò)結(jié)構(gòu)進行了改進,舍棄對全連接層的使用,并用深度可分離卷積替換標準卷積,從而降低網(wǎng)絡(luò)體量并減少計算量.在部署時,出現(xiàn)解碼器性能下降的問題.對此,使用BCH糾錯碼矯正解碼錯誤比特,從而實現(xiàn)秘密信息的正確提取.實驗結(jié)果表明,所提出的隱寫模型在移動端具有較好的表現(xiàn),能滿足一般的移動端隱寫需求,填補了在移動端深度學習隱寫研究上的空缺.
從結(jié)果上看,所設(shè)計的隱寫應(yīng)用能為安全相關(guān)從業(yè)人員提供更便利的隱蔽通信方法.在未來的工作中,擬針對移動端使用時的性能下降問題開展相關(guān)研究,期望在保持較小的計算量下,盡可能提升隱寫性能,尤其是生成圖像的質(zhì)量.這要求在輕量化中盡可能保留對隱寫性能影響較大的組成部分,而刪去無關(guān)緊要的分支,具體細節(jié)還有待進一步的研究.
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2020年11期)2020-12-14 06:59:52
藝術(shù)品鑒證.中國藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國藝術(shù)金融(2018年12期)2018-08-26 06:03:48
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
