HCGAN:一種基于GAN 的高容量信息隱藏算法
2022-05-06 06:06:26張克君李旭于新穎馮麗雯秦昊聰張健毅
湖南大學學報(自然科學版) 2022年4期
張克君,李旭,于新穎,馮麗雯,秦昊聰,張健毅
(1.北京電子科技學院網絡空間安全系,北京市 100071;2.北京郵電大學網絡空間安全學院,北京市 100876)
隨著網絡信息技術的快速發展和移動終端設備的不斷普及,數字多媒體成為互聯網通信的主要載體.數字多媒體的廣泛應用使得網絡中充斥著大量對國家、企業或個人而言十分敏感的信息.為保證這些信息能被安全地傳遞,發送方通常需要對信息進行加密,同時加密后的密文只能被持有特定密鑰的接收者解密,但密文的偽隨機性會暴露秘密信息的存在,從而引來攻擊者的懷疑和攻擊.信息隱藏技術通過將敏感的秘密信息偽裝成普通信息來隱藏秘密信息,為上述問題提供了解決方案,對信息安全有著重要意義[1].
在信息隱藏過程中,發送方首先將秘密信息嵌入載體中形成含秘載體,隨后把含秘載體上傳到公共信道[2].特定的接收方從公共信道中下載含秘載體,使用密鑰或提取算法從中提取出秘密信息.在秘密信息的傳遞過程中,除了通信雙方之外,其他人雖然可以下載含秘載體但無法獲取其中的秘密信息.信息隱藏技術的這種隱蔽性能夠有效阻止攻擊者對秘密信息的感知和破壞,進而保證了秘密信息在傳遞過程中的安全[3].
信息隱藏技術和加密技術的結合既防止了秘密信息的存在被知曉,又保護了秘密信息的內容,但仍不能保證秘密信息的絕對安全.發送方在嵌入秘密信息時會不可避免地對載體造成干擾,隱寫分析就可以對這些干擾進行分析并判斷出載體是否含有秘密信息.信息隱藏和隱寫分析互為對手,在相互對抗中不斷發展進步.為了對抗隱寫分析,信息隱藏已經從早期的最低有效位(Least Significant Bit,LSB)替換算法[4]發展到現在根據載體內容來嵌入秘密信息的自適應信息隱藏算法.在不斷進步的信息隱藏技術的推動下,隱寫分析也很快實現了從專用到通用,從低維特征到高維特征的跨越.
不斷進步的隱寫分析算法雖然促進了信息隱藏算法的發展,卻對信息隱藏技術的安全性提出了挑戰.近年來,深度學習技術在運算速度更快的硬件支持下迅速發展,不斷涌現出各種網絡模型.深度置信網絡[5]及反向傳播算法的提出更是推動了深度學習技術在計算機視覺、自然語言處理和自動駕駛等領域的發展.深度學習強大的學習能力和特征表達能力,使得隱寫分析算法的設計不再需要豐富的專業知識.在基于深度學習的隱寫分析算法被提出之后,隱寫分析對含秘載體的檢測能力越來越強,這迫使信息隱藏領域的研究者開始研究更加安全的信息隱藏算法.
在對信息隱藏技術的探索中,Goodfellow 等人于2014 年提出的生成對抗網絡[6](Generative Adver?sarial Networks,GAN)受到了信息隱藏技術研究者的關注.GAN 包含兩個神經網絡,其中一個網絡能夠生成符合真實樣本分布的生成樣本,另一個網絡用來區分真實樣本和生成樣本,這兩個網絡互相對抗并交替訓練.GAN 這種對抗博弈的方法和信息隱藏技術與隱寫分析算法互相對抗并不斷發展的情況十分相似,因此信息隱藏技術的研究者期望將GAN 用于信息隱藏中以得到更強的安全性和更高的隱寫容量.迄今為止,基于GAN 網絡的信息隱藏算法并沒有完全實現上述目標,它們在隱寫容量、安全性和秘密信息提取準確率等方面還存在不足.因此,研究基于GAN 的信息隱藏技術并使其在隱寫容量和安全性等方面獲得提升有著重要的實際意義.
本文提出了一種新的基于GAN 的高容量信息隱藏算法(HCGAN).該算法能夠在高容量的情況下保持較高的秘密信息提取率,并且有較強的抗隱寫分析能力.HCGAN 算法由三部分組成:①基于Im-Residual結構的編碼器,發送方能夠通過編碼器將秘密信息嵌入載體圖像中形成隱秘圖像;②基于稠密結構的解碼器,接收方可以通過解碼器將秘密從隱秘圖像中提取出來;③基于隱寫分析的鑒別器,用來進行對抗性訓練以提高隱秘圖像的抗隱寫分析能力.本文的主要貢獻如下:
1)提出了基于Im-Redisual 結構的編碼器,其中Im-Residual 結構是基于Residual 結構進行優化所形成的,Im-Residual 結構的編碼器采用多次嵌入的思想能夠降低秘密信息因特征提取而產生的信息損失,從而提高秘密信息提取率.
2)設計了基于稠密結構的解碼器,利用Dense結構特征復用的能力提取出更多有用特征,以進一步提高解碼器的秘密信息提取率.
3)提出了一種基于隱寫分析的鑒別器,通過GAN 的對抗訓練思想進一步提升HCGAN 信息隱藏算法的抗隱寫分析能力.
1 相關工作
1.1 經典的信息隱藏算法
根據所使用的方法不同,信息隱藏技術可以分為經典的信息隱藏算法和基于深度學習的信息隱藏算法.
最低有效位替換算法作為早期的信息隱藏算法,只對像素中最不影響圖像視覺效果的最低有效位進行修改[4].LSB 替換算法能保證載體的視覺質量,但在嵌入過程中沒有考慮載體的統計特征.因此,隱寫分析算法可以輕易地根據直方圖異常等特征識別出通過LSB 替換算法獲得的含秘載體.像素值差分[7](Pixel Value Differencing,PVD)使用兩個連續像素之間的差來表示秘密信息,比LSB 替換算法更安全,但是也存在統計特征的異常.此后,研究者們設計信息隱藏算法時就注意保持某些統計特征不變.LSB 匹配算法對LSB 替換技術進行改進,如果秘密比特和載體圖像的LSB 不匹配,則在相應的像素值上隨機加減1[8].隨機加減1 的方法可以保持載體圖像的統計直方圖不變,但最低位和次低位的統計特征異常仍會使LSB匹配算法不夠安全[8].除了可以在空間域嵌入秘密信息以外,也可以在各種變換域嵌入秘密信息.離散余弦變化(Discrete Cosine Trans?form,DCT)就是一種變換域.與傅立葉變換類似,DCT 可以將圖像從空間域轉換到頻率域.JPEG 格式的圖像就使用了DCT,其對每個顏色成分使用余弦變換來將大小為8×8的連續像素塊轉換為64個余弦系數.JSteg[9]、OutGuess[10]等方法都是在DCT 的基礎上嵌入秘密信息的信息隱藏算法.
信息隱藏算法能夠根據載體內容自適應地嵌入秘密信息來提高算法的安全性.2010 年,Pevny 等人[11]提出的HUGO 就是一種自適應的信息隱藏算法.HUGO 首先通過嵌入信息對載體圖像的影響來定義失真函數,隨后使用加權范數函數將像素空間壓縮為特征空間,并在失真函數最小的位置嵌入秘密信息[11].2012年,Holub等人[12]提出的WOW(Wavelet Obtained Weights)算法可以根據圖像內容在紋理復雜的區域嵌入更多的信息.2014 年Holub等人[13]提出的S-UNIWARD 算法是一種與嵌入域無關的通用失真函數.雖然HUGO、WOW 和SUNIWARD的失真函數各不相同,但三個算法的最終目的都是通過最小化失真函數來自適應地嵌入秘密信息.此后提出的經典的信息隱藏算法或是改進失真函數[14],或是改進隱寫編碼[15].這些改進雖然提高了信息隱藏的安全性,但對信息隱藏算法的隱寫容量提高非常有限.
1.2 基于深度學習的信息隱藏算法
基于深度學習的信息隱藏算法被提出后,經典信息隱藏算法的安全就面臨著嚴重的威脅.將深度學習應用于信息隱藏領域以對抗基于深度學習的隱寫分析算法成為信息隱藏領域中新的研究方向.特別是生成對抗網絡,其優秀的圖像生成能力和博弈對抗的思想引起了信息隱藏領域研究者們的關注.
2017 年,Hayes 等人[16]提出將GAN 與信息隱藏相結合的Ste-GAN-ography算法.該算法使用三個普通的神經網絡分別作為嵌入秘密信息的生成器、提取秘密信息的提取器和進行隱寫分析的鑒別器,訓練過程和一般的生成對抗網絡相同.2017 年,Tang等人[17]提出了ASDL-GAN 算法.該算法首先學習一個概率映射矩陣來為秘密信息尋找合適的嵌入位置,然后使用傳統的STC方法嵌入秘密信息.Yang 等人[18]在ASDL-GAN 的基礎上進行改進,使用Tanhsimulator激活函數、基于U-NET[19]的生成器和SCA[20]判別器來減少訓練時間并增強抗隱寫分析能力.Liu等人[21]于2018年提出了一種直接使用ACGAN生成器進行無載體信息隱藏的Stego-ACGAN 算法.該算法通過建立圖像類別與文本之間的映射字典,將秘密信息表示為圖像類別信息,然后將圖像類別信息輸入生成器生成含秘圖像,從而實現無載體的信息隱藏[21-22].2019 年,Zhang 等人[23]提出一種基于約束采樣的含密載體生成方法.該方法首先訓練一個生成器,然后通過數字化卡登格子對生成器進行約束采樣,以獲得滿足條件的含密圖像.
自2017 年提出在載體圖像中隱藏秘密圖像的應用場景后,圖像信息隱藏這一方向迅速成為信息隱藏領域的研究熱點[24].2017 年,Baluja 等人[24]提出使用神經網絡在圖像中尋找合適的位置并嵌入秘密圖像信息.該方法對編碼過程進行訓練,將整個秘密圖像嵌入載體圖像中并使秘密圖像信息分散到圖像的每個比特中.2018 年,Zhang 等人[25]提出將封面圖像分為Y、U、V 三個通道,并通過編碼器將灰度化的秘密圖像隱藏到封面圖像的Y 通道中.2020年,Duan等人[26]提出了一種結合圖像橢圓曲線密碼學和深度學習的大容量信息隱藏算法.該算法利用離散余弦變換對秘密圖像進行變換,再用橢圓曲線密碼術對變換后的圖像進行加密,最后使用SegNet[27]網絡來隱藏和提取秘密信息.
圖像信息隱藏算法帶來的高隱寫容量是在損失部分秘密圖像數據的前提下達成的.這些算法之所以能隱藏秘密圖像信息,是因為圖像能夠在損失部分數據后不影響信息的呈現.如果要隱藏較多的文本或其他類型的秘密信息,使用現有的圖像信息隱藏算法會導致較低的秘密信息提取準確率和較弱的抗隱寫分析能力.
本文對圖像信息隱藏算法進行研究后發現引起秘密信息損失的主要原因是卷積層只能提取有限特征.因此,本文設計了基于Im-Redisual 結構的編碼器,通過減少編碼過程中的信息損失來提高秘密信息提取率.本文利用基于稠密結構的解碼器和基于隱寫分析的鑒別器分別來提高秘密信息提取率和抗隱寫分析能力.
2 基于GAN的高容量信息隱藏算法HCGAN
為解決信息隱藏算法存在的隱寫容量低和抗隱寫能力弱的問題,本文提出了一種基于GAN 的高容量信息隱藏算法(HCGAN).如圖1 所示,HCGAN 算法主要由三部分組成:基于Im-Residual 結構的編碼器、基于稠密結構的解碼器和基于隱寫分析的鑒別器.基于Im-Residual 結構的編碼器將輸入的秘密信息和載體進行編碼以得到含秘載體.發送方得到含秘載體后將其上傳到公共信道中.接收方從公共信道中獲得含秘載體后,使用基于稠密結構的解碼器從含秘載體中解碼出秘密信息.基于隱寫分析的鑒別器的任務是區分含秘載體和普通載體,并在訓練時提供梯度以優化基于Im-Residual 結構的編碼器.需要注意的是,基于隱寫分析的鑒別器只在模型訓練時使用.模型只需使用基于Im-Residual 結構的編碼器和基于稠密結構的解碼器就可以完成秘密信息的傳遞.本節將詳細介紹HCGAN 模型的三個組成部分及其總體架構,并描述其訓練過程.

圖1 基于GAN的高容量信息隱藏模型的整體框架Fig.1 Overall framework of high capacity information hiding model based on GAN
2.1 基于Im-Residual結構的編碼器
為提高模型的隱寫容量,本文在殘差網絡結構的基礎上進行改進,得到了一種被稱為Im-Residual的網絡基礎結構.Im-Residual 結構通過增加秘密信息的直接映射來減少秘密信息在特征提取過程中的損失.基于Im-Residual 結構的編碼器更適用于信息隱藏,并且能夠增加載體中可以嵌入的秘密信息.
編碼器的目標是將秘密信息安全地嵌入載體圖像中,從而方便解碼器從中提取出秘密信息.如圖2(a)所示,基于深度學習的信息隱藏算法的編碼器一般使用多個基礎卷積層+LeakyReLU 激活函數+BN 層結構作為卷積神經網絡.因為卷積神經網絡是通過卷積核提取特征,再將提取出來的特征歸一化處理后作為下一個卷積核的輸入,所以在此過程中不可避免地會因為提取特征而損失信息.對圖像類型的秘密信息而言,損失一部分不重要的信息是可以接受的,并且不會影響秘密信息內容的傳遞.但是對于其他類型如文本類型的秘密信息而言,損失一部分信息是不可接受的.因此,為了使編碼器結構能適用于其他類型的秘密信息,Kevin A.Zhang 等提出使用Dense 結構的卷積神經網絡來降低編碼器對于信息的損失,如圖2(b)所示.但Dense 結構也會導致輸入增加,進而增加需訓練的參數[28].
在研究和分析了Dense結構之后,我們發現其能減少信息損失的核心原因不是Dense 結構帶來的特征的多次重復使用,而是對秘密信息的多次嵌入.因此,本文提出了基于Im-Residual 結構的編碼器,如圖2(c)所示.在殘差結構的基礎上通過短路多次嵌入秘密信息,優化了編碼器模型,減少了約1/3 的訓練參數,最終得到了更優的提取率和視覺性能.Dense 結構和Im-Residual 結構的參數對比如表1 所示,表中D為嵌入率.

圖2 三種編碼器對比圖Fig.2 Comparison of three encoders

表1 Dense結構和Im-Residual結構的參數對比Tab.1 Comparison of parameters between Dense structure and Im-Residual structure
在本文中,基于Im-Residual 結構的編碼器通過Im-Residual 結構的卷積神經網絡將秘密信息嵌入載體圖像中以得到含秘圖像,如公式(1)所示:

式中:C為W×H×3的彩色載體圖像,M∈{0,1}D×w×H為將要嵌入的秘密信息,S為W×H× 3的彩色含秘圖像.
2.2 基于稠密結構的解碼器
在基于Im-Residual 結構的編碼器將更多的秘密信息嵌入載體中之后,如何從含秘載體中更好地提取出秘密信息就成了后續研究的重點.Im-Residual 結構可以使用更少量參數完成將少量信息嵌入圖片等含有大量信息的載體中,以減少過擬合風險并完成編碼器工作.但在需要從大量信息中提取出少量信息的解碼器場景中,Im-Residual 結構就無法提供足夠的信息供后續網絡層使用.因此為提高解碼器的提取能力,本文設計出了一種基于稠密結構的解碼器.稠密連接網絡中每一個網絡層輸出的特征映射會直接疊加到后面網絡層的輸入中,以實現特征的復用.特征的復用保證了后面網絡層的信息總是多于前面網絡層的信息.基于稠密結構的解碼器就是利用稠密結構特征復用的能力對含秘載體的特征進行多次處理以提高秘密信息的提取準確率.
基于深度學習的信息隱藏算法的解碼器使用的也是基本的卷積層+LeakyReLu+BN 層結構,如圖3(a)所示.然而,網絡層數的增加會帶來信息損失的問題.稠密結構通過將卷積層提取出的特征疊加在之后所有的卷積層的輸入中,來實現各層特征的復用并降低信息的損失.因此,本文設計出基于稠密結構的解碼器來對含秘圖像中的秘密信息進行提取,如圖3(b)所示.實驗結果顯示基于稠密結構的解碼器在高容量的信息隱藏算法中表現出更優的秘密信息提取率,并能指引編碼器實現更優的視覺效果.

圖3 兩種解碼器對比圖Fig.3 Comparison of two decoders
本文模型將基于Im-Residual 結構的編碼器和基于稠密結構的解碼器組合起來形成了一種自編碼器.這種自編碼器能夠實現高隱寫容量的信息隱藏,其過程如公式(2)所示:

式中:E(C,M)代表W×H×3的彩色含秘圖像,是基于稠密結構的解碼器從含秘圖像中提取出的秘密信息,D為嵌入率,表示我們想要在載體圖像的每個像素中嵌入的秘密信息比特數.
2.3 基于隱寫分析的鑒別器
基于Im-Residual 結構的編碼器和基于稠密結構的解碼器所構成的自編碼器能夠實現高隱寫容量的信息隱藏,但是在含秘圖像中嵌入大量的秘密信息會導致其抗隱寫分析能力降低.因此,為了提高含秘圖像的抗隱寫分析能力,本文提出了基于隱寫分析的鑒別器.該鑒別器利用其鑒別結果和GAN 的對抗性來訓練編碼器,從而生成更安全的含秘圖像.
本文在XuNet 的基礎上進行改進,使用全部的SRM濾波核和KV核作為預處理層,并在模型訓練時將SRM 濾波核的參數固定.相比于KV 核,使用全部的SRM濾波核能夠提供更多的噪聲信息以便后面的神經網絡進行特征提取和分類.為了適用于彩色含秘圖像,本文在對含秘圖像進行分析前加入了灰度層來將彩色含秘圖像變為灰度含秘圖像,以便后續的處理.基礎的鑒別器和本文提出的基于隱寫分析的鑒別器對比圖如圖4所示.

圖4 兩種鑒別器對比圖Fig.4 Comparison of two discriminators
利用GAN 的對抗博弈能力,本文提出的基于隱寫分析的鑒別器和基于Im-Residual 結構的編碼器實現了相互對抗并且相互提供梯度,最終提高了基于Im-Residual 結構的編碼器輸出含秘圖像的抗隱寫分析能力.在訓練過程中,我們將含秘圖像或載體圖像輸入基于隱寫分析的鑒別器得到對應的鑒別結果,如公式(3)所示:

式中:C表示尺寸為3 ×W×H的彩色載體圖像,M表示需嵌入的秘密信息,p表示分類結果,一般用輸入圖像是載體圖像的概率來表示.
2.4 HCGAN的整體架構和損失函數設計
將基于Im-Redisual 結構的編碼器、基于稠密結構的解碼器和基于隱寫分析的鑒別器組合起來就是本文提出的HCGAN 算法的整體架構,如圖5 所示.其中,⊕代表像素相加.首先,發送者將秘密信息M和彩色載體圖像C輸入編碼器網絡來得到隱秘圖像S.之后,接收者將隱秘圖像S輸入解碼器網絡得到解密后的信息.基于隱寫分析的鑒別器僅在訓練時使用,用來判斷S或C是否為隱秘圖像,并通過對抗性訓練優化編碼器網絡以提高隱秘圖像S的抗隱寫分析能力.

圖5 HCGAN信息隱藏算法架構Fig.5 HCGAN information hiding algorithm architecture
本文提出的基于GAN 的高容量信息隱藏模型包含編碼器、解碼器和鑒別器三個部分,因此需要對這三個部分分別設計損失函數
2.4.1 相似性損失
基于Im-Residual 結構的編碼器作為嵌入過程需要將秘密信息嵌入載體圖像中形成含秘圖像,因此,首先要保證在載體圖像和含秘圖像之間不存在肉眼可以感知的失真.圖像之間的相似性可以使用SSIM 和PSNR 來表述.為了便于計算,本文使用均方誤差(也稱L2 損失)作為載體圖像和含秘圖像相似性的評價指標,如公式(4)所示:

式中:C表示載體圖像,W和H表示載體圖像的寬和高,PC表示載體圖像的分布,M表示秘密信息,E(C,M)則表示編碼器網絡的輸出,即含秘圖像.
2.4.2 準確率損失
準確率損失指的是基于稠密結構的解碼器從含秘圖像中提取出的秘密信息和原本的秘密信息之間的差距.交叉熵是一種機器學習的損失函數,可以用來衡量兩個隨機變量之間的差別,因此本文選擇交叉熵函數作為算法的準確率損失,如公式(5)所示:
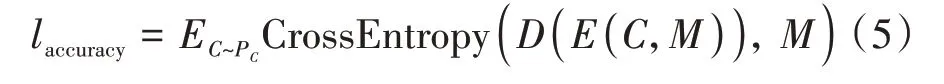
式中:PC表示載體圖像的分布,D(E(C,M))表示解碼器提取出來的秘密信息.交叉熵函數在這里用CrossEntropy表示,如公式(6)所示:

式中:y表示真實分類標簽,在二分類中y可以為0或表示預測樣本標簽為1 的概率.因此,交叉熵函數也可以表示為公式(7):

2.4.3 安全性損失
基于隱寫分析的鑒別器的目標是區分含秘圖像和載體圖像,同時具有一定的隱寫分析的能力.因此和一般的GAN 一樣,本文使用鑒別器的輸出作為安全性損失,如公式(8)所示:

式中:S(E(C,M))表示鑒別器的輸出.
2.4.4 編碼器的損失函數
基于Im-Residual 結構的編碼器是模型的核心,其性能的優劣對上述三個損失都有很大的影響,因此本文將基于Im-Residual 結構的編碼器的損失函數定義為公式(9):

2.4.5 解碼器的損失函數
與基于Im-Residual 結構的編碼器相比,基于稠密結構的解碼器的損失函數就比較簡單,只與準確率損失有關,如公式(10)所示:

2.4.6 鑒別器的損失函數
基于隱寫分析的鑒別器被用來區分載體圖像和含秘圖像,并在訓練過程中給基于Im-Residual 結構的編碼器提供梯度.因此在訓練整個網絡時,基于隱寫分析的鑒別器訓練至關重要,它所提供的梯度直接影響著基于Im-Residual 結構的編碼器性能和含秘圖像的質量.因此,本文使用Wasserstein 距離作為基于隱寫分析的鑒別器的損失函數,如公式(11)所示:
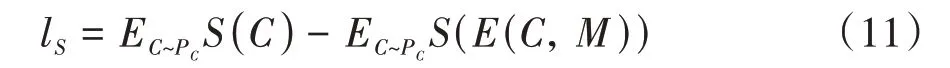
每次迭代使用損失函數來判斷神經網絡的好壞,并使用梯度下降的方法來更新神經網絡的參數.
3 實驗分析
信息隱藏算法的性能可以從三個角度進行評估:圖像中可以隱藏的數據量,即容量;含秘圖像與載體圖像之間的相似度,即失真;隱寫分析工具避免檢測的能力,即安全性.因此,本節分別設計實驗驗證容量、失真和安全性.若無特殊說明,所有實驗均使用Pytorch 框架實現,并在單個NVIDIA GTX1080 Ti GPU 上進行訓練.ADAM 優化器用于最小化損失,學習率為0.000 4.
3.1 評價標準
3.1.1 峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)
實驗使用PSNR 和SSIM[26]來評價含秘圖像和載體圖像的相似度.PSNR 代表峰值信噪比,給定載體圖像C、含秘圖像S和可能的最大像素值MAX1,PSNR的計算方式如公式(13)所示:
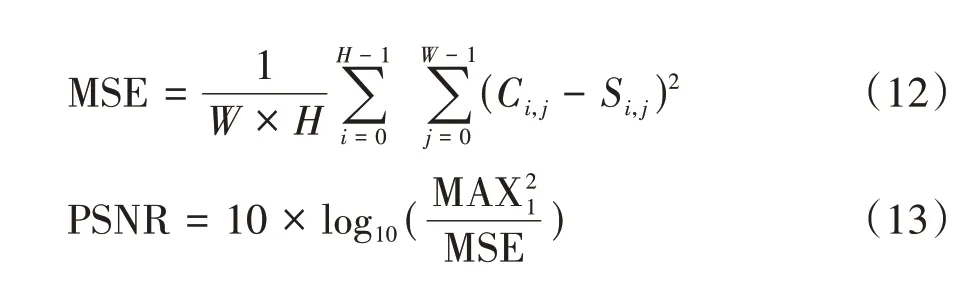
3.1.2 結構相似性(Structural SIMilarity,SSIM)
SSIM 代表結構相似性,由載體圖像C的采樣x和含秘圖像S的采樣y之間的三個比較衡量——亮度、對比度和結構來計算,如公式(14)所示:

式中:μx和μy分別是x和y的均值,σx和σy分別是x和y的方差,σxy是x和y的協方差.r1=(k1MAX1)2、r12=(k2MAX1)2為兩個常數,一般設k1為0.01、k2為0.03.
3.1.3 RS-BPP評價方法
為了測量基于深度學習的信息隱藏算法的有效容量,本文采用Zhang 等人提出的RS-BPP[28]評價方法.該方法表示圖像中可以可靠傳輸的平均比特數除以圖像的大小.因此,RS-BPP 可以直接與傳統的隱寫技術進行比較,其值等于1 -2p,p為提取錯誤率.
3.2 失真和容量分析
本文在LUSN-bed數據集中對不同編碼器-解碼器結構在嵌入率D ∈{1,2,…,6}的情況下進行訓練,并分別使用PSNR、SSIM 和RS-BPP 對各個算法的失真和容量在測試集中進行測試,結果如圖6 和表2所示.

圖6 不同編碼器-解碼器在不同嵌入率下的隱秘圖像Fig.6 Secret images of different encoders-decoders at different embedding rates
從圖6 中可以看出,就算是在6 bpp 的嵌入率的情況下,隱秘圖片也未顯示出肉眼可見的失真.通過對比表2 中高嵌入量下的基礎提取器和基于Dense結構的提取器的結果可以發現,無論使用哪種編碼器,基于Dense 結構的解碼器總是有更高的容量,可證明使用Dense 結構確實可以提高解碼器的提取準確率.同樣,相同條件下基于Im-Redisual 結構的編碼器也顯示了比其他編碼器更高的容量和較小的失真.由表2 可知,無論在哪種嵌入率下,HCGAN 模型總是顯示出較優的性能.

表2 不同編碼器-解碼器結構下各個算法的失真和容量Tab.2 Distortion and capacity of each algorithm under different encoder-decoder structures
為了研究神經網絡是如何嵌入秘密信息的,本文在6 bpp嵌入率下將HCGAN 算法得到的隱秘圖像減去載體圖像得到殘差圖像并將其灰度化,如圖7所示.從圖7可以看出,HCGAN算法能夠自適應地尋找嵌入位置,并在紋理復雜的區域嵌入更多的信息,在平滑的區域嵌入較少的信息.

圖7 載體圖像(左)、隱秘圖像(中)、殘差圖像(右)Fig.7 Carrier image(left),hidden image(middle),residual image(right)
為了進一步驗證HCGAN 算法的泛化能力,本文采用CelebA 和COCO 數據集在1 bpp、3 bpp、6 bpp 的嵌入率下對本文模型進行試驗,結果如表3和表4所示.由表可知,本文提出的算法適用于各種不同的圖像集并表現良好.

表3 解碼器為Dense結構下不同數據集的表現Tab.3 The performance of different data sets under the Dense structure

表4 解碼器為Basic結構下不同數據集的表現Tab.4 The performance of different data sets under the Basic structure
3.3 安全性分析
安全性是信息隱藏算法的另一種重要指標,其主要是指抗隱寫分析能力,通常使用隱寫分析工具的檢測率進行評估.本節使用一個流行的開源隱寫分析工具StegExpose(結合了幾種現有的隱寫分析技術,包括樣本對、RS 分析、卡方攻擊和初級集)進行實驗,來驗證HCGAN 模型生成不可檢測的含秘圖像的能力.為了進行對照實驗,本文采用LUSN-bed 數據集分別在1 bpp、3 bpp、6 bpp 嵌入率下訓練HCGAN 模型和其他結構不變只改變鑒別器為普通卷積結構鑒別器的信息隱藏算法模型.模型訓練完成后,分別給各個模型輸入1 000個測試集中的圖像得到1 000 個隱秘圖像,然后使用StegExpose 工具對2 000個圖像進行分析并畫出ROC曲線,如圖8所示.需注意的是,圖中的直線表示隨機判斷的ROC曲線.
從圖8 中可以看出,無論是1 bpp、3 bpp 還是6 bpp嵌入率的信息隱藏模型,使用隱寫分析器作為鑒別器的HCGAN 算法的抗隱寫分析能力總是優于其他結構不變只改變鑒別器為普通卷積結構鑒別器的模型.即使在嵌入率為6 bpp的情況下,StegExpose工具的檢測率也低于0.7,可以看出本文算法能夠更有效地抵抗基于深度學習的隱寫分析算法.
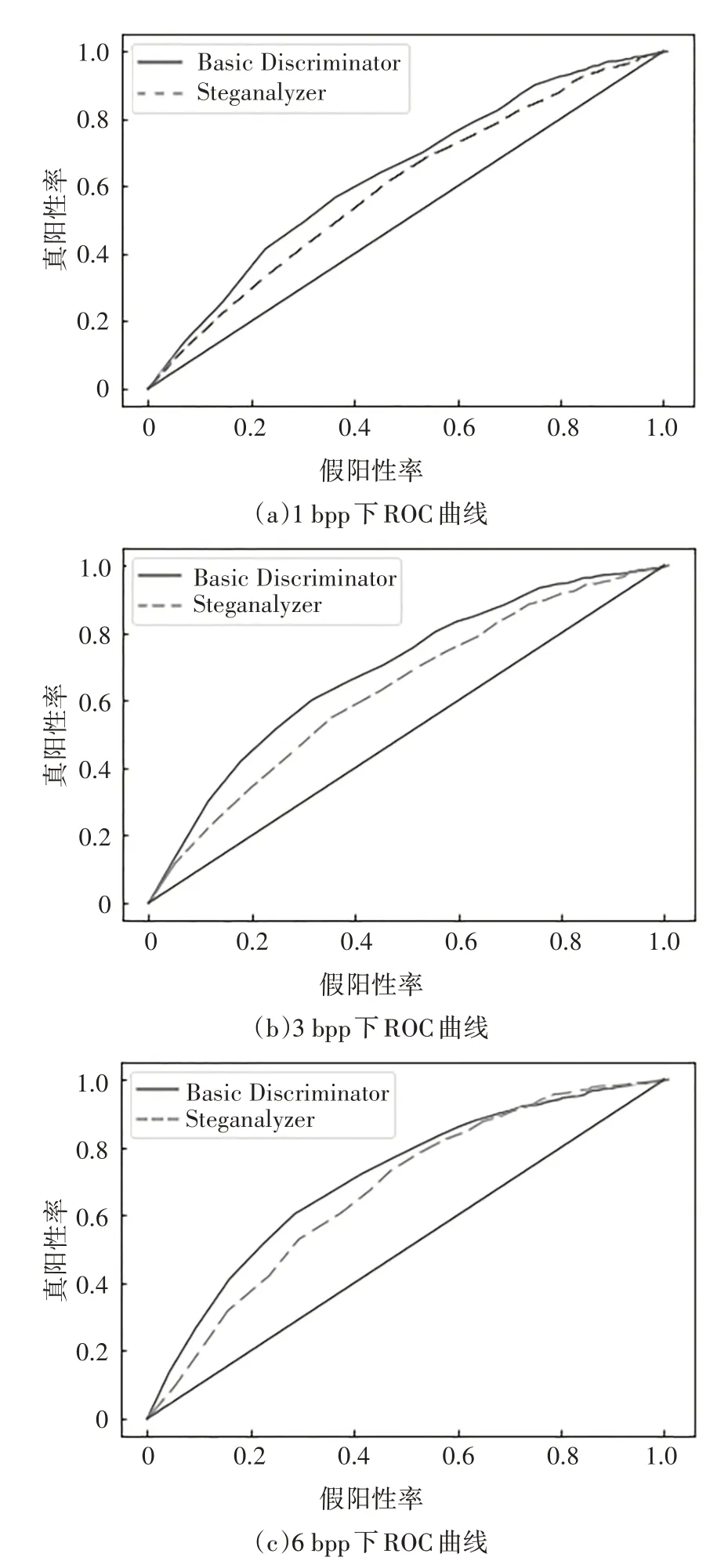
圖8 不同嵌入率下的ROC曲線Fig.8 ROC curve under different embedding rates
為了驗證本文算法具有抵抗基于深度學習的隱寫分析能力,以及避免由于對XuNet 的針對性訓練而引起的檢測不可信問題,本文使用Yedroudj 等人[29]于2018年提出的Yedroudj-Net隱寫分析模型來檢測本文模型的抗隱寫分析能力,結果如表5 所示.需要注意的是,Yedroudj-Net 在訓練時采取半盲檢測方式,其訓練集中包含各種嵌入率下分別由普通卷積結構的鑒別器和基于隱寫分析的鑒別器引導的基于Im-Residual結構的編碼器所生成的含秘圖像.
從表5 中可以看出,在1 bpp、2 bpp 等較低嵌入率下基于隱寫分析的鑒別器引導基于Im-Residual結構的編碼器生成的含秘圖像有著較低的檢測準確率.在5 bpp和6 bpp的高嵌入率下,由于載體圖像中嵌入了大量秘密信息所帶來的大量擾動,從而使Yedroudj-Net 隱寫分析器能夠實現接近100%的檢測準確率.

表5 Yedroudj-Net隱寫分析網絡的檢測準確率Tab.5 The detection accuracy of Yedroudj-Net steganalysis network %
最后,本文在Yedroudj-Net 隱寫分析模型下比較了HCGAN 算法和經典信息隱藏算法WOW、SUNIWARD 在相似安全性下的嵌入率,結果如表6 所示.注意,這里的訓練集包含各嵌入率下分別由普通卷積結構的鑒別器和基于隱寫分析的鑒別器所生成的含秘圖像(作為負向樣本)和載體(作為正向樣本).從表6中可以看出,本文提出的信息隱藏算法能夠在嵌入率為2.0 bpp 下顯示出比WOW 和SUNIWARD 算法在0.4 bpp 的嵌入率下更低的隱寫分析檢測率,即更高的安全性.這進一步驗證了本文提出的信息隱藏模型能夠實現高隱寫容量并且在高隱寫容量下保持較強的安全性.

表6 相似安全性下各個算法的嵌入率對比Tab.6 Comparison of the embedding rate of each algorithm under similar security
4 總結與展望
本文提出了一種基于GAN 的高容量信息隱藏算法HCGAN,該算法能夠以較高的提取率隱藏高容量秘密信息,并具有一定的抗隱寫分析能力.實驗表明,HCGAN 算法能有效嵌入3 bpp 以上高容量的秘密信息,并且在高容量下依舊具有較強的安全性.
信息隱藏技術常因新的創意或者其他領域的進展而有長足的發展.結合本文工作,本節提出了未來研究信息隱藏技術的一些思路.本文提出的模型利用了GAN 的對抗性,但沒有關注GAN 能通過噪聲生成符合真實圖像分布的圖像生成能力.因此將GAN的圖像生成能力用于信息隱藏領域是后續研究的一個方向.本文提出的模型雖然擁有較高的安全性,但還是有可能被隱寫分析檢測出來.在近幾年對于神經網絡的研究中,有部分研究者發現對一張已經正確分類的圖片進行細微的像素修改后,DNN 會將其錯誤地分類為其他類型[30].在今后的工作中,將這種對抗性樣本引入信息隱藏技術,使基于深度學習的隱寫分析將含秘圖像錯誤分類,以此來進一步提高含秘圖像的抗隱寫分析能力.
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中華詩詞(2019年7期)2019-11-25 01:43:04
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
山東工業技術(2016年15期)2016-12-01 05:31:22
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
