基于結構化文本及代碼度量的漏洞檢測方法
2022-05-06 06:06:32楊宏宇應樂意張良
湖南大學學報(自然科學版) 2022年4期
楊宏宇,應樂意,張良
(1.中國民航大學安全科學與工程學院,天津 300300;2.中國民航大學計算機科學與技術學院,天津 300300;3.亞利桑那大學信息學院,圖森美國AZ 85721)
計算機軟件在各個領域的廣泛應用,使得軟件漏洞問題也日益嚴重.面對多樣化的軟件漏洞類型,如何高效地進行漏洞檢測成為當前研究的熱點問題.對源代碼進行漏洞檢測是保障軟件安全的有效手段之一.目前,基于代碼度量和基于深度學習的方法是較為常見的源代碼漏洞檢測方法[1].
代碼度量[2]被用于描述軟件代碼特性,以相關定義的數值來描述代碼的基本狀況.代碼度量雖然是一種粗粒度的源代碼表征方式,但是在一定程度上可以表征代碼的基本狀況.基于代碼度量的漏洞檢測方法通過源代碼度量工具對目標代碼進行代碼度量獲取對應指標的數值,利用機器學習算法,經過訓練生成漏洞檢測器.Ferenc 等[3]基于代碼度量應用機器學習算法和網格搜索算法構建漏洞檢測模型并采用重采樣策略解決訓練數據不平衡問題.Sul?tana[4]利用機器學習和統計學方法追蹤代碼度量、代碼模式和漏洞之間的聯系,提出一種漏洞檢測方法,并利用該方法對開源軟件進行漏洞檢測.基于代碼度量的漏洞檢測方法的主要不足是:①檢測粒度粗且可解釋性差;②精確率低且誤報率高.
隨著深度學習在自然語言處理領域的應用,研究人員嘗試將深度學習技術應用于編程語言.當前深度學習技術已經普遍應用于信息安全領域[5],基于深度學習的漏洞檢測方法能夠自主學習代碼文本信息與漏洞之間的關聯性以此建立漏洞檢測模型.Li等[6]首次將深度學習技術引入漏洞檢測領域,提出一種VulDeePecker 自動化漏洞檢測系統,能夠對C/C++語言編寫的源代碼進行漏洞檢測.Saccente 等[7]提出Achilles 漏洞檢測方法,在Java 源代碼上進行測試并取得不錯的效果,表明基于深度學習的源代碼漏洞檢測方法能夠應用于多種編程語言.上述兩種方法將源代碼完全視為線性文本,無法充分表征源代碼特征.為更加充分表征編程語言的語法和語義,結構化表征方式被應用于源代碼的表征.陳肇炫等[8]提出一種基于結構化表征的智能化漏洞檢測系統Astor,在復雜且語法豐富的數據集中,檢測效果優于線性表征方法.基于深度學習的漏洞檢測方法能夠完全脫離人工干預進行漏洞檢測,但仍存在不足.基于深度學習的漏洞檢測方法的主要不足有:①需要依賴大量數據進行訓練;②對不同類型漏洞的檢測結果波動性較大;③精確率和召回率有待提升.
針對計算機軟件二進制代碼的漏洞檢測技術是一種底層的漏洞檢測技術.當無法獲取軟件高級語言源代碼時,文獻[9]將反編譯軟件二進制代碼作為特征,應用深度學習技術進行特征學習并構造漏洞檢測模型,得到了較好的檢測性能.文獻[10]通過計算二進制函數和漏洞二進制函數特征庫的相似度進行漏洞檢測,該方法通過大量的訓練后的模型準確率得到提升.文獻[11]在經典代碼切片技術的基礎上改善二進制代碼過程間切片方式及切片粒度,使得檢測精度和效率有所提升.在無法獲取源代碼的情況下,利用二進制代碼依舊可以進行漏洞檢測并且有較好的檢測能力.但是基于二進制代碼的檢測方法并不直觀且表征方式單一.
上述工作在源代碼表征方式上,均采用了單一的表征方式,無法全面表征源代碼,因此導致檢測效果不佳.針對上述檢測方法表征方式單一導致檢測效果不佳的問題,為進一步提升漏洞檢測效果,本文提出一種基于結構化文本及代碼度量的漏洞檢測方法,在現有研究的基礎上從表征方法和特征擬合兩個方面做出改進,在函數級粒度上對源代碼進行漏洞檢測.首先,深度優先遍歷源代碼抽象語法樹得到結構化文本信息,使用源代碼靜態解析工具獲取代碼度量值;其次,通過構造基于自注意力機制的神經網絡捕獲結構化文本信息中的長期依賴關系,以擬合結構化文本和漏洞存在之間的聯系并轉化為漏洞存在的概率,采用深度神經網絡對代碼度量的結果進行特征學習以擬合代碼度量值與漏洞存在的關系,并將其擬合的結果轉化為漏洞存在的概率;最后,采用支持向量機對由上述兩種表征方式獲得的漏洞存在概率做進一步的決策分類,并獲得漏洞檢測的最終結果.在對比實驗中,針對存在不同類型漏洞的11 種源代碼樣本進行漏洞檢測實驗,本文方法對每種漏洞的平均檢測準確率為97.96%.與現有基于單一表征的漏洞檢測方法相比,本文方法的檢測準確率提高了4.89%~12.21%,同時,本文方法的漏報率和誤報率均保持在10%以內.
1 源代碼漏洞檢測方法設計
1.1 方法設計思路
本文方法從結構化文本信息和代碼度量兩個維度對源代碼進行表征,利用表征結果和預設的標簽對構造的神經網絡進行訓練.訓練完成的神經網絡模型即為漏洞檢測模型,應用漏洞檢測模型對待檢測源代碼進行漏洞檢測得到檢測結果.本文方法中4個部分的設計思路如下.
1)數據預處理.為生成符合本文漏洞檢測粒度的訓練集和測試集,在本階段對原始數據集以函數級粒度進行切片并設置監督學習標簽.預處理階段的輸出為代碼的函數切片以及對應的監督學習標簽.
2)數據表征.為充分表現源代碼特征,從結構化文本信息和代碼度量兩個維度對預處理后的數據進行表征.為從源代碼結構化文本信息角度表征源代碼,利用AST 作為中間載體,采用深度優先遍歷機制收集源代碼文本特征并轉化為向量形式;為從代碼度量角度表征源代碼,需要定義代碼度量指標,通過源代碼靜態解析工具獲取對應的度量值.本階段的輸出為向量形式的結構化文本信息以及代碼度量值序列.
3)模型構建及訓練.為擬合數據表征的結果和漏洞存在之間的關系,構建合適的神經網絡模型對表征結果進行特征學習.構建的神經網絡模型能對結構化文本信息和代碼度量值進行特征學習,綜合兩種特征給出漏洞檢測結果.最后,采用表征結果和預設的標簽對模型進行訓練,本階段的輸出為訓練完成的漏洞檢測模型.
4)源代碼漏洞檢測.為在本階段應用訓練完成的模型進行漏洞檢測,對待檢測源代碼進行特征提取,提取特征的方式與表征方式相同.將提取到的特征輸入訓練完成的模型中,輸出漏洞檢測的結果.
1.2 方法架構設計
本文提出的源代碼漏洞檢測模型由數據預處理、數據表征、模型搭建及訓練、源代碼漏洞檢測4個部分組成,該方法的核心框架如圖1 所示.該漏洞檢測模型的4個部分的主要處理過程為

圖1 本文漏洞檢測方法框架Fig.1 Framework for vulnerability detection in this paper
1)數據預處理.數據預處理階段包括代碼切片和設置監督學習標簽兩個部分.本文方法在函數級粒度進行漏洞檢測,因此需將源代碼數據切分為函數片段并根據函數片段是否存在漏洞設置標簽.
2)數據表征.為充分表征函數片段的信息,分別從結構化文本信息和代碼度量兩種維度對預處理后的數據進行表征.利用抽象語法樹(Abstract Syntax Tree,AST)表征函數片段的文本信息.定義代碼度量指標對函數片段進行代碼度量.
3)模型構建及訓練.構建一種神經網絡,由該神經網絡針對兩種維度表征結果的數據類型進行特征學習.利用兩種表征結果以及預設的標簽對神經網絡進行訓練以構造漏洞檢測模型.
4)源代碼漏洞檢測.利用訓練完成的漏洞檢測模型對待檢測源代碼進行漏洞檢測.待檢測源代碼的預處理和表征方式與訓練數據相同,將表征結果輸入訓練完成的漏洞檢測模型得到檢測結果.
2 數據處理及表征
2.1 數據預處理
本文采用的數據集為美國國家標準與技術研究院的Juliet Test Suite 數據集[12],該數據集包含118 種CWE[13]類型的28 881 個Java 文件.由于基于深度學習的方法對于數據量的需求較大,所以在研究中選取測試用例超過1 000例的漏洞類型.雖然在本文研究中以Java 語言源代碼作為研究對象,但本文方法并不受編程語言類型限制,只要被檢測程序的源代碼能夠進行結構化表征和代碼度量,本文方法依然適用.
為生成符合本文檢測粒度的訓練集和測試集,需要對收集的數據進行預處理.數據預處理階段包括代碼切片和監督學習標簽設置兩部分.
2.1.1 代碼切片
本文方法的檢測粒度是函數級別,所以對需要表征的源代碼按函數進行切片.漏洞源代碼用例如表1所示.

表1 漏洞源代碼用例Tab.1 Vulnerability source code case
代碼切片可以從Java 文件中分離出不含空行和注釋的函數代碼,代碼切片的具體過程如下.
1)源代碼清洗.為提升源代碼的信息密度,防止無用信息被表征,以字符串匹配的方式消除代碼中的空行和注釋.
2)函數切片.利用Java靜態解析工具Javalang[14]解析Java 源文件獲得類中包含的所有函數并存儲在列表中.
2.1.2 監督學習標簽設置
判斷源代碼函數是否存在漏洞是一個典型的二分類問題.本文針對漏洞檢測設計的神經網絡是一個二分類監督學習模型,因此需要對訓練數據設置標簽.
Juliet Test Suite 數據集中,已經在函數名稱上標注了標記“good”(無漏洞)或“bad”(有漏洞).采用字符匹配的方法匹配函數名稱中的標記,標記為“good”的函數片段設置標簽為“0”,標記為“bad”的函數片段設置標簽為“1”.由于函數名稱也會作為文本信息被表征,為了不使上述標記影響模型的訓練效果,依據標記添加標簽后,將其用隨機字符替代.
2.2 數據表征
為充分表現源代碼特征,從代碼結構化表征和代碼度量兩個不同維度對源代碼進行表征.代碼結構化表征可以獲得代碼結構化的文本信息,代碼度量能夠表征代碼的基本狀況.
2.2.1 代碼結構化表征
編程語言是一種結構化的語言,源代碼中的信息有明確的結構關系.因此表征自然語言的方法并不能充分表征源代碼中的語法和語義.為了得到更貼合實際的源代碼特征,采用結構化表征方法對源代碼進行表征.結構化表征方法包括以下三個步驟.
步驟1:利用Java 源代碼解析工具javalang 解析代碼,得到抽象語法樹節點和邊的信息,根據節點和邊的信息生成抽象語法樹.
步驟2:深度優先遍歷抽象語法樹,依次收集節點信息.深度優先遍歷抽象語法樹的結果使得樹形數據轉化為一維文本數據.
步驟3:將一維文本數據轉化為神經網絡的輸入.由于神經網絡的輸入是向量形式的數據,因此需要進一步處理一維的文本數據.首先對文本數據作分詞處理,然后通過統計方法生成詞典,根據詞典將文本表示為向量.
2.2.2 代碼度量
本文方法旨在對函數級別的源代碼進行漏洞檢測,因此需要在代碼函數級別上進行度量.為使完全依賴數據的深度學習方法能與安全專家的先驗知識進行有效交互,并使檢測模型的自適應性更強,在代碼度量中需要人工參與定義代碼度量指標.本文方法中的代碼度量處理過程包括2個步驟.
步驟1:度量指標定義.對代碼度量的指標進行定義,在代碼度量階段使用的主要度量指標是Chid?amber&Kemerer指標[15],與傳統的McCabe指標和Halstead metrics 指標相比,Chidamber&Kemerer 指標是專門針對面向對象程序語言提出的,故對Java 語言的適應性更強.具體的度量指標如表2 所示,其中包含函數和函數所在類的相關信息.
步驟2:代碼度量.使用代碼度量工具[16]進行代碼度量可得到表2所示指標的具體量化數值.

表2 代碼度量指標Tab.2 Code metrics
3 深度神經網絡的構建與訓練
3.1 神經網絡總體框架
對源代碼的表征結果分別為結構化的文本信息和代碼度量產生的數字序列.因此需要設計神經網絡對結構化文本信息和數字序列進行特征學習,并綜合二者判斷結果給出最終的漏洞檢測結果.
在本文方法中構建的神經網絡模型有三個部分:①基于自注意力(Self-Attention,SA)機制[17]的神經網絡;②深度神經網絡(Deep Neural Networks,DNN);③支持向量機(Support Vector Machine,SVM).該神經網絡的主要結構如圖2所示.

圖2 神經網絡總體框架Fig.2 Framework of neural network
其中,基于SA 的神經網絡模型用于文本序列的特征學習,DNN模型用于代碼度量結果的特征學習,SVM 模型用于對上述兩個模型的輸出結果進行處理和分類并得到最終的漏洞檢測結果.
3.2 基于SA機制的神經網絡模型構建
分析文本數據最重要的目的是捕獲其中的長期依賴關系,這種依賴關系在編程語言中尤為關鍵.受自然語言語法和人類文字編輯習慣的影響,自然語言中的依賴關系在時間跨度上是有限的.但是這種依賴關系在編程語言中的時間跨度是不受控制的,例如定義的變量或函數,在代碼中的任意位置都可能被調用.因此在對源代碼結構化文本漏洞檢測時,通過SA機制解決依賴問題.
SA 結構如圖3 所示,對于每一個輸入的詞向量xi,SA將其表示為向量qi、ki、vi.為獲取這3個向量,分別定義3 個不同的權值矩陣WQ、WK、WV,這3 個矩陣在訓練階段通過反向傳播算法不斷更新優化.將權值矩陣與輸入矩陣X=[x1,x2,x3,…,xn]相乘來獲得對應的向量集和,計算方式如公式(1)~公式(3)所示.

圖3 SA結構Fig.3 SA structure

式中:X為輸入詞向量xi組成的矩陣,WQ為對應的權值矩陣,Q是由向量qi組成的矩陣.

式中:X為輸入詞向量xi組成的矩陣,WK為對應的權值矩陣,K是由向量ki組成的矩陣.

式中:X為輸入詞向量xi組成的矩陣,WV為對應的權值矩陣,V是由向量vi組成的矩陣.
SA的計算結果為:
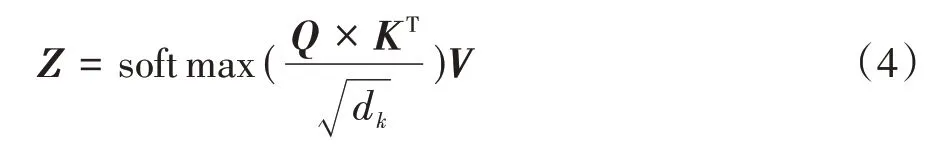
式中:dk為尺度標度,與向量qi的維度相等;Q、K、V分別為公式(1)~公式(3)的計算結果,是輸入矩陣X的三種不同的表示形式.
在公式(4)中,Q和K相乘的結果用于反映每個詞與其他詞的相關程度,但是這個結果會隨著詞向量維度的增加而不斷增大.如果Q和K相乘的結果非常大,會造成softmax 結果無限接近1,會使得梯度較小,從而影響參數的更新.因此需要利用dk約束計算結果的大小.softmax 能夠計算詞與詞的關聯程度在句子中的比重,softmax 的結果再與V相乘,相當于一個加權求和的結果,這個結果可以反映每個詞對于句子的貢獻程度.在本文研究中,這個貢獻程度表示這個詞與漏洞存在的關聯程度.
由上述計算過程可知,SA 機制能夠反映文檔內部每個詞和其他所有詞的直接交互情況,對比循環神經網絡(Recurrent Neural Network,RNN)需要按照序列逐步累計計算來獲得文本信息中的長距離相互依賴關系,SA 機制能更好地捕捉文本信息長期依賴關系.所以相較于傳統RNN,SA 更適合進行結構化文本特征學習任務.
本文構建的基于SA 的神經網絡由輸入層、SA層、全連接層、輸出層構成,其中全連接層由128 個神經元組成.由于SA 中的計算都是線性計算,加入全連接層以擬合非線性特征.為通過文本特征得到漏洞存在的概率,輸出層以Sigmoid 作為激活函數.Sigmoid函數如公式(5)所示.

Sigmoid 函數能將神經網絡的輸出映射到[0,1]之間,能將學習到的文本特征轉化為漏洞存在的概率.通過源代碼結構化表征結果和預設的標簽對基于SA 的神經網絡進行訓練,在訓練完成的神經網絡中輸入源代碼結構化文本信息,即可輸出對應源代碼存在漏洞的概率.
3.3 DNN模型構建
代碼度量的結果是一段數字序列,序列中的每個元素表示對應度量指標的具體數值,并且度量結果各個元素之間不存在相互依賴關系.基于上述應用場景,DNN 相較于傳統機器學習算法能夠在較短的時間內學習到序列特征.因此應用DNN 進行代碼度量的特征學習,其結構如圖4 所示,隱藏層的神經元個數均為64.

圖4 DNN結構Fig.4 DNN structure
對輸入的代碼度量結果,在經過兩層隱藏層擬合代碼度量特征后,利用Sigmoid 函數作為激活函數將輸出結果映射到[0,1]之間.利用代碼度量結果和預設的標簽對DNN 進行訓練,在訓練完成的DNN 模型中輸入代碼度量結果即可輸出對應源代碼存在漏洞的概率.
3.4 SVM模型構建
本文漏洞檢測模型以學習文本序列特征的基于SA 的神經網絡和學習代碼度量特征的DNN 為基礎構建.在完成上述模型的訓練后,能夠應用這兩種模型分別從文本信息和代碼度量兩個維度判斷代碼是否存在漏洞.為得到更加精確的漏洞檢測結果,需要綜合上述兩種模型的輸出結果.因此本文以上述兩種模型的輸出作為特征,應用SVM作進一步分類,判斷代碼是否存在漏洞.
在獲取兩種模型輸出的漏洞存在概率后,需要應用分類算法對輸出進行分類以盡可能消除兩種表征方式判斷出現分歧的部分.因此,在應用分類算法后,檢測效果會得到明顯提升.
選擇SVM作為這一階段的分類器主要有以下兩個原因:①SVM 在分類任務中效果好,并且分類思想簡單直觀,能夠準確繪制其決策邊界,以直觀表現本文方法的可行性;②分類方式靈活,可以通過調整其核函數進行線性分類和非線性分類.由于無法提前判斷兩種模型的輸出是否是線性可分的,SVM 的分類方式相較于其他分類算法更加適合作為本階段的分類器.
常規的SVM通過繪制最大間隔的超平面進行分類,但這種方法無法進行非線性分類.由于基于SA的神經網絡和DNN 的輸出結果可能出現線性不可分的情況,設置SVM的核函數以進行非線性分類.本方法構建的SVM 模型利用線性核(linear)、多項式核(poly)和高斯核(rbf)對基于SA 的神經網絡和DNN的輸出結果進行分類.在訓練完成的SVM模型中,輸入基于SA的神經網絡和DNN輸出的漏洞存在概率,輸出漏洞檢測的最終結果.
4 實驗設計及結果分析
4.1 評價指標
本文采用準確率、精確率、召回率、F1-Score、誤報率、漏報率6 個指標對提出的漏洞檢測模型進行評價.為計算上述6 個評價指標,需要在實驗中收集以下4 種數據:①真正類(True Positive,TP)即被正確分類的有漏洞樣本數量;②假正類(False Positive,FP)即不含漏洞樣本被誤報的數量;③假負類(False Negative,FN)即未被成功檢測的漏洞樣本數量;④真負類(True Negative,TN)即不存在漏洞的樣本被準確判斷的數量.6個評價指標的定義如下.
1)準確率A:準確分類的樣本占總樣本的比例.

2)精確率P:在所有被判斷為存在漏洞的樣本中,判斷正確的樣本比例.

3)召回率R:被成功檢測出的漏洞樣本占所有漏洞樣本的比例.

4)F1-Score:精確率和召回率的調和平均值,反映模型整體表現情況.

5)誤報率FPR:無漏洞樣本被誤報的比例.

6)漏報率FNR:漏洞樣本中未被檢測出的樣本所占比例,FNR=1-R.
4.2 實驗與結果分析
為驗證本文方法的性能,將本文方法與基于源代碼文本結構化表征的漏洞檢測方法[8]、基于文本線性表征的漏洞檢測方法[7]和基于代碼度量的漏洞檢測方法[3]進行對比實驗.具體實驗環境配置如表3所示.

表3 實驗環境配置Tab.3 Experimental environment configuration
4.2.1 檢測模型構建及性能評估
本文提出的基于結構化文本及代碼度量的漏洞檢測方法,綜合了源代碼文本的結構化表征和代碼度量兩種表征方式.因此模型的構造需要分三步進行:①基于SA 的神經網絡訓練及測試;②DNN 模型訓練及測試;③SVM 模型訓練及測試,其中SVM 模型的輸出結果是本文檢測方法的最終結果.訓練及測試所需數據集如表1所示,將表1中收集的測試用例進行分割,得到訓練集和測試集.
1)基于SA 的神經網絡訓練及測試.本文利用基于SA 的神經網絡進行代碼結構化文本特征的學習.為驗證SA 機制在捕獲代碼結構化文本長期依賴能力優于其他神經網絡,與其他4 種神經網絡進行對比實驗,分別為:CNN、LSTM、BLSTM、GRU.對上述模型進行訓練,經過測試分別得到5 種模型的性能指標,實驗結果如圖5~圖10所示.

圖5 五種神經網絡準確率A對比結果Fig.5 Accuracy comparison of five neural networks

圖6 五種神經網絡精確率P對比結果Fig.6 Precision comparison of five neural networks

圖7 五種神經網絡召回率R對比結果Fig.7 Recall comparison of five neural networks
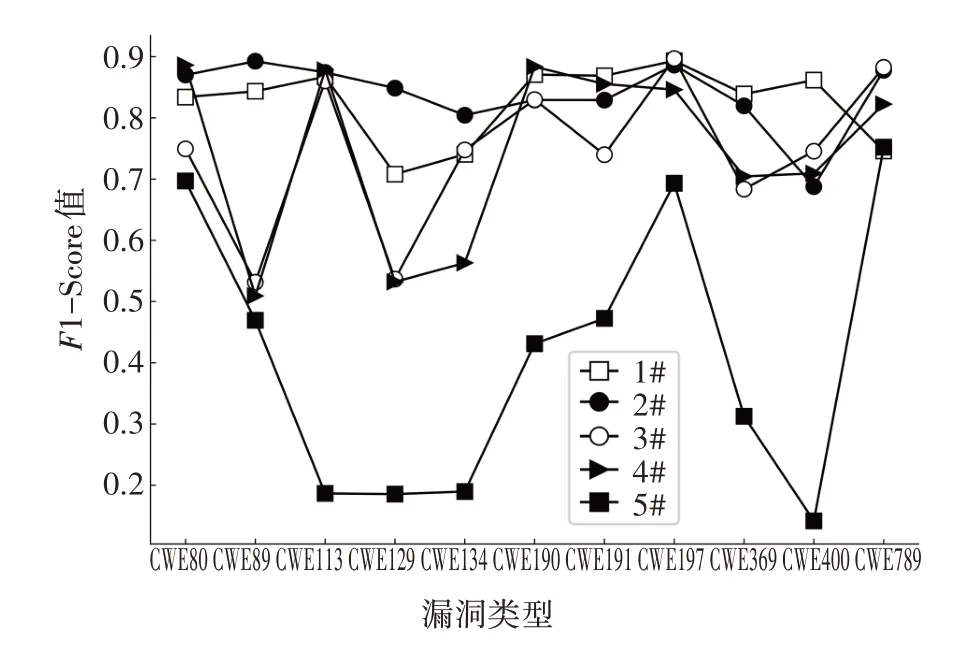
圖8 五種神經網絡F1-Score對比結果Fig.8 F1-Score comparison of five neural networks

圖9 五種神經網絡誤報率FPR對比結果Fig.9 FPR comparison of five neural networks

圖10 五種神經網絡漏報率FNR對比結果Fig.10 FNR comparison of five neural networks
由圖5~圖10 可見,基于SA 的神經網絡在測試集上的準確率和精確率較高且誤報率較低,這說明與采用其他4 種神經網絡模型相比,基于SA 的神經網絡模型對源代碼的結構化文本特征擬合效果更好.并且基于SA的神經網絡F1-Score保持在較高的水平,這說明該神經網絡在利用結構化文本特征進行漏洞檢測時的整體表現優于其他模型.由圖6~圖11的曲線趨勢可見,基于SA的神經網絡在面對不同漏洞類型的表現也較為穩定.綜上可知,基于SA的神經網絡能夠充分擬合源代碼結構化文本和漏洞存在之間的聯系,比其他神經網絡更加適合基于文本結構化表征的漏洞檢測任務.
2)DNN 測試及訓練.針對代碼度量特征,采用DNN 構建一個漏洞檢測模型,其在測試數據上的實驗結果如表4所示.

表4 基于代碼度量方法的實驗結果Tab.4 Experimental results based on code metrics
實驗結果表明,基于代碼度量的方式雖然準確率較高,但漏報率極高.例如,在對CWE129 的檢測準確率達到81.93%的前提下,漏報率達到69.09%.表明代碼度量表征方法對存在漏洞的代碼表征效果不好,導致檢測結果出現偏差.可見,采用這種粗粒度的表征方式只適用于粗略判斷源代碼是否存在漏洞,不能準確檢測源代碼的漏洞.因此代碼度量在一定程度上能夠判斷代碼的健康狀況,但僅依靠代碼度量不能充分表示漏洞代碼的特性.
3)SVM 模型訓練及測試.在前序實驗中,通過對結構化文本特征和代碼度量特征訓練,得到2 種不同維度的檢測模型.在本實驗中,將測試數據輸入2種檢測模型分別得出源代碼存在漏洞的概率,以2個神經網絡檢測模型的輸出作為新的特征,采用SVM 進行決策分類,得到最終檢測結果,即判斷漏洞是否存在.通過調整核函數利用SVM 進行線性分類和非線性分類.本文分別使用線性核(linear)、多項式核(poly)和高斯核(rbf)對上述兩種檢測模型的輸出作進一步分類.以CWE113 漏洞為例說明分類過程,不同核函數的SVM決策邊界如圖11所示.

圖11 CWE113測試數據的決策邊界Fig.11 Decision boundary for CWE113 test data
圖11(a)是基于SA 的檢測模型和DNN 檢測模型的輸出散點圖,圖11(a)~圖11(d)中的每一個點表示測試數據集中的一個函數片段,圓點表示該函數真實存在漏洞,“×”點表示該函數不存在漏洞.圖中橫坐標表示基于結構化文本特征的檢測模型輸出的漏洞存在概率,縱坐標表示基于代碼度量的檢測模型輸出的漏洞存在概率.例如靠近右上角的點表示基于SA 的檢測模型和DNN 檢測模型都判斷該函數有很大概率存在漏洞.圖11(b)~圖11(d)分別表示SVM 中3 種不同核函數的決策邊界.SVM 模型的具體評估結果如表5~表7所示.

表5 線性核SVM分類結果Tab.5 Linear kernel SVM classification results

表6 多項式核SVM分類結果Tab.6 Polynomial kernel SVM classification results

表7 高斯核SVM分類結果Tab.7 Gauss kernel SVM classification results
由表5~表7可見,經過SVM 的進一步分類決策,漏洞檢測的各項指標均有大幅提升,但是對于不同核函數的SVM 分類結果相差不大.出現這種現象的原因是,在CWE113 測試數據中,基于SA 的神經網絡和DNN 的輸出是線性可分的.但是本文方法在應用過程中,由于漏洞類型的多樣性和源代碼的復雜性,無法保證基于SA的神經網絡和DNN的輸出都是線性可分的,因此本文方法采用三種不同核函數進行分類.對比表4~表7 以及圖5~圖10 中的數據可見,本文方法在結構化表征方法和代碼度量方法的基礎上,提高了準確率、精確率和召回率.
4.2.2 對比檢測實驗
為驗證本文提出方法的優越性,將本文方法和基于文本結構化表征的漏洞檢測方法[8]、基于代碼度量的漏洞檢測方法[3]、基于線性文本表征的漏洞檢測方法Achilles[7]進行對比實驗.其中基于結構化文本的方法采用的是基于SA 機制的神經網絡模型、基于代碼度量的方法采用DNN 模型、基于線性文本的方法采用LSTM 模型.分別搭建上述4 種檢測模型,在相同數據集下進行訓練和測試,4 種模型的漏洞檢測準確率對比結果如圖12所示.
從圖12 可見,基于代碼度量的方法、基于結構化表征的方法和Achilles 對不同漏洞的檢測平均準確率分別為85.75%、93.07%和92.18%,本文方法對不同漏洞的檢測平均準確率為97.96%,均高于其他3 種方法.本文方法能夠取得較好的漏洞檢測效果,有以下兩個原因:①本文方法從源代碼結構文本信息以及代碼度量兩個維度對源代碼進行表征,相比于單一表征方法,本文的表征方法更加全面;②文本信息特征是漏洞檢測過程中較為重要的特征,本文所構建的基于SA 的神經網絡,能夠較好地捕捉文本信息中的長期依賴關系.

圖12 4種模型的漏洞檢測準確率對比結果Fig.12 Accuracy comparison results of four vulnerability detection methods
5 結束語
為進一步提高源代碼漏洞檢測準確率,降低誤報率,本文提出一種基于結構化文本及代碼度量的漏洞檢測方法.通過代碼度量和結構化文本兩種表征方法對源代碼進行表征,利用神經網絡模型進行特征學習以構造漏洞檢測模型,進行漏洞檢測.實驗結果表明本文提出的方法有較好的檢測效果.
本文方法僅從兩個維度對源代碼進行表征,考慮的表征維度仍不夠全面.未來的工作重點是發掘更多適合漏洞檢測的源代碼表征方式,改進表征方式以獲得更優的檢測性能.
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
