基于注意力機制的視頻檢索算法設計
2022-05-09 10:42:26北方工業大學信息學院蘇清松
數字技術與應用 2022年4期
北方工業大學信息學院 蘇清松
針對視頻信息中空間域和時間域上特征提取存在運算成本高和時序信息不明顯的問題,本文使用基于注意力機制的殘差網絡和雙向LSTM復合模型,將視頻提取出的關鍵幀輸入到嵌入注意力機制的卷積神經網絡和雙向LSTM網絡結構中分別提取視頻的空間信息和時序信息,將本網絡模型進行實驗驗證準確率有了一定的提升。
隨著互聯網和自媒體的發展,視頻文件逐漸成為了人們日常生活中的主流信息載體。由于之前對文本和圖片數據研究的積累,對該類型數據已有較為成熟和完善的分類檢索方法,人們的研究方向也逐漸轉移到視頻領域[1]。面對數量巨大的視頻信息,如何高效檢索出用戶需要的內容成為信息檢索領域研究的重要問題。注意力機制從模擬生物學的角度出發,可以根據任務需求專注于輸入或特征子集,自動地學習到待處理信息中比較重要的部分。Sanghyun Woo等[2]提出CBAM,通過通道注意力模塊和空間注意力模塊依次對輸入特征進行處理后獲得精煉特征。在深度學習領域,循環神經網絡經常用來學習序列的時序信息,因此被廣泛應用到自然語言處理等領域。而長短期記憶神經網絡(LSTM)是RNN中最具有代表性的結構,Wang等[3]人提出了3D CNN與LSTM相結合的網絡,同時對原始視頻進行顯著性檢測,有效降低了網絡參數和訓練的難度。Tran D等[4]在二維CNN的基礎上融合時間信息實現了3D CNN,該方法收斂較慢且相對使用更多的資源;Donahue J等[5]提出了基于CNN和LSTM的模型LRCN,該模型分別使用CNN和LSTM提取空間信息和時間信息,然后使用Softmax計算得出預測值,該方法準確率相對較低。
針對以上出現的問題,本文卷積神經網絡基礎上嵌入SENet模塊,為視頻不同通道賦予不同的權重,隨后輸入到雙向LSTM網絡中提取時序信息,從而提升視頻特征的表示和檢索能力。
1 相關技術
1.1 SENet模塊
SENet是一種通道注意力網絡模型,通過Sequeeze與Excitation操作得到不同通道的權重信息,進而對與目標相關性比較小的通道進行抑制,同時對與目標相關性大的通道信息賦予更大的權重。整個注意力操作通過學習得到各個通道的權重系數并進行加權處理,從而使得模型對各個通道的特征信息有更好的表達能力。
1.2 LSTM網絡
LSTM是一種具有記憶功能的神經網絡,每個單元由遺忘門、輸入門、輸出門和兩個狀態信息(隱藏狀態和細胞狀態)組成。其中遺忘門決定記憶單元中的上一時刻有多少信息被保留到當前時刻,在反向傳播時可以防止梯度彌散和梯度爆炸,輸入門的作用是決定有多少信息輸入記憶單元,輸出門的作用是決定存儲單元的輸出信息。所以LSTM相比于傳統RNN最大的特點是使用門結構對視頻信息和記憶單元之間的交互內容信息進行控制。
2 方法設計
本文在ResNet50網絡中嵌入SE模塊對輸入的視頻幀進行空間特征提取,并對注意力模塊的嵌入位置在進行對比試驗。其中,方法(1)不使用注意力模塊;方法(2)在每個殘差結構中使用注意力模塊;方法(3)在ResNet50的第1至第5組卷積后使用注意力模塊;方法(4)在第2至第5組卷積后使用注意力模塊。實驗結果如表1所示,由于ResNet50網絡中第一組卷積相較于后四組卷積能夠處理視頻圖像中更為原始的底層信息,所以本文采用方法(4)且相較于其他方法在準確率上有了提升。

表1 注意力模塊效果驗證Tab.1 Attention module effect verification
本文采用雙向LSTM進行視頻時序特征提取,在前向傳播中將特征信息輸入LSTM,反向傳播中將特征信息以反向形式輸入LSTM模型,每層LSTM網絡對應輸出一個隱藏狀態信息,模型參數由反向傳播進行更新,該模塊可以提取視頻信息的前后時序關系并進行輸出。整體處理流程如圖1所示。
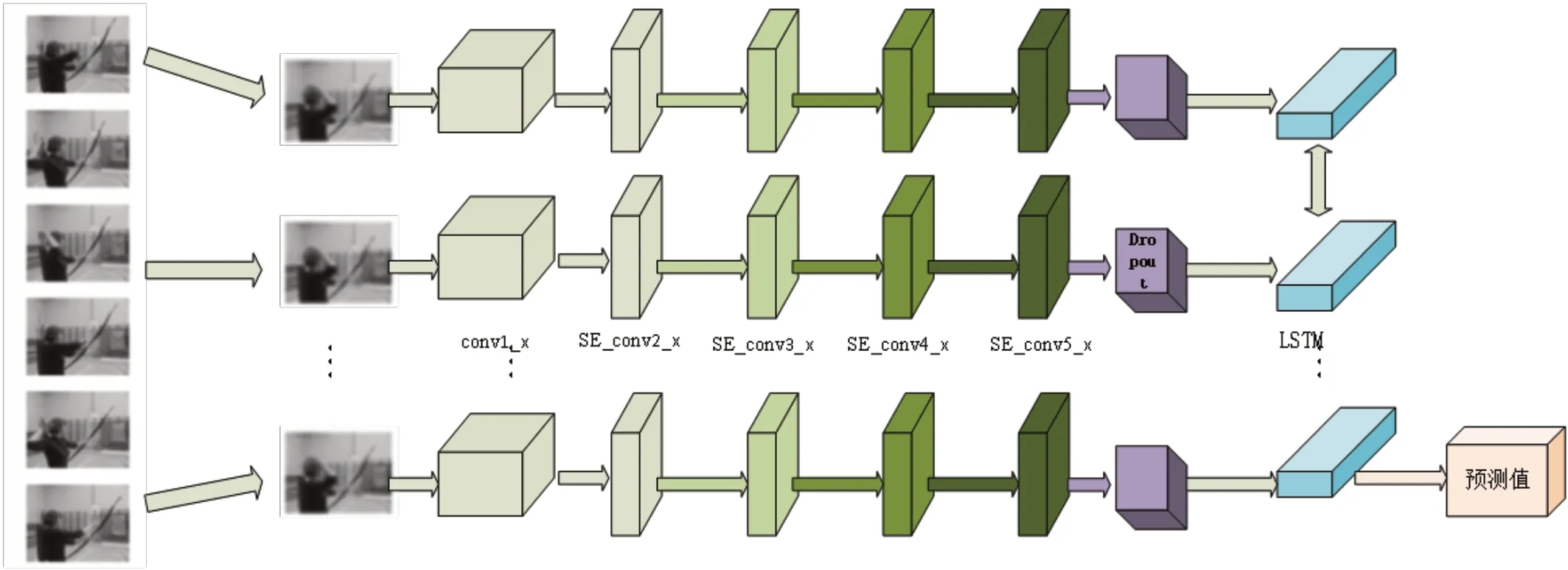
圖1 本文模型網絡流程圖Fig.1 This paper models the network flow chart
在卷積神經網絡模塊中,conv1_x采用了64個7×7大小的卷積核,步長為2,池化層采用卷積核為3的最大池化,步長為2。SE_conv2_x采用3組64個1×1的卷積核、64個3×3的卷積核和256個1×1的卷積核,并且在每組之后添加一組Attention模塊,其中Attention模塊由3個卷積核為1的最大池化、兩個全連接層、ReLU激活函數和Sigmoid激活函數組成,通過加入Attention模塊給提取的通道特征給予不同的權重,提升特征表達的能力,從而提升視頻檢索的準確率。SE_conv3_x采用4組128個1×1的卷積核、128個3×3的卷積核和512個1×1的卷積核,并且在每組卷積之后加入和SE_conv2_x相同的Attention模塊。SE_conv4_x采用6組256個1×1的卷積核、256個3×3的卷積核和1024個1×1的卷積核,并且在每組卷積之后加入和SE_conv2_x相同的Attention模塊。
SE_conv5_x采用3組512個1×1的卷積核、512個3×3的卷積核和2048個1×1的卷積核,并且在每組卷積之后加入和SE_conv2_x相同的Attention模塊。將上一模塊的輸出進行Dropout處理后作為LSTM的輸入進行處理,根據LSTM結構調整輸入序列完成前向傳播過程,最后經過輸出單元將LSTM模塊中的隱層進行輸出。
3 實驗及結果
3.1 數據集
本文實驗是在UCF-101數據集上進行的,該數據集全部從YouTube上收集,包含101個類別共13320個視頻片段。
3.2 實驗細節
本文實驗環境為:處理器:Intel Core i7-6700HQ,顯卡:GTX960M,內存:16G,操作系統:Windows10,編譯平臺:Python、PyTorch1.2.0。
(1)數據預處理。本文首先對UCF-101數據集進行訓練集和測試集的劃分,然后進行關鍵幀的提取工作。其中訓練集和測試集的比例為4∶1并對數據集進行隨機打亂處理,有利于提升模型的健壯性,關鍵幀采用隨機選取的方式并以大小為224×224的圖像作為輸入。
(2)模型訓練。本文提取空間特征是選用嵌入注意力機制的ResNet50網絡,移除最后的全連接層和全局平均池化層。模型的訓練過程總共300個epoch,batch_size為32,優化器使用Adam,dropout為0.4,學習率為0.0001。
(3)參數優化。訓練過程中batch_size、epoch、dropout和網絡深度對準確率影響較大。Batch_size越大,輸入神經網絡的數據量越多,模型的擬合能力越強,當超過一定值,模型的預測效果會向差的方向變化。使用mAP對實驗結果進行評估。其中不同神經網絡層數下使用不同的Dropout進行訓練的結果如圖2所示。

圖2 不同網絡層數在dropout變化下準確率變化情況Fig.2 The accuracy changes under dropout changes at different network layers
可以看出,相同Dropout條件下,mAP通常會隨網絡層數的加深而增大,因為卷積神經網絡的層數會影響視頻的特征提取精度;同一層數卷積神經網絡模型下,mAP值隨著Dropout的增大而增大,當到達一定大小后,隨著mAP的增大反而會減小。其中,在進行的對比試驗中,當卷積神經網絡層數為50且Dropout=0.4時,mAP得到最大值0.94。
3.3 實驗結果
最后為了進一步驗證本文工作,與之前的方法進行對比結果如表2所示,可以看出,本文在UCF-101數據集具有較高的準確度,證明了本文算法的可行性。
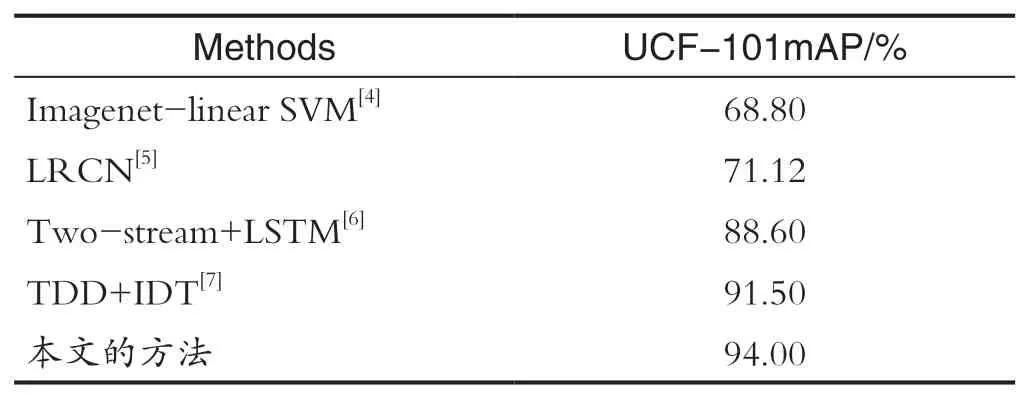
表2 不同算法在UCF-101數據集準確率對比Tab.2 Comparison of accuracy of different algorithms in UCF-101 data set
4 結語
針對不同視頻幀對表達視頻內容的貢獻度和得到的視頻特征不能充分表示該視頻的特征信息和視頻時序信息的特點,本文采用基于注意力機制的視頻檢索方法,通過卷積神經網絡融合注意力模塊進行視頻空間特征信息提取、雙向LSTM實現視頻時序特征提取,可以自動為更重要的信息賦予更高的權重,提高模型的魯棒性和對視頻內容的表達能力,減少過擬合程度,實現精準識別。在UCF-101數據集上進行訓練,完成使用不同網絡層數進行試驗效果對比工作,證明了將注意力嵌入卷積神經網絡獲取的語義特征輸入到LSTM中使得網絡整體性能得到提升,同時準確率也得到了提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
