基于改進SSD算法的農田煙火圖像檢測研究
2022-05-10 01:25:10曹麗英
無線電工程 2022年5期
李 琳,曹麗英
(吉林農業大學 信息技術學院,吉林 長春 130118)
0 引言
隨著我國經濟建設飛速發展,人們生活水平不斷提高,天然氣普及到家家戶戶,各種家電層出不窮,導致對柴草的需求一再減少,農田里的秸稈無處銷售,農民朋友便選擇燃燒秸稈[1]。但燃燒秸稈對環境影響極為嚴重,不僅容易引起“火燒連營”的火災事故,燃燒產生的煙灰更污染了空氣,降低可見度,極易引起交通事故,不完全燃燒產生的氣體會引發人體呼吸道疾病。因此,如何在火焰和煙霧形成早期進行檢測具有重大的理論和實際意義[2]。
農田火災的監控系統多數來自于農田中高塔上的攝像頭和無人機等設備,而這種圖像中往往包括多種物體,比如建筑、道路、汽車和作物等,并且圖像的清晰度受天氣、光照等因素影響[3]。除此之外,圖像中的煙霧和火焰相對于整幅圖像來說很小,而且背景也很復雜。
傳統的煙火檢測方法主要采用傳感器等技術,但是安裝大量傳感器的成本很高,野外放置易受灰塵、氣流和人為因素的干擾,因此檢測精度較低。煙霧檢測在國內外已經做了大量研究,并且基于圖像的煙霧檢測方法也在不斷提出,主要研究方向是結合煙火圖像的動靜態特征進行檢測[4]。典型的動靜態特征包括目標顏色、運動方向、運動范圍和時間軌跡等[5]。
深度學習是機器學習研究的重要領域,相比于傳統算法,深度學習算法可降低硬件成本,不依賴人工特征工程。目前已有學者將深度學習應用于煙霧檢測方向,王中林[6]使用改進的支持向量機進行煙霧檢測;馮路佳等人[7]通過將提取到的運動背景放入卷積神經網絡(Convolutional Neural Networks,CNN)中進行煙霧檢測;段鎖林等人[8]通過對火焰區域進行RGB灰度處理進行火焰區域檢測。
本文結合深度學習,使模型可以自我學習煙霧和火焰的特征,同時利用視頻監控設備和無人機等設備對農田中的秸稈燃燒行為進行數據采集,及時對農田中秸稈燃燒產生的煙霧和火焰進行檢測,可以在秸稈燃燒初期進行相應的檢測,從而實現快速、大范圍的煙火警告。此外,該方法安裝和使用成本適中,有利于進行推廣。Single Shot MultiBox Detector(SSD)算法[9]是目前深度學習目標檢測中較優秀的算法之一,在保證了精度的同時,又提高了檢測速度,可以達到實時檢測的需求。
1 改進SSD網絡模型的構建
1.1 SSD目標檢測算法
SSD是目前主要的檢測框架之一,該方法于2016年由Wei Liu提出,是基于單個神經網絡的目標檢測算法,可以一次完成目標定位與分類。基礎網絡參考了VGG16網絡,為了連接基礎網絡的特征映射圖而補充了輔助卷積層。預測卷積層是預測特征映射圖每個點的矩形框信息和所屬類別信息,從不同層獲取特征并進行預測,隨著層次結構的增加,語義變得更加復雜,SSD網絡結構如圖1所示。SSD算法使用直接卷積的方式對特征圖進行預測并獲取結果。SSD特有的網絡結構使得采用3×3×q的卷積核即可對m×n×q的特征圖進行檢測[10],從而減少計算量。SSD使用低層特征圖檢測小目標,高層特征圖檢測大目標。
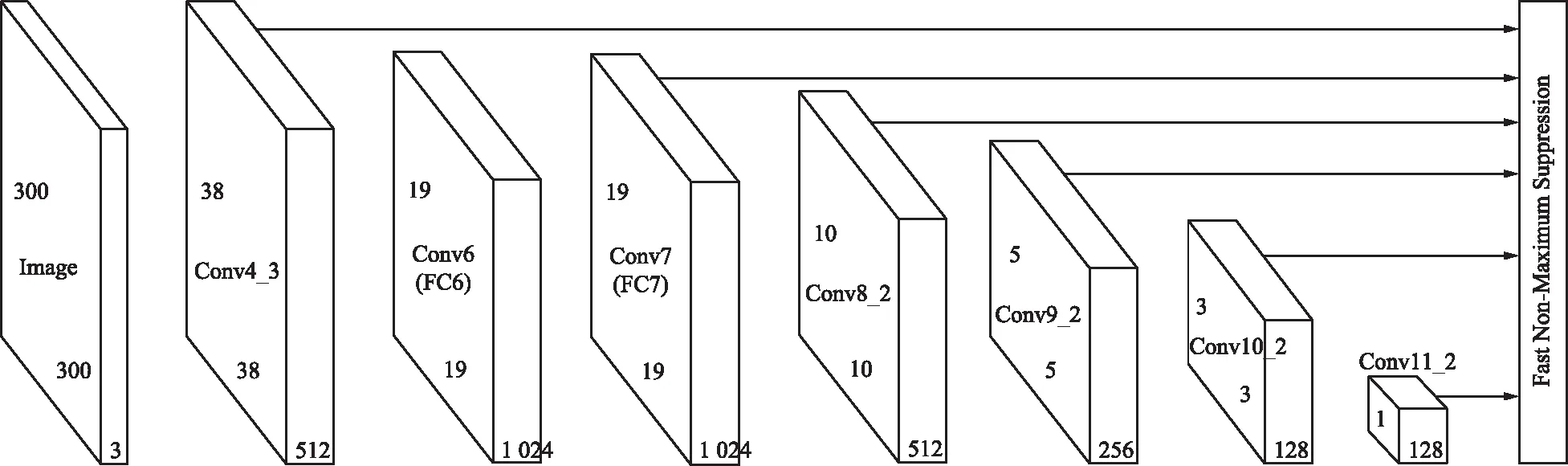
圖1 SSD網絡結構Fig.1 SSD network structure
SSD在預測時參考了Faster R-CNN[11]中候選框的方法,但為了減小訓練時的難度,設置了比Faster R-CNN更少的4個先驗框,有效提高目標檢測速度。SSD算法雖然能夠多層次提取特征,但是隨著層次加深,形狀易發生變化的目標語義會變得更加抽象,特征提取難度大大增加,因此實現不同尺度多種語義層次的特征提取,才能真正意義上幫助模型提升檢測精準度。SSD算法在進行小目標檢測時效果一般,常常出現漏檢現象。
1.2 改進SSD網絡模型
為了使SSD算法更好地契合農田煙火檢測場景,解決SSD對小目標檢測精度不高、訓練過程易產生梯度下降和梯度爆炸等問題,對經典SSD網絡結構進行修改:在經典SSD模型的基礎網絡VGG16的每2個卷積層中引入殘差網絡(Residual Network,ResNet)結構的思想,共組成4個ResNet+VGG16的結構;結合特征金字塔網絡的融合思想,增強SSD網絡對圖像信息進行表達輸出,更好地展現出圖像各個維度的信息,提升小目標的檢測效率,使用組歸一化替代批量歸一化避免數據量小對模型的影響,改進后的SSD網絡結構如圖2所示。

圖2 改進SSD網絡結構Fig.2 Improved SSD network structure
在進行煙火目標檢測時,先驗框的設置極其重要,先驗框尺寸為:
(1)
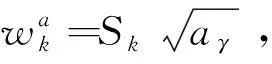
1.2.1 引入ResNet模塊
ResNet是在深度學習中用于提取主干特征的一種網絡模型。在CNN中,網絡層數越多,模型對事物的表征能力越強,但同時會產生性能快速下降的情況,這種情況稱為“退化”。為解決該問題,ResNet網絡應運而生[12]。提出殘差的概念,殘差結構有2種,本文引入的殘差結構如圖3所示。

圖3 殘差結構Fig.3 Residual structure
殘差模塊的數學公式為:
f(x)=h(x)-x,
(2)
式中,f(x)為殘差模塊中的殘差;x為殘差模塊的輸入部分;h(x)為經過第1次線性變化并通過激活函數處理的輸出結果。
改進SSD網絡模型將待預測的圖片進行多層次卷積時,在VGG16網絡的每2次卷積中進行殘差學習,由于存在前后維度不一致的情況,此時使用步長為2的池化層進行降采樣操作,可以避免無用參數對時間復雜度的影響,有效提高特征整合度。
1.2.2 引入特征金字塔思想
特征金字塔網絡是一種高效提取圖片多維度特征的方法,可以使不同尺度特征圖之間互相融合,將淺層細節與高層語義結合并提高圖像識別率,同時對小目標有更高的特征映射分辨率[13-16],可以解決經典SSD算法不能區分不同維度特征信息的缺點,但由于農田復雜的背景會對目標分辨率產生干擾,給FPN特征提取帶來困難。為解決該問題,本文在引入FPN思想時對FPN結構進行調整,改進后結構如圖4所示。
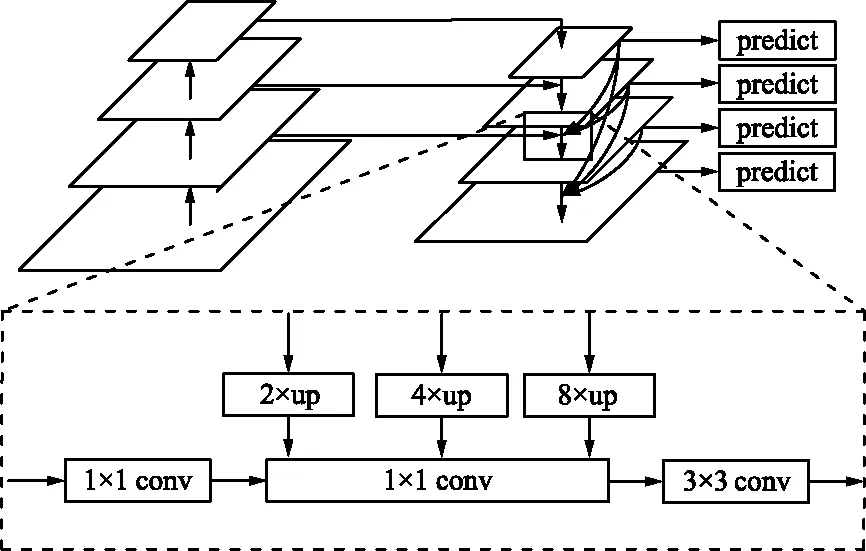
圖4 改進特征金字塔網絡Fig.4 Improved feature pyramid network
改進后的FPN結構可以進行跨層級連接,將高層級特征跨層與低層級特征融合,使用雙線性插值代替臨近插值,得到更優秀的上采樣效果。
改進SSD網絡模型對Conv7采用雙線性插值方法進行上采樣操作,與Conv4_3進行特征融合作為Conv4_3的特征圖,同理將Conv8_2進行上采樣與Conv7進行融合作為Conv7的特征圖,將經過卷積的Conv11_2,Conv10_2,Conv9_2,Conv8_2與融合后的Conv7和Conv4_3組成一個新的特征金字塔通過非極大值抑制進行預測。
1.2.3 歸一化方法
經典SSD算法進行歸一化處理時使用批量歸一化(Batch Normalization,BN)[17]。BN在對大量數據進行歸一化處理時效果較好,能夠有效減少訓練過程中產生的誤差,但在對少量數據進行歸一化時,其訓練產生的誤差會隨著數據量減少而逐漸增大[18]。為了使模型在數據量較少的情況下也能有效減少誤差,本文采用組歸一化(Group Normalization,GN)實現模型的訓練。GN將數據進行分組,每個組中的數據進行歸一化,最后將各組結果合并,其數學表達式為:
(3)
(4)
式中,σ為標準差;μ為均值;x為待歸一化處理的數據。S在GN中定義如式(4)所示,其中C/G代表通道數量。
2 實驗設計
2.1 實驗環境
本文實驗在64位Windows10操作系統下,運行內存32 GB,GPU為GeForce RTX 2080Ti(11 GB顯存),處理器為Inter(R) Core(TM) i9-10900K CPU@3.00 GHz。采用Python3.7和Tensorflow 1.10.0框架實現模型的搭建以及模型的訓練及驗證。
2.2 實驗數據集
由于截至目前還沒有比較權威的煙霧和火焰檢測標準數據集,因此本實驗數據部分來自網絡圖片平臺,部分來自項目拍攝,其中包括在自然環境下,田間高塔定點拍攝圖像和無人機拍攝圖像,經人工篩選,共計3 500張,圖片樣本如圖5所示。通過LabelImg圖像標注工具中的矩形框對圖像進行人工標注,標注時盡量沿待檢測煙霧和火焰邊緣進行標注,以免進行模型訓練時不能夠準確地學習到煙霧和火焰的特征,避免模型不易飽和、誤檢率高的問題。

圖5 圖像樣本集Fig.5 Image sample set
2.3 數據增強
在SSD模型中,數據增強是一種有效增加數據集樣本數量的方式,從而提升模型的泛化能力以及魯棒性[19]。數據增強可以將現有圖像進行縮放操作,對圖像中的小目標進行放大可以更明顯地觀察其內在結構,提高小目標檢測效果。數據增強還可以通過裁剪方式,保留待檢測目標未被遮擋的部分。本文采用如圖6所示的隨機縮放、隨機旋轉和隨機翻轉等方式對數據進行增強。當隨機生成的裁剪框與目標的交并比(Intersection over Union,IOU)不滿足要求,則要求刪除;如IOU滿足但目標中心點不包含在隨機裁剪框也要求刪除,經過數據增強后數據集擴充至7 000張圖片。

(a) 隨機縮放

(b) 隨機旋轉

(c) 隨機翻轉
2.4 實驗過程
整體實驗過程如圖7所示。

圖7 實驗流程Fig.7 Experimental flow chart
將數據集隨機劃分為訓練集和測試集,分別包含5 400張和1 600張圖片。訓練集用于網絡模型的訓練,測試集用于確定模型后進行測試實驗。
實驗采用隨機梯度下降的方法來訓練優化模型[20]。該方法可以在每次迭代過程中只選取一個隨機樣本數據用來更新模型參數,因此迭代次數大幅提升,但每次的學習是非常快速的,并且可以進行在線更新。
首先將數據集分辨率統一為300 pixel×300 pixel,然后使用訓練集來訓練網絡模型。將激活函數學習率設置為e-4,學習率衰減因子設置為0.97,最大迭代步數為2×104,訓練過程中每進行1×103次迭代后將所得模型進行保存,當訓練結束后將目標檢測準確度作為評判標準來選取最優模型。使用測試集對模型進行驗證實驗,并對實驗結果進行分析。
2.5 評估標準
在本實驗中,使用每秒傳輸幀數(Frames pre Second,FPS)、平均精度均值(Meanaverage Precision,mAP)和平均精度(Average Precision,AP)作為目標檢測評估參數[21]。FPS表示1 s能夠處理的圖片數量,值越大說明算法的識別速度越快,mAP是目標檢測算法中常用的綜合評估多個類別下的平均準確率,AP是衡量單個類別下算法的準確率。AP和mAP為:
AP=∑precision/N,
(5)
mAP=∑AP/M,
(6)
式中,precison表示正確檢測圖像數量在算法檢測出圖像數量中的占比;N為目標類別圖片總數;M為類別總數。
3 實驗結果與分析計
3.1 改進網絡結構模型對模型性能的影響
本文在經典SSD網絡模型的基礎網絡中引入殘差模塊,將改進后的SSD模型與經典SSD模型使用相同訓練數據集進行訓練,當模型達到飽和后使用相同測試數據集進行對比實驗,實驗結果如表1所示。
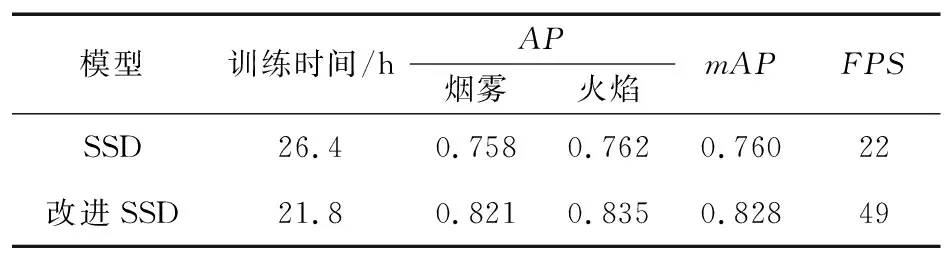
表1 改進SSD模型與經典SSD模型性能對比Tab.1 Performance comparison between improved SSD model and classical SSD model
由表1可以看出,改進SSD模型與經典SSD模型相比較,訓練時間有明顯縮短,并且在檢測速度上提升極為明顯,識別準確率也高于經典SSD模型。
3.2 FPN與多尺度特征圖對模型性能的影響
經典SSD模型使用多尺度特征融合方式從不同層抽取不同尺度特征進行預測,無上采樣過程;FPN結合多尺度特征融合思想,將頂層通過上采樣與低層特征進行跨層級融合,且每層都進行獨立預測。本實驗在改進SSD模型中引入FPN并與原有的多尺度特征圖進行對比,共進行3次測試,測試結果如表2所示。

表2 FPN與多尺度特征圖性能對比Tab.2 Performance comparison between FPN and multiscale feature map
由表2可以看出,在改進SSD模型中結合FPN思想后使模型檢測精度有較大提升,由于FPN中上采樣使得頂層與低層融合,因此在檢測速度上稍遜于多尺度特征圖。
3.3 不同歸一化方法對模型性能的影響
在模型訓練時,對數據進行歸一化的方法極其重要。本次實驗在引入FPN的改進SSD模型中分別使用組歸一化和批量歸一化2種歸一化方法對相同數據集進行對比測試,測試結果如表3所示。

表3 組歸一化與批量歸一化性能對比Tab.3 Performance comparison between GN and BN
由表3可以看出,使用組歸一化替代批量歸一化,在數據量較小時,識別準確率更高。
3.4 不同網絡模型比較
為比較改進后的SSD模型更適用于農田場景下的煙火圖像檢測,在本次實驗中使用改進SSD模型分別與經典SSD模型、YOLOv3模型、Faster R-CNN模型使用相同數據集進行模型訓練,訓練過程中每進行1×103次迭代后將所得模型進行保存,經過2×104次迭代后,4種模型分別生成20個模型,模型準確率曲線和損失曲線如圖8和圖9所示。
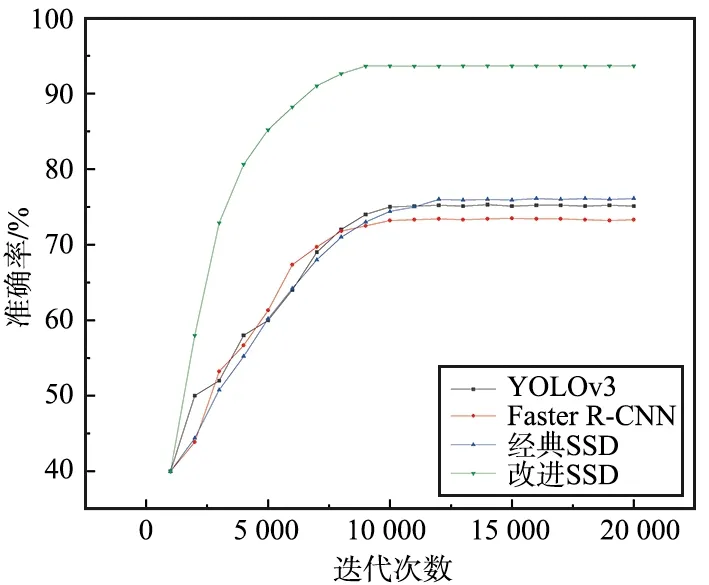
圖8 模型準確率Fig.8 Model accuracy

圖9 模型損失曲線Fig.9 Model loss curve
模型訓練的實質是從不斷迭代的過程中尋找最小損失值的過程。由圖8可以看出,隨著迭代次數增加模型準確率不斷提高,最終趨于穩定。由圖9可以看出,YOLOv3,Faster R-CNN,經典SSD和改進SSD 四種模型分別在0.5×104,0.7×104,0.7×104和1.0×104次迭代時損失曲線趨于平緩,并且分別在1.5×104,1.6×104,1.8×104和1.3×104次迭代時損失曲線趨于收斂,模型達到飽和,此時模型準確率最高,因此選擇這4個模型進行后續測試實驗。從準確率曲線和損失曲線中可以看出,改進后的SSD模型收斂速度更快,收斂效果更好,準確度更高。
為了驗證本文提出的改進SSD神經網絡模型能夠有效識別圖片中的煙火小目標,將改進的SSD模型與經典SSD模型、YOLOv3模型和Faster R-CNN模型使用相同的測試數據集進行實驗,并對得到的結果進行分析,實驗結果如圖10所示。

圖10 煙火目標檢測效果Fig.10 Smoke and flame detection effect
由圖10可以看出,4種模型均能夠對圖片中的煙霧圖像進行檢測,改進SSD模型能夠有效對圖片中的煙霧和火焰目標進行檢測,其他3種模型均存在較為明顯的漏檢現象;圖片中煙火圖像相對較小,YOLOv3模型、Faster R-CNN模型和經典SSD模型未能有效識別,而本文所采用的模型能更好地識別小目標。不同煙火檢測模型的測試結果統計如表4所示。

表4 煙火目標檢測模型對比Tab.4 Comparison of smoke and flame target detection models
通過使用不同的網絡模型對相同測試集圖片中煙霧、火焰圖像檢測生成的結果進行分析,可得到如下結論:
① 從對圖片中圖像較小的火焰識別結果來看,引入殘差思想后的SSD模型結合FPN可以有效地將淺層細節與高層語義相結合,并使用組歸一化方法進而大幅度提升圖像中較小火焰識別的精準度。與YOLOv3模型相比,在煙霧識別上AP值提升20.4%,在火焰識別上AP值提升16.6%。與Faster R-CNN模型相比,在煙霧識別上AP值提升21.6%,在火焰識別上AP值提升19.1%。與經典SSD網絡模型相比,在煙霧識別上AP值提升18.0%,在火焰識別上AP值提升17.6%。
② 在使用相同測試集進行實驗的情況下,改進SSD模型相對于YOLOv3模型、Faster R-CNN模型和經典SSD模型在檢測準確度上均有較大提升,實驗結果表明,mAP值分別提高了18.5%,20.3%和17.7%。
③ 從圖像檢測速度來看,YOLOv3模型比經典SSD模型和Faster R-CNN模型的效率更高,由于本文提出的模型在經典SSD模型的結構上進行改進,速度提升更為明顯,改進后的SSD算法FPS比YOLOv3模型高18,比Faster R-CNN模型高30,比經典SSD模型高24。
4 結束語
本文提出了一種基于改進SSD算法的煙火圖像檢測方法,可以在農田秸稈燃燒等行為產生煙霧和火焰的初期進行有效的監測,為有關環保部門及時提供預警。煙火識別的核心問題在于提取有效的煙霧和火焰的特征。在使用深度學習對煙霧火焰檢測分類的基礎上,解決了傳統CNN計算量大、占用存儲空間大和計算時間長的問題。將改進后的SSD煙火檢測模型與YOLOv3模型、Faster R-CNN模型和經典SSD模型進行仿真實驗,可以看出改進后模型對煙火目標檢測更精確,尤其對小目標的識別定位更加精準,同時在檢測速度方面有較大提升。在接下來的研究中將繼續擴充數據集并對網絡結構進行更深層次優化,使模型達到更加優秀的效果。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
