基于LDA和加權Word2vec的科學知識圖譜構建研究
2022-05-12 09:25:24楊云帆李坤琪楊秀璋羅子江
現代計算機 2022年5期
趙 凱,楊云帆,袁 杰,李坤琪,楊秀璋,羅子江
(貴州財經大學信息學院,貴陽 550025)
0 引言
隨著科學研究環境逐步改善,大量研究成果問世,科學文獻數量呈指數式增長,但是科研工作者閱讀、分析、利用文獻的速度遠遠低于文獻發表的速度,科學知識圖譜就是在此情況下出現的一種提升文獻利用效率的科學方法,在趨勢研究、熱點發現、學科發展研究方面具有重要意義。有關科學知識圖譜最早可追溯到20 世紀60年代,美國科學研究所名譽所長Eugene 等人在引文數據的基礎上手繪完成DNA 領域發展圖譜,此后,作為科學知識圖譜發展史上具有里程碑意義的文獻共被引分析和作者共被引分析方法也被逐步提出,為科學知識圖譜的早期發展奠定了堅實基礎。21 世紀以來,眾多學者致力于科學知識圖譜可視化的研究,2004年美國雷德賽爾大學的陳超美教授開發了CiteSpace,后由大連理工大學WISE 實驗室引入國內,主要功能是對特定領域文獻進行計量以探尋學科領域演化的關鍵路徑及知識轉折點;2008年瑞典于默奧大學的Perrson 教授開發了BibExcel,主要用于文獻計量分析;2009年荷蘭萊頓大學科技研究中心的Van和Waltman開發了VOSviewer,主要面向文獻數據,側重科學知識的可視化。近年來國內關于科學知識圖譜的文獻數量也逐年增多,據中國知網相關數據顯示,2019年與科學知識圖譜相關的中文文獻量為714篇,相比2018年的553篇增長了29%。
1 相關研究概述
科學知識圖譜作為一種直觀展示科學知識間關聯度的方法,受到眾多學者青睞。國外相關研究中,Price作為科學知識圖譜的早期開拓者,為科學知識圖譜的發現與發展做出了重要貢獻;德國著名科學計量學家Kretschmer有關三維空間模型的研究為科學知識圖譜的進一步發展奠定了堅實的基礎。我國學者對于科學知識圖譜的研究相比于國外學者較晚,陳悅和劉則淵于2005年將科學知識圖譜的概念引入國內,為我國科學知識圖譜相關研究奠定基礎;侯海燕以可視化方法對《科學計量學》1978年至2004年發表的1927 篇論文做作者共引分析,發現世界上最有影響力的50 位科學計量學家;劉榮在科學知識圖譜的基礎上,通過多維度分析、主成分分析等方法,研究分析了創新歷史與其現狀,并在此基礎上針對我國的實際情況,提出保持較高增速與增強國力的幾點建議;歐陽芬和張蕾選取1949—2019年CNKI數據庫中收錄的2248 篇有關語文教材的相關論文,運用CiteSpace 軟件繪制語文教材的研究機構、研究作者、研究熱點等知識圖譜,深層挖掘新中國成立70周年以來語文教材的發展趨勢;王露楊和楊國立收集CSSCI 中11284 篇與外國語言學研究有關的論文,運用知識圖譜方法分析了外國語言學研究的研究熱點和發展趨勢;王山等運用關鍵詞共現網絡圖譜分析、關鍵詞引用突變分析、共詞聚類分析等方法對中國知網數據庫下載的2013—2017年政治經濟學研究領域的相關文獻進行了科學計量分析,發現了近年政治經濟學的研究現狀、研究熱點,預測了政治經濟學未來的發展趨勢;陶于祥等采用時間演化分析、詞頻分析等方法,利用CiteSpace可視化軟件作出學科共現圖譜,綜合梳理了國內外人工智能領域的發展脈絡、演變過程和研究熱點;許曉陽等通過結合專利與論文兩類文獻,以關鍵詞共現為基礎,識別學科研究熱點。
綜上所述,科學知識圖譜中,關鍵詞共現圖譜與主題演化圖譜是學者們常用的可視化分析方法,其中的常規算法通常采用向量空間模型(vector space model,VSM)表示文本。基于向量相似距離來計算文本相似度,主要缺陷是沒有考慮詞語之間的語法關系,忽略了詞語之間的相似性,無法解決文本數據中存在同義詞和多義詞的情況。針對此問題,本文采用基于潛在狄利克雷分布(latent dirichlet allocation,LDA)和加權Word2vec 的科學知識圖譜構建方法。該方法首先利用LDA 模型抽取主題及每個主題下的關鍵詞,再用Word2vec 獲取每個主題下關鍵詞的詞向量,通過加權計算詞向量得到主題向量,進而計算主題相似度與重要度,最后以可視化方法構建主題共現圖譜和主題演化圖譜,從而達到從語義層面揭示領域發展變化的目標。
2 相關技術介紹
2.1 LDA模型
LDA是一種無監督學習的主題概率生成模型,也被稱作三層貝葉斯概率模型,是在PLSA(probabilistic latent semantic analysis)模型的基礎上增加貝葉斯架構模塊所形成的,具體模型如圖1所示。
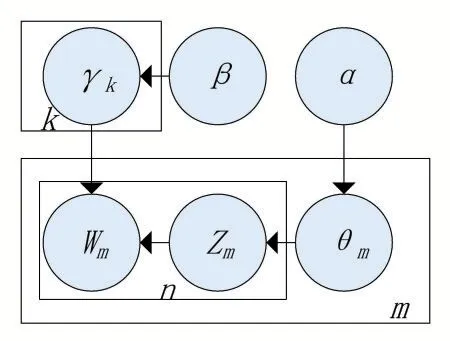
圖1 LDA文檔主題生成模型
2.2 Word2vec
Word2vec是2013年Google 公司開發的一款用于詞向量計算的開源工具,它根據上下文信息將輸入的特征詞訓練為詞向量,用空間向量的相似度來表示語義相似度。其提供兩種語言模型,分別是CBOW(continuous bag-ofwords)模型和Skip-gram 模型。CBOW 模型旨在通過上下文來預測當前詞的概率,其結構如圖2 所示;Skip-gram 模型則利用當前詞的詞向量來預測上下文,其結構如圖3所示。兩種模型輸入輸出的內容完全相反,但在模型的訓練過程上是相同的。

圖2 CBOW模型
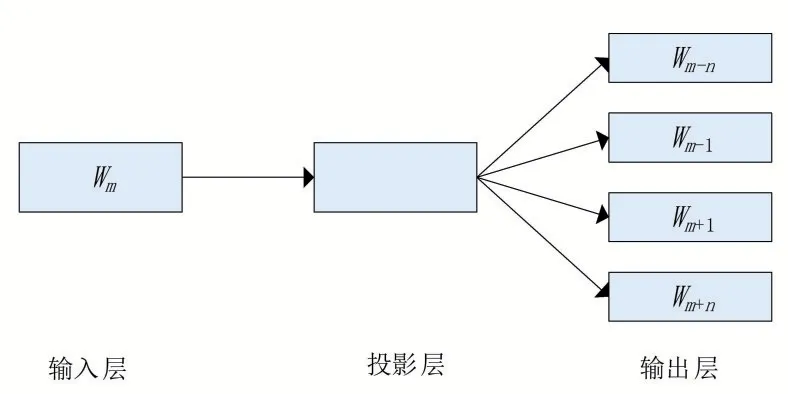
圖3 Skip-gram 模型
3 基于LDA和加權Word2vec的科學知識圖譜構建研究
本文旨在從語義層面揭示領域發展變化情況,采用基于LDA和加權Word2vec 的科學知識圖譜構建方法,以中國知網某領域期刊題目、摘要及關鍵詞作為分析對象,經過數據預處理后,利用LDA 模型抽取主題與關鍵詞,再采用Word2vec 獲取關鍵詞的詞向量,通過加權計算詞向量得到主題向量,進而計算主題相似度與重要度,最后以可視化方法構建知識圖譜。具體流程如圖4所示。
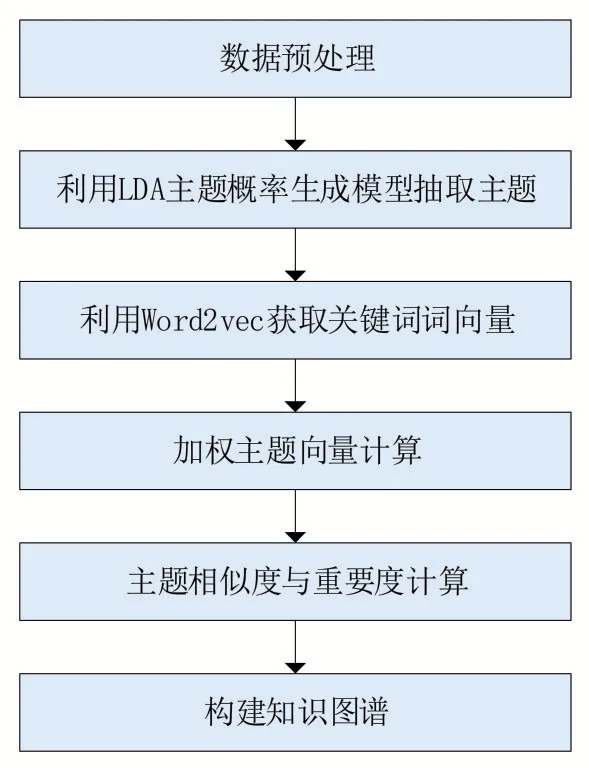
圖4 基于LDA和加權Word2vec的科學知識圖譜構建研究方法
3.1 數據來源與數據預處理
期刊論文的題目、摘要和關鍵詞能夠較好地反映研究領域的熱點主題和發展過程,因此本文以中國知網某領域期刊題目、摘要及關鍵詞為分析對象。數據預處理主要包括中文分詞、去除停用詞和關鍵詞過濾。文中運用的分詞工具為Python 語言環境下結巴(Jieba)分詞工具;去停用詞階段使用的是哈工大公開的停用詞表;關鍵詞過濾采用TF-IDF 算法,通過計算每個詞語的TF-IDF 值過濾小于指定閾值的詞語,形成關鍵詞集合。
3.2 利用LDA主題概率生成模型抽取主題
本文基于Python 第三方模塊sklearn 中的LDA 模型實現主題分布研究,并調用可視化包pyLDAvis 來確定主題數量。對比傳統的困惑度方法,視距圖(Intertopic Distance Map)更加清晰直觀地展現各主題之間的關系和對應主題下關鍵詞詞頻,從而達到合理確定主題數量的目標,避免主題中關鍵詞重疊或過于稀疏。
3.3 利用Word2vec獲取關鍵詞詞向量
研究以預處理后的文檔為基礎數據,采用CBOW 模型,利用Python 語言下的Word2vec 第三方包將詞訓練為詞向量,然后從中提取主題下各關鍵詞的詞向量,以便后續處理。
3.4 加權主題向量計算
主題為多個不同頻次的關鍵詞集合,以往研究通常采用主題內所有關鍵詞詞向量的均值來表示該主題向量,但這種方法沒有考慮到詞頻問題。因此本文采用TF-IDF 加權平均法對主題內不同關鍵詞賦予不同權重,計算公式如式(1)所示。
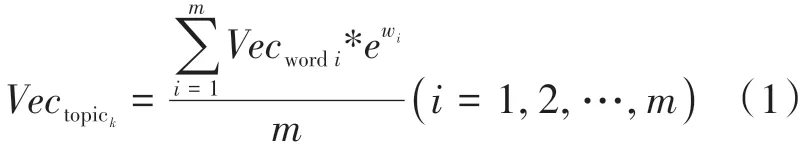
式(1)中:表示主題的主題向量;為關鍵詞的詞向量;w為關鍵詞的TFIDF值;為主題中關鍵詞數量。
3.5 主題相似度與重要度計算
主題相似度(resemblance,Res)反映主題之間的關聯性和演化趨勢,其值為不同主題之間的語義相似度,表示主題間的關聯性,是以夾角余弦公式為基礎改進的,具體計算公式如式(2)所示。
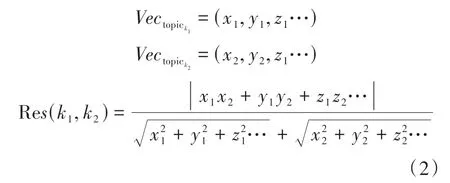
式(2)中:是根據式(1)計算得到的加權主題向量;(,,…)表示主題向量各個維度的數值;Re(,)表示主題與主題間的主題相似度。
主題重要度(imporantance,Imp)反映主題在研究領域內的重要程度,數值的大小與主題重要度成正比,其隨時間的變化情況能夠反映主題在領域中相對重要性的變化。本文采用主題內各關鍵詞TF-IDF 的均值表示主題重要度,具體計算公式如式(3)所示
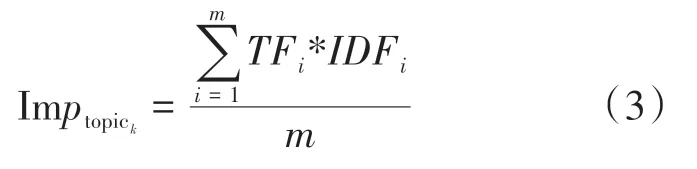
式(3)中:topic表示主題;為主題中關鍵詞個數;TF與IDF分別表示關鍵詞的文本頻率與逆文檔頻率指數。
3.6 科學知識圖譜構建
目前基于內容分析的科學知識圖譜存在以下不足:①關鍵詞共現圖譜不具有主題概念、無法判斷關鍵詞歸屬。②主題演化圖譜不包含時間信息,無法判斷主題隨時間的變化趨勢。解決上述問題。本文參照傳統的關鍵詞共現圖譜和文獻主題演化圖譜,構建包含關鍵詞歸屬的主題共現圖譜和增加時間橫軸的主題演化圖譜,結合兩種圖譜集中展示學科主題、主題重要度和主題相似度等三個方面的信息。
(1)主題。通過圓形表示每個主題,在主題演化圖譜中結合了時間橫軸展現不同時間段的主題信息。
(2)主題重要度。通過圓形的大小表現主題重要度,圓形半徑越大,主題重要度越高。
(3)主題相似度。為展現各主題隨著時間推移的演變趨勢,將各主題用寬度不等的線連接,連線的寬度與主題間相似度成正比。
4 實證研究結果
為了驗證本文提出的基于LDA和加權Word2vec 的科學知識圖譜構建方法的可行性,本文采用信息服務領域的期刊論文做實證研究,數據來源于中國知網數據庫,主要包含期刊題目、摘要和關鍵詞三個方面,涉及58917篇期刊論文,時間節點跨越2000—2019 共20年。研究將整體數據分為兩種形式,第一種是將20年數據依據每4年一個階段劃分為5 部分,在此基礎上繪制主題演化圖譜,以研究近20年信息服務領域的主題演化趨勢;另外一種是將總數據進行整體分析,所得結果作為主題共現圖譜繪制依據,借此探討信息服務領域近20年來的研究熱點。
4.1 主題提取結果
本文通過調用pyLDAvis 繪制視距圖以確定合理的主題數量,因篇幅限制僅展示總數據主題1 的關鍵詞,如圖5 所示,五個圓圈表示五個主題,基本沒有重疊,表示提取效果良好,右邊為關鍵詞詞頻。另外總年段數據的主題提取結果如表1所示,各年段數據的主題提取結果如表3所示。

表1 2000—2019年總數據各主題關鍵詞
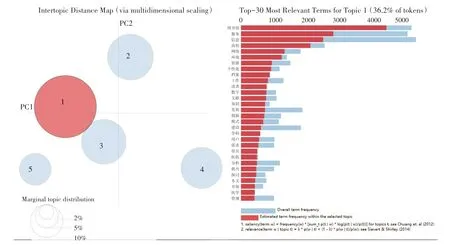
圖5 總數據視距圖
4.2 主題相似度與主題重要度計算
主題相似度計算:利用式(2)計算總數據不同主題間的相似度,舉例來講就是分別計算出主題1 與主題2、3、4、5,主題2 與主題3、4、5,主題3 與主題4、5,主題4 與主題5 之間的相似度。
主題重要度計算:主題重要度主要依據主題關鍵詞的TF-IDF 值,按式(3)計算,基于以上兩種條件,計算出總數據與各年段下每一個主題的主題重要度。總數據主題重要度與相似度如表2所示,由于篇幅原因,分年度數據不做贅述。

表2 總數據主題重要度與相似度
4.3 科學知識圖譜構建
主題共現圖譜結果如圖6所示。
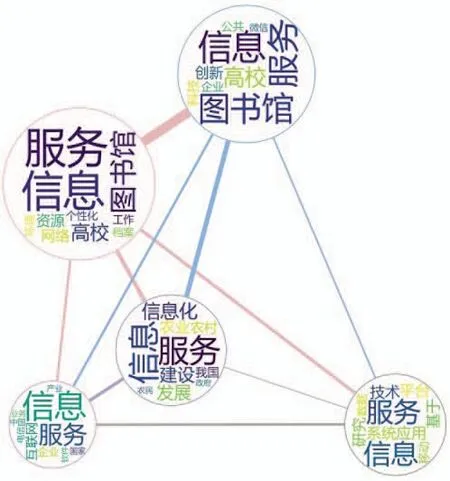
圖6 主題共現圖譜
從圖中可見:
(1)近20年來,信息服務領域主要的研究方向為高校圖書館個性化建設和技術創新、基于信息服務平臺的“三農”發展、基于計算機應用系統的技術研究、中國互聯網企業研究等。以上研究對象具有一個共同的特點:均是以信息資源管理為基礎,通過對數據的分析與處理,為主體的發展提供服務。
(2)從主題重要度來講,近20年間信息服務在高校圖書館方向的研究是一大熱點,與高校圖書館相關的主題重要度分別占據前兩位,主要原因是信息服務是高校圖書館最基本的職能之一,高校圖書館也為信息服務的發展提供良好的條件,憑借5G、大數據和云計算等高新技術得到進一步發展,如5G 時代高校圖書館信息服務、大數據環境下高校圖書館研究和云計算環境下高校圖書館服務模式探索等均是一種體現。
(3)從主題關聯度來講,高校圖書館個性化建設和技術創新兩個主題之間關聯度最大。隨著互聯網技術的發展,網絡資源對圖書館的沖擊最大,而技術創新與個性化建設均是為了提升圖書館信息服務水平,兩者互為補足,互相促進,是圖書館適應社會發展趨勢的重要方法;高校圖書館個性化建設與中國互聯網企業研究關聯度最小,主要原因是二者研究對象具有明顯差異,高校圖書館最主要的職能是為高校師生提供學習、研究的良好環境,屬于服務為主的部門,而互聯網企業是盈利性機構,是以計算機網絡技術的發展為生存的根本,但是近年來高校圖書館與互聯網企業的聯系越發緊密,互聯網企業為圖書館信息技術的建設提供了巨大幫助,相信這會是二者不斷協調發展、互相促進的契機。
主題演化圖譜結果如圖7所示。
結合表3和圖7可以看出:
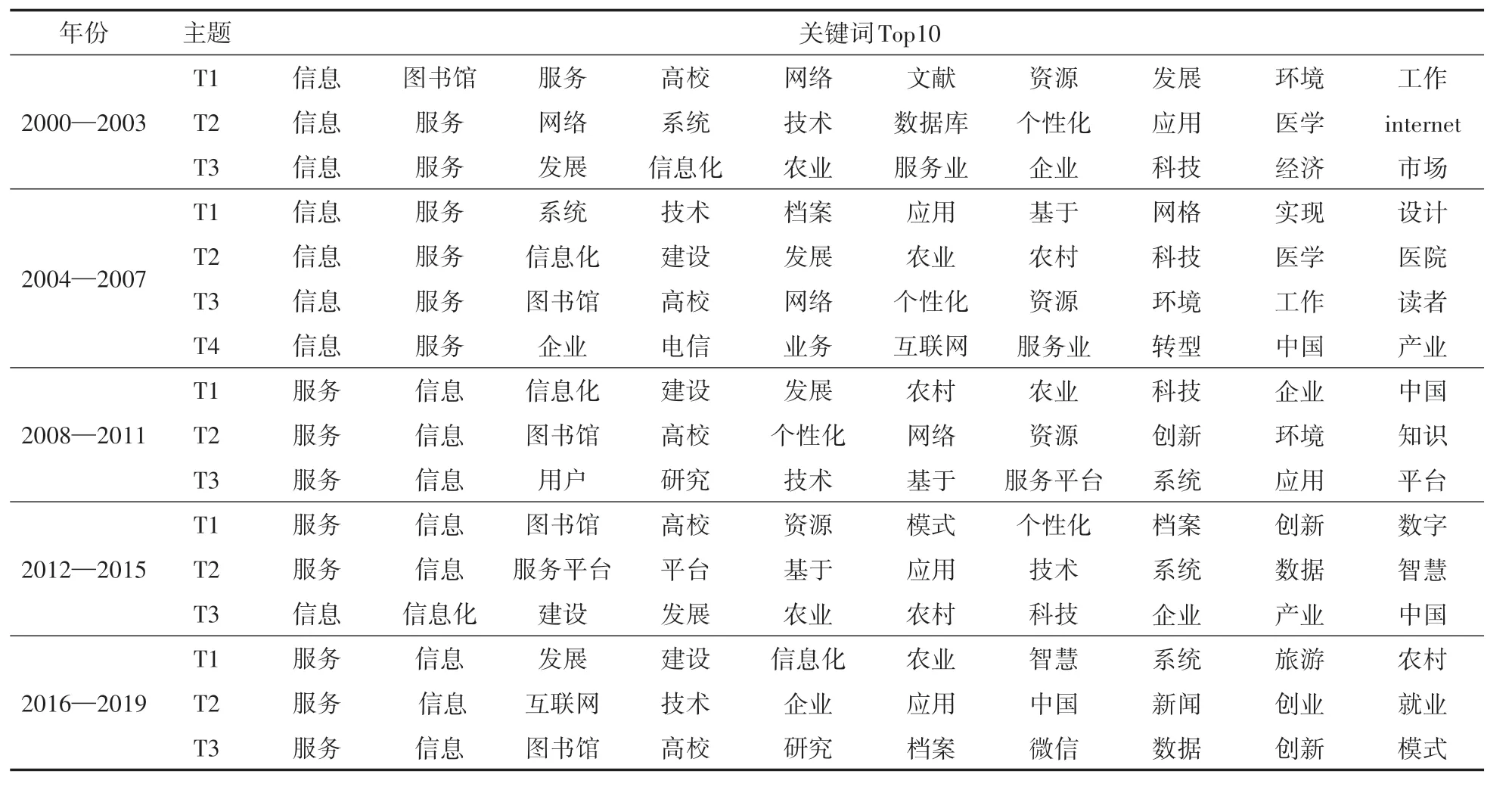
表3 2000—2019年各年段主題關鍵詞
(1)各年段研究側重點不同。2000—2003和2004—2007 兩個年段,該領域主要側重點是對信息技術的發展,而2008年至今三個年段主要側重點是服務,基于這種現象,我們認為信息服務是基于信息技術才實現對社會的服務,堅實的信息技術是支撐服務的基礎,但并非完全舍棄對信息技術的發展,而是在利用信息技術服務社會的同時也同樣重視信息技術的發展。
(2)從主題關聯度來看,20年間存在三條關鍵主題演化路徑(圖7 中三種顏色不同的路徑),分別是高校圖書館、計算機技術應用和農業農村方向的研究。而且各路徑在大的研究方向下不斷出現新的研究內容,同時也伴隨著舊研究內容的消失,以高校圖書館演化路徑為例,2000—2003年以文獻資源的研究為重點,隨著時間的推移,結合社會發展,2004—2007年段出現讀者個性化研究、2008—2011年段出現圖書館創新、2012—2015年段出現數字圖書館研究、2016—2019年段則以圖書館服務模式創新為主要研究方向。
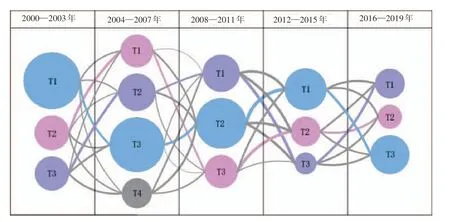
圖7 主題演化圖譜
(3)從主題重要度來看,高校圖書館演化路徑中每個主題的重要度在其所在年段均為最大,并且研究內容均與高校圖書館有關,因此本文認為有關高校圖書館的研究是信息服務領域近20年間最大的研究熱點,這種趨勢也會繼續延續下去。
5 結語
科學知識圖譜作為一種直觀展示科學知識間關聯度的方法,可以大幅提升文獻利用效率,在趨勢研究、熱點發現、學科發展研究方面具有重要意義。針對現有可視化分析算法中沒有考慮詞語間語法關系、忽略詞語間相似性、無法解決同義詞和多義詞的問題,本文提出一種基于LDA 與加權Word2vec 的科學知識圖譜構建方法,實現文本-詞向量-知識圖譜的一系列轉化,達到從語義層面揭示領域發展變化情況的目標。首先,研究以中國知網信息服務領域期刊數據為分析對象,經過數據預處理后,利用LDA 模型抽取主題及每個主題下的關鍵詞,再采用Word2vec獲取每個主題下關鍵詞的詞向量,通過加權計算詞向量得到主題向量,進而計算主題相似度與重要度,最后以可視化方法構建主題共現圖譜,分析了現階段信息服務領域各大研究方向、研究熱點與其關聯性,同時構建主題演化圖譜,揭示了領域內各階段研究側重點,挖掘出關鍵主題演化路徑與其發展趨勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
小太陽畫報(2018年1期)2018-05-14 17:19:25
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
光學精密工程(2016年6期)2016-11-07 09:07:19
