基于特征選擇改進的隨機森林IP定位方法
2022-05-12 09:25:28張鶴林劉淵博
現代計算機 2022年5期
張鶴林,甘 勇,2,劉淵博
(1.鄭州輕工業(yè)大學計算機與通信工程學院,鄭州 450001;2.鄭州工程技術學院,鄭州 450001)
0 引言
隨著互聯網的飛速發(fā)展,網絡應用、網絡數據和網絡實體等逐步構成了網絡空間,網絡空間與海陸天空等地理空間不同,是一個動態(tài)空間,數據交互極快。但是從網絡空間安全的角度出發(fā),還是很有必要對網絡空間進行測繪。網絡實體定位技術如同地理空間測繪中的水文測量技術一樣,能夠實現網絡實體資源到地理空間的映射,是網絡空間測繪的基礎,由于網絡實體通常可以通過網絡實體的IP 地址來進行唯一標識,從而確定該網絡實體在一定粒度上的地理空間位置,因此又可以稱為IP 定位技術。
目前主流的IP 定位技術有三類:基于數據庫查詢的方法、基于網絡測量的方法和基于機器學習的方法。基于數據庫查詢的方法方便快捷,但是定位結果完全取決于數據庫,可能會有很大的誤差。基于網絡測量的方法是較傳統且有效的方法,主要通過網絡測量獲取網絡實體之間的網絡空間信息,比如最常用的時延和跳數兩種信息,將其通過一些參數近似轉換為物理空間的距離,從而推斷出目標IP 的地理位置。基于機器學習的方法其核心思想是將IP 定位轉換為分類或者聚類問題,以IP 地址、時延和跳數等信息作為特征來訓練模型,從而得出目標IP的地理位置。
本文結合了網絡測量的數據和IP 地址本身共同形成多特征的數據集,使用隨機森林這一機器學習分類模型,并根據網絡IP 地址數據不平衡和各特征重要性不一致會影響網絡IP 定位結果的特點,對特征權重算法Relief F 做出改進,融入隨機森林分類算法的特征選擇步驟中,提出一種基于特征選擇改進的隨機森林城市級IP定位方法。
1 特征選擇算法改進
1.1 Relief F算法改進
Relief 算法是一種比較常見且高效的特征權重算法,其核心思想是根據數據中每個特征對于分類的相關度不同,計算給出不同的權重,再根據不同的要求設定閾值,丟棄不符合閾值要求的特征。假設訓練集為,一般是隨機選取出一個樣本,首先需要找到樣本同類型且最近鄰的樣本,然后再找到樣本不同類型同樣最近鄰的樣本。對于數據中任一個特征來說,如果與的距離小于與的距離,就認為特征是有利于提高分類準確率的,該特征的權重就會適當加大,反之則減小權重。一般來說,都會多次計算取各特征權重平均值,假設計算次,各特征的計算方式如式(1)所示。
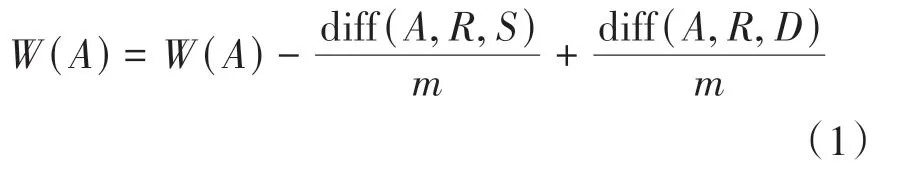
由于Relief只能處理二分類問題,改進算法Relief F 算法在Relief 算法基礎上增加了多分類問題的解決策略,其核心思想是:把抽取樣本和樣本這一過程,重新設置為從每類樣本分別找到個最近鄰的樣本。此方法不僅能提高算法穩(wěn)定性,同時也減輕了噪聲對結果的干擾,權重計算方式如式(2)所示。
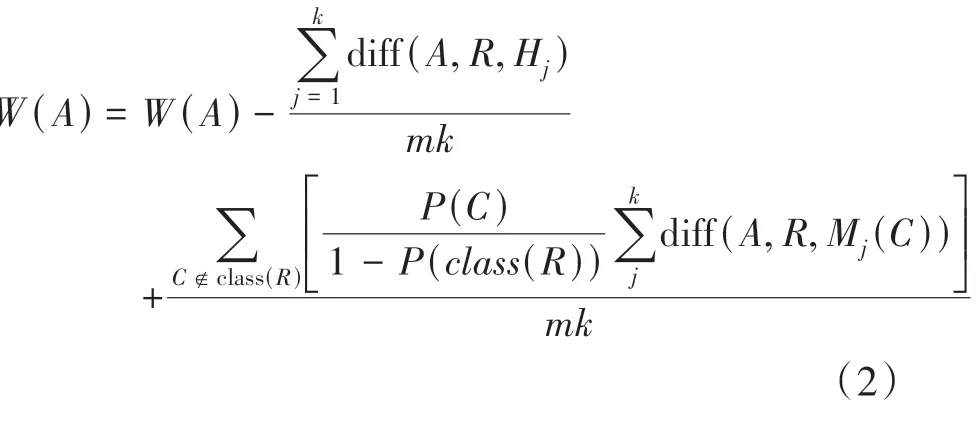
()是原數據集中類別為的樣本所占比例,M()表示類?class()中第個最近鄰樣本,diff(,,)表示對于特征來說,樣本和的差。
Relief F算法的改進僅僅是針對分類問題的,算法在抽取不同類別樣本時采用的是隨機抽取相同數量的樣本的方式,一般情況下能達到很好的穩(wěn)定性和抗噪聲干擾能力,但是要想解決不平衡數據引起的問題,這并不是最佳的方式。
因此,本文對以上Relief F 算法的抽樣步驟做出改進,通過提高少數類樣本的抽樣比重,使得特征對少數類有更多的決定權。具體做法是:假設為訓練集樣本個數,其中為正類樣本的數量,同樣的為負類樣本的數量,為初始抽樣的數量,取值為訓練集中少數類樣本的數量,為最近鄰同類樣本的數量,為最近鄰異類樣本的數量。若抽取的樣本為正類和負類時,則分別為式(3)和式(4)所示,的值均為-。
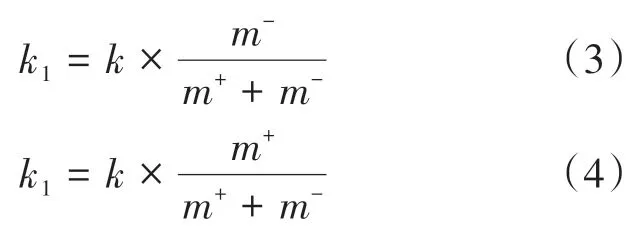
在計算對應特征的權重時,原本的值是固定設置的,改進后分別設定。這樣保證其為樣本集中的少數類數量,同時也在抽樣過程中確保少數類比多數類具有更高的比例,這是針對IP 地址數據的不平衡的特點進行的改進,理論上可以避免多數類造成的分類精度假高問題,改進后的權重公式如式(5)所示。

1.2 R-RF算法流程圖及偽代碼
Relief F 算法在隨機森林中的應用主要是將特征進行排序,按權值大小將特征平均的分成三個區(qū)間。在之后隨機森林算法生成決策樹步驟中,均勻的抽取三個區(qū)間的特征,組成分類效果均勻的特征子集訓練決策樹,將新算法命名為R-RF算法,其具體流程如圖1所示。
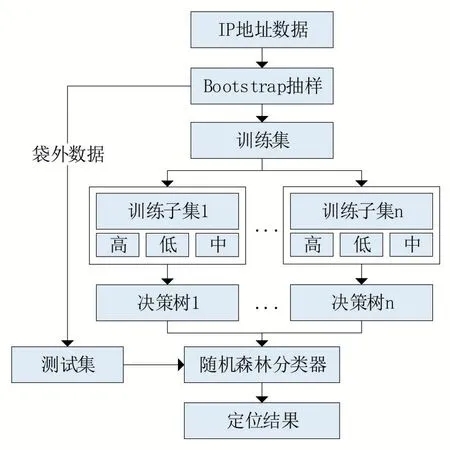
圖1 Relief F結合隨機森林算法流程
首先對IP 地址數據集采用Bootstrap 方法進行抽樣,隨機得到各訓練子集,其中袋外數據集作為測試集用于最后的算法評估,然后對所有訓練集數據運用上一節(jié)的改進Relief F 算法計算特征權重,得到帶有權值的特征集合。特征按權值大小排序,權值越大的分類性能越好。將排好序的特征按照分類性能平均的分為高、中、低三個特征集合。在構建決策樹時,不再采用隨機抽樣的策略,而是在高中低三個特征集合中均勻的抽取特征,保證生成的決策樹有很高的穩(wěn)定性。不斷地進行特征抽取生成決策樹,組成最終的隨機森林。
R-RF算法核心步驟偽代碼

2 構建多特征IP地址數據庫
現有的IP地址數據庫,大多數對于信息如何采集并不公開,不同的IP 地址數據庫在更新頻率、IP地址覆蓋率和聲稱的準確度上都會有一些差異。表1 列舉了四個國內外具有代表性的IP地址數據庫,對它們的一些關鍵信息加以展示。

表1 常見IP地址數據庫關鍵信息
IP 地址數據庫中的信息通常包含了IP 地址段、運營商、大洲、國家、省級區(qū)域、城市級區(qū)域、經緯度和郵編等信息,其中IP 地址數據庫的部分屬性可能會缺失,如:Country=中國,Region =未知,City=未知,ISP=中國電信,ZIP Code=未知。為了補全不同IP地址數據庫中可能缺失的信息,同時結合IP 地址本身和網絡測量數據作為特征,從而提高算法的分類精度,需要構建多特征IP 地址數據庫,其完整的構建過程如圖2所示。

圖2 多特征IP地址數據庫構建流程
首先將各IP 地址數據庫里的數據統一化處理,統一處理為數值或者字符串便于分類識別,再根據IP 地址段選擇出2個及以上IP 地址數據庫均收錄的信息,僅有1個數據庫收錄的IP 地址段信息其可靠性不高,丟棄該條記錄。對于其他的特征信息,如果所有數據庫都沒有記錄這些信息,無法互相補全,同樣丟棄該條記錄。如果有數據庫收錄了這些特征信息但是完全不相同,根據優(yōu)先級選擇特征信息,如果是不完全相同的情況,通過投票的方式決定特征信息。經過這一步的處理,可以得到初步融合的IP 地址數據庫。
其中優(yōu)先級選取的原則,根據四個IP 地址數據庫城市覆蓋率大小定義優(yōu)先級先后為:IP2location、百度、純真、新浪。經過上述過程初步融合的IP 地址數據庫,其中記錄的IP 地址數據各特征為IP 地址、運營商、省級區(qū)劃代碼、城市區(qū)劃代碼。再對以上初步融合的IP 地址數據庫中每一條IP 地址使用探測源進行網絡測量,得到時延和跳數信息,丟棄無法進行網絡測量的IP 地址數據。再將IP 地址分割為4 段,最終得到本文實驗使用的多特征IP地址數據庫,其各特征分別為IP1、IP2、IP3、IP4、運營商、時延、跳數、省級區(qū)劃代碼、城市區(qū)劃代碼。
最終得到的多特征IP 地址數據庫,不僅具有更多的特征,信息也更加完整,能有效提高IP定位的準確率。
3 實驗與結果分析
3.1 各特征權重計算
根據多特征IP 地址數據庫的數據,首先需要評價并計算出每個特征對于分類的貢獻度。本文使用隨機森林算法分別對多特征IP 數據庫中每一個特征進行分類測試,得到準確率、精準率與召回率的調和平均數(F1-Measure)以及ROC 曲線面積這三項評價指標的結果如表2所示。
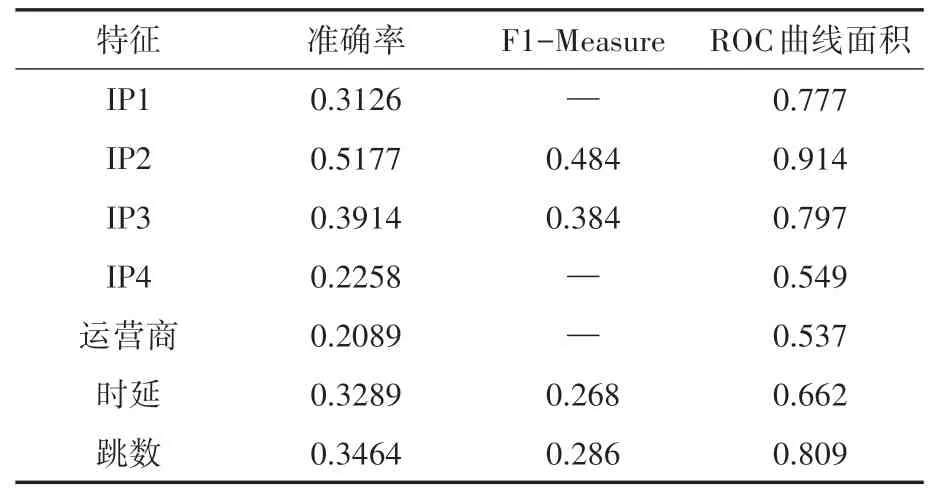
表2 單一特征分類評價指標對比
表2 中IP1、IP4和運營商三個特征的F1-Measure 為空,因為在僅使用這三個特征中的一個進行分類時,部分城市的分類結果完全錯誤,造成該城市所對應的F1-Measure 無法計算,從而導致該項特征總體分類情況的F1-Measure 無法計算得出。
由于單獨使用個別分類效果較差的特征時,分類的準確度無法真正反映分類的效果,以及部分分類結果全部錯誤導致部分F1-Measure 為空這兩點問題,表2可以簡單直觀反映各特征的重要性,但是無法直接給出各特征對于分類的貢獻度,而各特征的貢獻度在特征選擇部分至關重要,在R-RF算法的特征選擇部分更是需要根據貢獻度來對特征進行加權。在圖3給出計算得到的各特征對于分類的貢獻度,其數值大小與表2里各特征的準確率高低趨勢基本一致,同樣依次是IP2、IP3、跳數、時延、IP1、IP4、運營商。

圖3 各特征對分類貢獻度
3.2 IP定位結果
在均使用多特征IP 數據集進行分類的情況下,首先使用隨機森林算法對多特征IP 數據庫中河南省各城市進行IP 定位,所得到混淆矩陣如圖4所示。
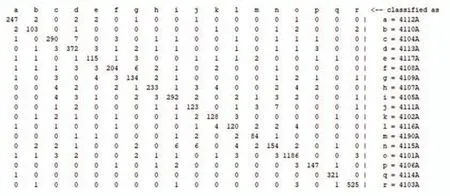
圖4 隨機森林算法分類所得混淆矩陣
再使用R-RF 算法對多特征IP 地址數據庫進行IP定位,得到的混淆矩陣如圖5。

圖5 R-RF算法分類所得混淆矩陣
明顯可以從圖4的混淆矩陣看出,隨機森林算法分類錯誤的樣本個數有一些是大于2個的,但是在R-RF算法的混淆矩陣中,分類錯誤的樣本個數都不超過2個。
使用隨機森林算法和改進的R-RF算法分別進行分類測試,得到準確率、精準率與召回率的調和平均數(F1-Measure)以及ROC 曲線面積這三項評價指標的結果如表3所示。
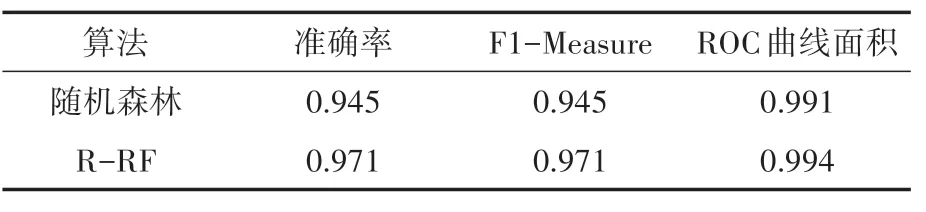
表3 兩種算法分類評價指標對比
將準確率、F1-Measure、ROC 曲線面積這三項常用指標的總體結果繪制成折線圖,如圖6所示。由折線圖可以直觀的看出在均使用多特征IP數據集進行分類的情況下,R-RF算法比原始隨機森林算法得到的分類準確率更高,分類性能更好,證明了改進算法的有效性。
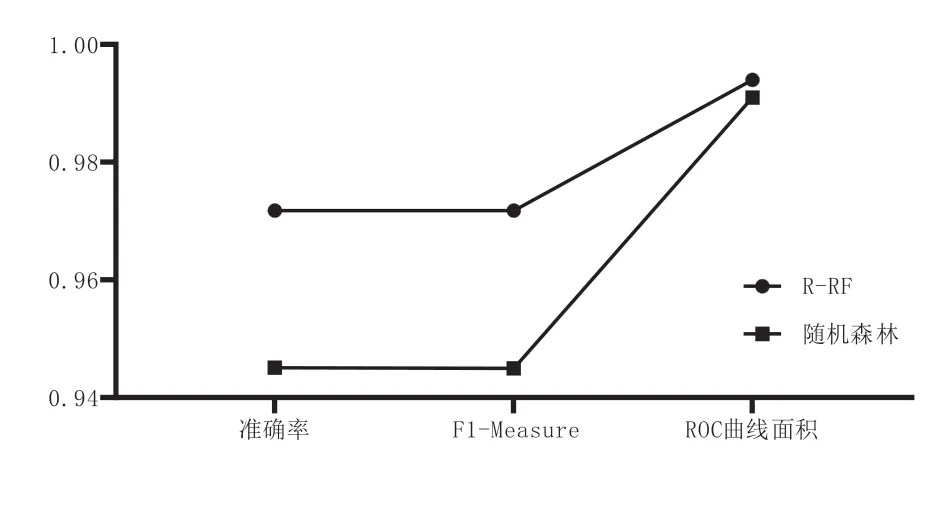
圖6 兩種算法分類評價指標對比
4 結語
本文結合網絡測量數據和IP 地址本身共同構建了多特征IP 地址數據庫,并根據網絡IP 地址數據不平衡和各特征重要性不一致會影響網絡IP 定位結果的特點,對特征權重算法Relief F做出改進,融入隨機森林分類算法的特征選擇步驟中,對原始隨機森林算法在IP 定位領域做出改進。實驗結果表明在均使用多特征IP 數據集進行分類的情況下,R-RF 算法比原始隨機森林算法得到的分類準確率更高,分類性能更好,證明了改進算法的有效性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
