一種基于區域權重平滑的弱監督目標定位方法
2022-05-13 03:16:26劉富,羅冰,裴崢
西華大學學報(自然科學版) 2022年3期
劉 富,羅 冰,裴 崢
(西華大學無線電管理技術研究中心,四川 成都 610039)
目標定位已被應用至監控、二維碼識別等領域,它要求生成準確圍繞目標的檢測框[1?2]。目標定位以目標檢測框作為監督信息,需要大量的訓練數據。隨著其應用領域的不斷拓展,在新場景下制作準確且大量的標簽便成為了一個棘手的問題,于是研究者探索弱監督下的解決辦法[3?4],即僅使用圖像類別標簽。Class activation maps(CAM)[4]在圖像分類網絡[5]中引入全局均值池化并取消部分全連接層,在網絡中間層得到與目標類別對應的激活區域,利用該區域,加以閾值篩選,完成目標定位。然而,CAM 所得的結果趨向于覆蓋目標的顯著性區域。這是因為在圖像分類任務中,目標的顯著性區域,如鳥的頭、人的軀干等,能夠提供強大的類別信息,這便導致網絡在分類預測時會過于依賴它們。在這樣的情況下,中間層特征往往僅在目標顯著性區域激活,以致無法得到準確的定位結果。
針對上述問題,一系列擦除式方法[6?7]被提出。Adversarial erasing(AE)[6]將所得激活區域在原圖像上進行擦除,在擦除后的圖像上進行分類訓練,迫使網絡關注目標的其他部位。Attentionbased dropout layer(ADL)[7]通過注意力機制探索顯著性區域并隨機地擦除它們,其訓練過程更為簡便。當顯著性區域被擦除后,網絡只能從目標其余部位獲取類別信息,其對這些部位的依賴程度越高,對應激活值也就越大,這樣便達到了平衡顯著性區域與其余部位的目的。不同于以往修正特征的方法,本文從損失函數上探索區域平衡策略。筆者發現,經卷積神經網絡所提取的視覺特征通常在不同通道表征不同的區域,并且目標激活區域由這些通道及它們對應的分類層權重決定,但是極少數的通道卻占據了較大的權重,而這些通道的視覺信息恰好對應顯著性區域,這便導致了定位區域響應的稀疏性。為使網絡在定位目標時充分考慮各個通道所攜帶的視覺信息,本文提出分類層權重的自適應標準差正則項(standard deviation regularization,SDR),通過控制正則項所涵蓋的權重范圍,分類層能夠在學習到相近權重的同時保留分類能力,這樣便能完成目標區域平滑。
1 相關工作
由于缺少檢測框標簽信息,弱監督目標定位無法如目標檢測那般直接進行回歸,更多的是采用由視覺特征生成檢測框這樣自下而上的方法。
1.1 弱監督目標定位
弱監督目標定位方法大多基于CAM[4]。CAM首先訓練圖像分類網絡,然后將所得分類層權重與對應視覺特征進行卷積,得到定位區域。然而,這樣的方法通常只能得到目標的顯著性區域。為了解決該問題,AE[6]利用所得顯著性區域對原圖像進行擦除,迫使網絡關注整個目標。Hide-and-seek(Has)[8]則采用了隨機擦除圖像塊的方式,簡便同時有效。在擦除后的圖像上提取信息會導致性能下降,于是,Adversarial complementary learning(Acol)[9]融合顯著性區域與擦除后結果,得到了更為整體的目標。上述方法需要先得到顯著性區域后,才能進行擦除,訓練步驟繁瑣。ADL[7]則直接利用注意力機制[10]提取顯著性區域,并隨機擦除視覺特征,能夠在減少訓練步驟的同時提升準確率。不同于上述擦除式的方法,Divergent activation(DANet)[11]從相似的物種間提取共性并引入空間位置差異,迫使網絡學習到更多視覺模式。然而,這些方法均從修正視覺特征的角度出發,并未關注到分類層權重對激活區域的影響。
1.2 目標檢測
目標檢測方法按回歸次數可分為:一階段檢測方法、二階段檢測方法。整體上,一階段方法僅進行單次回歸,處理速度快,但準確率不如后者。You only look once(YOLO)[12]將特征譜分為數個網格,并在網格上進行回歸。考慮到較小的目標在網絡的最高層可能丟失,Single shot multibox detector(SSD)[13]采用了多級檢測方法。Focal Loss[14]針對訓練樣例中正負例不均衡的問題,將focal loss用于平衡正負例損失。上述方法雖擁有較快的檢測速度,但對設備性能的要求仍然較高,無法應用于輕量化終端。文獻[15]使用MobileNetV2 替換YOLOv3 特征提取網絡,并提出針對紅外圖像的增強算法,能夠在提升檢測精度的同時大大減少模型參數量。在二階段檢測方法中,R-CNN[16]首先提取候選區域,然后進行回歸。在R-CNN 中,每個候選區域均會進行單獨的特征提取,速度較慢。FAST R-CNN[17]針對整幅對象僅提取一次特征,并直接利用候選區域選擇特征,能夠大大加快檢測速度。傳統算法由于無法使用GPU 加速處理,提取候選區域的速度較慢。Faster R-CNN[18]則提出直接由卷積網絡生成候選區域,速度更快。這類方法需要檢測框標簽,但標簽制作較為繁瑣。本文則考慮僅使用弱標簽,意在減輕標注工作量。
2 基于區域平滑的弱監督目標定位方法
現有方法較少關注分類層權重對目標區域的影響。本文通過引入分類層權重的自適應標準差正則項,迫使網絡學習到相近的權重,能夠在降低顯著性區域關注度的同時提升其余區域所占比重。網絡框架圖如圖1 所示。圖中GAP 表示全局均值池化,Conv 表示卷積操作。
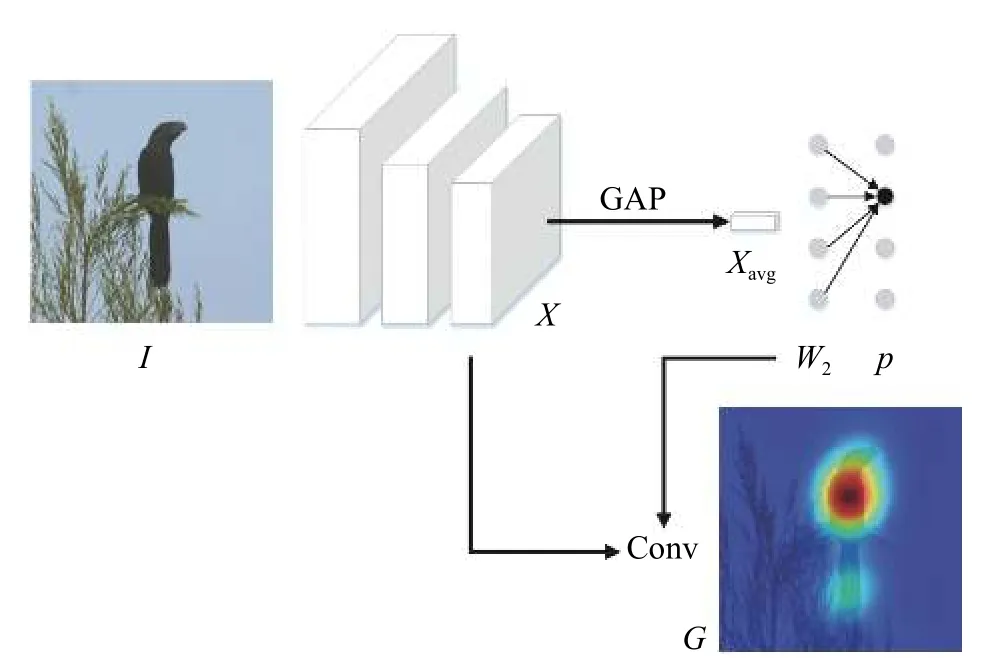
圖1 網絡框架圖
2.1 目標區域生成
目標區域生成需要首先訓練圖像分類網絡。對于一幅圖片I,利用卷積網絡提取其視覺特征X,X=f(I,W1),其中f、W1分別表示卷積網絡及其參數。X∈RK×H×W,K、H、W分別表示視覺特征的通道數、高和寬。然后池化視覺特征并進行類別預測,其損失函數可表示為:
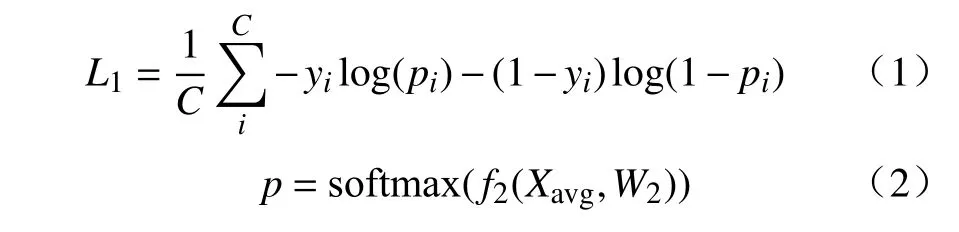
式中:yi表 示圖像類別標簽;pi表示圖片屬于類別i的 概率;C表示類別總數;Xavg∈RK,表示在特征譜X上進行全局均值池化的結果;f2、W2分別表示分類層及其權重,W2∈RC×K;softmax表示激活函數。W2表示了網絡對各個通道所攜帶類別信息的依賴程度,值越高,表明對應通道池化前的視覺區域越能提供強大的類別信息,利用這樣的對應關系便可得到目標區域。在具體實現上,使用W2在X上進行卷積,并進行歸一化后,得到目標區域Gn,為
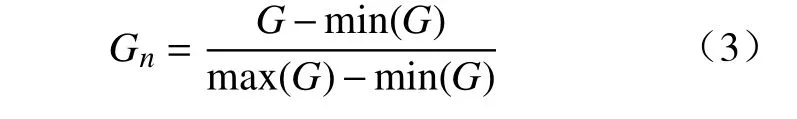
式中:G表 示卷積結果;min、max分別表示取最小值與最大值。此外,為剔除背景,需進行閾值篩選,其篩選結果為
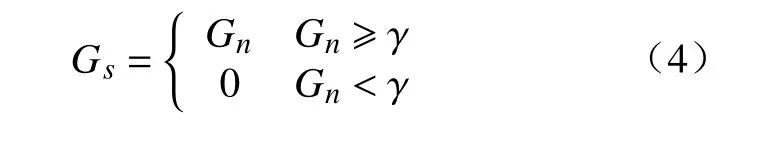
式中Gs表示目標區域經閾值 γ篩選后的結果。然而,這樣的方法趨向于覆蓋目標最具有顯著性類別信息的部位。為得到覆蓋目標全局的結果,本文提出了分類層權重的自適應標準差正則項。
2.2 自適應標準差正則項
分類層權重W2在 視覺特征X上的卷積可以拆分為乘積的和。記二者乘積的結果為M,則M∈RC×K×H×W。在M的通道維度求和,即可得到卷積結果G,G∈RC×H×W。該結果能夠表示圖像I中不同類別目標的激活區域。在M的空間維度求均值得到S,S∈RC×K。該結果能夠表示特定類別下各個通道在生成激活區域時所占的比重。然而,在通道重要性S中,極少數通道產生了較大的值,并支配了最終定位區域。如圖2 所示,S由大至小排序后,前3 個值遠遠大于其他,這表明激活區域易受少部分通道影響。它們對應通道的激活區域如圖3 中第1 行所示,均落在了鳥的頭頂位置。圖3 中第2 行則是那些較小的值所對應的區域,它們雖然能夠覆蓋目標的其余位置,如鳥頭、鳥嘴,但由于遠遠低于前3 個值,經閾值篩選后往往被視為背景。對激活區影響最大的3 個通道僅覆蓋鳥的頭部,而其他通道雖覆蓋更多部位,但由于權重過低,往往被視為背景,這導致了激活區域的不平滑。縮小通道重要性S之間的差距,便可保留更多目標區域。引入分類層權重W2的標準差正則項能驅使網絡學習到相近的權重,這樣便能平衡各個通道所占比重,但是,當所有權重相近時,網絡將無法進行類別判斷。因此,本文僅考慮對生成激活區域貢獻最大的前Q項。記S最大值與閾值 γ的乘積為通道閾值Ss,則大于Ss的項表征前景的可能性更高,那么將Q初步確定為S中大于Ss的項數便能將權重平滑控制在表征前景的通道上。在該情況下,引入的標準差正則項為

圖2 通道重要性S
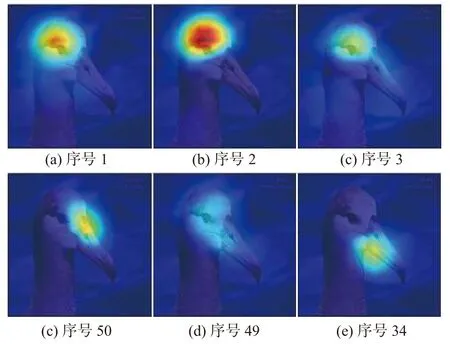
圖3 通道重要性S 中各序號對應激活區域


式中:λ表示超參數,用于控制正則項在損失中的比重。這樣便能迫使網絡在保持分類性能的同時學習到相近的權重。使用平衡后的權重在視覺特征上進行卷積便可得到更為整體的目標區域。與以往方法[4]相同,經閾值 γ篩選后,在所得區域上計算聯通圖便可得到檢測框。
3 實驗
本文在CUB200-2011[19]、OpenImages[20]數據集上進行實驗。CUB200-2011 共有11 778 張圖片,其中5 994 張圖片用于訓練,5 794 張圖片用于測試,共涵蓋200 個類別。在OpenImages 方面,有29 819 張圖片用于訓練,2 500 張圖片用于驗證,5 000 張圖片用于測試,共涵蓋100 個類別。與文獻[4]中方法相同,量化指標選擇TOP-1Loc、TOP-1Clas、MaxBoxAccV2[20](Max)、PxAP[20]。TOP-1Loc 表示預測檢測框與真實檢測框交并比超過50%且類別預測正確的圖片比例。TOP-1Clas 表示圖片分類預測的正確率。與TOP-1Loc 不同,Max 不考慮類別預測是否正確,并且在生成檢測框時,Max 選擇多個閾值篩選,并保留全體測試數據在不同閾值下效果最佳的一項。相較于TOP-1Loc,Max 更側重體現與類別無關且最適合當前方法閾值的定位性能。PxAP 同樣不考慮類別預測結果,但其測試數據不再是檢測框,而是像素級的目標區域,其目的是探索不同方法間的細節差異。這4 個指標均是值越大,效果越好。
3.1 實驗細節
本文選擇Has[8]作為實驗基準。為排除不相關因素的干擾,引入自適應標準差正則項(SDR)后,除新增的超參數Q、λ以外,其余結構及參數均保持一致。具體地,網絡結構選擇經ImageNet 預訓練的VGG 分類網絡。在訓練階段,網絡執行分類任務并迭代50 次。參數設置方面,本文使用SGD Optimizer,并設置初始學習率為0.00016,沖量為0.9,權重衰減為0.0005。此外,網絡每迭代15 次學習率降低90%。超參數設置方面,Q取 70,λ取0.5。在測試時,選擇類別預測P最大的一項作為分類結果。之后以該項對應卷積核權重在全局池化前一層視覺特征上進行卷積,便可得到激活區域。檢測框生成選擇與CAM[4]相同的方法。
3.2 實驗結果及分析
本文在CUB200-2011[19]、OpenImages[20]數據集上與近幾年主流方法CAM[4]、CutMix[21]、Has[8]等進行了對比。網絡結構方面,CAM、Has 及本文所提方法(SDR)均使用16 層的VGG 網絡(VGG16),而CutMix、ACol 則是選擇使用卷積層替換掉VGG 網絡尾部的最大池化層(VGG16-L)用以獲取更高分辨率的激活區域。這樣的替換操作并非總是有效,因此后續的方法,如Has 并未采用該策略。此外,上述方法均使用了ImageNet 預訓練權重。訓練時,上述所有方法的輸入圖像大小調整為224×224,并將batchsize 設置為32。網絡共迭代50 次,并且每迭代15 次,學習率降低90%。測試時,由于閾值 γ對TOP-1Loc 影響較大,各方法設定了不同值,如表1 所示,“*”表示本文實驗所得結果。對于其他指標,各方法采用完全一致的參數設置。

表1 各方法在Top-1Loc 指標下閾值 γ的設定
CUB200-2011 上的實驗結果如表2 所示,“*”表示本文實驗所得結果,SDR 表示本文所提方法實驗結果。在Top-1Loc 指標下,CutMix[21]相對于基準CAM[4]產生了較大提升,這是因為它在一幅圖像中隨機裁剪圖像塊對目標圖像進行替換,以擾亂網絡對目標圖像關鍵區域的關注度,進而生成更為均勻的激活區域。Has[8]則是隨機擦除圖像中的多個塊,在該情況下,網絡為提取類別信息將更多地關注目標各個部位,因此其所得激活區域更為平滑,定位準確率也更高。CutMix 與Has 分別通過替換、擦除隱式地降低網絡對目標顯著性區域的關注度,而本文則是在擦除的基礎上通過正則項顯式地降低顯著性區域關注度,因而獲得了更好的定位性能。在Max 指標下,SDR 定位精度產生了較為明顯地提升,這是因為對區域的平滑造成了區域最大值的下降,而表征背景像素的值并未產生相應變化,此時使用固定的背景篩選閾值 γ將導致更多像素被視為前景。因此,對于固定 γ的TOP-1Loc指標,Max 提升更為明顯。

表2 CUB 數據集下的實驗結果
考慮到背景像素篩選閾值 γ對Top-1Loc 指標影響較大,圖4 示出了各個閾值下的定位精度。可以看出,定位精度隨閾值增加呈現出先增大后減小的變化趨勢。這是因為,當 γ較小時,過多的背景像素被視為前景,導致定位性能較差,而隨著γ 逐漸增加,背景像素得以正確識別,因此定位性能不斷上升;當 γ達到最佳值后,若繼續增加,將導致本應是前景的區域被視為背景,因而定位精度產生了退化。SDR、Has 的最佳精度為58.81%、58.21%,分別在 γ取0.12、0.13 時得到,表明在平衡通道重要性后應當選取較低的γ。
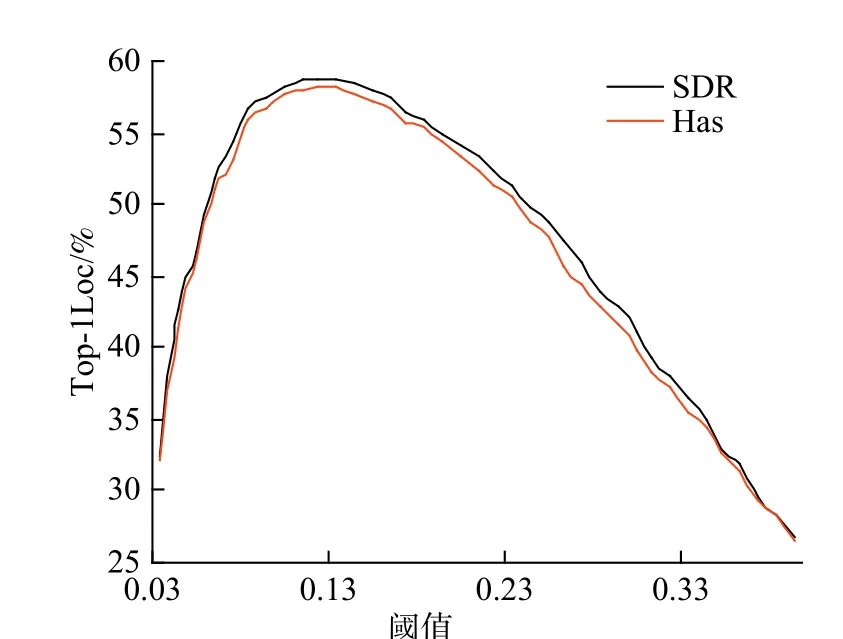
圖4 CUB 數據集不同閾值γ 下定位精度
OpenImages 實驗結果如表3 所示,其中SDRCAM 表示將本文所提標準差正則項引入CAM。在該指標下,SDR 較Has 提升了0.6%、SDR-CAM較CAM 提升了0.69%,表明本文所提方法在各個閾值下的綜合結果更為準確。

表3 OpenImages 數據集下的實驗結果
CUB200-2011 數據集下主觀結果如圖5 所示,每一幅子圖中:第1 行表示激活區域,色彩深淺對應激活值大小,色彩越深表明該處存在目標的可能性越大;第2 行表示定位結果,其中綠色邊界框表示測試標簽,紅色檢測框表示預測結果,二者重合度越高表示定位效果越好。通過比較圖5(a)、5(b)、5(c)能夠發現:CAM 無法在鳥的頭部激活,其對應檢測框覆蓋范圍最小;Has 由于頭部激活值較低,被視為了背景;本文所提方法(SDR)通過平衡通道權重縮小不同區域激活值之間的差異,在鳥頭部分得到了較大值,所生成的檢測框也更緊湊。
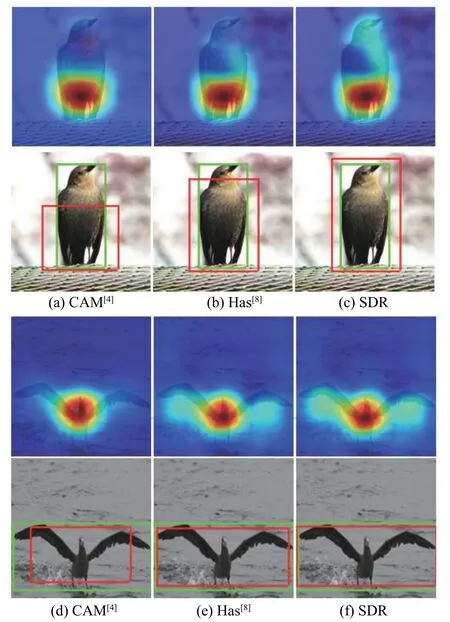
圖5 CUB200-2011 數據集下各算法激活區域及定位結果
檢測框由激活區域各方位頂點生成,雖能定位目標卻無法精確評估激活區域。為了細致地探究各方法間的差異,OpenImages 提供了像素級的目標區域作為測試數據,該數據集下的測試結果如圖6 所示。圖像由左至右分別表示輸入、Has 預測結果、SDR 預測結果、標簽。從圖中可以看出:Has 對目標中遠離顯著性類別信息的部位響應效果較差,如第1 行中熱氣球的左上角及第2 行中左側的鞋子;本方法由于降低了對顯著性區域的關注度,能夠更多地從目標其余部位提取類別信息,因而所得響應區域更為準確。

圖6 OpenImages 數據集下的定位區域
本方法中超參數Q、λ對預測結果具有顯著的影響。表4 給出了固定正則項權重 λ=0.9,調整最大通道數Q時的實驗結果。Q越大表示用于平衡的權重越多。當Q過高時,會導致不具有類別信息的通道產生較大的值,而原本具有類別信息的通道所對應權重反而會降低,從而造成性能下降。表5 示出固定Q=50,調整 λ 的實驗結果。λ用于平衡分類損失與正則項。由于弱監督目標定位依賴分類網絡所得的具有類別信息的視覺特征,需設置較小的λ。本文發現當Q=70且 λ=0.5時,效果最好。

表4 Q 對實驗的影響

表5 λ 對實驗的影響
4 結論
針對弱監督定位中激活區域趨向于覆蓋目標局部的問題,本文提出了一種基于區域權重平滑的目標定位方法,使網絡能夠關注到視覺特征中不同通道所表征的區域信息,從而得到更為緊湊的目標檢測框。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
電測與儀表(2015年5期)2015-04-09 11:30:52
