基于復雜結構信息的圖神經網絡序列推薦算法
2022-05-14 03:28:04胡承佐王慶梅李迪超
計算機工程 2022年5期
胡承佐,王慶梅,李迪超,王 錚
(1.北京科技大學國家材料服役安全科學中心,北京 100083;2.南方海洋科學與工程廣東省實驗室,廣東珠海 519080;3.澳門大學 計算機與信息科學系,澳門 999078;4.北京科技大學 計算機與通信工程學院,北京 100083)
0 概述
推薦系統是數據挖掘和機器學習領域最重要的應用之一,它能夠幫助平臺用戶緩解信息過載的問題,并在電商平臺、音樂網站等許多網頁應用中挑選出有價值的信息。在大部分推薦系統中用戶的行為序列是按照時間排列的,并且呈現出匿名性和大數據量的特征。為了預測用戶在下一時刻的行為信息,基于會話序列的推薦通過挖掘用戶歷史行為中的序列順序特征信息,從而學習用戶的喜好[1]。會話序列是指在一段時間間隔內的由用戶點擊而產生的項目序列,而基于會話序列的推薦能捕捉到序列內部的依賴關系對序列預測的重要性[2]。用戶在某一個會話序列中通常有著一個共同的目的,如購買下裝衣物;而用戶在不同序列之間的行為特性可能關聯性不大,如在別的會話中用戶的目的是購買手機配件等。
鑒于其較高的實際價值,基于會話序列的推薦在近年來得到了研究人員很大的關注,并且出現了許多具有良好效果的研究成果。早期的算法主要基于馬爾科夫鏈和循環神經網絡(Recurrent Neural Networks,RNN)。隨著近期圖神經網絡(Graph Neural Networks,GNN)的興起并且在許多下游任務中有著較好的表現[3-4],有研究人員將GNN 應用到了基于會話序列推薦中[5-6]。盡管這些基于GNN 的算法有著較好的表現,但是這些算法也存在以下問題:忽略了點擊序列中重復出現的項目,多次出現的項目與其他項目的重要程度是不同的,這些項目在一定程度上能夠體現用戶偏好信息;在生成項目的向量表示時沒有較好地利用會話序列圖中的結構信息,只考慮項目之間的方向性還有所欠缺,引入項目之間的無向關系能夠更好地學習用戶的行為信息。
為解決以上問題,本文提出一種基于復雜結構信息的圖神經網絡序列推薦算法。利用帶注意力的圖卷積網絡和門控圖神經網絡,分別提取序列圖中項目之間的無向結構信息與有向結構信息,并引入注意力機制建模項目之間的復雜轉換,從而得到項目隱含向量,根據隱含向量利用注意力網絡結合會話的全局信息與局部信息,生成準確的會話向量表示。
1 相關工作
1.1 傳統推薦算法
早期的基于鄰域建模算法在用戶不匿名的推薦場景中使用最鄰近算法進行會話序列預測[7-9],需要測量項目之間或者會話之間的相似度。DAVIDSΟN 等[7]提出一種通過項目共同出現的模式來計算項目之間相似度的算法,并根據待預測會話序列中的項目推薦最有可能跟其共同出現的項目。PARK 等[9]提出一種將會話序列轉換成向量的算法,然后計算會話向量之間的余弦相似度。DIAS 等[8]基于PARK 的研究提出用聚類算法將稀疏會話向量轉換為稠密向量,然后再計算稠密向量之間的余弦相似度,但它受到數據稀疏性的影響,且沒有考慮到會話向量內部項目之間的復雜轉換關系。
而基于馬爾科夫鏈的算法可以更好地獲得序列中順序信息。最簡單的基于馬爾科夫鏈的算法利用訓練集中項目的轉換頻率來計算得到轉換矩陣[10],但不能應對那些在訓練集中沒出現過的轉換關系。FPMC 算法[11]通過一種張量分解的算法將轉換矩陣進行分解,從而解決了該問題。另外一種解決算法是馬爾科夫隱嵌入[12],首先把項目映射到歐式空間中,然后通過計算項目之間的歐式距離從而估算項目之間的轉換概率。因為狀態空間存在著數據爆炸的問題,基于馬爾科夫鏈的算法多數都只考慮了用戶點擊序列對連續項目之間的單向轉換,導致會話中的其他項目被忽略。
1.2 基于深度學習的算法
循環神經網絡(RNN)對會話序列有著強大的建模能力,能很好地解決基于馬爾科夫鏈算法的不足。GRU4Rec[13]是一個基于RNN 的會話序列推薦算法,它的原理是將多個GRU 層堆疊在一起。受計算機視覺和自然語言處理領域中非常流行的注意力機制啟發,LI 等[14]采用帶注意力的混合編碼算法對用戶的序列行為和目標進行建模,并且實驗證明了學習到的序列表現結果十分有效。因此,后續基于RNN的工作都融入了注意力的機制[15-17]。
近幾年圖神經網絡在許多任務中都有著較好的表現[18],也有一些研究人員將圖神經網絡引入到基于會話序列的推薦中。SR-GNN[4]將會話序列建模為不帶權重的有向會話圖,圖中的邊代表項目之間的轉換關系,然后利用門控圖神經網絡(Gated Graph Neural Networks,GGNN)在有邊相連的節點間進行信息的傳 播。XU 等[6]在SR-GNN 的基礎上利用GGNN 來提取局部信息,并且用自注意力網絡來捕獲遠距離項目之間的全局依賴關系。上述算法證明,對于基于會話序列的推薦,GNN 是一個值得研究的方向。
本文的主要貢獻如下:
1)利用會話序列建立會話圖。根據會話圖的鄰接關系,利用圖卷積網絡提取圖中的無向結構信息,通過門控圖神經網絡提取圖中的有向結構信息,最后對中間項目隱含向量通過線性變換得到最終的項目隱含向量。
2)在提取會話圖中的結構信息時,給會話序列中出現的重復點擊項目分配更高的注意力,并在生成項目隱含向量時引入注意力機制,根據項目間依賴的程度修改相應項目的權重系數。
3)進行大量的實驗并在3 個公開數據集上證明了該算法比現有的算法表現更優。
2 算法描述與模型框架
2.1 公式化描述
基于會話序列的推薦旨在根據用戶當前的會話序列數據給出用戶下個時刻點擊項目的預測,而在該過程中完全不依賴用戶的長期偏好信息。
在基于會話序列的推薦中,令V=代表所有會話序列中出現過的m個項目的集合。那么一條長度為n的匿名會話序列能夠用列表s=來表示,且會話s中的項目是按時間先后順序排列的,每個νi∈V代表了用戶在會話s中點擊的項目。基于會話序列的推薦就是要預測用戶的下一個點擊,即會話s中的序列標簽νn+1。利用基于會話序列的推薦模型,對每個會話s都可以得到所有可能項目的概率其中概 率向 量中包括了出現在當前會話后下一個點擊項目的所有可能情況,且每個元素的值都代表了對應項目的推薦得分中排名最高的前K個的項目即為將要推薦的候選項目。
2.2 總體框架
對基于會話序列的推薦,首先從歷史會話序列的信息中構建有向會話序列圖。GCN 和GNN 分別能提取會話圖中項目轉換的無向結構信息和有向結構信息,并相應地生成精確的項目隱含向量。而后將得到的項目隱含向量輸入到注意力網絡中,同時考慮會話的全局信息與局部信息,從而構造出更可靠的會話表示,并以此推斷下一次的點擊項目。
模型的整體框架如圖1 所示。首先將每個會話序列s轉換為有向會話序列圖Gs=(Vs,εs,As),其中:Vs代表點集;εs代表邊集;As代表鄰接矩陣的集合。在會話圖Gs中每個節點都代表一個項目νi∈V,而且每條邊(νi-1,νi)∈εs都代表了用戶先后點擊了項目νi-1和項目νi。將As定義為3 個鄰接矩陣和的拼接,其中表示無向圖的帶權重鄰接矩陣分別表示帶權重的入度鄰接矩陣和出度鄰接矩陣。然后依次對每個會話圖Gs進行處理,根據會話圖Gs生成每個項目νi∈s對應的初始項目隱含向量xi,依次通過帶無向注意力網絡的圖卷積網絡、帶有向注意力網絡的門控圖神經網絡,分別得到每個圖中涉及的所有節點的中間隱含向量,再通過一個線性層得到精確的最終的項目隱含向量,將得到的項目隱含向量輸入目標注意力網絡,從而得到每條會話序列所對應的會話隱含向量。最后通過線性變換和一個softmax 層對每個會話預測所有可能項目被點擊的概率。

圖1 本文模型總體框架Fig.1 Overall framework of the proposed method
2.3 項目隱含向量
在建立好會話圖Gs之后,首先將每個節點νi∈V映射到隨機嵌入向量空間中得到d維向量表示xi∈Rd,再通過對應的神經網絡模型和線性層得到hi∈Rd。圖神經網絡對基于會話序列的推薦有天然的適應性,因為它可以在考慮到豐富的節點連接關系的前提下自動提取會話圖的特征。下面將介紹生成最終節點向量過程中使用的兩個網絡模型。
2.3.1 帶注意力的無向結構信息
本文采用文獻[19]算法構建圖卷積網絡(GCN)。會話圖Gs中的帶權重無向鄰接矩陣是一個稀疏且對稱的鄰接矩陣,其中,aij代表了節點νi和νj之間的邊權重,節點間無相連關系則表示為aij=0。將度矩陣D定義為對角矩陣D=diag(d1,d2,…,dn),且對角線上的值等于鄰接矩陣的行元素之和di=圖中的每個節點νi都有對應的d維特征向量xi∈Rd,所以總的特征矩陣X∈Rn×d就是圖中每個特征向量的堆疊,即X=[x1,x2,…,xn]T。
與卷積神經網絡(CNN)和多層感知機(MLP)類似,GCN 在多層結構中對于每個節點的特征νi進行學習并得到新的特征表示,然后再輸入對應的線性分類器。對于第k層的圖卷積層,矩陣H(k-1)表示所有節點的輸入向量,H(k)表示節點的輸出向量。最初的d維節點向量即初始輸入的特征,并輸入到首層GCN 中:

層數為K的GCN 相當于對圖中所有節點的特征向量xi應用一個K層的MLP 模型,每個節點的隱含向量表示在每層的一開始都和其鄰居節點進行均值化。在每個圖卷積層中,節點的向量表示有3 個更新階段:特征傳播,線性轉換和逐點非線性激活。本文用于學習項目隱含向量所到的只有特征傳播階段。
特征傳播是GCN 和MLP 之間的本質區別。在每層的最開始,每個節點νi的特征都與它的局部鄰居的特征向量進行均值化:
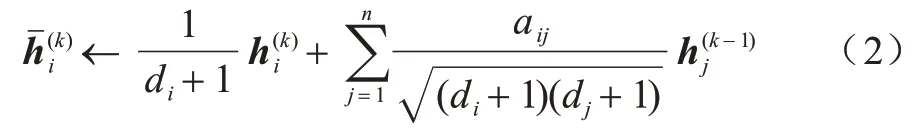
上述的更新公式可以用整個圖的簡單矩陣操作來簡化。S代表“對稱歸一化”后帶自環的鄰接矩陣:

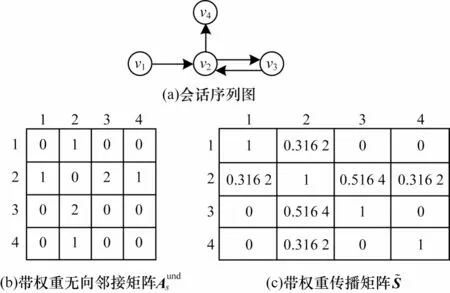
圖2 會話序列圖與其對應的帶權重無向鄰接矩陣和帶權重傳播矩陣Fig.2 Session sequence graph and its corresponding weighted undirected adjacency matrixand weighted propagation matrix
因此,式(2)的等價更新形式就可以變成一個對于所有節點的簡單稀疏矩陣相乘:

上述步驟沿著圖上邊對節點的隱含向量表示進行局部平滑,將GCN 作為特征預處理算法對特征進行傳播后,使得節點能夠吸收相鄰節點的帶注意力信息,并最終使得局部相連的節點能夠有相似的預測表現[20]。
2.3.2 帶注意力的有向結構信息
本文根據文獻[21]構建模型GGNN。對于會話圖Gs中的節點νi,節點向量的更新公式如下:

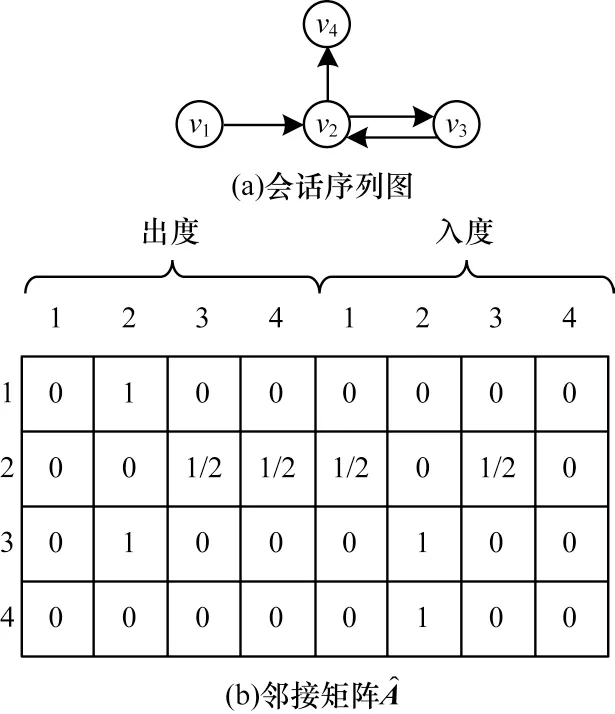
圖3 會話序列圖與其對應的鄰接矩陣Fig.3 Session sequence graph and its corresponding adjacency matrix
所以,對于每個會話圖Gs,GGNN 模型在相鄰節點之間傳播帶注意力的節點信息,而重置門控和更新門控分別決定需要進行舍棄或者保留的信息。
2.3.3 項目隱含向量的生成
在經過圖卷積網絡(GCN)和門控圖神經網絡(GGNN)的信息處理后,分別得到前者是對初始嵌入向量進行了帶注意力的無向結構信息處理;后者在前者的基礎上更加精細地提取圖結構中帶注意力的有向結構信息。
為了平衡帶注意力的無向結構信息與有向結構信息的比例,采用式(11)進行控制:

其中:γ為超參數。
2.4 會話向量表示的生成
2.4.1 基于目標注意力的向量
在得到每個項目的向量表示后,進一步構建目標向量,從而能在考慮到目標項目的前提下對歷史行為的相關性進行分析,目標項目是指所有待預測的候選項目。因為在實際應用場景中,用戶得到的推薦項目只匹配其一小部分的興趣,所以利用文獻[22]提出的目標注意力模型來計算目標會話中所有項目對目標項目的注意力得分。
本文利用局部目標注意力模型來計算會話s中所有項目νi對每個目標項目νt∈V的注意力得分βi,t:
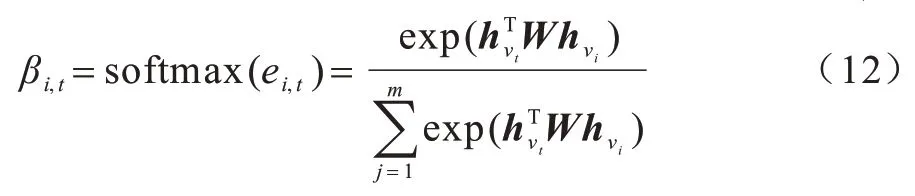
在式(12)中,會話中的項目與候選目標分別匹配,并且用帶權重矩陣W∈Rd×d來進行成對的非線性轉換。然后再用softmax 函數對得到的自注意力分數進行歸一化,并得到最后的注意力分數。
對于每個會話序列s,用戶對目標項目νt的興趣可以表示為:

2.4.2 會話向量的生成
本文利用會話s中涉及到的項目向量進一步地探索用戶的短期和長期喜好,從而得到會話中的局部向量與全局向量,并綜合2.4.1 節中計算得出的基于目標注意力的向量生成最終的會話向量。
首先是局部向量,在一個會話序列s中,用戶最終的行為通常是由當前序列中最后一個交互的項目決定的。所以,將用戶的短期興趣表現為局部向量slocal∈Rd,且該局部向量即為會話序列中最后一個項目的向量表示。

對于全局向量,將用戶的長期偏好定義為全局向量sglobal∈Rd,其聚合了會話s中所有出現的項目向量。同時,利用注意力機制來引入最后交互的項目與整個 會話中 出現的項目[ν1,ν2,…,νn]之間的 依賴關系。
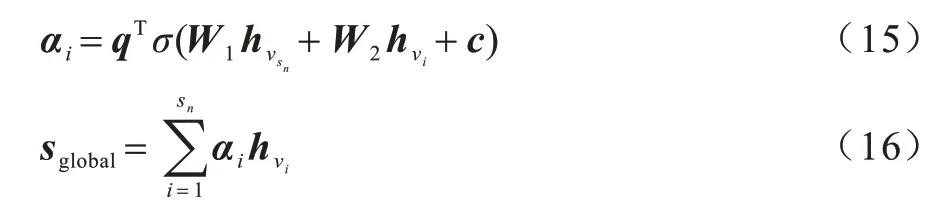
其中:q,c∈Rd且W1,W2∈Rd×d是相應的權重參數。
最后對于前面得到局部向量、全局向量和基于目標注意力的向量,將三者進行拼接并利用線性轉換得到會話序列s所對應的會話向量。
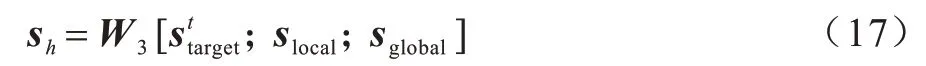
其中:權重參數W3∈Rd×3d,將3 個向量拼接的結果投射到向量空間Rd中。值得注意的是,對不同的目標項目會對應地生成不同的會話向量。
2.5 推薦生成

對于每個會話圖Gs,將損失函數定義為預測值與實際值的交叉熵:

其中:y代表會話序列下一時刻真實點擊項目的獨熱編碼向量。
最后使用基于時間的反向傳播(BPTT)算法來訓練提出的模型。值得注意的是,在基于會話序列的推薦場景中,多數會話都是相對較短的序列。為了防止過擬合的出現,采用較小的訓練次數是比較適宜的。
3 實驗結果與分析
本節介紹使用的數據集、數據預處理策略和評價指標,將提出算法與其他算法進行比較,最后在不同的實驗設置下給出模型的詳細分析。
3.1 數據集和數據預處理
本文選擇在實際應用中兩個有代表性的數據集來評估所提出算法,數據集分別是RecSys Challenge 2015發布的公開數據集Yoochoose 和CIKM Cup 2016 發布的公開數據集Diginetica。Yoochoose 數據集包含了電子購物平臺上6 個月內的用戶點擊流,而Diginetica 數據集中只包含了交易成功的數據,即用戶的購買流。
為了公平比較,本文遵循文獻[14,23]的預處理算法,在兩個數據集中將長度為1 的會話序列和總出現次數小于5 次的項目濾去,同時遵循文獻[1]的預處理算法,將長度大于20 的會話序列濾去。因為一個會話序列如果長度過長,那么用戶的主要目的在項目轉換間很有可能已經發生了改變,后續的推薦如果基于若干目的中的一個進行推薦,則很難達到精準預測的效果。經過上述處理,最終在Yoochoose 數據集中得到了7 897 532 條會話和37 470 個項目,在Diginetica 數據集中得到了185 517 條會話和43 093 個項目。對于訓練集和測試集的劃分,在Yoochoose 數據集中選擇最后一天的數據作為測試集,在Diginetica 數據集中則選擇最后一個星期的數據進行測試,剩余的數據則作為訓練集輸入模型。由于Yoochoose 訓練集規模過于龐大,遵循文獻[14,23]的做法,將Yoochoose 訓練數據中距離測試集時間最近的1/64 和1/4 部分的數據劃分出來作為訓練數據。
和文獻[24]的策略相同,本文進一步通過切分輸入序列數據來生成對應的序列和標簽。對于輸入會話序列s=[ν1,ν2,…,νn],作為一種數據增強策略,生成一系列的 序列和標簽([ν1],ν2),([ν1,ν2],ν3),…,([ν1,ν2,…,νn-1],νn),其中[ν1,ν2,…,νn-1]是生成的序列,而νn代表了下一時刻點擊的項目,即序列的標簽。
數據集具體情況如表1 所示。
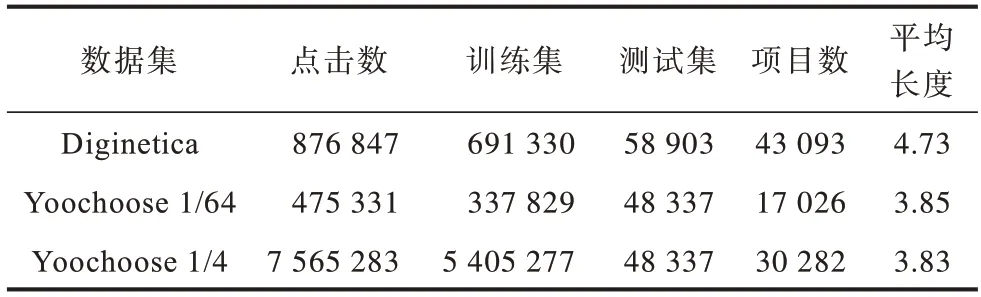
表1 實驗數據集統計結果Table 1 Statistical results of experimental datasets
3.2 評價指標
本文采用在基于會話序列的推薦中常用的兩個度量標準作為算法的評價指標:
1)P@20(Precision)。是一種被廣泛使用的預測精度的度量標準,它代表了算法推薦結果的前20 項中正確推薦的比例。
2)MRR@20(Mean Reciprocal Rank)。是算法推薦結果中正確推薦項目的倒數排名均值。當真實結果在算法的推薦排位中超過20 時,對應的倒數排名為0,MMR 度量標準是一種考慮了推薦順位的算法,較大的MRR 值代表了在推薦列表中真實結果位于排名列表的頂部,這也證明了推薦系統的有效性。
3.3 參數設置
根據文獻[4,14,22-23],本文在兩個數據集中均將隱含向量的維度設置為d=100。所有超參設置都利用均值為0、標準差為0.1 的高斯分布函數進行初始化。同時還采用小批量Adam 優化器對這些參數進行優化,并且將初始的學習率η設置為0.001,且每3 個訓練周期衰減0.1。此外,批處理大小設置為100,L2 正則化參數設置為10-5。
3.4 與相關算法的比較
為了評估所提算法的性能,將其與會話序列推薦問題的現有算法中有代表性的算法進行比較,即PΟP、S-PΟP、Item-KNN、BPR-MF、FPMC、GRU4Rec、RepeatNet、NARM、STAMP、SR-GNN、TAGNN。
1)PΟP 和S-PΟP 算法的策略是分別在訓練集和當前會話序列中推薦前K個出現頻率最高的項目。
2)Item-KNN[25]推薦與當前會話序列項目相似的項目,其中相似度定義為會話向量之間的余弦相似度。
3)BPR-MF[26]是一種基于貝葉斯后驗優化的個性化排序算法,它通過隨機梯度下降優化成對項目排序的目標函數。
4)FPMC[11]是一種基于馬爾科夫鏈的序列推薦算法。
5)GRU4Rec[13]使用循環神經網絡來對用戶序列進行建模。
6)RepeatNet[16]在重復消費的場景下將常規神經推薦算法與新的重復推薦機制集成在一起。
7)NARM[14]使用帶有注意力機制的循環神經網絡來捕捉用戶的主要意圖和序列行為特征。
8)STAMP[23]利用自注意力機制捕捉用戶在當前會話序列中的大致意圖和最后一次點擊行為的興趣點所在。
9)SR-GNN[4]通過使用門控圖神經網絡來捕捉項目轉換之間的關系。
10)TAGNN[20]在使用圖神經網絡模型的基礎上利用注意力網絡捕捉會話序列中的項目與目標項目的相似程度。
各算法在P@20 和MRR@20 這2 個指標上的性能表現如表2 所示,其中加粗數字為最佳結果。本文提出算法能夠靈活地在會話圖上構建項目之間的聯系,并且提取其中帶注意力的有向結構信息和無向結構信息,使得后續目標注意力的學習能夠更加準確,并且綜合用戶在會話中的全局興趣和局部興趣給出最后的推薦。由表2 中的實驗數據可以看出,本文算法在3 個數據集上的2 個指標上都獲得了最好的表現結果,這也證明了所提算法的有效性。
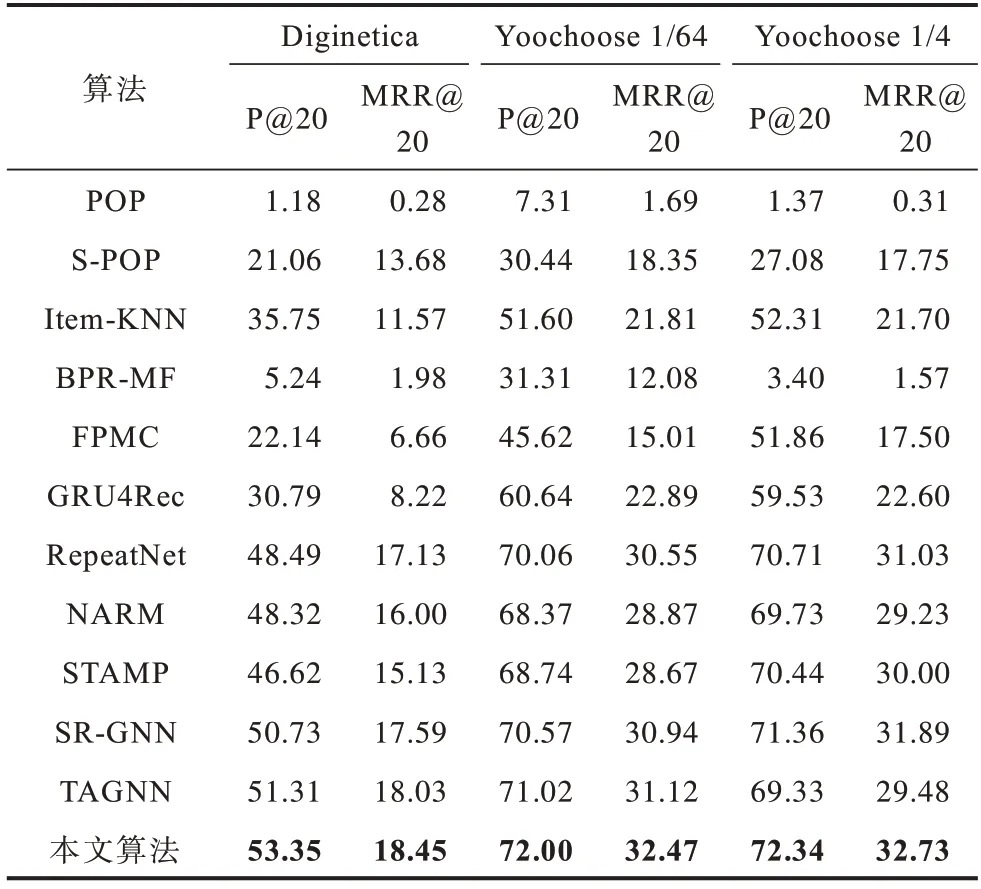
表2 不同算法實驗結果對比Table 2 Comparison of experimental results of different algorithms
從表2 可以看出:傳統推薦算法如PΟP 和S-PΟP在基于會話序列的問題上表現不盡如人意,因為其忽略了用戶在當前會話中的偏好,僅考慮了前K個最受歡迎的項目。BPR-MF 說明利用會話中的語義信息具有一定意義,而表現更好的FPMC 則說明利用一階馬爾科夫鏈來建模會話序列是相對有效的算法。同樣作為傳統推薦算法,Item-KNN 比前兩者更優。值得注意的是,Item-KNN 僅依賴計算物品之間的相似度,這說明了物品的同時出現也是一種比較重要的信息。而Item-KNN 沒有考慮到會話中的時序信息,不能捕獲到物品之間轉換的信息。
與傳統算法不同,基于深度學習的算法在所有數據集上的結果都有更好的表現。GRU4Rec 是一種基于循環神經網絡的算法,它的表現結果優于大部分傳統算法,與一部分傳統算法達到相近的程度。這說明了循環神經網絡對于序列數據有著一定的建模能力。然而GRU4Rec 主要聚焦在對會話序列進行建模,無法捕獲會話中的用戶偏好,其后出現的算法如NARM 和STAMP 都對GRU4Rec 有著顯著的提升。NARM 顯式地捕獲用戶在會話中的主要偏好,而STAMP 利用注意力機制考慮用戶的短期興趣,也優于GRU4Rec。RepeatNet 通過考慮用戶的重復點擊行為達到了較好的預測效果,這說明對用戶的行為習慣進行建模具有一定的重要性。RepeatNet相比NARM 與STAMP 提升有限,可能是因為僅通過項目特征來對用戶的重復點擊習慣進行建模是不充分的,且基于RNN 的結構無法捕獲會話內的一些共同的依賴關系。
基于圖神經網絡的算法將每個會話序列都構建成一張子圖,并且通過圖神經網絡對會話中的所有項目進行編碼。SR-GNN 和TAGNN 比所有基于RNN 的模型有著更好的結果。SR-GNN 利用門控圖神經網絡來學習會話序列內項目之間的依賴關系,TAGNN 進一步利用注意力機制挖掘會話內的項目與目標項目之間的依賴關系。然而,這些算法都完全根據會話圖的有向關系進行學習,而沒有綜合考慮會話圖中的無向關系,因為會話序列中物品和物品之間的關系有時往往不是單向的關系而是雙向的,利用無向的結構信息能夠捕獲到物品之間更加全面的關系,且它們都忽視了會話序列中出現的重復點擊特征,從直覺上來講一個序列中重復出現項目的重要性應當是更大的。此外,在實際推薦場景中項目和項目之間的關聯程度是多變的,而這些算法對于會話內項目和項目之間的依賴關系采用的是平均化算法,不能通過權重或者注意力的算法體現出某一項目對其他項目的依賴程度。
本文提出算法相比其他算法表現都要更優。具體而言,在3 個數據集上,對于P@20,相對表現最佳的相關算法有3.55%、1.38%、1.37%的相對提升,對于MRR@20,對表現最佳的相關算法有1.92%、4.34%、2.63%的相對提升。本文算法能夠很好地提取會話圖中的結構信息,先后利用圖卷積網絡和門控圖神經網絡對圖中的無向結構信息和有向結構信息進行提取,并將兩者進行線性組合從而達到向量的精準表示。考慮到會話序列中的重復點擊項目,通過注意力網絡提高重復信息的權重,同時通過增加自環和矩陣操作提高會話圖中節點的自我信息比例,使得節點不容易受到其他節點的噪聲干擾。根據項目與項目之間不同的依賴關系,利用注意力網絡分配不同的權重,從而使得網絡能夠生成精確的向量表示。
3.5 消融實驗
本文提出的算法能夠靈活地捕捉會話圖中的結構信息和項目之間的關系。為了驗證模型中各組成成分的實際作用,設置了幾種模型變體進行消融實驗。在實驗環節中選擇SR-GNN[4]作為對比的基準算法,實驗中的數據以對比SR-GNN 的相對提升百分比的形式展示。
本文進行以下有向結構信息和無向結構信息的組合分析:1)GCN,只提取會話圖中的無向結構信息;2)GNN,只提取會話圖中的有向結構信息;3)GCN+GNN,將隨機初始向量同時輸入到兩個神經網絡中,然后把模型輸出結果進行線性組合;4)GCN+GNN(GCN),首先將隨機初始向量輸入到GCN 中,然后把GCN 模型的輸出向量作為GNN 模型的輸入,最后將2 個模型的輸出結果進行線性組合。實驗對比結果如圖4 所示,其中AVG 代表4 種組合條件在3 個數據集上的平均表現。
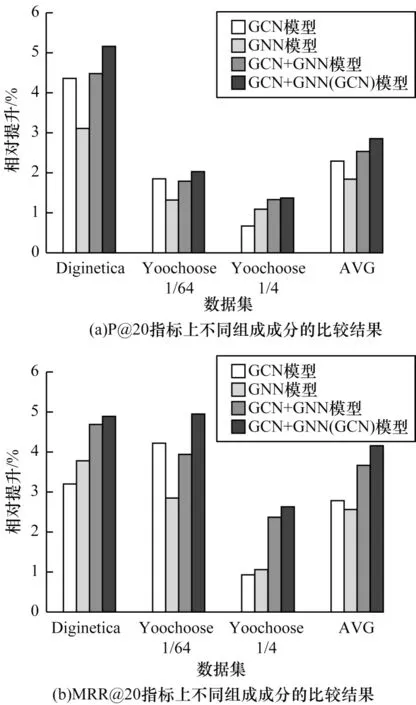
圖4 不同結構信息的實驗結果Fig.4 Experimental results of different structural information
從圖4 可以看出,綜合有向結構信息與無向結構信息的GCN+GNN(GCN)模型在3 個數據集的2 個指標P@20、MRR@20 上都取得了最佳的結果,這證明了綜合考慮有向結構信息和無向結構信息的重要性。圖4中平均數據AVG 還顯示了單獨考慮無向結構信息相比單獨考慮有向結構信息表現更加優異。從單個數據集的表現上可以看出,在Yoochoose 1/4 數據集和Diginetica 數據集的MRR@20 指標上,考慮有向結構信息表現稍好于無向結構信息。這一定程度上反映了在基于會話序列的推薦中用戶的偏好與項目之間的聯系、項目之間的轉換方向在不同的場景下有著不同的重要程度,但平均而言還是無向結構信息更重要。這說明在基于會話序列推薦的場景下用戶在項目之間的轉換方向雖然值得考慮,但還是需要重點考慮用戶瀏覽的項目之間的聯系,才能更好地學習到用戶的偏好。而比前兩者更好的做法是綜合考慮有向結構信息和無向結構信息,圖4 中GCN 結合GNN 的方法在3 個數據集的綜合表現及平均表現AVG 上,基本都要比單獨使用GCN 或GNN 的表現要好。而其中GCN+GNN 的方法中2 個網絡模型的輸入數據都是隨機嵌入向量,而GCN+GNN(GCN)的方法中GNN 模型的輸入是經過GCN 模型提取無向結構信息的向量,這說明了相比直接使用隨機向量,先對無向結構信息進行提取而后再進行有向結構信息的提取能夠得到更精準表示的嵌入向量。
本文進行重復點擊注意力信息和項目間依賴關系的組合分析如下:1)GCN+GNN,不考慮重復點擊注意力信息和項目間不同的依賴關系;2)AttGCN+GNN,只在GCN 中考慮重復點擊項目的注意力信息;3)GCN+AttGNN,只在GNN 中考慮項目之間不同程度的依賴關系;4)AttGCN+AttGNN,同時在GCN 中融合重復點擊的注意力信息和在GNN 中融合帶注意力的項目依賴關系。實驗結果如圖5 所示。
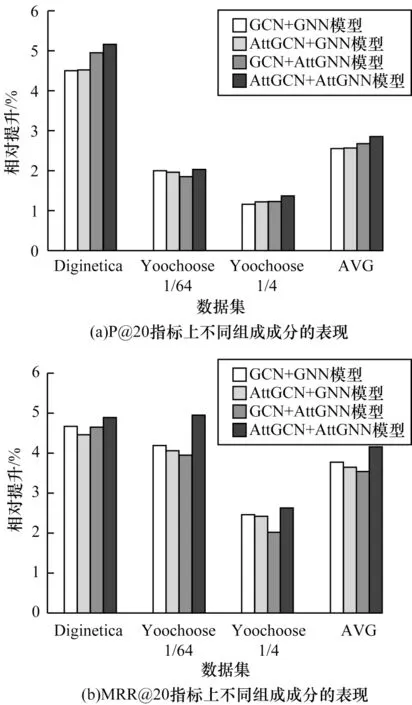
圖5 不同注意力信息組成成分的實驗結果Fig.5 Experimental results of different attention information composition
從圖5 可以看出,綜合考慮重復點擊注意力信息和項目間依賴關系的AttGCN+AttGNN 在3 個數據集的2 個指標上均取得了最佳的實驗結果,這說明重復點擊行為和項目間的依賴關系在基于會話序列的推薦中有一定的重要性。根據圖5(a),單獨考慮重復點擊注意力和項目間關系的注意力比不考慮任何注意力信息的GCN+GNN 要有更好的表現,綜合考慮兩者的AttGCN+AttGNN 效果最佳,說明了注意力信息確實能夠使得重要的信息盡可能地保留并得到更加精準表現的嵌入向量。根據圖5(b),雖然綜合考慮兩種注意力的AttGCN+AttGNN 仍能獲得最佳的實驗表現,但是單獨考慮兩者注意力其中之一的表現會略差于不考慮任何注意力信息的GCN+GNN 的表現,即單獨使用注意力信息雖然能夠提高推薦結果的精確率,但是對推薦排名的預測效果并不好。可能是向量在輸入GCN 和GNN 模型時,如果一個模型考慮了注意力而另一個模型沒有考慮,那么2 個模型中鄰接矩陣的表現模式也就沒有統一,導致向量在兩個模型之間輸入輸出時不能同時利用注意力保留結構信息,反而使得結構信息因為注意力模式不一致受到干擾,所以最后沒有生成精準表示的嵌入向量,即不能在預測階段計算出每個項目準確的預測得分。
4 結束語
在基于會話序列的推薦場景中,用戶的重復點擊行為和圖結構信息都能在不知用戶歷史偏好的情況下很好地預測出用戶的行為。本文提出一種基于有向與無向信息同注意力相融合的圖神經網絡序列推薦算法。利用GCN 與GNN 模型提取會話序列圖中的有向結構信息與無向結構信息并進行線性組合,在2 個模型的內部引入注意力機制,對用戶的重復點擊和項目之間的復雜轉換信息進行有效提取,使得生成的會話向量在推薦過程中預測更準確。在3 個數據集上的實驗結果表明,該算法精度優于目前現有的算法,并驗證了注意力機制和復雜的結構信息的有效性。下一步將在研究復雜圖結構的基礎上,尋找更好的隱含向量表現方式和向量組合方式,提高會話序列推薦的準確率。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
現代企業(2015年9期)2015-02-28 18:56:50
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
