項目式學習在高中信息技術教學中的應用
2022-05-15 15:16:01陳文劍
廣東教學報·教育綜合 2022年53期
關鍵詞:高中信息技術
陳文劍
【摘要】項目式學習是一種以學生為中心的教學方式。在項目式學習過程中,學習者會積極地收集信息、獲取知識、探討方案,以此來解決具有現實意義的問題。本文以Python語言為基礎,把項目式學習融入到高中信息技術教學中,通過網絡數據采集培養學生分析問題和解決問題的能力,提升學生的信息素養。
【關鍵詞】高中信息技術;項目式學習;Python爬蟲;網絡數據采集
《普通高中信息技術課程標準(2017年版2020年修訂)》提倡使用項目式學習。項目式學習是一種以學生為中心的教學方式,在項目式學習過程中,學習者會積極地收集信息、獲取知識、探討方案,以此來解決具有現實意義的問題。因此,在項目式學習過程中,學生不僅要學習《課程標準》的相關內容,還要懂得如何在現實生活中將這些知識學以致用。結合高一開設的Python編程教學和必修一第五章第二節《數據的采集》,引導學生學以致用,設計了這個教學項目。
一、項目情境背景
隨著信息技術的發展,網絡購物已是一種時尚和趨勢,大家購物時總希望能買到物美價廉的商品,許多消費者在網購時都會留意商品的價格和銷量。為了幫助大家更好更快地在購物網站上獲取搜索商品的名稱、價格和銷量,通過網絡數據采集實現商品信息定向爬取,我們使用所學的Python知識編寫一個爬蟲程序來獲取網頁中的數據。所謂“網絡爬蟲”,是一種按照一定的規則,自動地抓取萬維網信息的程序,通俗地講就是通過程序去獲取web頁面上自己想要的數據。
這個項目以映射真實世界問題為學生提供學習情境,對高中生富有挑戰性的體驗,同時也能更加驅動他們探究的積極性。
二、項目教學目標及任務
學生已經具備Python語言的基本知識和初步技能,能編寫簡單的Python程序,但沒嘗試過使用Python進行網絡數據采集,缺少相關的認知和體驗,從現實抽象出來問題并解決有一定難度。本項目的教學目標如下:
(1)了解requests.get()的方法去獲取網頁的數據;
(2)理解re模塊中findall()函數匹配商品信息的方法;
(3)理解str.split()函數對字符串進行切片的方法,利用xlsxwriter模塊創建xlsx文件并添加數據到文件中;
(4)掌握列表的基本操作方法;
(5)通過小組協作,學會查找和合理利用數據解決生活中的實際問題。
本項目教學任務:通過Python爬蟲程序獲取淘寶搜索商品頁面的信息,提取商品名稱、價格和銷量,并把爬取到的商品數據以Excel文件的格式存儲。
三、項目學習的流程
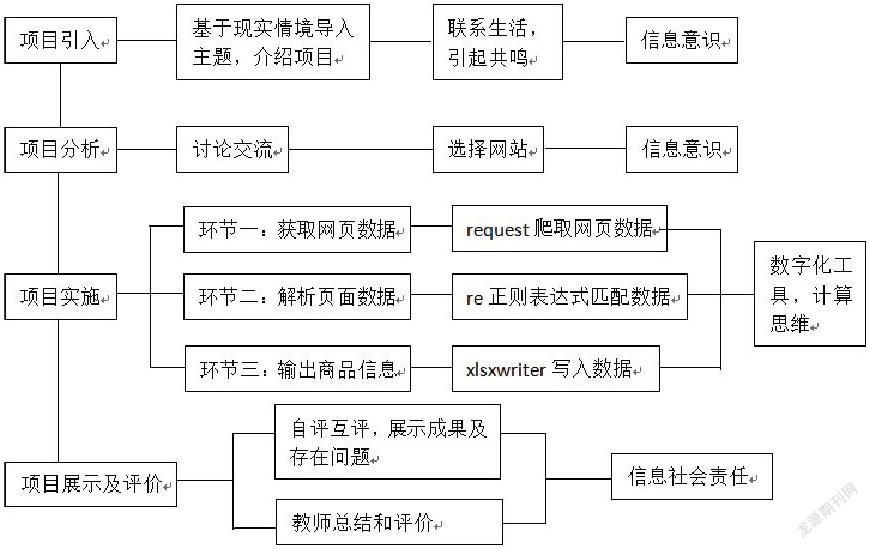
根據項目的主題,首先明確要爬取的網站和數據,通過合適的方法獲得頁面信息,再把解析出來的頁面數據輸出,以問題為驅動和導向,學生積極、主動地獲取知識,進行有針對性的學習和研究,將學習到的知識轉化為能力,應用到實際問題的解決中。本項目學習流程如下圖:
四、項目教學的過程
(一)項目引入
問題:如何在購物網站上獲取搜索商品的名稱、價格和銷量?
活動:教師提出問題,學生分組討論和思考
設計意圖:項目主題聯系實際生活,引起學生共鳴。很多學生獲取搜索商品的名稱、價格和銷量都是通過購物網站上的搜索引擎進行查找的,但商品數量繁多令人眼花繚亂,手動收集方式不太適用。本項目以學習如何使用python程序快速、自動地定向爬取商品信息,實現網絡數據采集。
(二)項目分析
活動:學生分組討論選擇一個廣為人知、商品的種類比較豐富,數據具有一定的開放性等特點的網絡商城。
設計意圖:挑選能夠實現商品信息定向爬取的購物網站,結合獲取數據的難易程度,決定把淘寶網作為獲取商品信息的來源。
(三)項目實施
環節一:獲取網頁數據
活動1:查看網頁的cookie和user-agent信息
問題:為何使用cookie和user-agent?
知識技能:了解網頁的cookie(儲存在用戶本地終端上的數據)和user-agent(HTTP請求頭)的作用。
設計意圖:因為許多網站都實施反爬蟲機制,當我們用requests get( )直接訪問淘寶網站,除了網址不提供其它的信息,那么網站收到的cookie和user-agent是空時,會被直接識別是一個機器人,不讓訪問及爬取它的網站信息。借助cookie和user-agent把我們的python爬蟲程序偽裝成一個正常的訪客,從而達到接入網站的目的。
活動2:商品翻頁時地址處理
設計意圖:因為我們要爬取的商品信息頁面往往不止一個,當數據進行翻頁時,我們需要找出網址變化規律。在淘寶網可發現,查詢商品的第二頁開始,每一頁最后是s=xx,xx是44的倍數,因為搜索頁每頁有44個商品。找到規律后,構造查詢商品網址url的語句如下:
url='https://s.taobao.com/search?q=+goods+'&s='+ str(44*i) '
活動3:利用requests.get()獲取網頁信息
知識技能:理解python第三方庫requests.get( )獲取網頁信息
設計意圖:requests庫是網絡請求庫,requests.get( )方法的作用是發出標準的HTTP請求的動作,把cookie和user-agent添加到requests.get()的請求頭中,模擬用瀏覽器打開一個網頁獲取數據,再使用text屬性取得網站返回的網頁源代碼。獲取網頁數據的關鍵過程及語句如下:
import? requests
header = {'cookie': 'miid=42...
'user-agent': "Mozilla/5.0... }
#登錄淘寶賬號,按F12打開開發者模式獲取cookie和'user-agent
result= requests.get(url, headers= header)
result.encoding = result.apparent_encoding
html=result.text
環節二:解析頁面數據
知識技能:掌握re模塊中findall()函數匹配商品信息的方法;掌握split()函數對字符串切片的方法;掌握列表的操作方法,使用循環結構在列表中保存商品的信息。
活動4:使用正則表達式匹配商品的相關信息
設計意圖:獲得搜索商品的網頁后,如何在紛繁的數據中提取商品的名稱、價格和銷量?re正則表達式能動態地、模糊地匹配字符串。通過查看源代碼可以找到如下信息:商品名稱、價格和銷量分別對應于“raw_title”“view_price“和“view_sales“。因為每一頁面有多個商品名稱、價格和銷量,需要使用re模塊中的findall()函數來匹配頁面所有滿足條件的字符串。
演示講解findall()函數的使用方法,引導學生使用findall()函數對商品的名稱、價格和銷量分別進行匹配。關鍵過程及語句如下:
import? re
r_title =? re.findall(r'\"raw_title\"\:\".*?\"',html)# 商品名稱
v_price = re.findall(r'\"view_price\"\:\"[\d\.]*\"',html) #商品價格
v_sales =re.findall(r'\"view_sales\"\:\".*?\"', html)# 商品銷量
提出問題:使用findall()函數匹配商品網頁數據后,能夠直接輸出商品的名稱、價格和銷量嗎?
學生經過分析發現不能,因為這三個列表中的數據都是以鍵值對的形式進行存儲:
r_title = ["raw_title":"商品名稱1" , "raw_title":"商品名稱2" ...]
v_price = ["view_price":"商品價格1" , "view_price":"商品價格2" ...]
v_sales=[" view_sales ":"商品銷量1" , " view_sales ":"商品銷量2" ...]
思考問題:如何對列表中的數據去掉其中的鍵,只留下值?
引導學生可以發現,鍵值對的形式中間有個冒號,只要把鍵和值通過冒號進行切片,然后提取冒號后面的值,就能分別獲取商品的名稱、價格和銷量。
活動5:通過for…in結構,遍歷列表元素,使用split()函數通過冒號對字符串進行切片處理
通過for…in結構,遍歷列表元素,先用split()函數將字符串以冒號進行切片,將商品的鍵和值分開,然后再通過索引取出所得數組中的第二個元素的值,從而分別獲取商品的名稱、價格和銷量,然后把這3個值組成一個小列表,再把這個小列表通過append()函數存儲到一個新列表中。關鍵過程及語句如下:
for i in range(len(r_title)):
title = eval(r_title[i].split(':')[1])
price = eval(v_price [i].split(':')[1])
view = eval(v_sales [i].split(':')[1])
infolist.append([title, price,view])
至此,每個商品的名稱、價格和銷量被提取出來,商品信息的列表格式如下:infolist = [["商品名稱1","價格1","銷量1"] , ["商品名稱2","價格2","銷量2"] ...]
環節三:輸出商品信息
知識技能:利用xlsxwriter模塊創建 xlsx 文件并添加數據
活動9:通過for…in結構,遍歷商品信息的列表元素,把數據添加到excel中
利用xlsxwriter模塊創建xlsx文件,通過for…in結構,遍歷列表infolist的元素,分別提取商品的名稱、價格和銷量,通過worksheet.write_string的方法寫入到excel中的B列、C列和D列,注意列表中每個元素的第一個索引值是0,第二個索引是1,依此類推。
關鍵遍歷語句代碼如下:
import? xlsxwriter
for x in infolist:
count += 1
worksheet.write("A"+str(count), count)
worksheet.write("B"+str(count), x[0])
worksheet.write("C"+str(count), x[1])
worksheet.write("D"+str(count), x[2])
但學生運行程序后,卻發現excle里面沒有數據,多次檢查后發現爬蟲程序中沒有把excel表關閉,導致寫入的內容會存在緩沖區中,并沒有真正的寫入文件里,所以還要對excle文件調用close( )函數進行關閉。
設計意圖:使用python對excle寫入數據操作,培養學生使用python程序對文件進行讀寫時良好的信息意識操作習慣。
(四)項目展示及評價
活動:采用小組自評和互評相結合的方法,請幾個小組的代表展示通過爬蟲程序獲取網絡數據的簡要過程,還有學習過程中遇到的困難,小組如何克服這些困難。其他小組對展示小組的成果進行項目評價。最后,教師進行總結和結合每個小組的成果予以評分和建議。
設計意圖:根據學習金字塔理論,當學習者把自己習得的知識或技能講授給他人時,學習效率最高,讓學生在分享和交流中共同進步。同時,學生在項目交流中會遇到很多問題,例如,有學生發現爬蟲程序反復運行時需要間歇性更換cookie或者過段時間再運行,否則會出現爬幾次后爬不到數據的情況。教師應及時指出因為淘寶也有反爬蟲機制,從而引導學生不能使用爬蟲程序去爬取任意的網站,進而培養學生信息社會責任的意識。
本課以項目為主線,學生為主體,教師為引導,通過“選擇網站”——“獲取網頁數據”——“解析頁面數據”——“輸出商品信息”四個環節完成利用python進行網絡數據采集,實現淘寶商品信息定向爬蟲,解決生活中的實際問題,培養學生分析問題和解決問題的能力。項目式學習比傳統的教學模式更能激發學生學習的主動性,讓學生由被動學習轉變為主動學習,把信息技術的知識融會貫通,提升學生的信息素養,促進學生的全面發展。
參考文獻:
[1]中國大學MOOC(慕課).Python網絡爬蟲與信息提取[OL].https://www.icourse163.org/course/0809BIT021A-1001870001.
[2]于雁.python模擬程序的編寫及應用[J].電腦知識與技術,2019(30).
[3]夏雪梅.項目化學習設計:學習素養視角下的國際與本土實踐[J].教育科學出版,2018.
責任編輯? 陳? 洋
猜你喜歡
亞太教育(2016年34期)2016-12-26 16:42:01
考試周刊(2016年96期)2016-12-22 23:26:55
考試周刊(2016年95期)2016-12-21 01:12:16
中學教學參考·理科版(2016年9期)2016-12-15 06:38:05
中學教學參考·理科版(2016年9期)2016-12-15 06:35:13
中學教學參考·理科版(2016年9期)2016-12-15 06:32:59
考試周刊(2016年94期)2016-12-12 12:01:36
新課程·中學(2016年9期)2016-12-01 12:48:13
新課程·中學(2016年9期)2016-12-01 12:47:24
啟迪與智慧·教育版(2016年9期)2016-11-26 09:07:43
