大數據時代公安網絡輿情風險識別研究
2022-05-15 02:50:00靳會峰
中國人民警察大學學報 2022年4期
劉 通,靳會峰
中國人民警察大學 宣傳處,河北 廊坊 065000
0 引言
網絡輿情是社會輿論的一種表現形式,是公眾在互聯網空間內對熱點事件、話題發表的言論與觀點[1-2]。而大數據輿情監測是為適應大數據時代輿情新特征而發展起來的,基于大數據分析技術的網絡輿情風險識別,可以有效地從海量網絡信息中識別危機事件與社會風險的信息源頭,分析公眾輿論觀點和情感傾向,并通過匹配數據庫中已有的相似事件進行風險評估和策略優化選擇[3]。發現并識別網絡輿情隱性風險、分析其演變發展規律,是及時應對輿情危機的前提[4-5]。
國外學者從網絡輿情預測分析角度開展了大量研究。Salehan等利用大數據技術建立了一個在線消費者評論預測模型,通過分析讀者感情傾向得出:具有積極情緒的標題更容易引起讀者關注[6]。Poria等提出一種基于深度學習的觀點提取方法,使用7層深度卷積神經網絡標注了輿情信息中用于情感分析的關鍵詞,極大提高了輿情信息數據識別的準確度[7]。Hardy等人在輿情信息數據公開度方面進行了相關研究,探討了將政府數據公開發布的好處及潛在輿情風險[8]。國內學者多以網絡輿情的演變與傳播規律、輿情風險的識別等為對象開展相關研究。黃微等研究了大數據環境下多媒體網絡輿情信息傳播要素和運行機理,構建了傳播機理的總體關系架構,為政府部門開展網絡輿情信息監管工作提供重要支持[9]。徐江虹深刻分析了高校網絡輿情在內容、主體、傳播媒介、傳播方式等方面的新變化,并在輿情識別、研判、處理等方面提出了新的治理方案[10]。高歌等從系統動力學角度剖析了大數據時代網絡輿情演化機理,闡釋了網絡輿情演化階段和要素[11]。王政構建了以主題為引導的輿情風險識別平臺,能夠更加準確迅速地了解和掌握網絡輿情發展現狀與變化規律,并對信息采集模型中的元搜索算法進行改進,加大了對各類輿情信息數據收集的深度與廣度[12]。
筆者基于大數據分析和網格建模思想初步建立了一種遺傳算法優化的動態網格輿情風險識別系統,可從大數據平臺獲取的海量輿情信息中篩選關鍵信息,有效預測并評估輿情風險。
1 大數據時代網絡輿情的新特點
伴隨著網絡信息技術的普及,社會輿論表達逐步實現了對網絡媒體平臺的全覆蓋[13]。網絡輿情正以其特有的方式反作用于現實社會,造成積極或負面的影響[14]。在大數據時代背景下,網絡輿情呈現出許多新特點和新變化:(1)規模大。據國際數據公司(IDC)研究報告,到2020年,全球數據使用量達到35.2 ZB,2021年非結構化數據占有比例將達到互聯網整個數據量的75%以上。(2)傳播快。與傳統輿情不同,基于互聯網媒介的網絡輿情傳播速度更快、受眾更廣。其主要原因是互聯網的開放性拓寬了網絡用戶的社交空間,尚不健全的信息發布審核機制也加快了網絡信息的自由傳播。(3)種類多。大數據時代網絡輿情信息復雜多樣、種類繁多。來自社會不同領域和階層的網民廣泛參與輿情信息的發布和傳播,構成了具有多元性、全民性、交互性、實時性的輿情信息網絡。
總之,網絡輿情的大數據特征使得公安網絡輿情風險識別、監管和引導工作增加了復雜性和不確定性。
2 大數據時代網絡輿情風險的數據采集
大數據時代背景下的網絡輿情新特點擴大了普通民眾的話語權,也對網絡輿情風險識別提出了新的挑戰。海量的網絡輿情信息數據離不開平臺技術的支持[15-16],通過大數據分析處理和輿情結構建模,可以對輿情發展態勢和影響進行研判。應當充分發揮大數據前瞻預測和數據比對兩大技術優勢:前瞻性趨勢預測,即對趨勢作出正確判斷,是大數據時代輿情管理的核心;數據比對分析,即充分利用多樣化數據,將不同領域的數據關聯起來進行分析。對輿情發展趨勢的預測分析是網絡輿情風險識別的重要技術內容,通過對重點主題進行密切跟蹤與監測,同時做好數據采集、分析,結合歷史上的類似事件進行趨勢預測,提出應對和防范措施,可最終達到風險規避目的。另外,許多網絡輿情信息都存在潛在關聯,相互關聯的網絡信息編織成巨大的輿情信息網絡,挖掘輿情信息數據中的內在聯系,建立信息數據關聯度評級機制,有助于風險識別與防范。
本文利用大數據平臺的全端數據采集獲取輿情風險樣本數據集,以具備應用程序接口的新浪微博為例,采用爬取工具收集網絡用戶輿情信息關鍵詞儲存于元數據庫中,以供輿情風險檢測模型進行訓練及算法優化。輿情信息樣本數據的采集應遵循隨機原則,輿情個體之間保持相對獨立。大數據平臺的全端數據采集主要包含涉及Android、iOS、Web、macOS、C++的前端采集,涉及Node、C、PHP、Java、Python的后端采集。
2.1 基于規則網格的網絡輿情建模
基于規則網格的大數據網絡輿情結構建模是對復雜網絡進行抽象建模的一種方法。具體來說,它涉及由頂點、邊、面、多邊形和元素組成的網格結構。數據網格化是將空間分布不均勻的數據按照某種方法轉換成有代表性的值的過程。
規則網格結構建模的基本思想:規則網格通常由規則形狀組成,如正方形、三角形和矩形。規則網格中的每個網格單元都對應一個數值矩陣,在空間相鄰的網格單元之間存在輿情信息的相互作用。通過常規的基于網格的結構建模和交互計算,可將網絡輿情信息資源進行整合[17]。
基于網格的輿情結構建模規則:以網絡輿情風險識別系統為代表的復雜多組分系統的基本組成部分不是粒子,而是能夠思考的普通公眾成員。在這樣的系統中,每個人與有限數量的同伴互動,而不是與其他所有人互動。因此,可以采用基于規則網格的建模方法,對輿情系統中涉及的復雜交互進行結構建模。在這樣的模型系統中,每個人的基本運動方程通常是未知的,很難使用傳統的統計分析來評估。將現代物理學中的量子力學與常規的基于網格的建模方法相結合,可以有效描述微觀粒子的結構、性質和運動。因此,可以嘗試用描述物質世界的網格方法來描述社會系統,即認為“人類像粒子一樣移動”,從微觀的角度,利用隨機性和無序性來解釋宏觀的社會現象。
2.2 基于規則網格的輿情模型優化
規則網格提供了復雜網絡的抽象表示,基于規則網格的輿情建模與仿真是結構復雜的輿情建模的重要組成部分。在常規的基于網格的輿情結構建模中,可以采用如圖1所示的四鄰域、八鄰域或拓展鄰域空間關聯來模擬大數據時代輿情形成與演變過程中的互動[18-19]。基于輿情網格化結構建模規則,將理性的輿情互動轉化為簡單的空間鄰域關系。

圖1 空間鄰域關系圖
復雜動態網格輿情風險識別系統是一種由節點和邊組成的系統,節點之間相互連接。對節點進行分析,統計節點之間的數據關聯度,對于研究網絡輿情的拓撲結構具有重要意義[20]。各個節點所擁有的相鄰節點數量稱為節點度。如果已知網絡內各節點的度,就能知道網絡的節點度序列及其分布,這是任何復雜網絡最基本的拓撲特征。通過多次實驗可以得出網絡輿情的度分布特征,結果表明大多網絡輿情的節點度主要服從冪分布、泊松分布和指數分布。在網絡拓撲結構中,兩個節點之間的距離,即一對節點之間的最短路徑,定義為連接兩個節點的最小邊數或最小權值之和。相關研究案例中的輿情互動網絡表明,網絡輿情互動節點度呈現出較為清晰的冪分布,平均路徑較短。這一特征對于研究網絡結構和輿情傳播效率具有重要意義。
在復雜系統中,節點可以用來表示不同的個體,而邊可以用來表示不同的個體抽象聯系,通常適用于描述系統中個體之間的關系和他們的集體行為。許多現存的復雜系統可以被描述為輿情網絡[21]。
3 大數據時代公安網絡輿情風險識別方法
網絡輿情作為互聯網時代公民言論的全新表現形式,成為了公民言論自由從現實向虛擬延伸的重要載體[22]。網絡輿情風險是負面輿論所引發的危機事件,會對公眾個體造成不同程度的損傷[23]。網絡輿情風險有別于現實社會風險之處在于其隱性特征。最常見的網絡輿情風險表現為輿情主體情感的失控,包括主觀焦慮的強化和放大、集體情緒宣泄和個人理性的迷失。網絡輿情風險的識別分析有賴于大數據分析技術,而基于海量數據的數學建模和風險識別系統設計是當前的兩大重要研究方向。
3.1 大數據時代公安網絡輿情演化及風險識別的數學建模
近年來,各種各樣的模型和模擬技術被用于輿情演化傳播研究,其起初主要基于傳染病模型,如SIS、SIR和SEIR模型等。也有一些研究者提出了動態觀點模型等,他們認為人們的觀點會隨著時間和周圍環境的變化而變化,從而影響信息的傳播。
網絡輿情涉及多個學科,來自不同學科背景的學者對網絡輿情演變的研究視角不同。目前常見的數學建模思想有:基于元胞自動機建模思想、基于Agent建模思想、基于社會網絡的建模思想、基于博弈論思想。常見的風險演化模型有:基于多數原則的網絡輿情風險演化模型、基于有限信任的網絡輿情風險演化模型以及基于Sznajd的網絡輿情風險演化模型。
眾多的建模思想和演化模型有著不同的建模標準,且大多具有單一、非系統的缺陷[24]。規則網格模型可有效實現輿情風險模型從非理性到理性、從單一到多維、從非系統性到系統性的轉變。但基于規則網格模型的輿情演化模型也存在一定的局限性,只考慮了輿情信息發布者與被調查者之間的關系,公眾觀點、網民心理等輿情要素在規則網格模型中沒有體現。因此,本文在規則網格輿情模型的基礎上提出了基于大數據信息采集的動態網格輿情風險模型,并借助遺傳算法進行了模型優化。
3.2 借助遺傳算法優化的動態公安網絡輿情風險模型
3.2.1 引入概率關系
不同于傳統的規則網格輿情模型,本文建立的基于遺傳算法優化的動態網格模型強調連接關系在一定程度上具有概率性。考慮到各種輿情因素的影響是有概率性的,因此輿情網絡中的節點邊緣連接也應該具有一定程度的概率性。復雜動態網格模型可以有效評估邊緣概率和動態網絡分析中隨時間的變化。
復雜動態網格模型分析是基于輿情監測平臺收集到的相關輿情數據而建立的,要想對網絡輿情風險演化模型進行構建,首要的任務就是對網絡輿情信息進行獲取[25]。由于網絡輿情信息中包含大量的高頻關鍵詞,因此需要將相似的關鍵詞進行整合并且引入概率關系。
在引入概率關系的復雜動態網格輿情模型中,以反映某一具體輿情事件中公共個體觀點和態度的關鍵詞為節點,而邊則表示在同一輿情信息中出現了兩個關鍵詞節點。Pi是模型中個體輿情觀點態度的屬性值,由積極關鍵詞在輿情信息中所占的比例決定,如公式(1)所示:
式中,Hi表示輿情個體i發布的網絡信息中包含的關鍵詞總數;hi表示輿情個體i發布的網絡信息中積極關鍵詞的數量。
3.2.2 考慮輿情因素之間的驅動關系
網絡輿情風險作為一種復雜的社會現象,其形成和演變也涉及網絡輿情各驅動因素之間的相互作用。復雜動態網格輿情模型可以很好地描述某一特定輿情危機發展過程中各要素之間的相互關系,一定程度上反映控制輿情演變內部驅動因素作用的機制。
在網絡輿情中,輿情事件類型是節點,類型之間的轉化是邊緣。Pn代表動態網格模型中個體的屬性值,其值由輿情事件的類型和特征決定,且該變量的值在[0,1]范圍內。本文根據網絡輿情事件的風險程度,將其分為九個類別,類別1到類別9分別賦值為0.1到0.9來體現由低到高的風險程度。通過計算不同類型輿情的驅動因子,可以確定復雜動態網格輿情模型中公共主體的屬性值Pm,如公式(2)所示:
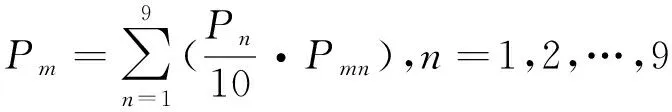
(2)
式中,n表示環境子網中分為9類的網絡輿情事件的參考屬性值;Pmn表示動態網格輿情風險模型中第m個輿情信息主體發出的信息屬于第n個事件類型的概率。
3.2.3 遺傳算法優化
鑒于大數據時代海量輿情信息挖掘和識別的并行化、非線性化要求,本文采用并行搜索性能較強的遺傳算法進行風險模型優化。遺傳算法是一種基于自然演化原理的搜索優化機制,其具有很好的全局搜索能力,能在搜索過程中獲取和收集搜索域內的有效數據以供尋優求解[26-27]。在大數據平臺下充分利用遺傳算法的優勢可以更好地完善網絡輿情風險網格模型、提高模型的收斂效果,更好地預測和識別輿情風險。遺傳算法流程如圖2所示。
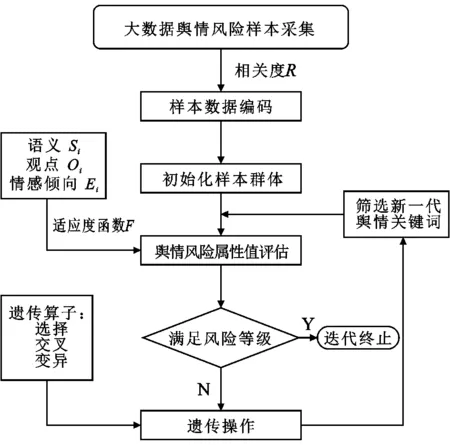
圖2 遺傳算法流程圖
3.2.3.1 設置樣本變量。借助大數據平臺進行海量信息采集,將關鍵詞的事件相關度R作為必要約束條件設置樣本量范圍。編碼方法直接影響到交叉、變異等遺傳算子的計算效率,本文采用二進制編碼方法進行輿情數據樣本的數字化編碼,編碼原則依照上文提出的引入概率關系的輿情個體屬性值Pi與考慮各因素間驅動關系的輿情主體屬性值Pm。類比染色體基因中AGCT4中堿基對的隨機排列,將屬性值Pi與Pm映射為隨機排列的二進制編碼串。
3.2.3.2 構造初始化函數。遺傳算法中的每一條染色體對應一個解決方案,常用適用度函數衡量解決方案的優劣[28-30]。本文基于元數據庫中采集的關鍵詞語義Si、觀點Oi、情感傾向Ei來構建適應度函數。適應度函數F定義為以上3個風險屬性參量的加權和,如公式(3)所示:
F=ζ1Si+ζ2Oi+ζ3Ei
(3)
式中,ζ1、ζ2、ζ3分別為參量Si、Oi、Ei的加權系數。且三個參量的可能值為-1,0,1,分別代表積極、中性、消極的詞義屬性。加權值之和越大意味著適應度越大,進而輿情風險程度越高。輿情信息樣本的適應度評估結果如圖3所示。
圖3 輿情信息樣本的適應度評估結果
3.2.3.3 選擇。利用遺傳算法中的選擇操作可以篩選風險等級更高的輿情信息關鍵詞,選擇機制是影響遺傳算法性能的主要因素。本文采用“輪盤賭”選擇方法進行輿情事件特征類型選擇,輿情個體被篩選進入下一代的概率等于其適應度與種群中所有個體適應度之和的比值,相應的MATLAB程序代碼如下:
fitvalue=[3 2 1 0 -1 -2 -3]; %輿情信息對應的適應度值
totalf=sum(fitvalue); %適應值之和
p=fitvalue./totalf; %單個輿情個體被選中的概率
q=cumsum(p); %輿情個體的累積概率
c1=c2=c3=c4=c5=c6=c7=c8=c9=0 %9類輿情事件的次數初值
while c1+c2+c3+c4+c5+c6+c7+c8+c9<=1997
fitin=1;
newin=1;
m=sort(rand(4,1)); %生成一組從小到大排列的隨機數組
while newin<=4
if q(fitin)>m(newin)
s(newin)=fitin;
switch s(newin)
case 1
c1=c1+1;
case 2
c2=c2+1;
case 3
c3=c3+1;
case 4
c4=c4+1;
case 5
c5=c5+1;
case 6
c6=c6+1;
case 7
c7=c7+1;
case 8
c8=c8+1;
case 9
c9=c9+1;
end
newin=newin+1;
else
fitin=fitin+1;
end
end
end
3.2.3.4 交叉。本文采用單點交叉,在大數據采集的輿情關鍵詞樣本編碼中隨機設置一個交叉點,然后在該點交換兩個輿情個體的部分編碼。單點交叉過程示意圖如圖4所示。
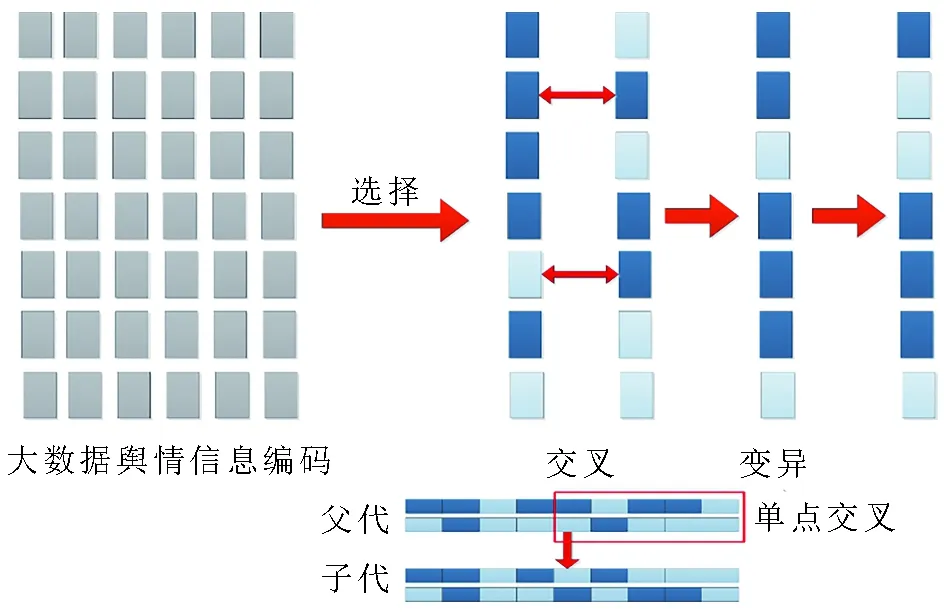
圖4 單點交叉過程示意圖
3.2.3.5 變異。遺傳算法采用概率的變遷規則來指導搜索方向,變異概率的大小影響著大數據采集樣本的多樣性與風險識別算法的優化精度。變異運算的主要內容是按照式(2)的概率將編碼串中某些部分的基因值進行替換,即對輿情主體的某個或某些個體屬性值進行改變。優化算法的終止條件是輿情個體適應度達到給定閾值,或者輿情個體風險等級達到預設峰值。最后比較每個輿情個體的適應度,適應度較低的被視為高風險等級輿情個體篩選出來,并針對相應的輿情事件指定應對措施。
3.3 大數據時代下公安網絡輿情風險識別系統可靠性分析
網絡輿情以網絡為載體,極大地改變了輿情的傳播方式、傳播速度、傳播內容與參與時效。公安機關可以充分利用復雜網格輿情建模思想和大數據分析,發揮大數據分析的優勢,以提高網絡輿情風險識別的能力和效率,更好地發揮網絡輿情的積極作用,促進社會的公平正義和發展進步。
然而,目前有關網絡輿情風險識別系統的研究仍然相對較少,尤其是對其可行性和可靠性的論證分析。其在大數據環境下與現實網絡輿情的交互性應用中,離不開系統可靠性分析。應當充分利用真值表法(狀態枚舉法)、全概率公式法(分解法)、系統邏輯圖法等對網絡輿情風險識別系統進行系統可靠性的分析評估。系統的可靠性預計是一個自下而上、從局部到整體、由小到大的系統綜合過程,目的在于發現薄弱環節、提出改進措施、進行方案比較,以提高網絡輿情風險識別系統的可行性、可靠性與高效性。
4 結語
目前,眾多學者從多角度對網絡輿情進行了深入研究,本文提出基于遺傳算法優化的動態網格輿情建模方法,可為公安機關應對大數據時代的網絡輿情風險提供重要參考。
基于大數據分析,初步探索了網絡輿情風險的復雜內在機制和相關規律。結合大數據時代網絡輿情多層次、多維度、多屬性特征以及驅動關系,系統建立了輿情動態網格結構模型。
從網絡輿情發展演變的角度,綜述了大數據時代基于復雜結構的動態網格輿情建模研究。考慮復雜動態網格輿情模型分類標準及對大數據時代網絡輿情風險多維結構的表征能力,利用規則網格上的粒子相互作用模型,對網絡輿情進行動態建模。基于網絡關鍵詞語義、觀點、情感的屬性分析,設計了包含大數據樣本采集、輿情風險適應度函數、風險源識別選擇、交叉變異的遺傳優化算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
