高斯混合生成模型檢測健康數據異常
2022-05-17 06:02:00朱壯壯周治平
計算機與生活 2022年5期
朱壯壯,周治平
江南大學 物聯網工程學院,江蘇 無錫214122
近年來,人們對健康的生活方式越發重視,越來越多的人通過運動手環來監測自己的健康。運動手環可以監測人們的運動狀況和一些行為方式,如睡眠時長、心率和運動步數等。Lim 等人發現患有疾病的手環佩戴者和健康佩戴者的手環數據存在顯著的差異,且特定指標與特定疾病的關聯較大,如運動步數和靜息心率這兩個指標都與心血管疾病和代謝紊亂有關。對于手環佩帶者而言,在對數據缺乏有效分析的情況下,僅僅依靠手環顯示的信息并不能準確地了解其身體的健康狀況。對于手環收集到的數據,異常值是指與某些疾病相關聯的指標偏離個體基準的數據。因此有必要找出手環數據中的異常值,提前判斷出用戶身體是否存在隱患,以便提前做出相應治療,這對改善用戶身體健康有重大的作用。
基于距離的異常值檢測方法,包括近鄰(nearest neighbor,NN)和平均近鄰,主要是基于對全維空間中距離的評估,該方法假定異常點與正常點之間的距離較遠,因此計算每個樣本點之間的距離(或者平均距離),并與距離閾值比較,若大于閾值則視為異常點。然而,當處理高維數據時,相關距離和近鄰的概念變得沒有意義,異常檢測的效果也變差。在這個大數據時代,數據呈現高維度特征,使得在進行異常檢測時,容易出現“維度災難”問題。為了解決該問題,許多研究都集中在基于降維的異常值檢測方法上。傳統的技術采用兩步法,即先降維,再進行異常檢測,這兩個步驟分別訓練,在沒有異常檢測指導的情況下進行降維訓練,容易丟失異常檢測的關鍵信息。Zhou 等人將深度神經網絡(deep neural network,DNN)降維和均值(-means)聚類方法結合起來,便于同時優化這兩個任務,減少解耦學習的影響,提升檢測效果。
深度學習領域的學者們已經提出了多種異常檢測技術用以改進檢測性能。Zong等人提出了DAGMM方法,該方法首先利用深度自編碼器將原始數據進行潛在空間表示,并將低維特征表示和重構誤差特征輸入GMM(Gaussian mixture model)中進行密度估計,通過選擇合適的密度閾值,將密度高于該值的數據記為異常值。然而,該方法假設異常是不可壓縮的,因此不能從低維潛在空間中有效重建輸入數據。相較于VAE 使用重建概率重構原始數據,重構誤差缺乏客觀性,導致DAGMM 方法檢測性能不佳。與GMGM(Gaussian mixture generative model)類 似,Nalisnick 等人提出了將VAE(variational autoencoder)與GMM 結合在一起的DL-GMM 方法,它采用混合高斯分布近似VAE 的后驗,從而提高了原始VAE 的容量。但是,它不適用于無監督的異常值檢測。Liu等人提出了一種基于多視圖主題模型的異常檢測方法,該方法利用多視圖主題模型對原始數據中的特征進行建模得到對應的關系,能夠大大降低檢測的誤報率,但是該方法檢測準確性偏低。
鑒于此,本文利用GMGM,用以進行人體活動數據的異常檢測。在該模型中,使用生成模型中的VAE生成數據潛在分布和重構誤差來訓練DBN(deep brief network),以預測樣本的混合成員隸屬度。高斯混合模型通過樣本的混合成員隸屬度預測得到每個數據的樣本密度,將密度高于訓練階段閾值樣本視為異常。GMGM 共同優化了VAE、DBN 和GMM,從而避免了模型解耦的影響。
本文有三個主要的貢獻:
(1)為了盡可能保留原始數據的特征,生成網絡利用VAE為原始樣本生成潛在分布和重構誤差特征。
(2)為了避免在計算樣本密度過程中,由于矩陣的奇點問題導致協方差矩陣無法求解,GMGM 利用樣本的混合概率、均值和協方差來構造協方差矩陣的Cholesky 分解,以計算樣本密度。
(3)由于傳統的兩步法技術在進行異常檢測時會丟失關鍵信息,GMGM 以一種端到端的方式共同優化VAE、DBN 和GMM,以保留數據的原始特征。
基于該方法,文本實現了健康數據的異常檢測,并在真實數據集上進行了實驗,結果表明,所應用算法可以有效地檢測健康數據中的異常。
1 相關工作
1.1 變分自編碼器
變分自編碼器的提出,旨在解決傳統的算法處理復雜場景中推斷和訓練困難且耗費大的問題,它能夠生成輸入數據潛在變量的低維表示。變分自編碼器可以看作一個特征器,根據原始樣本分布,構建出其概率分布以重構數據。相比深度自編碼器采用重構誤差進行重構數據,重構概率是一種概率測量,它考慮了變量分布的可變性,比重構誤差更具原則性和客觀性。因此,本文選取VAE 進行特征提取,解決“維度災難”問題,同時保留原始數據的多模態特征。近年來,變分自編碼器逐漸與深層神經網絡結合,通過隱含層的堆疊以一種無監督的方式進行參數優化。假設∈R表示一個維度為的向量,∈R表示對應的維度為′的潛在表示,(·)表示概率分布函數,則概率分布的生成過程可以表示為:

1.2 高斯混合模型
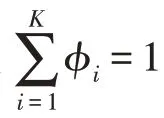
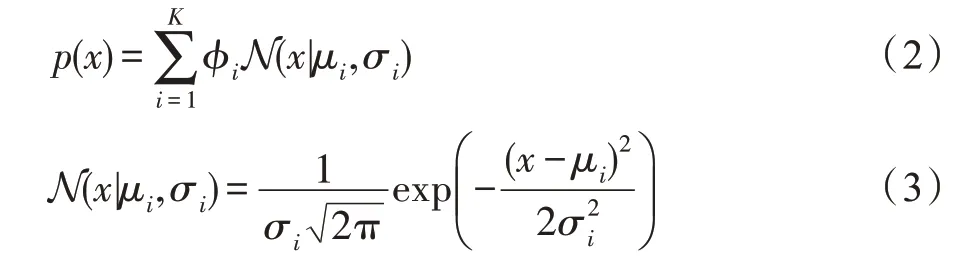
GMM 模型訓練階段,使用EM 算法以最大化似然函數的方式求解模型最佳參數,即混合概率φ、均值μ和協方差σ,直至模型收斂。
2 本文算法
針對GMM 對高維數據進行密度估計時,會出現時間復雜度較高的問題,本文利用GMGM 對健康數據進行異常檢測。如圖1 所示,該模型主要由兩部分組成:生成模型和高斯混合模型。GMGM 的工作原理如下:首先,生成模型通過VAE 對輸入樣本進行降維處理,以便生成樣本點的潛在空間表示和基于重構的特征提供給DBN;接著,DBN 采用饋送,預測得到樣本點的混合成員隸屬度;最后,利用混合成員隸屬度,GMM 預測每個數據的樣本密度,將樣本密度高于訓練階段的閾值的數據視為異常。
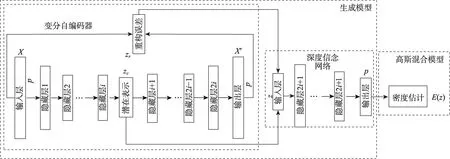
圖1 高斯混合生成模型結構示意圖Fig.1 Structure diagram of Gaussian mixture generative model
2.1 本文算法
在高維空間中,會出現一種“維度災難”的現象,即隨著數據維度的增加,密度預測的時間復雜度會急劇增加,性能下降。為了解決此問題,生成模型通過VAE 對數量為,維度為的輸入數據=[,,…,x]∈R進行重構處理,提取樣本點的潛在空間表示和重構特征,以保留樣本的固有多模態信息,并將其作為DBN 的輸入。

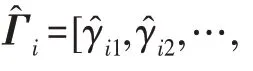

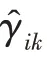
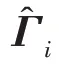
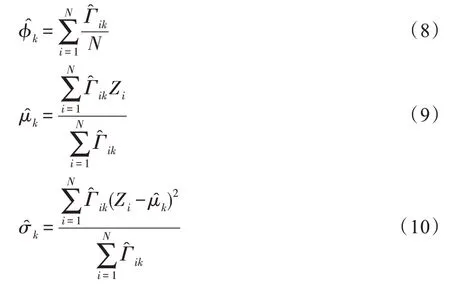
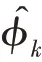
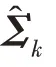
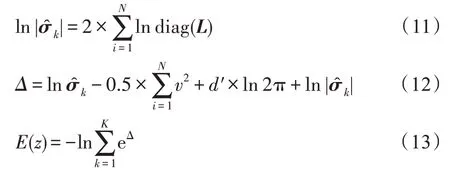
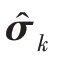
傳統的兩步法技術在進行異常檢測時會丟失關鍵信息,因此需要將降維過程與密度估計過程聯合訓練,相互優化。GMM 在利用EM 算法進行模型訓練時,首先根據當前參數計算每個數據的混合成員隸屬度,接著利用得到的混合成員隸屬度計算模型參數,直至收斂。因此,本文中GMGM 將期望最大化算法的E 步驟中的樣本屬于各子分布的概率替換為端到端結構中生成模型的輸出,以一種端到端的方式共同訓練了生成模型與GMM;接著,利用EM 算法中M 步對GMM 中的均值、協方差等做參數估計,然后極大化似然函數,相對于傳統的訓練方式,更易達到理想的檢測效果。
在測試階段,GMGM 可以根據式(13)預測樣本的密度,將樣本密度高于訓練階段閾值的數據視為異常。
2.2 目標函數
由于解耦學習性能不佳,在GMGM 中,將VAE、DBN 和GMM 統一起來,共同進行模型訓練。給定個數據點的樣本集,目標函數如下:
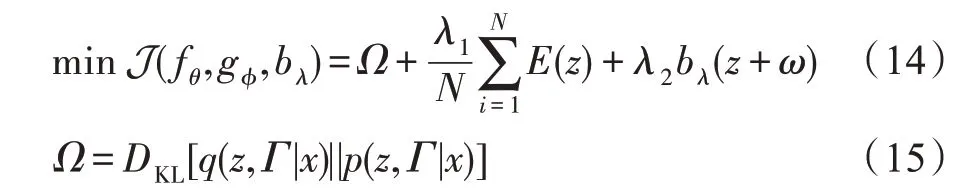
式(15)表示后驗分布(,|)和最大似然分布(,|)的KL散度。通過最小化后驗分布與最大似然分布的KL散度,以最大程度地提高多維輸入的似然。
()模擬可以觀察輸入樣本的概率。通過最小化樣本密度,以最大化觀察到輸入樣本的可能性,以便得到VAE、DBN 和GMM 參數的最佳組合。
和是用于規范目標函數的超參數,實驗中,=0.1,=0.001 通常可以得到較好的結果。最小化J(f,g,b)可為生成模型和GMM 提供最佳的參數組合。
2.3 算法復雜度分析
假設∈R表示數量為,維度為的原始輸入數據,GMGM 方法需要對原始數據進行重構處理,設定隱含層層數為3,即三層編碼器、三層譯碼層,′為設置的各隱藏層節點數(即每層輸出維度)中的最大值,該部分的時間復雜度為(′);DBN分別預測各樣本屬于個組件的概率,該部分包括反向傳播過程和Softmax 過程,該部分的時間復雜度為(′);利用GMM 進行密度估計,該步驟的時間復雜度為((+1)),因此GMGM 的時間復雜度為((+1)+(+1)′)。隨機異常選擇(stochastic outlier selection,SOS)算法采用相異度矩陣以親和力的概念量化兩點之間的關系,其時間復雜度為(),遠高于本文算法;經典的異常檢測算法如VAE,其時間復雜度為(′),DAGMM 時間復雜度為((+1)+(+2)′)。
3 實驗評估
實驗平臺配置為Windows10 操作系統、Intel Core i7-7700HQ CPU 處理器、2.80 GHz、20 GB 內存,所有算法由Python 實現。
本文選取了5 個數據集,皆來自ODDS 數據庫,這些數據集包含異常類,并根據樣本標簽區分。標簽為0 的數據為正常類,標簽為1 的數據為異常類,數據集的數據特征見表1。
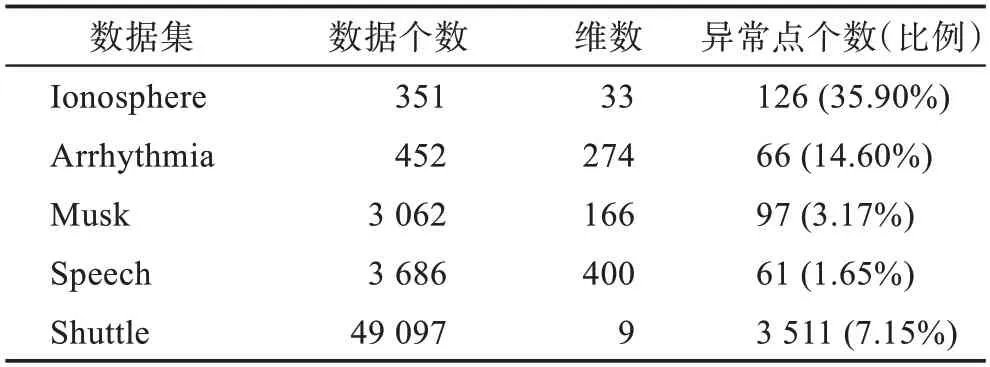
表1 數據集信息Table 1 Dataset information
為驗證算法性能,將本文算法與SOS、基于變分編碼器的異常檢測算法、深度自編碼器高斯混合模型(deep autoencoding Gaussian mixture model,DAGMM)進行了比較。選取的原因是:SOS 算法使用關聯的概念來計算每個數據點的異常值概率,這與本文預測每個樣本點密度的方式類似;本文算法是基于變分自編碼器的異常檢測算法的改進,因此選取其作對比;DAGMM 采用深層自編碼器提取原始數據的特征,通過多層感知機估計樣本的混合成員隸屬度,最后通過GMM 計算每個樣本點能量進行異常檢測,其檢測效果較好,并且結構與本文算法相似,因此選取其作為對比算法。
本文所用的評估異常檢測算法的性能指標是:召回率(Recall)、1分數(1-Score)、正確率(ACC)和受試者工作曲線(area under curve,AUC)。較好的異常檢測算法應該有較高的Recall、1-Score、ACC、AUC。
3.1 實驗對比結果與分析
對于各樣本集,GMGM 的參數設置如下:數據集Ionosphere、Arrhythmia、Musk、Speech 和Shuttle 的潛在空間表示維度分別為3、4、4、4、2;為了確定GMM最優組件的個數,需要使用一些分析標準來評估模型的可能性。本文參考了文獻[6]與文獻[7],發現其主要是采用了貝葉斯信息準則(Bayesian information criterion,BIC)的評價方法來確定組件個數,模型的BIC 值越低,GMM 預測樣本數據樣本密度的性能越好。對于本文中所有的數據集,GMM 組件個數取3時,模型BIC 值最小,因此對于所有的數據集,GMM組件個數設置為3。
為了驗證GMGM 針對高維數據檢測性能的優勢,選取了維度較大的Speech 數據集,采用定性的方式,與SOS、VAE 和DAGMM 算法進行ROC 曲線的對比,對比結果如圖2所示。從圖中可以看出,相較于SOS、VAE和DAGMM算法ROC曲線下面積AUC值,GMGM異常檢測方法的面積最大,即AUC值最高。其中,VAE 算法的檢測效果最差,可能是因為VAE 在對數據進行潛在空間表示的時候,把原始樣本跟異常有關的關鍵信息錯誤地進行了刪除,導致檢測AUC值較低;而GMGM 采取的是端到端的聯合訓練,可以同時訓練VAE、DBN 和GMM,使三者模型參數達到最優,檢測效果較為理想。
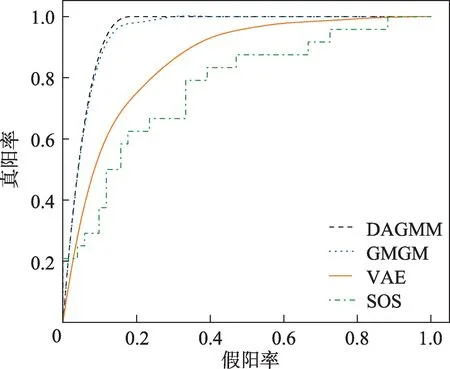
圖2 各算法檢測Speech 數據集的ROC 曲線Fig.2 ROC curves of each algorithm for Speech
從圖3 中可以看出,對于不同的數據集,本文算法在取得最好的檢測效果時,所對應的VAE 編碼器層數都不同。當值增大時,各數據集對應的AUC值總是先增大后減小。這是因為先增大值可以使得編碼器很好地進行數據重構,較好地學習到原始樣本的特征,因此AUC 值增大;但是之后隨著繼續增大,導致訓練過擬合,使得算法AUC 值減小。經過綜合考量,對圖3 中5 個數據集的值選擇分別是4(33-16-8-3)、5(274-136-64-16-5)、5(166-84-42-12-5)、5(400-200-100-50-5)、2(9-2)。
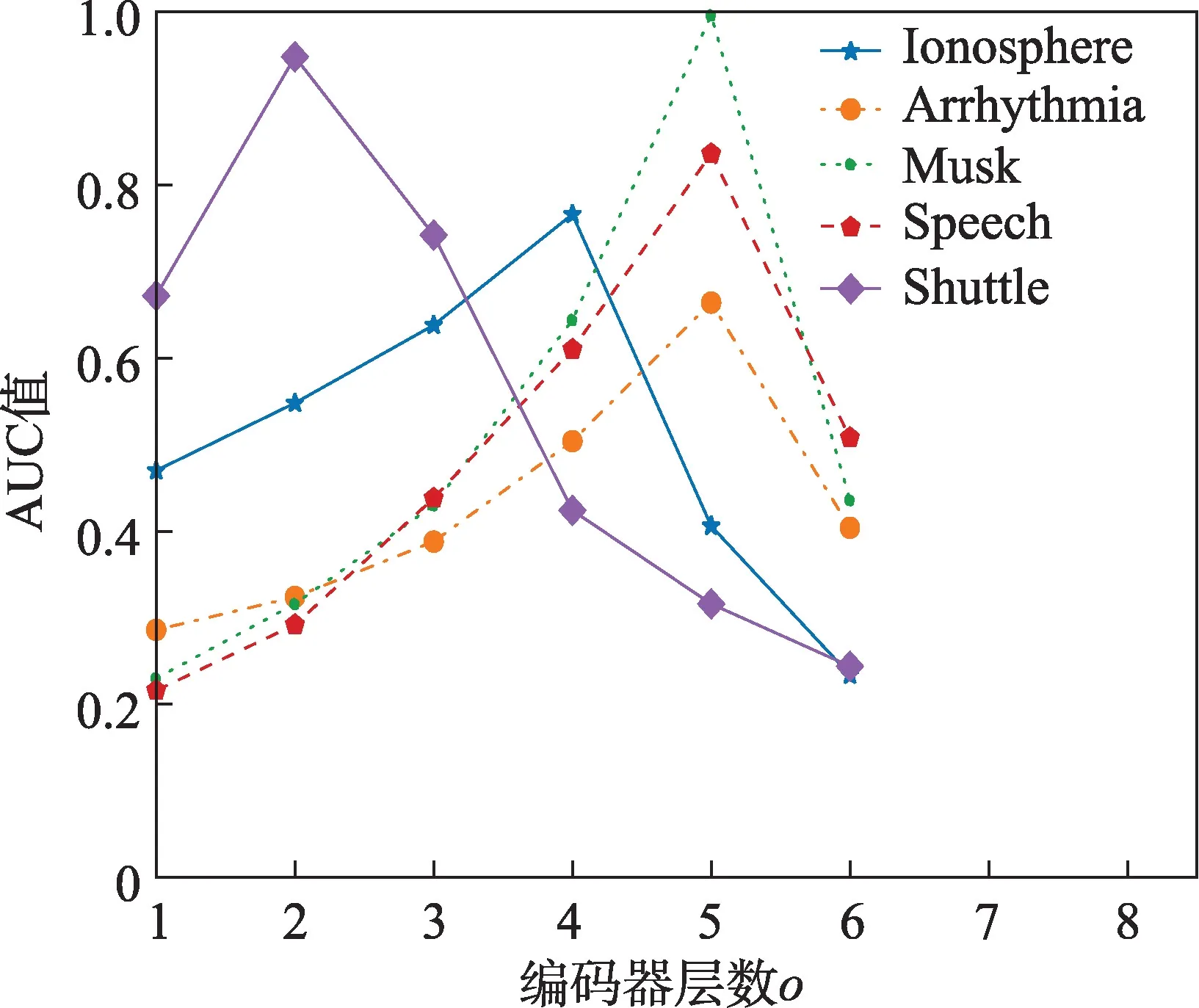
圖3 各數據集在GMGM 上的不同o 對應AUC 值Fig.3 AUC curves with different o for different datasets on GMGM
為了驗證GMGM 在時間復雜性上的優勢,將其與SOS 算法、VAE 算法和DAGMM 算法的平均檢測時間進行對比,對比結果如表2 所示。
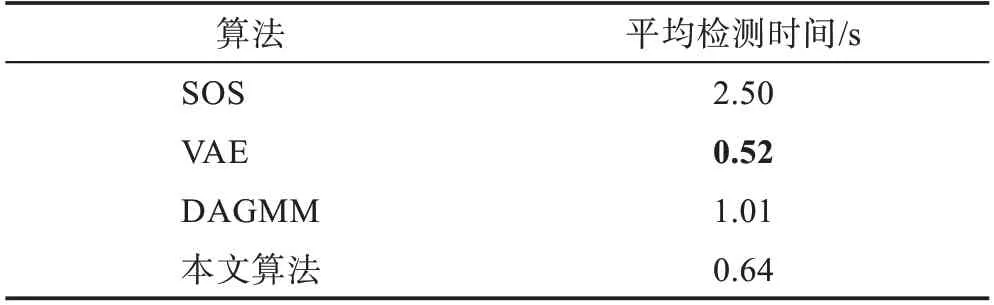
表2 各算法平均檢測時間對比Table 2 Comparison of average detection time of each algorithm
從表2 可以看出,雖然本文算法的平均檢測時間不是最低,但是比平均檢測時間最低的VAE 算法僅相差了0.12 s;并且其平均檢測時間比性能較好的DAGMM 算法提升了37%,體現了本文算法在檢測時間方面的優勢。
為了驗證本文端到端結構的有效性,將本文算法與獨立訓練的模型進行對比,實驗結果如表3 所示。從表中可以看出,采用端到端訓練的GMGM 的各個指標均高于獨立訓練的模型。
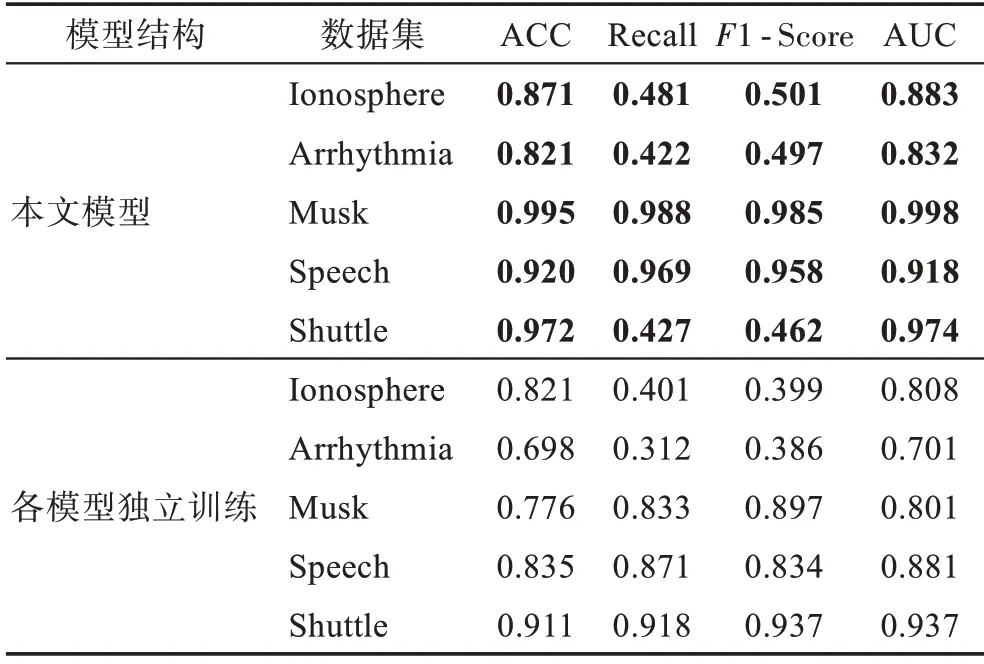
表3 不同模型結構實驗結果對比Table 3 Comparison of experimental results of different model structures
為了驗證本文算法性能的優勢,將本文算法與VAE 算法、SOS 算法和DAGMM 算法進行對比,計算各異常檢測算法性能指標ACC、Recall、1-Score 和AUC值,列入表4中。其中VAE算法的隱含層層數和各層節點數與生成網絡中的VAE 相同;DAGMM 與文獻[6]具有相同的參數設置。
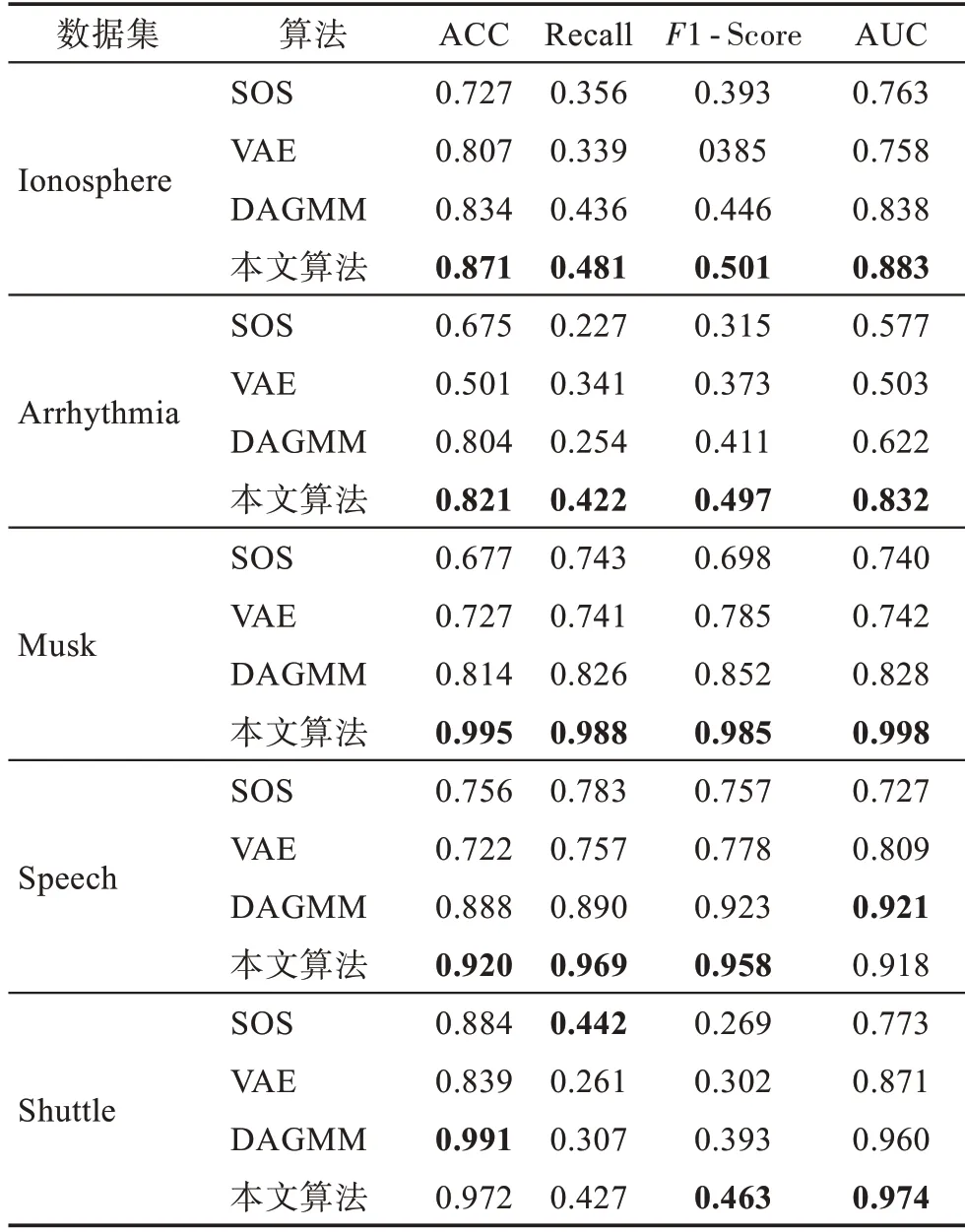
表4 不同算法實驗結果對比Table 4 Comparison of experimental results of different algorithms
從表4 的對比實驗結果可以看出,GMGM 的準確率僅在大數據集Shuttle 上稍低于DAGMM 算法;其AUC 值也僅在Speech 數據集上稍低于DAGMM算法;在大數據集Shuttle 上的Recall 值雖然不是最高,但與最高值相差不多;在高維數據集Musk 上準確率達到了0.995,遠高于SOS 算法的0.677,在維數較高且數據量較大的Arrhythmia 數據集上也表現出較為理想的檢測效果;在Shuttle數據集上,雖然本文算法的ACC 和Recall 稍有降低,但是1-Score 與AUC值分別提高了7 個百分點與1.4 個百分點。這種情況發生的原因可能是,算法中的潛在空間表示能夠較好地捕捉到數據的整體特性,提高了數據的局部結構能力,降低了算法的時間復雜度;但同時,VAE 在對大數據集Shuttle 進行潛在空間表示的時候,由于數據量比較大不可避免地會出現過擬合現象,這也是本文算法需要改進的地方。
3.2 健康數據異常檢測結果
算法的性能得到了驗證之后,利用該算法在收集到的健康數據上進行實驗,對異常值進行檢測。圖4是采用本文算法進行異常檢測可視化的結果。其中黑色點表示正常數據,紅色點表示異常數據。

圖4 GMGM 算法在健康數據上異常檢測結果Fig.4 Detection results by GMGM on health data
為了突出該算法的優勢,又采用了檢測效果同樣好的DAGMM 算法在同一實驗環境下對同樣的健康數據進行了實驗,結果如圖5。
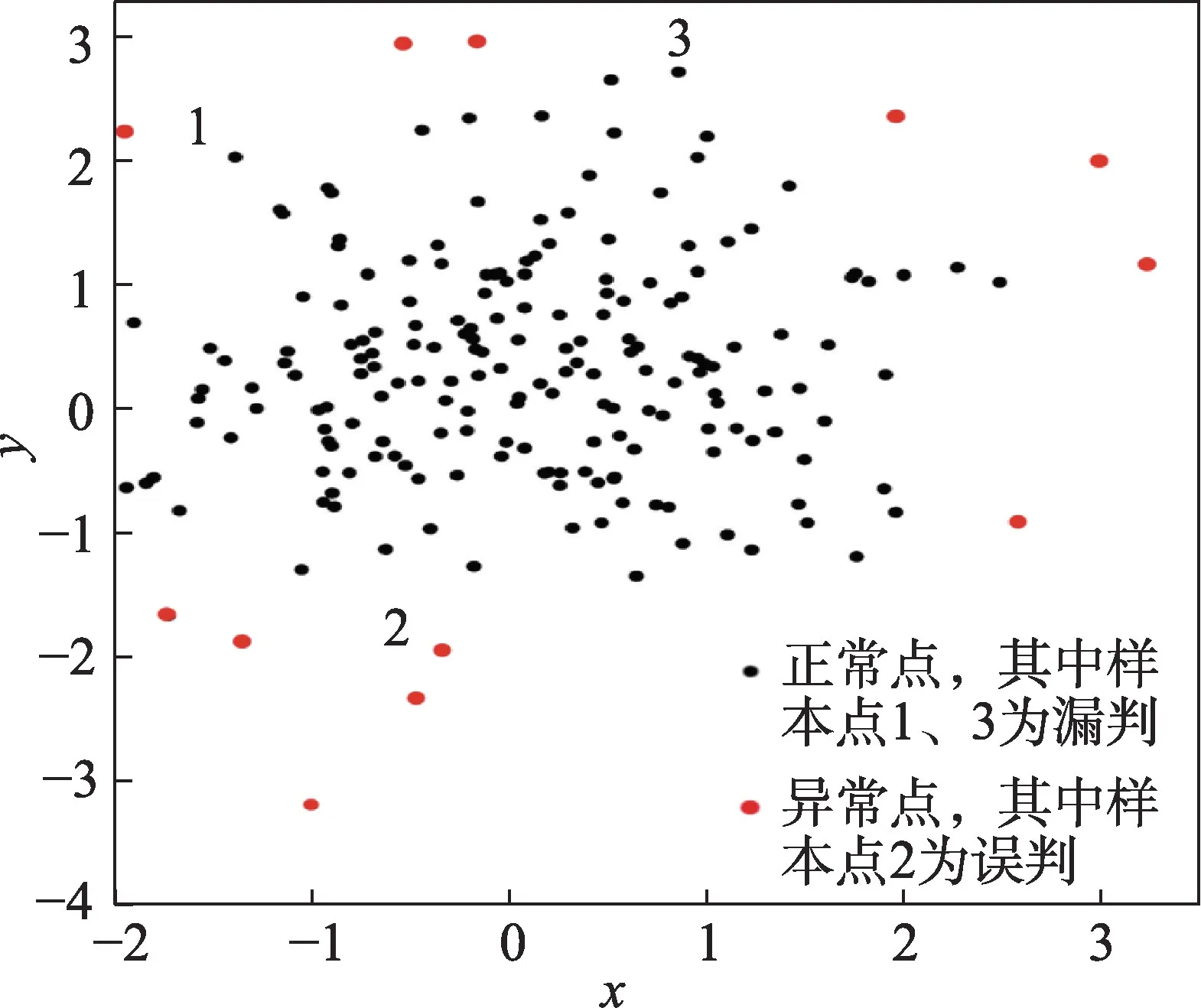
圖5 DAGMM 算法在健康數據上異常檢測結果Fig.5 Detection results by DAGMM on health data
對比圖4 和圖5 可以看出,兩種檢測方法對于比較明顯的異常樣本點都可以檢測出來,但是DAGMM算法在數據邊緣存在誤判和漏判現象。標號為1、3的樣本點為漏判,標號為2 的樣本點為誤判。而本文算法在檢測邊緣異常點時,僅3 樣本點進行了漏判,整體性能較好。
4 結論
針對運動手環采集的活動數據存在未知異常數據的問題,利用GMGM 用以進行異常檢測。在該模型中,使用生成模型中的樣本潛在分布和重構特征來訓練DBN,以估計各樣本的混合成員隸屬度;接著,利用GMM 預測各樣本的密度進行異常值的檢測。生成網絡與GMM 共同優化,避免了模型解耦的影響。在實驗部分,采用具有代表性的異常檢測數據集進行實驗,結果表明,該方法具有理想的檢測效果。最后,利用該方法在真實數據集上可視化異常檢測結果,結果表明漏報率和誤報率均低于DAGMM算法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
