基于多模態音視頻融合的質量評價算法
2022-05-24 10:11:56袁同慶
沈陽工業大學學報 2022年3期
袁同慶, 席 鵬
(1. 安徽師范大學 a. 智能教育研究院, b. 教育科學學院, 安徽 蕪湖 241000; 2. 中國科學技術大學 蘇州研究院, 江蘇 蘇州 215000)
目前,質量評價任務主要采用調查問卷的形式搜集評價目標相關的主觀評價資料,這種方式主要采用評價主體的主觀評價,不僅耗時、費力且采集的調查問卷不易保存,難以分析和利用[1-3].近年來,隨著互聯網技術和信息技術的快速發展,質量評價逐漸采用網絡形式展開,不僅可以搜集評價目標的主觀評價結果,而且評價主體可以提交充分的材料以佐證評價結果[4].采用信息化的質量評價與采集方式,可以及時、全面地采集評價主體對于評價目標的反饋情況[5-7].雖然這種方法簡化了傳統的質量評價采集方式,但仍需花費大量的人力資源和時間對這些評價進行分析與處理.為了提升質量評價的精度和速度,國內外學者提出了基于機器學習方法[8]、基于深度學習方法[9]和基于情感詞典方法[10-11]對評價主體的調查問卷進行分析.其中,基于情感詞典的方法通過構建包括形容詞、程度副詞和否定詞的情感詞典對評價文本進行分類;基于機器學習的方法采用傳統的機器學習技術來完成文本情感數據的分類;而基于深度學習的方法使用深度神經網絡從文本數據中提取特征,并進行情感分類[12-13].雖然這些方法使基于調查問卷的質量評價得到了顯著的提升,但若僅采用調查問卷數據進行質量評價仍顯說服力不足.
隨著多媒體技術的普及,在信息化評價過程中留下了大量的視頻和語音資料,如何充分挖掘這些多媒體數據中的有效信息成為了研究的熱點.本文充分利用多媒體資源,提出了一種基于多模態音視頻融合的客觀質量評價算法.該算法充分考慮評價目標的視頻、音頻和文本信息,并挖掘信息間的相關性進行評價與分類.
1 多模態特征提取
本文采用多模態數據進行客觀質量評價.為了實現多模態數據的統一輸入和處理,對不同的模態提取不同的特征,并根據其特點選擇相應的分類器進行預測分類.最后,對各模態的分類預測結果進行融合訓練,組成一個綜合分類器,從而得到質量分類結果.
1.1 文本特征提取
文本數據包含了對評價目標的直接評價,然而文本數據包含著復雜的語言種類和語法,使得對其分析與建模異常困難.為了有效提取出文本中包含的與評價目標相關的特征,本文首先使用Jieba分詞工具對輸入文本進行分詞,即將文本序列表示成詞向量集合;然后過濾掉與評價目標無關的停用詞,包括中英文標點符號、特殊字符、阿拉伯數字和一些影響較小的高頻詞匯;最后,使用Word2vec模型將詞向量表示為多維空間向量.
本文通過提取文本的互信息作為文本特征,互信息通過衡量事件發生所提供的信息量來衡量文本特征對于評價結果的影響[14].互信息計算表達式為
(1)
式中,X和Y分別為文本特征集合及類別集合.本文選取前K個互信息最大的特征作為輸入文本集合的特征.
1.2 語音特征提取
語音作為評價目標的一種信息媒介,不僅包含評價目標的內容,且包含事件發生時周圍環境.本文通過提取語音信息特征,從語音信號中獲取評價目標的相關信息.首先對語音信號進行預加重、分幀和加窗等處理,然后提取語音的梅爾頻譜倒譜系數(MFCC)特征.其中,預加重處理采用數字濾波的方法來提升語音信號的高頻衰減;分幀是將語音信號分割成較短的幀序列;加窗則是采集在增強采樣點附近的語音信號.MFCC特征是根據人類聽覺的臨界頻帶效應來模擬人耳對不同聲音的感知和響應,從而提取特征.具體的特征提取過程如下:
1) 使用快速傅里葉變換對N幀語音序列x[n](n=0,1,2,…,N-1)進行變換.
2) 將傅里葉變換后得到的頻率信號轉換為梅爾尺度Mel(f)=2 597lg(1+f/700).
3) 計算三角形濾波后的結果,即
F(l)=∑wl(k)|x[k]| (l=1,2,…,L)
(2)
式中:k為轉換后的頻率;
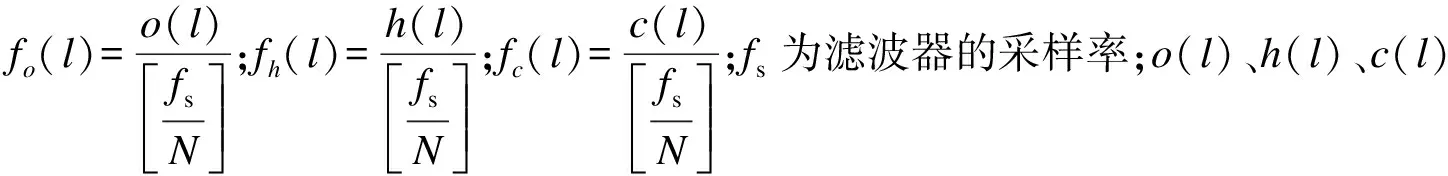
4) 對步驟3)中得到的結果進行對數運算和離散余弦運算,得到MFCC特征為
(3)
1.3 視頻特征提取
本文使用循環神經網絡提取視頻特征,該網絡采用CNN結構來提取輸入幀的表征特征,采用堆疊的RNN單元來捕捉時序信息.提取單元結構如圖1所示,R為ReLU(Conv())函數,用來提取輸入幀的表征,T為Sigmoid(Conv())函數,用來提取時序信息,oi,t為網絡輸出,ci,t表示第t幀在第i個循環單元的記憶狀態.
本文采用堆疊的循環特征提取單元來提取輸入視頻的深度特征.由于深度網絡在建模長序列時容易出現梯度消失的問題,本文使用跳躍連接來加深網絡.為了訓練該網絡以提取評價目標相關的特征,本文直接使用BP算法對輸出特征進行分類訓練,通過最小化網絡輸出與評價標簽之間的交叉熵損失來完成迭代優化.
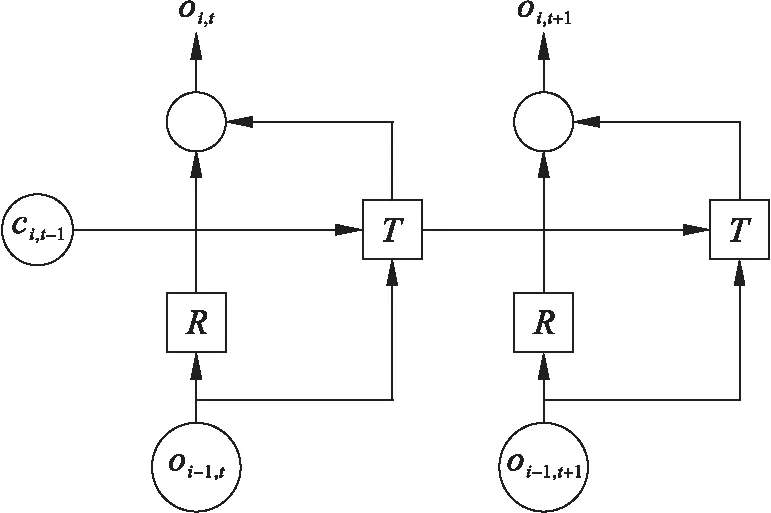
圖1 循環特征提取單元Fig.1 Recurrent feature extraction unit
2 基于Stacking算法的客觀評價分類
由于評價數據中存在大量的與客觀質量評價無關的數據,需要對這些數據進行篩選和過濾,以此實現客觀評價質量的分類.本文使用了Stacking算法構建客觀質量分類模型來融合不同數據間的特點.算法分別對視頻、語音和文本所提出的特征構建預測分類模型,然后使用一個元分類器對其分類結果進行融合,并得到最終的課程評價結果.相比于其他集成學習方法,該算法適用于異構數據和異質分類器,且最終的分類結果采用更復雜的元分類器,而并非傳統集成學習方法所采用的平均法或基于投票的方法.本文使用樸素貝葉斯算法(NB)對文本特征進行分類,使用支持向量機算法(SVM)對語音特征進行分類,使用BP算法對視頻特征進行分類,而元分類器則采用SVM分類器.文中各分類器將輸入數據分類為正向情感、負面情感和無關三類,其中無關類即為不包含任何情感傾向.
文中提出的算法主要包含兩層學習:多模態初始學習器和元學習器,其中多模態初始學習器采用K折交叉驗證的方式進行訓練,在訓練預測器的同時生成訓練元數據所需的數據;在得到這些數據后,訓練元學習器實現多模態數據的融合和評價質量的預測.元學習器的輸入為基學習器的輸出,而不同模態的數據具有不同的特點,故本文為每個初始學習器賦予了一個權重.

基于該權值計算方式,本文基于Stacking算法構建的質量分類模型的訓練步驟如下:
1) 定義訓練數據集D={(x1,y1),(x2,y2),…,(xK,yK)}=(X,Y),初始學習器M1,M1,…,MZ;
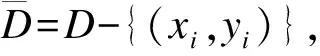
3) 對于每個分類器計算其權重.根據各初始分類器的預測結果對訓練數據進行篩選,刪除與質量預測無關的數據.
4) 使用上述步驟得到的初始分類器,針對各訓練數據的預測結果和各分類器的權重來訓練元分類器.
3 實驗與分析
本文以質量評估為例進行仿真試驗與分析.為了對模型進行訓練和測試評估,本文搜集了某高校20門公共課程的多媒體數據,包括教學視頻、語音和文本評價,共采集了包括30名學生對于各門課程的評價結果.其中約有20 TB視頻數據,10 GB語音數據和5 GB文本數據,每一門課程對應的視頻、語音和文本的比例大約為1∶12∶60.通過統計各課程的評價結果,并將其作為標簽進行模型訓練評估.隨機選取該數據集中15門課程的數據作為訓練集,使用剩下的5門課程數據作為測試集進行仿真分析.本文實驗平臺為Intel Xeon CPU E5-2430,使用Ubuntu操作系統,并采用Python實現所提出的分類算法.文中使用預測準確率和預測結果的F1值作為算法性能的評價指標,F1計算方式為
(4)
(5)
(6)
式中:TP為正確分類的正類;FP為錯誤分類的正類;FN為錯誤分類的負類.本文將每條評價對應的類別作為正類,將其他類別作為負類.
首先驗證了各個基礎分類器的分類準確率與F1值,結果如表1所示.其中樸素貝葉斯算法采用多項式樸素貝葉斯算法,其平滑參數設置為1.支持向量機算法采用徑向基核函數,核帶寬設置為0.5,懲罰因子設置為1.BP算法采用3層神經網絡設計,其輸入神經元數量為100,輸出神經元預測類別數量為3,包括正向評價、中性評價和負面評價.從表1結果可以看出,使用文本評價數據可以得到最高的分類精度,而使用視頻和語音得到的評估精度相對較低.綜合各初始分類器的預測結果后,可以得到精度更高的質量評價結果.由此表明,融合多模態數據可以提升質量評價的精度.

表1 各類預測結果的準確率和F1值Tab.1 Accuracy and F1 values of various prediction results
為了驗證所提出自適應加權算法的有效性,對加權前后模型的分類精度進行測試,結果如圖2所示.從圖2中可以看出,采用加權算法不僅可以提升元分類器的性能,還可提升各初始分類器的性能,表明所提出的分類器加權方法能夠明顯提升預測精度.

圖2 加權前后分類精度比較Fig.2 Comparison of classification accuracy before and after weighting
本文對于不同數據采用了不同的分類器,并使用元分類器集成所有分類器的預測結果.為了驗證該多樣性集成方法的有效性,將所提出的方法與僅采用單一分類器的方法進行比較,結果如圖3所示.從圖3中可以看出,所提出的多樣性集成方法具有最優的分類精度,且相對于僅使用單一分類器的方法有明顯提升.根據不同數據的特點,選擇不同的分類器將有助于提升質量評價的精度.
為了比較本文與傳統算法性能間的差異,使用提出的數據集進行了驗證實驗,結果如表2所示.其中,文獻[4]采用純調查問卷的方式進行質量評價;文獻[7]只使用文本特征提取的方法進行評價.從表2中可以看出,相比于傳統的算法,本算法具有明顯的性能優勢.其中,文獻[7]方法所使用的特征比較單一,而本文算法融合多模態的特征進行評價,說明使用多模態特征可以明顯增強評價的精度.

圖3 集成模型與初始分類器比較Fig.3 Comparison of ensemble model and initial classifier

表2 不同方法的性能比較Tab.2 Performance comparison of different methods
4 結 論
本文提出了一種基于多模態音視頻融合的質量評價算法,該算法根據客觀質量評價過程中產生的視頻、音頻和文本等多媒體數據對相關的具體情況進行分類.通過對不同模態數據提取不同的特征,并使用Stacking算法挖掘不同特征間的關聯關系,從而預估出評價結果.以質量評價為例,搜集和整理了質量評價數據集,在該數據集上的測試結果表明,本文所提出的方法能有效提升評價精度.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
