基于空間信息的泛洪算法在行人重識別系統中的應用研究
2022-05-25 04:48:00李御瑾張雅麗葛馨陽趙佳鑫施新凱
現代計算機 2022年6期
關鍵詞:實驗
李御瑾,張雅麗,葛馨陽,趙佳鑫,施新凱
(中國人民公安大學信息網絡安全學院,北京 100038)
0 引言
利用視頻監控拍攝的畫面判斷出現在不同監控中的行人是否是同一個行人并生成其軌跡的技術已經廣泛應用于智能視頻監控、安保、刑偵等領域。這種運用計算機視覺和機器學習等方法判斷監控視頻中的特定行人是否出現在其他監控視頻中的技術稱為行人重識別(person Re-identification,Re-ID)。有學者將行人重識別系統劃分為行人檢測和行人重識別兩部分,行人檢測主要應用深度學習的方法對原始圖像數據進行訓練學習并提取出更有效的特征,基于深度學習的行人檢測系統具備極高的魯棒性和準確率。隨著較大規模數據集的出現,深度學習在行人重識別領域的應用研究逐年遞增。基于大規模數據集與深度學習的行人重識別方法根據任務不同分為兩類,一類是基于圖像,一類是基于視頻序列。不管是基于圖像還是基于視頻序列,行人重識別的主要任務都是特征提取和相似度度量兩個步驟。
在行人重識別系統的應用中,原始視頻幀經過行人檢測并提取特征之后與對應幀重新存入特征庫。傳統的行人重識別系統,其前端攝像頭僅能夠采集數據并不具備前置的計算處理功能,需要將數據回傳至數據中心進行處理。隨著邊緣計算在行人重識別系統中的應用,系統逐漸從前端采集、后端分析的模式轉變為前端智能化、前后端協同計算和軟硬件一體化的新模式。
按照功能來說,行人重識別系統在特征提取與相似度度量之間應該還有一個階段,即確定度量對象。如圖1所示,文獻[3]提供的行人重識別系統框架中,在特征提取與相似度度量之間加入“確定度量對象”階段。該階段的主要任務是從特征庫的指定度量范圍中檢索出進行相似度度量的對象,進行相似度度量的次數與總耗時和所占用算力都成正比關系,因此,縮小檢索范圍可有效減少度量次數和度量耗時,節約算力。目前主流的行人重識別系統,在提取到待度量目標的特征后,通過遍歷度量的方式或按照時間劃分檢索范圍來在特征庫中進行相似度度量。城市部署的攝像機數量將會越來越多,盡管單個視頻所提取的目標特征信息所占空間不大,但是一個城市每天產生的視頻監控數據量將只增不減,根據視頻數據所提取的特征庫也將隨之增大,因此,不論是遍歷檢索還是按照時間劃分度量范圍對于行人重識別系統而言都將是一項高耗時、高占用的任務。為了提高度量效率,本文在已有的研究基礎上提出一種基于泛洪算法并結合空間信息的檢索度量方式,在前端采集數據時通過內嵌全球定位系統(global positioning system,GPS)芯片提供空間信息并回傳,在后端將前端所提取的特征與其回傳的空間信息進行關聯并建立空間信息數據庫。應用泛洪算法在進行度量時縮小度量范圍,在不損失度量的準確度和完整度的前提下達到提高度量效率的目的,且能有效利用特征所關聯的空間信息進行軌跡分析,整體提高行人重識別系統的應用效果。
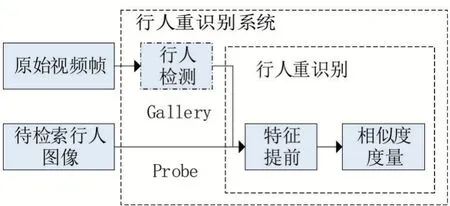
圖1 行人重識別系統
1 基于空間信息的泛洪度量算法
泛洪算法(flooding)在計算機網絡領域中是一種路由算法,簡單來說是設備群中交換信息的一種協議。分為不受控泛洪與受控泛洪兩種。在不受控制的泛洪中,每個節點無條件地將數據包分發給它的每個鄰居。如果沒有條件邏輯來控制就會產生廣播風暴(當廣播數據充斥網絡無法處理,并占用大量網絡帶寬,導致正常業務不能運行,甚至徹底癱瘓即為“廣播風暴”)。在受控泛洪中有兩種算法來避免廣播風暴,分別是序列號受控泛洪(sequence number controlled flooding,SNCF)和反向路徑轉發(reverse path forwarding,RPF)。在SNCF中,節點將自己的地址和序列號附加到數據包中,每個節點都有地址和序列號的存儲器。如果它在內存中收到一個數據包,它會立即丟棄它,而在RPF中,節點只會轉發數據包。如果它是從下一個節點收到的,它將發送回發送者。
本文應用泛洪算法的受控泛洪原理,在特征庫檢索中改進該算法,算法主要目的是改進并縮小度量范圍。目前主流的行人重識別系統在提取到待度量目標的特征后通過遍歷度量的方式或按照時間劃分度量范圍來在特征庫中選取對象進行相似度度量,目標的軌跡在時空上具有一定的相關性,即當目標被一臺攝像機拍攝到以后,該目標被另一臺攝像機再次拍攝到的可能性與兩臺攝像機的間距以及兩次拍攝時間間隔均成反比,簡單來說就是當一臺攝像機拍攝到一個目標之后,與該臺攝像機相距最近的幾臺攝像機在較小的時間間隔內再次拍攝到目標的可能性最大。然而,遍歷度量或根據時間劃分度量范圍并沒有較好地利用目標軌跡的時空相關性,沒有優先選擇可能性較大的攝像機提取的特征進行度量,而是對所有攝像機或者指定時間段內攝像機提取的特征進行度量。算法實現方法是充分利用目標軌跡的時空相關性,將度量范圍以空間距離和時間間隔進行優先級劃分,逐級進行相似度度量。將高優先級的度量范圍定義為源點度量,低優先級的度量范圍定義為節點度量。算法流程如圖2所示,圖中左邊部分為源點度量,右邊部分為節點度量。是源點列表信號量,當為0時源點列表為空,當為1時源點列表不為空。是節點列表信號量,當為0時,節點列表為空,反之亦然。首先將和置為零,分別依次執行源點度量和節點度量,然后檢測源點列表和節點列表,如果為空,則返回0。如此循環,直到源點列表和節點列表都為空,和都為0的時候代表度量完成。
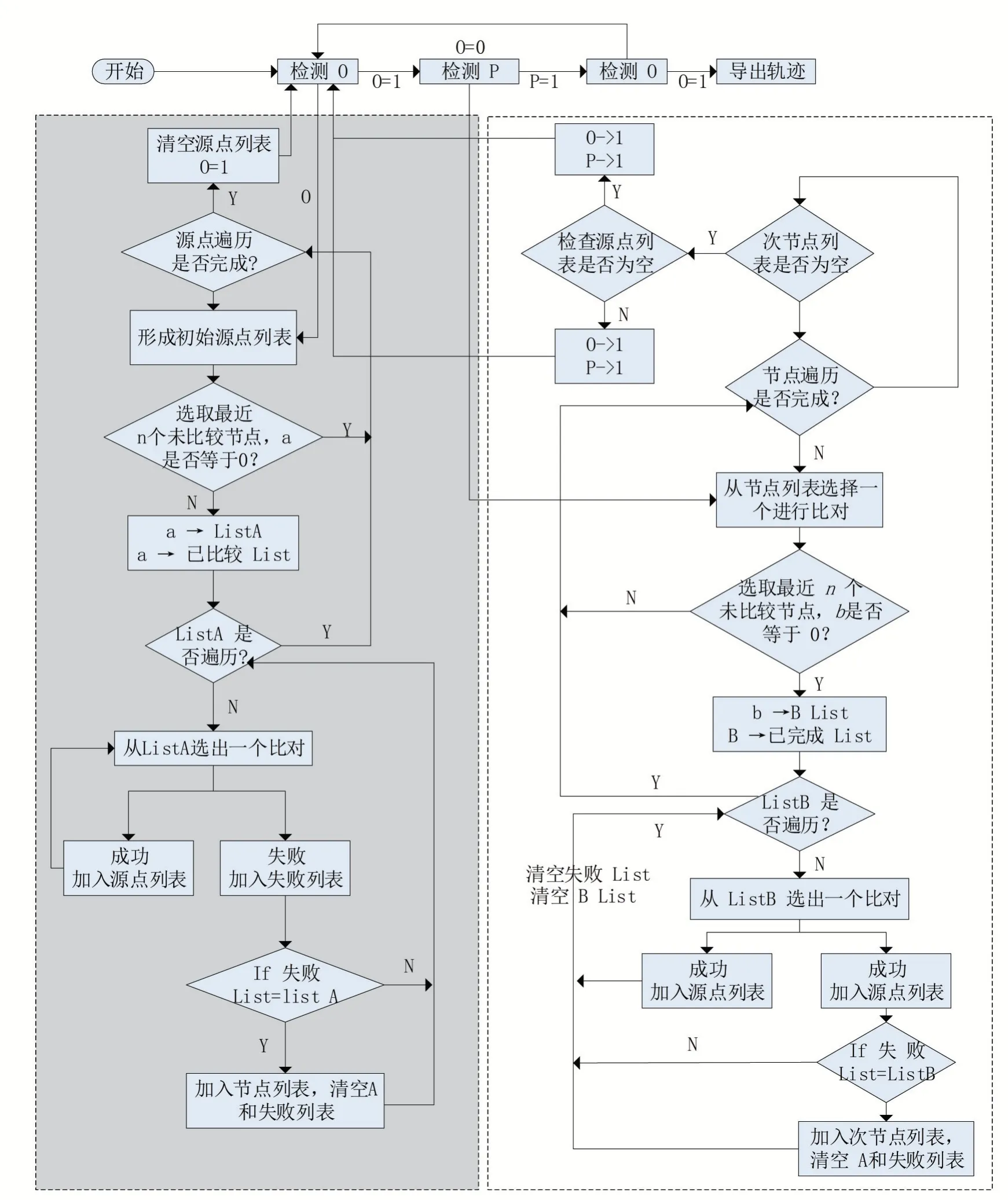
圖2 算法流程圖
由于需要搭建空間信息數據庫,因此本文采用mysql進行數據存儲。在mysql中建立名為camerafile的數據庫,在庫中分別建立兩張表,一張表是設備檔案表(命名為cameraid),另一張是設備距離表(命名為distance_table)。設備檔案表中的字段為“Lon”,“Lat”,分別為該設備的經緯度。然后分別對每臺設備兩兩之間計算直線距離,根據結果建立設備距離表。設備距離表中字段為“Orig”、“Dest”和“distance”,“Orig”為源點的設備編號,“Dest”為目標設備的編號,“distance”為兩點之間的直線距離。搭建空間信息數據庫的前提是獲取攝像機的經緯信息以及物理地址信息,兩兩分別計算直線距離據此建立距離表。定義為與源點攝像機相聚最近的攝像機臺數,定義為總度量范圍。
在創建空間信息數據庫時需提前建立設備檔案表以及設備距離表,在輸入待度量目標并獲取采集該圖片的設備編號后,通過泛洪算法(如圖3所示)從數據庫中的設備距離表中提取出指定范圍內的最近個其他設備編號,并設置總度量半徑以在這些設備采集的視頻數據中進行相似度度量,與兩個參數可根據實際情況進行設定。泛洪度量分為源點度量與節點度量。如果在該范圍內出現高于閾值的結果則將該節點加入到源點列表,如果沒有則加入節點列表,待源點度量結束后再進行節點度量。
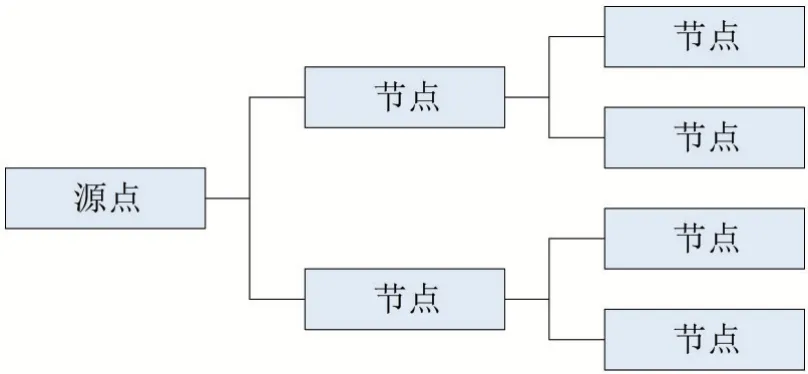
圖3 泛洪算法示意圖
1.1 源點度量
從源點列表中順序選出一個源點,根據設備距離表計算出與源點相距最近的個節點,然后進行特征相似度計算。如果有節點高于閾值,則將該節點加入到源點列表中,如果個節點都沒有高于閾值的節點,則將源點加入到節點列表中,然后從源點列表中順序選出下一個源點,直到源點列表遍歷完,源點度量結束,源點度量示意圖如圖4所示。
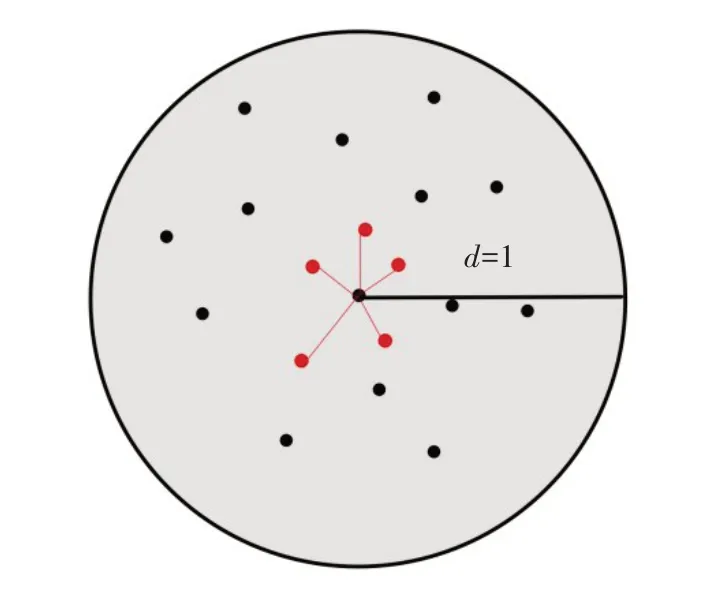
圖4 源點、節點度量示意圖
1.2 節點度量
從節點列表中順序選出一個節點,然后計算出與該節點相距最近的個節點并依次進行度量,如果有節點度量成功則將該節點加入源點列表,否則將節點加入次節點列表,然后從節點列表中選出下一個節點,如圖5所示。進行完節點度量之后,所有節點被分別加入源點列表和次節點列表。如果次節點列表不為空,則將次節點列表賦值給節點列表重新進行節點度量。直到節點列表遍歷完,節點度量結束。此時,分別檢測源點列表與節點列表,直到源點列表與節點列表均為空,即在指定區域內無法再計算得出新的節點。
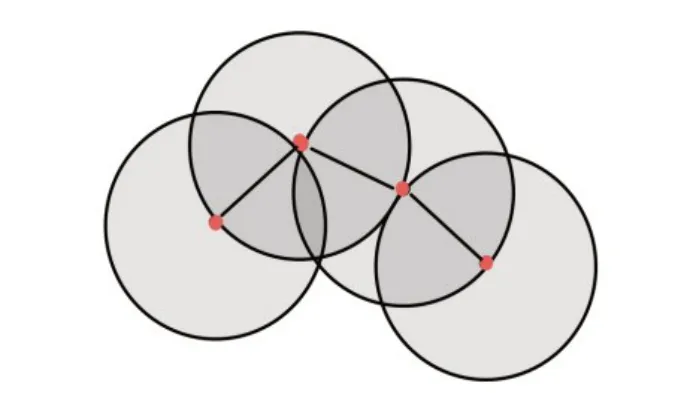
圖5 節點度量示意圖
泛洪算法是根據源點最近的點位進行度量,單次最大攝像頭數量越多,則單次搜索半徑越大,總搜索時間增加。總搜索半徑是預先設置的總搜索區域,算法中體現為以初始源點為圓心的總搜索半徑,凡是超過該搜索范圍的其他節點均不會被度量。
2 實驗及結果分析
本文在行人檢測部分使用的是YOLOv3目標檢測算法,并且使用YOLO416 COCO權重。在行人重識別部分是在Bag of Tricks and A Strong ReID Baseline的開源代碼基礎上進行改進。訓練部分將MSMT17數據集、Market1501數據集和CUHK03數據集進行了聯合訓練,然后在沒有進行訓練的DukeMTMC27數據集進行測試,測試效果滿足使用需求。本文實驗共設置兩組實驗模型,一組使用空間信息并結合泛洪算法進行度量,另一組使用遍歷算度量方式。
2.1 實驗數據
2.1.1 空間信息數據
本文所提出的方法主要應用于縮小度量范圍,對于監控設備數據要求的經緯度。由于目前還未大規模部署內嵌GPS芯片的網絡攝像機,因此從無錫市城市管理局發布的《無錫市城市管理視頻監控系統點位調整信息公示》中獲取到無錫市部分監控點位的物理位置和經緯度原始數據,處理后得到圖6。
圖6 部分監控點位原始數據
空間信息數據庫創建兩張表,一張表是采集設備檔案表,另一張是設備距離表。由于從無錫市城市管理局所收集到的監控點位信息并沒有對攝像機進行編號,因此將每一臺設備進行編號,并輸入其物理位置與經緯度信息。然后對每一臺采集設備建立設備檔案表并存入mysql數據庫中,如圖7(a)所示;對每臺設備兩兩之間根據經緯度計算直線距離,根據結果依次建立設備距離表,如圖7(b)所示。
圖7 設備檔案表與設備距離表
2.1.2 視頻圖像數據
視頻數據使用在校園錄制的模擬街道監控視頻,錄制設備為索尼HDR-CX405,隨機選取校園道路五個位置架設高約3 m的三腳架進行錄制,共計403段,平均每段有5 s,由151幀構成,行人監控截圖如圖8所示。本文分別將某臺設備所采集的視頻放置在該設備編號命名的文件夾中,其中視頻的命名格式為(攝像機編號_視頻編號),監控點位共有311個,隨機從403段中抽取10段依次放置于編號文件夾中,相當于總視頻庫中共有3110個監控視頻。

圖8 行人監控示意圖
2.2 評價指標
為了驗證算法對特征庫進行泛洪度量的有效性,本文設置了四個評價指標,分別是度量次數、度量準確度、度量完整度以及度量時間。度量次數越少對計算機的算力占用越低,在度量準確度相同的情況下度量時間越短則度量效率越高。度量準確度與度量完整度的定義如下:
度量準確度=度量到的相關視頻數/總度量視頻數
度量完整度=度量到的相關視頻數/庫中實際相關視頻數
2.3 實驗環境及參數設置
2.3.1 實驗環境
本實驗的操作系統為Microsoft Windows 10(64位),CPU型號為(英特爾)Intel(R)Core(TM)i7-10750H CPU@2.60GHz(2592 MHz),本實驗使用一塊NVIDIA GeForce RTX 2060(6144 MB)顯卡,使用pytorch 1.7.1以及tensorflow-gpu 2.1.0作為深度學習框架,依賴Python 3.7.1環境完成編程。
2.3.2 參數設置
實驗中先將一組節點設置為目標軌跡路線,然后分別調用泛洪度量與遍歷度量從起始節點的視頻監控開始度量,并將度量結果與設置的目標軌跡路線進行比較。本次實驗將待度量目標設置為身穿深藍色短袖和黑色長褲的行人,如圖9中(a)所示。

圖9 目標與度量成功示意圖
2.4 實驗結果與實驗分析
為驗證泛洪算法的有效性,本文設置三個對照試驗,共計十五組。在泛洪算法中需設置單節點最大攝像機數和最大度量半徑,最大攝像機數以及最大度量半徑的取值取決于監控點位的密集程度,在監控點位密集區域最大攝像機數和單節點最大搜索半徑應設置較小,單次度量總量小能夠提高度量速度,而在監控點位稀疏的地區二者均可以設置較大半徑,增加單次度量數量以提高度量效率。如果度量成功則會標記目標并輸出該節點視頻,如圖9中(b)所示。
實驗對象:第一組至第五組
不變量:軌跡節點(節點間距均小于1 km)、泛洪算法參數設置(最大攝像機數設置為5(=5),單節點最大搜索半徑設置為1 km(=1))
變量:分別使用泛洪算法與遍歷算法
實驗目的:驗證泛洪算法的有效性
實驗結果見表1
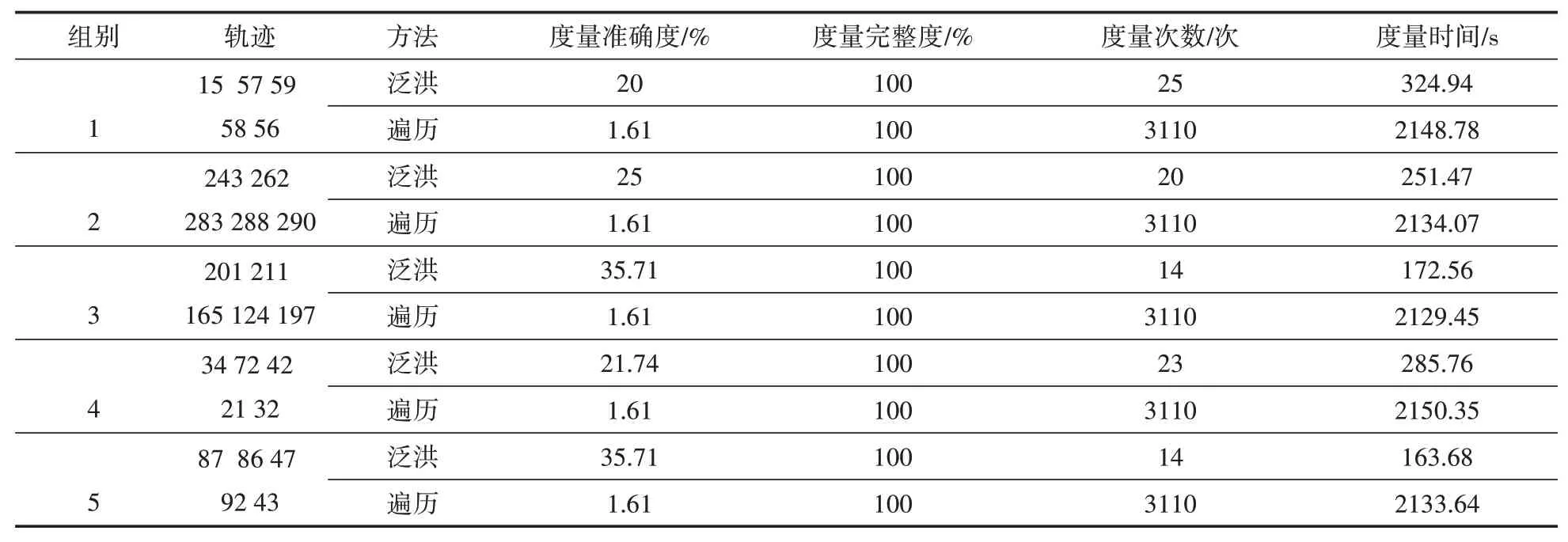
表1 實驗一結果
實驗分析:在該五組實驗中,軌跡節點平均間距在1 km以內。對于視頻圖像庫而言度量時間主要取決于度量次數。遍歷度量的范圍始終為全庫共計3110段視頻,因此其度量次數、度量時間、度量準確度與度量完整度都不變,采用泛洪算法之后視頻的平均度量次數會減少,如圖10所示,度量出相似視頻圖像的時間大幅縮短,如圖11所示。在度量完整度相同的情況下,泛洪算法結果,平均準確度為27.63%,平均度量次數為19.2次,平均度量時間為239.68 s,而遍歷算法結果的平均準確度為1.61%,平均度量次數為3110次,平均度量時間為2139.26 s。
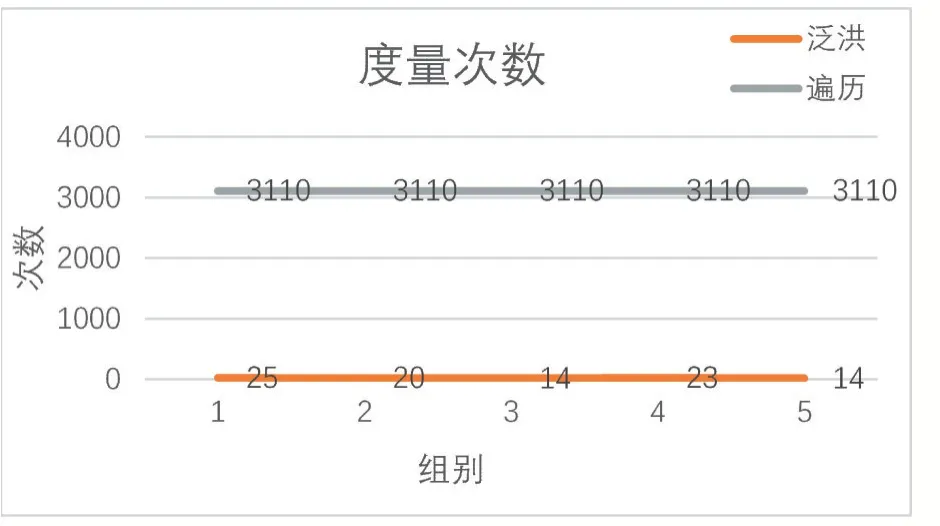
圖10 實驗一度量次數
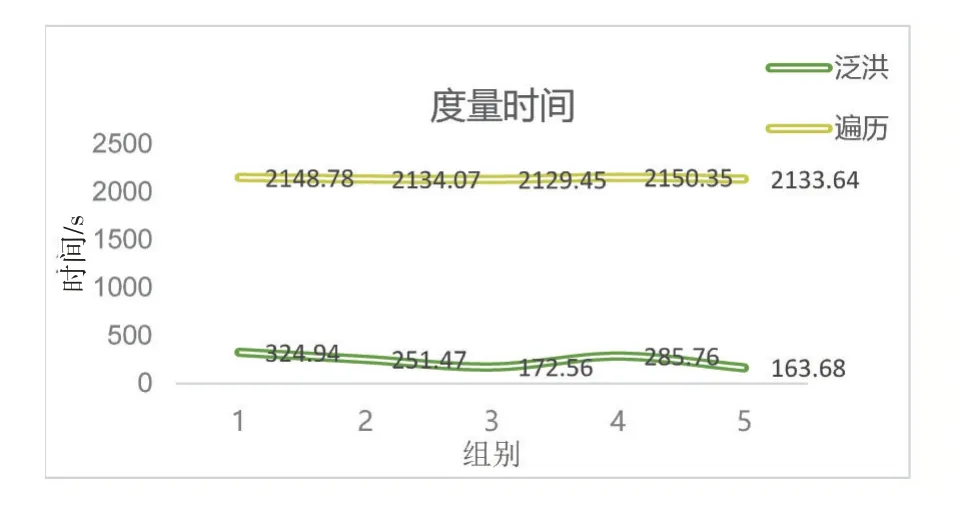
圖11 實驗一度量時間
實驗結論:當軌跡節點平均間距在1 km以內時,在完整度相同的前提下,泛洪算法的準確度、度量次數和時間均優于遍歷算法。
實驗對象:第一組至第十組
不變量:前五組沿用第一組實驗結果,泛洪算法參數設置(最大攝像機數設置為5(=5),單節點最大搜索半徑設置為1 km(=1))
變量:第一組至第五組的平均間距較小(在1 km左右)、第六組至第十組平均間距較大(在1 km以上)
實驗目的:分析節點平均間距對泛洪算法的影響
實驗結果見表2。
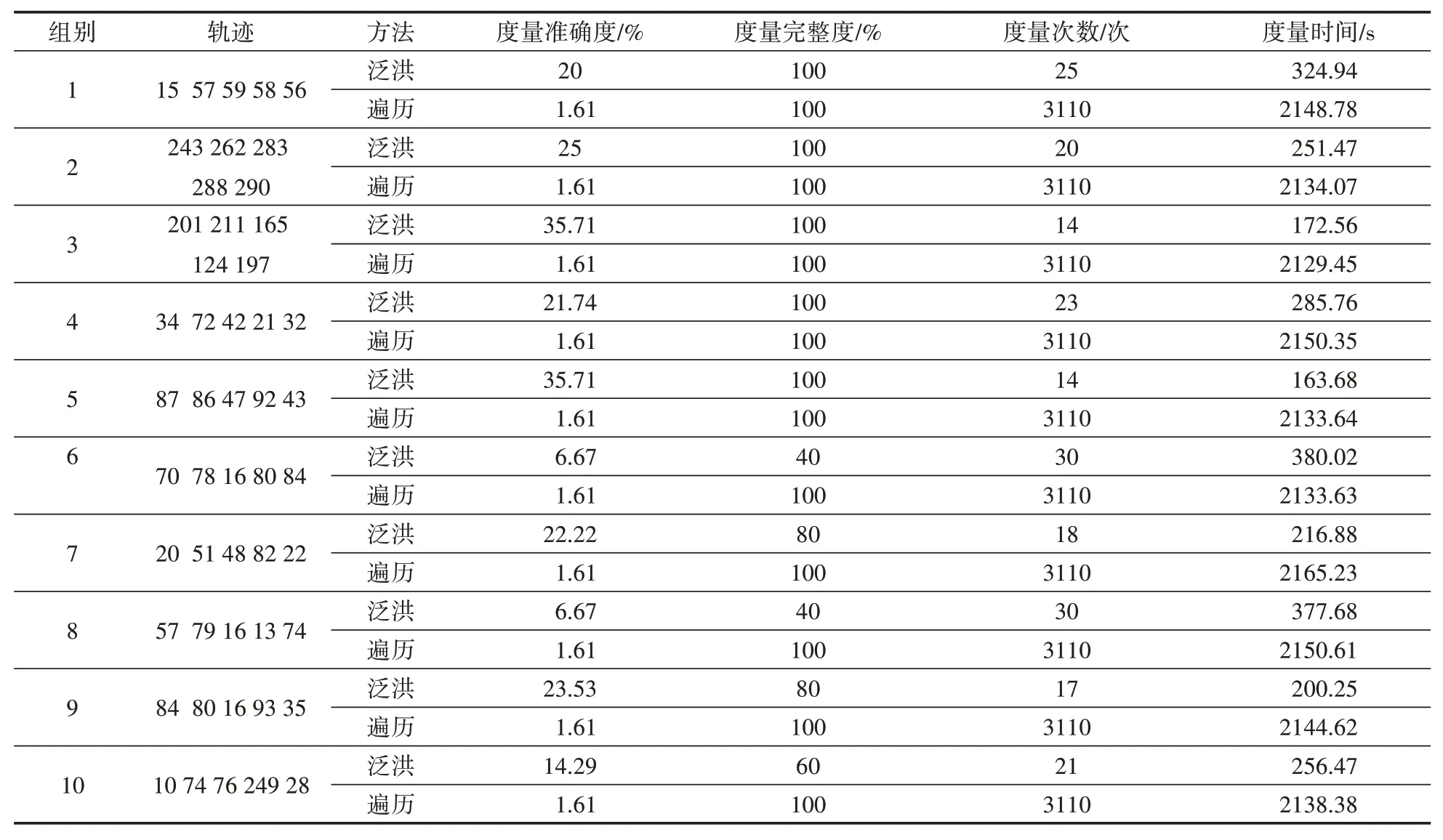
表2 實驗二結果
實驗分析:在前五組實驗中,軌跡節點平均間距在1 km以內;后五組中平均間距大于1 km。十組實驗中泛洪算法的參數設置都相同(即最大攝像機數和單節點最大度量半徑都相同),當節點平均間距增大之后,對于未改變參數設置的泛洪算法,其度量準確度與完整度均有所下降,如圖12所示。前五組泛洪算法結果:平均準確度為27.63%,平均度量次數為19.2次,平均度量時間為239.68 s,后五組結果平均為度量完整度為60%,度量準確度為14.68%,度量次數為23次,度量時間為286.26 s;前五組遍歷算法結果為平均準確度為1.61%,平均度量次數為3110次,平均度量時間為2139.26 s,后五組遍歷算法結果為平均準確度為1.61%,平均度量次數為3110次,平均度量時間為2146.50 s。
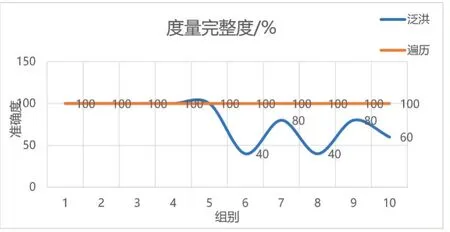
圖12 實驗二度量完整度
實驗結論:在泛洪算法的參數設置為(最大攝像機數設置為5(=5),單節點最大搜索半徑設置為1 km(=1)),當軌跡節點平均間距大于1 km之后,泛洪算法的準確度、完整度明顯降低,度量時間與度量次數均明顯增加,可見平均節點間距對泛洪算法有直接影響,對遍歷算法無較大影響。
實驗對象:第六組至第十五組
不變量:第六組至第十組沿用實驗二結果,軌跡節點均相同
變量:第六組至第十組泛洪算法設置參數為最大攝像機數設置為5(=5),單節點最大搜索半徑設置為1 km(=1);第十一組至第十五組設置參數為最大攝像機數設置為5(=5),單節點最大搜索半徑設置為2 km(=2)
實驗目的:分析泛洪算法中單節點最大搜索半徑對算法影響
實驗結果見表3。
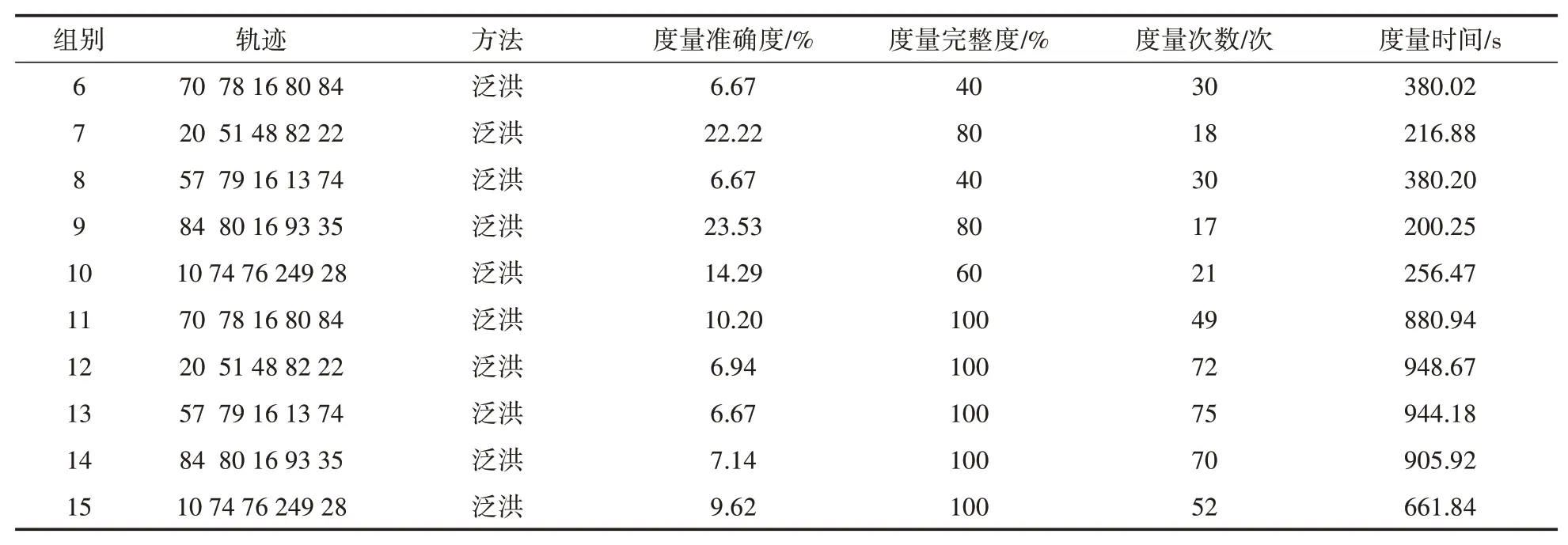
表3 實驗三結果
實驗分析:十組實驗的軌跡節點都相同,平均間距在1 km以上,前五組的單節點最大搜索半徑為1 km(=1),后五組單節點最大搜索半徑為2 km(=2)。通過增大泛洪算法單節點最大搜索半徑,能夠有效地提高泛洪算法的度量完整度,如圖13所示。
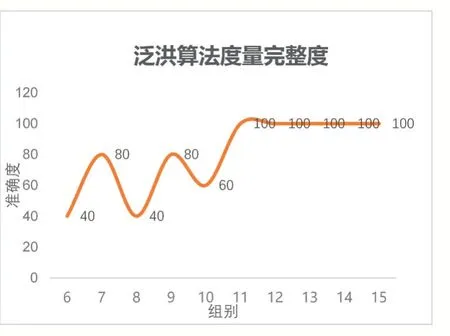
圖13 實驗三泛洪算法度量完整度
前五組泛洪算法的結果平均為度量完整度為60%,度量準確度為14.68%,度量次數為23次,度量時間為286.26 s,后五組結果平均為度量完整度為100%,度量準確度為8.11%,度量次數為64次,度量時間為868.31 s。
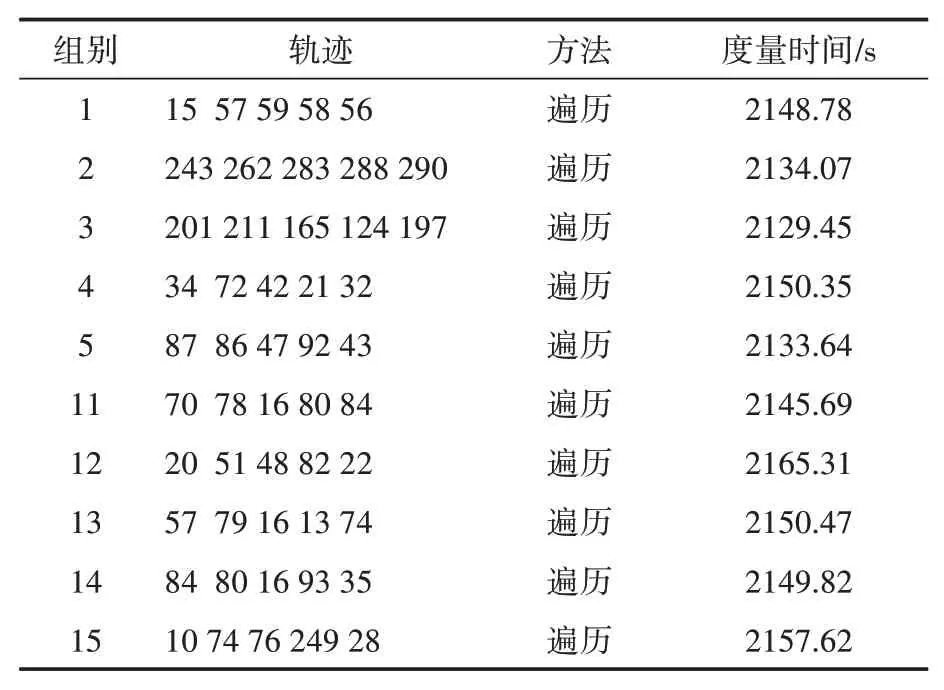
表4 遍歷算法度量時間
實驗結論:軌跡節點平均間距大于1 km之后,通過調節泛洪算法的單節點最大搜索范圍能夠提高完整度,但準確度會降低,度量次數和度量時間增加。在相同度量完整度的情況下,通過對比調節參數前后的度量時間,可以得出雖然增大了單節點最大搜索半徑會增加度量時間,但為了獲得較高的度量完整度,度量盡量多的目標,增加的度量時間仍遠遠少于遍歷度量的時間,如圖14所示。
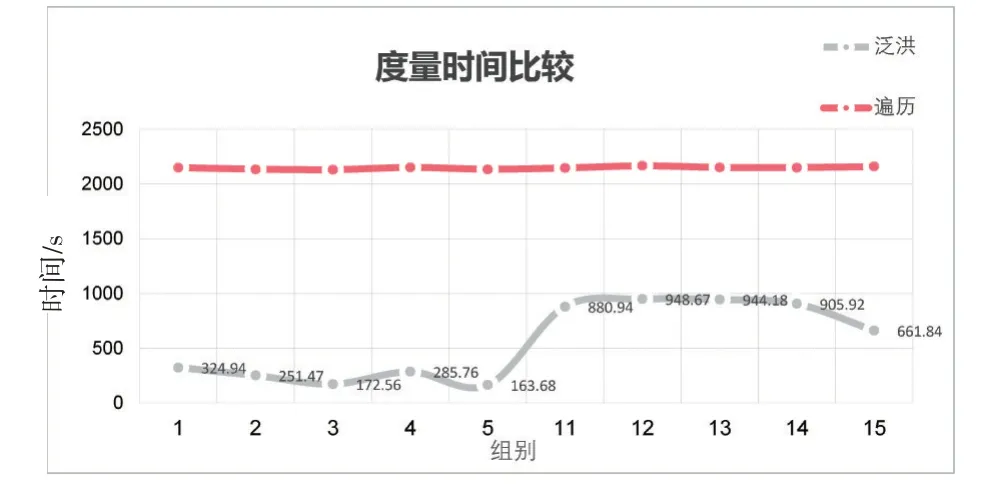
圖14 實驗三度量時間比較
3 結語
本文提出一種結合空間信息并以泛洪算法為基礎的改進度量方法。該方法將空間信息與特征建立關聯,在行人重識別系統進行相似度度量時,有效利用目標軌跡的時空相關性并根據特征關聯的空間信息來縮小度量范圍,快速度量目標特征。實驗結果表明,在度量出所有目標特征的情況下泛洪算法的度量時間與度量次數均優于遍歷算法;而在犧牲度量完整度的情況下,泛洪算法能夠更快速地度量出目標特征。如果增加單點最大度量范圍,則會增加度量次數與時間,但能夠提高泛洪算法的度量完整度。結合空間信息的泛洪算法在行人重識別系統中的應用能夠協助民警在公安工作中迅速檢索度量出目標并得出其軌跡路線。此外,對于任何在原始數據中能夠提供空間信息的數據均能夠使用本方法進行快速度量,例如在全球新冠病毒肆虐的背景下,使用本方法能夠迅速度量目標,對于快速進行精準高效的流調工作、及時排查風險、消除隱患具有重要意義。
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
