基于情感分析和隨機森林的中國電視劇產業研究
2022-05-25 04:48:02李坤琪李曉峰宋卓遠楊秀璋羅子江
現代計算機 2022年6期
李坤琪,李曉峰,袁 杰,楊 鑫,趙 凱,宋卓遠,楊秀璋,羅子江
(貴州財經大學信息學院,貴陽 550025)
0 引言
隨著人們物質生活質量的提高,大眾精神文化上的需求也在日益增加,觀看電視劇已成為人們日常生活中一種不可或缺的娛樂休閑方式。近年來,中國電視劇產業發展良好,電視劇收視比重由2017年的30.9%提升至2018年的32%;2018年中國網絡視頻用戶規模達6.12億,較上一年增長5.8%。同時,隨著互聯網技術的迅猛發展,人們更愿意從網絡渠道搜尋優質電視劇,并在觀看后參與對其的評論和打分,進而表達自己的態度和情感。在這些電視劇數據中蘊藏著影響制片方決策和用戶觀看的價值信息,因此,對電視劇的相關信息進行有效挖掘十分必要。
然而,國內外對電視劇等影視作品進行數據挖掘等深層次的研究相對較少,如王曉東等基于文獻資料和對比研究的方法,對中國電視劇市場的現狀進行研究,并針對存在的問題提出對策和建議。Pang等首次通過機器學習實現對電影評論的情感分類,并證明SVM模型的分類效果最佳。但這些研究方法較為單一,難以發現數據中更多的潛在規律,并且沒有將用戶情緒進行多維度的細致甄別和應用。
針對以上問題,本文提出一種基于情感分析和隨機森林的研究方法,并結合共詞和可視化技術對中、韓、美、英、日5國的電視劇數據進行詳盡分析。通過構建電視劇領域情感詞典,實現從劇評中有效提取觀眾的情緒訴求和分布狀態;借助共詞分析來計算各演員間的合作關聯度,明確不同演員陣營;利用隨機森林分類算法預測電視劇口碑好壞,進而實現優質電視劇的智能推薦。
1 中國電視劇產業相關研究進展
電視劇作為一種文化產品,早已緊密融入到人們的生活中,并發揮著寓教于樂、以文化人的作用。目前,在互聯網的推動下,電視劇的傳播和收看方式均發生改變,網絡劇逐漸被大眾所青睞。據藝恩咨詢數據顯示,2018年上線網絡劇286部,較2017年的225部增加了27%,播放量呈現增長態勢。2016年6月國家廣電總局發布《關于進一步加快廣播電視媒體與新興媒體融合發展的意見》,提出加強網絡劇的創作。網絡劇的崛起拓寬了市場需求,并為電視劇產業注入新鮮力量。
與此同時,隨著云計算、互聯網的蓬勃發展,網絡數據呈爆炸式增長,大數據及人工智能等技術迅速興起并廣泛應用于各個領域,改變了人們以往的生活方式,其中電視劇的評論、主演及口碑等因素極大影響著觀眾們的擇劇意愿,因此通過數據挖掘等技術來優化中國電視劇產業,進而打造出符合大眾需求的優質電視劇顯得尤為重要。
當前國內外關于電視劇研究的方法主要有統計分析、機器學習、情感分析和口碑挖掘等。在電視劇數據分析上,梁文鳳以網絡改編劇的觀眾為研究對象,借助SPSS統計工具對觀眾的收視行為、忠誠度、滿意度及產品涉入度之間的關系進行深入分析。朱寒婷等提出一種在首播前預測電視劇流行度的方法,通過時間序列和多元線性回歸模型對搜索數據展開預測,并取得良好效果。
在劇評情感分析上,馮悅悅利用doc2vec詞嵌入技術對已標記評論進行詞向量訓練,并在此基礎上實現未標記評論的情感預測。陳浩然等通過情感詞典和節目要素詞典對綜藝彈幕進行挖掘,證明觀眾情感值和對節目的認可度之間具有一定相關性。
在口碑挖掘上,朱琳等從口碑主體、交流介質、討論內容三個方面對中國電視劇網絡口碑形成的影響因素進行深入挖掘。苑清敏等基于口碑營銷理論和實證分析,構建了網絡口碑對消費者觀看選擇的結構模型。
因此,本文在已有方法的基礎上,將情感分析、隨機森林和共詞分析等技術進行結合并加以創新,從多個維度去挖掘電視劇的風格類型、文化差異、觀眾情緒、參演人員和質量口碑之間的關聯及內在規律,以期能更好地推動中國電視劇產業的健康發展。
2 中國電視劇產業的研究思路及方法
2.1 整體思路
本文研究的整體思路框架如圖1所示。
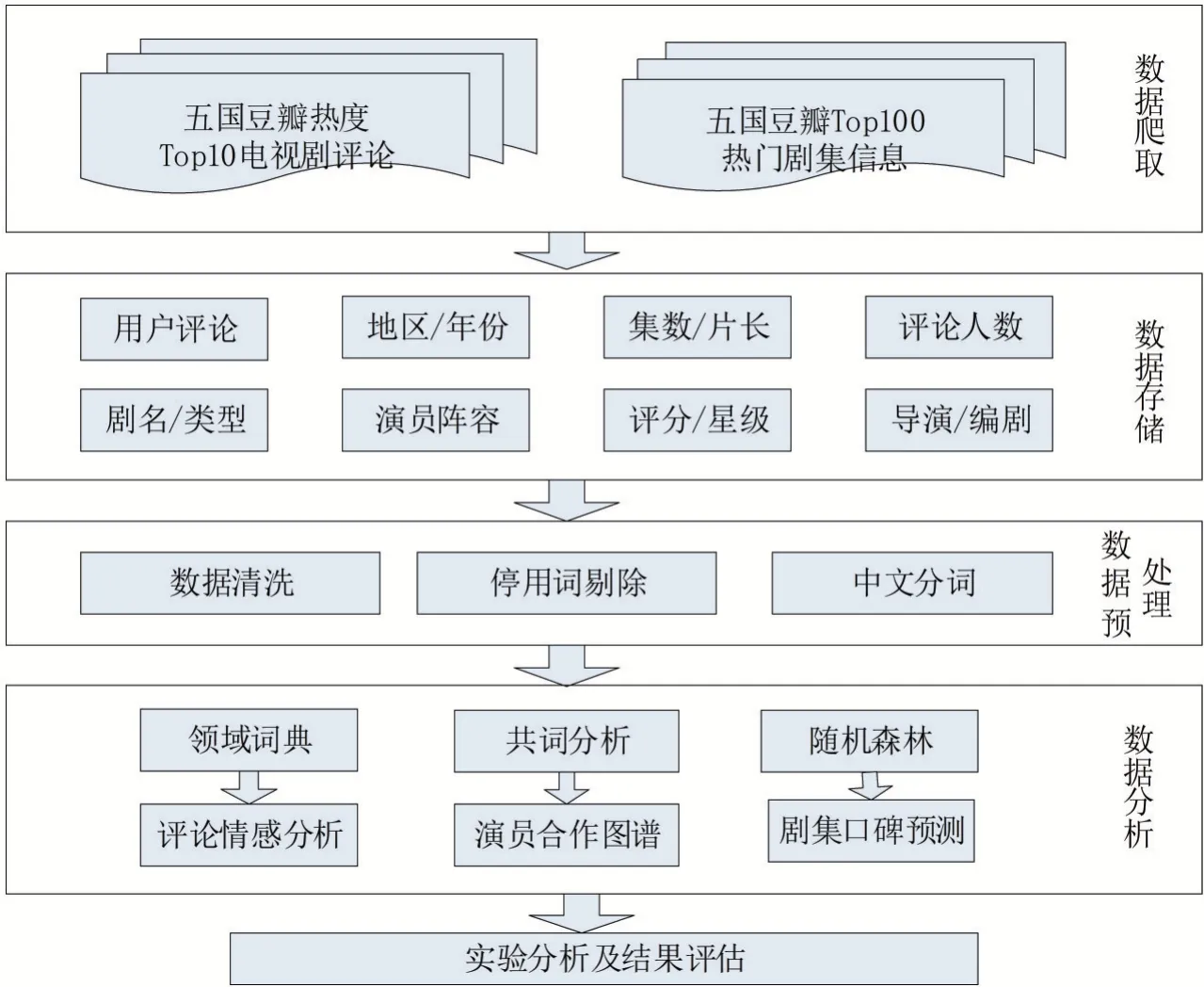
圖1 電視劇數據分析整體思路
2.2 數據獲取
本文數據源自豆瓣網,借助八爪魚數據采集器實現中、韓、美、英、日五國熱度前10部電視劇評論和前100部劇集詳細信息的獲取。其中,共采集評論11000條,剔除無效及重復評論,得到有效評論10768條,和五國的500條劇集信息一同存儲至Excel中。
2.3 數據預處理
為使實驗結果最佳,分析前還需對數據進行預處理操作,以保證數據質量,具體操作如下:
2.3.1 數據清洗
旨在使數據更加規范、詳細和可靠。針對數據缺失問題,文中參照百度百科進行手動填充,此外,對極個別異常值數據進行剔除處理。
2.3.2 剔除停用詞
評論內容中常常包含大量無意義的詞語和符號,如“的”“等”“…”“/”等,會給分析帶來影響,因此,本文構建停用詞表對其進行過濾去除。
2.3.3 中文分詞
實驗調用Python內的中文分詞庫來完成此項操作。同時,分詞中會出現詞語誤判現象,如“不忍直視”可能在分詞后會變為“不忍”和“直視”兩個詞語。為避免此類情況,文中增加了自定義詞典,進而提升分詞精度。
2.4 情感分析
情感分析是對文本內容中的情緒進行識別、抽取、分析及推理的研究。本文采用詞典匹配模式來辨別、提煉用戶評論中的情感詞,并據其所在詞典內的情感類別進行統計分析。實驗中情感詞典選用的是大連理工大學情感詞匯庫,該詞典將情感細致劃分成“樂”“好”“驚”“怒”“哀”“懼”“惡”7類,能夠較好滿足實驗需求。此外,運用Word2vec模型來實現情感詞典的擴充。
2.5 隨機森林算法
隨機森林是在多個決策樹的基礎上進階而成的集成學習算法,屬于監督學習,其內每棵決策樹為一個弱分類器。匯集多棵決策樹的隨機森林可以并行化運算,進而提升整體的分類性能。本研究將從Sklearn機器學習包中調用隨機森林算法對各國電視劇口碑好壞進行預測。
3 實驗分析及結果評估
3.1 電視劇領域詞典構建
近年來,隨著影視網絡的不斷發展,各種網絡新詞層出不窮,這類詞語往往包含獨特的情感內涵,不能被忽略,然而基礎情感詞典中并沒有更新此類詞語,因此,本文采用Word2vec模型進行電視劇專屬領域的詞典構建,基本步驟如下。
(1)對各國電視劇評論數據進行結巴分詞、停用詞剔除、詞性標注和訓練詞向量等操作;
(2)將分詞后的情感詞按詞頻降序排列,從中挑選前50個詞語作為情感種子詞;
(3)通過Word2vec模型尋找與情感種子詞相關聯的候選詞,并于基礎詞典中完成重復值篩選,進而擴充、完善情感詞典。
為使電視劇評論的情感分析效果最佳,實驗中由3名相關專業研究生對候選詞進行情感類別標注,并從結果中挑選兩次及以上的相同結果作為詞最終的情感類別,標注不同的,以3人商討后的結果為準。最后將93個候選詞和相應的情感類別加入情感詞典,完成電視劇領域專屬情感詞典的構造。
經擴展后的領域詞典在性能上得到較大提升。以《慶余年》為例,圖2是擴展前后兩種詞典對其評論的情感分析對比圖,從中發現,在7個維度上領域詞典的情感詞識別度均有不同程度的提高,尤其在“樂”“好”“惡”3個維度上效果更為顯著,為后續分析奠定了基礎。

圖2 《慶余年》評論中兩種詞典的性能比較
3.2 電視劇評論情感分析
對劇評進行細粒度情感研究,可以使投資方和制片人更好地獲悉廣大觀眾的確切需求,從而站在觀眾的視角描述電視劇,進而實現觀眾情緒分析、劇集風格對比、文化差異比較等實際應用。
3.2.1 觀眾情緒分析
在基于領域詞典的劇評情感分析方面,同樣以詼諧幽默的《慶余年》為例,劇評內容情感分布如圖2所示。由圖2可知,該劇以正向歡快的情緒(樂、好)為主,同時亦伴隨著一定的負面情緒(惡、怒)和些許悲傷情緒(哀),觀眾評論中情緒和劇集內容所呈現情感狀態十分吻合。但具體到單條評論,文中隨機抽取兩條個例,并將其情感分布用餅圖形式加以展現(見圖3),顯然圖3(a)的該觀眾感受到的更多是美好和溫暖,而圖3(b)的觀眾感受卻是厭惡、悲傷和恐懼。借助可視化,能夠清晰地洞悉觀眾在情緒感知上的差異。

圖3 《慶余年》個例評論情感分布
3.2.2 劇集風格對比
電視劇風格類型的不同,帶給觀眾們的情緒感知亦有差異。圖4為熱度前10部國劇的評論細粒度情緒分布對比圖,細致地呈現出觀眾在不同電視劇上的感受。圖4顯示,《三生三世枕上書》《下一站是幸福》《錦衣之下》的“樂”“好”情緒占比較高,其中《下一站是幸福》居首,說明觀眾較于偏愛這類愛情、青春偶像等題材電視劇,究其原因,是該類型劇情較為迎合觀眾的審美期待,呼應了人們的情感生活;此外,《大明風華》《鶴唳華亭》《慶余年》中“惡”的情緒占比較大;《鶴唳華亭》《錦衣之下》《將夜2》的“哀”的情緒占比較多;而《大明風華》《鶴唳華亭》《唐人街探案》的“怒”的情緒占比較高,表明觀眾對《大明風華》《鶴唳華亭》等歷史古裝劇持消極態度較多;同時還可以發現觀眾對《錦衣之下》的感知呈現兩極分化,對《鶴唳華亭》的情緒豐富,各占比均較高,說明觀眾對其爭議較大,而《唐人街探案》的“懼”情緒占比最高,這與其懸疑推理劇的風格十分符合。

圖4 10部國劇的用戶評論情感分布
3.2.3 國度間劇集差異比較
圖5為五國電視劇評論的用戶情緒分布圖,由圖5可知,用戶對各國劇評的情緒感知在整體上呈現為正面情感,這說明國內大多觀眾對于英、美、日、韓4國電視劇的內容較為認可,亦表明我國的影視市場包容性強,對差異性文化接受度高等特點。然而在多維度的情緒分布中,5國劇集又有明顯區別,如美劇和英劇中“哀”“懼”情緒都占比較多,但美劇更偏向于“怒”,英劇更偏向于“驚”,符合實際中美劇、英劇的劇情編排。日劇中“驚”和“懼”的情感較為明顯。韓劇中“樂”“好”“哀”居多,與生活中觀眾喜愛其唯美浪漫、催人淚下情節的普遍現象基本一致,這是韓劇劇情與人們內心情感產生共鳴的緣故。通過對不同國家的影視評論進行情感挖掘,有助于把握各國的影視編制特色,進一步了解其各自的文化差異,從而打造出極具自身魅力的精品電視劇。
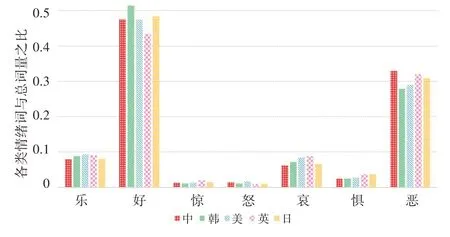
圖5 五國劇評各類情緒分布
3.3 共詞分析演員關系圖譜
演員是觀眾與劇集角色情智交流的橋梁,一部優秀電視劇的產生需要合適演員來將特定角色形象演繹到位,因此演員人選不僅是電視劇成敗的關鍵還是觀眾擇劇時考慮的重要因素。為了深入探究各演員間合作關系及其潛在規律,本文采用共詞分析法計算豆瓣電視劇中各國熱度前100部的所有演員共現情況,計算規則是:兩位演員同時出演一部電視劇就視為共現,并存在一條關系邊,反之則沒有。
以國劇為例,運用Gephi軟件繪制演員關系知識圖譜,結果如圖6所示,共挖掘出核心演員200名和關系邊4864條。圖中節點代表演員,其顏色為相似類別,大小表示演員的重要程度,這可以更好展現演員間的關聯情況。圖6顯示,該圖譜中演員分成不同陣營,各陣營相對獨立但彼此又間互相聯系,其中“楊紫”“迪麗熱巴”“易烊千璽”“李現”等新生代演員和“王勁松”“王永泉”“靳東”“王凱”等實力派演員活躍于熒屏,深受廣大觀眾喜愛。同時,推薦制劇方和這些演員合作,以提高劇集收視率。

圖6 豆瓣國劇演員關系圖譜
3.4 隨機森林分類算法
本文將對豆瓣網中各國熱度前100部的電視劇(共500部)進行隨機森林分類實驗,并根據電視劇的豆瓣評分對其劃分成三類,即口碑較差、口碑中等和口碑較好,進而實現電視劇質量的預測。其中將豆瓣評分位于區間[0,6)、[6,8)、[8,10]的電視劇分別定義為口碑較差、中等、較好3個等級(滿分10分)。該數據集共包含9個特征,如表1所示。
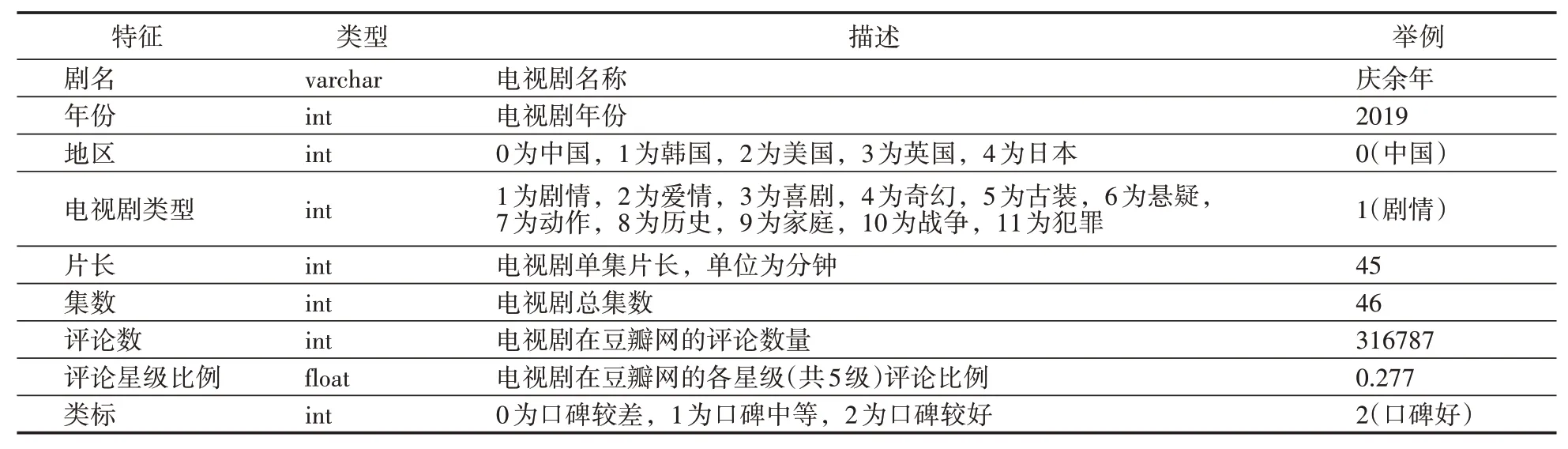
表1 數據集特征
為保證實驗公平有效,文中將數據集按4∶1進行隨機劃分,以400部電視劇作為訓練集,100電視劇作為測試集。并基于隨機森林進行口碑等級預測,最后選取準確率、召回率、特征值三個指標評估算法的分類性能。實驗結果如表2所示。
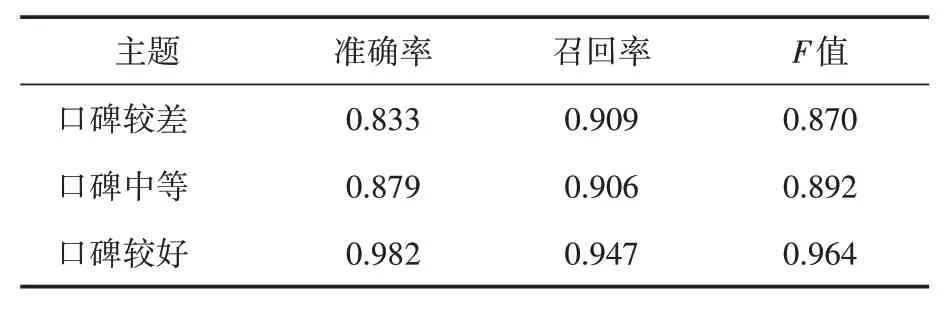
表2 隨機森林分類結果
從表2可知,口碑較好的電視劇實驗結果最佳,準確率為0.982,召回率為0.947,值為0.946。
4 結語
本文以豆瓣網電視劇數據為研究對象,借助情感詞典、共詞分析和隨機森林等方法實現觀眾細粒度情緒分析、演員間關系挖掘以及電視劇口碑好壞預測,通過可視化技術將結果多維度呈現。得出以下結論。
(1)構建的領域詞典在性能上得到較大提升,可以從電視劇評論中有效提取出觀眾的情緒訴求和分布狀態,并加以可視化展現,能夠為影視業提供一種新的分析視角。
(2)通過對電視劇評論的情感分析得出:觀眾評論中蘊含的情緒和劇集內容所呈現的情感狀態具有一致性。同時,觀眾的情感感知亦存在差異,需更更深入地獲悉觀眾在評論中的情感需求。
(3)我國電視劇市場呈現兼容并包的良好局面,韓、英、美、日等國劇集的加入,極大豐富了廣大觀眾的文化娛樂生活。五國劇集風格不盡相同、各有所長,與觀眾的情緒分布具有一定的相關性。同時,我國也需吸取各國劇集的優點,并加強自身的創新能力。
(4)共詞分析的演員合作關系圖譜共發掘出200名核心演員與4864條關系,其中相似度較高的演員被聚類為同一陣營,各陣營相對獨立但彼此間又互相關聯,直觀地展現出演員們的合作現狀,這可以為制劇方在選擇合適演員方面提供一定的參考價值。
(5)隨機森林算法對豆瓣網各國共500部的電視劇進行口碑預測分析,并將結果分為口碑較差、中等、較好三類。經驗證,整體預測效果良好,是向觀眾推薦優秀劇集的有效方法。
總之,本文研究方法能夠有效挖掘出我國電視劇數據中蘊藏的價值信息,對于打造出更符合大眾口味的優秀電視劇具有重要的理論意義和實際價值。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
電子制作(2018年18期)2018-11-14 01:48:24
中國生殖健康(2018年5期)2018-11-06 07:15:40
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
山東工業技術(2016年15期)2016-12-01 05:31:22
