基于知識圖譜的通用學(xué)習(xí)路徑生成研究
2022-05-26 04:23:06白玉帥徐洪勝
綿陽師范學(xué)院學(xué)報 2022年5期
白玉帥,徐洪勝,魏 銘,唐 海
(湖北汽車工業(yè)學(xué)院電氣與信息工程學(xué)院,湖北十堰 442002)
0 引言
近年來,個性化在線學(xué)習(xí)系統(tǒng)的研究因疫情的影響而變得異常迫切,越來越多的學(xué)者和專家關(guān)注并投入到此領(lǐng)域的研究中.在線學(xué)習(xí)系統(tǒng)服務(wù)于在線學(xué)習(xí)者,滿足其個性的需求,緩解當(dāng)前在線學(xué)習(xí)中存在的“信息過載”與“學(xué)習(xí)迷航”等問題.眾多專家學(xué)者從不同的角度對個性化在線教育進(jìn)行分析與討論:劉芳等[1]重視學(xué)習(xí)者特征,并以此構(gòu)建學(xué)習(xí)者模型進(jìn)行學(xué)習(xí)資源推薦;李浩君等[2]從學(xué)習(xí)資源角度出發(fā),利用優(yōu)化算法,為在線學(xué)習(xí)者推薦最優(yōu)學(xué)習(xí)資源與學(xué)習(xí)路徑;申云鳳等[3]分析并量化在線學(xué)習(xí)行為特征,引入多重智能型算法進(jìn)行學(xué)習(xí)路徑的個性化推薦.學(xué)習(xí)路徑生成的研究已然成為在線學(xué)習(xí)系統(tǒng)的重要研究領(lǐng)域.
學(xué)習(xí)路徑的研究隨著在線學(xué)習(xí)系統(tǒng)的盛行而日益蓬勃.歐美國家對學(xué)習(xí)路徑開展研究的時間較早、成果也較為顯著:美國匹茲堡大學(xué)Peter Brusilovsky[4]依據(jù)奧蘇泊爾的有意義學(xué)習(xí)理論,采用模糊神經(jīng)網(wǎng)絡(luò)方法判斷知識水平、動機(jī)等,實(shí)現(xiàn)學(xué)習(xí)路徑的定制.奧地利格拉茨大學(xué)的Nussbaume[5]采用知識空間理論和布魯姆目標(biāo)分類法判斷學(xué)習(xí)者的知識水平,創(chuàng)建適應(yīng)性學(xué)習(xí)路徑.國內(nèi)對該領(lǐng)域的研究也取得了一定的進(jìn)展:姜強(qiáng)等[6]利用序列模式挖掘算法,挖掘、分析并匹配計算學(xué)習(xí)者特征與學(xué)習(xí)對象,生成精準(zhǔn)的個性化學(xué)習(xí)路徑.牟智佳等[7]對在線學(xué)習(xí)系統(tǒng)服務(wù)與數(shù)據(jù)處理技術(shù)間的關(guān)系進(jìn)行論述,提出了基于學(xué)習(xí)特征模型的自適應(yīng)學(xué)習(xí)路徑生成框架.
當(dāng)前,多數(shù)的研究傾向于關(guān)注如何構(gòu)建個性化的學(xué)習(xí)路徑以解決在線學(xué)習(xí)質(zhì)量差、效率低等問題,但個性化路徑生成效果并不理想.本研究在構(gòu)建學(xué)科知識圖譜的基礎(chǔ)上提出了一種通用與可行的學(xué)習(xí)路徑,為當(dāng)前大多數(shù)在線學(xué)習(xí)群體提供“學(xué)習(xí)導(dǎo)航”的功能,提高學(xué)習(xí)質(zhì)量、提升學(xué)習(xí)效率.
1 學(xué)習(xí)路徑研究現(xiàn)狀
1.1 學(xué)習(xí)路徑定義

圖1 基于學(xué)習(xí)行為活動的學(xué)習(xí)路徑Fig.1 Learning path based on learning behavior activities
關(guān)于學(xué)習(xí)路徑的概念界定,目前主流的定義分為兩種:其一,學(xué)習(xí)者在一定的學(xué)習(xí)方法指導(dǎo)下,根據(jù)其學(xué)習(xí)的目標(biāo)、水平等,對所需完成的學(xué)習(xí)活動進(jìn)行排序[8].即通過挖掘?qū)W習(xí)者學(xué)習(xí)活動時的行為日志數(shù)據(jù),如瀏覽課件、交流提問和在線測試等,并結(jié)合學(xué)習(xí)者的學(xué)習(xí)風(fēng)格對學(xué)習(xí)活動進(jìn)行序列化,形成基于學(xué)習(xí)行為活動的學(xué)習(xí)路徑,其路徑結(jié)構(gòu)如圖1.

圖2 基于知識單元的學(xué)習(xí)路徑Fig.2 Learning path based on knowledge unit
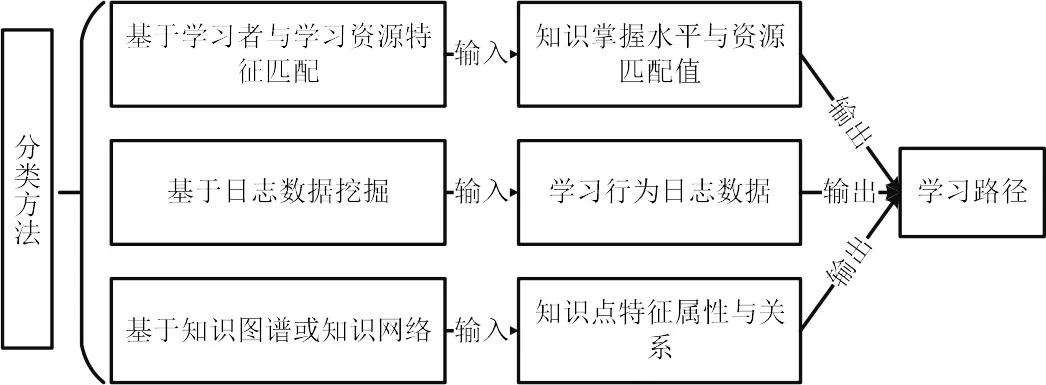
圖3 學(xué)習(xí)路徑自動生成方法分類Fig.3 Classification of automatic learning path generation methods
其二,將學(xué)習(xí)路徑抽象化,理解成學(xué)習(xí)節(jié)點(diǎn)的組織序列,由路徑節(jié)點(diǎn)和節(jié)點(diǎn)間的關(guān)系構(gòu)成學(xué)習(xí)路徑[9],其中路徑節(jié)點(diǎn)是最基本的構(gòu)成要素,是學(xué)習(xí)者完成學(xué)習(xí)目標(biāo)所需要進(jìn)行的最小學(xué)習(xí)單元.利用學(xué)習(xí)單元本身的屬性特征及其之間的關(guān)系,在不違背學(xué)習(xí)單元之間內(nèi)在邏輯的前提下,對待學(xué)習(xí)單元進(jìn)行序列化,形成基于知識單元的學(xué)習(xí)路徑,其路徑結(jié)構(gòu)如圖2.
1.2 學(xué)習(xí)路徑自動生成方法分類
根據(jù)對學(xué)習(xí)路徑生成研究的核心思路與策略的不同特征將其分為三類[10],歸納成圖3.
1.2.1 基于學(xué)習(xí)者與學(xué)習(xí)資源特征匹配的方法 通過計算學(xué)習(xí)者掌握知識水平與學(xué)習(xí)資源間匹配程度,按照兩者匹配程度的高低對學(xué)習(xí)者進(jìn)行學(xué)習(xí)資源的序列化推薦.例如,李浩君[11]引入在線學(xué)習(xí)資源相斥的排序規(guī)則,根據(jù)相斥度的大小實(shí)現(xiàn)在線學(xué)習(xí)資源序列化推薦服務(wù).此類路徑生成方法強(qiáng)調(diào)的是個性化定制,但存在違背知識點(diǎn)之間內(nèi)在邏輯及認(rèn)知規(guī)律的風(fēng)險.
1.2.2 基于日志數(shù)據(jù)挖掘的方法 利用學(xué)習(xí)者的學(xué)習(xí)行為日志數(shù)據(jù),采用關(guān)聯(lián)規(guī)則挖掘算法,從海量的知識單元序列或在線學(xué)習(xí)者的學(xué)習(xí)測試記錄中獲取知識單元的關(guān)系并以此構(gòu)建學(xué)習(xí)路徑.例如,申云鳳[3]利用網(wǎng)絡(luò)學(xué)習(xí)日志,結(jié)合學(xué)習(xí)風(fēng)格與能力水平,量化學(xué)習(xí)行為特征,采用多重智能型算法實(shí)現(xiàn)了對個性化學(xué)習(xí)路徑的推薦.此類路徑生成方法充分考慮了群體學(xué)習(xí)者的智慧,但忽視了自組織學(xué)習(xí)路徑本身也可能存在錯誤,利用從群體經(jīng)驗中總結(jié)出的學(xué)習(xí)路徑并不一定具備普適性.
1.2.3 基于知識圖譜或知識網(wǎng)絡(luò)的方法 根據(jù)知識圖譜本身包含的知識點(diǎn)屬性與知識點(diǎn)之間的關(guān)系作為算法的輸入,在確保學(xué)習(xí)路徑符合知識點(diǎn)之間內(nèi)在邏輯的基礎(chǔ)上,結(jié)合自定義的網(wǎng)絡(luò)節(jié)點(diǎn)拓?fù)渑判蛩惴ㄅc優(yōu)化算法構(gòu)建成學(xué)習(xí)路徑.例如,淵明[12]設(shè)計出三層知識圖譜結(jié)構(gòu)并結(jié)合學(xué)習(xí)者模型,對在線學(xué)習(xí)者推薦學(xué)習(xí)路徑.此類學(xué)習(xí)路徑生成方法從學(xué)科領(lǐng)域知識結(jié)構(gòu)出發(fā)規(guī)劃學(xué)習(xí)路徑,保證了學(xué)習(xí)路徑生成結(jié)果的邏輯性與科學(xué)性,但目前而言對知識圖譜的設(shè)計、開發(fā)與維護(hù)的代價較高,需要投入大量的人工精力與資源.
以上三類學(xué)習(xí)路徑的生成方法各有優(yōu)劣,總體而言,基于知識圖譜或知識網(wǎng)絡(luò)生成學(xué)習(xí)路徑的準(zhǔn)確性較高,也更符合學(xué)習(xí)者的認(rèn)知規(guī)律.但目前基于此類方法的相關(guān)研究缺乏對知識圖譜構(gòu)建過程的討論,圖譜設(shè)計的質(zhì)量也難以保證,故本研究將先從知識圖譜的設(shè)計與構(gòu)建等角度展開分析與討論.
2 通用學(xué)習(xí)路徑自動生成方法
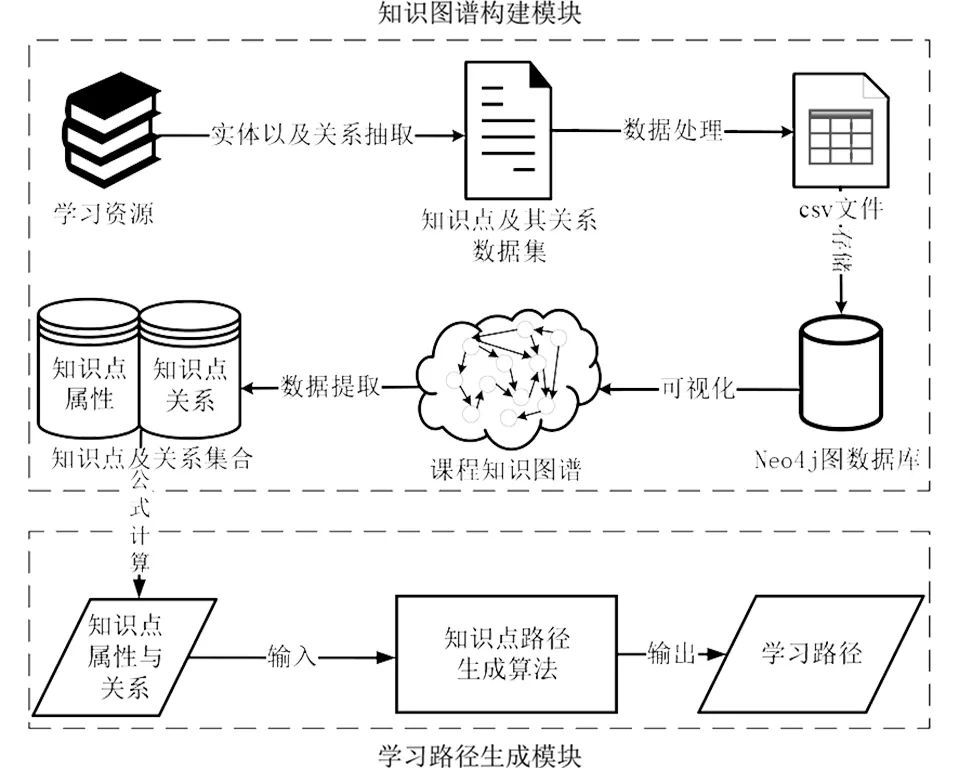
圖4 基于知識圖譜的通用學(xué)習(xí)路徑生成方法Fig.4 General learning path generation method based on Knowledge graph
學(xué)習(xí)路徑生成是從知識圖譜到通用學(xué)習(xí)路徑,最終生成個性化的學(xué)習(xí)路徑.本研究重點(diǎn)討論基于知識圖譜的通用學(xué)習(xí)路徑自動生成方法如圖4所示,分為兩部分.第一部分是知識圖譜創(chuàng)建模塊,此部分采用以機(jī)器為主、人工為輔的方式構(gòu)建知識圖譜;第二部分是學(xué)習(xí)路徑生成模塊,將第一部分知識圖譜中相關(guān)信息作為輸入,結(jié)合算法實(shí)施與參數(shù)調(diào)試得到通用學(xué)習(xí)路徑.本研究構(gòu)建的知識圖譜為大學(xué)本科計算機(jī)科學(xué)與技術(shù)專業(yè)必修課程“C語言程序設(shè)計”.
2.1 課程知識圖譜

為確保知識圖譜構(gòu)建的質(zhì)量,采取人工設(shè)計概念層、自動提取關(guān)鍵詞以及由學(xué)科專家手動篩選知識點(diǎn)及知識點(diǎn)間關(guān)系的方法構(gòu)建課程知識圖譜.此外,還充分考慮知識圖譜中實(shí)體類型、屬性及關(guān)系,設(shè)計出知識圖譜的模式層,其結(jié)構(gòu)如表1所示.
基于知識特征的最優(yōu)學(xué)習(xí)路徑規(guī)劃(節(jié)點(diǎn)排序)研究的關(guān)鍵是節(jié)點(diǎn)之間的關(guān)系.例如,知識點(diǎn)的難度、中心度及關(guān)系權(quán)重的確定等[13].因此,在設(shè)計學(xué)習(xí)路徑自動生成時,充分考慮知識點(diǎn)在知識圖譜中的屬性及關(guān)系.知識圖譜中需要包含對知識點(diǎn)之間的父子及兄弟關(guān)系的記錄,父子關(guān)系即知識點(diǎn)之間的包含關(guān)系,用以描述知識點(diǎn)之間整體與局部的關(guān)系;兄弟關(guān)系即平行關(guān)系,用以描述處在同一個層面上的多個知識點(diǎn),且彼此之間不存在任何依賴關(guān)系.
知識點(diǎn)屬性方面,除id和名稱屬性外,還添加了知識點(diǎn)的重要度、難度、中心度和拓?fù)鋵蛹壦膫€屬性,以此豐富知識圖譜模式層的構(gòu)建,提高知識圖譜設(shè)計的質(zhì)量.
2.2 學(xué)習(xí)路徑生成算法
本研究設(shè)計了知識點(diǎn)拓?fù)渑判蛩惴ǎ凑罩R點(diǎn)的重要度由高到低、難度由易到難、中心度由大到小和拓?fù)鋵蛹売蓽\至深原則,結(jié)合知識圖譜的結(jié)構(gòu)及知識點(diǎn)間的關(guān)系對知識點(diǎn)進(jìn)行排序,生成通用學(xué)習(xí)路徑.
2.2.1 知識點(diǎn)屬性特征值計算 利用TextRank關(guān)鍵詞提取算法對文本資源進(jìn)行處理,得到知識點(diǎn)集合及知識點(diǎn)重要度.其公式表示為:
(1)
式中:Ws(Vi)為節(jié)點(diǎn)Vi的權(quán)重;Ws(Vj)為上次迭代后的節(jié)點(diǎn)Vj的權(quán)重;wji為節(jié)點(diǎn)Vj與節(jié)點(diǎn)Vi之間的相似度;d為阻尼系數(shù),一般取值為0.85.
知識點(diǎn)難度的定義參考課程要求,將其分為了解、理解、掌握與應(yīng)用四個等級,并分別賦予1到4的權(quán)重.
根據(jù)知識圖譜的性質(zhì),利用知識點(diǎn)的入度與出度的比值計算知識點(diǎn)的中心度,比值越大,說明知識點(diǎn)的中心度越高,其對后續(xù)學(xué)習(xí)的貢獻(xiàn)越大[14].知識點(diǎn)入度與出度的定義如下.
(2)
中心度計算公式如下:
(3)
式中:C(v)為節(jié)點(diǎn)Vi的入度與出度的比值;Pre(Vi)為知識點(diǎn)Vi的一階前驅(qū)知識點(diǎn)集合;Suc(Vi)為知識節(jié)點(diǎn)Vi的一階后繼知識點(diǎn)集合.
知識點(diǎn)拓?fù)鋵蛹壙筛鶕?jù)知識圖譜的結(jié)構(gòu)設(shè)計直接獲取.
利用上述屬性值計算知識點(diǎn)排序指標(biāo)Wkpi,如公式(4)所示.其中重要度Impkpi利用公式(1)中Ws(Vi)節(jié)點(diǎn)的權(quán)重值.
Wkpi=wimp×Impkpi+wdiff×Diffkpi+wcent×Centkpi+wtp×Tpkpi
(4)
式中:Impkpi、Diffkpi、Centkpi、Tpkpi分別為知識點(diǎn)kpi的重要度、難度、中心度與拓?fù)鋵蛹墸鴚imp、wdiff、wcent、wtp為人工賦予的屬性權(quán)重值.

圖5 學(xué)習(xí)路徑生成算法流程圖Fig.5 Flow chart of learning path generation algorithm
2.2.2 算法流程 通用學(xué)習(xí)路徑生成算法流程如圖5所示.
圖中:
①待排序的知識點(diǎn)集合KG,本研究將知識圖譜中所有知識點(diǎn)都列為待排序的知識點(diǎn)集合,并且,為了后續(xù)的分析與計算,本研究手動指定了一個初始知識點(diǎn)KP0.
③知識點(diǎn)及關(guān)系的三元組列表L,可直接從Neo4j圖數(shù)據(jù)庫中導(dǎo)出.列表L的記錄信息為(KPm,R,KPn),表示知識點(diǎn)KPm與KPn的關(guān)系為R.
④知識點(diǎn)重要度、難度、中心度與拓?fù)鋵蛹墝傩蕴卣鲾?shù)據(jù)Impkpi、Diffkpi、Centkpi、Tpkpi以及知識點(diǎn)排序指標(biāo)Wkpi.
⑥結(jié)合知識圖譜及知識點(diǎn)屬性特征數(shù)據(jù),利用拓?fù)渑判蛩惴ㄉ蓪W(xué)習(xí)路徑.
最后,算法的輸出為通用的學(xué)習(xí)路徑Pathkp,Pathkp=(KP1,KP2,…,KPn).
3 實(shí)驗分析

實(shí)驗環(huán)境及設(shè)備工具的選擇對實(shí)驗結(jié)果有較大的影響,為了盡可能產(chǎn)生最好的實(shí)驗效果,主要使用的系統(tǒng)開發(fā)環(huán)境如表2所示.
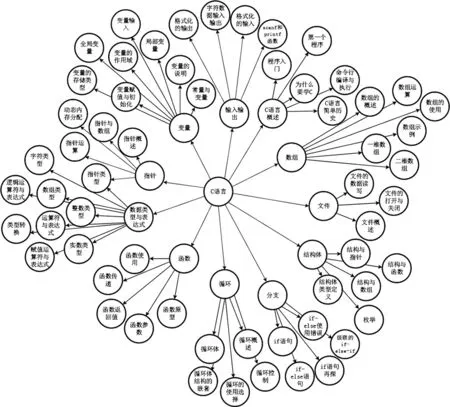
圖6 《C語言程序設(shè)計》知識圖譜Fig.6 Knowledge graph of C language programming
從某在線學(xué)習(xí)平臺隨機(jī)爬取某大學(xué)本科必修課程“C語言程序設(shè)計”,將其處理后轉(zhuǎn)為文本.利用TextRank提取關(guān)鍵詞算法得到500個待排序知識點(diǎn)集合及其重要度值Impkpi,經(jīng)篩選后添加知識節(jié)點(diǎn)關(guān)系屬性,同時結(jié)合專業(yè)課程書籍將知識點(diǎn)與知識點(diǎn)之間的關(guān)系整理成CSV文件,并將文件導(dǎo)入到Neo4j圖數(shù)據(jù)庫中形成可視化的知識圖譜,如圖6所示.
根據(jù)知識圖譜中知識點(diǎn)屬性及其之間的關(guān)系,分別計算得到知識點(diǎn)難度、中心度、拓?fù)鋵蛹墝傩蕴卣髦礑iffkpi、Centkpi、Tpkpi.利用公式(4)計算并調(diào)試參數(shù)后得到知識點(diǎn)排序指標(biāo)Wkpi,其計算結(jié)果如表3所示.

表3 屬性特征及排序指標(biāo)的值Tab.3 Attribute characteristics and values of sorting indicators
結(jié)合上述步驟,并使用設(shè)計的知識點(diǎn)拓?fù)渑判蛩惴ㄗ詣由苫谥R圖譜的通用學(xué)習(xí)路徑,將路徑可視化后如圖7(a)所示.同時,邀請相關(guān)領(lǐng)域?qū)<覍χR點(diǎn)進(jìn)行路徑設(shè)計,生成了專家路徑,如圖7(b)所示.

圖7(a) 自動生成路徑Fig.7(a) Auto-generate path圖7 (b)專家路徑Fig.7(b) Expert path
完成算法實(shí)現(xiàn)與參數(shù)調(diào)試后,為得到學(xué)習(xí)路徑自動生成質(zhì)量,將其與專家路徑做效果對比.路徑相似度計算公式如下所示.
(5)
式中:pathep、pathat分別為專家路徑與自動生成路徑;KPmatched為專家路徑與自動生成路徑相匹配的學(xué)習(xí)路徑個數(shù);KPtotal為學(xué)習(xí)路徑總數(shù).
由公式(5)計算得到自動生成的學(xué)習(xí)路徑與專家設(shè)計的路徑相似度為81.94%,說明本研究設(shè)計的基于知識圖譜自動生成的學(xué)習(xí)路徑的規(guī)劃方法是可行的.
此外,還利用了學(xué)習(xí)路徑評估指標(biāo)fitness[10],進(jìn)一步檢驗自動生成路徑的質(zhì)量.fitness評估指標(biāo)的計算公式如下所示.
(6)
式中:penaltyadi為學(xué)習(xí)路徑違背知識點(diǎn)間相鄰原則的數(shù)量;penaltyorder為學(xué)習(xí)路徑違背知識點(diǎn)間先修后繼原則的數(shù)量.學(xué)習(xí)路徑違背規(guī)則的數(shù)量越少,fitness數(shù)值就越小,說明路徑生成的質(zhì)量越高.

根據(jù)公式(6)計算專家路徑與自動生成路徑的fitness評估指標(biāo)如表4所示.可見,自動生成路徑的fitness值偏小,與專家路徑的fitness指標(biāo)值差距也較小,說明自動生成路徑的質(zhì)量較高,接近專家設(shè)計路徑的水準(zhǔn).
通過兩種方法生成的路徑評測表明,本研究設(shè)計的基于知識圖譜的通用學(xué)習(xí)路徑的自動生成方法是合理的、可解釋的,且路徑生成的質(zhì)量較高.
與采用多重智能型算法生成的個性化學(xué)習(xí)路徑相比[3],通用學(xué)習(xí)路徑的生成受到稀疏問題的影響較小,無需事先得到大量學(xué)習(xí)者信息才能為其提供路徑推薦;本研究應(yīng)用TextRank算法與使用BiLSTM+CRF模型[12]進(jìn)行實(shí)體抽取相比,直接獲取了知識節(jié)點(diǎn)的重要度,降低了算法時間復(fù)雜度.
4 結(jié)論
本研究設(shè)計了一種從知識圖譜到通用學(xué)習(xí)路徑自動生成的方法,為個性化學(xué)習(xí)路徑的生成與學(xué)習(xí)資源的推薦乃至個性化學(xué)習(xí)系統(tǒng)的構(gòu)建打下堅實(shí)基礎(chǔ).實(shí)驗表明通用學(xué)習(xí)路徑生成方法的可行性較高,質(zhì)量也較好,在線學(xué)習(xí)過程中可替代專家制定的路徑,為在線學(xué)習(xí)者提供一條通用、合理與可解釋的學(xué)習(xí)路徑,從而提高在線學(xué)習(xí)者的學(xué)習(xí)效率與質(zhì)量.
在進(jìn)一步的研究中可以考慮,如知識圖譜中難度屬性可從歷史學(xué)習(xí)者的知識點(diǎn)得分記錄,學(xué)習(xí)時間成本等角度考慮,實(shí)現(xiàn)難度取值多元化;對比實(shí)驗環(huán)節(jié),組織被試人員依據(jù)路徑開展學(xué)習(xí),進(jìn)一步驗證自動生成路徑的質(zhì)量與效果.后續(xù)研究將主要針對以上方面進(jìn)行更為深入的探討與分析.
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
體育科技文獻(xiàn)通報(2022年3期)2022-05-23 13:46:54
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12
天津外國語大學(xué)學(xué)報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機(jī)設(shè)計與研究(2019年4期)2019-05-21 07:21:24
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
