基于遺傳算法和長短記憶神經網絡組合模型的加油站銷量預測
2022-05-27 10:11:02潘詩元易萬里李翔宇
化工自動化及儀表 2022年2期
潘詩元 易萬里 李翔宇
(1.中國石油大學人工智能學院;2.中國人民大學統計學院;3.東北財經大學統計學院)
成品油企業實現準確的加油站銷量預測可支撐企業進行準確的庫存管理與配送計劃編制,具有重要意義。 在成品油二次物流運輸中,需要對加油站的銷量進行精準預測,從而得到不同加油站的準確需求,做出精確的調度,使企業運行更加高效。 因此,加油站銷量預測是成品油二次物流運輸中不可或缺的部分。
傳統的加油站銷量預測一般處理成時間序列預測問題,但加油站銷量受很多因素影響且有諸多非線性特征,使得基于時間序列理論設計的銷量預測模型精度偏低。 目前的主流銷量預測方法主要有周平均、線性回歸、指數平滑、ARIMA、機器學習和深度學習。 由于技術的限制,現有加油站銷量預測多為利用周平均值或采用時間序列模型(如指數平滑模型)進行預測。 李艷東等提出建立指數平滑模型對第2天的銷量進行預測的時間序列模型,該模型目前用于一部分加油站銷量預測業務,模型預測速度快但精度較低[1]。張晨和邱彤提出一種基于決策樹集成模型的加油站銷量預測方法,利用積累的歷史銷售數據和相關特征數據進行計算, 對加油站的銷量進行預測,該模型由于樹模型難以避免過擬合,雖然在訓練集測試時精確度較高但在測試集時精度較低[2]。唐靜等提出一種適應度模型,用于遺傳算法參數尋優,建立了基于遺傳算法的電路診斷模型參數閉環尋優框架, 并分析參數搜索算法的收斂性,模型使用啟發式算法進行參數調優,對故障的識別效果會增強,誤分類率降低,同理可應用于各種模型的超參數調優,增加模型的精確性[3]。在國外的能源預測研究中,Laib O等使用LSTM模型通過電力市場、 當地天氣與日歷3個特征學習每小時時間序列數據的長期關系,并對總電力系統電網損失進行預測[4]。 Li W和Becker D M提出深度LSTM(DLSTM)模型,該方法在預測長間隔時間序列數據集時通過疊加更多的LSTM層避免淺層神經網絡架構的局限性,并應用遺傳算法優化配置DLSTM的最佳架構,最后將該模型與經典模型進行對比, 發現DLSTM模型均優于其他模型[5]。Sagheer A和Kotb M使用LSTM模型預測阿爾及利亞國內不同地區的天然氣消費量,先對不同地區的消費量進行聚類以減少時間序列的非平穩性,最后考慮歷史因素、氣象因素(如溫度、風速、濕度和日照)以及經濟因素(石油價格、客戶數量、GDP 和天然氣價格)并使用LSTM預測第2天的天然氣消耗量,最后以阿爾及利亞各地天然氣消費量為案例證明了該方法的有效性[6]。Tulensalo J等提出基于LSTM的深度學習方法和特征選擇算法的混合模型進行電價預測,先通過基于Shapley值的方法評估特征重要性,再使用LSTM模型進行電價預測[7]。 由于銷量的時間序列具有較強的非線性特征,現有的模型存在精度較低的問題。
目前,國內加油站銷量預測大多使用時間序列模型(如指數平滑、ARIMA等),但在實際業務中,由于ARIMA的預測速度較慢,一般使用指數平滑模型進行預測,而預測銷量曲線對于實際銷量曲線會有時間上的偏移,尤其在節假日前后偏移更為明顯,需要靠人工經驗進行修正。 同時,時間序列模型只能進行單變量預測,對于受多個因素影響的加油站銷量預測并不精確。
1 模型提出
文獻[2]提出加入其他特征變量(如星期、天氣及節假日等), 并使用機器學習中的樹模型與集成學習的思想進行多變量銷量預測,最后得到的結果中,訓練集精度較高,但是測試集精確度并不理想。 究其原因,主要是用樹這種分類模型做回歸問題難以避免過擬合。
而深度學習領域的長短記憶神經網絡(Long Short-Term Memory,LSTM) 適用于處理和預測時間序列中間隔和延遲非常長的重要事件[8]。同時,LSTM能進行多特征回歸,也因為其獨特的門控機制使其可自動決定記憶或遺忘哪些信息,從而避免多余特征的影響或者因部分數據噪聲而造成過擬合導致訓練集精度不理想的情況。由于LSTM超參數較多, 人工調參一般難以獲得最優參數,于是將LSTM模型的超參數作為種群輸入參數,將均方根誤差作為目標函數,使用遺傳算法(GA)來自動調參,從而將模型的準確度做進一步提升。
2 加油站銷量預測原理
2.1 LSTM
LSTM由循環神經網絡(RNN)改進而來。RNN會受到短時記憶的影響, 如果一條序列足夠長,那它很難將信息從較早的時間步傳送到后面的時間步,所以RNN不適合長時間序列的預測。 而LSTM很好地解決了RNN短時記憶的問題,LSTM具有稱為門的內部機制,門結構在訓練過程中會學習該保存或遺忘哪些信息,隨后,它可以沿著長鏈序列傳遞相關信息以進行預測。LSTM每個細胞單元的結構如圖1所示。
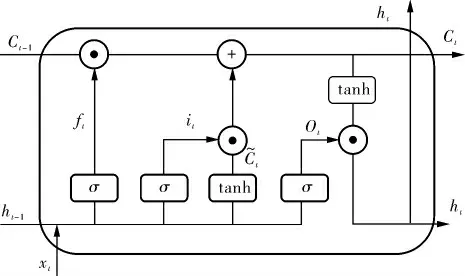
圖1 LSTM每個細胞單元的結構
LSTM一個細胞單元里包含遺忘門、輸入門和輸出門3種門結構, 同時包含細胞狀態向量和隱藏層狀態兩種狀態,隱藏層狀態是最終網絡的輸出,而細胞狀態會參與隱藏層狀態的計算。
設t時刻輸入LSTM的向量xt=(x1,x2, …,xn),LSTM隱藏層狀態輸出ht=(h1,h2,…,hm),則每個細胞單元的計算流程如下:
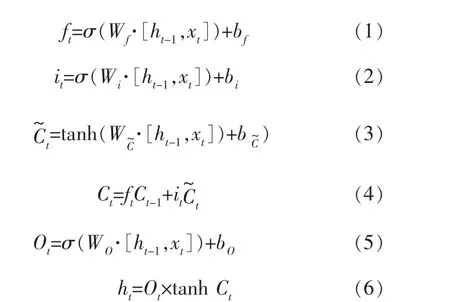
其中,Wf、Wi、、WO為權重矩陣, 在訓練過程中會自動學習更新;bf、bi、、bO為偏移量。遺忘門輸出的向量ft與輸入門輸出的向量it分別通過Sigmoid函數將值調整到0~1;輸入門的輸出向量通過tanh函數將值調整到-1~1, 再將上一個細胞狀態向量與這3個向量相加乘, 得到此次細胞狀態向量Ct。 最后,通過輸出門的輸出向量Ot與細胞狀態向量Ct得到最終隱藏層狀態輸出ht。
2.2 詞嵌入
本項目加入的加油站銷量特征中含有文本類型特征,需將文本轉換為向量,再使用LSTM進行預測。
2.2.1 One-hot編碼
One-hot編碼又稱一位有效編碼,主要是采用N位狀態寄存器對N個狀態進行編碼,不同狀態的寄存器位置相互獨立,并且在任意時刻對同一狀態有且只有一個寄存器有效。
One-hot編碼是分類變量作為二進制向量的表示。 本試驗中將每個分類值映射到整數值。 然后,每個整數值被表示為二進制向量,除了整數的索引之外, 其他都是零值。 如周一到周日的One-hot編碼分別是[1000000,0100000,0010000,0001000,0000100,0000010,0000001]。
One-hot編碼也是將文本轉換為向量的方法之一, 但是如果文本過長,One-hot編碼就非常稀疏且不利于計算。
2.2.2 Embedding
Embedding的主要目的是對稀疏特征向量進行降維, 通過Embedding層的權重矩陣計算來降低維度。 除此之外,Embedding矩陣給每個分類變量分配一個固定長度的向量表示,這個長度可以自行設定。
筆者處理文本的思路便是先將文本進行One-hot編碼處理,再使用Embedding進行降維,最終得到文本向量。
2.2.3 遺傳算法
遺傳算法起源于對生物系統進行的計算機模擬研究[9],是模仿生物界進化機制而尋求問題最優解的高效、并行、全局搜索方法。 遺傳算法包括編碼、初始化種群、評估適應度、判斷終止條件、選擇、交叉、變異和解碼步驟,其流程如圖2所示。
由于遺傳算法可擴展性強,可將LSTM的每層細胞單元個數、 全連接層L2正則化權重參數、dropout參數、迭代次數、batch_size作為參數集合,將RMSE作為適應度函數, 經過遺傳算法的迭代來尋找LSTM模型的最優超參數。 其中L2正則化參數為模型學習過程中的懲罰項,目的是防止模型過擬合;dropout是指在深度學習網絡訓練過程中,對神經網絡單元,按一定概率將其暫時從網絡中丟棄,dropout參數是丟棄的概率;batch_size是一次迭代訓練選取的樣本數;RMSE是預測值與真實值偏差的平方與觀測次數n′比值的平方根,是評價模型精度的指標之一。
3 試驗及結果分析
3.1 數據處理
3.1.1 特征提取
本項目選取的是昆明某加油站 (92#汽油)2019~2021年共計940日的數據,并在原始數據中添加“星期、溫度、天氣、節假日、油價”5個特征。對以上特征進行數據統計,結果如圖3~7所示(其中1 t的92#汽油為1 379 L)。
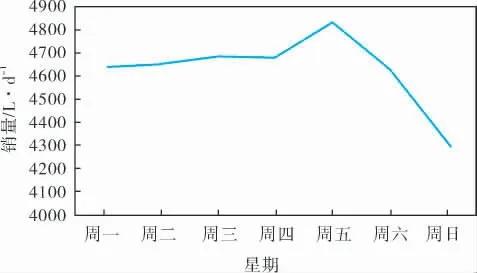
圖3 星期與銷量
圖3對每周周一到周日所有銷量加和取平均,可以看出,銷量在周一至周五呈上升趨勢,在周五達到峰值,并在周六、周日有所下降,周日達到最低點。 加油站銷量與星期特征有較強的相關性。
圖4對相同溫度取平均值來觀察溫度對銷量的影響。 由于地域關系,昆明的溫度波動范圍在1.5~25.0 ℃,極少出現低溫或高溫情況。 從圖4可以看出,銷量與溫度特征的相關性較小。
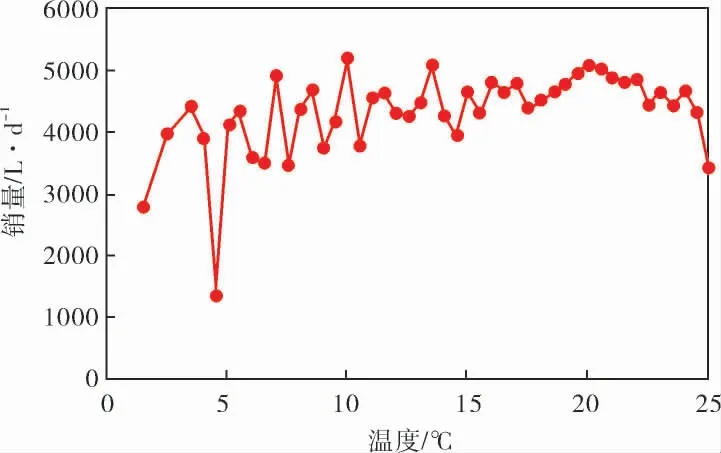
圖4 溫度與銷量
圖5對相同天氣情況取平均值來觀察天氣對銷量的影響。 因地域關系,昆明當地的天氣種類包含不完全,但是仍然可以看出,暴雨等惡劣天氣對于銷量影響較大。
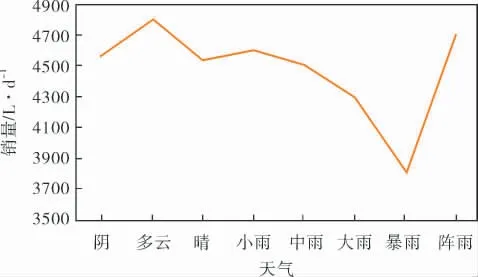
圖5 天氣與銷量
圖6對相同油價取平均值來觀察油價對銷量的影響。 雖然油價受到了部分特殊因素的影響,但是仍然可從圖中得出,隨著油價上漲,銷量呈現略微下降的趨勢,說明加油站銷量與油價特征有一定的相關性。
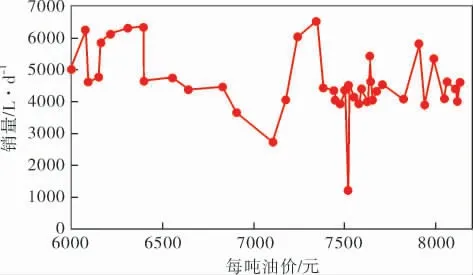
圖6 油價與銷量
圖7對節假日以及節假日前一天取平均值來觀察節假日對銷量的影響。 通過對比發現,節假日前銷量會高于平時銷量,節假日期間(除春節)銷量略高于平常, 春節期間銷量則遠低于平常,說明加油站銷量與節假日特征有較強的相關性。
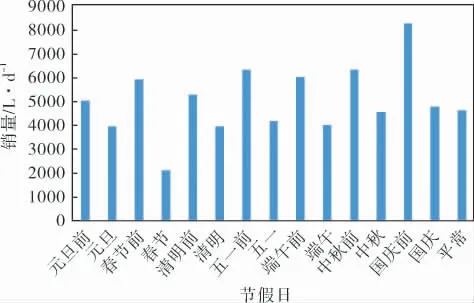
圖7 節假日與銷量
3.1.2 特征篩選
由于考慮到所增加的特征可能與銷量并沒有太大的關聯性,于是將這些特征通過隨機森林[10]評估其特征重要性。
使用隨機森林進行特征重要性評估,即計算隨機森林中的每棵樹特征重要性評分并取平均值。 通常可以用基尼指數作為評價指標來衡量。

其中,K表示隨機森林有|K|個類別,pmk′表示節點m中類別k′所占的比例,pmk表示節點m中類別k所占的比例。
特征Xj在節點m的重要性, 即節點m分支前、后的基尼指數評分變為:

其中,GIl和GIr分別表示分支后兩個新節點的基尼指數。
假設特征Xj在決策樹i中出現的節點為集合M,那么特征Xj在第i棵樹的重要性為:
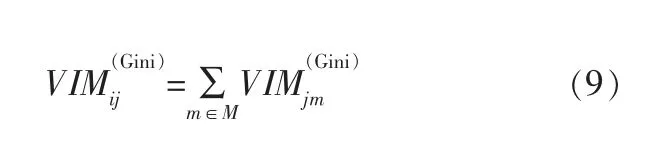
假設隨機森林中共有n棵樹,則:
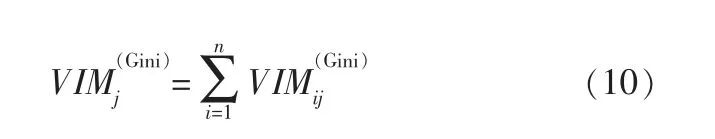
最后,把求得的重要性評分做歸一化:
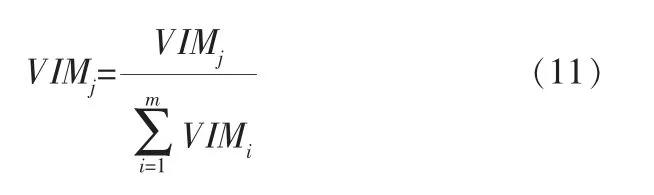
溫度、星期、天氣、油價、節假日通過隨機森林得到的特征重要性評分如圖8所示,可以看出,天氣和溫度特征的重要性評分都較低,但是考慮到惡劣天氣對銷量的影響較大,僅把溫度特征刪除。 從客觀角度分析,之所以溫度對于銷量影響不大,其實是地域因素,即本項目預測的加油站地處昆明,溫度變化相對較小,如果要預測每年溫差較大的地區,溫度特征需保留。
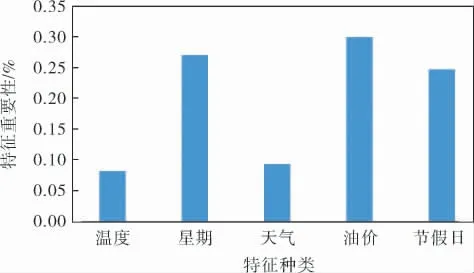
圖8 隨機森林特征重要性評分
3.2 建模過程
本項目的建模流程如圖9所示。

圖9 建模流程
本項目原始數據為時間與銷量的時間序列數據,建模過程如下:
a. 特征提取。加入溫度、天氣、油價、節假日、星期特征。
b. 特征篩選。通過隨機森林對擴充特征進行特征重要性評分,將溫度特征刪除。
c. 文本編碼。 對天氣和星期這兩個文本類特征進行One-hot編碼; 再使用Embedding方法進行降維,將星期從1×7維度的向量降維為1×1,將天氣從1×8維度的向量降維為1×3。
d. LSTM模型預測。 將處理完畢的數據放入LSTM模型進行預測。
e. 遺傳算法調參。 將LSTM模型的超參數作為參數集合輸入遺傳算法, 并將RMSE作為目標函數,通過遺傳算法得到最優超參數。
f. 結果評估。 驗證模型的準確性。
3.3 結果分析
3.3.1 模型對比
先憑借經驗設置LSTM超參數,得到模型預測結果。 細胞單元個數設置為50,dropout參數設置為0.5,L2正則化權重參數設置為0.01, 迭代次數設置為600,batch_size設置為32。
再將LSTM中的超參數放入遺傳算法尋找最優超參數。 超參數集合有:細胞單元個數、dropout參數、L2正則化權重、迭代次數、batch_size,目標函數為RMSE。 使用遺傳算法對LSTM模型超參數進行調參,設置的種群規模參數為15,最大進化代數為15,差分進化中的參數為0.5,重組概率為0.7,編碼方式為RI。 分別調用遺傳算法5次,得到的最優參數見表1。
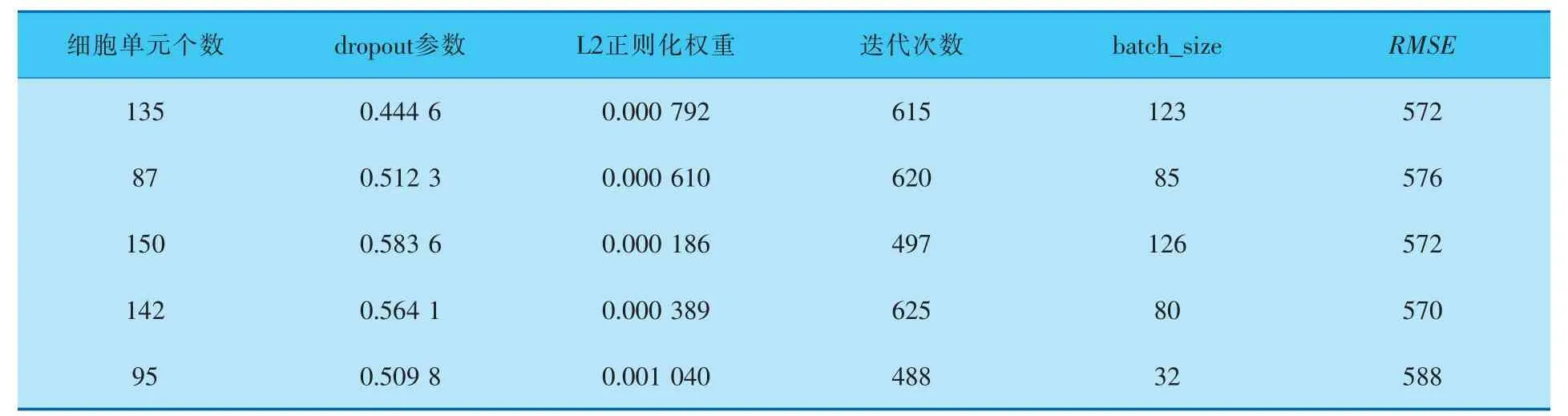
表1 遺傳算法最優超參數結果
根據最后5個結果,最終選擇的細胞單元個數為140,dropout參數為0.550 0, 全連接層L2正則化權重為0.000 400,迭代次數為620,batch_size為80。
將遺傳算法得到的最優參數作為LSTM模型的超參數, 同時將2019年1月至2021年7月共計940天的數據劃分訓練集與測試集。 將2019年與2020年作為訓練集訓練,2021年作為測試集預測,并將結果與一次指數平滑進行對比。
目前,成品油調度系統中使用的是一次指數平滑方法對加油站銷量進行預測,此方法能夠較為有效地實現短期預測,但是其與真實值相比存在滯后,其計算式為:
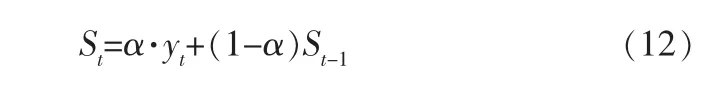
其中,St為t期平滑值,α為平滑常數,yt為t期實際值,St-1為t-1期的預測值。
3.3.2 結果分析
分別采用GA-LSTM與一次指數平滑進行預測,得到的結果見表2,預測圖像如圖10、11所示。可以看出,一次指數平滑模型存在預測滯后的問題,尤其是在春節前后的時間段,銷量波動劇烈,一次指數平滑模型預測滯后明顯,并且在測試集后半段預測一次指數平滑基本是一條直線。 而GA-LSTM的預測能較好地預測波峰和波谷,對于加油站銷量這種非線性特征明顯的數據也能有不錯的預測效果。同時因為LSTM超參數較多的原因,使用遺傳算法對LSTM的超參數進行調整,GA-LSTM模型比憑借經驗設置的LSTM模型精度提升了3%,RMSE下降了40 L/d,使得LSTM模型預測更加精確。

圖10 訓練集與測試集預測圖像
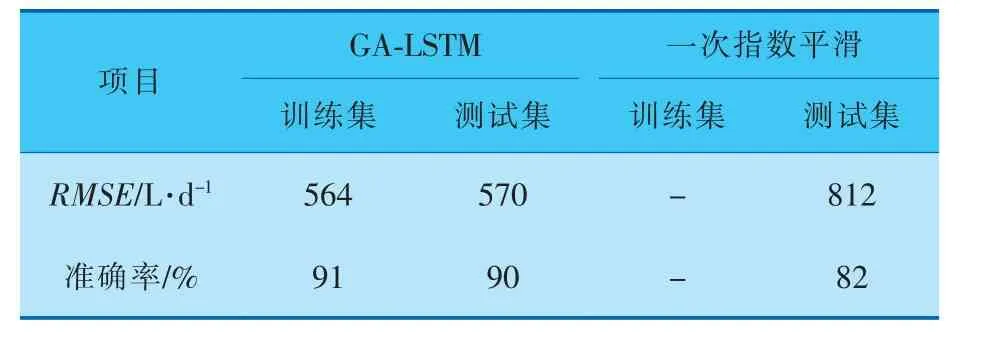
表2 不同模型結果對比
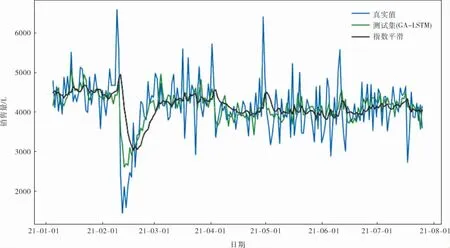
圖11 測試集預測圖像
從數據分析,GA-LSTM的RMSE比一次指數平滑要小很多,并且準確性提升了9%。同時,由于加入了節假日特征,GA-LSTM對于節假日前后銷量波動比較劇烈的部分也較為敏感,能夠進行有效預測。
4 結束語
提出基于GA-LSTM組合模型的加油站銷量預測模型, 在時間加銷量的原始數據上增加天氣、溫度、油價、星期、節假日特征來輔助預測,提升了預測精度,模型的準確率保持在90%以上,精度也高于目前的成品油調度系統中運用的一次指數平滑模型,并且該模型僅需訓練一次,之后預測直接加載模型數據即可, 無需再次訓練,具有實際落地應用的良好前景。 模型的預測靈活性強, 可以通過前m天的數據預測后n天的數據,來滿足不同預測的需求。 該模型不僅適用于加油站銷量預測,還適用于其他受多種因素影響的銷量預測。
進一步的探究為加入注意力機制和挖掘潛在影響銷量的特征。 將該模型配置在企業的成品油調度系統中,使得該預測模型能在企業系統中落地應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
