一種基于目標空間轉換權重求和的超多目標進化算法
2022-05-28 10:33:58梁正平駱婷婷王志強朱澤軒胡凱峰
自動化學報 2022年4期
關鍵詞:方法
梁正平 駱婷婷 王志強,2 朱澤軒 胡凱峰
現實應用中存在各種各樣的多目標優化問題(Multi-objective optimization problems,MOPs),如電能分配[1]、污水處理控制[2]、服務質量優化[3]、車輛路徑規劃[4]、軟件項目管理[5]、微電網管理[6],等等.由于MOPs 的不同目標函數之間通常相互沖突,MOPs 的最優解集不是單一的解而是一組折衷解,即帕累托最優解集(Pareto optimal set).雖然一些性能優越的多目標進化算法(Multi-objective evolutionary algorithms,MOEAs),如NSGA-II[7],SPEA2[8]和MOEA-PPF[9]等能很好的處理MOPs,但在解決超多目標優化問題(Many-objective optimization problems,MaOPs)時,上述算法的性能將顯著下降.原因是隨著目標函數的增加,非支配個體在種群中所占的比例將呈指數式增長,基于帕累托關系的算法會逐漸喪失收斂壓力[10].為解決該問題,學術界從不同角度對超多目標進化算法(Manyobjective evolutionary algorithms,MaOEAs) 進行了較廣泛的探討[11-15],大致可分為以下四類:1) 基于放松支配.該類算法的主要思想是通過擴大支配范圍來增強種群往PF 方向收斂的壓力.代表性方法有?支配[16],L支配[17]和模糊支配[18-19]等;2) 基于指標.該類算法將個體的指標值作為環境選擇的衡量標準,如IBEA[20],HypE[21]和ARMOEA[22]等;3) 基于分解.該類算法將MaOPs 分解為多個單目標優化問題(Single-objective optimization problems,SOPs)[23],隨后在進化框架下同時優化這些SOPs,如MOEA/D[24],NSGAIII[25]和SPEAR[26]等.4)混合型.該類算法采用兩種或者兩種以上的方法來實現對超多目標問題的優化,如Two_arch2[27]和HpaEA[28]均融合了基于支配和基于指標的方法,SRA[29]則采用了多指標的策略.在上述算法中,基于分解的MaOEAs 受到了學術界的高度關注,該類算法的核心是對參考向量和分解方法的設計.
參考向量主要影響種群在PF 上分布的均勻性,即多樣性.在經典的分解類算法MOEA/D 中,采用一組均勻分布在目標空間上的向量集作為參考向量.該參考向量在規則PF 問題上能取得優越的性能,但不能很好地處理退化、不連續、凹凸混合等不規則PF 問題.原因在于不規則PF 上參考向量的分布不均勻,進而造成種群在PF 上分布不均勻.針對該問題,學術界提出了很多對均勻分布的參考向量進行調整的方法,如CA-MOEA[30]通過層次聚類方法來調整每代的參考向量,MOEA-AWA[31]則根據種群中的精英個體來對參考向量進行調整,類似的調整方法還有g-DBEA[32]和DDEANS[33]等.然而,由于頻繁調整參考向量,參考向量調整類算法的性能在處理規則PF 問題時容易惡化[34].
分解方法主要影響種群的搜索效率,即收斂性.現有研究表明[35-37],切比雪夫方法可有效處理各種PF 形狀的問題但搜索效率很低,權重求和方法雖然不能處理好非凸PF 問題但搜索效率卻很高.為此,Ishibuchi 等提出了兩種改進方案,分別為自適應切比雪夫和權重求和方法AS[37],同時使用切比雪夫和權重求和方法SS[38],以綜合切比雪夫和權重求和各自的優勢.此外,Wang 等提出了局部權重求和方法LWS[39],在綜合性能上取得了顯著的效果.但由于LWS 加入了局部的思想,一定程度上降低了權重求和方法的搜索效率.
總體而言,雖然學術界已對基于分解的MaOEAs進行了較廣泛研究,但該類方法的性能仍存在較大提升空間.為盡可能不損害權重求和方法搜索效率高的優勢,同時又能處理好各類PF 為非凸型的問題,本文從改進現有分解方法的角度,提出了一種基于目標空間轉換權重求和的超多目標進化算法,簡稱NSGAIII-OSTWS.其中目標空間轉換權重求和(Objective space transformation based weighted sum,OSTWS)將各種類型問題的PF 轉換為凸型曲面,再利用權重求和方法對問題進行優化.具體地,首先利用預估PF 的形狀計算個體到預估PF 的距離;然后,根據該距離值將個體映射到目標空間中預估凸型曲面與理想點之間的對應位置;最后,采用權重求和函數計算出映射后個體的適應值,據此實現對問題的優化.為驗證OSTWS的有效性,本文在NSGAIII 框架的基礎上,將OSTWS 與現有的7 個分解方法在WFG、DTLZ 和LSMOP 測試問題集上進行了對比,同時將所提的NSGAIII-OSTWS 與9 個具有代表性的MaOEAs 進行了對比,實驗結果表明NSGAIII-OSTWS具備良好的競爭性能.
本文的內容安排如下.第1 節介紹與本文相關的背景知識.第2 節闡述目標空間轉換權重求和方法OSTWS,以及基于OSTWS 的超多目標進化算法NSGAIII-OSTWS.第3 節介紹實驗設計、實驗結果,并進行相關討論.最后對本文進行總結并指出未來的研究方向.
1 背景知識
1.1 多目標優化問題
一般來說,一個MOP 的數學定義可表述為:
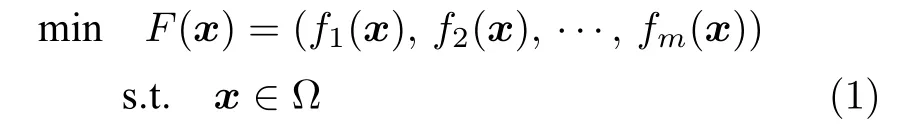
其中,x是決策空間 Ω 中的n維決策向量,m是目標函數的個數,Rm是目標空間.F:Ω→Rm組成m個目標函數.目標數m大于3 的MOPs 也被稱為超多目標優化問題,即MaOPs.假設x和y是決策空間中的兩個不同候選解,x支配y(記為x?y) 當且僅當?i∈{1,2,···,m},fi(x)≤fi(y) 且?i ∈{1,2,···,m},fi(x)<fi(y).如果候選解x不被任何其他解所支配,則稱候選解x為帕累托最優解.所有帕累托最優解的集合稱為帕累托最優解集(Pareto optimal set,PS),即PS={x/?y ∈Ω,x ?y}.所有帕累托最優解對應的目標向量構成帕累托最優前沿(Pareto optimal front,PF),即PF={F(x)|x ∈PS}.
1.2 分解方法
分解方法決定了基于分解的MaOEAs 的搜索效率,對算法的性能有著重要影響.研究者們設計了許多不同的分解方法,并在各種MaOPs 上展現出了優越的性能.常見的分解方法有以下三種:
1)權重求和(Weighted sum,WS)法:WS 方法通過加權的方式將所有目標組合成一個單一的目標,其數學定義如下:
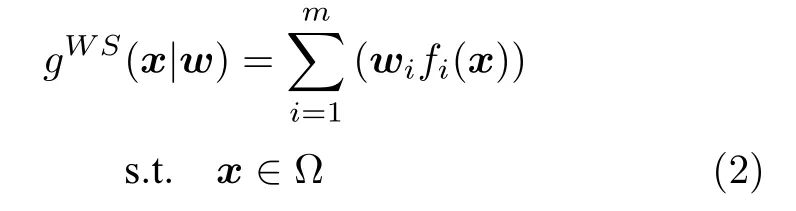
2)切比雪夫(Techebycheff,TCH)法:TCH 方法將MaOP 轉化為一個SOP 的數學定義如下:
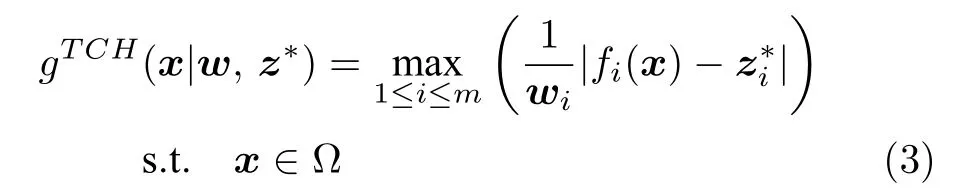

3)基于懲罰的邊界交叉(Penalty-based boundary intersection,PBI)法:PBI 方法構造子問題的數學定義如下:
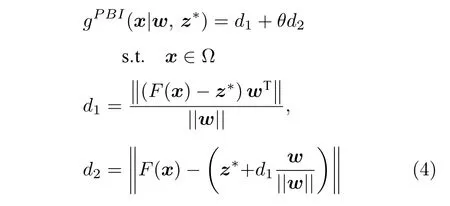
其中,θ(θ>0) 為一個事先設定的懲罰因子,d1為向量 (F(x)-z*) 在權重向量w上的投影長度,d2為F(x)到w的垂直距離.圖1(c)為PBI 方法的示意圖.由PBI 的定義(式(4)) 和圖1(c) 可知,θ是平衡收斂性(用d1衡量)和多樣性(用d2衡量)的關鍵性參數.近來有研究表明[43-44],當PBI 處理PF為凸的問題時,較大的θ可以獲得較好的種群分布,而較小的θ值有利于種群更好地收斂到PF.

圖1 分解方法WS,TCH 和PBI 在參考向量w 上的二維示意圖,其中虛線為等高線Fig.1 Illustration of the decomposition methods WS,TCH and PBI on reference vector w,where dashed lines are contour lines
2 NSGAIII-OSTWS 算法
2.1 動機
在基于分解的算法中,分解方法將MaOP 轉化為若干個SOPs,然后在進化框架下以協同的方式優化每個SOPs.如果沒有選擇合適的分解方法,或者使用的分解方法不能很好地將MaOP 轉化為SOPs,基于分解的MaOEAs 最終獲得的種群就有可能無法逼近PF.
目前,上節介紹的三種分解方法,即WS、TCH和PBI,已在基于分解的MaOEAs 中被廣泛應用.圖1 是這三種方法在二維目標空間下的示意圖.每個子圖中的等高線將目標空間劃分為兩個區域,位于同一條等高線上的解具有相同的質量,靠近理想點z*區域的解質量則要優于另外一區域.如圖1(a)所示,WS 的等高線是一條經過候選解且垂直于參考向量的直線,其優越區域[39]占整個區域的1/2.從圖1(b)可以看出,TCH 的等高線則為經過候選解和參考向量的兩條相互垂直的直線,其優越區域為 1/ 2m,隨著目標函數m的增加,該值會顯著減小.圖1(c)中,PBI 的等高線是經過候選解和參考向量的兩條相交直線,它的優越區域由懲罰因子θ決定.θ值越大,則優越區域的面積越小,通常情況下該區域的面積小于整個區域面積的1/2.由上述分析可知,WS 的優越區域是最大的.換言之,采用WS 可以更大概率搜索到比目前更優的解,即收斂速度最快.然而,當采用WS 處理非凸問題時,PF 中的大部分點會被丟失[24],從而嚴重損失種群的多樣性[39].綜上所述,相比TCH 和PBI 而言,WS 具有更強的收斂性但卻不能處理好非凸問題.
為充分發揮WS 搜索效率高的優勢,同時又能處理好各類PF 形狀為非凸的問題,研究者們提出了一些WS 的改進方法,如AS[37]和SS[38]等.然而,這些方法的主要思想僅是利用TCH 方法來處理WS 不能處理好的凸型PF 問題,并未對WS 方法本身進行改進.最近,Wang 等[39]提出了一種新穎的WS 方法,即局部權重求和方法LWS.該方法的主要思想是對于每個搜索方向,只在其相鄰解中挑選最優解.LWS 方法能夠較好處理包括PF 非凸在內的各類型PF 問題,但由于LWS 在求解最優解時加入了局部的思想,也在一定程度上降低了WS方法搜索效率高的優勢.為驗證該結論,本文將LWS 方法和WS 方法分別嵌入到基于分解的算法NSGAIII[25],形成算法NSGAIII-WS 和NSGAIIILWS.圖2 為這兩個算法在PF 為凸的測試問題ZDT1[45]上的最終種群分布圖.其中,運行次數為20 次,迭代次數為120 代,種群大小為200,決策變量數的大小參照文獻[45]設置,其它參數與NSGAIII保持一致.從圖2 可以看出,NSGAIII-WS 算法獲得的種群具有更好的收斂性.為盡可能發揮權重求和方法搜索效率高的優勢,同時又能處理好非凸型PF 問題,本文提出了一種新穎的方法——目標空間轉換權重求和方法.
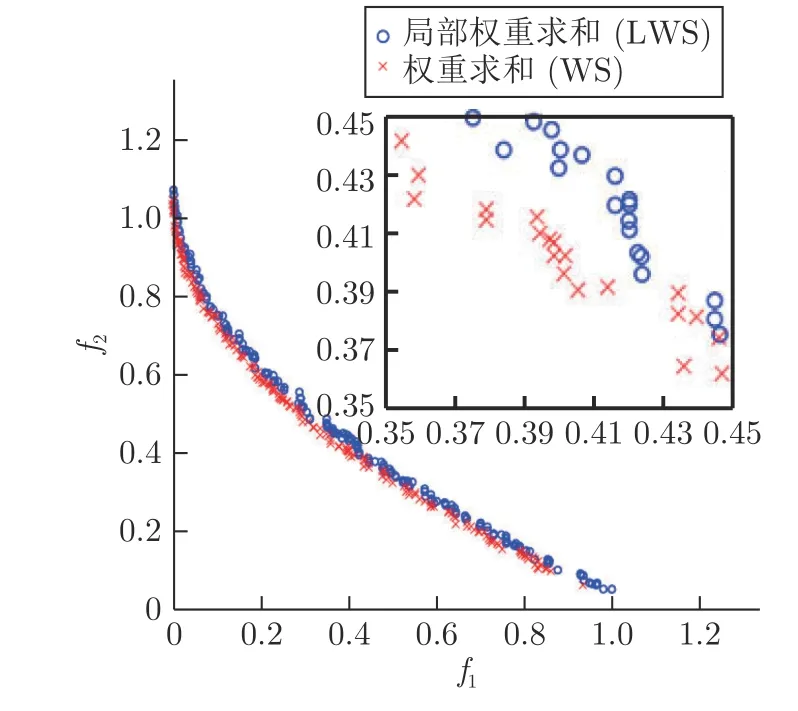
圖2 NSGAIII-WS 和NSGAIII-LWS 算法在ZDT1上獲得的最終種群分布Fig.2 The final population distribution obtained by NSGAIII-WS and NSGAIII-LWS algorithm on ZDT1
2.2 目標空間轉換權重求和方法
目標空間轉換權重求和方法OSTWS 的核心思想,是將各種問題的PF 轉換為凸型曲面,并基于該凸型曲面進行求解.OSTWS 方法的偽代碼如算法1 所示.

首先,采用NSGAIII[25]中的歸一化策略對種群U進行歸一化處理,然后利用2REA[46]中的估PF 方法預估出PF 的形狀.種群歸一化的目的是維持種群的多樣性.在進化前期,由于種群中的大部分個體并未收斂到PF,歸一化會存在較大的誤差,但在進化后期,大部分個體都已靠近或收斂到PF,此時種群歸一化所帶來的誤差會逐漸降低.預估的過程是先選取一組候選曲率p值逐一計算種群中非支配個體到理想點的Lp范式值,并據此計算出各p值所對應的標準方差.方差越小,代表該p值所對應的曲面越能擬合當前種群的分布.最終選取具有最小方差的p值所對應的曲面作為預估的PF 形狀.之后,將種群中的所有個體映射到所預估的PF 上,映射公式如下:
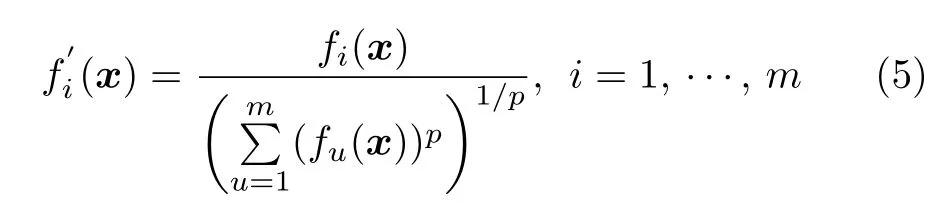
接下來,以原點作為理想點,分別計算原始個體與映射個體到理想點之間的歐氏距離值d1(x)和d2(x),并將d1(x) 減去d2(x),以此得到目標空間轉換所需的距離值d(x).隨后,根據d(x)值將個體轉換到目標空間中凸曲面與理想點之間對應的位置,從而完成目標空間的轉換.具體的做法是以等距離d(x)的形式將原始種群中的所有個體映射到預設的凸曲面內.預設凸曲面的定義如下:
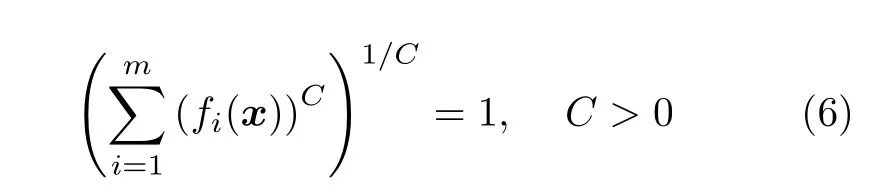
其中,[f1(x),f2(x),···,fm(x)]為預設凸曲面上的一個向量,C為預設凸曲面的曲率值,種群中個體映射到預設凸曲面內的數學公式如下:
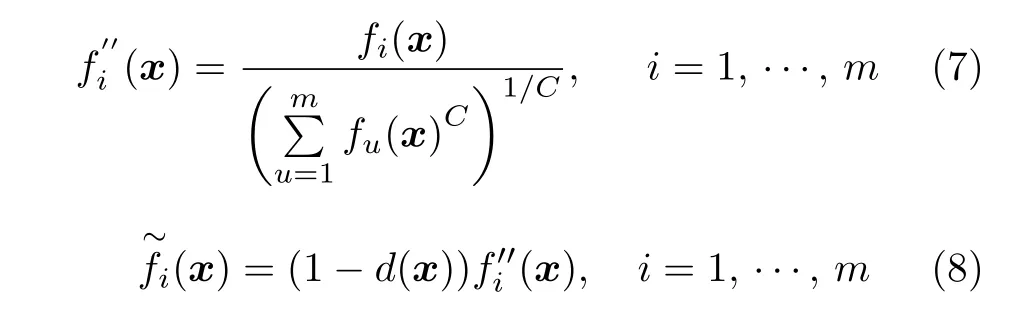
最后,將最小化求解問題轉化為最大化求解問題并采用WS 方法計算出目標空間轉換后個體的適應值,適應值越大代表個體越優秀.
為更直觀地展示OSTWS 方法,圖3 示例了使用OSTWS 方法將線形、凸形和凹形PF 中的個體轉換到凸目標空間的整個過程.以3(a)為例,首先,預估出真實PF 的形狀(直線),并將種群中的所有個體(a,b,c)映射到直線上(a',b',c'),然后計算出原始個體(a,b,c)與映射后個體(a',b',c')之間的歐氏距離值d1,d2,d3.值得注意的是,距離值(d1,d2,d3)具有正負之分,如果原始個體到理想點的歐氏距離大于映射后個體到理想點的歐氏距離,則上述距離值為正,否則為負.接下來,將原始種群中的所有個體(a,b,c)以等距離 (d1,d2,d3)形式映射到預設凸曲線內,完成種群到凸目標空間的轉換,轉換后的個體為a′′,b′′,c′′.最后,采用WS方法逐一計算個體(a′′,b′′,c′′) 的適應值,適應值越大的個體被挑選到下一代進化過程中的概率也越大.

圖3 OSTWS 方法將PF 形狀為線形(a),凸形(b)和凹形(c)種群中的個體轉換到凸目標空間的整個過程Fig.3 The whole process of transforming the population individuals from linear (a),convex (b) and concave(c) into convex objective space by OSTWS method
2.3 將OSTWS 方法整合到NSGAIII 中
在進化算法領域,MOEA/D 和NSGAII 是兩個基于分解的經典算法,NSGAIII 則是NSGAII 在高維目標空間下的改進版.相比MOEA/D,NSGAIII 專門針對MaOPs,且在高維空間下能夠更好地維持種群的多樣性[25,47-48].為公平比較各種分解方法在處理MaOPs 時的有效性,本文選擇NSGAIII作為基礎算法,并將OSTWS 方法嵌入NSGAIII形成新的算法NSGAIII-OSTWS,算法2 為其偽代碼.首先,初始化規模為N的種群U和參考向量W,然后對種群U進化過程,直至算法達到最大迭代次數.
算法2.NSGAIII-OSTWS 算法


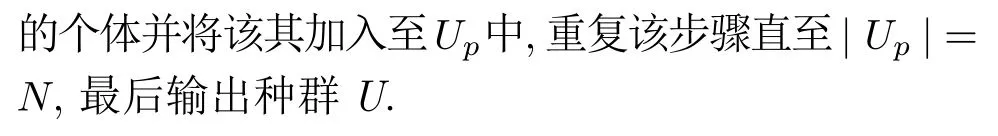
2.4 時間復雜度分析
時間復雜度是衡量算法性能的一個重要方面,影響算法的整體計算開銷.下面根據NSGAIII-OSTWS 的主要流程對其時間復雜度進行詳細分析.算法2 第4 行的子代個體生成中,二進制交叉和多項式變異需要O(DN)的計算開銷,其中D為決策變量的數量.算法2 第6 行對規模為2N的種群進行非支配層排序要花費O(Nlogm-2N)[25]的計算代價.算法2 第15 行,即算法1,其計算開銷包括以下四方面:1) 將規模為2N的種群進行歸一化(算法1 第1 行),需要O(mN) 的計算開銷.2)計算出2N個個體到預設曲面的距離(算法1 第4~7行),需要O(mN) 的計算開銷.3) 將2N個個體的目標空間轉換到特定曲面內(算法1 第8~9 行),需要O(mN)的計算開銷.4)計算目標空間轉換后2N個個體到參考向量W的權重求和值(算法1 第10~12 行),需要O(mN|W|) 的計算開銷,其中|W|是參考向量的個數.因此,算法1 的時間復雜度為O(mN|W|).之后,在最壞情況下NSGAIII-OSTWS 需對2N個個體進行參考向量的歸屬,此時需要花費O(mN|W|) 的計算代價.最后,NSGAIIIOSTWS 需挑選N-|Up |個個體至下一代進化過程需要O(L|W|) 的計算量,其中L=|Fl|.此外,在通常情況下,N≈|W|,N>m.考慮到以上因素和計算結果,NSGAIII-OSTWS 的時間復雜度為Max(O(DN),O(mN|W|)).
3 實驗與分析
3.1 實驗設置
1) 測試問題和評價指標
為檢驗NSGAIII-OSTWS 的性能,本文選取了超多目標優化領域中使用最為廣泛的兩組測試問題集WFG[51]、DTLZ[52]和最新的大規模決策變量測試問題集LSMOP[53].在DTLZ 中,DTLZ8-9 為帶約束的問題,因此本文只考慮對DTLZ1-7 問題的研究.參照文獻[39],WFG 和DTLZ 中的決策變量數目統一設置為D=100,其中WFG 中的位置變量數設為k=m-1.LSMOP 的相關參數與原文[53]保持一致.
為定量評估算法的求解性能,分別采用世代距離(Generational distance,GD[54]),覆蓋PF(Coverage over the pareto front,CPF[55]) 和修正的反轉世代距離(Modified inverted generational distance,IGD+[56]) 進行收斂性、多樣性和綜合性(平衡收斂性和多樣性的能力)性能衡量,其計算公式分別如下:
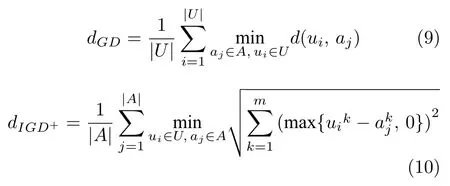
其中U為算法輸出的最終種群,A為測試問題PF面上的一組均勻參考點.對于目標維度不相同的縮放問題(如:WFG),在計算GD 和IGD+指標之前需對A和U進行歸一化處理[48].GD 和IGD+值越小,代表算法的性能越好.參照文獻[57],本實驗設置計算GD 和IGD+所需的參考點數為10 000.
2) 參數設置
由于分解算法的種群規模取決于參數H和m,其中H為沿每個目標軸所考慮的分區.為公平起見,本章所測試的目標維度及其對應的種群大小統一設置為表1 所示.為避免參考向量分布不均勻的情況,當m>5 時,本文采用兩層參考向量生成方法生成參考向量[58].交叉和變異操作所需的參數設置如表2 所示.在NSGAIII-OSTWS 中,曲率C值的參數經驗設置為2,其影響在實驗分析部分進行研究.比較算法的其他參數設置與其原始論文保持一致.所有算法的終止準則被指定為最大迭代次數(MAXGen),本文中所有測試問題的MAXGen 設為300.每個算法在每個測試問題上獨立運行20 次.為檢驗算法性能的顯著性差異,采用Wilcoxon[59]秩和檢驗來評估一種算法在GD 或IGD+值方面是否優于另一種算法.符號 “+”,“-” 和 “≈”表示相應的競爭算法在5%的顯著性水平上分別比所提算法NSGAIII-OSTWS 更好,更差和無統計性差異.
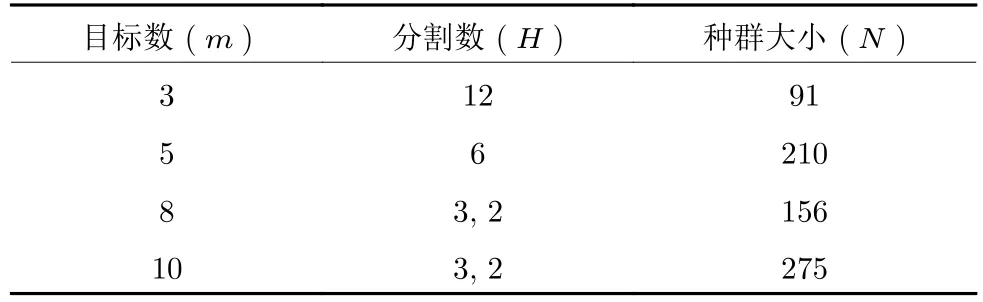
表1 種群大小設置Table 1 Setting of the population size

表2 交叉變異參數設置Table 2 Parameter settings for crossover and mutation
3.2 實驗結果與分析
1) OSTWS 方法的有效性驗證
為驗證目標空間轉換權重求和方法(OSTWS)的有效性,本小節將OSTWS 方法與其他7 個分解方法,即切比雪夫方法(TCH)、懲罰邊界交叉方法(PBI[24])、局部權重求和方法(LWS[39])、自適應切比雪夫和權重求和方法(AS[37])、同時使用切比雪夫和權重求和方法(SS[38])、自適應Lp 方法(PaS[36]) 和自適應懲罰方法(APS[60]) 在算法NSGAIII 的框架上進行比較實驗.表3、表4 和表5 分別統計了上述分解方法在DTLZ1-DTLZ7、WFG1-WFG9 和LSMOP1-LSMOP9 測試問題上所獲得的GD 均值和標準差(括號內為標準差),其中每個問題的最佳結果以灰色背景突出顯示.圖4為各個算法在所有測試問題上的平均IGD+表現分,分值越小表示該算法整體性能越好.
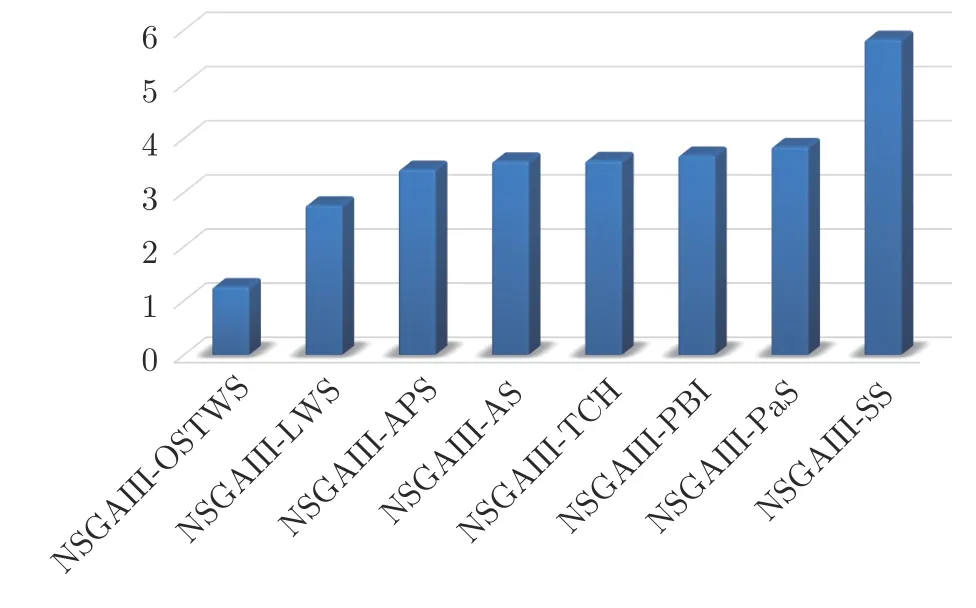
圖4 NSGAIII-OSTWS,NSGAIII-LWS,NSGAIII-TCH,NSGAIII-PBI,NSGAIII-AS,NSGAIII-SS,NSGAIII-APS和NSGAIII-PaS,在所有測試問題實例中的平均IGD+性能得分排名.得分越小,整體性能越好Fig.4 Ranking in the average performance score over all test problem instances for the algorithms of NSGAIII-OSTWS,NSGAIII-LWS,NSGAIII-TCH,NSGAIII-PBI,NSGAIII-AS,NSGAIII-SS,NSGAIII-APS and NSGAIII-PaS.The smaller the score,the better the overall performance in terms of IGD+
由表3、表4 和表5 可以看出,NSGAIII-OSTWS 在絕大部分DTLZ 測試問題上都取得了最佳GD 均值,此外,雖然NSGAIII-OSTWS 沒能在所有的WFG 和LSMOP 測試問題中獲得最具競爭力的GD 性能,但總體上獲得了最優的性能,這表明本文所提出的OSTWS 方法是非常有效的,原因在于充分利用了WS 方法搜索效率高的優勢.
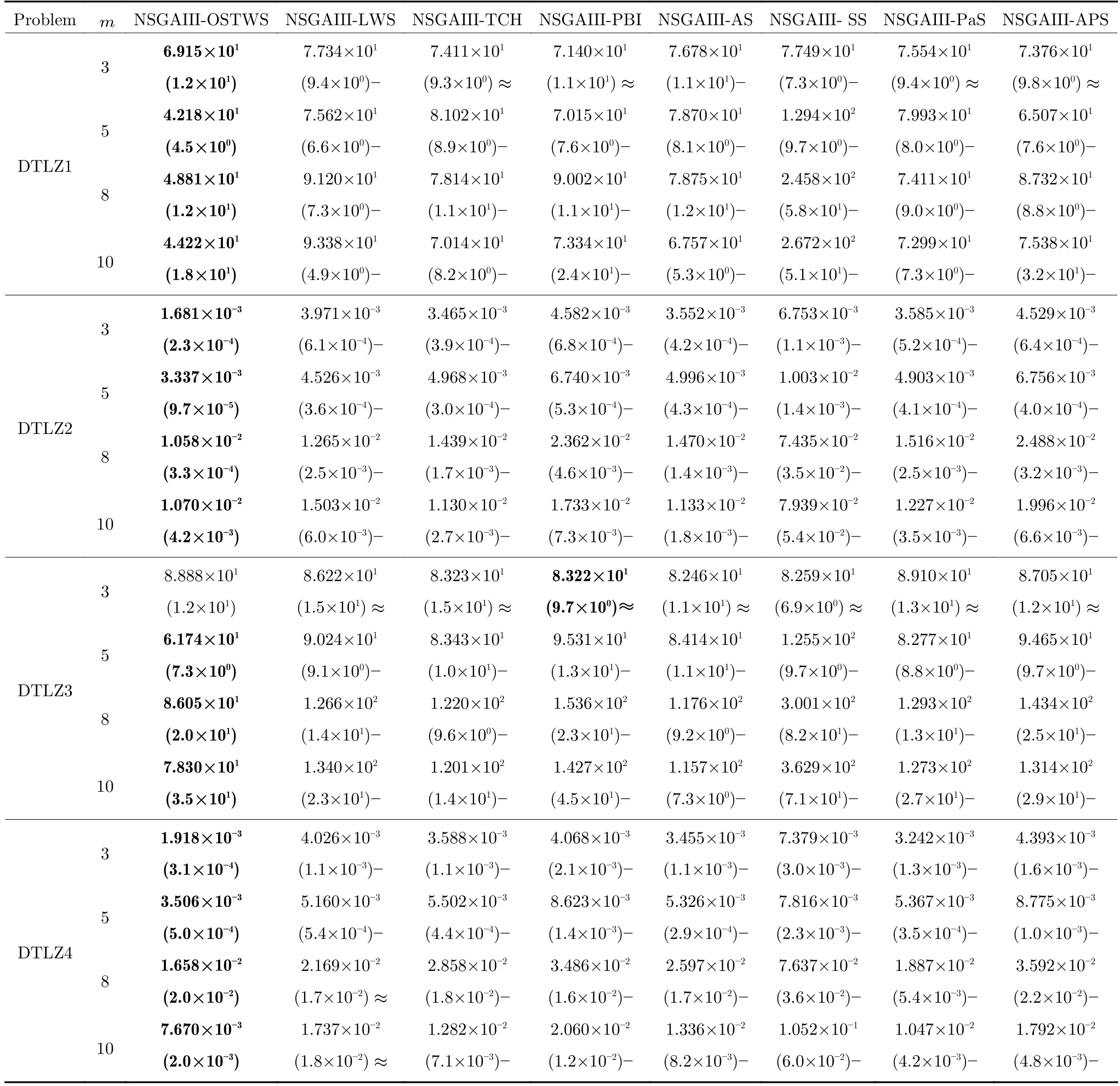
表3 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題為DTLZ1-7 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示Table 3 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and DTLZ1-7 test problems.The best average value among the algorithms for each instance is highlighted in bold
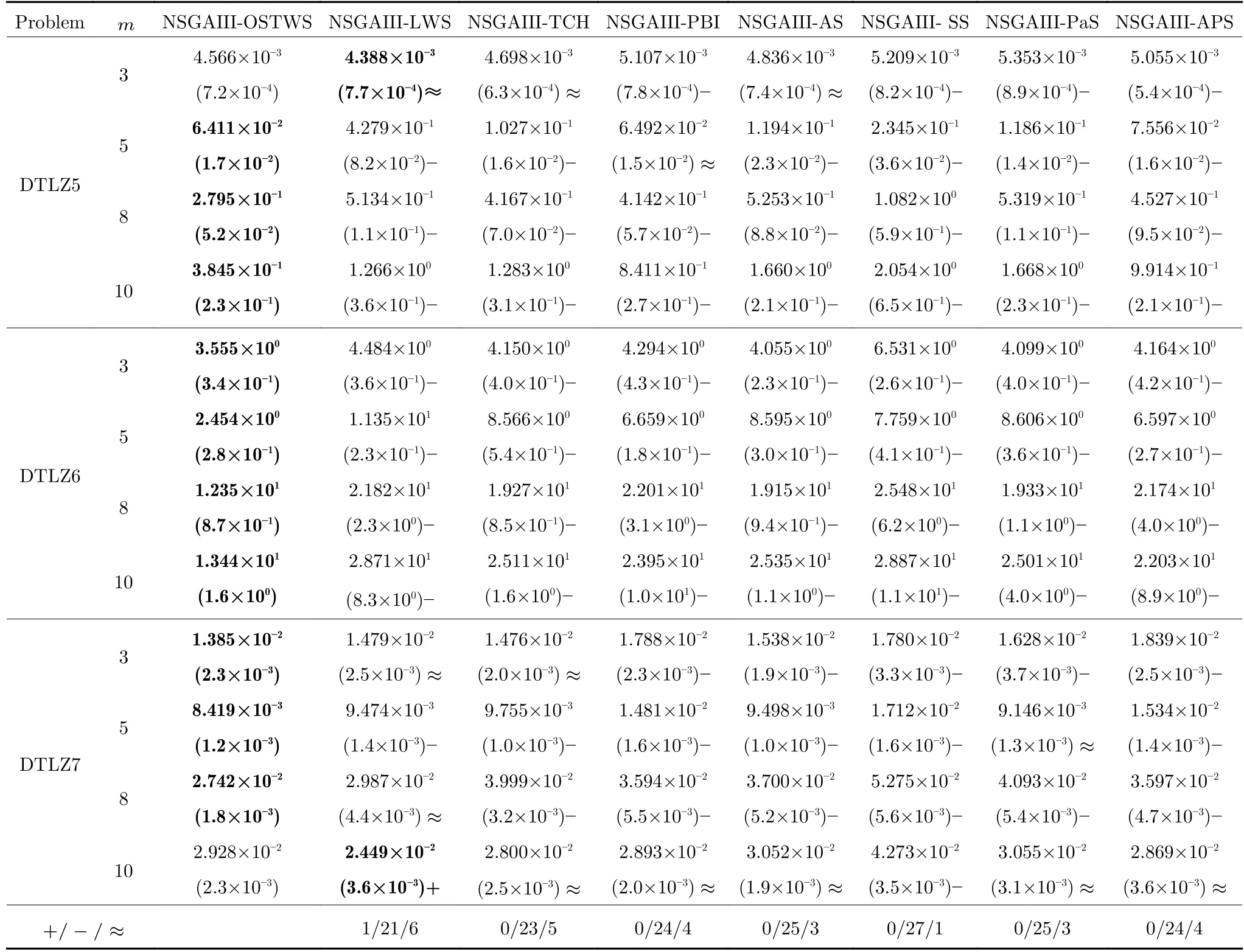
表3 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題為DTLZ1-7 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示 (續表)Table 3 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and DTLZ1-7 test problems.The best average value among the algorithms for each instance is highlighted in bold (continued table)
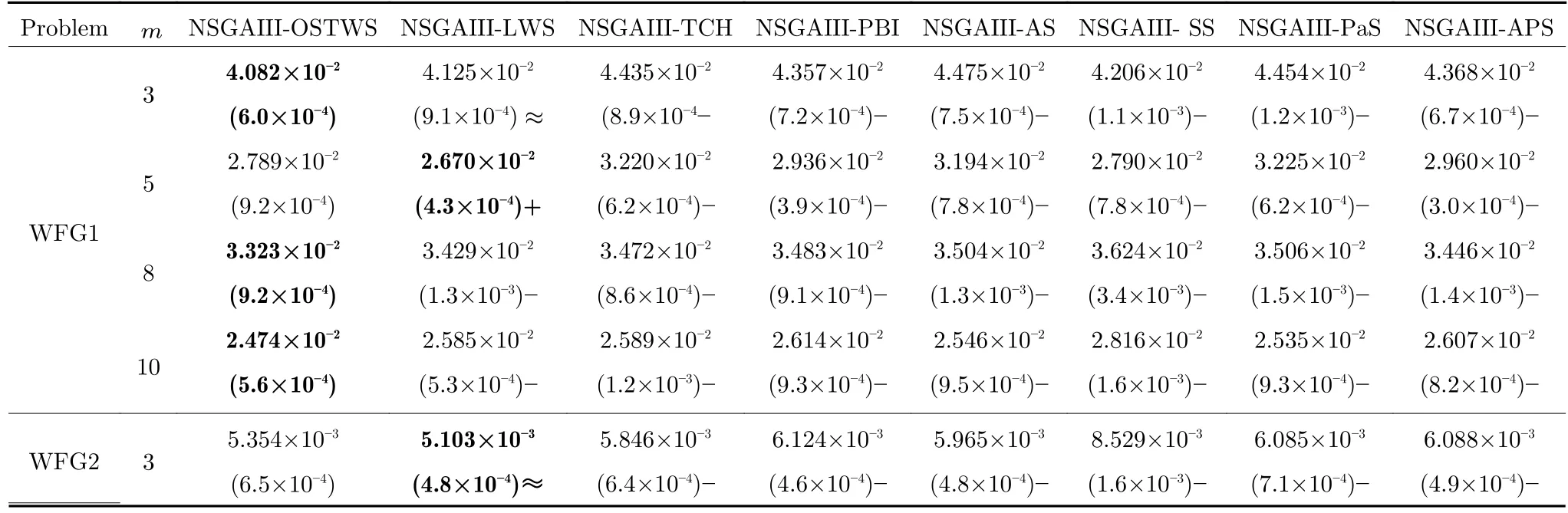
表4 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題集為WFG1-9 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示Table 4 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and WFG1-9 test problems.The best average value among the algorithms for each instance is highlighted in bold
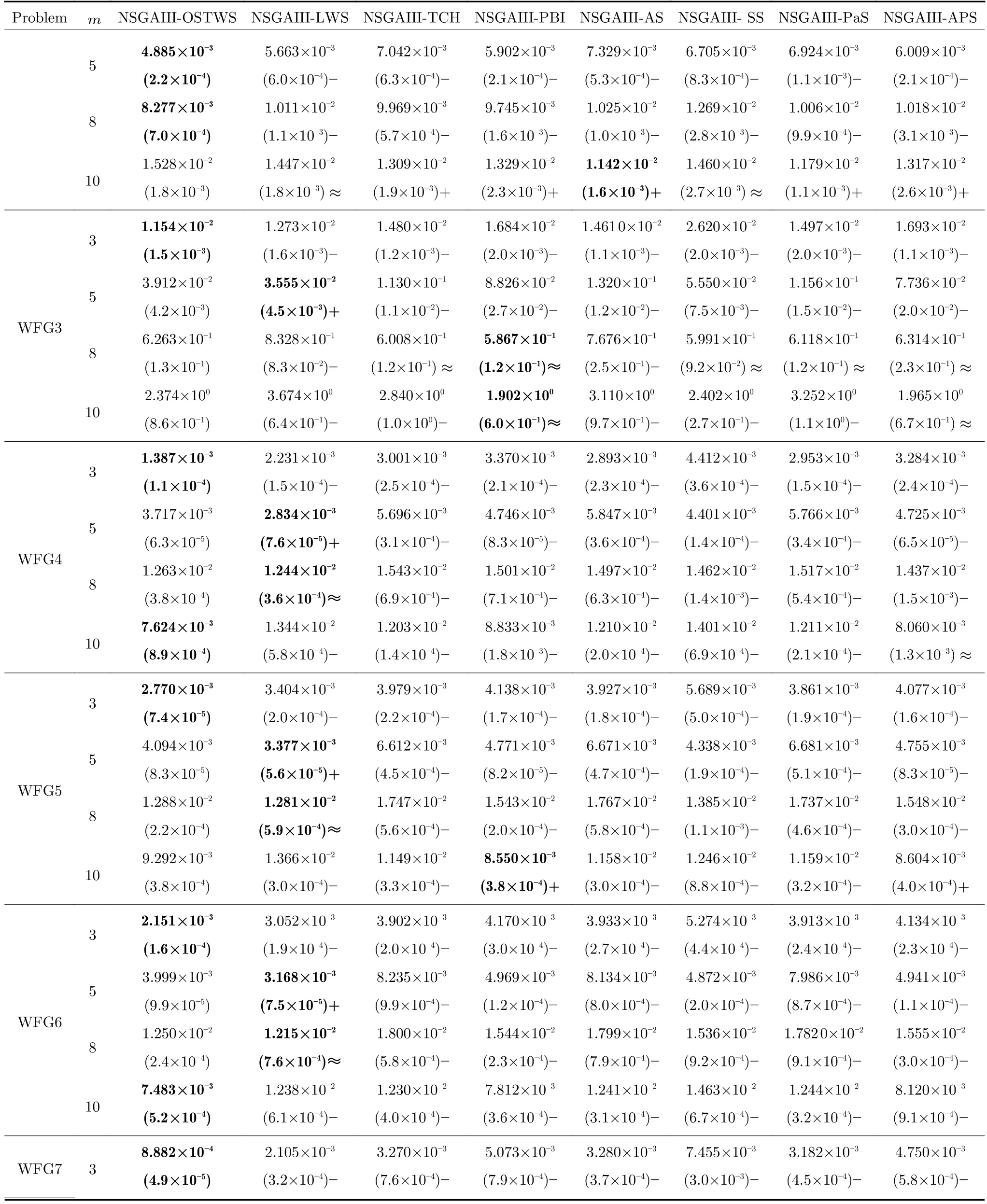
表4 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題集為WFG1-9 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示 (續表)Table 4 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and WFG1-9 test problems.The best average value among the algorithms for each instance is highlighted in bold (continued table)
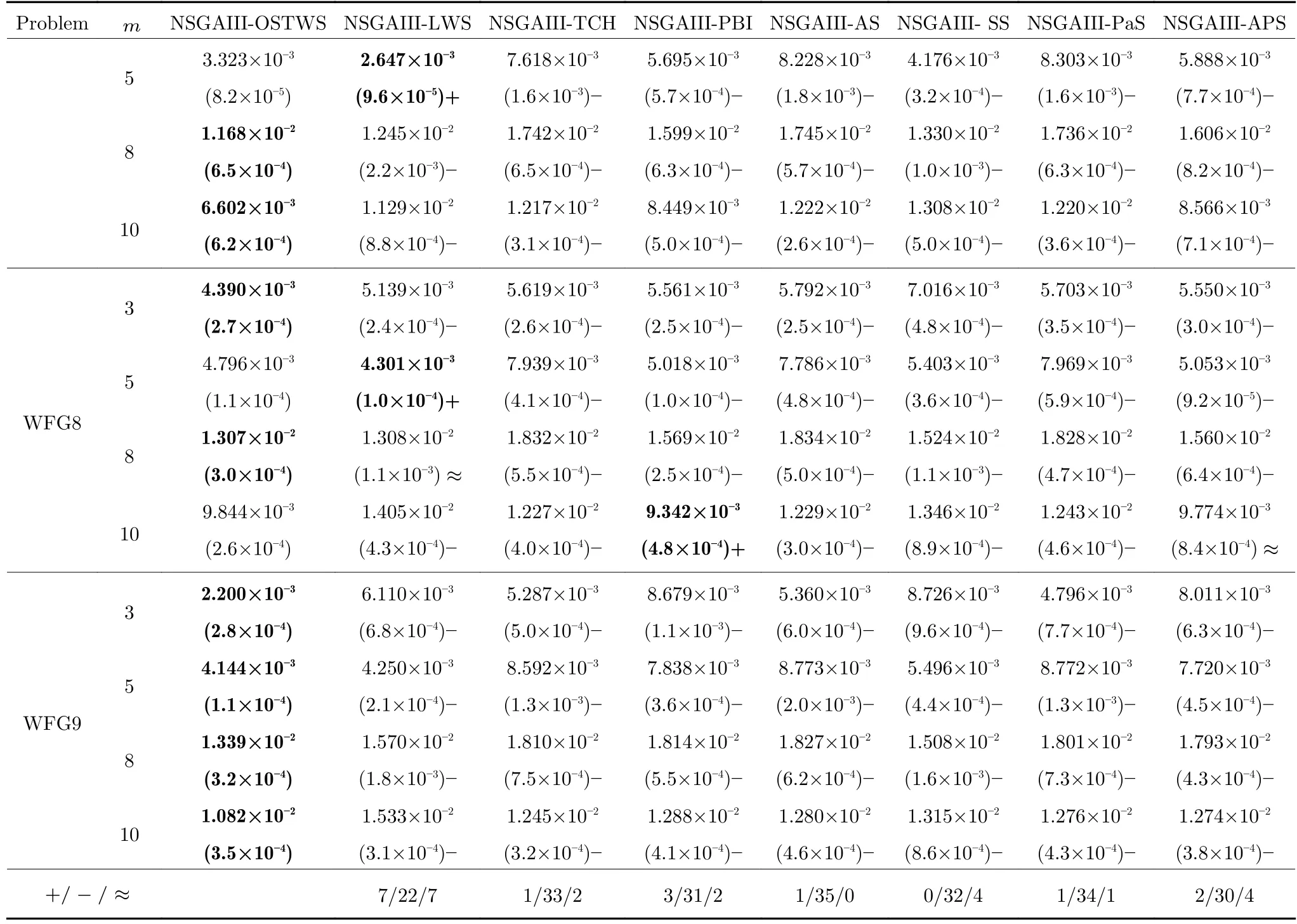
表4 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題集為WFG1-9 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示 (續表)Table 4 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and WFG1-9 test problems.The best average value among the algorithms for each instance is highlighted in bold (continued table)
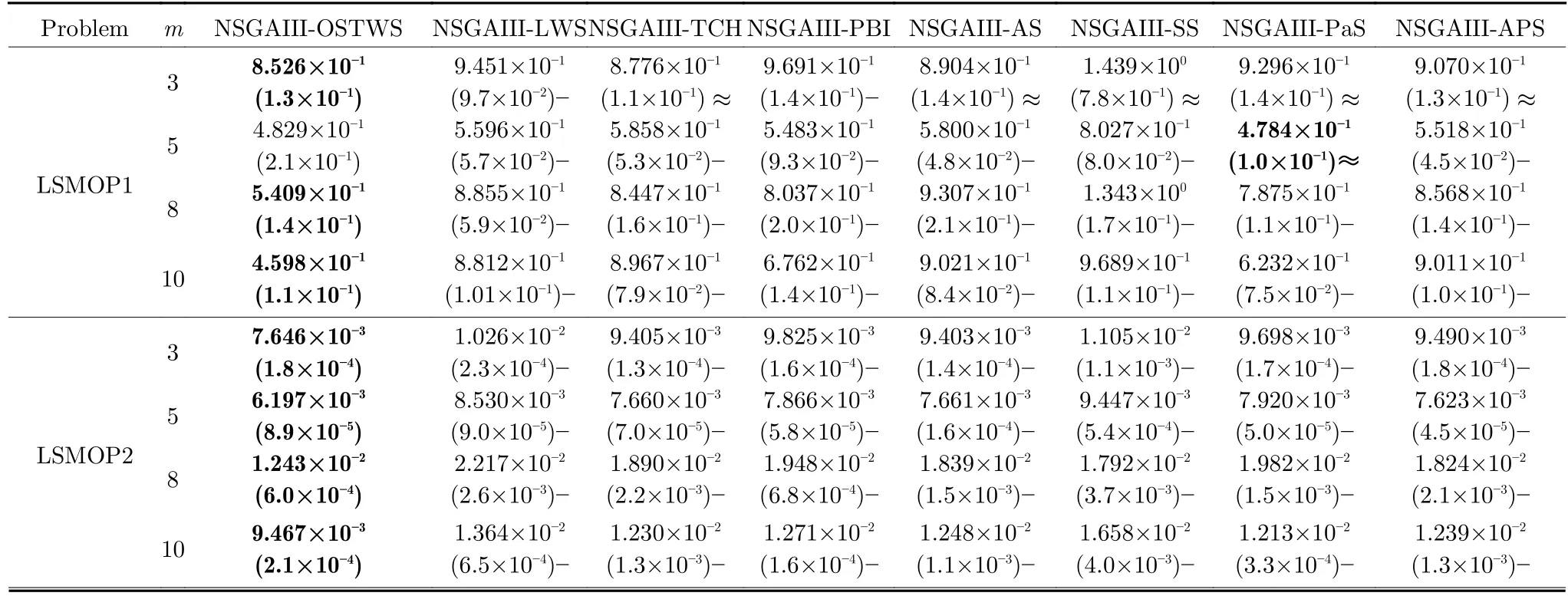
表5 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題集為LSMOP1-9 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示Table 5 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and LSMOP1-9 test problems.The best average value among the algorithms for each instance is highlighted in bold
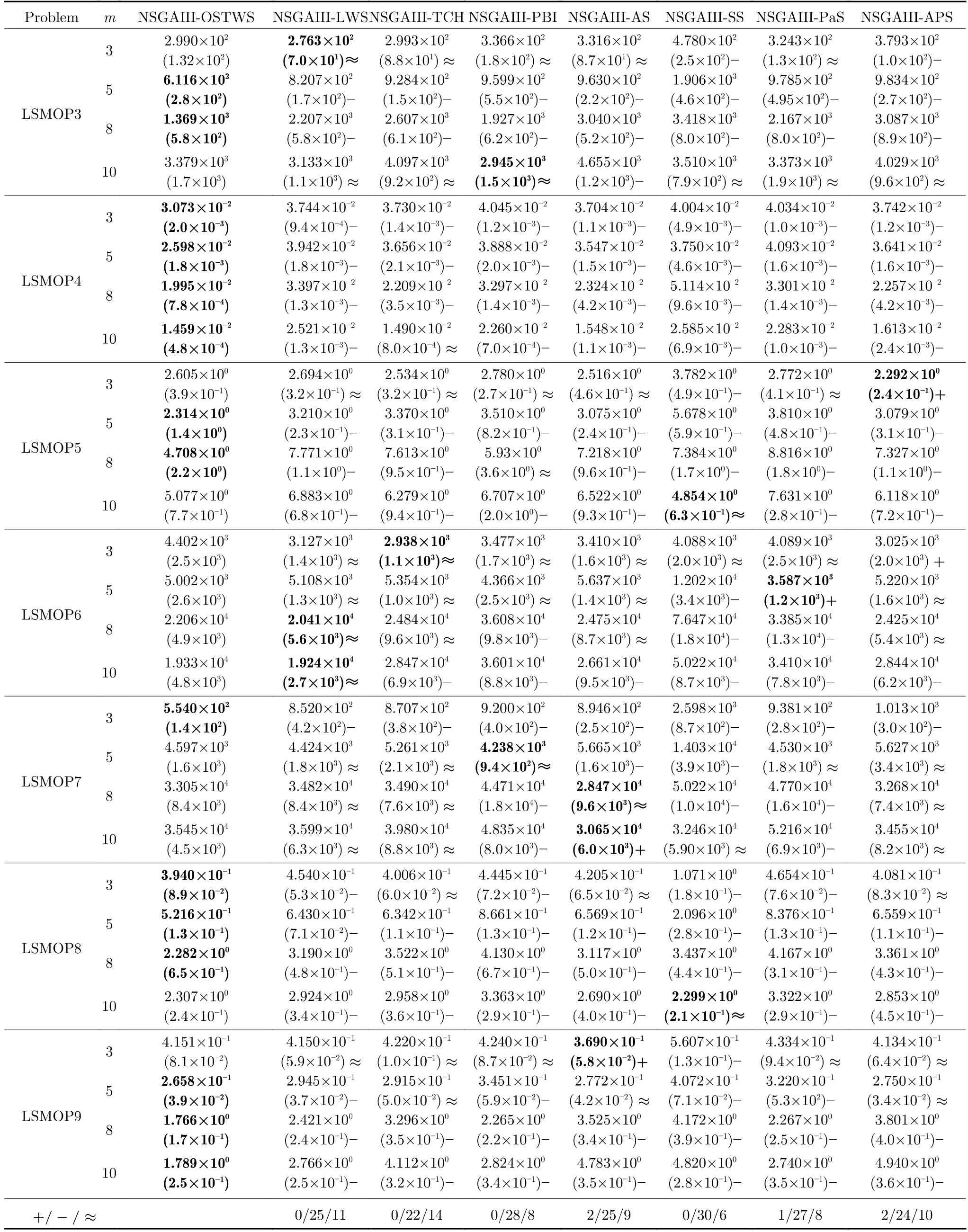
表5 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題集為LSMOP1-9 上獲得的GD 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示 (續表)Table 5 The statistical results (mean and standard deviation) of the GD values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and LSMOP1-9 test problems.The best average value among the algorithms for each instance is highlighted in bold (continued table)
下面具體分析各個算法在DTLZ1-DTLZ7、WFG1-WFG9 和LSMOP1-LSMOP9 測試問題上的性能.DTLZ1 是一個線性問題,NSGAIII-OSTWS 在該問題上獲得了最佳的GD 值,即在線性的DTLZ1 問題上,OSTWS 方法的收斂性要強于其它所對比的分解方法.DTLZ2-4 和WFG4-9 為凹問題,對于DTLZ2-4,NSGAIII-OSTWS 獲得了最優性能.為直觀展示各個算法在凹問題上的收斂性能,圖5 例舉了所有算法在10 維DTLZ2問題上的最終種群分布圖.從圖5 可以看出,算法NSGAIII-OSTWS 的種群分布在目標空間[0,1]內,其它算法的種群大部分都分布在目標空間[0,1.2]內,這表明算法NSGAIII-OSTWS 能很好的將種群收斂到PF 上,而其它算法卻不能.雖然WFG4-9同樣為凹問題,但相對于DTLZ2-4 來說,WFG4-9測試問題具有多峰、帶欺騙和變量不可分離等更加復雜的特點,從而給算法帶來了更大的挑戰.但從表4 可以看出,NSGAIII-OSTWS 在大部分WFG4-9 測試問題上都能取得最佳的性能指標值.DTLZ5-6 和WFG3 為退化問題,對于DTLZ5-6,NSGAIIIOSTWS 仍然表現出了最佳的收斂能力.在WFG3上,由GD 指標的統計數據可知NSGAIII-OSTWS 的性能則一般.WFG1 是一個凹凸混合問題,WFG2 和DTLZ7 為不連續問題,在這三個問題上,NSGAIII-OSTWS 的性能會有所下降.原因是OSTWS 很難快速且準確地預估出此類PF 的形狀,需要消耗一定的迭代次數,從而降低了種群的收斂速度.但本文所采用的預估PF 方法最終能較好地預估出這些問題的PF 形狀,故在處理這些不規則測試問題時依然取得了較好的性能.相對于DTLZ和WFG 測試問題集,LSMOP 具有更大規模的決策變量,種群的收斂難度增大,對現有的超多目標算法提出了更大的挑戰.由于OSTWS 繼承了權重求和分解方法的高搜索效率,因此相對于原始的NSGAIII 算法,NSGAIII-OSTWS 在難收斂的大規模決策變量問題處理上仍具有顯著的優勢,能較快地將種群進化至PF.從表5 可以看出,本文所提出的算法NSGAIII-OSTWS 在LSMOP 的大部分測試問題上都取得了最佳的GD 指標值,這再次驗證了OSTWS 方法具有很強的搜索效率.綜合統計結果可以看出,NSGAIII-OSTWS 在DTLZ、WFG和LSMOP 測試集上雖然沒能在每個測試實例上都獲得最優的GD 結果,但總體收斂性能優異.
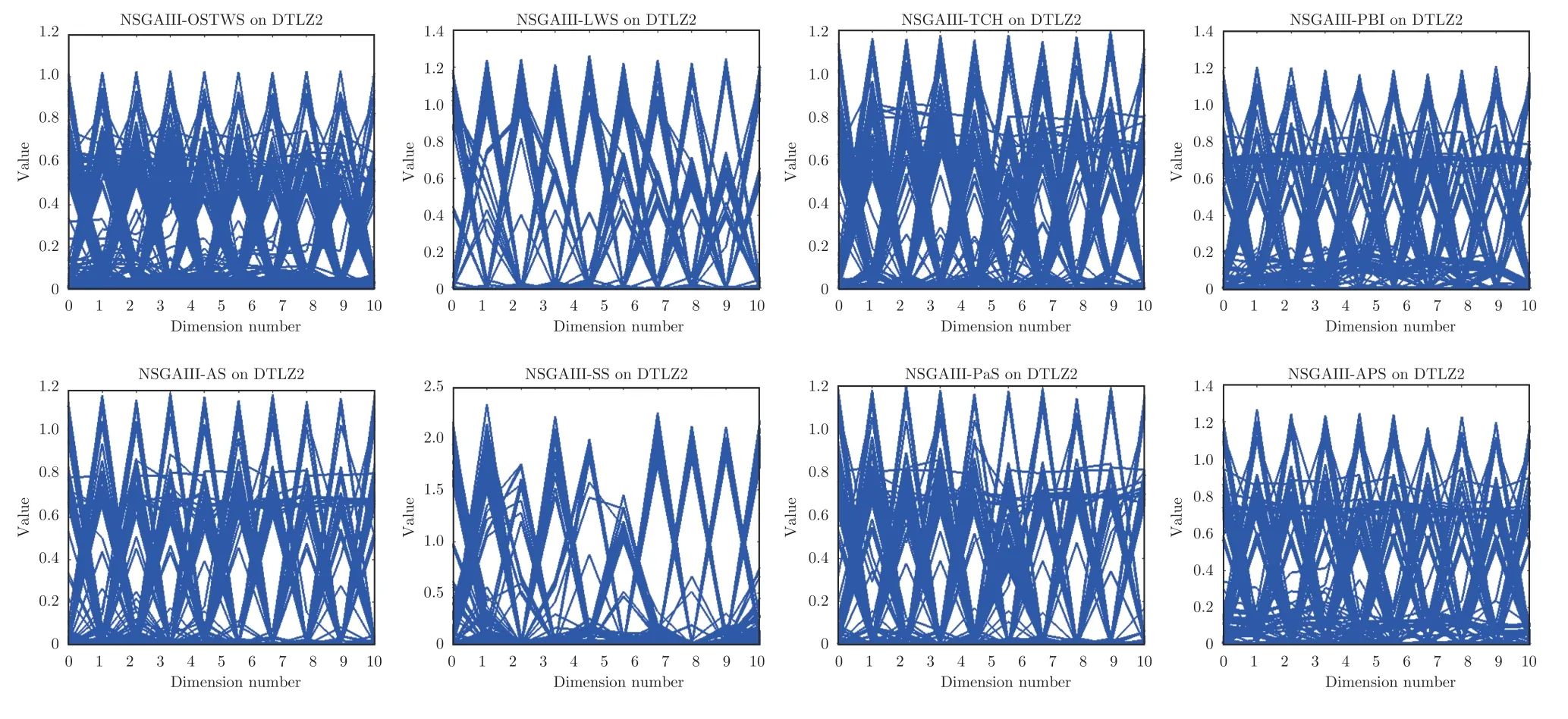
圖5 NSGAIII-OSTWS,NSGAIII-LWS,NSGAIII-TCH,NSGAIII-PBI,NSGAIII-AS,NSGAIII-SS,NSGAIII-PaS 和NSGAIII-APS 在10 維DTLZ2 問題上所獲得的解集Fig.5 Solution set of NSGAIII-OSTWS,NSGAIII-LWS,NSGAIII-TCH,NSGAIII-PBI,NSGAIII-AS,NSGAIII-SS,NSGAIII-PaS and NSGAIII-APS on DTLZ2 problem with 10-objectives
為進一步測試本文所提出的OSTWS 在多樣性維持上的性能,我們在前沿面為線性(DTLZ1)、凹型(DTLZ2)、退化(DTLZ5)和不連續(DTLZ7)的問題上,將NSGAIII-OSTWS 與其他7 個算法進行對比.表6 展示了上述算法在最新多樣性評價指標CPF 上的平均測試結果,可以看出OSTWS 在整體上取得了最佳的多樣性性能.
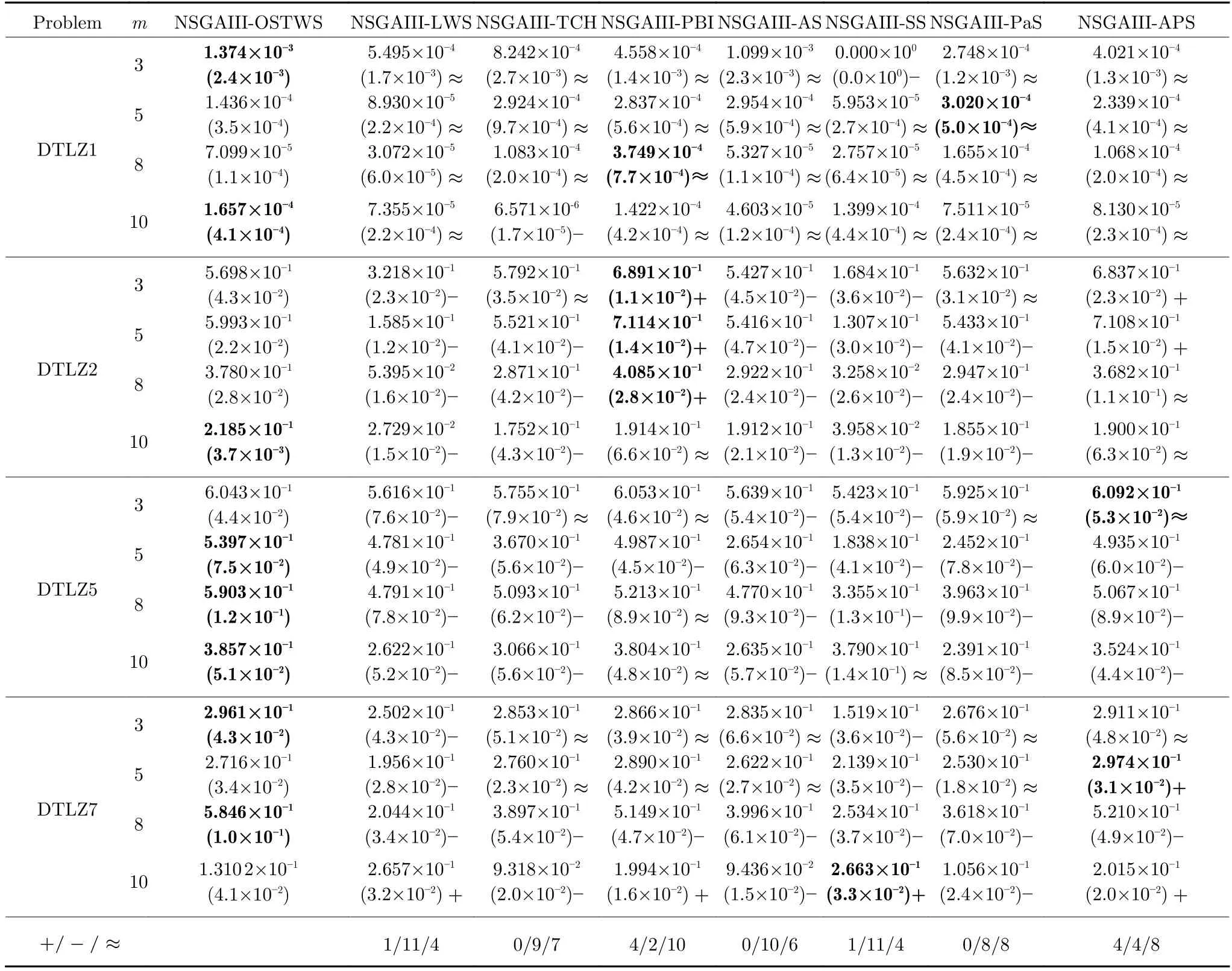
表6 OSTWS,LWS,TCH,PBI,AS,SS,PaS 和APS 方法在框架為NSGAIII,測試問題集為DTLZ1,DTLZ2,DTLZ5 和DTLZ7 上獲得的CPF 值統計結果(均值和標準差).每個實例算法中的最好結果以加粗突出顯示Table 6 The statistical results (mean and standard deviation) of the CPF values obtained by OSTWS,LWS,TCH,PBI,AS,SS,PaS and APS methods on the NSGAIII framework and DTLZ1,DTLZ2,DTLZ5 and DTLZ7 test problems.The best average value among the algorithms for each instance is highlighted in bold
為直觀地展示算法在平衡收斂性和多樣性上的綜合性能,圖4 給出了各個算法在IGD+上的性能打分圖,分值越小表示該算法整體性能越好.從圖4可以看出,算法NSGAIII-OSTWS 獲得了最小的IGD+打分值,這表明與NSGAIII 的變體相比,NSGAIII-OSTWS 具有很強的綜合性能.
2)算法整體性能驗證與分析
為測試算法NSGAIII-OSTWS 的綜合性能,將NSGAIII-OSTWS 與9 個先進的MaOEAs 進行對比實驗,分別為NSGA-III[25]、Two_arch2[27]、SRA[29]、SPEAR[26]、DDEANS[33]、HpaEA[28]、ARMOEA[22]、MaOEA-IT[61]和PaRP/EA[62].表7、表8和表9 分別為上述算法在DTLZ、WFG 和LSMOP 測試問題集上所獲得的IGD+統計結果.

表7 NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT 和PaRP/EA在DTLZ1-7 上上獲得的IGD+值的統計結果Table 7 The statistical results of the IGD+ values obtained by NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,hpaEA,ARMOEA,MaOEA-IT and PaRP/EA on DTLZ1-7
從表7,表8 和表9 的數據可以看出,與其它先進的MaOEAs 相比,NSGAIII-OSTWS 在絕大部分測試問題上取得了最佳IGD+值,這表明NSGAIIIOSTWS 在平衡收斂性和多樣性上非常具有競爭力.首先,由表7,表8 和表9 可以看出,NSGAIIIOSTWS 的性能要明顯優于經典算法NSGAIII,說明OSTWS 在很大程度上提高了NSGAIII 的整體性能,這再次驗證了OSTWS 的有效性.其次,NSGAIII-OSTWS 的整體性能要強于其它最新算法Two_arch2、SRA、SPEAR、DDEANS、HpaEA、ARMOEA、MaOEA-IT 和PaRP/EA,尤其是在規則問題上,如DTLZ1-4 和WFG4-9.原因是NSGAIII-OSTWS 在規則問題上易于預估出PF 的形狀,從而有利于加速種群的收斂.值得注意的是,DDEANS 也獲得了較好的性能,原因是DDEANS采用了參考向量調整的方法,從而能在不規則測試問題上,如DTLZ7 和WFG1-2,較好地維持種群的多樣性.

表8 NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT 和PaRP/EA在WFG1-9 上上獲得的IGD+值的統計結果Table 8 The statistical results of the IGD+ values obtained by NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT and PaRP/EA on WFG1-9

表9 NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT 和PaRP/EA在LSMOP1-9 上獲得的IGD+值的統計結果Table 9 The statistical results of the IGD+ values obtained by NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT and PaRP/EA on LSMOP1-9
為直觀展示各個算法在平衡種群收斂性和多樣性上的能力,圖6 給出了所有算法在10 維DTLZ4問題上的最終種群分布圖.從圖6 可以看出,算法NSGAIII-OSTWS 獲得的種群具有良好的收斂性和多樣性,而對比算法NSGA-III、Two_arch2、SRA、SPEAR、DDEANS、HpaEA、ARMOEA 和MaOEA-IT 獲得的種群都沒有收斂到PF,這反映了NSGAIII-OSTWS 的優越性.此外,為進一步觀察各個算法的收斂性能,圖7 給出了各個算法在DTLZ、WFG 和LSMOP 測試問題上的平均GD表現分,分值越小表示該算法的收斂性性能越好.從圖7 可以看出,算法NSGAIII-OSTWS 在絕大部分測試問題上都獲得了最低的GD 表現分,表明與其它類型的算法相比,NSGAIII-OSTWS 具有很強的收斂能力,這歸功于NSGAIII-OSTWS 算法采用的OSTWS 方法具有很高的搜索效率,從而使得種群能快速的收斂到PF.但對于退化和不連續的不規則測試問題DTLZ5-7,由于較難準確預估出真實PF 的形狀,導致NSGAIII-OSTWS 在處理DTLZ5-7 問題時收斂性會有所下降.
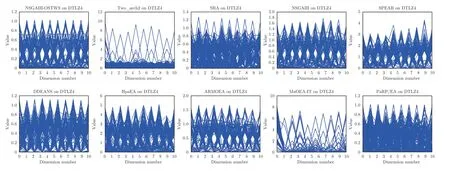
圖6 SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT 和PaRP/EA 在10 維DTLZ4 問題上所獲得的解集Fig.6 Solution set of NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS HpaEA,ARMOEA,MaOEAIT and PaRP/EA on DTLZ4 problem with 10-objectives
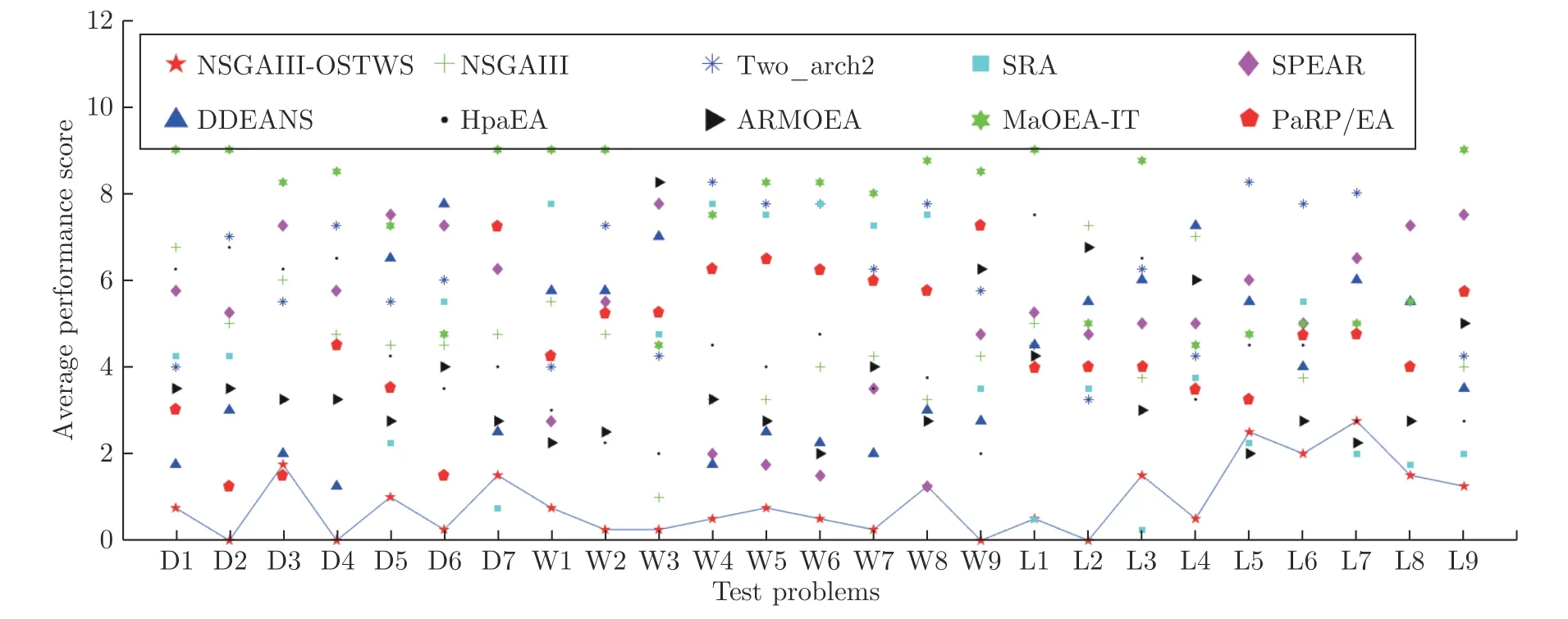
圖7 NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT 和PaRP/EA在所有測試問題,即DTLZ(Dx),WFG(Wx) 和LSMOP(Lx) 上的平均GD 表現分,分值越小,算法的整體性能越好.通過實線連接NSGAIII-OSTWS 的得分,以便易于評估分數Fig.7 Average performance score of NSGAIII-OSTWS,NSGAIII,Two_arch2,SRA,SPEAR,DDEANS,HpaEA,ARMOEA,MaOEA-IT and PaRP/EA on all test problems,namely DTLZ(Dx),WFG(Wx)and LSMOP(Lx).The smaller the score,the better the overall performance in terms of GD.The values of NSGAIII-OSTWS are connected by a solid line to easier assess the score
3)參數C的敏感性分析
NSGAIII-OSTWS 算法的核心是將各種問題的PF 轉換為凸型曲面,其中參數C用于控制預設凸曲面的曲率,因此對算法的性能有著一定的影響.由于預設曲面為凸形,其曲率值C>1.圖8 為不同預設凸曲線在參考向量w上獲得的最優解示意圖.從中可以看出,當 1<C <2 時,由參考向量w獲得的最優解逐漸靠近w;當C=2 時,w獲得的最優解正好位于w上;當C>2 時,w獲得的最優解逐漸遠離w.由于參考向量主要用于對種群多樣性的管理,最優解越靠近參考向量越有利于多樣性的維護,因此C值取2 相比其它取值更能維持種群的多樣性.為驗證這一結論,本小節在凹凸混合問題WFG1、凹問題WFG4、線性問題DTLZ1 和不連續問題DTLZ7 上測試了C為{1.2,2,3,4,5,6,7,8,9,10}的IGD+性能.圖9 為實驗結果,可以看出,隨著C值的增加,NSGAIII-OSTWS 的整體性能先逐漸提升后逐漸惡化,當C=2 時,算法具有最佳的性能,這驗證了當C值取2 時算法具備良好性能這一結論.
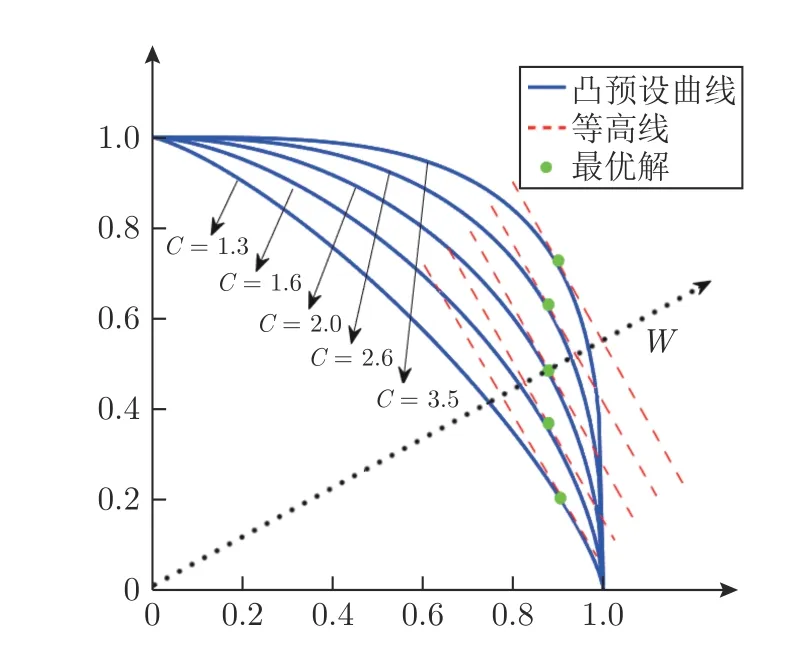
圖8 不同預設凸曲線在參考向量w 上獲得的最優解示意圖Fig.8 The optimal solution obtained by different preset convex curves on the reference vector w
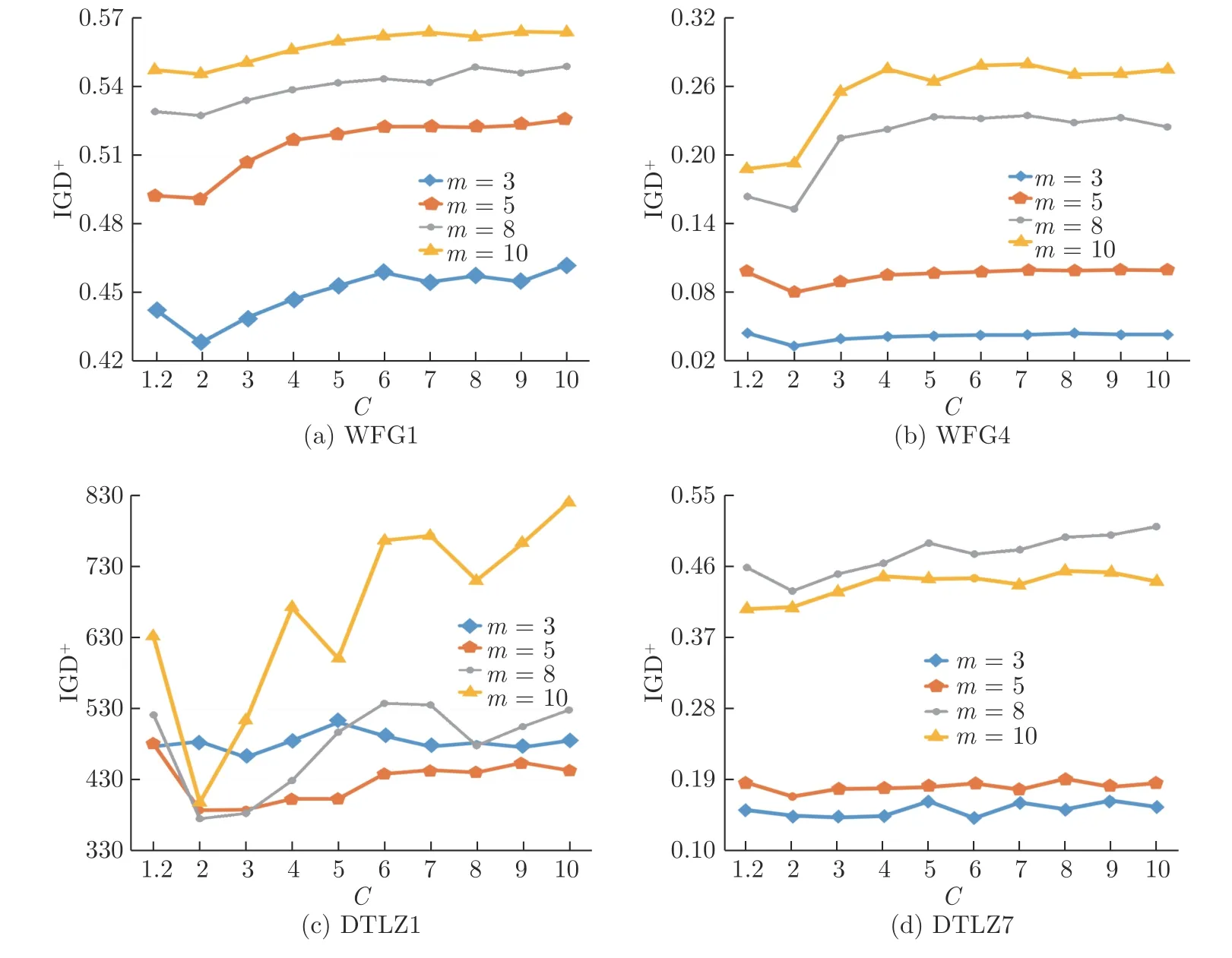
圖9 不同 C 值在WFG1,WFG4,DTLZ1 和DTLZ7 問題的3,5,8 和10 目標維度上的IGD+均值Fig.9 The median IGD+ values of different C values on WFG1,WFG4,DTLZ1 and DTLZ7 problems with 3-,5-,8-,and 10-objectives
4 結論
為充分發揮權重求和搜索效率高的優勢,同時又能處理好PF 形狀為非凸的問題,本文提出了一種基于目標空間轉換權重求和的超多目標進化算法,簡稱NSGAIII-OSTWS,其中目標空間轉換權重求和方法(OSTWS)將各種問題的PF 轉換為凸型曲面,再對其進行優化求解.為驗證NSGAIIIOSTWS 的有效性,NSGAIII-OSTWS 與7 個NSGAIII 的變體以及9 個最新的MaOEAs 在WFG、DTLZ 和LSMOP 測試問題集上進行了實驗對比.實驗結果表明,相比其他算法,NSGAIII-OSTWS具備良好的競爭性能.
雖然所提算法NSGAIII-OSTWS 在處理MaOPs 上取得了優越的性能,但仍有一些開放性的工作值得進一步的探索.例如,不規則問題的PF 形狀難以精確預估,這勢必導致個體映射的不準確進而影響算法的性能.因此,未來需要進一步研究如何更加精確地映射個體.此外,將本文所提出的算法應用于現實生產和生活中各類實際問題的求解具有重要的價值,這也是未來需要進一步開展的工作.本文所提算法的源代碼已在https://github.com/CIA-SZU/LTT 上公開.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56