基于改進(jìn)GFCC特征參數(shù)的廣播音頻語種識別
2022-05-30 11:49:44邵玉斌杜慶治
吉林大學(xué)學(xué)報(bào)(理學(xué)版) 2022年2期
邵玉斌, 陳 亮, 龍 華, 杜慶治
(昆明理工大學(xué) 信息工程與自動化學(xué)院, 昆明 650500)
在監(jiān)聽無線廣播中, 亟待解決的問題是如何準(zhǔn)確高效地識別其他電臺語種, 從而及時(shí)將實(shí)時(shí)語音轉(zhuǎn)入相應(yīng)的翻譯器進(jìn)行翻譯. 廣播音頻的構(gòu)成復(fù)雜, 包括背景音樂、 噪聲、 男女說話的不同等干擾因素, 更增加了語種識別(language identification, LID)的難度. 目前, 通常使用包括神經(jīng)網(wǎng)絡(luò)、 機(jī)器學(xué)習(xí)等方法提取與語種相關(guān)的特征進(jìn)行學(xué)習(xí)建模, 從而提高語種識別的準(zhǔn)確率.
如何去除不相關(guān)因素的干擾, 從一段語音信號中提取能描述語種特征的特征參數(shù), 是語種識別的關(guān)鍵. 傳統(tǒng)特征參數(shù)包括Mel頻率倒譜系數(shù)(Mel-frequency cepstral coefficients, MFCC)[1]、 線性預(yù)測編碼系數(shù)(linear prediction coefficient, LPC)、 線性預(yù)測倒譜系數(shù)(linear prediction cepstrum coefficient, LPCC)、 伽馬頻率倒譜系數(shù)(gamma frequency cepstral coefficients, GFCC)[2]等. 目前, 語種識別方法的研究主要集中在如何提取有效的底層聲學(xué)特征, 輸入到對應(yīng)的模型或神經(jīng)網(wǎng)絡(luò)中進(jìn)行訓(xùn)練, 得到語種識別模型. 語種分類模型有多種, 其中包括隱Markov模型、 高斯混合模型、 SVM分類器、 I-vector[3]等. 較常用的底層聲學(xué)特征是伽馬頻率倒譜系數(shù). GFCC參數(shù)使用Gammatone濾波器代替Mel濾波器, 更好地模擬了人體耳蝸頻率特征, 再經(jīng)過離散余弦變換, 去除同一幀的不同特征維度之間的相關(guān)性, 從而能更好地對特征參數(shù)進(jìn)行建模, 達(dá)到較好的識別效果. Gammatone濾波器[4]在語音信號處理方面, 包括說話人識別、 語種識別、 語音情感識別[5]等方面應(yīng)用廣泛. 文獻(xiàn)[6]提出了使用Gammatone濾波器濾波提取GFCC參數(shù), 同時(shí)加上差分特征用于語種識別, 并使用GFCC參數(shù)提取移位差分倒譜(shifted delta cepstra, SDC)特征, 提高了語種識別的準(zhǔn)確率; 文獻(xiàn)[7]提出了用指數(shù)壓縮代替對數(shù)壓縮, 更好地模擬人耳的非線性特性, 提高了說話人識別的效果; 文獻(xiàn)[8]提出了使用融合MFCC和GFCC的特征參數(shù)用于說話人識別, 再加上一階差分和二階差分, 取得了更好的說話人識別的識別準(zhǔn)確率; 文獻(xiàn)[9]提出了在GFCC的基礎(chǔ)上, 加上多窗口估計(jì)、 均值減法、 方差去噪、 自回歸移動平均濾波等, 增強(qiáng)了說話人識別的魯棒性; 文獻(xiàn)[10]提出了一種基于聲道沖激響應(yīng)頻譜參數(shù), 并融合Teager能量算子倒譜參數(shù)的融合特征作為語種識別方法; 文獻(xiàn)[11]提出了將加權(quán)音素對數(shù)似然比(weighted phone log-likelihood ratio, WPLLR)應(yīng)用于語種識別, 有效降低了語種識別的錯(cuò)誤率. 在基于神經(jīng)網(wǎng)絡(luò)相關(guān)語種識別算法中, 文獻(xiàn)[12]提出了一種基于Senone的深度神經(jīng)網(wǎng)絡(luò)語種識別算法; 文獻(xiàn)[13]提出了LID-Senone統(tǒng)計(jì)特征, 比Senone特征能達(dá)到更好的語種識別效果. 基于深瓶頸特征(deep bottleneck feature, DBF)[14]的語種識別方法能有效抑制底層聲學(xué)特征中的背景噪聲、 說話人差異、 信道差異等影響, 從而有效提取與語種相關(guān)的特征, 提升識別效果. 在噪聲環(huán)境下, 可采用語音去噪算法[15]對語音進(jìn)行去噪后再進(jìn)行語種識別. 針對廣播音頻, 傳統(tǒng)算法提取語音語種特征時(shí), 未能去除部分細(xì)節(jié)特征包括男女說話的不同、 電臺廣播頻道的不同等的影響, 從而可能導(dǎo)致語種識別成為說話人識別或其他與語種無關(guān)的特征識別.
本文提出一種基于GFCC改進(jìn)特征參數(shù)的語種識別方法. 首先對每幀語音進(jìn)行歸一化處理, 去除不同說話人音量大小的影響; 然后對分幀后的每幀語音信號進(jìn)行快速Fourier變換(FFT), 先取平方再取對數(shù), 得到對數(shù)能量譜. 對能量譜信號進(jìn)行離散余弦變換(DCT), 將高維參數(shù)置0再進(jìn)行逆離散余弦變換(IDCT)得到能量譜包絡(luò)信號, 以去除部分與語種無關(guān)的細(xì)節(jié)特征. 再使用能量譜包絡(luò)信號代替原來的能量譜信號通過Gammatone濾波器組進(jìn)行濾波. 同時(shí)為提升GFCC參數(shù)的中高階分量, 使其相鄰值之間具有一定區(qū)分性, 在計(jì)算DCT倒譜后進(jìn)行倒譜提升, 得到改進(jìn)的GFCC特征參數(shù). 最后使用隱Markov模型(hidden Markov model, HMM)語種識別系統(tǒng)進(jìn)行仿真實(shí)驗(yàn), 實(shí)驗(yàn)結(jié)果表明, 在廣播音頻語種識別中本文的改進(jìn)GFCC特征優(yōu)于傳統(tǒng)GFCC特征及其衍生特征.
1 特征提取
首先對語音信號進(jìn)行預(yù)處理, 得到分幀信號, 對每幀語音信號提取能量譜包絡(luò), 利用Gammatone濾波器組濾波, 然后進(jìn)行DCT變換, 計(jì)算DCT倒譜信號, 再進(jìn)行倒譜提升, 得到改進(jìn)的GFCC特征參數(shù). 改進(jìn)的GFCC參數(shù)提取流程如圖1所示. 由圖1可見, 本文加入了求能量譜包絡(luò)和倒譜提升兩個(gè)模塊. 在進(jìn)行預(yù)處理后, 將語音信號提取對數(shù)能量譜包絡(luò)代替原來的能量譜, 同時(shí)在求得DCT倒譜后進(jìn)行倒譜提升.

圖1 改進(jìn)的GFCC參數(shù)提取流程Fig.1 Improved GFCC parameter extraction process
改進(jìn)的GFCC參數(shù)提取過程如下:
步驟1) 預(yù)處理. 首先, 對語音信號進(jìn)行預(yù)處理, 其中包括歸一化、 預(yù)加重、 分幀、 加窗. 歸一化的作用主要是去除不同語種語音的音量大小對語種識別的影響. 歸一化方式采用能量歸一化, 表達(dá)式為
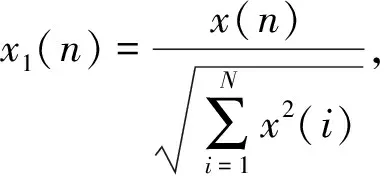
(1)
其中x(n)為輸入的一段語音序列,x1(n)為歸一化后的語音序列.
其次, 對語音信號進(jìn)行預(yù)加重.為提升高頻分量, 需對語音信號進(jìn)行預(yù)加重, 減小高頻分量的損失, 用公式表示為
y(n)=x1(n)-ax1(n-1),
(2)
其中a通常取0.97,y(n)為預(yù)加重后的語音序列.
設(shè)分幀的幀長為l, 則幀移取幀長的1/2.根據(jù)語音的短時(shí)平穩(wěn)特性, 本文語音分幀的幀長取1 024, 幀移取512.為減小語音信號每幀的邊緣抖動等影響, 需對信號進(jìn)行加窗處理.
步驟2) FFT變換. 對每幀信號進(jìn)行FFT變換, 從時(shí)域變換到頻域, 得到頻域信號X(k).
步驟3) 取能量譜包絡(luò).通過FFT變換的頻域信號X(k)取絕對值, 再取對數(shù)得到對數(shù)能量譜E(k), 表達(dá)式為
E(k)=20lg|X(k)|.
(3)

圖2 能量譜包絡(luò)提取流程Fig.2 Energy spectrum envelope extraction process
能量譜包絡(luò)提取流程如圖2所示.對得到的能量譜經(jīng)過DCT變換, 將大部分信息集中到低維, 再將高維若干維參數(shù)置為0(高維參數(shù)不同維數(shù)置0會得到不同的識別效果), 最后經(jīng)過IDCT變換, 得到能量譜包絡(luò)信號. 語音分幀幀長為l, 所以得到的能量譜包絡(luò)信號維數(shù)也是l.將能量譜包絡(luò)后的信號記為E1(k).
一幀語音信號對數(shù)能量譜和能量譜包絡(luò)如圖3所示.由圖3可見, 原始能量譜信號的波動起伏較大, 曲線較尖銳.取包絡(luò)后, 去除了一些幅值較大或較小的點(diǎn), 信號的曲線變得平滑, 且波動起伏較小.能量譜包絡(luò)去除了一些細(xì)節(jié)信息, 例如男女說話的不同、 背景噪聲諧波等, 反映了信號與語種相關(guān)的趨勢.傳統(tǒng)的GFCC參數(shù)提取未提取能量譜包絡(luò), 本文改進(jìn)方法提取能量譜包絡(luò)后再進(jìn)行Gammatone濾波.
步驟4) Gammatone濾波器組濾波. Gammatone濾波器組由M個(gè)中心頻率不同的濾波器組成, 每個(gè)Gammatone濾波器沖激響應(yīng)為
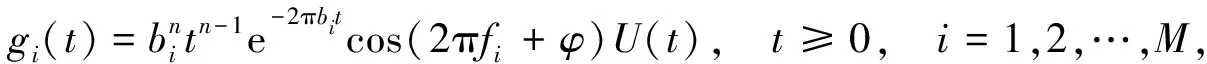
(4)
其中:n為濾波器階數(shù), 一般取4;bi為第i個(gè)濾波器的帶寬;fi為第i個(gè)濾波器的中心頻率;φ為相位.
每幀語音信號取能量譜包絡(luò)后, 使用Gammatone濾波器組進(jìn)行濾波, 相當(dāng)于對每幀的包絡(luò)信號E1(k)與Gammatone濾波器的頻域響應(yīng)Gi(k)相乘并相加, 用公式表示為
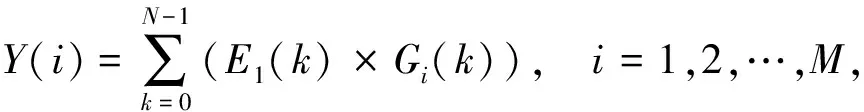
(5)
其中i表示第i個(gè)Gammatone濾波器,k表示頻域信號的第k個(gè)值,N為信號長度,Y(i)為經(jīng)過第i個(gè)濾波器濾波后的信號.
步驟5) DCT倒譜. 對經(jīng)過Gammatone濾波器組濾波后的信號進(jìn)行離散余弦變換, 得到GFCC參數(shù), 表達(dá)式為
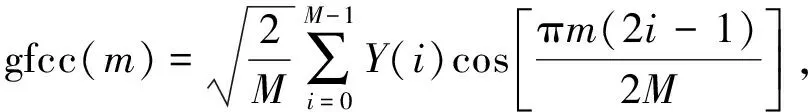
(6)
其中m表示第m維GFCC特征參數(shù),i表示第i個(gè)濾波器,M為濾波器的個(gè)數(shù), 也表示進(jìn)行DCT變換后特征參數(shù)的維數(shù). 進(jìn)行DCT變換減小了同一幀信號中不同維度之間的相關(guān)性. 定義進(jìn)行DCT變換后的參數(shù)為本文改進(jìn)的GFCC算法1.
圖4為從語料中某條語音提取的GFCC參數(shù)樣本, 如取第25幀的GFCC參數(shù), 不取能量譜包絡(luò)與取能量譜包絡(luò)的對比結(jié)果. 由圖4可見, 取譜包絡(luò)的GFCC參數(shù)與未取譜包絡(luò)的GFCC參數(shù)曲線相比, 前幾維無太大變化, 第5維后的GFCC參數(shù)曲線變平緩了, 在第10維后幅值幾乎接近于零. 說明取包絡(luò)后去掉了細(xì)節(jié)信息, 僅保留了與語種相關(guān)的信息.
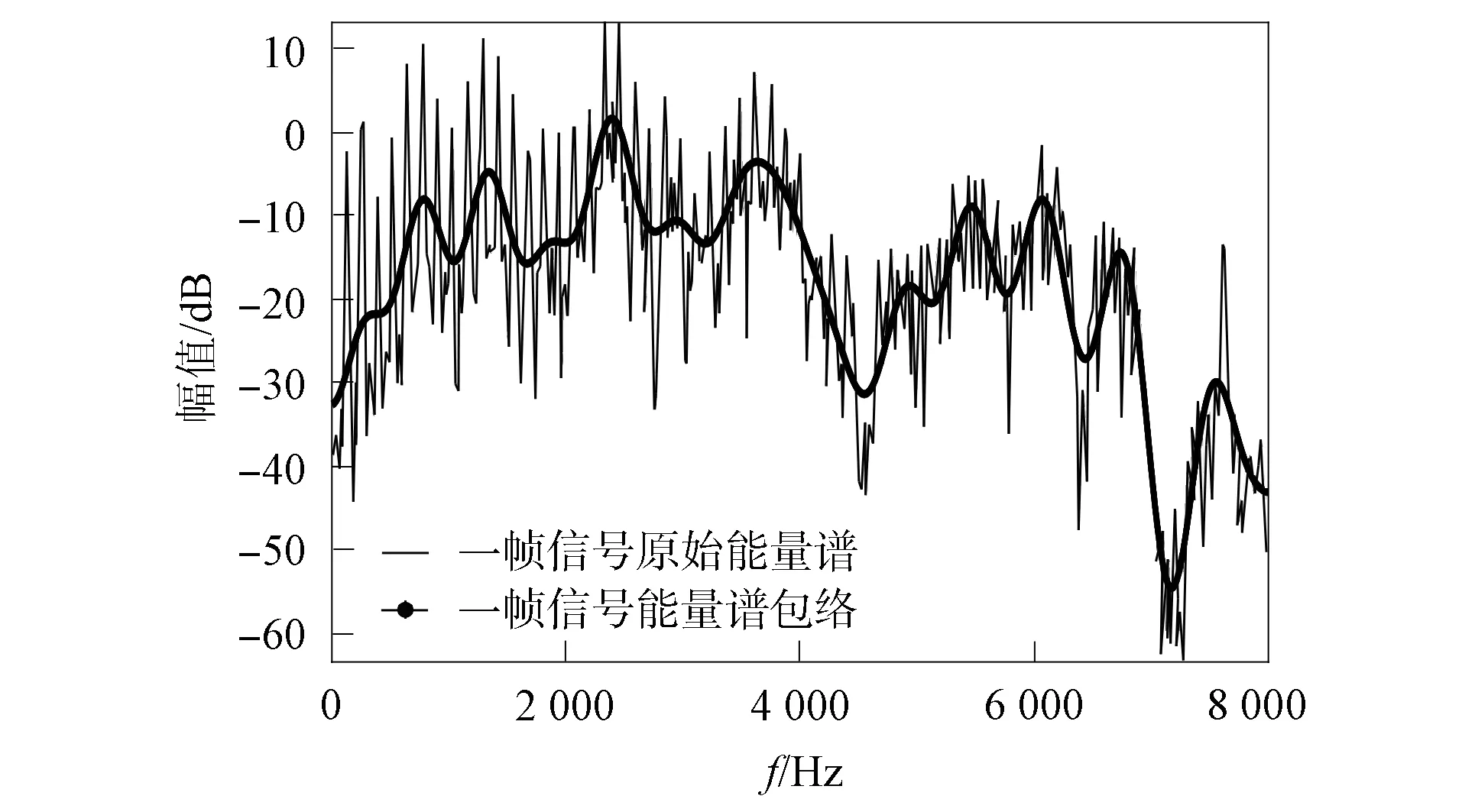
圖3 一幀信號的原始能量譜和能量譜包絡(luò)Fig.3 Original energy spectrum and energy spectrum envelope of a frame signal
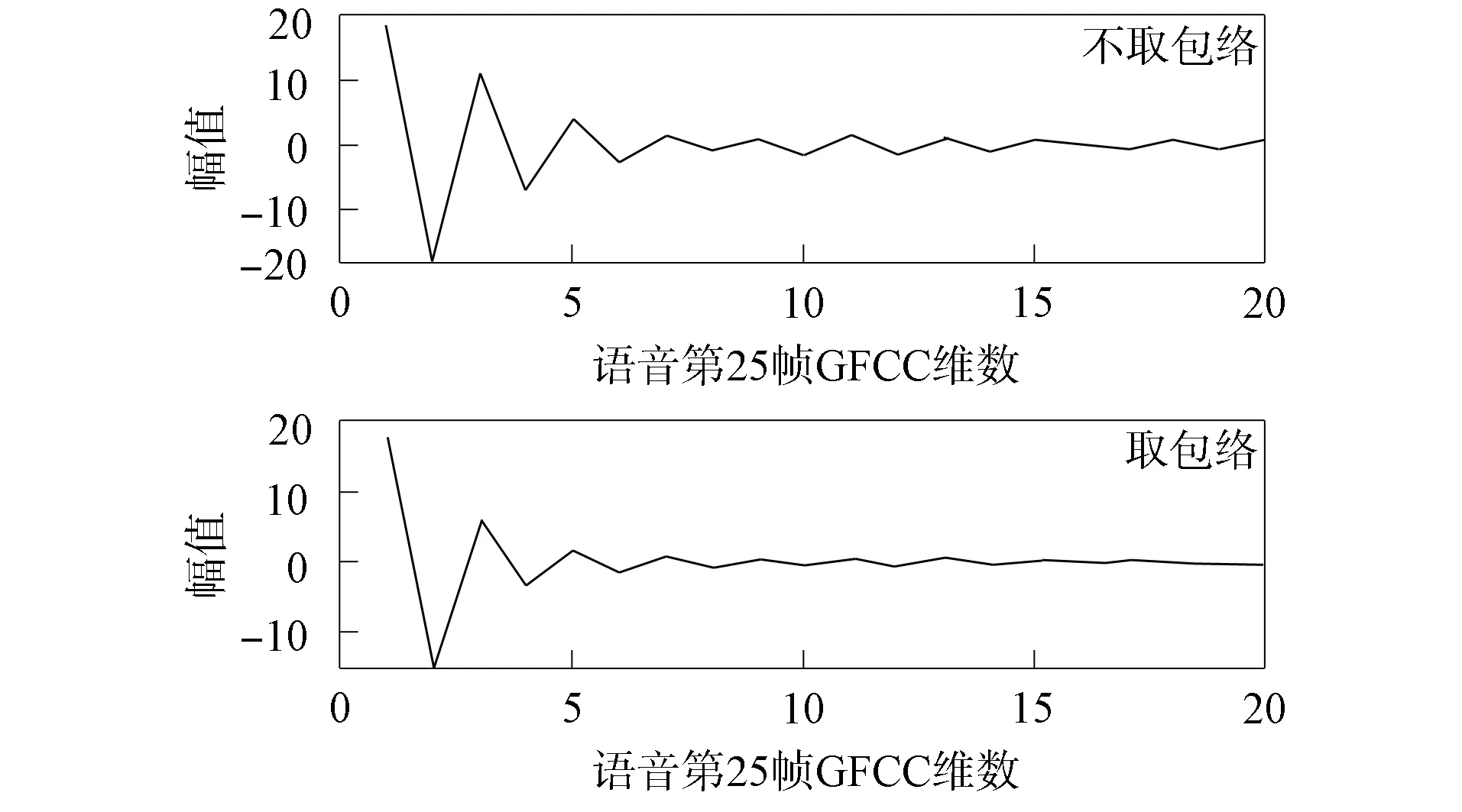
圖4 一幀GFCC參數(shù)不取包絡(luò)與取包絡(luò)的對比Fig.4 Comparison of GFCC parameters of a frame without envelope and envelope
步驟6) 倒譜提升. 對GFCC參數(shù)進(jìn)行倒譜提升, 由于進(jìn)行DCT變換求倒譜后, 低階GFCC參數(shù)值較大, 因此采用倒譜提升以降低低階GFCC參數(shù)值, 提升中高階參數(shù)值, 使中高階GFCC參數(shù)相鄰值之間具有一定的區(qū)分性.
常用的倒譜提升函數(shù)為半升正弦函數(shù), 表示為
w1(m)=0.5+0.5sin(πm/M),m=1,2,…,M.
(7)
本文采用倒譜提升函數(shù)
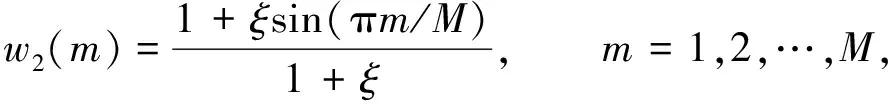
(8)
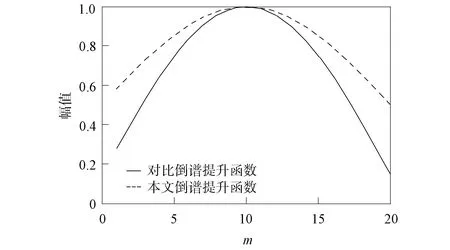
圖5 兩個(gè)倒譜提升函數(shù)對比曲線Fig.5 Comparison curves of two cepstrum lifting functions
對倒譜提升函數(shù)進(jìn)行了歸一化. 其中ξ為一個(gè)可變系數(shù), 當(dāng)ξ=1時(shí)等同于式(7).經(jīng)過實(shí)驗(yàn), 本文取ξ=6時(shí), 效果最好.式(7)倒譜提升函數(shù)和式(8)中ξ=6時(shí)的倒譜提升函數(shù)0~20內(nèi)的曲線如圖5所示.由圖5可見, 與式(7)相比, 本文的倒譜提升函數(shù)兩端較低, 中間較高, 進(jìn)行倒譜提升后更降低了GFCC參數(shù)低階分量值, 提升了中高階分量值. 倒譜提升函數(shù)與經(jīng)過DCT變換后的信號相乘, 得到倒譜提升后的信號gfccen(m), 用公式表示為
gfccen(m)=gfcc(m)m×w2(m).
(9)
定義進(jìn)行倒譜提升后的參數(shù)為本文改進(jìn)的GFCC算法2.
2 語種識別
本文使用HMM作為語種識別的訓(xùn)練和識別模型. HMM模型作為一種常用的對語音信號進(jìn)行建模的統(tǒng)計(jì)模型, 在語音信號處理領(lǐng)域, 包括語音分離、 語音增強(qiáng)、 說話人識別、 語種識別等方面都已得到廣泛應(yīng)用. 使用HMM模型對語音數(shù)據(jù)提取的特征參數(shù)進(jìn)行建模, 保留了語音數(shù)據(jù)特征之間的前后關(guān)聯(lián)性, 能更好地?cái)M合同一語種的語音數(shù)據(jù), 形成一個(gè)能區(qū)別于其他語種的模型. 對不同語種的語音數(shù)據(jù)特征參數(shù)進(jìn)行訓(xùn)練建模, 分別擬合出與當(dāng)前語種特征相類似的模型. 識別時(shí), 將語音特征參數(shù)視為觀測字符序列與模型進(jìn)行匹配, 得到與觀測字符序列對應(yīng)的最佳狀態(tài)序列, 從而達(dá)到語種識別的目的.
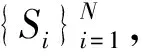

(10)
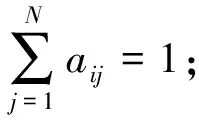
πi=P{S1=si},i=1,2,…,N,
(11)
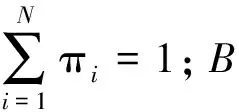
本文的語種訓(xùn)練和識別流程如圖6所示.首先, 對HMM模型進(jìn)行初始化, 然后對訓(xùn)練集的不同語種語料提取改進(jìn)的GFCC特征參數(shù), 放入模型中進(jìn)行訓(xùn)練. 通過Baum-Welch算法進(jìn)行循環(huán)迭代, 重估3組模型參數(shù){A,π,B}, 得到不同語種對應(yīng)的識別模型. 其次, 對測試集提取改進(jìn)的GFCC特征參數(shù), 使用Viterbi算法, 將每條語音提取的特征參數(shù)與不同的語種識別模型進(jìn)行匹配, 尋找匹配概率最大的狀態(tài)序列, 即為識別得到的語種.
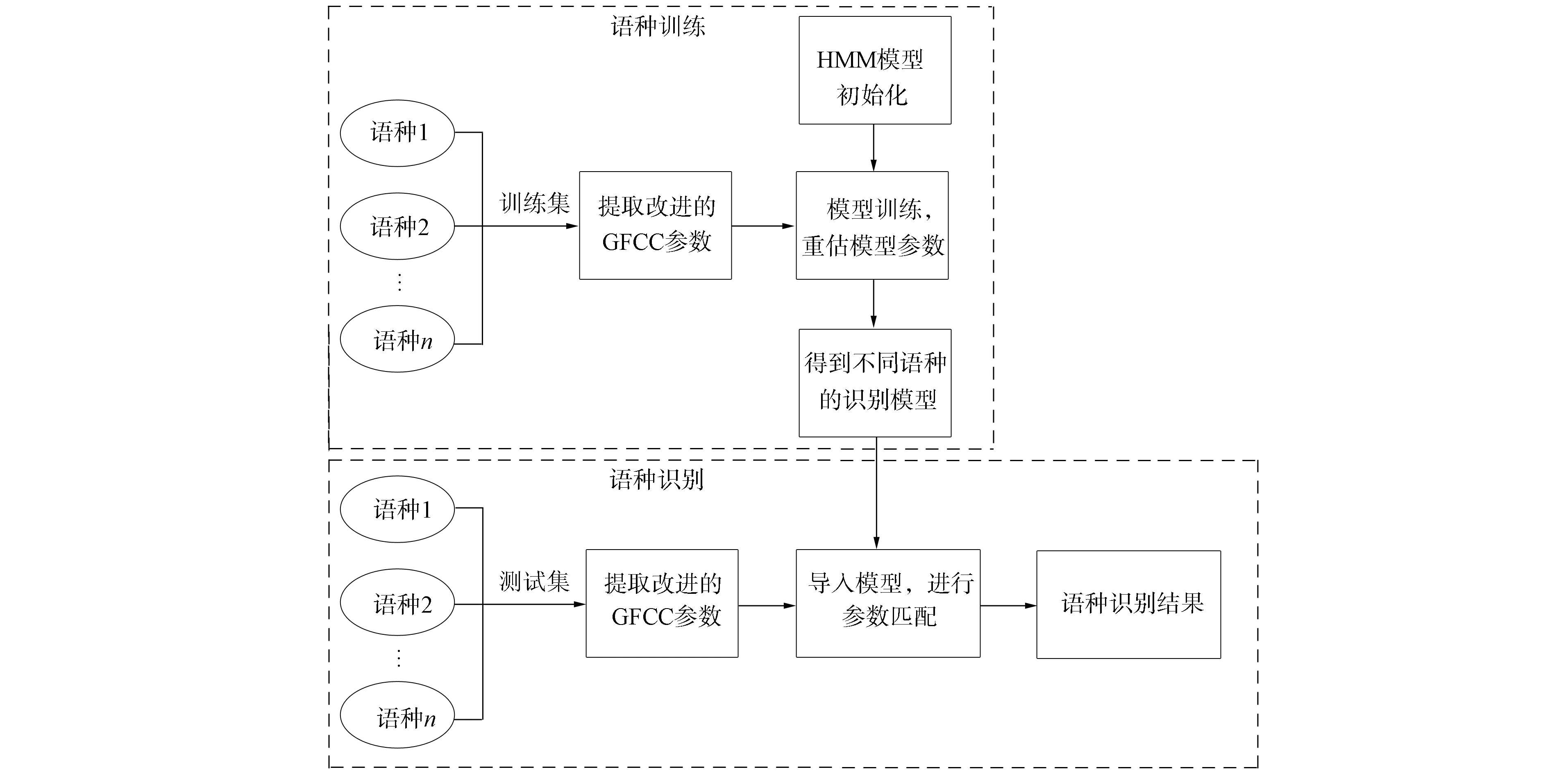
圖6 語種訓(xùn)練和識別流程Fig.6 Flow chart of language training and identification
3 實(shí)驗(yàn)仿真及分析
3.1 實(shí)驗(yàn)語料
本文實(shí)驗(yàn)語料來自中國國際廣播電臺, 主要包括老撾語、 柬埔寨語、 緬甸語、 藏語、 維吾爾語、 越南語6種語言. 每個(gè)語種語料采自多個(gè)頻道不同時(shí)間段的、 不同說話人的廣播音頻. 6種語種的語音數(shù)據(jù)采集好后通過人工剪輯的方式, 去掉較長的靜音段、 音樂段以及背景音樂較強(qiáng)的語音段. 再通過音頻轉(zhuǎn)換軟件轉(zhuǎn)為單聲道數(shù)據(jù), 采樣頻率為16 kHz, 采樣深度16位. 每個(gè)語種的廣播音頻中都含有一定的背景音樂, 且包括電臺主持人說話語音、 本地人說話語音及采訪語音等. 每個(gè)語種的語音都包含多個(gè)說話人, 包括男女混合, 每個(gè)語種的語料都被剪切成3 s的固定長度語音, 每條語音之間重疊1 s. 實(shí)驗(yàn)語料中, 每個(gè)語種訓(xùn)練集由3個(gè)頻道的不同時(shí)間段采集的廣播音頻組成, 包含2 500條語音, 從中隨機(jī)抽取2 000條語音進(jìn)行訓(xùn)練. 測試集由不同于訓(xùn)練集的另外兩個(gè)頻道的不同時(shí)間段采集的廣播音頻組成, 包含500條語音.
3.2 實(shí)驗(yàn)設(shè)計(jì)
本文實(shí)驗(yàn)采用MATLAB2019a作為測試平臺, 測試本文提出的改進(jìn)GFCC算法1與算法2的有效性.
實(shí)驗(yàn)1測試本文改進(jìn)的GFCC算法2在提取能量譜包絡(luò)時(shí), 對DCT變換后的1 024個(gè)參數(shù)64維、 128維、 192維后的值置為0的識別結(jié)果, 各特征命名及說明列于表1. 本文Gammatone濾波器個(gè)數(shù)取20個(gè).

表1 各特征命名及說明
實(shí)驗(yàn)2提取本文改進(jìn)的GFCC算法2的特征參數(shù)分別與傳統(tǒng)的GFCC特征參數(shù)、 GFCC加上一階差分和二階差分(GFCC-Delta-Acceleration, GFCC-D-A)特征參數(shù)以及本文改進(jìn)的GFCC算法1特征參數(shù)進(jìn)行對比, 測試識別效果.
對語音信號提取特征參數(shù), 使用HMM模型進(jìn)行訓(xùn)練識別. 初始HMM模型的狀態(tài)數(shù)和每個(gè)狀態(tài)對應(yīng)的混合模型成分?jǐn)?shù)均設(shè)置為10, HMM模型訓(xùn)練時(shí)循環(huán)迭代20次.
3.3 實(shí)驗(yàn)結(jié)果與分析
實(shí)驗(yàn)1對每幀語音信號提取能量譜包絡(luò)時(shí)對不同維度參數(shù)置0的改進(jìn)的GFCC算法2特征參數(shù), 使用HMM模型進(jìn)行訓(xùn)練, 通過循環(huán)迭代, 得到每個(gè)語種對應(yīng)的特征模型. 對測試語種語料提取同樣的特征參數(shù), 計(jì)算與語種模型對應(yīng)的最佳狀態(tài)序列, 得到語種識別結(jié)果. 采用每個(gè)語種語音識別正確的個(gè)數(shù)除以每個(gè)語種語音總個(gè)數(shù)得到的準(zhǔn)確率作為評價(jià)指標(biāo).
取能量譜包絡(luò)時(shí), 對DCT變換后的高維參數(shù)不同維度參數(shù)置0, 會有不同的識別效果. 幀長為1 024, 所以得到的能量譜包絡(luò)信號維數(shù)也是1 024. 測試本文改進(jìn)的GFCC算法2在提取能量譜包絡(luò)時(shí), 對DCT變換后的1 024個(gè)參數(shù)64維、 128維、 192維后的值置為0的識別結(jié)果. 識別結(jié)果列于表2.

表2 能量譜包絡(luò)不同維數(shù)置0語種識別準(zhǔn)確率
由表2可見, 對192維后的參數(shù)置0識別效果最好, 達(dá)到86.4%, 對128維后的參數(shù)置0識別效果次之, 對64維后的參數(shù)置0識別效果最低, 但相對于最好效果, 平均識別準(zhǔn)確率只降低了1.4%. 原始能量譜及不同維數(shù)置0能量譜包絡(luò)如圖7所示. 由圖7可見, 取能量譜包絡(luò)時(shí)對DCT變換后不同維數(shù)置0的包絡(luò)圖不同, 丟失的信息量也不同, 對64維后的參數(shù)置0丟失的信息量最多, 對192維后的參數(shù)置0丟失的信息量最少, 但相對于原始能量譜, 取包絡(luò)都去掉了很大一部分細(xì)節(jié)信息, 反映了能量譜的大致走勢. 相對于192維后參數(shù)置0的能量譜包絡(luò), 64維后參數(shù)置0的能量譜包絡(luò)信息去掉過多, 可能將部分用于區(qū)分語種的信息丟失了, 從而降低了準(zhǔn)確率.

圖7 原始能量譜及不同維數(shù)置0能量譜包絡(luò)Fig.7 Original energy spectrum and energy spectrum envelope with different dimensions set to 0
由實(shí)驗(yàn)1可知, 在取語音信號能量譜包絡(luò)時(shí)對DCT變換后的參數(shù)192維后的參數(shù)置0效果最好, 所以實(shí)驗(yàn)2的能量譜包絡(luò)均對192維后的參數(shù)置0.
實(shí)驗(yàn)2對每個(gè)語種的每幀語音信號提取文獻(xiàn)[7]中的GFCC特征參數(shù)、 文獻(xiàn)[6]中的GFCC-D-A特征參數(shù)以及本文改進(jìn)的GFCC算法1特征參數(shù)、 改進(jìn)GFCC算法2特征參數(shù), 使用HMM模型進(jìn)行訓(xùn)練識別. 識別結(jié)果列于表3.

表3 廣播音頻語種識別準(zhǔn)確率
由表3可見, 本文改進(jìn)的GFCC算法2對每個(gè)語種的識別準(zhǔn)確率均較好, 平均識別準(zhǔn)確率最高, 相比GFCC參數(shù), 平均識別準(zhǔn)確率提升了6%. 加上一階差分和二階差分的GFCC-D-A參數(shù)平均識別準(zhǔn)確率比GFCC的識別準(zhǔn)確率高1%, 比改進(jìn)的GFCC算法2低5%. 本文改進(jìn)的GFCC算法1相比于GFCC參數(shù)平均識別準(zhǔn)確率提升了3.5%, 比本文改進(jìn)的GFCC算法2低2.5%. 說明本文的倒譜提升方法也提升了語種識別的準(zhǔn)確率. 因此, 本文改進(jìn)的GFCC算法2相比傳統(tǒng)的GFCC參數(shù)識別準(zhǔn)確率有提升, 說明本文的改進(jìn)算法有效.
綜上所述, 本文在傳統(tǒng)GFCC特征參數(shù)的基礎(chǔ)上對GFCC參數(shù)提取過程進(jìn)行了改進(jìn). 首先對語音信號進(jìn)行歸一化, 減小了不同說話人音量大小的影響. 然后對每幀語音信號進(jìn)行FFT后, 取能量譜包絡(luò), 去掉細(xì)節(jié)特征, 通過Gammatone濾波器濾波后進(jìn)行DCT變換得到改進(jìn)的GFCC算法1特征參數(shù), 再進(jìn)行升正弦倒譜提升, 提升了GFCC參數(shù)的中高階分量, 得到改進(jìn)的GFCC算法2特征參數(shù). 仿真實(shí)驗(yàn)結(jié)果表明, 本文改進(jìn)GFCC算法1的特征參數(shù)相比于GFCC參數(shù)及加一階差分和二階差分的GFCC-D-A參數(shù)可達(dá)到更好的識別效果, 進(jìn)行倒譜提升后的改進(jìn)GFCC算法2的特征參數(shù)對識別準(zhǔn)確率有進(jìn)一步提升. 本文改進(jìn)的GFCC算法2特征參數(shù)對6個(gè)語種可達(dá)86.4%的識別準(zhǔn)確率, 識別效果最好, 說明本文改進(jìn)的GFCC特征參數(shù)有效.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
考試與評價(jià)·高一版(2020年6期)2020-11-02 02:45:24
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機(jī)械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學(xué)學(xué)報(bào)(2015年3期)2015-11-11 17:20:00
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
