多分支主干監督網絡下的RGB-D圖像顯著性檢測
2022-05-30 19:44:32王衛兵張曉琢鄧強
哈爾濱理工大學學報 2022年4期
王衛兵 張曉琢 鄧強


摘要:針對現有的RGB-D圖像顯著性檢測技術難以充分挖掘深度圖像的有效信息,無法使RGB特征和深度特征有效融合的問題,提出了一種多分支主干監督網絡下的RGB-D圖像顯著性檢測方法。基于Resnet50網絡獲得兩種圖像的各層特征,利用深度改進模塊從通道和空間注意力的角度提取到有用的深度特征信息。利用特征分組監督融合模塊,依據卷積神經網絡的理論,對RGB和深度特征從高層到底層分組進行多尺度多模態特征融合,每組融合加入上層融合結果和真值圖進行監督,最終迭代得到預測顯著圖。通過4個具有代表性數據集上進行的實驗,對比目前先進的RGB-D圖像顯著性檢測,表明此模型平均絕對誤差指標最小,在F值、E值和S值指標上均有提高,性能優于其他模型,具有良好的魯棒性。
關鍵詞:
RGB-D圖像顯著性檢測;多分支主干監督網絡;神經網絡;注意力機制;多模態融合
DOI:10.15938/j.jhust.2022.04.006
中圖分類號: TP391
文獻標志碼: A
文章編號: 1007-2683(2022)04-0039-07
RGB-D Image Saliency Detection Based on Multi-branch Backbone Supervised Network
WANG Wei-bing ZHANG Xiao-zhuo DENG Qiang
(1.school of computer science and technology, Harbin university of science and technology, Harbin 150080, China;
2.On Line Operation Center of Harbin Power Supply Company, Heilongjiang Electric Power Co., Ltd., Harbin 150036, China)
Abstract:Aiming at the problem that the existing RGB-D image saliency detection technology is difficult to fully explore the effective information of depth image and can not effectively integrate RGB features and deep features, an RGB-D image saliency detection method under multi-branch backbone supervision network is proposed. We obtain the layer features of RGB image and deep image based on Resnet50 network, using the deep improvement module, useful deep feature information is extracted from the perspective of channel and spatial attention. Using the feature grouping supervised fusion module, according to the theory of convolutional neural network, the RGB and deep features are grouped from high level to bottom for multi-scale and multi-modal feature fusion. Each fusion group is supervised by the upper level fusion result and truth map, and finally the predicted saliency map is obtained iteratively. Experiments on four representative data sets show that compared with the current advanced RGB-D image saliency detection model. This model has the smallest average absolute error index, improves in F value, E value and S value, has better performance than other models, and has good robustness.
Keywords:RGB-D image saliency detection; multi-branch backbone supervised network; neural network; attention mechanism; multimodal fusion
0引言
顯著性目標檢測技術的關鍵是提取目標場景中最吸引人的重要區域,近年來,許多人在計算機視覺領域探索了顯著性目標檢測技術,將該項技術應用于語義分割[1],圖像分類[2],圖像壓縮[3]和圖像分割[4]等領域。在過去幾年里,已經提出了各種基于RGB-D圖像的顯著性目標檢測模型,微軟Kinect等深度傳感器的出現也提升了對深度圖像的捕獲。但目前的顯著性目標檢測方法和技術仍然存在不足。
RGB-D圖像中RGB圖像與深度圖像是成對出現的,RGB圖像提供詳細的顏色紋理信息,深度圖像則提供目標區域的形狀,位置等眾多空間信息。由于采集設備的限制,在數據集中會出現邊緣模糊或遭受噪聲干擾的低質量深度圖像,如何克服其造成的影響,從中獲取有用的特征信息成為提升顯著性檢測性能的關鍵之一。JL-DCF[5]網絡將深度圖像視為彩色圖像的特殊情況,使用共享的 CNN 進行特征提取;DPANet[6]網絡使用深度感知模塊來評估深度圖的潛力并減少污染的影響;D3Net[7]網絡提出了深度過濾單元,過濾掉影響性能的深度圖像。
當從RGB圖和深度圖中捕獲到高質量的多尺度特征時,如何將其有效融合以獲得高水平的顯著圖也是當前探索顯著性檢測技術的熱點問題。CPFP[8]模型提出了流體金字塔積分模塊以分層的方式融合跨模態信息;TAN[9]引入了通道式注意機制實現選擇性的跨模態跨層次特征融合。這些方法從不同角度探索了如何使特征有效匹配融合,特征融合的效果決定著檢測性能的高低。
針對上述問題,本文采用了一種新型的多分支主干監督網絡進行RGB-D圖像的顯著性檢測。
本文的主要貢獻有:
①為了盡可能全面充分融合各級有用特征,本文采用了一種多分支主干監督的網絡結構對RGB-D圖像進行顯著性目標檢測,其中,基于卷積神經網絡引入特征分層監督融合模塊(feature grouped supervision module,FGM),利用高層特征具有指導優化低層細節特征的特點,從高到低分組迭代監督優化結果。
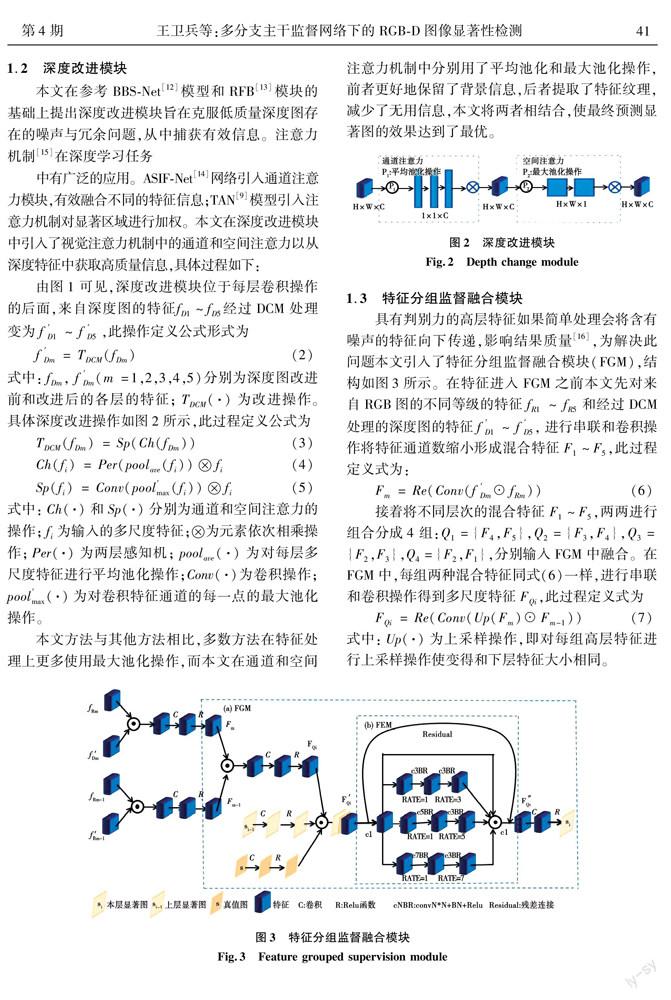
②為了有效利用深度圖像的特征信息,減少低質量深度圖的影響,本文基于注意力機制引入深度改進模塊(deep change module,DCM),增強了深度特征的顯著性表現能力。
③在廣泛使用的數據集上進行的實驗表明,本文提出的網絡模型對RGB-D圖像的顯著性檢測能力優于目前先進的模型,具有良好的魯棒性。
1方法
目前RGB-D圖像顯著性檢測技術多數直接聚合多模態多尺度的特征[10-11],本文采用雙流結構,將RGB和深度圖像分別輸入,獲得獨立特征再進行處理融合。
1.1多分支主干監督網絡
1.2深度改進模塊
1.3特征分組監督融合模塊
1.4本文模型的代碼描述
2實驗
2.1數據集
2.2評價指標
2.3實驗細節
本文在windows10操作系統上進行實驗,使用CPU型號為英特爾酷睿I7-7700HQ,2.8GHz,GPU型號為 1080ti,應用了深度學習模型框架pytorch[25]。本文使用預訓練好的ResNet50模型,同時去掉最后池化層和全連接層,學習率設為10-4,每隔50輪下降10倍,通過對圖像進行翻轉和邊界剪裁進行數據增強操作,當批次大小設為10,模型訓練迭代50次時,耗時大約6h。
2.4與先進方法對比
結果對比:本文與4種當前先進的RGB-D圖像顯著性檢測模型CPFP[8],CTMF[26],TAN[9]和BBSNet[12]進行了實驗對比,圖4和圖5分別展示它們在平均絕對誤差(MAE)和E值上的比較,其中,MAE越小,E值越大表明模型性能越好,明顯看出,本文模型在不同數據集上都取得了最高的E值和最小的MAE。對于F值和S值對比結果如表1所示,本文模型比 CPFP,CTMF,TAN和BBSNet的F值在NJU2000數據集上分別提高了3.34%、6.04%、6.16%和 0.45%,在其他數據集上也有不同程度的提高;對于S值,本文模型也高于其他模型。綜合以上數據,可得本文模型顯著性檢測效果良好,評價指標整體結果優于其他模型,具有一定競爭力。
可視化對比:如圖6所示,展示不同影響檢測結果情況下各模型輸出的顯著圖。圖6中第1行圖像是在普通背景下檢測單目標物體,可以看出本文模型識別出的物體邊緣更清晰;第2行圖像是在受光線干擾情況下識別物體,光線反射易造成圖像原本顏色或形狀改變,本文模型能夠有效克服其帶來的影響,更好識別目標物體;第3行圖像是在復雜場景下對多物體進行識別,本文模型能夠清晰地檢測出所有物體;第4行圖像是在低對比度場景中識別物體,本文模型充分利用深度圖像的有用特征,取得了可靠結果。
2.5特征分組監督融合模塊實驗對比
對特征分組融合監督模塊的有效性進行檢測,視覺結果如圖7所示,其中,圖7(a)是僅使用簡單卷積操作的NFGM(no feature grouped supervision module,NFGM)算法各層所得,圖7(b)是本文模型在FGM融合的各階段生成的顯著圖S1~S4,可以明顯看到目標物體邊緣逐層開始清晰,最后得到了效果良好的結果圖;NFGM算法各層輸出的顯著圖與本文模型輸出的顯著圖對應相比,目標物體輪廓模糊,有明顯的冗余特征,再結合表2數據,本文模型各項評價指標都遠優于NFGM算法。故從視覺和評價標準兩方面來看,本文引入的特征分組監督融合模塊高質量完成了特征的融合,提升了模型的顯著性檢測性能。
2.6深度改進模塊實驗對比
對深度改進模塊有效性進行實驗對比,實驗結果如表3所示,其中,NDCM(no depth change module,NDCM)是未對深度圖像做增強處理的算法,可以看出本文算法各性能指標均優于NDCM算法,表明深度信息能夠顯著提升模型的性能,帶來很多增益,為目標檢測提供空間信息細節上的指導。
3結語
本文基于卷積神經網絡,提出了一種多分支主干監督網絡框架,引入深度改進模塊和特征分組監督融合模塊,以從高到低迭代優化的方式輸出顯著性預測結果。本文模型在4個具有代表性的數據集上均達到了良好的效果,具有較強的魯棒性。在未來工作中,可以開發一種端到端的框架,實現深度模塊改進與多模態特征融合同步完成,加強關聯性研究。
參 考 文 獻:
[1]SU W, WANG Z F. Widening Residual Refine Edge Reserved Neural Network for Semantic Segmentation[J]. Multimedia Tools and Applications, 2019, 78(13):18229.
[2]陳宇,周雨佳,丁輝. 一種XNet-CNN糖尿病視網膜圖像分類方法[J].哈爾濱理工大學學報,2020,25(1):73.CHEN Yu,ZHOU Yujia,DING Hui. An XNet-CNN Diabetic Retinal Image Classification Method[J].Journal of Harbin University of Science and Technology,2020,25(1):73.
[3]GUO Chenlei , ZHANG Liming. A Novel Multiresolution Spatiotemporal Saliency Detection Model and its Applicationsin Image and Video Compression[J]. IEEE Transaction son Image Processing, 2010, 19(1): 185.
[4]朱素霞,祖宏亮,孫廣路. 一種基于空間信息的FSICM圖像分割算法[J].哈爾濱理工大學學報,2020,25(4): 101.ZHU Suxia, ZU Hongliang, SUN Guanglu. Image Segmentation Algorithm Named FSICM Based on Spatial Information[J]. Journal of Harbin University of Science and Technology,2020,25(4): 101.
[5]FU K, FAN D P, JI G P , et al. JL-DCF: Joint Learning and Densely-Cooperative Fusion Framework for RGB-D Salient Object Detection [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Seattle, WA, USA, 2020,11(3):404.
[6]CHEN Z, CONG R, XU Q, et al. DPANet: Depth Potentiality-Aware Gated Attention Network for RGB-D Salient Object Detection[C]// IEEE Transactions on Image Processing, 2020,24(8):3736.
[7]FAN D P, LIN Z, ZHANG Z, et al. Rethinking RGB-D Salient Object Detection: Models, Data Sets, and Large-Scale Benchmarks[C]//IEEE Transactions on Neural Networks and Learning Systems, 2020,11(36):325.
[8]ZHAN J, CAO Y, FAN D, et al. Contrast Prior and Fluid Pyramid Integration for RGBD Salient Object Detection[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA, 2019,29(3):2925.
[9]CHEN H, LI Y. Three-Stream Attention-Aware Network for RGB-D Salient Object Detection[J]. IEEE Transactions on Image Processing, 2019, 28(6): 2825.
[10]ZHU C, CAI X, HUANG K, et al. PDNet: Prior-Model Guided Depth-Enhanced Network for Salient Object Detection[C]//2019 IEEE International Conference on Multimedia and Expo (ICME). Shanghai China, 2019,36(7):199.
[11]CHEN S, TAN X, WANG B, et al.Reverse Attention-Based Residual Network for Salient Object Detection[J]. IEEE Transactions on Image Processing, 2020, 29 (1): 3763.
[12]FAN D P, ZHAI Y J, BORJI A, et al. BBS-Net: RGB-D Salient Object Detection with a Bifurcated Backbone Strategy Network[J]. Computer Vision-ECCV,2020, 12357(1): 275.
[13]LIU S, HUANG D, WANG Y. Receptive Field Block Net for Accurate and Fast Object Detection[C]//ECCV. 2018,33(1):404.
[14]LI C. ASIF-Net: Attention Steered Interweave Fusion Network for RGB-D Salient Object Detection[J]. IEEE Transactions on Cybernetics, 2021, 51(1): 88.
[15]孫廣路,吳猛,邱景,等.針對長視頻問答的深度記憶融合模型[J].哈爾濱理工大學學報,2021,26(1):1.SUN Guanglu,WU Meng,QIU Jing, et al.Deep Memory Fusion Model for Long Video Question Answering[J].Journal of Harbin University of Science and Technology,2021,26(1):1.
[16]劉政怡,段群濤,石松,等.基于多模態特征融合監督的RGB-D圖像顯著性檢測[J].電子與信息學報,2020,42(4):997.LIU Zhengyi, DUAN Quntao,SHI Song, et al. RGB-D Image Saliency Detection Based on Multi-modal Feature-fused Supervision[J].Journal of Electronics and Information Technology, 2020,42(4):997.
[17]JU R, GE L, GENG W, et al.Depth Saliency Based on Anisotropic Center-surround Difference[C]// 2014 IEEE International Conference on Image Processing (ICIP). Paris, France, 2014,7025(22):1115.
[18]PENG H W, LI B, XIONG W H, et al. RGB-D Salient Object Detection: A Benchmark and Algorithms[C]// Computer Vision-ECCV,2014,45(33):92.
[19]LI G, ZHU C. A Three-Pathway Psychobiological Framework of Salient Object Detection Using Stereoscopic Technology[C]// 2017 IEEE International Conference on Computer Vision Workshops (ICCVW). Venice, Italy, 2017,18(9):783.
[20]LI N, YE J, JI Y, et al. Saliency Detection on Light Field[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 8(39):1605.
[21]KRAHEN P. Saliency Filters: Contrast Based Filtering for Salient Region Detection[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2012,3(46):733.
[22]ACHANTA R, HEMAMI,S, Estrada F, et al. Frequency-tuned Salient Region Detection[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition,2009,4(13):1597.
[23]BORJI A, CHENG M, JIANG H, et al. Salient Object Detection: A Benchmark[J]. IEEE Transactions on Image Processing, 2015, 12(24): 5706.
[24]FAN D, CHENG M, LIU Y, et al. Structure-Measure: A New Way to Evaluate Foreground Maps[C]//2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy, 2017,34(6):4598.
[25]STEINER B, DeEVITO Z, CHINTALA S, et al. PyTorch: An Imperative Style, Highperformance Deep Learning Library[C]// NIPS, 2019,48(3):8024.
[26]HAN J, CHEN H, LIU N, et al.CNNs-Based RGB-D Saliency Detection via Cross-View Transfer and Multiview Fusion[J]. IEEE Transactions on Cybernetics, 2018, 11 (48): 3171.
(編輯:溫澤宇)
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
人大建設(2020年4期)2020-09-21 03:39:12
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
浙江人大(2014年4期)2014-03-20 16:20:16
