用活Word 批量提取和修改視頻字幕
2022-05-30 15:20:49平淡
電腦愛好者 2022年2期
平淡
1. 使用剪映智能識別字幕
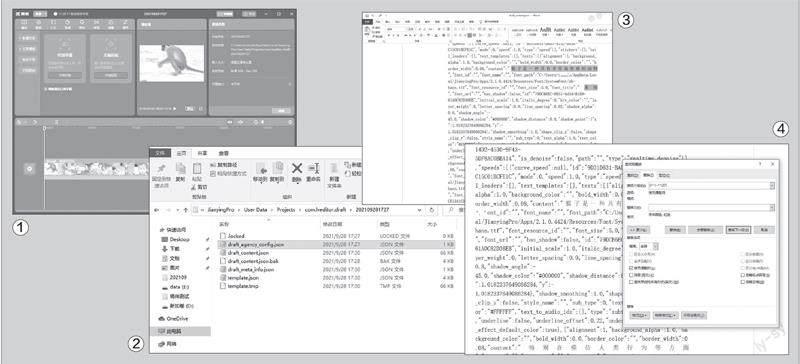
首先到“https://lv.ulikecam.com/?_s=4”下載“剪映”。啟動程序后點擊“導入視頻”,導入需要識別字幕的視頻。接著在上方的菜單欄內依次切換到“文本→智能字幕”,點擊“識別字幕”下的“開始識別”按鈕(圖1)。
這樣字幕文件會被自動識別到本地保存。打開“C:\Users\用戶名\AppData\Local\JianyingPro\UserData\Projects\com.lveditor.draft\”,這里保存了很多以時間命名的文件夾,具體時間和在“剪映”中導入的視頻時間相對應。根據導入時間打開對應的文件夾,比如打開“202109281727”文件夾(表示2021.09.28,17:27開始的導入操作),其中的“draft_content.json”就是識別好的字幕文件(圖2)。
2. 將字幕導入Word進行處理
在圖2所示的窗口中右擊“draft_content.json”文件并依次選擇“打開方式→選擇Word打開”,打開文檔后通過仔細查看可以發現,識別到的字幕是混雜在一堆英文當中的漢字,前后兩條字幕之間都有一個“系統”字樣的字符進行分割(圖3)。
因此,如果要將字幕提取出來進行編輯,只需將文檔中的漢字(包含其中的標點)復制出來即可。具體的提取方法有兩種:
方法1:標記文字后提取
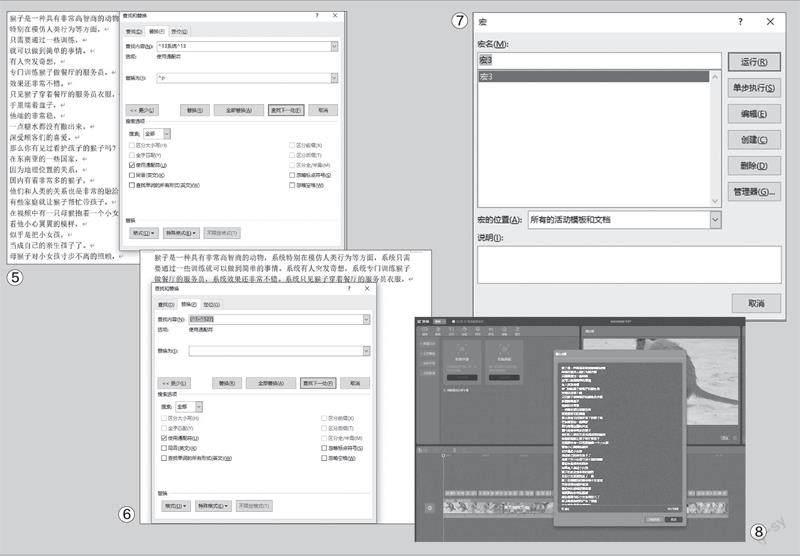
如果只是提取一個視頻中的字幕,按下“Ctr l+H”快捷鍵打開“查找和替換”對話框,接著在“查找內容”處輸入“[!^1-^127]”(不含雙引號,表示查找所有漢字及其中文標點)。接著定位到“替換為”處并依次點擊“替換→格式→字體→紅色字體”,表示將找到的字符設置為紅色字體。繼續點擊“更多”按鈕,在展開的“ 搜索”選項下勾選“使用通配符”。最后點擊“全部替換”,這樣所有的漢字和標點都會標紅顯示(圖4)。
繼續選中任意紅色漢字,依次點擊“開始→選擇→選定所有格式類似的文本(無數據)(S)”,選中紅色漢字復制到新建的文檔中,同上再次打開“查找和替換”,在“查找內容”處輸入“^13系統^13”(即上一個硬回車+系統+下一個硬回車的內容,因為上下條字符都包含這個內容)、“替換為”處輸入“^p”(表示段落標記)。點擊“全部替換”后就可以得到實際的字幕內容了。這樣在Word中即可對所有字幕內容進行編輯了(圖5)。
方法2:刪除非漢字字符保留字幕
如果經常需要提取視頻字幕的內容,我們可以依次點擊“開發工具→宏→錄制”,接著錄制下面的操作:
同上打開“ 查找和替換”對話框,在“查找內容”處輸入“[^1-^127] ”(即查找所有的西文字符)、“替換為”處留空。點擊“全部替換”,僅保留中文字幕和中文標點的內容(圖6)。
繼續查找“系統”,將其替換為“^p”,這樣每條字幕內容會分行顯示。然后點擊“停止”完成宏的錄制。接著打開宏,將宏的位置設置為“所有的活動模板和文檔”(圖7)。
將上述的文檔保存為啟用宏的模板文件。以后當我們需要提取字幕文字時,先用記事本程序打開圖2所示文件夾下的“draft_content.json”文件,按下“Ctrl+A”快捷鍵全選文本,復制后粘貼到上述的模板文件中。打開宏窗口后選擇上述錄制的宏3,點擊“運行”即可自動提取出字幕內容了。
3. 將處理好的字幕添加到視頻中
完成字幕的提取和編輯后,再次按下“Ctrl+A”快捷鍵全選文本,然后返回圖1所示的窗口,點擊“文稿匹配”下的“開始匹配”,在打開的窗口中將編輯好的字幕內容粘貼到文本框中,然后點擊“開始匹配”,這樣字幕便會自動整合到視頻中了(圖8)。
最后點擊“剪映”窗口右上角的“導出”,按提示將視頻導出并保存,然后上傳到抖音、快手等中,就可以從中看到自己制作的字幕了。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
科學大眾(2021年21期)2022-01-18 05:53:48
科學大眾(2021年17期)2021-10-14 08:34:02
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
臺聲(2016年2期)2016-09-16 01:06:53
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
語文知識(2014年1期)2014-02-28 21:59:13
