融合標簽層級結構的文本分類
2022-06-07 06:14:04劉瀚鍇黃賢英朱小飛付朝燕
山西大學學報(自然科學版) 2022年2期
劉瀚鍇,黃賢英,朱小飛,付朝燕
(重慶理工大學 計算機科學與工程學院,重慶 巴南 400054)
0 引言
文本分類是自然語言處理技術中非常重要的領域,被廣泛應用于垃圾郵件過濾、新聞分類、情感分析、惡意評論檢測等場景。層級文本分類(Hierarchical Text Classification,HTC)是文本分類領域中的一項特殊任務,分類結果對應標簽層級結構中的一個或多個節點。如圖1所示,標簽被分層存儲在預先定義好的樹形結構中。層級文本分類可用于解決為專利申請分配分類代碼[1]、網頁分類[2]、表情符號推薦等任務。工業界和學術界對HTC任務都進行了廣泛的研究。

圖1 預先定義好的標簽層級結構Fig.1 Structure of predefined label hierarchy
Fall等[3]提出使用傳統分類模型(樸素貝葉斯),將HTC問題簡化為平坦的多標簽分類問題,直接預測位于最后一級葉子結點的類別。這種簡化方法忽略了標簽的層級結構信息。為解決這個問題,Read等[4]提出對于每個二分類模型的屬性空間都用0或1來拓展,代表之前所有分類器的標記相關性,從而形成分類器鏈。然而當第一個分類器中的一個或多個預測較差時,分類誤差可能會沿鏈進行傳播。同樣,Mayne等[5]將獨立的樸素貝葉斯分類器組成分層分類器,父分類器的輸出概率作為額外特征傳播到子分類器,每個分類器都使用二元正態分離進行單詞特征選擇。Shimura等[6]在學習層級信息的時候,將上層標簽信息以微調卷積神經網絡的方式傳遞到下層標簽的學習中。Zhou等[7]通過引入先驗層級信息和樣本分布概率,使用Bi-TreeLSTM和GCN構建層次感知結構編碼器來建模標簽關系。然而通過樣本集中標簽出現次數計算得到的標簽節點傳遞概率可能存在移植性較差的問題,在實際應用場景中,不同類別文本的數量可能隨著熱點的變化而變化。且該模型只考慮了標簽層級結構信息,并未考慮標簽語義結構信息,其在一定程度上造成了標簽特征的浪費。
總之,現有的研究方法主要分為兩類:(1)關注局部,傾向于構造多個層次分類模型,然后以自頂向下的方式遍歷層次結構。每個分類器預測對應的類別或類別層次。(2)關注全局,將所有類別集合在一起,用單個分類器進行預測。
盡管這些方法從一定程度上引入了標簽的結構信息,卻忽略了標簽的語義結構特征、層級結構特征以及它們與輸入文本特征之間的關系。同時,大多數HTC任務標簽集有多個層級,且一篇文本可能同時屬于多個類別。如圖1所示,語義相似度較高的標簽可能隸屬于同一個或不同的父級標簽下。當標簽數量較大、標簽相似度較高時,通過人工閱讀進行標注的方法構造數據集存在諸多主觀因素,容易造成分類錯誤和分類缺失的問題。
為解決以上問題,提出了融合標簽結構的層級標簽文本分類模型(LHSSL)。首先通過傳統編碼器提取輸入文本特征,連接激活函數得到預測概率分布。然后引入使用外部語料預訓練好的語言模型得到標簽嵌入向量,計算標簽嵌入向量間的相似度得到標簽的語義相關結構圖。根據數據集給出的多層級類別標簽,構建標簽的層級結構矩陣。同時由于標簽數量較少,使用單層圖卷積就可以提取整個圖結構的特征。因此使用共享參數的單層圖卷積學習語義結構圖與層級結構圖的共享特征得到了兩種標簽嵌入。利用自注意力機制學習標簽之間的關系得到新的標簽嵌入向量。計算文本嵌入與標簽嵌入的相似度,并且動態融合輸入文本的特征。經過激活后構造標簽模擬分布,將兩個分布加和平均并激活后得到最終的分類結果。
本文的主要工作有:(1)通過數據標簽集提取標簽的語義結構信息與層級結構信息。(2)提出LHSSL文本分類模型,將標簽語義結構信息、層級信息以及輸入文本特征進行融合,學習標簽的模擬分布作為預測的soft target。(3)在20NG、8NG_E、8NG_H、WOS11967四個數據集上驗證了模型的有效性。(4)當標簽數量較多且層級劃分較精細時,不同的標簽可能具有較強的相似性從而導致數據標簽標注錯誤。因此引入一定噪聲并驗證了在數據集標簽含有30%噪聲時,LHSSL同樣有效。
1 相關工作
1.1 圖卷積神經網絡
圖結構數據含有豐富的信息,其中屬性信息描述了圖中節點的固有屬性,結構信息描述了圖中節點的關聯性質。相較于卷積神經網絡和循環神經網絡,圖卷積神經網絡更適用于處理非歐幾里得結構性的圖數據。圖卷積的目的是通過聚合節點自身以及鄰居節點的信息提取拓撲圖的空間特征。基于建模圖卷積神經網絡時關注領域不同[8],研究人員提出了如Spectral CNN[9]、GAT[10]、R-GCNs[11]、FastGCN[12]等多種變體。許多現實世界中的問題都能通過圖結構進行表述,圖卷積神經網絡也在社交網絡、推薦系統、知識圖譜、生物遺傳和路徑規劃等領域有著廣泛的應用。
圖卷積神經網絡同樣可以應用在文本分類任務中。Yao等[13]對整個語料庫構圖,將詞與文檔作為節點,詞節點之間的邊依據詞的共現信息構建,文檔節點與詞節點之間的邊由詞頻和詞的文檔頻率構建,通過圖神經網絡對圖進行建模從而將文本分類問題轉化為節點分類問題。Liu等[14]提出TensorGCN框架用于文本分類問題,框架利用語義、句法、順序上下文信息構造文本圖張量,并執行圖內傳播、圖間傳播分別用于在單個圖中聚合來自鄰居節點的信息以及協調圖之間的異構信息。
1.2 標簽嵌入
標簽嵌入學習是通過學習標簽的向量表示來增強模型的分類效果。Chai等[15]提出引入外部知識生成標簽的模板描述、從輸入文本中抽取關鍵句生成標簽的提取表述和通過語言模型生成輸入文本的摘要得到標簽的抽象描述從而得到標簽的向量表示;Zhou等[6]利用不同標簽在數據集中出現的次數作為先驗概率來構建標簽結構樹對標簽進行編碼;Pappas等[16]提出一種連接文本向量和標簽向量的方式,用來提取標簽之間的非線性關系;Du等[17]通過計算單詞向量與標簽向量的logits來解決傳統文本分類忽略字級匹配的問題。Huang等[18]使用注意力機制,讓學習的文本向量與標簽向量進行循環學習、交互。本文也構建了模型學習標簽之間的關系從而生成含有豐富信息的標簽嵌入向量。
1.3 標簽平滑
標簽平滑算法(label smoothing:LS)由Szegedy等[19]于2016年提出。標簽平滑用于解決由使用one-hot向量表示標簽帶來的模型過擬合的問題,以及全概率和零概率導致樣本所屬類別和其他類別預測概率相差盡可能大致使模型過于自信的問題。當面對數據集標簽集合中某些標簽存在一定相似性以及數據集存在誤標的情況下仍使用one-hot向量表示標簽會一定程度上影響模型的預測能力。標簽平滑通過引入超參數E作為錯誤率,當樣本標簽為0時,使用較小的E而不直接使用0作為標簽進行訓練,同樣的,當樣本標簽為1時,使用1-E作為樣本標簽進行訓練,使樣本標簽變得不那么極端,從一定程度上增強了模型的泛化能力。Müller等[20]指出LS除了可以提高模型的泛化能力以外還可以提高模型的校準性。He等[21]也驗證了LS在圖片分類任務中取得的優異表現。
1.4 標簽增強
標簽分布反映了數據集中每個標簽與樣本匹配的程度。然而大多數數據集的標簽都是單一標簽的集合,要獲取數據真實的標簽分布,需要對每條樣本進行大量的標注,當標簽數目較多時,會花費大量的時間與精力,標注的準確性也得不到保障。因此,Gayar等[22]、Wang 等[23]、Hou等[24]、Guo等[25]分別提出了 Fuzzy C-Means、Label Propagation、Mainifold Learning、Labe confusion learning 等標簽增強的方法,利用樣本集自身的特征空間構造標簽分布。
2 模型設計
LHSSL的模型框架如圖2所示。整個框架主要分為三個部分:預測概率分布計算、標簽模擬分布構造以及損失計算。
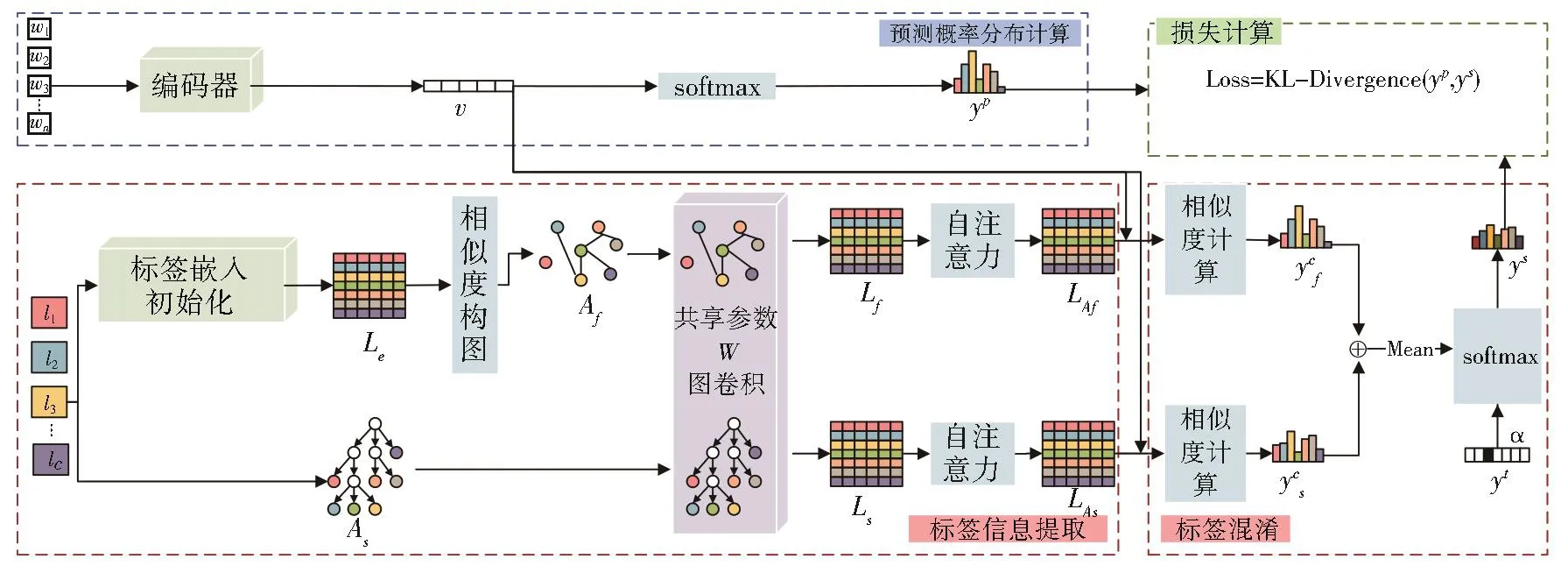
圖2 模型結構Fig.2 Model structure
2.1 預測概率分布計算
計算輸入文本分類預測概率分布,可以使用任何一種輸入編碼器,例如:CNN、RNN、LSTM、Bert等用于提取輸入文本特征。連接softmax激活函數進行非線性轉換得到預測的標簽的概率分布。
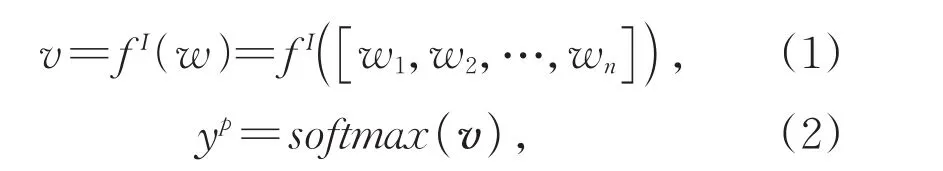
其中fI為輸入編碼函數,用于將長度為n的輸入文本 w=[w1,w2,…,wn]轉化為長度為 n、維度為 d 的向量表示 v=[v1,v2,…,vn]。yp為預測的概率分布。
2.2 標簽模擬分布構造
2.2.1 標簽信息提取模塊
標簽信息提取模塊分為兩個子模塊:標簽語義結構特征提取和標簽層級結構特征提取。
標簽語義結構特征提取模塊首先初始化標簽嵌入向量,將包含層級結構的標簽集L中的每個標簽按照層級結構拆分為多個單詞。如talk.politics.mideast可拆分為單詞talk、politics、mideast三個單詞的共同表示。通過引入使用外部語料庫預訓練好的語言模型,如word2vec、glove等,得到每個單詞的嵌入向量。將單詞嵌入向量累加后除以單詞的個數得到每個層級標簽的嵌入表示。
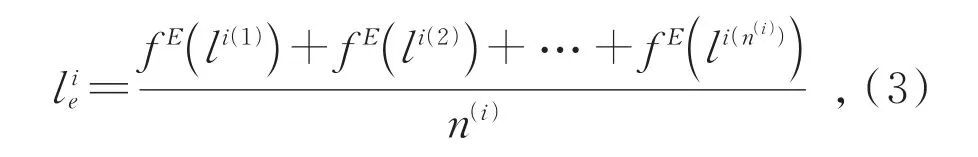
其中n(i)為第i個層級標簽中的單詞數量。拼接每個層級標簽嵌入向量后得到標簽集初始嵌入矩陣為標簽層級結構葉子節點個數,即數據集標簽個數。通過余弦相似度計算每個標簽嵌入向量間的相似度用于構圖,連接相似度大于0.8的節點對,并將節點對間的連接強度用min-max進行標準化后作為鄰接矩陣Af中對應元素的值。
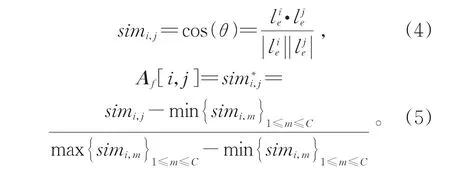
標簽層級結構特征提取模塊通過數據集中標簽本身的層級結構構造結構關系圖。圖3為20NG數據集標簽層級結構的一部分。其中標簽talk.politics.guns和talk.politics.mideast分別由單詞 talk、politics、guns和單詞 talk、politics、mideast組成。其中相同的單詞為talk和politics,即兩個標簽同屬于父級標簽talk下的politics中,因此具有兩級的層級相關性,關系圖中對應邊的權重為2。基于這個規則,再次構建一個初始值為0,大小為C*C的鄰接矩陣As,其中元素的值由兩兩標簽之間的層級相關度決定。
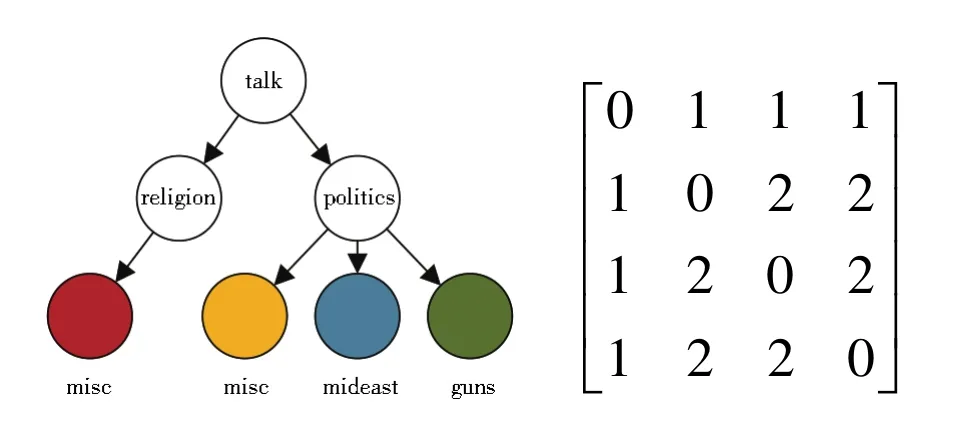
圖3 Talk標簽組層級結構圖及層級結構矩陣Fig.3 “Talk”label group hierarchy chart and hierarchy matrix
標簽的語義結構特征和層級結構特征并不是完全無關的。Ding等[26]在異常節點檢測任務中提出通過元學習利用同領域中不同關系圖提取節點的特征,并驗證了其有效性。同時,數據集標簽數量較少。基于這兩點,提出通過共享參數矩陣的單層圖卷積提取兩個圖數據的相關特征并得到包含共享特征的標簽嵌入。
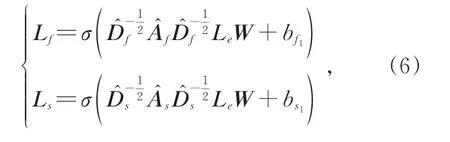

2.2.2 標簽混淆模塊
通過點積計算輸入文本嵌入v與兩種標簽嵌入LAf和LAs中每個標簽的相似度得到兩個相似度分布隨著輸入文本的變化也是基于輸入樣本動態變化的,在只考慮標簽之間相關性的基礎上又增加了一定的靈活性。

其中Wf∈RC×C、Ws∈RC×C、bf∈RC、bs∈RC分別為可學習的參數矩陣和偏置項。將兩個相似度概率分布相加取平均值后可得到標簽分布yc:

將通過相似度計算得到的標簽概率分布作為target缺乏一定的準確性與說服力。因此引入原始樣本真實標簽的one-hot向量yt構建標簽模擬分布ys,并用超參數α控制真實標簽的指導程度(標簽模擬分布的流程如表1所示):

表1 標簽模擬分布構造流程Table 1 Flowchart of construction of label simulation distribution

2.3 損失計算
使用KL散度作為損失函數,衡量模擬標簽分布ys和預測標簽分布yp的匹配程度:
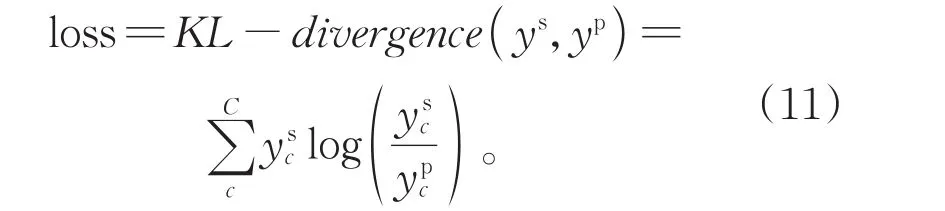
通過最小化KL散度對模型進行優化。學習的標簽模擬分布使得標簽的表示更加平滑,有助于使模型更好地表達容易混淆的樣本。面對相似性較強的樣本時,模型會將錯誤標簽的概率按標簽結構關系和語義關系分配到相似的標簽上,增強了模型的泛化能力以及應對噪聲的能力。
3 實驗設置
3.1 數據集
本文在4個數據集上進行了實驗:20NG、8NG_H、8NG_E和WOS11967。
20NG全名為20NewsGroups,是一個用于文本分類、文本挖掘和信息檢索研究的新聞語料數據集。20NG數據集一共有18 821條樣本,分為20個標簽,屬于5個標簽組。從20NG數據集中選取相關性較強的8個類別和相關性較弱的8個類別的樣本集合,并將他們劃分為20NG的兩個子數據集8NG_H和8NG_E,如表2所示。

表2 8NG_H和8NG_E數據集的標簽劃分Table 2 Label division of 8NG_H and 8NG_E dataset
WOS11967[27]是通過 Web of Science 論文數據庫構建的文本分類數據集。WOS11967是WOS數據集的子數據集,共有35個類別標簽,隸屬于 Computer Science、Electrical Engineering、Psychology、Mechanical Engineering、Civil Engineering、Medical Science、biochemistry共7個大類下。每條樣本包含一篇文章的標簽、關鍵詞和摘要,練集本文只選擇文章的標簽和摘要作為最終的數據。每個數據集中的訓、驗證集、測試集隨機劃分,訓練集、驗證集的樣本數量占整個數據集的60%和15%,剩余的為測試集。
4個數據集的基本信息如表3所示。其中|L|是每個數據集的標簽數量,Max Depth是標簽層級結構最大深度,Avg(|Li|)是平均每個節點的深度。Train Size、Val Size、Test Size分別表示訓練集、驗證集、測試集的樣本數目。
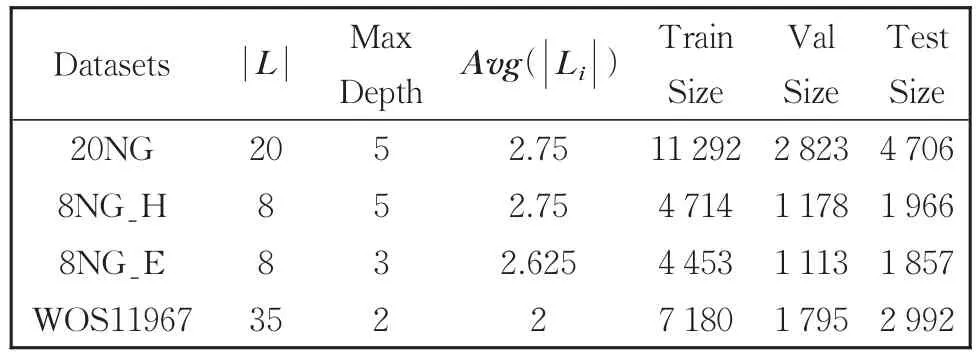
表3 數據集基本信息Table 3 Basic information of data set
3.2 實驗參數設置
模型中主要超參數α、st的設置如表4-5所示。

表4 噪聲為0時α和st的取值Table 4 Values ofαandstwhen the noise is 0

表5 噪聲為0.3時α和st的取值Table 5 Values ofαandstwhen the noise is 0.3
除α以及st以外,構建標簽語義結構圖時使用的相似度閥值參數設置為0.8。詞嵌入維度為768,詞典大小為20 000。實驗將LHSSL模型與傳統的文本分類模型Bert、LSTM以及加入標簽平滑后的Bert和LSTM進行對照。其中Bert中Transformer編碼器隱層為2、隱層神經元數為128、多注意力頭的數目為2。模型的隱層維度為64維。在訓練中使用Adam優化器,學習率設置為0.000 1,訓練過程中的批處理大小為512,使用Bert為基本預測模型時的迭代次數為150次,使用LSTM為基本預測模型時迭代次數為60次。為了防止過擬合,在網絡的每一層加入Dropout,丟棄概率為0.5。同時,label smooth的E為0.1,圖卷積的Adam優化器的學習率為0.2。
3.3 實驗參數設置
觀察表6-8中數據可以得到結論:無論數據集的標簽中是否含有噪聲,利用標簽的語義關系以及層級結構關系特征,從一定程度上都能提高模型的分類性能。

表6 無噪聲時測試集上的準確率Table 6 Accuracy on test set without noise
當數據真實標簽中不含噪聲且使用Bert作為基本預測模型時,加入標簽平滑或使用LHSSL并沒有明顯的提升,甚至在8NG_E數據集上有了0.247 8%的輕微下降。其中8NG_E標簽數量少、相關性弱、層級結構少且淺,導致加入元素基本都為0的矩陣作為標簽關系信息對模型幾乎起不到任何作用,這是導致出現這一結果的主要原因。同理,8NG_H由于標簽層級結構較為單一,準確率提升同樣不明顯。而20NG、WOS11967數據集標簽相對較多,標簽結構相對復雜,學習到的標簽相關性也更加豐富,分類的效果因此挺升得相對較多。當使用LSTM作為基本預測模型時,這一特點更加顯著。因此可以得出:當數據集標簽數量越多、標簽關系越復雜時,LHSSL模型的提升效果越好。同時,當數據集中不存在噪音或存在少量噪音時,分類準確率提升更加顯著。

表7 10%噪聲時測試集上的準確率Table 7 Accuracy on test set at 10% noise
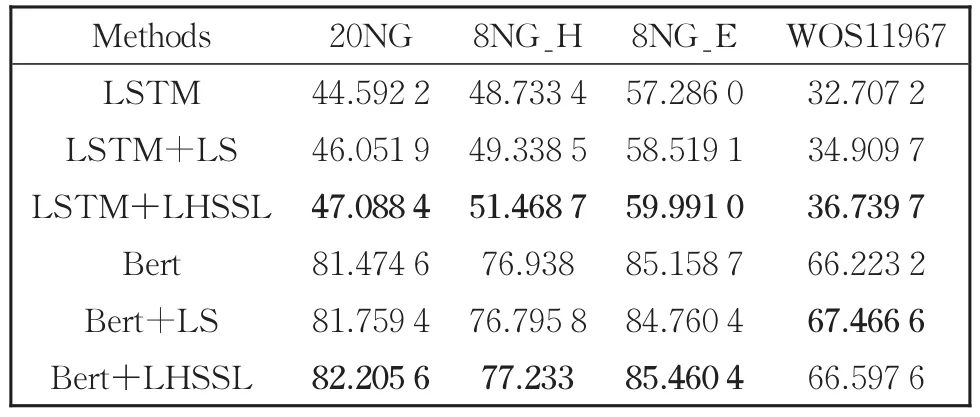
表8 30%噪聲時測試集上的準確率Table 8 Accuracy on test set at 30% noise
對模型分類結果(如圖4-圖5)可視化后可以觀察到在相似度較高的標簽的樣本上分類效果提升并不明顯。但在對分類效果較差的類別上,增加LHSSL模塊的確對準確率提高有一定作用。例如用黃框中sci.med被誤分為comp.sys.mac.hardware的數量明顯下降,證明在標簽關系上模型學習到一些有用信息,為標簽增加了一定的區分度。
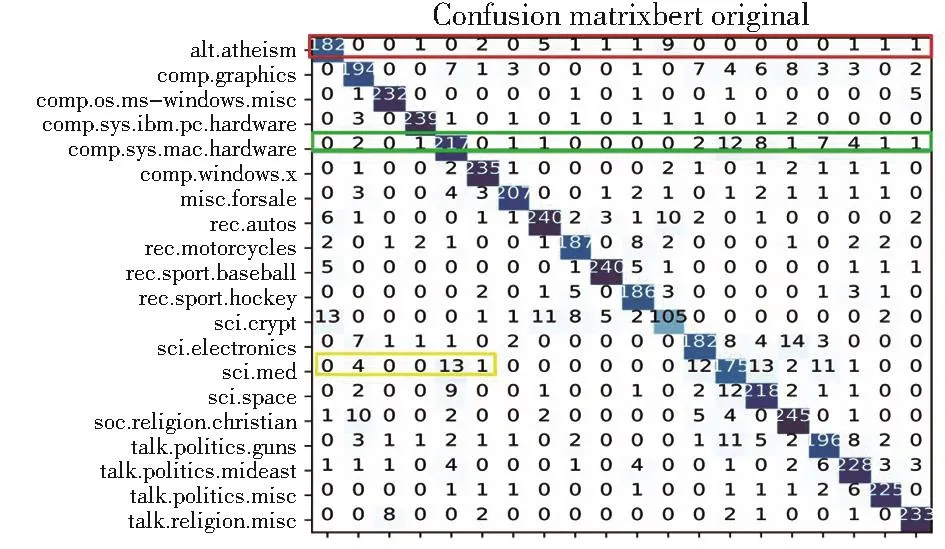
圖4 Bert在20NG測試集上的分類結果Fig.4 Classification results of Bert on 20NG test set
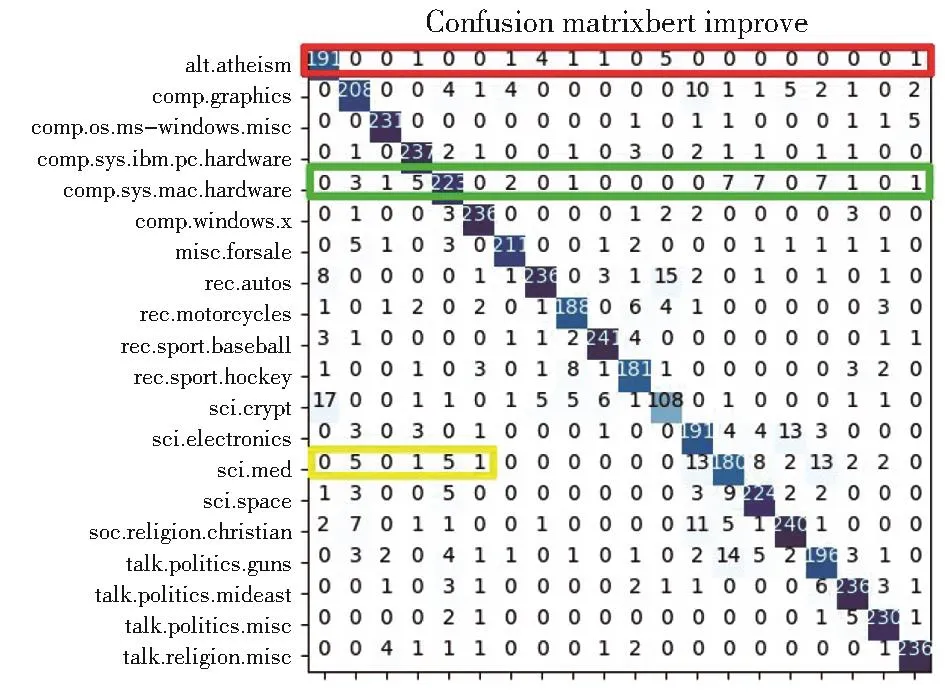
圖5 Bert+LHSSL在20NG測試集上的分類結果Fig.5 Classification results of Bert+LHSSL on 20NG test set
由圖6可以觀察到,除了類別19,20NG數據集中每個類別的樣本數目幾乎不存在明顯差異。而WOS11967數據集中,每個類別的樣本數量逐漸減少,最多只有450條左右,最少只有53條,相差將近8倍。這可能導致模型在訓練集上沒有捕捉到足夠的特征信息,出現在訓練集上準確率高而在驗證集與測試集上準確率較差的情況。因此在未來的工作中還需要針對樣本數量少以及樣本不均衡的問題進一步對模型進行改進。
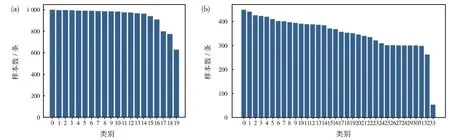
圖6 20NG(a)、WOS11967(b)數據集樣本分布Fig.6 Sample distribution of 20NG(a)and WOS11967(b)data sets
3.4 消融實驗
為驗證加入標簽語義圖、標簽結構圖以及融合兩個圖的特征對模型分類效果的提升作用,在 20NG、8NG_H、8NG_E、WOS11967四個數據集上進行了消融實驗。觀察僅通過預訓練詞向量生成的標簽嵌入與輸入文本嵌入構造模擬分布、只對標簽語義圖進行卷積、只對標簽結構圖進行卷積以及提取標簽語義圖和標簽結構圖的共享特征四種情況時,模型的分類效果。并在20NG數據集上采用T檢驗進行顯著性驗證。首先提出零假設,即各模塊對模型分類效果提升沒有明顯差別。設立檢驗水準為0.05,通過計算,p值分別為0.007 89、0.006 77、0.014 40均小于檢驗水準,因此拒絕原假設,統計顯著。
觀察表9,可以得出結論,無論標簽語義結構特征還是標簽層級結構特征,對分類都有較好的提升作用。這表明,當面對標簽沒有層級結構的文本分類任務數據集時,通過構造標簽語義結構并學習其特征,同樣能提高模型預測的準確率。而在融合兩個圖的共享特征后,模型的性能有了進一步提高。大部分情況下,使用標簽語義結構特征對模型的提升作用大于使用標簽層級結構特征。由于8NG_H數據集中標簽的層級結構較為單一,大多數標簽為父級標簽下一級的標簽,相較于層級結構信息,標簽集的語義相關信息更加復雜,因此使用語義圖特征的效果提升比使用層級結構圖特征更加明顯,甚至在學習共享特征后,模型的準確率比起只使用語義結構特征反而降低了1.409 2%。而當使用8NG_E數據集時,使用層級結構特征比使用語義結構特征準確率更高,這是因為8NG_E中標簽差異性較強而相關性較弱,因此并不能生成相較豐富的語義結構特征供模型進行學習訓練。
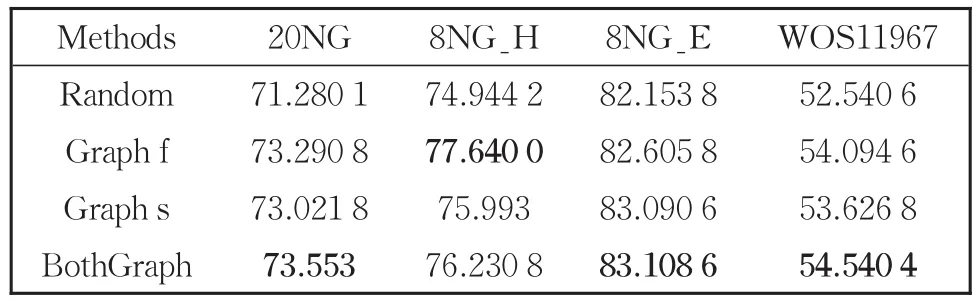
表9 標簽噪聲為0時消融實驗效果Table 9 Effect of ablation on test data sets with 0 noise
3.5 參數敏感性實驗
模型引入超參數α用來控制真實標簽的指導程度,不同的數據集α的取值不同。經過實驗,發現引入標簽噪聲、數據集標簽數量、標簽層級結構的深度和復雜度等因素對α的取值都有一定影響。
實驗結果表明,在20NG數據集中,數據集樣本標簽不含有噪聲時,α設置為0.5的準確率相較于設置為3和8時更高。當對標簽引入0.3的噪聲時,α設置為3時模型的準確率高于α設置為0.5,因此面對包含一定噪聲的數據集時,需要原始標簽對模型預測指導程度更強。圖7呈現的是擾動為0和0.3時WOS11967驗證集的準確率。可以觀察到在添加擾動時設置一個相對較大的α模型的準確率更高,而不添加擾動時設置相對較大的α效果同樣較好,這可能是因為WOS11967數據集中每個標簽都隸屬于某個父標簽,層級結構都為2,導致不同標簽的層級結構信息幾乎完全相似,因此需要原始標簽較強的指導。

圖7 在噪聲為0(a)與0.3(b)的WOS11967數據集上α的敏感性實驗Fig.7 Sensitivity experiment ofαon WOS11967 data set with noise of 0(a)and 0.3(b),respectively
圖8呈現的是擾動為0時模型在8NG_H和8NG_E驗證集上的準確率。由于8NG_E數據集標簽相關性較低且幾乎沒有層級結構,可看作相對獨立的標簽,因此α的取值仍較大。8NG_H數據集存在各標簽層級信息差異不明顯,但其標簽層級結構相較于8NG_E更加豐富,因此α取值分別為0.5、3、8時模型準確率的差異沒有8NG_E大。

圖8 在噪聲為0的8NG_H(a),8NG_E(b)數據集上α的敏感性實驗Fig.8 Sensitivity experiment ofαon 8NG_H(a),8NG_E(b)data sets with noise of 0,respectively
同時為了避免過擬合,獲得相對較好的泛化能力,使用早停策略。即當模型在數據集上進行了st次完整的訓練時,停止使用標簽混淆分布而使用原始的one-hot向量和基本分類模型進行訓練。圖9可以觀察到在加入早停策略后,模型在無噪聲的WOS11967數據集上分類準確率有了明顯提高,而在數據集存在噪聲時提升較小,且由于標簽混亂導致持續波動,模型不能很好地擬合。
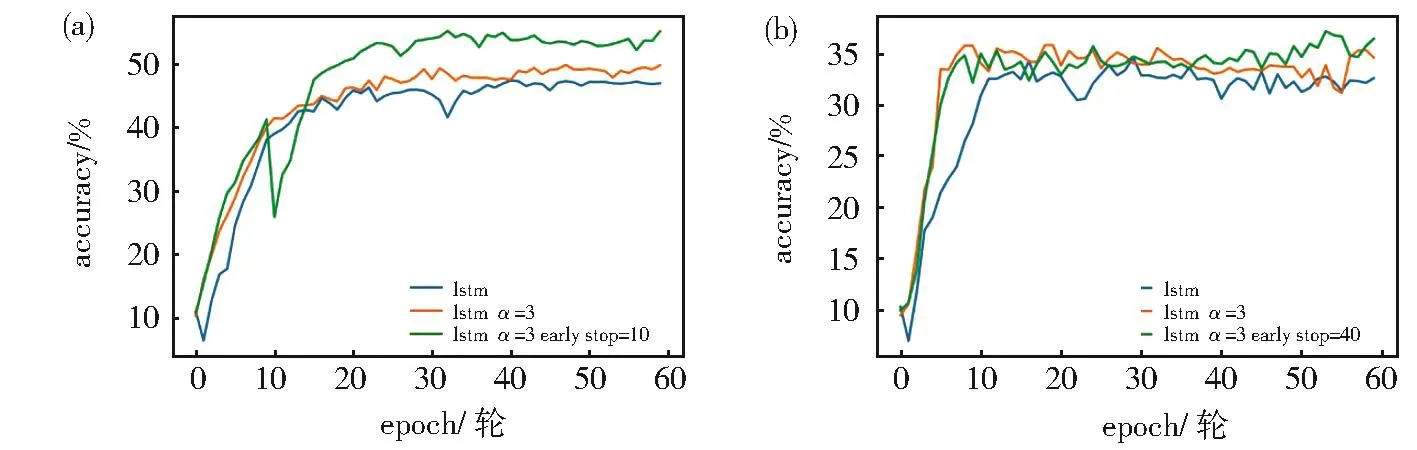
圖9 在噪聲為0(a)與0.3(b)的WOS11967數據集上st的敏感性實驗Fig.9 Sensitivity experiment ofston WOS11967 data set with noise of 0(a)and 0.3(b),respectively
4 結論
本文通過學習標簽結構特征解決層級標簽文本分類任務沒有充分利用標簽信息的問題。首先使用基本編碼器連接softmax得到標簽預測分布。然后通過共享參數的圖卷積神經網絡學習利用標簽集構造的標簽語義結構圖和標簽層級結構圖的特征,得到兩種標簽嵌入,并使用自注意力機制學習標簽關系。計算輸入文本嵌入與標簽嵌入的相似度分布。引入超參數控制樣本真實標簽的指導程度,構造標簽模擬分布。計算標簽模擬分布與標簽預測分布的KL散度。通過與忽視標簽信息直接對輸入文本分類與使用標簽平滑提高模型的魯棒性,LHSSL能進一步提升層級標簽分類的準確率。該模型不改變原始分類模型的結構,并且只在訓練的過程中使用,因此不會增加模型預測的時間損耗。并且標簽關系越復雜,預測準確率提升越明顯。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
