類(lèi)間數(shù)據(jù)不均衡條件下基于平衡隨機(jī)森林的軸向柱塞泵故障診斷方法
2022-06-09 06:29:12馬歆宇岳毅趙亞鵬
液壓與氣動(dòng) 2022年3期
關(guān)鍵詞:分類(lèi)
馬歆宇岳 毅趙亞鵬
(1.燕山大學(xué) 河北省重型機(jī)械流體動(dòng)力傳輸與控制重點(diǎn)實(shí)驗(yàn)室,河北 秦皇島 066004;2.燕山大學(xué) 先進(jìn)鍛壓成形技術(shù)與科學(xué)教育部重點(diǎn)實(shí)驗(yàn)室,河北 秦皇島 066004)
引言
作為液壓系統(tǒng)的主要?jiǎng)恿υ簤罕玫男阅苤苯佑绊懸簤合到y(tǒng)的正常工作[1-4],其狀態(tài)監(jiān)測(cè)與故障診斷是液壓系統(tǒng)運(yùn)維的重要環(huán)節(jié)。軸向柱塞泵常見(jiàn)故障有泵發(fā)熱、配流盤(pán)磨損、滑靴與斜盤(pán)磨損、松靴以及輸出流量不足等[5-7]。
在實(shí)際的液壓泵故障診斷過(guò)程中,正常樣本的數(shù)量遠(yuǎn)大于故障樣本的數(shù)量,即不同類(lèi)別的樣本數(shù)量極度不均衡。這時(shí),傳統(tǒng)的分類(lèi)方法就難以取得好的分類(lèi)效果。因?yàn)椴煌?lèi)別樣本數(shù)量差距很大,在分類(lèi)時(shí)分類(lèi)器會(huì)將少數(shù)類(lèi)樣本誤判為多數(shù)類(lèi)樣本從而無(wú)法達(dá)到較高的分類(lèi)準(zhǔn)確率。目前非均衡數(shù)據(jù)處理方法一般分為兩類(lèi):一是數(shù)據(jù)層面,通過(guò)欠采樣或過(guò)采樣方法改變數(shù)據(jù)的原始分布,將非均衡數(shù)據(jù)轉(zhuǎn)變?yōu)榫鈹?shù)據(jù);二是算法層面,通過(guò)改進(jìn)分類(lèi)器提高少數(shù)類(lèi)樣本的識(shí)別準(zhǔn)確率。
從數(shù)據(jù)層面處理非均衡數(shù)據(jù)的方法是重構(gòu)數(shù)據(jù)集,使非均衡數(shù)據(jù)趨向均衡,然后進(jìn)行處理[8]。重構(gòu)數(shù)據(jù)集的方法是重采樣,有欠采樣與過(guò)采樣兩種。
欠采樣算法通過(guò)除去一部分多數(shù)類(lèi)樣本使其與少數(shù)類(lèi)樣本數(shù)量一致或相近來(lái)實(shí)現(xiàn)數(shù)據(jù)均衡。常見(jiàn)的欠采樣算法有隨機(jī)欠采樣算法、Tomek links方法[9]、壓縮最近鄰規(guī)則、單邊選擇方法[10]、近鄰清理方法[10-11]等。因?yàn)榍凡蓸铀惴〞?huì)除去部分樣本,所以被除去樣本的屬性也會(huì)一并除去,因此會(huì)影響原始數(shù)據(jù)的分布進(jìn)而影響分類(lèi)器的性能。
過(guò)采樣通過(guò)人為增加少數(shù)類(lèi)樣本使少數(shù)類(lèi)樣本數(shù)目與多數(shù)類(lèi)樣本數(shù)目一致或相近,從而達(dá)到數(shù)據(jù)均衡。常見(jiàn)的過(guò)采樣方法有隨機(jī)過(guò)采樣、合成少數(shù)類(lèi)過(guò)采樣(Synthetic Minority Over-sampling Technique,SMOTE)[12]。ESTABROOKS A等[13]提出根據(jù)數(shù)據(jù)集情況自適應(yīng)地選擇重采樣率的多重采樣方法;TAEHO J等[14]提出根據(jù)聚類(lèi)改進(jìn)的同時(shí)能夠處理非均衡數(shù)據(jù)類(lèi)間問(wèn)題和類(lèi)內(nèi)問(wèn)題的采樣方法;HAN Hui等[15]對(duì)SMOTE方法進(jìn)行了改進(jìn),提出了僅對(duì)邊界附近少數(shù)類(lèi)樣本進(jìn)行過(guò)采樣的Borderline-SMOTE過(guò)采樣方法;HE Haibo等[16]提出性能優(yōu)于SMOTE和隨機(jī)過(guò)采樣的自適應(yīng)合成采樣算法。由于過(guò)采樣方法是增加樣本數(shù)量,這有可能會(huì)造成樣本重復(fù),若樣本特征較少則會(huì)導(dǎo)致過(guò)擬合。
從算法層面處理非均衡數(shù)據(jù)的方法是對(duì)數(shù)據(jù)集內(nèi)不同類(lèi)別的樣本設(shè)置不同的特征權(quán)重,或改變算法的結(jié)構(gòu)。目前使用較多的方法有集成學(xué)習(xí)算法、代價(jià)敏感算法等。
將多個(gè)弱分類(lèi)器組合成1個(gè)強(qiáng)分類(lèi)器,是集成方法中被廣泛使用的技術(shù)。常見(jiàn)的集成學(xué)習(xí)方法有Bagging算法、Boosting算法以及隨機(jī)森林(Random Forest,RF)算法等。AdaBoost算法是一種提高集成方法性能的算法,通過(guò)多次迭代,在每次迭代中修改正確分類(lèi)樣本與錯(cuò)誤分類(lèi)樣本的權(quán)重來(lái)提高分類(lèi)效果。SUN Yanmin等[17]改進(jìn)了AdaBoost算法,提出了AdaC1算法、AdaC2算法以及AdaC3算法;CHAWLA N V等[18]結(jié)合AdaBoost與SMOTE兩種算法,提出了提升泛化能力的SMOTEBoost算法; CHEN Chao等[19]改進(jìn)了隨機(jī)森林算法,提出了集數(shù)據(jù)均衡與分類(lèi)為一體的平衡隨機(jī)森林(Balanced Random Forest,BRF)算法。
此外,深度學(xué)習(xí)作為一種端到端的數(shù)據(jù)驅(qū)動(dòng)方法,在處理數(shù)據(jù)非均衡問(wèn)題方面也有著廣泛的應(yīng)用。SOHONY I等[20]采用神經(jīng)網(wǎng)絡(luò)集成算法處理類(lèi)不均衡問(wèn)題;KAZEMI Z等[21]提出使用深度自編碼器從樣本中提取特征,并使用Softmax網(wǎng)絡(luò)進(jìn)行樣本分類(lèi)以解決非均衡問(wèn)題。上述方法雖能在一定程度上解決數(shù)據(jù)非均衡問(wèn)題,但仍存在評(píng)價(jià)指標(biāo)不完善、在極度不均衡數(shù)據(jù)集上表現(xiàn)較差的缺點(diǎn)。
綜上所述,為解決軸向柱塞泵故障診斷中出現(xiàn)的正常數(shù)據(jù)與各類(lèi)故障數(shù)據(jù)不均衡的問(wèn)題,本研究將BRF算法應(yīng)用于軸向柱塞泵故障診斷領(lǐng)域;通過(guò)與傳統(tǒng)的SMOTE-RF算法、RF算法進(jìn)行比較,驗(yàn)證了BRF算法處理類(lèi)間數(shù)據(jù)不均衡條件下軸向柱塞泵故障診斷問(wèn)題的優(yōu)越性。
1 相關(guān)算法原理
1.1 SMOTE算法
SMOTE算法避免了隨機(jī)過(guò)采樣帶來(lái)的過(guò)擬合風(fēng)險(xiǎn),其并非復(fù)制現(xiàn)有的樣本,而是生成人造樣本,原理如圖1所示,X為樣本點(diǎn),通過(guò)對(duì)隨機(jī)選擇的少數(shù)類(lèi)樣本及其相鄰的少數(shù)類(lèi)樣本之間進(jìn)行線性插值來(lái)實(shí)現(xiàn)樣本生成。SMOTE執(zhí)行3個(gè)步驟來(lái)生成合成樣本:首先,選擇1個(gè)隨機(jī)的少數(shù)類(lèi)樣本a;在k個(gè)最近的少數(shù)類(lèi)鄰域中選擇樣本b;最后,在2個(gè)樣本之間隨機(jī)插值,得到新的樣本,插值公式如下:
x=a+w(b-a)
(1)
式中,x—— 新生成的樣本
w—— [0,1]之間的隨機(jī)權(quán)重
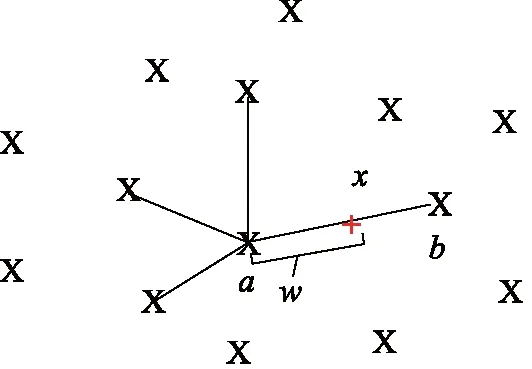
圖1 SMOTE算法樣本合成原理Fig.1 Sample synthesis principle of SMOTE algorithm
1.2 RF算法
RF算法是一種以決策樹(shù)為基本分類(lèi)器的集成算法。RF算法使用自助抽樣,從原始樣本中選取若干樣本組成樣本集,決策樹(shù)對(duì)每個(gè)樣本集進(jìn)行建模,組合多個(gè)決策樹(shù)的預(yù)測(cè),并通過(guò)投票獲得最終的預(yù)測(cè)結(jié)果[22],該算法的理論方法描述如下:
(1) 假設(shè)原始訓(xùn)練集中有N個(gè)樣本,采用隨機(jī)且有放回的自助抽樣選取自助樣本集,建立決策樹(shù),每次未選取的樣本構(gòu)成袋外(Out of Bag,OOB)數(shù)據(jù);
(2) 假設(shè)屬性總數(shù)為M,在每個(gè)決策樹(shù)的每個(gè)節(jié)點(diǎn)上隨機(jī)抽樣提取m(遠(yuǎn)小于M)個(gè)屬性,之后再采用某種策略(如信息增益等),從m個(gè)屬性中選擇一個(gè)最優(yōu)屬性作為分支和生長(zhǎng)的分裂變量;
(3) 分割節(jié)點(diǎn)按照步驟(2)處理,每棵決策樹(shù)都將生長(zhǎng)置于修剪之上(即生長(zhǎng)優(yōu)先于修剪);
(4) 生成的多個(gè)決策樹(shù)形成隨機(jī)森林,新的數(shù)據(jù)通過(guò)隨機(jī)森林分類(lèi)器進(jìn)行鑒別和分類(lèi),最終的分類(lèi)結(jié)果通過(guò)簡(jiǎn)單的投票獲得。
一般情況下,隨機(jī)森林是由大量分類(lèi)回歸樹(shù)(Classification and Regression Tree,CART)構(gòu)建而成的,CART決策樹(shù)以基尼系數(shù)為屬性選擇的標(biāo)準(zhǔn)。在理想狀態(tài)下,隨著節(jié)點(diǎn)不斷分裂,決策樹(shù)分支節(jié)點(diǎn)中的樣本也應(yīng)盡可能屬于同一類(lèi)[22],即保持節(jié)點(diǎn)的高“純度”。假設(shè)當(dāng)前數(shù)據(jù)集D中第k類(lèi)樣本所占的比例為pk(k=1,2,……,K),數(shù)據(jù)集D的純度可以用式(2)來(lái)體現(xiàn):
(2)
Gini(D)代表從數(shù)據(jù)集D中隨機(jī)選取2個(gè)樣本,其類(lèi)別不相同的概率。Gini(D)越小,數(shù)據(jù)集的純度越高。
設(shè)離散屬性a有Y個(gè)可能的取值,A={a1,a2,a3,…,aY},使用A對(duì)數(shù)據(jù)集D進(jìn)行劃分,就會(huì)生成Y個(gè)分支節(jié)點(diǎn),其中第i個(gè)分支節(jié)點(diǎn)囊括了D中所有在A上取值為ai的樣本,記為Di。
屬性a的基尼系數(shù)為:
(3)
式中,|D| —— 數(shù)據(jù)集D中樣本的數(shù)量
|Di| —— 數(shù)據(jù)集D在第i個(gè)分支節(jié)點(diǎn)中的樣本數(shù)量
在屬性選擇時(shí),選擇屬性集合A中基尼系數(shù)最小的屬性即可:
a*=arg min (Gini(D,A)),a*∈A
(4)
式中,a*—— 屬性集合中基尼系數(shù)最小的屬性。
在構(gòu)建決策樹(shù)時(shí),對(duì)于每棵樹(shù)(以第k棵樹(shù)為例),大約1/3的樣本不參與第k棵樹(shù)的生成。這些樣本是第k棵樹(shù)的OOB樣本。OOB樣本可以估計(jì)訓(xùn)練集之外的樣本的誤差率,該誤差被稱(chēng)為模型的推廣誤差。OOB誤差是隨機(jī)森林泛化誤差的無(wú)偏估計(jì),其結(jié)果類(lèi)似于k折交叉驗(yàn)證。
RF算法可以根據(jù)OOB樣本評(píng)估特征的重要性。對(duì)于隨機(jī)森林模型,假設(shè)其1個(gè)屬性變成1個(gè)隨機(jī)數(shù);這個(gè)屬性在模型中的重要性是通過(guò)比較變化前后的OOB誤差來(lái)評(píng)估的。屬性重要性的度量被定義為平均遞減精度(Mean Decreasing Accuracy,MDA)其表達(dá)式如下:
(5)
式中,Hn—— 改變特征后的OOB誤差
Qo—— 改變特征前的OOB誤差
Nt—— 決策樹(shù)的數(shù)量
OOB誤差下降程度越大,對(duì)應(yīng)屬性的重要性也越高。
將屬性按重要性高低降序排列,再根據(jù)重要性剔除1個(gè)或多個(gè)屬性,從而得到1個(gè)新的屬性集。使用新的屬性集重復(fù)上述步驟,直到剩余屬性個(gè)數(shù)達(dá)到設(shè)定值。最后比較步驟中所得到的各個(gè)屬性集對(duì)應(yīng)的OOB誤差率,選出OOB誤差率最小的屬性集,該屬性集中屬性的數(shù)量即為最佳決策樹(shù)節(jié)點(diǎn)屬性數(shù)量。
該算法在保持單棵樹(shù)精度不變的前提下,通過(guò)引入隨機(jī)性來(lái)降低決策樹(shù)之間的相關(guān)性。因此,RF算法可以提高預(yù)測(cè)的準(zhǔn)確性,而不會(huì)顯著增加計(jì)算量。鑒于這種優(yōu)異的性能,RF算法得到了廣泛的應(yīng)用。
1.3 BRF算法
在學(xué)習(xí)極不平衡的數(shù)據(jù)時(shí),自助抽樣很少甚至不會(huì)對(duì)少數(shù)類(lèi)樣本進(jìn)行抽取,這就導(dǎo)致決策樹(shù)在少數(shù)類(lèi)的預(yù)測(cè)方面表現(xiàn)很差。改善這一問(wèn)題的一個(gè)簡(jiǎn)單方法是使用分層自助抽樣,即在每個(gè)類(lèi)別中都進(jìn)行抽樣,但這種方法效果不佳。以往的研究表明,通過(guò)對(duì)多數(shù)類(lèi)進(jìn)行欠采樣或?qū)Ψ嵌鄶?shù)類(lèi)進(jìn)行過(guò)采樣來(lái)人為地使樣本均衡,對(duì)于給定的性能度量來(lái)說(shuō),這種方法更有效,并且欠采樣比過(guò)采樣具有優(yōu)勢(shì)。BRF算法從平衡的欠采樣數(shù)據(jù)中歸納出系統(tǒng)樹(shù), BRF算法的理論方法如下:
(1) 在每輪自助抽樣中加入隨機(jī)欠采樣方法,從少數(shù)類(lèi)中隨機(jī)抽取若干樣本,隨后從多數(shù)類(lèi)中隨機(jī)抽取相同數(shù)量的樣本組成均衡數(shù)據(jù)集,使用均衡數(shù)據(jù)集作為每次迭代的數(shù)據(jù)集;
(2) 在不修剪的情況下,從數(shù)據(jù)中歸納出最大規(guī)模的決策樹(shù),該樹(shù)由CART算法歸納而成,并做出以下修改: 在每個(gè)節(jié)點(diǎn)上,不是搜索所有屬性以獲得最佳分裂變量,而是僅隨機(jī)選取一個(gè)屬性作為分裂變量;
(3) 重復(fù)上述步驟,生成的多棵決策樹(shù)形成平衡隨機(jī)森林,新的數(shù)據(jù)通過(guò)平衡隨機(jī)森林分類(lèi)器進(jìn)行鑒別和分類(lèi),最終的分類(lèi)結(jié)果通過(guò)簡(jiǎn)單的投票獲得。
設(shè)非均衡數(shù)據(jù)集中各類(lèi)別樣本數(shù)量的比例為n1∶n2∶n3∶…∶nk。在RF算法的自助抽樣中,少數(shù)類(lèi)樣本很少被納入抽取范圍,此時(shí)決策樹(shù)中可能存在樣本類(lèi)別不全的現(xiàn)象;若使用分層自助抽樣,則各類(lèi)別樣本的權(quán)重是默認(rèn)相等的,即每輪自助抽樣中從訓(xùn)練集抽取的各類(lèi)別樣本數(shù)量的比例趨近于n1∶n2∶n3∶…∶nk,此時(shí)每棵決策樹(shù)中的重組數(shù)據(jù)集依舊是不均衡的。
BRF算法對(duì)此進(jìn)行了優(yōu)化,在自助抽樣過(guò)程中添加了隨機(jī)欠采樣環(huán)節(jié)。隨機(jī)欠采樣可以在隨機(jī)的條件下設(shè)定各類(lèi)別樣本的抽取數(shù)量,在自助抽樣時(shí)既可以做到充分利用少數(shù)類(lèi)樣本,又能對(duì)樣本數(shù)量較多的類(lèi)別進(jìn)行欠采樣處理,使每棵決策樹(shù)中不同類(lèi)別樣本的數(shù)量趨向均衡。
BRF算法的流程如下:首先,將原始數(shù)據(jù)集按照比例劃分為訓(xùn)練集與測(cè)試集,測(cè)試集不做任何處理,對(duì)任意一決策樹(shù)ti,都會(huì)使用隨機(jī)欠采樣方法從訓(xùn)練集中隨機(jī)抽取(有放回抽取)與各少數(shù)類(lèi)樣本數(shù)量相近或相等的多數(shù)類(lèi)樣本,隨后將抽取出的各多數(shù)類(lèi)樣本與少數(shù)類(lèi)樣本混合組成均衡數(shù)據(jù)集;在節(jié)點(diǎn)分裂時(shí)隨機(jī)選取一個(gè)屬性作為分裂變量,之后流程與RF算法相同,每棵決策樹(shù)會(huì)對(duì)各自的均衡數(shù)據(jù)集進(jìn)行分類(lèi)并得出一個(gè)結(jié)果;當(dāng)算法中的每棵樹(shù)都產(chǎn)生結(jié)果之后,再根據(jù)bagging原則投票選出最理想的一個(gè)作為最終結(jié)果并生成模型,最后將測(cè)試集數(shù)據(jù)導(dǎo)入生成的模型中即可得出結(jié)果,BRF算法的流程圖如圖2所示。
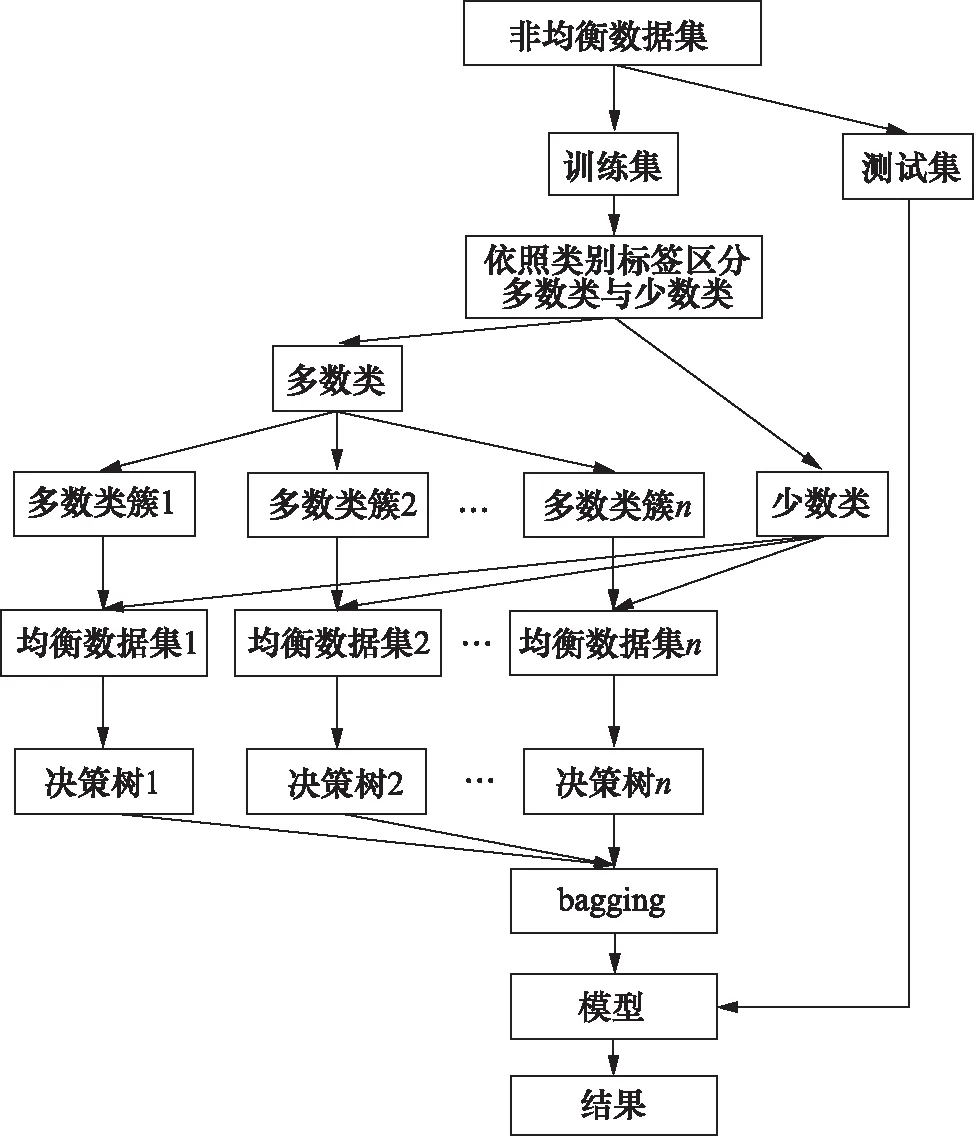
圖2 BRF算法流程圖Fig.2 Flow chart of BRF algorithm
2 BRF算法的性能研究
2.1 BRF算法參數(shù)選擇
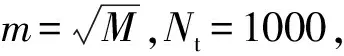
2.2 BRF算法性能評(píng)價(jià)指標(biāo)
一般情況下,在分類(lèi)結(jié)束后會(huì)出現(xiàn)如表1所示4種情況。通過(guò)混淆矩陣可以計(jì)算出一些評(píng)價(jià)指標(biāo),例如精確率、召回率、準(zhǔn)確率等。對(duì)于非均衡數(shù)據(jù),分類(lèi)器在分類(lèi)時(shí)大概率會(huì)將少數(shù)類(lèi)劃分為多數(shù)類(lèi),使用準(zhǔn)確率作為評(píng)價(jià)標(biāo)準(zhǔn)不適用于非均衡數(shù)據(jù)分類(lèi)。因此,引入G-mean,F(xiàn)-measure與精確率P共同作為評(píng)判指標(biāo)。

表1 混淆矩陣Tab.1 Confusion matrix
G-mean結(jié)合了特異度和召回率,表示只有當(dāng)分類(lèi)器對(duì)樣本中少數(shù)類(lèi)和多數(shù)類(lèi)的分類(lèi)效果都很好的情況下,G-mean的值最大;F-measure 同時(shí)結(jié)合了精確率和召回率,是兩者的加權(quán)調(diào)和平均,用于評(píng)價(jià)分類(lèi)器對(duì)某一類(lèi)樣本分類(lèi)性能的優(yōu)劣,因此可用于測(cè)量分類(lèi)器在少數(shù)類(lèi)樣本上的分類(lèi)性能[24]。
G-mean與F-measure的計(jì)算公式如下:
(6)
(7)
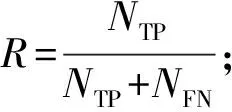
若是多分類(lèi)問(wèn)題,在計(jì)算時(shí)將所要計(jì)算的類(lèi)別視為正類(lèi),其余類(lèi)別視為負(fù)類(lèi),計(jì)算每個(gè)少數(shù)類(lèi)的G-mean,F(xiàn)-measure與精確率,然后分別取平均值作為整個(gè)少數(shù)類(lèi)的結(jié)果。
設(shè)非均衡數(shù)據(jù)集中有n類(lèi)樣本,其中類(lèi)別1為多數(shù)類(lèi),其余類(lèi)別為少數(shù)類(lèi)。則少數(shù)類(lèi)整體的G-mean,F(xiàn)-measure與少數(shù)類(lèi)平均精確率計(jì)算方式如下:
(8)
(9)
(10)
式中,G2到Gn分別為類(lèi)別2到類(lèi)別n的G-mean值,Ga為少數(shù)類(lèi)整體的G-mean值;F2到Fn分別為類(lèi)別2到類(lèi)別n的F-measure值,F(xiàn)a為少數(shù)類(lèi)整體的F-measure值;P2到Pn分別為類(lèi)別2到類(lèi)別n的精確率,Pa為少數(shù)類(lèi)平均精確率。
2.3 BRF算法性能分析
為證明BRF算法的優(yōu)勢(shì)與泛化能力,先使用公開(kāi)數(shù)據(jù)集對(duì)其進(jìn)行驗(yàn)證。驗(yàn)證所選數(shù)據(jù)集為UCI開(kāi)源數(shù)據(jù)集,4組數(shù)據(jù)集均為多分類(lèi)非均衡數(shù)據(jù),具體信息如表2所示。
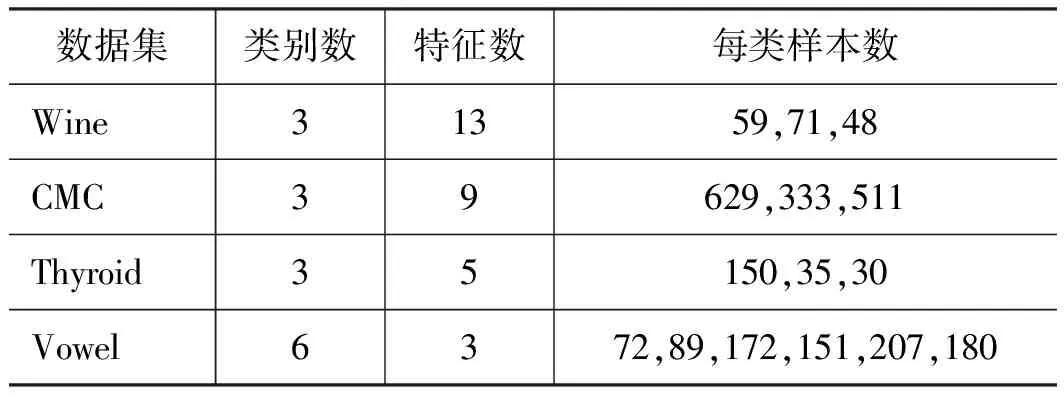
表2 所用數(shù)據(jù)集信息Tab.2 Datasets information used
數(shù)據(jù)集中樣本數(shù)量最多的類(lèi)別為多數(shù)類(lèi),其余類(lèi)別為少數(shù)類(lèi)。為保證結(jié)果準(zhǔn)確,每個(gè)數(shù)據(jù)集都進(jìn)行了10次計(jì)算,每次計(jì)算都會(huì)改變隨機(jī)數(shù)種子以保證每次訓(xùn)練集與測(cè)試集都不相同,取10次結(jié)果的均值作為最終結(jié)果,分類(lèi)結(jié)果如表3所示。
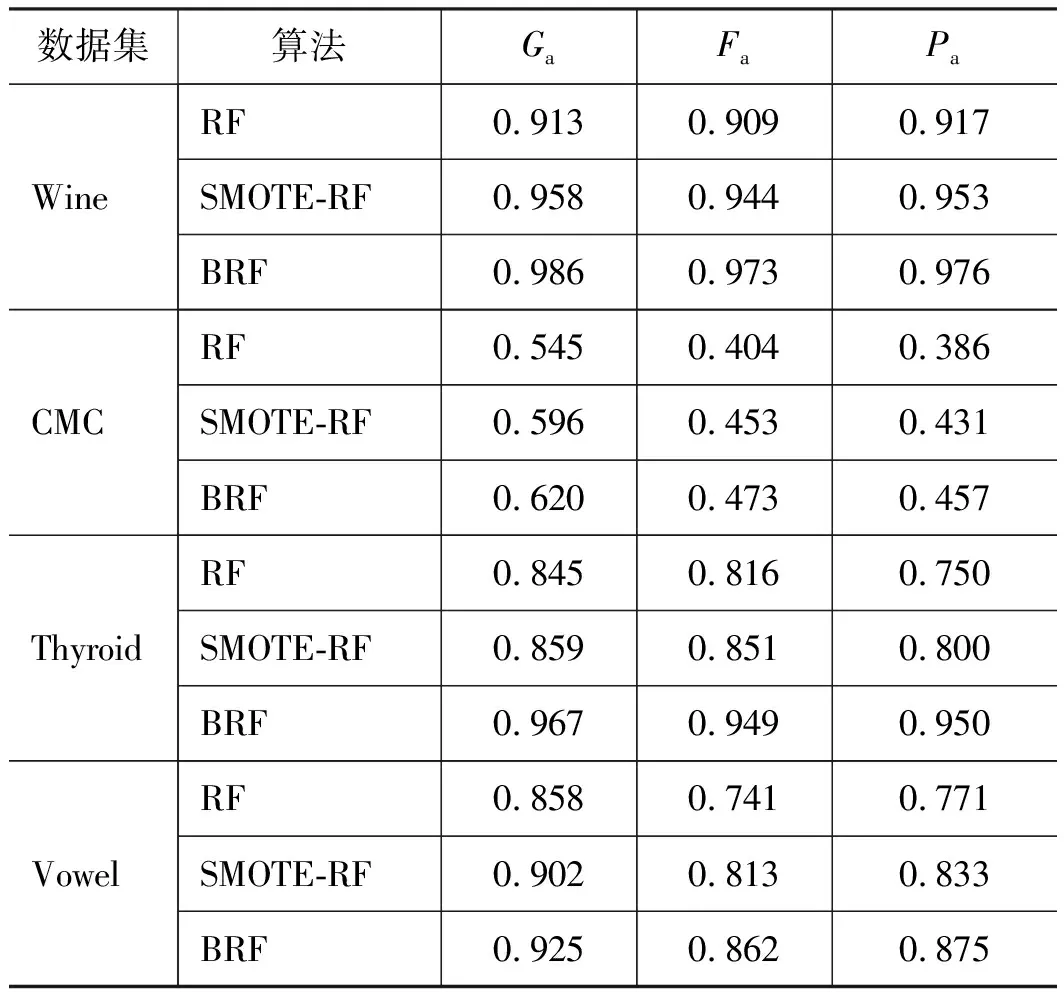
表3 各數(shù)據(jù)集分類(lèi)結(jié)果Tab.3 Classification results of each dataset
由表3可知,在4種數(shù)據(jù)集中,BRF算法的Ga,Fa,Pa均高于RF算法和SMOTE-RF算法。
其中,Thyroid數(shù)據(jù)集不均衡程度最高,BRF算法的Pa,Ga,Fa相較于RF算法分別提升了20%,0.122,0.133;相較于SMOTE-RF算法分別提升了15%,0.108,0.098。
其次為Vowel數(shù)據(jù)集,BRF算法的Pa,Ga,Fa相較于RF算法分別提升了10.4%,0.067,0.121;相較于SMOTE-RF算法分別提升了4.2%,0.023,0.049。
在CMC數(shù)據(jù)集上,BRF算法的Pa,Ga,Fa,相較于RF算法分別提升了7.1%,0.075,0.069;相較于SMOTE-RF算法分別提升了2.6%,0.024,0.020。
Wine數(shù)據(jù)集不均衡程度最低,BRF算法的Pa,Ga,Fa相較于RF算法提升了5.9%,0.073,0.064;相較于SMOTE-RF算法分別提升了2.3%,0.028,0.029。
通過(guò)上述分析可得,數(shù)據(jù)集的不均衡程度越高,BRF算法對(duì)少數(shù)類(lèi)的分類(lèi)精確率提升越大。
3 基于BRF算法的軸向柱塞泵故障診斷
3.1 故障注入及故障數(shù)據(jù)采集
本研究采用硬件設(shè)備與軟件程序相結(jié)合的方法采集實(shí)驗(yàn)數(shù)據(jù)。軟件采用LabVIEW2018,以此來(lái)監(jiān)控柱塞泵的工作狀態(tài),同時(shí)進(jìn)行數(shù)據(jù)采集。實(shí)驗(yàn)系統(tǒng)原理如圖3所示,柱塞泵振動(dòng)信號(hào)采自液壓泵故障模擬實(shí)驗(yàn)臺(tái),實(shí)驗(yàn)臺(tái)照片如圖4所示。

圖3 實(shí)驗(yàn)系統(tǒng)原理圖Fig.3 Schematic diagram of experimental system

圖4 實(shí)驗(yàn)臺(tái)照片F(xiàn)ig.4 Experimental bench photo
液壓泵為MCY14-1B型斜盤(pán)式軸向柱塞泵,柱塞數(shù)目為7,理論排量10 mL/r,額定工作壓力31.5 MPa;電機(jī)型號(hào)為Y132M-4,額定轉(zhuǎn)速為1480 r/min;加速度傳感型號(hào)為YD72D,頻率范圍1~18 kHz。對(duì)液壓泵端蓋的振動(dòng)信號(hào)進(jìn)行采集,試驗(yàn)時(shí)調(diào)定主溢流閥將系統(tǒng)壓力設(shè)置為5 MPa,采樣頻率設(shè)為10 kHz,每次采樣時(shí)長(zhǎng)為10 s。
試驗(yàn)共模擬4類(lèi)故障,分別為滑靴磨損、松靴、斜盤(pán)磨損、中心彈簧磨損。故障是使用故障元件代替正常元件注入的,故障元件是從液壓泵維修單位收集的磨損廢棄元件。數(shù)據(jù)采集結(jié)束后對(duì)原始振動(dòng)信號(hào)進(jìn)行小波包能量特征提取,小波包函數(shù)選用db5小波,分解層數(shù)為4,由16個(gè)子頻帶能量占比作為特征組成特征向量。各子頻帶B的頻率范圍如表4所示,故障元件照片與各類(lèi)別子帶能量譜分別如圖5、圖6所示。

表4 子頻帶及頻率范圍Tab.4 Sub-band and frequency range Hz

圖5 故障元件照片F(xiàn)ig.5 Faulty component photos
圖6中能量占比與子頻帶分別用PE與B表示,且二者均無(wú)量綱。由圖6可知,5種狀態(tài)下各子頻帶的能量占比區(qū)分度大,差異明顯,使用小波包能量特征提取方法能夠清晰有效地將5種狀態(tài)進(jìn)行區(qū)分。
選取不同狀態(tài)的柱塞泵端蓋的振動(dòng)信號(hào),經(jīng)小波包能量特征提取后制作成數(shù)據(jù)集。數(shù)據(jù)類(lèi)別包括正常、滑靴磨損、松靴、斜盤(pán)磨損、中心彈簧磨損。所得到的軸向柱塞泵故障數(shù)據(jù)集如表5所示,正常類(lèi)/單個(gè)故障類(lèi)比例為20∶1。
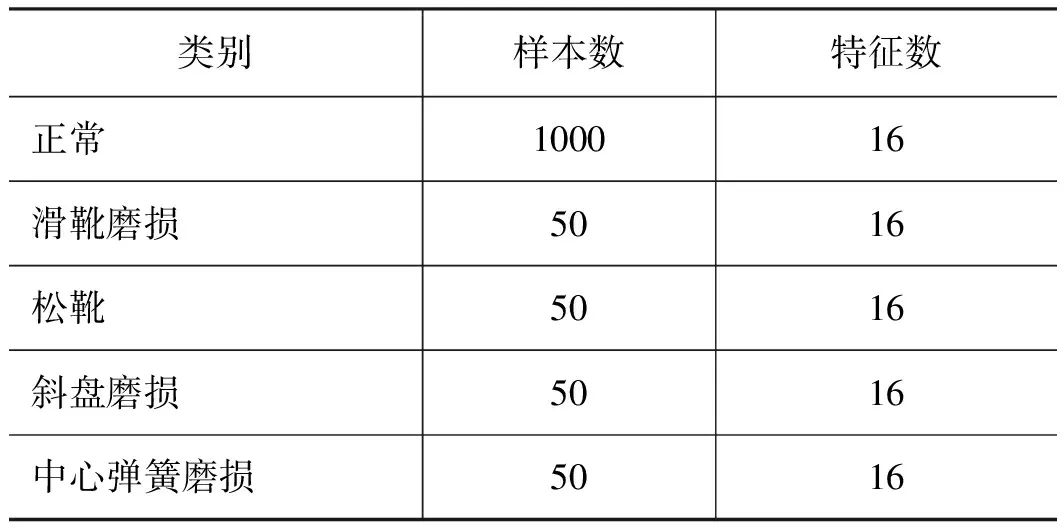
表5 軸向柱塞泵故障數(shù)據(jù)集Tab.5 Axial piston pump failure dataset

圖6 各狀態(tài)類(lèi)別下的子帶能量譜Fig.6 Sub-band energy spectrum of each state category
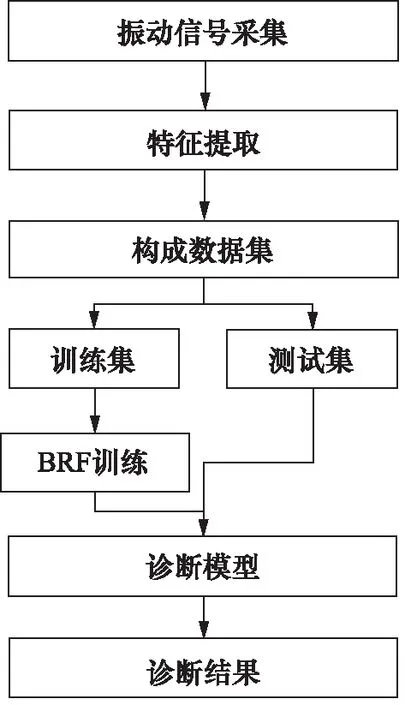
圖7 基于BRF的軸向柱塞泵故障診斷流程圖Fig.7 Fault diagnosis flowchart of axial piston pump based on BRF
完整的基于BRF的軸向柱塞泵故障診斷流程圖如圖7所示。
3.2 基于BRF的軸向柱塞泵故障診斷及結(jié)果分析
劃分軸向柱塞泵數(shù)據(jù)集時(shí),設(shè)置訓(xùn)練集與測(cè)試集比例為7∶3,設(shè)置軸向柱塞泵數(shù)據(jù)集中屬性總數(shù)M為16,RF算法與SMOTE-RF算法中的參數(shù)m為4,Nt為1000;BRF算法中Nt為1000。
數(shù)據(jù)集中正常樣本為多數(shù)類(lèi)樣本,滑靴磨損、松靴、斜盤(pán)磨損、中心彈簧磨損的樣本為少數(shù)類(lèi)樣本。為使結(jié)果準(zhǔn)確,進(jìn)行10次計(jì)算并對(duì)結(jié)果進(jìn)行平均。每次計(jì)算時(shí)都設(shè)置不同的隨機(jī)數(shù)種子,以確保每次的訓(xùn)練集與測(cè)試集都不相同,取均值作為最終結(jié)果,診斷結(jié)果如表6所示,表中7項(xiàng)評(píng)價(jià)指標(biāo)均無(wú)量綱。
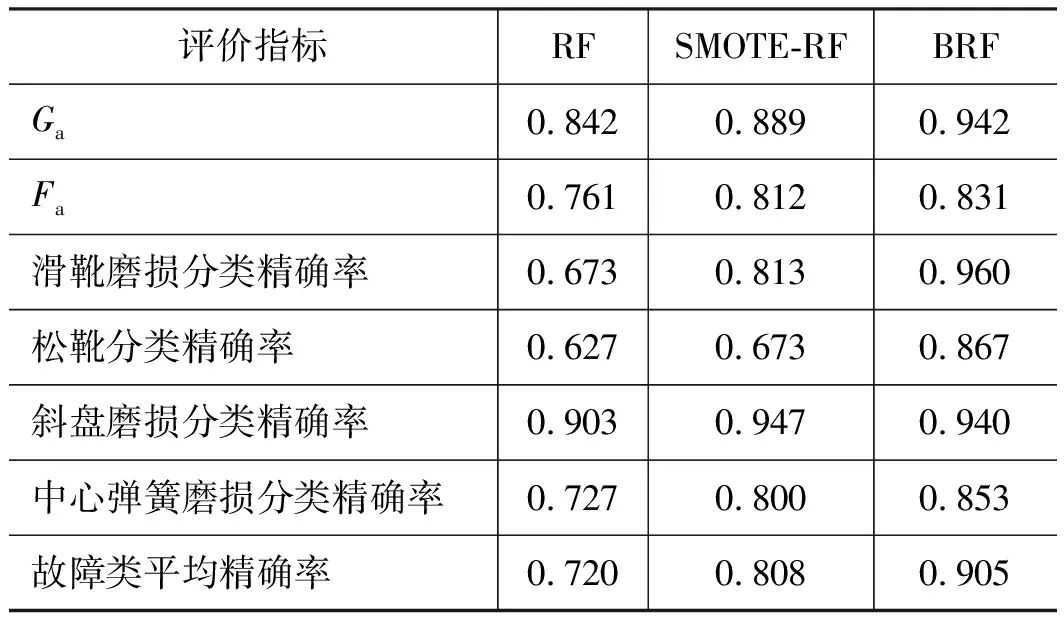
表6 軸向柱塞泵故障數(shù)據(jù)集的診斷結(jié)果Tab.6 Diagnosis results of axial piston pump fault dataset
由表6可知,BRF算法的滑靴磨損、松靴、中心彈簧磨損的分類(lèi)精確率相較于RF算法、SOMTE-RF算法有著較大的提升,BRF算法對(duì)斜盤(pán)磨損的分類(lèi)精確率雖不是最高,但也達(dá)到了0.94,僅比SMOTE-RF算法低0.7%,說(shuō)明BRF算法的整體性能優(yōu)于RF和SMOTE-RF算法。
在非均衡問(wèn)題中,不均衡程度沒(méi)有明確的度量標(biāo)準(zhǔn)。通常當(dāng)數(shù)據(jù)集中不同類(lèi)別樣本的比例超過(guò)5∶1時(shí)[8],數(shù)據(jù)不均衡所帶來(lái)的問(wèn)題就會(huì)凸顯出來(lái)。
為進(jìn)一步分析BRF的性能,將正常類(lèi)/單個(gè)故障類(lèi)比例分別調(diào)整至15∶1,10∶1,5∶1,隨后再次使用3種算法進(jìn)行計(jì)算。3種算法在不同不均衡比例下的Ga,Fa,Pa如圖8所示,圖中結(jié)果皆為10次計(jì)算結(jié)果的均值。
圖8為3種算法在不同不均衡比例下的性能,其中橫坐標(biāo)pns為正常類(lèi)/單個(gè)故障類(lèi)的比例。
由圖8可得,在4種不均衡比例下BRF算法的性能均優(yōu)于RF算法和SMOTE-RF算法。BRF的Ga,Fa,Pa始終高于其他2種算法,在比例為20∶1時(shí)提升最大,相比于RF算法分別提升了0.10,0.07,18.5%,相比于SMOTE-RF算法分別提升了0.053,0.019,9.7%。
4 結(jié)論
將BRF算法引入軸向柱塞泵故障診斷領(lǐng)域,提出了在類(lèi)間數(shù)據(jù)不均衡條件下基于BRF的軸向柱塞泵故障診斷方法:
(1) 利用開(kāi)源UCI數(shù)據(jù)對(duì)BRF,RF,SMOTE-RF 3種算法的性能進(jìn)行了比較,結(jié)果表明BRF算法的Ga,F(xiàn)a,Pa均高于其他2種算法,且在非均衡程度最高的數(shù)據(jù)集上性能提升最大;
(2) 對(duì)軸向柱塞泵不同類(lèi)型故障進(jìn)行模擬,采集了正常、滑靴磨損、松靴、斜盤(pán)磨損、中心彈簧磨損5種狀態(tài)的數(shù)據(jù),使用上述3種算法在不同的不均衡比例下進(jìn)行對(duì)比分析,結(jié)果表明,BRF算法性能始終優(yōu)于RF算法與SMOTE-RF算法,并且在數(shù)據(jù)不均衡比例最高時(shí)BRF的性能提升最大,滿足實(shí)際需要;
(3) 對(duì)于類(lèi)間數(shù)據(jù)不均衡的軸向柱塞泵故障診斷問(wèn)題,BRF能夠在符合實(shí)際(即數(shù)據(jù)處于高度不均衡狀態(tài))的前提下有效提升故障類(lèi)的分類(lèi)性能,該方法在處理類(lèi)間數(shù)據(jù)不均衡的軸向柱塞泵故障分類(lèi)問(wèn)題方面相較于傳統(tǒng)分類(lèi)算法具有明顯優(yōu)勢(shì)。

圖8 3種算法在不同不均衡比例下的Ga,Fa,PaFig.8 Ga, Fa, Pa for three algorithms under different imbalance ratios
猜你喜歡
西北民族大學(xué)學(xué)報(bào)(自然科學(xué)版)(2021年4期)2021-12-29 02:54:24
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫(huà)刊(2020年4期)2020-06-08 15:48:10
學(xué)生天地(2019年32期)2019-08-25 08:55:22
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
