基于YOLOv4改進算法的人群異常行為檢測研究
2022-06-16 03:29:22施新凱張雅麗李御瑾趙佳鑫
現代計算機 2022年7期
施新凱,張雅麗,李御瑾,趙佳鑫
(中國人民公安大學信息網絡安全學院,北京 100038)
0 引言
隨著經濟文化的快速發展,人們的社會活動也與日俱增,交通出行站點、大型活動現場以及大型商場等公共場所會出現人群聚集的情況,人群聚集往往可能出現矛盾糾紛事件,主要包括打架斗毆、非法縱火、打砸公物等。利用智能視頻異常檢測技術能夠對人群異常行為進行檢測并預警,可以減少群體性非法事件的惡化,保障群眾的生命財產安全。
Afiq 等將異常檢測分為基于高斯混合模型、隱馬爾可夫模型、光流法和時空技術等傳統方法。傳統的異常行為檢測方法在區域選擇及特征提取方面需要人工參與較多,客觀性不足且多數異常場景較為單一,滿足不了當今人群異常事件檢測的精度和速度要求。基于深度學習的人群異常事件檢測更有利于特征提取和場景遷移。彭月平等利用三維卷積神經網絡(C3D)提取HOG 時空特征,提高了對人群行為的表征能力。胡學敏等將視頻幀劃分為大小相同且互不重疊的子區域以實現異常人群定位,然后將子區域輸入改進的C3D 模型提取行為特征并輸出正異常分類概率。羅凡波等將視頻分割成多個子區域,并基于YOLOv3算法檢測異常行為的誘因,然后利用光流法獲取人群的平均動能判斷人群是否出現異常。熊饒饒等提出一種新的綜合光流直方圖特征描述人群行為,采用SVM 作為分類器,并利用網格遍歷搜索法結合交叉驗證法獲取最佳參數對分類器訓練。李萌等提出一種相互作用力直方圖(HOIF)用來描述運動信息特征,將其與顯著性信息特征相融合送入支持向量機(SVM)進行學習訓練,從而對人群事件進行分類。張娓娓等提出一種改進的C3DRF 檢測方案,在保證對異常行為分類精度的同時,顯著提升了訓練效率。
但當前人群異常事件檢測研究存在不足,主要因為異常行為在不同場景下定義不同,難以泛化;異常事件發生概率低導致正負樣本不均衡,難以學習足夠的異常行為特征;異常檢測實時性差,無法滿足當前視頻目標追蹤的需求。隨著深度學習在目標檢測領域的快速應用,用目標檢測的方式檢測人群中的異常目標,檢測準確率以及實時性可滿足對監控視頻數據處理的要求。其中,YOLOv4算法在目標檢測領域已經較為成熟,其檢測準確率及檢測速率均優 于SSD、YOLOv3、Faster-RCNN。目前,有關YOLOv4改進算法的研究中,主要改進思路是提高網絡的特征提取能力,從而提升模型的MAP 值。陳夢濤等通過在原主干網路中嵌入新型注意力機制CA 模塊,提升了網絡對小目標的特征提取能力。康帥等提出了在YOLOv4 主干網中加入混合空洞卷積,提高了網絡對行人特征的提取能力。
本文針對YOLOv4算法的主要改進方法是在主干網絡區域增加兩層卷積模塊,為深層的網絡傳遞更多的位置信息,且采用移動指數平均值(EMA)更新網絡參數來優化訓練模型;然后用Mixup 代替YOLOv4 中的Mosica 數據增強的方法,以便增大訓練的數據集;最后改進YOLOv4的特征融合結構(PAN),從而在特征融合時傳遞更多的語義信息。
1 YOLOv4改進算法
1.1 改進Mixup替代Moscia函數
YOLOv4算法使用的是Moscia 數據增強的方法,在理論上與CutMix 有一定的相似性,Cut-Mix 是將兩張圖片進行拼接,Moscia 是每次讀取四張圖片進行縮放、翻轉、合并成一張圖片對其檢測,如圖1所示。

圖1 YOLOv4采用的Moscia數據增強方法
為增大訓練的數據集、提升算法的魯棒性,本文采用Mixup 替代Moscia 數據增強函數。但Mixup 函數采用的是Beta 分布函數,Beta 分布函數原理是直接對圖像進行疊加,對圖像語義特征進行融合,而這樣圖像并不能展現原圖像中豐富的語義信息。因此本文在其基礎上對Mixup函數圖像融合的方式進行了一定的修改,采用0.2~0.8的均勻分布來選取圖像融合的系數,可以讓原來的圖像特征表達得更加豐富,效果如圖2所示。

圖2 Mixup改進版圖像增強效果
1.2 主干特征提取網絡改進
本文借鑒Resnet 殘差網絡的思想,加深網絡長度為深層網絡傳遞更多的位置信息。但如果在淺層的網絡結構中增加更多的卷積結構會導致整體網絡難以訓練,且沒有明顯的效果提升;如果在深層網絡添加卷積結構會導致整體網絡參數增長比較大,進而引起模型檢測速度的大幅度降低。于是在Darknet53 的基礎上,在如圖3 所示的主干網絡區域增加兩層卷積模塊,主干特征提取網絡的參數量增長較少,檢測速度幾乎沒有下降。

圖3 主干特征提取網絡上增加兩個卷積模塊
1.3 EMA更新網絡參數
為提高模型的測試指標并增加其魯棒性,本文提出使用指數移動平均值(EMA)更新網絡參數。EMA 是用來估計變量的局部均值,從而使得時刻變量的數值不只是取決當前時刻的數據,而是對時刻附近進行加權平均,使得更新得到的數值變得更加平滑,不會受到某次異常數據的影響,提升模型的魯棒性。原EMA 算法如公式(1)所示。
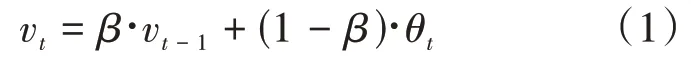
式中v表示第次更新的所有參數移動平均數,表示權重參數,θ表示在第次更新得到的所有權重參數。YOLOv4沒有采用動態的系數來更新網絡的權重,在此基礎上對引入的EMA 算法做出相應的改進,本文的改進點主要是對模型每個epoch 訓練得到的參數進行指數平均加權計算。算法如公式(2)所示。

式中等號右邊的N是第次模型訓練得到的結果,左邊的N是加權計算得到的結果,N- 1是第-1 次模型加權計算得到結果,是一個占比參數。由于訓練后期模型準確率逐漸提升,得到的模型參數準確性較高,因此訓練后期N- 1需降低占比參數值,訓練初始階段需調高占比參數值。本實驗主要將模型訓練分為四個階段,第一階段設置為0.9950,第二階段設置為0.9970,第三階段設置為0.9990,第四段設置為0.9998,實驗結果表明測試指標和魯棒性高于原模型。
1.4 改進PAN結構
YOLOv4算法采用的是在FPN 的結構上改進的PAN 結構,FPN 結構是指自頂向下將特征提取網絡結構中的高層特征與低層特征進行融合得到的特征圖,PAN 結構是指自底向上將低層特征與高層特征融合得到的特征圖。使用FPN+PAN 的特征融合方式相比較YOLOv3 中的FPN有著更高的語義信息,結構如圖4所示。

圖4 YOLOv4采用的PAN結構
為使模型融合特征效果得到進一步的提升,借鑒FSSD采用一種新的結構,采用的方式是將特征提取網絡中高層特征進行上采樣再將這些特征進行結合,再次使用FPN+PAN 的結構對這些特征進行特征融合,可以在特征融合時傳遞更多的位置信息和語義信息。改進后的PAN結構如圖5所示。

圖5 改進版的PAN結構
2 實驗及結果分析
2.1 實驗環境及數據集
本實驗是在Ubuntu 18.0 操作系統的服務器上進行編程實驗。GPU 使用的是英偉達2060,使用CUDNN 進行GPU 加速。采用的數據集是從互聯網上搜集的持刀、縱火、煙霧圖片數據集。
2.2 YOLOv4算法改進實驗
通過將搜集的持刀、縱火、煙霧的圖片數據進行過濾,獲得火焰數據集樣本圖片357張圖片,持刀的數據集樣本圖片398張,煙霧的數據集樣本圖片1865 張,將數據集通過labellmg 對圖片進行標注,在訓練模型的過程中,其中的參數設置如表1所示。

表1 YOLOv4改進算法模型訓練參數
將改進版YOLOv4 算法與YOLOv4 算法訓練的模型進行目標檢測,其對比效果如圖6所示。

圖6 檢測效果對比實驗
其中fire、smoke、knife 三種類別的圖像檢測準確率均有提升,在圖(a)中原版YOLOv4 算法檢測knife類別時產生誤檢,而在圖(b)中改進后的YOLOv4 算法能對knife 類別正確檢測。實驗結果表明改進后算法檢測結果的置信度高于原版YOLOv4算法,改進后的算法魯棒性更高。
2.3 實驗結果分析
本實驗主要從三個評價指標來評價該訓練模型,分別是: 平均精度均值(mean average precision,MAP)、召回率(recall)、每秒檢測圖片的幀數(frames per second,FPS),其中需引入準確率(precision)。算法如公式(3)、(4)所示:
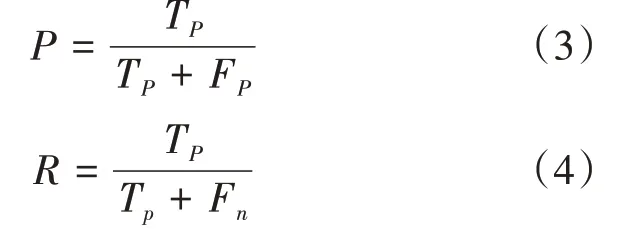
T表示預測到的正樣本的正確數量,F表示預測到的正樣本的不正確數量,F表示預測到的負樣本的不正確數量。曲線圍成的面積就是某一個類別的值,其中值是對所有類別的值進行求平均得到的。值越大,則表示該模型識別目標的精度越高。結果如圖7、圖8所示。

圖7 原YOLOv4算法的MAP值

圖8 改進版YOLOv4算法的MAP值
為進一步驗證本文改進的YOLOv4算法的魯棒性,將原YOLOv4 算法、EMA 改進網絡參數(YOLOv4_ema)算法、本文改進算法三個算法在此數據集上進行驗證實驗。測試平均精度均值()、每秒檢測圖片的幀數(FPS)值,如表2所示。
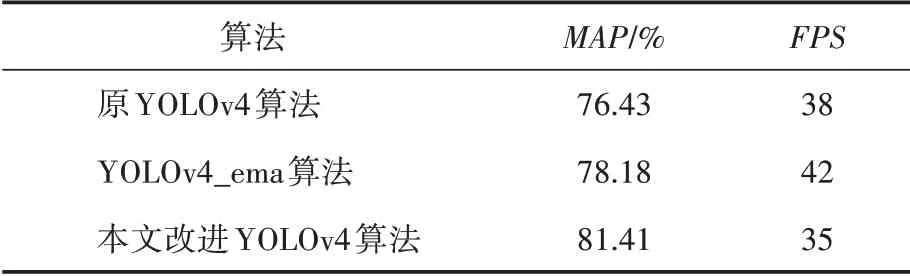
表2 YOLOv4改進算法對比結果
對比實驗數據可知,本文改進版YOLOv4算法有更高的檢測平均精度均值,值為81.41%,原 版YOLOv4 的值 為76.43%,YOLOv4_ema 的值為78.18%。實驗表明,改進版YOLOv4模型的檢測準確率更高,且魯棒性更強,同時在處理視頻的速度上,改進過的YOLOv4 算法FPS 略低于原版算法,但可以滿足對監控視頻進行實時檢測的需求。
3 結語
本文提出了基于YOLOv4改進算法的人群異常行為檢測方法,實驗結果顯示改進版的YOLOv4 算法在本數據集上訓練模型得到的較原版算法提升了近5%,其中fire、smoke、knife的檢測準確率較原版算法分別提升了4.64%、7.61%、2.68%;在處理視頻的速度上,改進版YOLOv4 算法的FPS 略低于原版算法,但可以滿足對監控視頻進行實時檢測的需求。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
