基于推薦算法的高血壓患者偏好方法研究*
2022-06-16 12:45:26趙貝寧熊巨洋趙仁偉
計算機與數字工程 2022年5期
趙貝寧 熊巨洋 趙仁偉 金 唐
(1.華中科技大學醫藥衛生管理學院 武漢 430030)(2.河南省澠池縣果園鄉中心學校 澠池 472400)
1 引言
隨著經濟的快速發展,人們的生活水平日異得到提高。由于各種不良的飲食習慣、作息習慣等原因導致高血壓疾病患者數量也呈現快速增長的趨勢。高血壓疾病的治療過程是繁瑣復雜的,同時不同類別的高血壓人群對于健康管理的偏好不盡相同,因此,有效找到各類高血壓患者的健康管理偏好對于治療高血壓疾病來說具有重要的意義。而推薦算法是解決信息與個性化需求之間的有效方法,在諸多的推薦算法中,協同過濾技術較為廣泛應用,但是傳統的協同過濾推薦算法具有實時性較差、拓展性較差的特點。針對推薦算法的缺點,部分專家學者提出了解決思路。如劉靖明,韓麗川等人結合K均值聚類方法,找到與用戶距離最近的集合實現推薦[1]。學者根據對用戶行為的分析,建立特征表,提出了聚類的標準[2~4]。李輝,石釗等建立“用戶-矩陣”改進聚類中的近鄰算法,從一定程度上找到解決推薦實時性問題的辦法[5]。周軍鋒、湯顯等根據用戶的評分結果,分段歸納用戶的分數,根據分數區分不同類別用戶進行推薦[6~8]。俞琰,邱廣華等通過對用戶興趣網的研究,提出網絡混合推薦算法,利用拓撲網絡結構分析用戶的興趣行為[9~13]。王均波將用戶興趣、時間效應、用戶對項目偏好程度以及用戶的特征有機的結合起來融入推薦算法中[7,14~15]。然而目前提出的推薦算法存在執行效率不高的問題,且推薦的準確度仍需要進一步考量。
對于高血壓疾病健康管理的用戶偏好度推薦,需要針對目前協同過濾算法存在的問題進行改進,在前期特征選擇階段進行興趣組合、興趣擴充等方法,在算法模型階段需要利用聚類思路,進行組合推薦,建立基于高血壓疾病患者的行為、特征和內容進行過濾與組合推薦,改進協同過濾推薦算法的實行性弱、擴展性差的特點,并提高推薦的準確度。
2 算法總體框架
傳統的協同過濾推薦算法是以用戶評分作為特征基礎,不同的分數代表不同用戶的喜好程度,以分數的特征代表用戶之間的特征。而組合建立推薦方法目的在于解決算法在運行過程中的數據稀疏性、準確度方面存在的問題,從而提高對高血壓患者健康管理偏好推薦的準確性。首先,對高血壓健康管理進行屬性分析,利用聚類的方法對項目評分值預測,建立“高血壓患者-健康管理”項目評分矩陣,為處理數據稀疏性做準備,保證推薦過程中的多樣性;其次將聚類的結果值作為特征分析依據,利用患者在在日常健康管理中的各種行為特征提取患者對健康管理的傾向度,提出高血壓患者對健康管理方式的偏好融合相似計算方法,改進傳統協同過濾方法中的局限相似性計算方法;最后,分析高血壓患者健康管理偏好傾向度的計算結果,對用戶進行聚類,實現健康管理方式的推薦,改進后的協同過濾推薦方法相對于傳統的方法在高血壓患者健康管理偏好推薦方面更具有實用性。算法總體框架結構如圖1所示。

圖1 算法總體框架
算法的執行過程中,健康管理項目聚類是先行開始的,其次高血壓患者進行聚類,利用近鄰相似度計算實現近鄰查找、預測和推薦,并將聚類的結果用于推薦中。其中除預測和推薦外的環節,均可提前進行處理,處理后實行推薦功能時僅需進行預測和推薦環節即可,后續對其余環節持續進行更新。這樣既可以節省算法的運行時間,也可以解決算法在應用過程中實時性差的問題。
2.1 基于內容的聚類算法描述
對象應具有的特征和采取的相似度計算方法關乎聚類效果的好壞,將高血壓患者的群體意見和健康管理的基本屬性相結合用于聚類計算,并通過組合擴大特征,實現提高算法計算精確度的目的,達到聚類準確性高的效果。方法從高血壓患者的行為特征和內容中提取健康管理的偏好標識,將標識與健康管理項目特征相結合,計算健康管理項目中的相似性,實現項目聚類。同時利用聚類結果判斷相似近鄰的健康管理子項目,根據鄰居集合確定所評的分值集合,將“高血壓患者-健康管理”項目評分矩陣進行填充,使得數據的稀疏性問題得到解決。因此,可以引入K-Means聚類方法實現項目聚類,主要步驟如下:
Step1:設定健康管理方式的項目集為I,I 中的子集分別為i1,i2,…,in,從I中任意選出S個子項目,并設S為聚類中心個數,可以看做C1,C2,…,Cn。
Step2:將項目和聚類中心的相似性記為sim(ii,Cj),以相似性為分界,將各個子項目劃分到相似度較高的聚類簇中,直至沒有可劃分的為止。
Step3:計算項目的平均值,并重新確定聚類中心。
Step4:將Step2 和Step3 持續重復,直至聚類中心C1,C2,…,CS與原循環中的聚類中心保持吻合度一致。
2.2 基于行為的聚類算法描述
在基于內容的聚類算法結果基礎上,將不同的高血壓患者對各種健康管理方式的評分特征設為滿意度,高血壓患者的各種行為記為關注度,對其進行相似度融合計算實現對高血壓患者的聚類,基于行為的聚類也采用K-Means聚類方法。
Step1:設定患者數為n,m 為用戶聚類數,患者集為U,從U 中選取m 個用戶,可以看做C1,C2,…,Cn。
Step2:將患者和聚類中心的相似性記為sim(Ui,Cj),以相似性為分界,將各個患者劃分到相似度較高的聚類簇中,直至沒有可劃分的為止。
Step3:計算平均值,并重新確定聚類中心。
Step4:將Step2 和Step3 持續重復,直至聚類中心C1,C2,…,Cm與原循環中的聚類中心保持吻合度一致。
2.3 協同過濾組合推薦
組合推薦方法的整體思路是:利用基于內容的聚類方法分析患者對各種健康管理方式的分值,將其填充到“高血壓患者-健康管理”項目評分矩陣,結合患者行為特征,實現內容與行為特征融合的聚類,利用患者對健康管理方式相似度偏好的計算方法,實現預測,根據預測結果進行推薦。組合推薦算法可分為挖掘高血壓患者傾向度、近鄰搜索、排序推薦三部分。
1)高血壓患者傾向度。傾向度的分析建立在行為集獲取的基礎上,對行為進行評分就是獲取患者喜愛程度的過程,將喜愛程度數字化,挖掘高血壓患者對健康管理方式的潛在興趣。
2)近鄰搜索。可看做是目標相似度較一致的患者聚類的過程,通過對患者間的相似度計算,將相同健康管理喜好的患者聚類,找到相似的鄰居。
3)排序推薦。利用最近的鄰居集合,采用預測計算公式計算患者間的相似性,將具有同類喜好的患者健康管理方式進行推薦,使患者獲得自己滿意的健康管理方式,產生推薦集。
算法具體步驟如下:
Step1:設定m 表示患者,n 表示健康管理方式,評分矩陣為Rm*n,矩陣中的每個元素表示患者對健康管理方式的評分。
Step2:設定相似度閾值為X,目標患者U,其它患者為V,m 為聚類數,則計算患者間的相似度sim(U,V)計算公式為
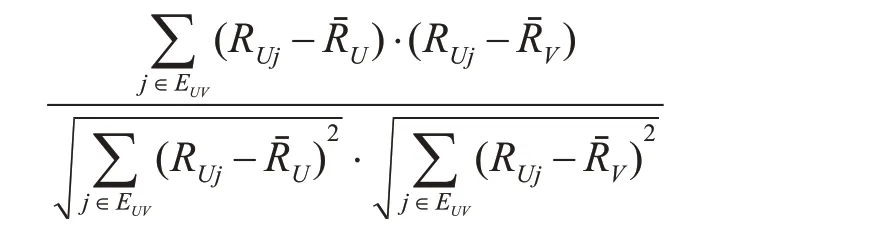
Step3:選取相似度大于閾值X 的患者集,取前m 個作為最近鄰居,獲得目標患者的最近鄰居集MN。
Step4:根據目標患者已有的評分信息,及最近鄰的評分數據,預測目標患者偏好的健康管理方式。預測公式如下:

其中,Rvk為患者V 對項目方式K 的評分,RˉU和RˉV分別是填充矩陣后的患者U,V的平均分值。因此,可以根據預測值進行推薦排序,推薦高血壓患者偏好度高的健康管理方式。
3 實驗結果及分析
實驗采用的數據集共包含6 萬條記錄,包括803個高血壓患者對1243個健康管理方式的評價,其中每個患者至少對20 個健康管理方式進行評分。為驗證算法的合理性以及可行性,與傳統的協同過濾推薦算法分別在實時性、數據稀疏性和準確性方面進行對比分析。
1)實時性
在實驗過程中,把聚類數和近鄰數的取值進行設定,在分析相關數據的基礎上,將患者聚類數均值取20 時分析算法在查詢最近鄰居效率的情況,實驗結果分別如表1和圖2所示。
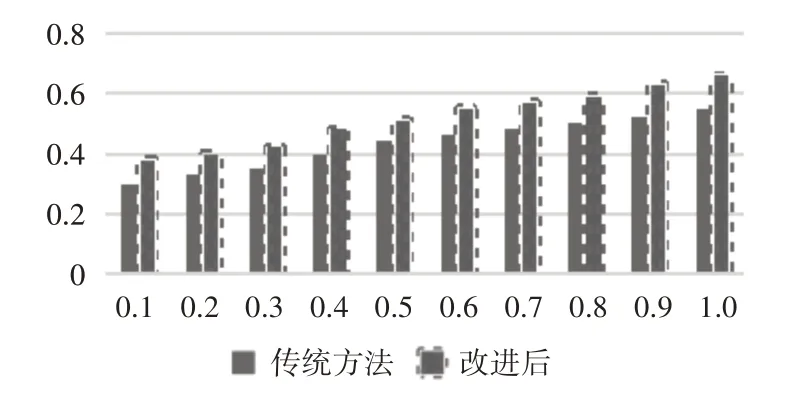
圖2 實時性對比分析圖
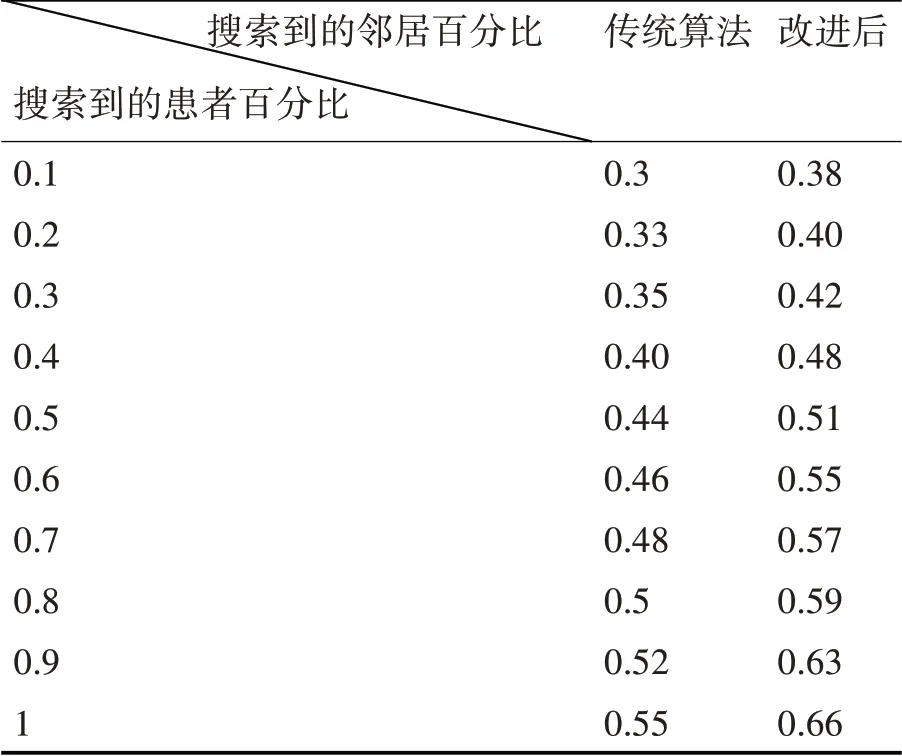
表1 實時性對比分析表
實驗結果可知,搜索的近鄰數與搜索患者百分比、制定患者近鄰數成正比增長的趨勢。因此,在聚類改進算法后,目標患者和近鄰患者劃分到最相似的患者簇中,利用較小的空間就可以找到較大的數量近鄰,使得效率得到明顯的提高。
2)數據稀疏性
數據稀疏性驗證主要是驗證實驗過程中填充評分矩陣方法,研究此方法對于數據稀疏性問題的效果,實驗對算法在原始均值填充和以聚類填充兩種方式作比較,以項目預測評分的MAE[0,1]均值作度量標準,實驗結果分別如表2和圖3所示。
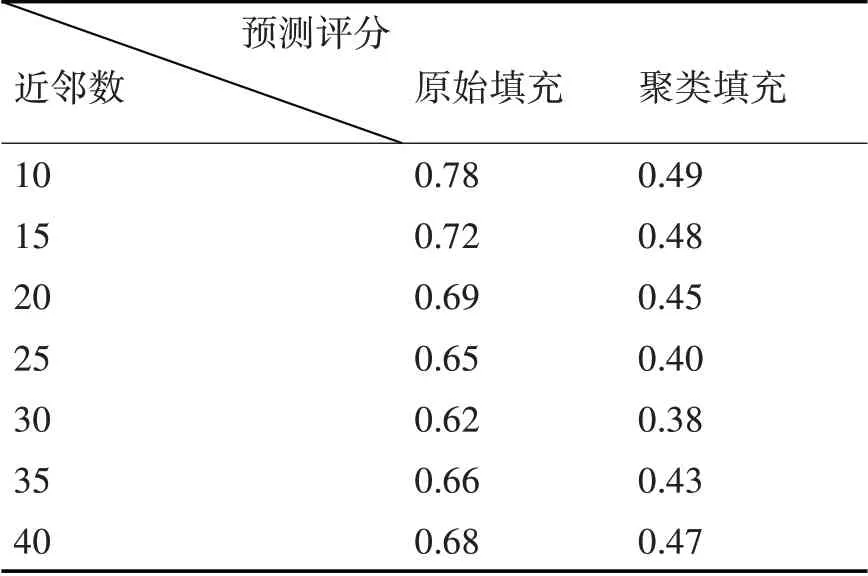
表2 數據稀疏性對比分析表
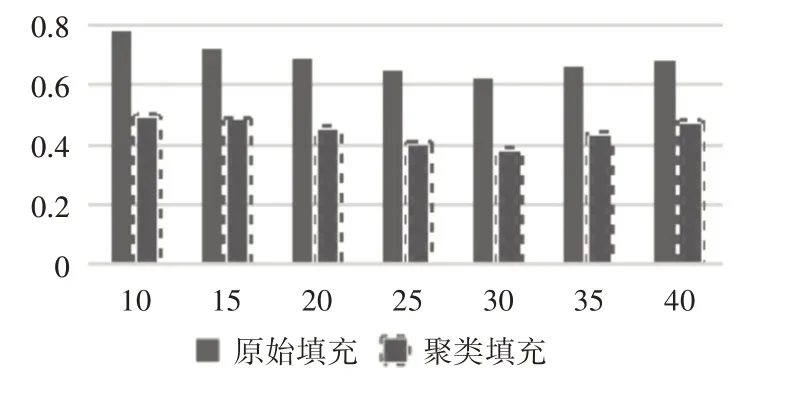
圖3 數據稀疏性對比分析圖
實驗結果可知,在評分矩陣中,聚類填充方法與原始均值填充方法的MAE 值更低,代表準確性更高。可以說明聚類填充評分矩陣的方法可以解決數據稀疏性的問題,提高推薦的精度。
3)準確性
在實驗過程中,為驗證改進后的推薦算法與傳統的協同過濾推薦算法相比的準確性,以預測評分MAE 作為度量標準,利用測試集進行多次實驗,可得到實驗結果如表3和圖4所示。
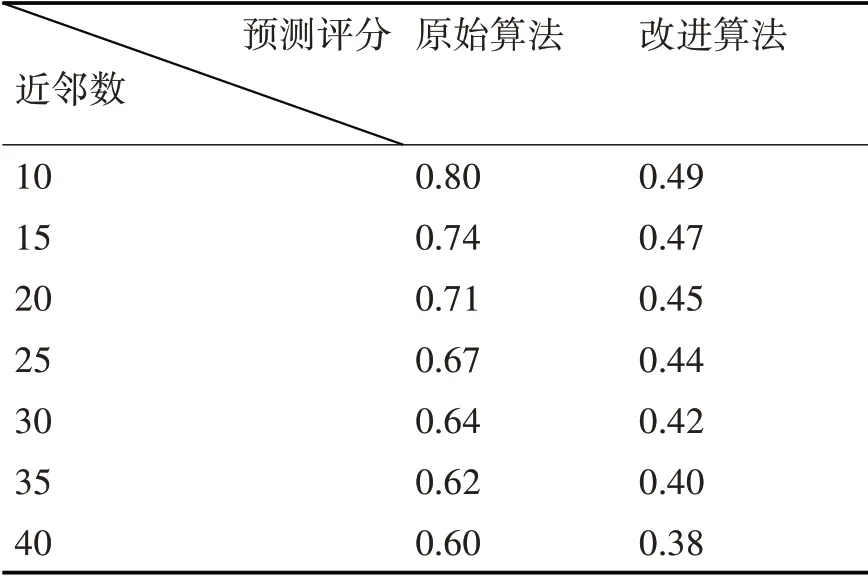
表3 算法準確性對比分析表
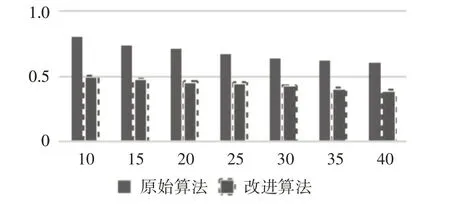
圖4 算法準確性對比分析圖
實驗結果可知,在鄰居數目由10~40 的逐步變化過程中,MAE 值在不斷降低,在實驗結果圖中可發現改進后的組合推薦算法MAE 值更低。因此,改進后的推薦算法較傳統的算法比具有較好的推進準確度。
4 結語
本文通過對高血壓健康管理方式的分析,研究了推薦算法的應用,并分析傳統協同過濾推薦算法的不足,對傳統協同過濾推薦算法存在的問題進行了研究,綜合健康管理方式和高血壓患者的行為特征,結合聚類思想方法對算法進行改進,得到了如下結論。
1)改進后的推薦算法較傳統協同過濾推薦算法相比,可以提高算法在應用過程中查詢高血壓患者最近鄰居的效率。
2)改進后的推薦算法較傳統協同過濾推薦算法相比,可以解決算法在應用過程中的數據稀疏性的問題,提高推薦的精度。
3)改進后的推薦算法較傳統算法協同過濾推薦相比,可以提高對高血壓患者選擇偏好度較高的健康管理方式的精度。
猜你喜歡
西部醫學(2021年10期)2021-10-28 08:25:50
基層中醫藥(2018年4期)2018-08-29 01:25:58
基層中醫藥(2018年6期)2018-08-29 01:20:14
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年5期)2015-02-27 07:53:25
