基于神經網絡的敏感文檔檢測*
2022-06-16 12:46:00沈麒寧
計算機與數字工程 2022年5期
沈麒寧
(江蘇科技大學 鎮江 212000)
1 引言
隨著近年來企業敏感信息外泄導致的安全事件頻發,數據防泄漏技術逐漸成為國內外業界研究的熱點,而電子文檔作為主流的信息載體之一,如何將敏感文檔準確識別出來,是實施防泄漏手段的前提。
目前主流的檢測技術包括三類:基于關鍵字匹配、基于機器學習和基于神經網絡。基于關鍵詞匹配的檢測方法的核心思想是:通過人工篩選出敏感信息的關鍵詞構成詞表,利用以AC 算法[1]、WM 算法[2]為代表的多模匹配算法將待測文本與詞表進行對比,根據事先設定的閾值來判斷文本內是否含有敏感信息。該方法依賴人工篩選關鍵詞構造的關鍵詞詞表,最終的識別結果很大程度上取決于詞典制定者的偏好;并且這種檢測方法是完全與語義無關的,通過一些簡單的詞語替換即可規避。基于機器學習的檢測方法將檢測過程視為文本的二分類過程,根據人工事先標注的統計學特征學習并進行分類。如文獻[3]提出了一種基于SVM 的敏感信息檢測方法;文獻[4]提出了一種基于敏感信息語義結構,通過上下文詞共現關系的電子文檔密級檢測方法。文獻[5]提出了一種基于K-近鄰算法的利用加權語義相似度比對進行敏感信息檢測的方法。這一類方法忽略了自然語言語序和上下文關系,導致模型對文本內容挖掘能力不足。文獻[6~7]提出了利用RNN 的線性序列結構收集文本中的敏感信息,刻畫特征并用于分類檢測。受益于模型對文本語義的學習能力,此類方法的檢測準確率通常高于機器學習方法。
在實際的檢測場景中,一段文字是否敏感往往取決于上下文語境,例如“兵員部署”一詞在軍事類文檔中是絕密,而在新聞和通俗讀物中敏感程度不高。這對檢測模型的文本語義表達能力提出很高的要求,而實際應用于訓練的敏感文檔樣本往往數量有限。為此,本文提出一種基于改進的elmo[8]的檢測模型,引入基于通用語料的預訓練動態詞向量豐富模型的語義表達能力,并構建數據集,通過與其他靜態詞向量表示模型進行比較,驗證了方法的可行性和先進性。
2 基于elmo的預訓練詞向量
2.1 模型原理
Elmo 模型于2018 年由Peters M,Ammar W 等人提出,利用雙向語言模型生成上下文相關的詞向量,對于解決一詞多義問題有很好的效果。該雙向語言模型的目標函數為

在訓練中,elmo 使用的是雙向長短期記憶網絡[9](Long Short-Term Memory,LSTM)。對于位置為k 的詞wk,令其通過一個L 層的biLM 計算得到共2L+1個表示:
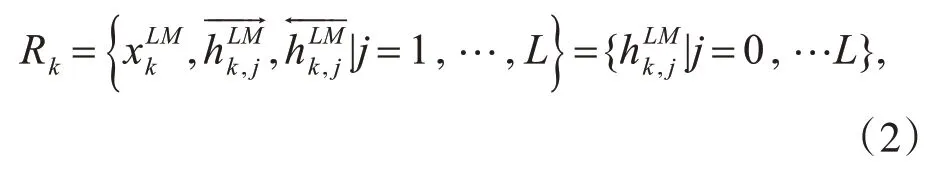
該模型結構如圖1所示。
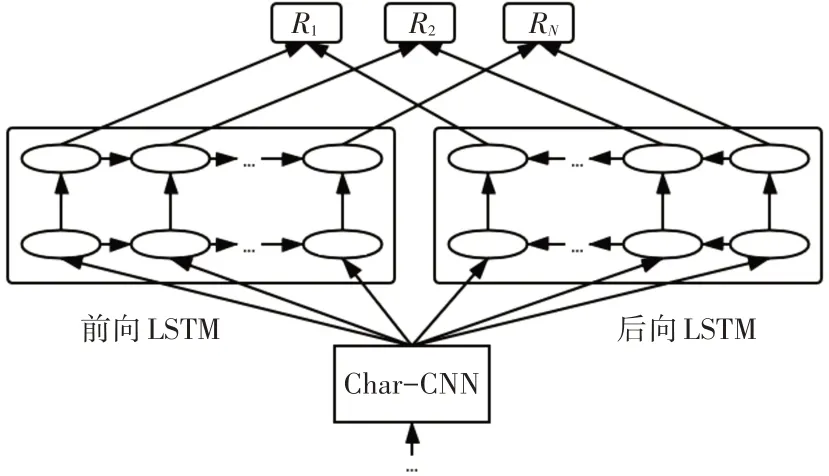
圖1 Elmo模型結構
對于一個文本序列輸入,首先使其通過字符卷積進行詞向量的初始化,再將詞向量分別送入兩個雙層的LSTM 網絡并行訓練,這里前向和后向LSTM 的網絡參數是獨立的。在需要使用時,可以簡單地提取最上層的結果作為詞的表示:E(Rk)=,也可以根據下游任務設置參數將所有層的結果組合從而壓縮得到最終的詞向量:

2.2 改進設計
對于輸入層,原模型中使用字符級別的CNN對詞向量進行初始化,對于英文單詞可以很好地提取子詞信息;在中文場景中,漢字不具備類似的語言學特性,因此本文選取Fasttext[10]作為初始化詞向量的方法,一方面避免了多層疊神經網絡的梯度消失問題,另一方面提高了預訓練通用語料的利用率,加強詞向量的文本表示能力。
由于LSTM 網絡參數數量較多,訓練時間過長,本文提出使用門限遞歸單元(Gated Recurrent Unit,GRU)[11]代替LSTM 單元結構。GRU 將LSTM單元結構中的遺忘門和輸入門組合為更新門,同時隱去了單元的內部狀態。它包括兩個門限結構:重置門用于采集需要保留的輸入向量和記憶信息;更新門用于記錄當前時序需要更新的信息的權值狀態。采用Bi-GRU 代替Bi-LSTM 可以在不損失詞向量質量的同時進一步加快模型的訓練速度。
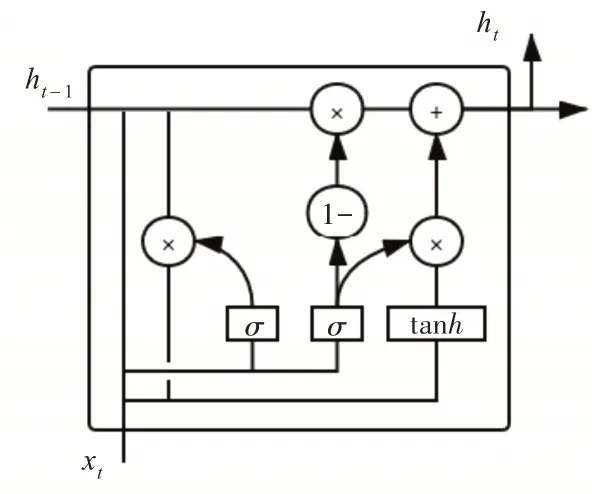
圖2 GRU的單元結構
從自然語言的角度,人們在順序讀取文本序列時理解文本內容比逆序讀取時更容易,語義表達更明確。因此本文猜想雙向語言模型中,前向網絡和后向網絡對詞向量表示的貢獻程度存在區別,前向網絡貢獻更大。為此,引入貢獻參數θ,不同于原模型中將前后向網絡輸出拼接作為詞表示的做法,以式(6)作為Bi-GRU的隱層輸出。
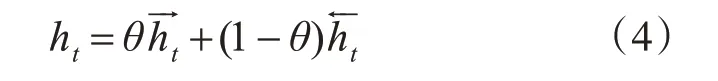
3 基于神經網絡的敏感文檔檢測模型
本文提出的檢測模型包括輸入層、elmo 層、神經網絡層和輸出層。
3.1 輸入層
未經處理的原始中文文本往往包含一些干擾和無用信息,為保證訓練數據質量,必須對文本進行預處理。預處理的步驟包括去除符號、分詞、去停用詞等。
3.2 elmo層
elmo層的作用是生成詞向量的表示,該網絡基于一個較大的通用語料訓練,因此網絡結構保存了大量的語言學信息。將改進的elmo 模型整體遷移到下游任務中時,僅需要少量的標注數據集訓練就可以達到較好的分類效果。預訓練完成后,將待檢測的敏感文本作為輸入,根據式(3)、(4),以一定權重組合Bi-GRU 中同一位置不同層的詞表示,從而完成對文本的向量化表示。
3.3 神經網絡層
神經網絡層接收詞向量的序列矩陣并抽取文檔特征,從而實現分類檢測。本文選取文獻[12]中提出的Text-CNN模型。該模型在處理文本分類任務時已經被證明可以取得較好的結果,并且相對RNN 模型具備高訓練效率的優勢。由于CNN 處理的是定長序列,因此需要根據訓練樣本集中的文本長度進行截斷或填充。對于定長文本序列構成的二維矩陣,采用不同尺寸的卷積核以滑窗形式進行卷積,并采用1-max pooling對得到的特征圖池化拼接得到最終的文本特征向量。
模型對敏感文檔的檢測流程如圖3所示。
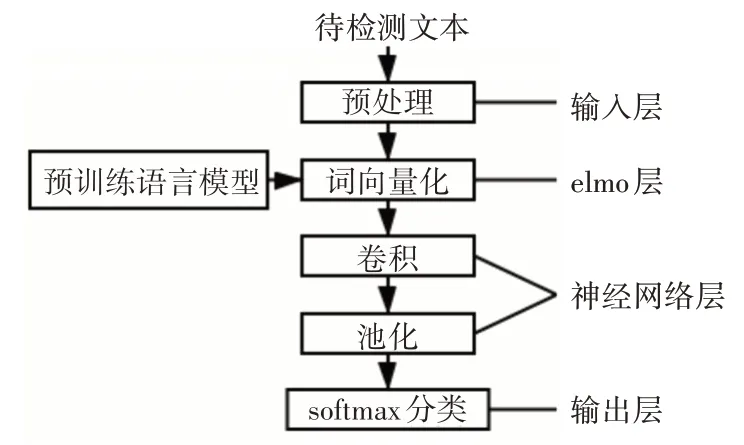
圖3 敏感文檔檢測模型
4 實驗
為驗證模型的文本表達能力對敏感檢測結果的影響,本文選取word2vec[13]、glove[14]兩種靜態詞向量作為對照。word2vec 是一種基于局部信息預測的無監督訓練模型[15],glove 是一種基于主題模型、依托全局語料中詞的共現頻率生成詞向量的模型[16]。兩者在文本分類領域中已經得到廣泛應用并有著較好的效果,因此適合作為基線模型用于對比。
4.1 數據集
實驗所需的數據集包含兩部分,一是用于詞向量訓練的通用語料,二是用于下游分類任務的專項語料。針對詞向量訓練的無監督學習過程,本文選用了中文維基百科語料,從中隨機選取20MB 左右的共13793 個文檔作為預訓練的通用語料;針對敏感信息檢測任務,該任務是一種有監督學習任務,本文爬取了維基解密中的原涉密中文文本作為“敏感”標簽的數據,從來源于搜狗實驗室的搜狐新聞數據集中隨機選取作為“非敏感”標簽的數據。
4.2 實驗結果
首先驗證引入貢獻參數θ的影響,在分類任務中θ取不同值時對準確率的影響如表1所示。
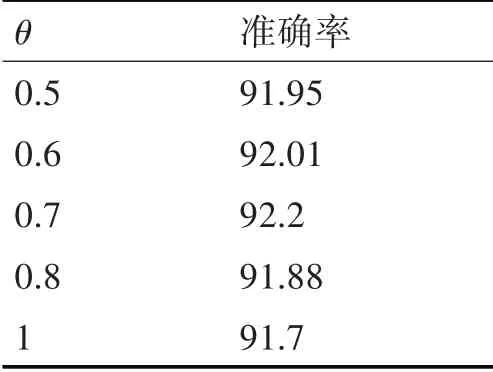
表1 不同θ 取值的影響
結果表明貢獻參數θ=0.7 時,分類準確率最優,驗證了引入參數θ區別前后向網絡貢獻的有效性。后續實驗中的改進elmo-CNN 模型均將θ值設為0.7。同時在模型的訓練過程中,與原elmo 模型對比發現,將Bi-LSTM 替換為Bi-GRU 后,模型每經過一個epoch 損失下降更多,網絡訓練的收斂速度加快。
為模擬實際檢測場景中上下文語境變化對文本敏感程度的影響,從前述數據集中選取了“軍事”和“政治”兩大類別的文檔,將其中來自維基解密的文檔標注為敏感,來自搜狐新聞的文檔標注為非敏感,形成對抗語境變化能力的測試集。結果如表2所示。

表2 不同預訓練詞向量的檢測結果對比
從表2可以看出,使用改進的elmo作為預訓練詞向量的檢測效果明顯優于另外兩者,提升幅度達到了6%左右。這是因為elmo 詞向量根據下游文本的上下文即時生成,并且融合了語序和語法特征,故而其語義表達的能力高于word2vec 和glove。另外,在實際檢測場景中,機構或企業往往由于業務領域的細分會存有大量處于同一類別的文檔,能否在這些同領域文檔中將敏感信息識別出來是評判檢測算法實用性的重要依據。在本實驗中設置類別相似而語境、語法發生改變的情況下,word2vec-CNN 和glove-CNN 的檢測能力均存在明顯下降,而改進的elmo-CNN 的檢測準確度下降程度較小,驗證了本文提出模型的優越性。
5 結語
本文構建了基于神經網絡的敏感文檔檢測模型,通過引入預訓練elmo 詞向量利用卷積神經網絡對敏感文檔實施檢測分類,緩解了敏感文檔訓練樣本不足的問題;并對原elmo 模型作出改進,提高了模型的語義表達能力以應對敏感檢測的復雜場景。實驗表明本文提出檢測模型是有效的,對敏感信息檢測領域的應用具備一定參考價值。由于敏感文檔的收集比較困難,在未來工作中,希望從提升驗證數據集質量和提高文本特征抽取能力兩個方面進一步對敏感信息檢測方法進行研究。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
