結合深度學習和Softmax 的零件瑕疵識別*
2022-06-16 12:46:16張新波朱姿娜張偉偉
計算機與數字工程 2022年5期
張新波 朱姿娜 張偉偉
(上海工程技術大學視覺測控與智能導航研究所 上海 201620)
1 引言
傳統的機器學習目標檢測更注重特征的提取,特征提取作為目標檢測中最關鍵的環節,眾多的研究者進行了大量研究,方向梯度直方圖(Histogram of Oriented Gradient)HOG[1]特征是Dalal 等在2005年針對行人檢測問題提出的特征,HOG 特征廣泛應用在于圖像識別領域。局部二值模式(LBP)[2]算子是T.Ojala 等于1994 年提出的,描述的是中心像素點的灰度值與周圍像素點灰度值的大小關系,表示 該 局 部 區 域 的 紋 理 特 征。Adaboosting[3]是Freund等于1996年提出的,Adaboost算法將多個弱分類器(一般采用單層的決策樹)進行組合,使之成為一個強分類器。采用的是迭代的思想,具有較高的檢測速度,不容易產生過適應現象。Cortes 和Vapnik(1995)[4]提出了支持向量機(SVM),SVM 算法是定義在特征空間上的間隔最大的線性分類器。
深度學習作為目前解決目標檢測識別問題的一種有效手段。Girshick[5]等在2014年提出了基于區域提名的卷積神經網絡R-CNN,R-CNN 在行人檢測和目標檢測等領域取得了巨大的成功,與此同時檢測速率低,計算成本大等問題非常突出,隨后針 對 此 問 題,Girshick 等(2015)又 提 出 了Fast R-CNN[6],相對于之前的R-CNN,在訓練時候的速度、測試時候的速度以及訓練所耗費的空間等方面有了很大的提升,Faster R-CNN[7],采用了區域生成網絡RPN 候選框提取模塊代替選擇性搜索Selective Search 模塊,大大提高了操作的效率。端到端的目標檢測則是另一類典型思路。此類方法不需要區域提名(Region Proposal),直接從圖像中回歸的方法提取目標。Redmon 提出的YOLO(You Only Look Once)[8],直接選用整張圖訓練模型,摒棄了滑窗和區域提名的方式,以此預測多個box 位置和類別的卷積神經網絡,提高了目標和背景區域的區分度。ECCV-2016 的SSD(single shot multibox detector)[9]算法,結合分配區域和回歸的概念,實現了速度與精度的均衡。Long 等提出的全卷積神經網絡(Fully Convolutional Network,FCN)[10]提供了嶄新的思路,首次實現了像素級的分類效果。在此基礎上,DeconvNet[11]等相繼出現。空間金字塔池化模塊(SPP)[12]由何凱明等于2014 年提出,可以將任意尺度的輸入轉換為相同尺度的輸出,且不同尺度特征的提取和拼接可以提高任務精度和網絡模型的魯棒性。Chen 等于2014 年提出的Deeplabv1[13]采用空洞卷積Fully-connected Conditional Random Field(CRF)來優化網絡,注重像素細節信息,提高了分割的精度,Ronneberger 等[14]隨后提出了一種新的網絡結構Unet,該網絡具有對稱的U型結構,通過對提取的圖像特征編解碼,更好地結合了高層和底層的信息特征,可以更加適合于提取細微的信息。
對于物體的瑕疵檢測特別是金屬類的物體,眾多的研究人員做了大量的工作。葉宏武等(2015)[15]提出了基于粒子群優化算法加權模糊C 均值聚類的零件缺陷圖像智能分割算法,精確識別定位零件表面瑕疵區域。雷泰等(2018)[16]基于導向線的刀路輪廓質量檢測方法。對已濾波圖像上輪廓的線寬、連通性和毛刺情況進行檢測。對于多類別瑕疵零件的研究不太深入。因此本文主要是運用深度學習技術,采用Softmax 算法對金屬零件進行瑕疵檢測識別。

圖1 零件實物圖
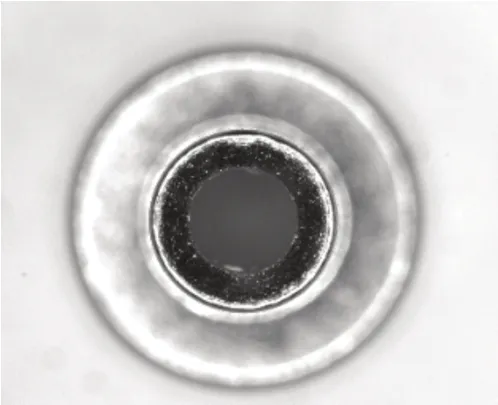
圖2 生產工位瑕疵檢測圖
2 算法模型
2.1 算法整體架構
本文的算法流程如圖3 所示:采用傳統CS-LBP 描述符來提取零件表面的紋理特征,來訓練Softmax分類器。然后選用Unet神經網絡對零件表面進行初步的區域提取,接著通過Softmax對Unet篩選出的初步區域進行二次分類,以此排除干擾區域。最終獲得單個零件的目標區域瑕疵的精準識別。
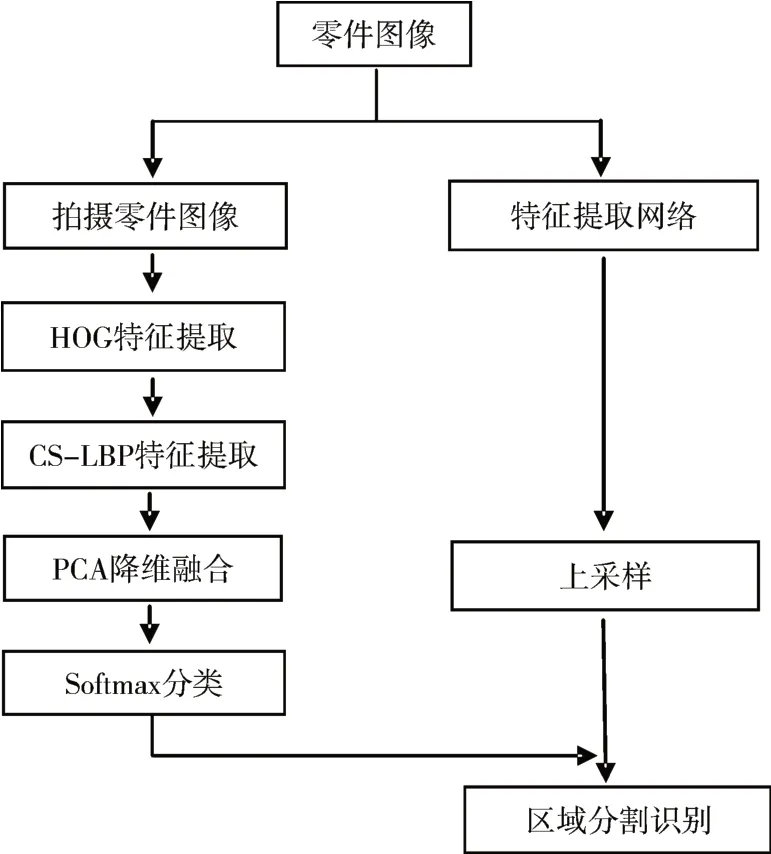
圖3 算法流程圖
2.2 基于多特征融合的Softmax分類器模型
2.2.1 CS-LBP特征
中心對稱局部二值模式CS-LBP 特征描述符,通過降低提取的特征維數以及減小計算復雜度,在一定程度上解決了上述弊端,由于考慮到像素對的灰度差值,因此與梯度描述符類似。CS-LBP 的檢測原理是:通過對局部區域中關于中心對稱的4 對像素差值的變化來描述紋理特征,計算公式如下所示:

式中(x,y)是局部區域中心像素點的坐標,gp表示周圍相鄰像素點的灰度值,gp+(N/2)表示關于與p 點關于中心點成中心對稱的像素點的灰度值。T 表示自定義閾值。s(x)表示符號函數,定義如下:
多年來,國家高度重視珠江水運發展,國務院先后頒布了《珠江—西江經濟帶發展規劃》《水污染防治行動計劃》;交通運輸部發布了《珠江水運發展規劃綱要》《關于推進珠江水運科學發展的若干意見》和《珠江水運科學發展行動計劃(2016-2020)》,這為打造西江“黃金水道”指明了方向。
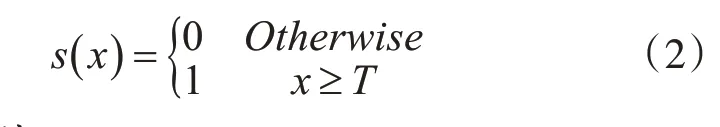
2.2.2 HOG特征
HOG 特 征 是 由Navneet Dalal & Bill Triggs 在CVPR 2005 發表的論文中提出來的,由于HOG 算子是在圖像中的局部方格中進行分析,所以此算子相對于其他的算子在圖像幾何以及光學變化方面有著良好的不變性。
通過計算圖像中局部區域的灰度梯度直方圖,提取HOG特征,其基本步驟如下:
1)將圖像劃分成若干Cell 計算每個Cell 在M個方向上的梯度直方圖。
2)將每個Block 中的Cell方向梯度直方圖串聯形成Block的方向梯度直方圖。
3)串聯圖像中所有的Block方向梯度直方圖輸出最終的圖像HOG特征。
本文HOG 特征設置如下:梯度方向個數M 取為9,Cell的大小為8*8,Block的大小為16*16。
2.2.3 特征降維融合
由于抓取區域具有金屬反光和紋理多變等特點,單個特征應用于圖片識別,容易造成遺漏或者錯誤的檢測。為了進一步提高識別的正確率,本文通過融合HOG 和CS-LBP 特征用于抓取區域的檢測。由于這兩種特征本身維數較大,直接進行拼接無疑會導致Softmax 分類器訓練耗時增加,致使訓練和檢測效率低下。因此本文采用主成分分析法對特征融合后的矩陣進行不同程度的降維,以提高訓練效率和檢測的準確率。
2.3 Unet模型
Unet 網絡模型首次被提出的應用場合主要集中在醫學圖像的分割領域,Unet網絡因為在上采樣的時候,有多個通道,能夠使得較多的上下文信息傳遞到更高分辨率的網絡層中。從而使得對于醫學圖像的分割可以做到更加精細化。
此網絡主要因其形似U 型而被命名為Unet,Unet 網絡結構包含了23 個卷積層,4 個最大池化層,每個池化層將特征尺寸降為原來尺寸的一半,在第8個和第9個卷積層使用Dropout技術,數值均設定為0.5,其中激活函數使用的是ReLU,在每一次下采樣操作中,都會將特征通道的數量加倍。在左側的收縮架構中,每一個步驟都是先使用反卷積操作,反卷積操作會將會使特征通道數量減小一半。特征圖的尺寸會增加一倍。每次反卷積操作后,將結果和收縮路徑中對應步驟的特征圖拼接,最后的結果進行兩次3*3 的卷積,最后一層的卷積核大小設定為1*1。圖4所示為U-Net網絡結構。

圖4 Unet網絡結構
3 實驗和結果
3.1 實驗環境
采用的實驗環境如下:Ubuntu16.04 操作系統,內存為16G,CPU 為Inter 酷睿i78700@3.2GHz,GPU為NVIDIA GTX-1080,Python3.6.5。
3.1.1 實驗準備
本實驗中的圖像數據等全是筆者自己采集制作并標注完成,其中考慮到采集的原始圖像很大部分具有單一性,因此對一些數據使用了數據增強技術:尺度變換、旋轉等操作,進行了數據擴充,完善豐富了數據的多樣性。其中采用大小為1080*960的圖片來訓練Unet網絡。最終用于訓練Softmax分類器的圖片選用的圖像大小為64*64 像素。其中正樣本的圖片數量為86 張,負樣本圖像數量為51張。
3.1.2 訓練過程
Softmax 分類器是對Logistic 二分類的一個拓展推廣,其基本原理比較簡單并且主要作為多分類問題的解決方案來使用。
把n 個訓練樣本記錄為{(x(1),y(1)),(x(2),y(2)),… ,(x(n),y(n))},ai為缺陷所屬類別的標簽,其中ai∈{1,2,…,m},m 為缺陷種類的總類別數。

圖5 負樣本

圖6 正樣本
訓練時,采用的是帶有動量的隨機梯度下降算法,學習率設為0.01,動量設定為0.9,學習率在訓練過程中進行多項式衰減,網絡在NVIDIA GTX 1080 GPU的加速訓練,訓練了500個epoch,花費時間是8h。
在最后一層使用交叉熵損失函數。函數公式如下:
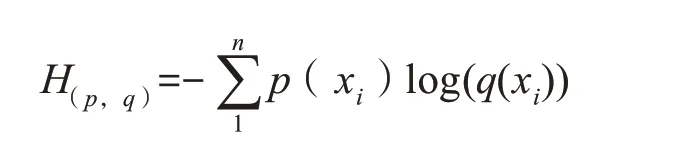
其中P(x)表示真實概率分布,q(x)表示預測概率分布。
3.2 結果分析
最終采用多特征融合的Softmax 算法,Unet 算法,以及本文提出的算法分別在零件數據集中進行了缺陷區域檢測。最終的實驗結果如圖7所示。

圖7 實驗檢測結果對比
從表1 中的實驗檢測結果進行分析。基于傳統的多特征融合Softmax算法在各個指標上都遜色于Unet 以及本文的算法。側面驗證了單純的機器學習的算法在缺陷檢測領域的局限性,而本文的算法檢測準確率達到了88.2%,錯檢率僅僅為3.4%,優于Unet 算法。由于金屬零件檢測過程中光照、角度等的影響,也會造成Softmax 分類器在多分類時出現錯誤的劃分。最終導致錯檢率和漏檢率都相對高于Unet 算法。從整體上對比分析,本文的算法達到了較為理想的檢測精度。

表1 三種模型實驗檢測結果
4 結語
針對零件瑕疵檢測流程中,傳統的缺陷檢測準確率不足的問題,提出了一種基于Unet 和多特征融合的Softmax 識別算法。該方法多特征融合的Softmax 分類器對Unet 的識別結果進行二次分析,最終實現了對瑕疵區域的精確識別,剔除了干擾區域。本文的算法主要有以下的優點:1)傳統的機器學習的目標檢測識別在根據人工選擇的缺陷特征對其分類時會導致精度較差,而本文的算法則可以在識別目標外形的基礎上,對缺陷的種類也能夠很好的識別。2)在圖像訓練集構建中,充分考慮了光照,拍攝角度等影響,對角度和光照等情況做了劃分,使得實際檢測中,算法具有一定的魯棒性。3)構建使用多特征融合的Softmax分類器有效彌補了單一網絡框架檢測的局限性,使得錯檢率得到了顯著的下降。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
