一種魯棒的半監(jiān)督聯(lián)邦學習系統(tǒng)
2022-06-16 05:24:26王樹芬馬士堯陳俞強
計算機工程 2022年6期
王樹芬,張 哲,馬士堯,陳俞強,伍 一
(1.哈爾濱石油學院 信息工程學院,哈爾濱 150028;2.黑龍江大學 數(shù)據(jù)科學與技術(shù)學院,哈爾濱 150080;3.廣州航海學院 信息與通信工程學院,廣州 510725)
0 概述
聯(lián)邦學習[1-3](Federated Learning,F(xiàn)L)是隱私計算領(lǐng)域的重要技術(shù),允許多個邊緣設備或客戶端合作訓練共享的全局模型。聯(lián)邦學習[4]的特點是每個客戶端只能私有地訪問本地數(shù)據(jù),而不能與云中心共享數(shù)據(jù)[5-6]。現(xiàn)有研究多數(shù)要求客戶端的數(shù)據(jù)都帶有真實的標簽,然而在現(xiàn)實場景下客戶端的數(shù)據(jù)多數(shù)是沒有標簽的。這種標簽缺失的現(xiàn)象通常是由于標注成本過高或缺少相關(guān)領(lǐng)域的專家知識造成的[7]。因此,如何利用本地客戶端上的無標簽數(shù)據(jù)來訓練高質(zhì)量的全局模型對聯(lián)邦學習而言是一個巨大的挑戰(zhàn)。
文獻[7-10]設計一種可將半監(jiān)督學習技術(shù)有效地整合到FL 中的半監(jiān)督聯(lián)邦學習(Semi-Supervised Federated Learning,SSFL)系統(tǒng)。文獻[7]引入一致性損失和已訓練的模型,為無標簽數(shù)據(jù)生成偽標簽。目前,偽標簽和一致正則化方法已廣泛應用于半監(jiān)督領(lǐng)域,但是偽標簽主要利用預測值高于置信度閾值的偽標簽來實現(xiàn)高精度模型,一致正則化技術(shù)通過在同一個無標簽數(shù)據(jù)中分別注入兩種不同噪聲應保持相同模型輸出來訓練模型[11]。因此,亟需設計一個通用的聯(lián)邦半監(jiān)督學習框架,但設計該框架存在兩個主要問題。第一個是傳統(tǒng)SSFL 方法[7,12-13]直接將半監(jiān)督技術(shù)(例如一致性損失和偽標簽)引入FL 系統(tǒng),之后使用聯(lián)邦學習算法來聚合客戶端的模型參數(shù)。這樣將導致模型在利用大量無標簽的數(shù)據(jù)學習后會遺忘從少量標簽數(shù)據(jù)中學習到的知識。文獻[10]分解了標簽數(shù)據(jù)和無標簽數(shù)據(jù)的模型參數(shù)用于進行分離學習,卻忽略了全局模型迭代更新之間的隱式貢獻。因此,全局模型將偏向于標簽數(shù)據(jù)(監(jiān)督模型)或無標簽數(shù)據(jù)(無監(jiān)督模型)。第二個是統(tǒng)計異質(zhì)性,即客戶端本地的訓練數(shù)據(jù)分布是非獨立同分布(not Identically and Independently Distributed,non-IID)的。其主要原因為不同的客戶端具有不同的訓練數(shù)據(jù)集,而這些數(shù)據(jù)集通常沒有重疊,甚至是分布不同的。因此,在異構(gòu)數(shù)據(jù)的訓練過程中,客戶端局部最優(yōu)模型與全局最優(yōu)模型會出現(xiàn)很大的差異。這將導致標準的聯(lián)邦學習方法在non-IID 設置下全局模型性能出現(xiàn)顯著下降和收斂速度慢的問題。目前,研究人員對此進行了大量研究并在一定程度上緩解了non-IID 問題。例如文獻[14]利用局部批處理歸一化來減輕平均聚合模型和局部模型之前的特征偏移。然而,此類方法給服務器或客戶端增加了額外的計算和通信開銷。
本文針對上述第一個問題,提出FedMix 方法,分析全局模型迭代之間的隱式效果,采用對監(jiān)督模型和無監(jiān)督模型進行分離學習的模型參數(shù)分解策略。針對上述第二個問題,為了緩解客戶端之間的non-IID 數(shù)據(jù)分布對全局模型收斂速度和穩(wěn)定性的影響,提出FedLoss 聚合方法,通過記錄客戶端的模型損失來動態(tài)調(diào)整相應局部模型的權(quán)重。此外,在實驗中引入Dirchlet 分布函數(shù)來模擬客戶端數(shù)據(jù)的non-IID 設置。
1 相關(guān)工作
半監(jiān)督聯(lián)邦學習試圖利用無標簽數(shù)據(jù)進一步提高聯(lián)邦學習中全局模型的性能[9]。根據(jù)標簽數(shù)據(jù)所在的位置,半監(jiān)督聯(lián)邦學習分為標簽在客戶端和標簽在服務器兩種場景[10]。文獻[12]提出FedSemi,該系統(tǒng)在聯(lián)邦學習設置下統(tǒng)一了基于一致性的半監(jiān)督學習模型[15]、雙模型[16]和平均教師模型[17]。文獻[8]提出DS-FL 系統(tǒng),旨在解決半監(jiān)督聯(lián)邦學習中的通信開銷問題。文獻[18]提出一種研究non-IID數(shù)據(jù)分布的方法。該方法引入了一個概率距離測量來評估半監(jiān)督聯(lián)邦學習中客戶端數(shù)據(jù)分布的差異。與以上方法不同,本文研究了標簽數(shù)據(jù)在服務器上這一場景,同時也解決了聯(lián)邦學習中non-IID 的問題。
由于每個客戶端本地數(shù)據(jù)集的分布與全局分布相差較大,導致客戶端的目標損失函數(shù)局部最優(yōu)與全局最優(yōu)不一致[19-21],特別是當本地客戶端模型參數(shù)更新很大時,這種差異會更加明顯,因此non-IID的數(shù)據(jù)分布對FedAvg[1]算法的準確性影響很大。一些研究人員試圖設計一種魯棒的聯(lián)邦學習算法去解決聯(lián)邦學習中的non-IID 問題。例如,F(xiàn)edProx[22]通過限制本地模型更新的大小,在局部目標函數(shù)中引入一個額外的L2 正則化項來限制局部模型和全局模型之間的距離。然而,不足之處是每個客戶端需要單獨調(diào)整本地的正則化項,以實現(xiàn)良好的模型性能。FedNova[23]在聚合階段改進了FedAvg,根據(jù)客戶端本地的訓練批次對模型更新進行規(guī)范化處理。盡管已有研究在一定程度上緩解了non-IID 問題,但都只是評估了特定non-IID 水平的數(shù)據(jù)分布,缺少對不同non-IID 場景下的廣泛實驗驗證。因此,本文提出一個更全面的數(shù)據(jù)分布和數(shù)據(jù)分區(qū)策略,即在實驗中引入Dirchlet 分布函數(shù)來模擬客戶端數(shù)據(jù)的不同non-IID 水平。
2 相關(guān)知識
2.1 聯(lián)邦學習
聯(lián)邦學習旨在保護用戶隱私的前提下解決數(shù)據(jù)孤島問題。FL 要求每個客戶端使用本地數(shù)據(jù)去合作訓練一個共享的全局模型ω*。在FL 中,本文假設有一個服務器S和K個客戶端,其中每個客戶端都存在一個獨立同分布(Independently Identical Distribution,IID)或者non-IID 數(shù)據(jù)集Dk。具體地,客戶端使用損失函數(shù)l(ω;x)訓練樣本x,其中ω∈Rd表示模型可訓練的參數(shù)。本文定義L(ω)=作為服務器上的損失函數(shù)。因此,F(xiàn)L需要在服務器端優(yōu)化如下目標函數(shù):

其中:pk≥0,表示第k個客戶端在全局模型中的權(quán)重。在FL 中,為了最小化上述目標函數(shù),服務器和客戶端需要執(zhí)行以下步驟:
步驟1初始化。服務器向被選中的客戶端發(fā)送初始化的全局模型ω0。
步驟2本地訓練。客戶端在本地數(shù)據(jù)集Dk上使用優(yōu)化器(例如SGD、Adam)對初始化的模型進行訓練。在訓練后,每個客戶端向服務器上傳本地模型。
步驟3聚合。服務器收集客戶端上傳的模型并使用聚合方法(例如FedAvg)聚合生成一個新的全局模型,即ωt+1=ωt+。之后服務器將更新后的全局模型ωt+1發(fā)送給下一輪被選擇參與訓練的客戶端。
2.2 半監(jiān)督學習
在現(xiàn)實世界中,例如金融和醫(yī)療領(lǐng)域,無標簽數(shù)據(jù)很容易獲得而標簽數(shù)據(jù)很難得到。與此同時,標注數(shù)據(jù)通常耗費大量的人力物力。為此研究人員提出了一種機器學習范式——半監(jiān)督學習[24-26]。半監(jiān)督學習可以在混合的數(shù)據(jù)集(一部分為標簽數(shù)據(jù),另一部分為無標簽數(shù)據(jù))上訓練得到高精度模型。因此,近些年半監(jiān)督學習在深度學習領(lǐng)域成為一個熱門的研究方向。在本節(jié)中,將介紹半監(jiān)督學習中的一個基本假設和兩種常用的半監(jiān)督學習方法。
假設1(一致性)在機器學習中存在一個基本假設:如果兩個無標簽樣本u1、u2的特征相似,那么相應模型的預測結(jié)果y1、y2也應該相似[14],即f(u1)=f(u2),其中f(·)是預測函數(shù)。
根據(jù)假設1,研究人員一般采用如下兩種常用的半監(jiān)督學習方法:
1)一致性正則化。該方法的主要思想是對于無標簽的訓練樣本,無論是否加入噪聲,模型預測結(jié)果都應該是相同的[19]。通常使用數(shù)據(jù)增強(如圖像翻轉(zhuǎn)和移位)的方式來給無標簽樣本添加噪聲以增加數(shù)據(jù)集的多樣性。假定一個無標簽數(shù)據(jù)集u=中的無標簽樣本ui,其擾動形式為,則目標是最小化未標記數(shù)據(jù)與其擾動輸出兩者之間的距離,其中fθ(ui)是樣本ui在模型θ上的輸出。一般地,采用Kullback-Leiber(KL)散度進行距離測量,因此一致性損失計算如下:
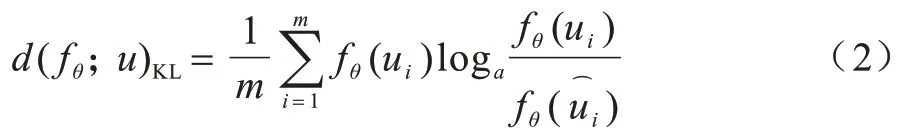
其中:m表示未標記樣本的總數(shù);fθ(ui)表示無標簽樣本在模型θ上的輸出。
2)偽標簽[15]。該方法利用一些標簽樣本來訓練模型,從而給無標簽樣本打上偽標簽。一般使用Sharpening[15]和argmax[15]方法來設置偽標簽,其中前者使模型輸出的分布極端化,后者會將模型輸出轉(zhuǎn)變?yōu)閛ne-hot。偽標簽方法也稱為自訓練方法,具體步驟如下:
步驟1使用少量的標簽數(shù)據(jù)訓練模型。
步驟2將無標簽數(shù)據(jù)輸入該模型,之后將無標簽數(shù)據(jù)的預測結(jié)果進行Sharpening 或argmax 操作,得到無標簽數(shù)據(jù)的偽標簽。
步驟3標簽數(shù)據(jù)和偽標簽數(shù)據(jù)共同訓練模型。
重復步驟2 和步驟3,直至模型收斂。
3 問題定義
目前,針對FL 的研究多數(shù)基于標簽數(shù)據(jù)訓練模型。然而,缺少標簽數(shù)據(jù)是現(xiàn)實世界中的一種常見現(xiàn)象。同時,在標簽數(shù)據(jù)不足的情況下,現(xiàn)有方法的實驗結(jié)果較差。半監(jiān)督學習可以使用無標簽數(shù)據(jù)和少量的標記數(shù)據(jù)來達到與監(jiān)督學習幾乎相同的模型性能。因此,本文將半監(jiān)督學習方法應用于聯(lián)邦學習框架中。在SSFL 系統(tǒng)中,根據(jù)標簽數(shù)據(jù)所在的位置,可以分為兩種場景:第一種場景是客戶端同時具有標簽數(shù)據(jù)和無標簽數(shù)據(jù)的常規(guī)情況,即標簽在客戶端場景;第二種場景是標簽數(shù)據(jù)僅可用在服務器上,即標簽在服務器場景。本文針對標簽在服務器場景,給出問題定義:當標簽數(shù)據(jù)只在服務器端,客戶端僅有無標簽數(shù)據(jù)時,在SSFL 中假設有1 個服務器S和K個客戶端。服務器上有1 個標簽數(shù)據(jù)集Ds=,每個客戶端均有1 個本地無標簽數(shù)據(jù)集。因此,在這種情況下,對于無標簽的訓練樣本ui,令為第k個客戶端的損失函數(shù),具體公式如下:
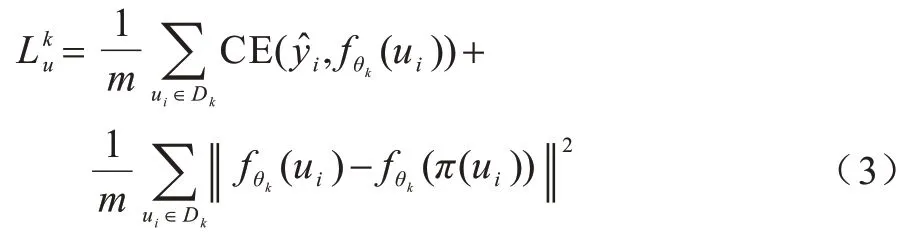
其中:m是無標簽樣本的數(shù)量;π(·)是數(shù)據(jù)增強函數(shù),例如無標簽數(shù)據(jù)的翻轉(zhuǎn)和平移;是無標簽樣本ui的偽標簽;是樣本ui在第k個客戶端的模型θk上的輸出。對于標簽樣本xi,令Ls為服務器端的損失函數(shù),具體公式如下:
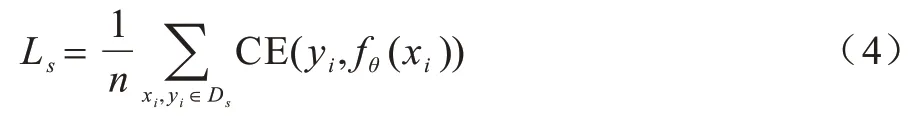
其中:n是標簽樣本的數(shù)量;fθ(xi)是樣本xi在模型θ上的輸出。因此,在SSFL 中標簽在服務器場景中國的目標是將損失函數(shù)最小化,具體公式如下:

整個學習過程類似于傳統(tǒng)的FL 系統(tǒng),不同之處在于服務器不僅聚合客戶端模型參數(shù),而且還使用標簽數(shù)據(jù)訓練模型。
4 系統(tǒng)與方法設計
4.1 半監(jiān)督聯(lián)邦學習系統(tǒng)設計
在半監(jiān)督聯(lián)邦學習系統(tǒng)(如圖1 所示)中,①~⑥表示訓練過程,服務器S持有一個標記的數(shù)據(jù)集Ds=。對于K個客戶端,假設第k個客戶端擁有本地無標簽的數(shù)據(jù)集。與傳統(tǒng)FL 系統(tǒng)類似,SSFL 中的服務器和客戶端合作訓練高性能的全局模型ω*,目標是優(yōu)化上述目標函數(shù)式(5),但是它們忽略了全局模型迭代之間的隱式貢獻,從而導致學習的全局模型不是最佳的。
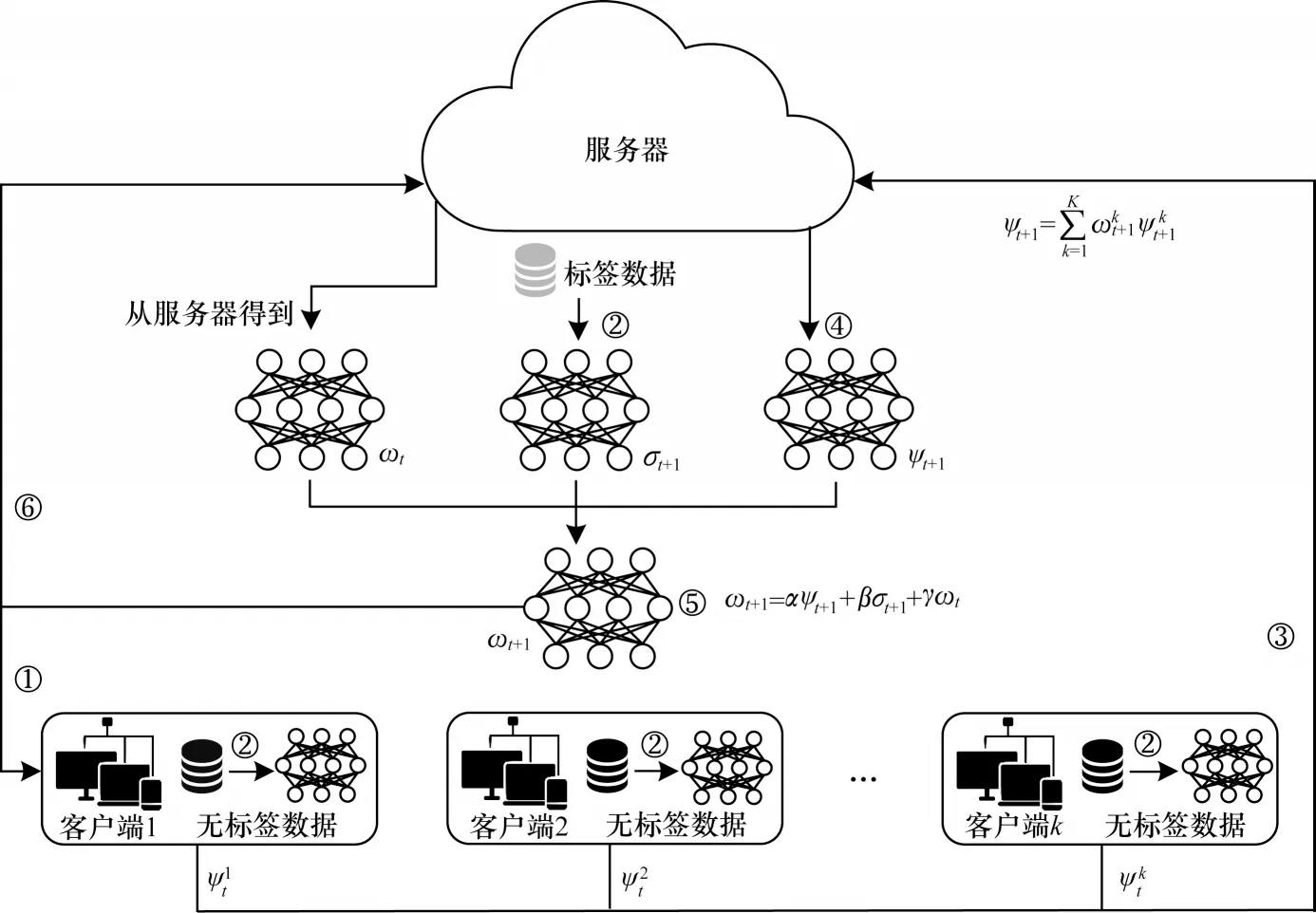
圖1 半監(jiān)督聯(lián)邦學習系統(tǒng)框架Fig.1 Framework of semi-supervised federated learning system
受此啟發(fā),本文提出一種FedMix 方法,該方法以細粒度的方式關(guān)注全局模型迭代之間的隱式貢獻,將在標記數(shù)據(jù)集上訓練的監(jiān)督模型定義為σ,在無標簽數(shù)據(jù)集上訓練的無監(jiān)督模型定義為ψ,聚合的全局模型定義為ω。具體而言,本文設計一種參數(shù)分解策略,分別將α、β和γ3 個權(quán)重分配給無監(jiān)督模型ψ、監(jiān)督模型σ和上一輪的全局模型ω。FedMix方法可以通過細粒度的方式捕獲全局模型的每次迭代之間的隱式關(guān)系,具體步驟如下:
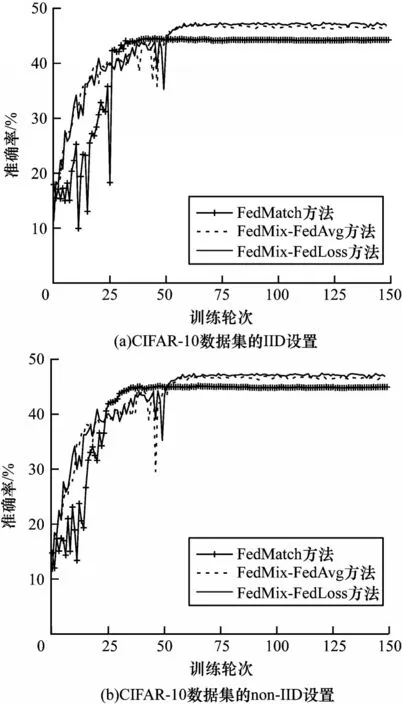
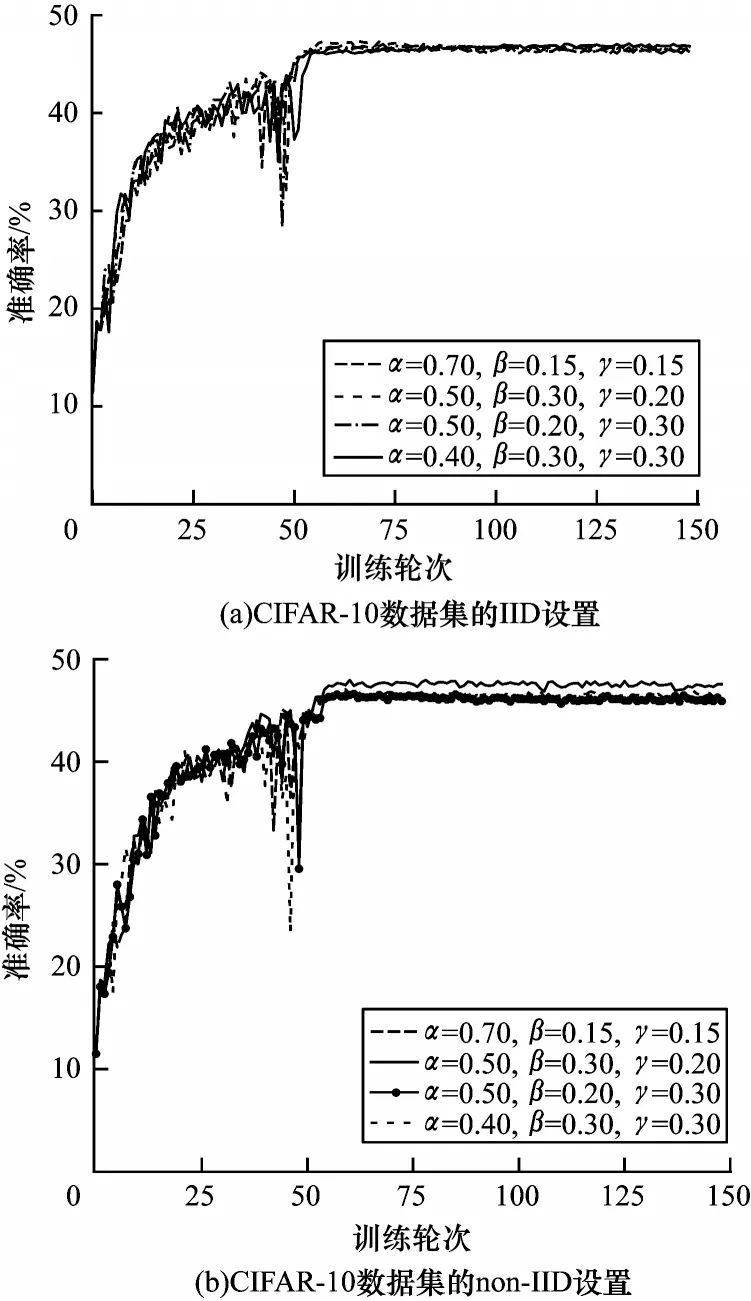
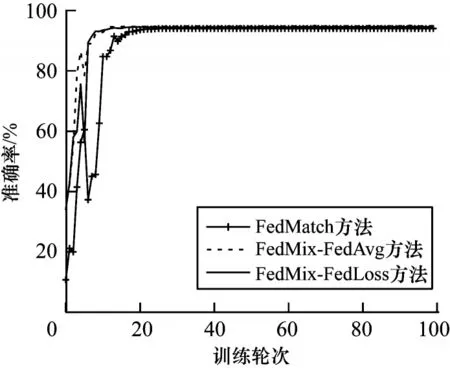
步驟1初始化。服務器從所有本地客戶端中隨機選擇一定比例F(0 步驟2服務器訓練。與FL 不同,在本文SSFL系統(tǒng)中,服務器不僅聚合客戶端上傳的模型,而且在標簽數(shù)據(jù)集Ds上訓練監(jiān)督模型σt(σt←ωt)。因此,服務器在標記的數(shù)據(jù)集Ds上使用本地優(yōu)化器來訓練監(jiān)督模型σt。目標函數(shù)的最小化定義如下: 其中:λs是超參數(shù);x和y來自標簽數(shù)據(jù)集Ds;表示在第t輪訓練中標簽樣本在監(jiān)督模型σt上的輸出。 步驟3本地訓練。第k個客戶端使用本地無標簽的數(shù)據(jù)來訓練接收到的全局模型,獲得無監(jiān)督的模型。因此,定義以下目標函數(shù): 其中:λ1、λ2是控制損失項之間比率的超參數(shù);是第k個客戶端在第t輪的無監(jiān)督模型;u來自無標簽的數(shù)據(jù)集Dk;π(·)是擾動的形式,即π1是移位數(shù)據(jù)增強,π2是翻轉(zhuǎn)數(shù)據(jù)增強;是通過使用本文提出的Sharpening 方法(如圖2 所示)獲得的偽標簽。 圖2 Sharpening 方法流程Fig.2 Procedure of Sharpening method Sharpening 方法的定義如下: 步驟4聚合。首先,服務器使用FedLoss 方法來聚合客戶端上傳的無監(jiān)督模型,得到全局的無監(jiān)督模型,即ψt+1=,其中是第k個客戶端在第t+1 次訓練輪次中的無監(jiān)督模型,是第k個客戶端的權(quán)重。然后,服務器將第t+1 輪的全局無監(jiān)督模型ψt+1、監(jiān)督模型σt+1和上一輪的全局模型ωt聚合得到新的全局模型ωt+1,如式(10)所示: 其中:α、β和γ是這3 個模型對應的權(quán)重,(α,β,γ)∈{α+β+γ=1且α,β,γ≥0}。 重復上述步驟,直到全局模型收斂。 FedLoss 聚合方法可以根據(jù)客戶端模型訓練的損失值調(diào)整相應局部模型的權(quán)重,用于提高聚合的全局模型的性能。原因是有些客戶端模型在本地訓練后性能較好,那么這些客戶端就應該對全局模型做出更多的貢獻。本文的目標是增大客戶端性能好的本地模型對全局模型的影響,以提高模型的性能。因此,F(xiàn)edLoss聚合方法的定義如下: 其中:F是客戶端參與率;K是客戶端的總數(shù);是第k個客戶端在第t+1 輪訓練的模型損失值;St+1是第t+1 輪中服務器選擇的客戶端集合。 為更好地評估本文所設計的系統(tǒng)對non-IID 數(shù)據(jù)的魯棒性,引入Dirchlet 分布函數(shù)[27-28]來調(diào)整本地客戶端數(shù)據(jù)的non-IID 水平。具體而言,通過調(diào)整Dirchlet 分布函數(shù)的參數(shù)(即μ)來生成不同non-IID水平的數(shù)據(jù)分布。假設第k個客戶端的本地數(shù)據(jù)集Dk有c個類,因此Dirichlet 分布函數(shù)的定義如下: 其中:Θ是從Dirichlet 函數(shù)中隨機選取的樣本集,Θ={φ1,φ2,…,φc}且Θ~Dir(μ1,μ2,…,μc);μ,μ1,μ2,…,μc是Dirichlet 分布函數(shù)的參數(shù),μ=μ1=μ2=…=μc;pk(φc)表示第c類數(shù)據(jù)占客戶端所有數(shù)據(jù)的比例。如圖3所示,μ越小,每個客戶端數(shù)據(jù)分布的non-IID 水平越高;否則,客戶端的數(shù)據(jù)分布傾向于IID 設置。 圖3 不同μ 時的Dirichlet 數(shù)據(jù)分布Fig.3 Dirichlet data distribution with different μ 針對標簽在服務器場景,將本文所提出的FedMix-FedLoss 方法與FedMatch 方法[10]在2 個數(shù)據(jù)集的3 個不同任務上進行比較。對于2 個真實世界的數(shù)據(jù)集(即CIFAR-10 和Fashion-MNIST),實驗在配置為Intel?CoreTMi9-9900K CPU @3.60 GHz 和NVIDIA GeForce RTX 2080Ti GPU 的本地計算機(1 臺服務器和K個客戶端)上模擬聯(lián)邦學習設置。 數(shù)據(jù)集1 為IID 和non-IID 的CIFAR-10。將CIFAR-10 數(shù)據(jù)集(包括56 000 個訓練樣本和2 000 個測試樣本)分為IID 和non-IID 這2 種設置用作實驗的驗證數(shù)據(jù)集。訓練集包括55 000 個無標簽的樣本和1 000 個標簽的樣本,分別分布在100 個客戶端和1 個服務器上。IID 設置每個客戶端有550 個樣本,即每個類別有55 個樣本,總共10 個類別。non-IID的設置引入了Dirchlet 分布函數(shù)來調(diào)整客戶端數(shù)據(jù)的non-IID 水平。對于所有的non-IID 實驗,均設置μ=0.1 用于模擬極端的non-IID 場景,即每個客戶端數(shù)據(jù)的數(shù)量和類別都是不平衡的。1 000 個標簽的樣本位于服務器上,其中每個類別有100 個樣本。同時,實驗設置客戶端參與率F=5%,即在每一輪中服務器隨機選擇5 個客戶端進行訓練。 數(shù)據(jù)集2 為流式non-IID 的Fashion-MNIST。使用包括64 000 個訓練樣本和2 000 個測試樣本的Fashion-MNIST 數(shù)據(jù)集作為驗證數(shù)據(jù)集。訓練集包括63 000 個無標簽的樣本和1 000 個標簽的樣本,其中前者不平衡地分布在10 個客戶端上,后者分布在服務器上。實驗同樣引入Dirchlet分布函數(shù)且參數(shù)μ=0.1。每個客戶端的數(shù)據(jù)被平均分為10 份,每輪訓練只使用其中的一份,訓練10 輪為1 個周期。將此設置稱為流式non-IID。同時,實驗設定客戶端參與率F=100%,即在每一輪中服務器選擇所有客戶端進行訓練。 本文使用FedMatch 基線方法,其使用客戶端間一致性損失和模型參數(shù)分解。在訓練過程中,本文方法和基線方法均使用隨機梯度下降(Stochastic Gradient Descent,SGD)來優(yōu)化初始學習率為η=1e-3 的ResNet-9 神經(jīng)網(wǎng)絡。設置訓練輪次t=150,在服務器上的標簽樣本數(shù)為Ns=1 000,客戶端每輪的訓練次數(shù)為Eclient=1,客戶端每輪的訓批次為Bclient=64,服務器每輪的訓練次數(shù)Eserver=1,服務器每輪的訓批次為Bserver=64。在Sharpening 方法中,設置A=5 和置信度閾值τ=0.80。 基線方法包括:1)SL,全部標簽數(shù)據(jù)在服務器端執(zhí)行監(jiān)督學習,客戶端不參與訓練;2)FedMatch,采用客戶端之間一致性損失的半監(jiān)督聯(lián)邦學習方法。本文方法包括:1)FedMix,無監(jiān)督模型、監(jiān)督模型以及上一輪的全局模型在相同權(quán)重設置下的半監(jiān)督聯(lián)邦學習方法,即α=β=λ=0.33;2)FedMix-FedAvg,在最優(yōu)模型權(quán)重設置下,結(jié)合半監(jiān)督聯(lián)邦學習系統(tǒng)框架與FedAvg 聚合規(guī)則的方法;3)FedMix-FedLoss,在最優(yōu)模型權(quán)重設置下,結(jié)合半監(jiān)督聯(lián)邦學習系統(tǒng)加FedLoss聚合規(guī)則的方法。由表1 可知:只使用標簽數(shù)據(jù)的監(jiān)督學習模型的準確率僅為19.3%,明顯低于半監(jiān)督聯(lián)邦學習的組合方法,并且在相同模型權(quán)重聚合下也低于不同權(quán)重的組合方法。 表1 不同方法的準確率比較Table 1 Accuracy comparison of different methods % 本文對CIFAR-10 和Fashion-MNIST 數(shù)據(jù)集在IID和non-IID 設置下的性能進行比較。圖4 給出了IID 和non-IID 設置下,不同組合方法的FedMix 和基線方法的準確率對比。實驗結(jié)果表明,本文FedMix 方法的性能均比基線方法好。例如,在IID 和non-IID 設置下,本文方法的最大收斂準確率均比基線準確率高約3 個百分點。這是由于本文全局模型為無監(jiān)督模型、監(jiān)督模型以及上一輪的全局模型三者最優(yōu)權(quán)重的聚合。但在non-IID 情況下,在模型訓練的中期,出現(xiàn)了性能大幅波動的現(xiàn)象。這是由于客戶端non-IID 設置影響了聚合的全局模型的性能。 圖4 IID 與non-IID 設置下不同方法的性能比較Fig.4 Performance comparison of different methods under IID and non-IID settings 圖5 給出了在IID 和non-IID 設置下FedMix-FedLoss 方法取不同權(quán)重值時的性能比較。從圖5(a)可以看出,當這3 個參數(shù)在IID 設置下相對接近時更容易達到更好的性能。從圖5(b)可以看出,在non-IID 設置下,隨著α的減小,準確率變得不穩(wěn)定,在α=0.5、β=0.3、γ=0.2 時,F(xiàn)edMix-FedLoss 方法的性能最好。 圖5 IID 和non-IID 設置下FedMix-FedLoss 方法在不同權(quán)重時的性能比較Fig.5 Performance comparison of FedMix-FedLoss method with different weights under IID and non-IID settings 圖6 給出了FedMix-FedLoss 方法在CIFAR-10 數(shù)據(jù)集上及在不同non-IID 設置下的性能比較。在此實驗中,μ=0.1 表示客戶端數(shù)據(jù)的最高non-IID 水平。隨著μ值增加,本地客戶端數(shù)據(jù)分布將更接近IID 設置。從實驗結(jié)果可以看出,對于不同的non-IID設置,F(xiàn)edMix-FedLoss 方法均可以達到穩(wěn)定的準確率且模型收斂準確率相差不超過1 個百分點。因此,F(xiàn)edMix-FedLoss方法對不同non-IID 設置的客戶端數(shù)據(jù)分布不敏感,即對不同設置的數(shù)據(jù)分布具有魯棒性。 圖6 不同non-IID 設置下FedMix-FedLoss 方法的性能比較Fig.6 Performance comparison of FedMix-FedLoss method under different non-IID l settings 圖7 給出了在服務器端使用不同數(shù)量的標簽樣本時,F(xiàn)edMix-FedLos 方法的準確率比較結(jié)果。由圖7 可以看出,F(xiàn)edMix-FedLos 方法在800 個標簽的樣本設置下,在訓練輪次為150 時的收斂準確率為47%,相比FedMatch 方法使用1 000 個標簽樣本時的最大收斂準確率高出2個百分點。但是當標簽樣本數(shù)減少到700個時,F(xiàn)edMix-FedLos 方法的準確率會大幅下降。 圖8 給出了Fashion-MNIST 數(shù)據(jù)集流式non-IID設置下不同方法的性能比較。從圖8 可以看出,本文方法的最高收斂準確率與基線方法基本相同,并且快于基線方法10 輪達到最高收斂準確率,同時減少了一半的通信開銷。 圖8 Fashion-MNIST 數(shù)據(jù)集流式non-IID 設置下不同方法的性能比較Fig.8 Performance comparison of different methods under streaming non-IID settings on Fashion-MNIST dataset 本文針對SSFL 中標簽數(shù)據(jù)位于服務器上的場景,設計魯棒的SSFL 系統(tǒng)。使用FedMix 方法實現(xiàn)高精度半監(jiān)督聯(lián)邦學習,解決了FL 系統(tǒng)中缺少標簽數(shù)據(jù)的問題。采用基于客戶端訓練模型損失值的FedLoss 聚合方法,實現(xiàn)SSFL 系統(tǒng)在不同non-IID 設置下的穩(wěn)定收斂。實驗結(jié)果表明,在使用少量標簽數(shù)據(jù)的情況下,本文SSFL 系統(tǒng)的性能明顯優(yōu)于主流的聯(lián)邦學習系統(tǒng)。下一步將通過半監(jiān)督學習算法改進無監(jiān)督模型的訓練方法,高效利用無標簽數(shù)據(jù)提升全局模型性能。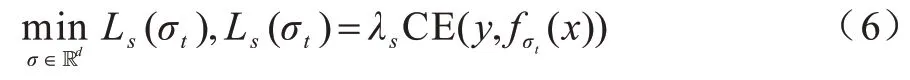



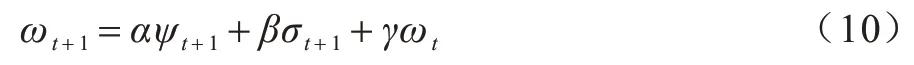

4.2 FedLoss 聚合方法

4.3 Dirchlet 數(shù)據(jù)分布函數(shù)


5 實驗驗證
5.1 實驗設置
5.2 實驗結(jié)果


6 結(jié)束語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
人大建設(2020年4期)2020-09-21 03:39:12
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
