基于主題情感聯合分析的游客畫像研究
2022-06-16 05:25:04李少波
計算機工程 2022年6期
李 琴,李少波,胡 杰
(1.貴州財經大學 大數據統計學院,貴陽 550000;2.貴州大學 機械工程學院,貴陽 550000)
0 概述
游客畫像是對游客屬性標簽化的過程,主要應用于旅游目的地的精準營銷、個性化服務、游客行為分析、輿情治理等方面,是實現智能化旅游的關鍵。酒店作為旅游經濟過程中的重要因素,與旅游經濟起著相互促進的作用。酒店是否符合現階段游客的需求成為游客衡量旅游目的地的重要因素之一。通過挖掘分析獲取不同群體的需求或喜好特點繼而推薦符合不同群體需求的酒店,是提升游客體驗和酒店運營的有效手段。現代旅游過程以社會互動和旅游信息交換為特征,其產物——游客生成文本,能夠反映游客的喜好、感知和需求信息,通過對游客生成文本進行分析,準確獲取不同群體的情感喜好等信息對旅游酒店推薦具有重要意義。
隨著深度學習的發展,以文本數據為主的自然語言處理技術異軍突起[1],在主題挖掘和情感分析等領域取得重大進展[2]。在大多數情況下,文本的主題和情感仍被割裂開來分析,然而在實際情況中,通常要求主題和情感具有相互指向性,例如“美麗的”指向具體對象如“花園”或“花園”指向情感要素如“美麗的”。如何進行主題和情感的聯合分析成為研究熱點。大量無監督主題情感分析模型應運而生,如JST 模型[3]、ASUM 模型[4]、JMTS[5]等。這類無監督主題情感模型認為詞的生成與主題和情感都相關,通過對每個句子或每個詞進行情感標簽和主題標簽采樣,以生成句子的主題和情感對。另一類無監督主題情感模型(如WLDA[6]、TSLDA[7]、JST-RR[8]等)通過引入先驗知識(如互信息、主觀性詞典、主題意見詞對、文本情感等),在獲取主題的同時提升情感檢測率。這類模型并不是完全無監督,其利用先驗知識誘導先驗,從而增強主題模型的稀疏性。這2 類模型均以隱含狄利克雷分布(Latent Dirichlet Allocation,LDA)為基礎模型,具有較強的挖掘能力。LDA 作為一種貝葉斯生成模型,主要依賴于關鍵詞詞頻信息。但是LDA 模型缺乏先驗信息的指導且僅適用于長文本的分析,采用吉布斯采樣進行后驗分布計算,當文檔數量多而主題個數較少時,LDA 模型的訓練速度相對較慢,并且需要在數學上重新推導新的推理算法進行更改。LDA 作為一種無監督模型,缺乏標簽的約束,其訓練得到的主題通常表達解釋能力較差。有監督學習利用標簽數據的正向回饋,其準確率優于無監督學習[9]。SLDA 模型[10]將元數據作為標簽(如情感評分等),以輔助推斷和預測標簽相關的主題,相對無監督的LDA,該模型具有更優的預測能力。
LDA 作為概率主題模型中簡單且經典的模型,為主題模型提供了一個標準框架,在學術界和工業界具有廣泛的研究和應用價值,但其自身的局限性卻不容忽視。隨著變分自編碼(Variational Auto-Encoders,VAEs)模型的提出,使用變分自編碼深度學習在特征提取方面(如情感、主題等)取得巨大的成 功[11-12]。VAEs 是一種深度生成模型,又稱為AEVB 算法,該模型基于變分的貝葉斯理論,將編碼器和解碼器設置為神經網絡,通過迭代優化過程學習最佳的編碼-解碼方案。結果表明[13],相比使用吉布斯采樣的LDA 主題模型,VAEs 在主題模型上的應用能夠有效挖掘主題,且更易擴展。此外,重參數化技巧RT(Reparameterization Trick)及SGVB 估計算法建立AEVB 算法的梯度反向傳播機制。RT 在技術方面的提高使得更多的分布能被應用在VAEs中,同時為VAEs 近似復雜概率模型提供更多的可能性。
研究工作表明[14-15],先驗分布的復雜度及超參數的選擇對于深度生成模型或貝葉斯神經網絡的性能具有重要意義。本文提出基于變分自編碼的有監督主題情感聯合分析模型SJST-VAE。通過先驗知識和情感標簽輔助主題的訓練和生成,利用截斷高斯模型變分參數構造適合主題挖掘過程的神經變分推斷形式,采用主題分布下的情感分類預測實現主題情感的聯合分析。
1 相關工作
變分自編碼在主題概率模型中得到廣泛應用[16]。LDA 的任何變體都需派生自定義推理算法,然而變分自編碼具有較強適應數據特征的能力,其推理方法為隱藏變量建模提供強大的架構,具有更強的可擴展性。AVITM(Autoencoding Variational Inference for Topic Models)模型[13]通過構建變分自編碼與主題模型的橋梁,降低Dirichlet 先驗和組件坍塌(類似于先驗信任的局部最優)對AEVB 算法產生的影響。針對傳統主題模型在短文本上表現較差的問題,文獻[17]利用詞向量和主題向量的點積構建詞的主題分布,并定義了詞的上下文表征以區分一詞多義的現象,提出一種利用詞向量語義關系輔助主題挖掘的嵌套變分貝葉斯的主題模型。文獻[18]提出使用Gumbel-Softmax 模型和高斯混合模型建模變分自編碼主題類別分布,解決局部最優的問題,并分析選擇不同分布模型對主題生成的影響。文獻[19]利用動態因子圖模擬主題在時間上的動態變化,基于變分自編碼構建動態的主題模型。針對傳統主題模型無法動態確定主題數量的問題,文獻[20]基于自編碼變分推斷的架構,提出一種循環神經主題模型,以發現從概念上無界限的主題。這些模型雖然根據變分自編碼易擴展的特性展現出在主題挖掘上的優勢,但是缺乏主題的情感指導或主題與情感的聯合分析。
主題情感的聯合分析是一種細粒度的意見挖掘,其目標是從文本主觀評論中獲取情感傾向的觀點或情感要素。在旅游領域中具體的實際應用尤其是旅游推薦具有重要意義。結合深度學習的思想,基于方面或目標實體的情感分類(TABSA)雖然在挖掘文本特征信息和對應情感屬性上取得較大進展,但是大多依賴于文本類別、特征屬性及對應情感類別的標注,使得實際工作面臨較大的困難。傳統的無監督主題情感模型在一定程度上解決數據標注缺乏的問題,但因計算復雜度高且時間消耗久等問題,導致模型難以擴展。變分自編碼主題模型的實現成為解決該問題的關鍵。文獻[18]基于傳統情感主題聯合模型JST,預先定義特征種子詞,通過對AVITM 模型進行擴展,實現變分自編碼的無監督情感與主題的聯合分析。但是任何無監督的模型都無法假設現實中的所有情況[10],其相較于有監督模型的準確率較低。根據當前旅游社交網站中文本評論及情感評分易于獲取的特點,本文基于AVITM 模型,以邏輯或知識表示先驗知識,利用情感監督主題的識別輔助預測情感分類,從而實現主題情感的聯合分析和酒店游客的特征畫像。
2 LDA 模型
LDA 模型由Dirichlet 先驗的主題分布得名,Dirichlet 先驗的選擇對于可解釋性主題的獲得具有重要作用。在LDA 模型中,主題被看作相關主題的詞匯分布,每個文檔被看作多個主題的分布。為生成文檔d,該過程會隨機選擇主題的分布θd,通過從主題分布中隨機選擇一個主題zd,n,從相應主題或主題的詞匯分布βk隨機選擇一個詞來生成文檔中每個可觀測詞wd,n。因此,LDA 中文檔d的生成如下:
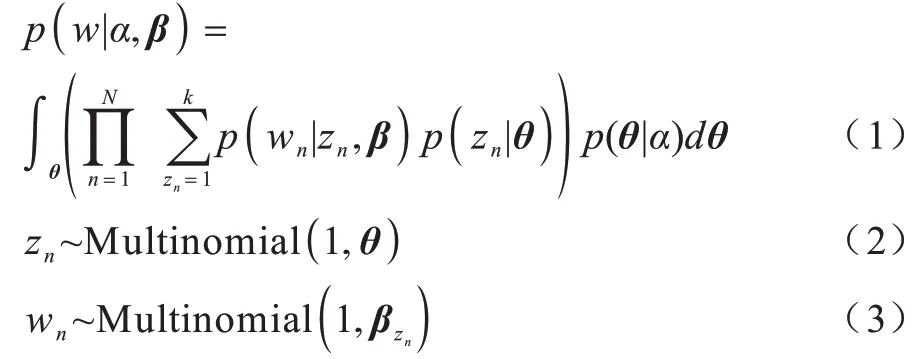
其中:α為Dirichlet 分布的超參數。在多項分布假設下,θ和β之間的耦合導致隱變量θ和z后驗分布的推理難以計算,需要借助各種近似方法。LDA 模型采用吉布斯采樣方法,即一類MCMC(Markov Chain Monte Carlo)算法,通過抽取大量樣本估計真實的后驗分布,但該方法計算復雜度高且時間消耗量大。
3 變分自編碼框架下主題分布的參數化
針對LDA 模型中后驗分布難以計算的問題,研究人員提出變分推理方法,通過優化過程尋求一種變分分布近似真實的后驗分布。MFVI(Mean-Field Variational Inference)方法是一種比較經典的變分推理方法,但是由于計算原因難以擴展到新的模型。AEVB 算法旨在以一種“黑匣子”推理方法來解決該問題,該算法利用推斷和學習使得簡單的采樣就能進行有效的近似推斷,不需要復雜的迭代推理方式(如MCMC)。
在LDA 模型中,隱變量z是離散變量,無法進行重參數化處理,通過求和運算折疊z變量,即將式(1)轉變為:
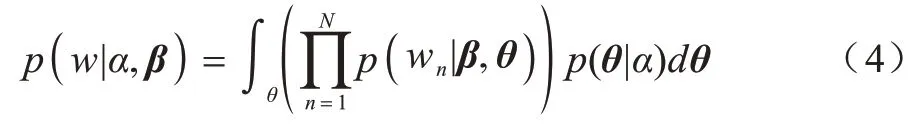
其中:wn|β,θ~Multinomial(1,βθ)。
因此,后驗分布難以計算的問題轉化為評估θ和β的分布。VAE 使用自編碼學習θ和β的分布,同時通過拉普拉斯將原始Dirichlet 先驗分布近似為變分分布。在LDA 主題模型中,主題變量的先驗θ=(θ1,θ2,…,θK)(K為主題個數)被定義為Dirichlet 分布,經過變分推理,主題變量的Dirichlet 先驗p(θ|α)通過拉普拉斯被近似為一個多元高斯分布。多元高斯分布由均值向量μ和對角協方差矩陣Σ定義,其中,所以p(θ|α)近似為q(θ)=LN(θ|μ,Σ),其中LN是邏輯正態分布。邏輯正態分布更能促進主題一致性。
通過拉普拉斯近似計算得到多元高斯分布的均值向量μ和對角協方差矩陣Σ,如式(5)和式(6)所示:
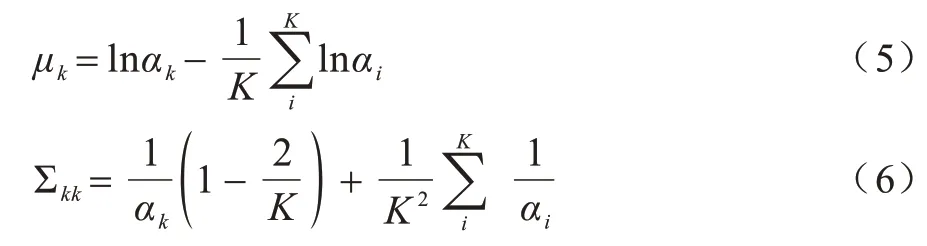
在變分自編碼框架下,將觀測數據文檔w詞序列作為輸入,將2 個推斷網絡作為前向神經網絡,其中,δ為推斷網絡的參數,即變分參數,,從而估計的值,每個網絡的輸出均為K維向量。
變分分布的構造有多種形式,高斯分布是其經典的變分分布形式。在變量原始分布未知的情況下,高斯分布可以為噪聲和不確定性建模。通過高斯先驗分布和RT 技術為變分分布建立無偏差或低方差的梯度估計器,如SGVB。
3.1 單高斯分布模型
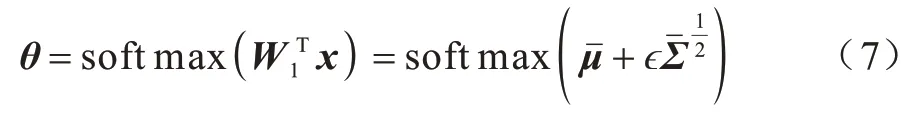
θ服從單高斯分布模型(Gaussian SoftMax,GSM),即:
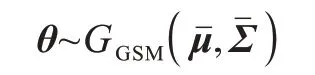
其中:W1為線性變換權重,偏差項做了省略處理。
3.2 截斷高斯模型
SB(Stick-Breaking)過程被用于主題變量Dirichlet過程的建設性定義,為其先驗提供初始關聯權重。在截斷高斯(GSB)模型構建過程中,通過逐次分割單位為1的區間順序獲取高斯先驗,其中θk表示每個分量。SB 構建過程如圖1 所示。
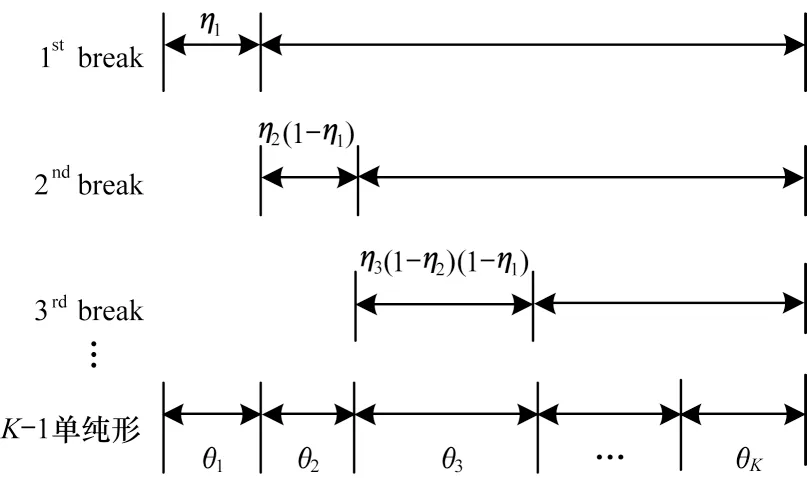
圖1 SB 構建過程Fig.1 SB construction process
設第1個類別的概率為分割比例η1,其余比例1-η1為后續的分割計算。高斯先驗的每一維計算如式(8)所示:
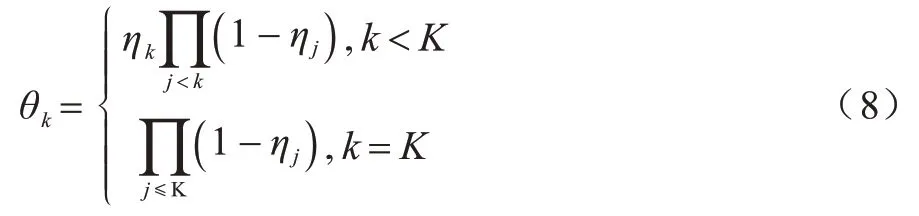
不同的K值需滿足=1。多項式概率參數的建模被轉化為二項式概率參數的對數建模。
設高斯樣本x∈RK,W2∈RK×(K-1),則,其構造過程如式(9)所示:
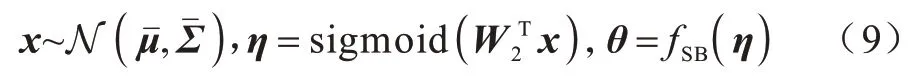
與Dirichlet 過程的SB 定義相比,高斯過程的SB為神經變分推斷提供更合適的形式。在高斯先驗的分配過程中,SB 構建過程缺乏控制力,SB 先驗可以更好地保留類別邊界,為半監督學習提供有效的正則化。同時,SB 過程能夠降低模型對主題數量變化的敏感度,更具穩定性。
4 本文模型
無監督主題模型缺乏有效先驗知識的指導或監督學習中數據的標注。針對該問題,本文基于LDA模型,引入詞頻相對主題的權重,以影響主題的先驗分布,從而指導主題的生成,同時通過情感標簽監督生成主題,利用主題特征預測情感分類,從而實現主題情感的聯合分析。本文模型SJST-VAE 以VAE 為主要架構,主要由先驗知識的指導、情感標簽的監督、變分目標損失函數的計算和主題情感的聯合分析這4 個部分組成。SJST-VAE 模型架構如圖2所示。
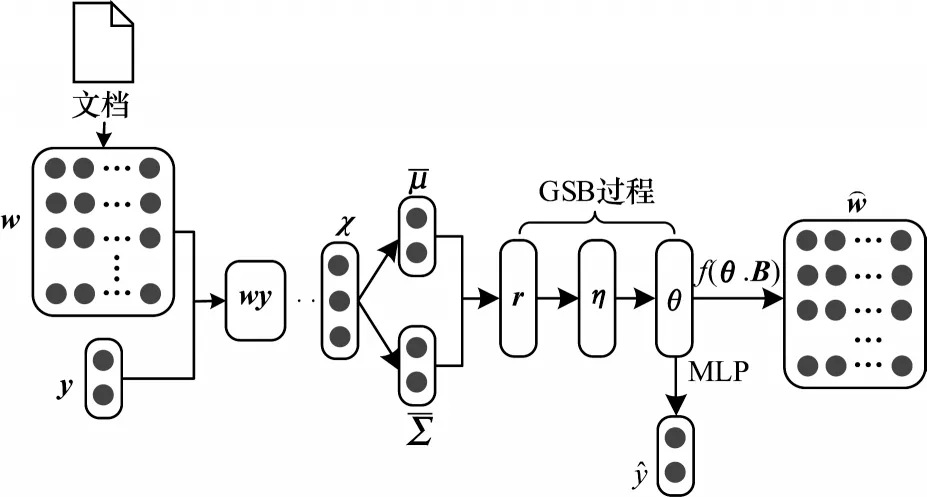
圖2 SJST-VAE 模型架構Fig.2 Framework of SJST-VAE model
4.1 先驗知識的指導
VAE 架構的優勢是為編碼網絡提供一種可以引入先驗信息的擴展方法。本文模型SJST-VAE以詞的Bagof-words 表征作為輸入,通過變分自編碼網絡獲取文檔的特征。此外,針對文本中權重過高的詞大多不能進行局部主題表示的問題,如IMDB 語料庫中,單詞“film”或“movie”在主題模型學習中往往相對不重要,本文通過弱化詞頻過高的詞,設置背景術語從而獲取相對常見的詞,以此促進主題的一致性。
假設語料由D個文檔組成,語料詞典大小為V,如圖2 所示,在變分自編碼網絡框架下,SJST-VAE 模型以文檔詞序列w作為輸入,通過2 個MLP 推斷網絡變分近似為具有對角正態先驗的文本表征r,即,如式(10)所示:

從而獲得r的近似后驗分布,如式(11)所示:

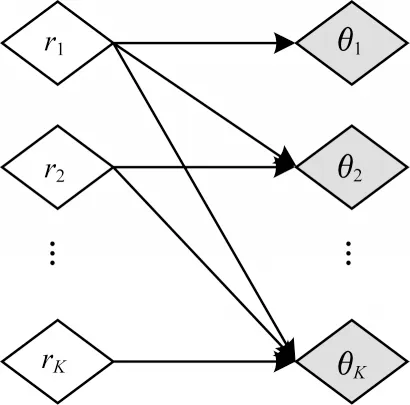
圖3 SB 映射過程Fig.3 SB mapping process
單純形θ如式(12)所示:

本文設置稀疏誘導先驗,即正態指數復合先驗,置于權重矩陣B∈RK×V(主題詞分布矩陣的初始化),使模型學習到詞頻相對主題的權重信息,同時定義背景術語d∈RV,表示詞頻中所有詞的詞頻對數值,旨在通過B與d的偏離程度將主題權重傾向于文檔中出現頻率大致相同的常見詞,而不是詞頻過高的詞。權重矩陣B的正態指數復合先驗過程如式(13)和式(14)所示:

其中:ξ>0 為指數分布率參數。重構文檔為:

整個神經網絡的損失函數如式(16)所示:

4.2 情感標簽的監督
除了能有效推斷文本主題外,本文模型SJSTVAE 還能推斷文本的潛在表達及預測文本的情感傾向,利用情感標簽對主題生成前后進行監督。生成主題后的監督是在可觀測詞的條件下,完成主題模型的變分自編碼解碼的過程,利用多層神經網絡進行訓練,將預測標簽與真實標簽的交叉熵作為損失函數,從而實現情感標簽的預測。情感預測標簽的計算如式(17)所示:

其中:fy為多層神經網絡。
在主題生成過程中,情感標簽還用于監督主題訓練過程,以促進局部主題的生成。SJST-VAE 模型在預測情感標簽時,利用one-hot 編碼表征文檔的情感標簽ey,并對編碼器網絡進行訓練,情感標簽ey被用于構建文本表征的特征,如(18)和式(19)所示:

其中:fg為多層感知器;Wx和Wy為線性權重參數。
在訓練過程中,情感類別標簽作為可觀測變量。在測試時,本文模型考慮所有可能的情感標簽向量,如正向或負向,使得文檔中所有詞概率對數和最大的標簽為所預測標簽,如式(20)所示:
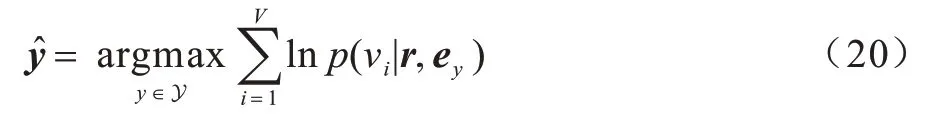
其中:vi為詞典中的詞,i={1,2,…,V}。
4.3 變分目標損失函數
與傳統變分推理類似,SJST-VAE 模型構造一個Dirichlet先驗的拉普拉斯近似,使Dirichlet分布可以近似為邏輯正態分布。本文假設Dirichlet先驗是對稱的,即所有超參數α取相同值,由式(5)和式(6)可得:

在變分自編碼架構下,本文設計高斯變分分布,以近似后驗分布qδ(r|w,ey)。模型學習的目標是使近似后驗分布盡可能接近于真實后驗分布p(r|α)。本文采用KL 散度進行相似度計算,找到能使KL 散度盡可能小的變分參數,如式(22)所示:

通過一系列計算推演,式(22)轉換為使變分下界ELBO 最大化,其變分下界如式(23)所示:
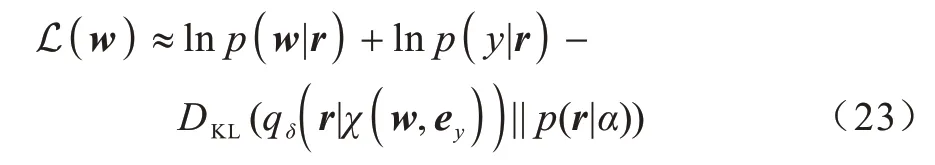
其中:KL 散度為正則項;其他部分為重構損失。KL散度如式(24)所示:
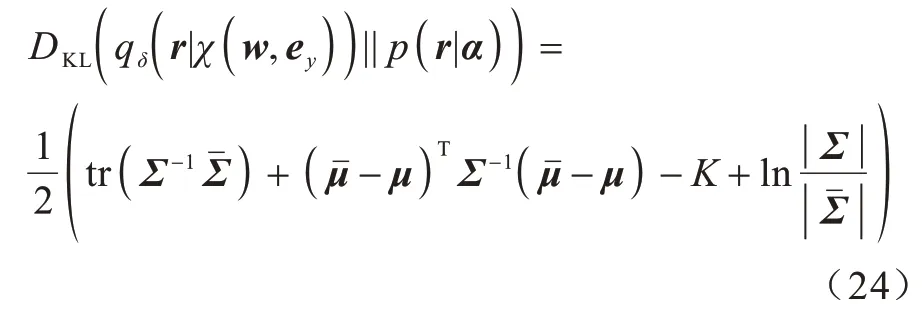
4.4 主題情感的聯合分析
SJST-VAE 模型通過變分自編碼網絡獲取各文檔的主題分布,并將其作為輸入,通過文檔的情感監督對MLP 神經網絡進行訓練,從而實現情感分類的預測。
本文假設文檔數據集有K個主題,并將只包含第k個主題的文本主題分布tk定義為除第k個分量為1 外,其余各分量均為0 的向量。因此,為獲得第k個主題的情感分布,模型以tk作為輸入向量進行情感預測,其中k=1,2,…,K,以獲取各個主題下的情感概率分布。
5 實驗結果與分析
5.1 數據集與參數設置
本文將IMDB 語料集作為評估SJST-VAE 模型的數據集,該數據集包含50 000 條電影評論,其中25 000 條負面評論和25 000 條正面評論,且訓練集25 000 條和測試集25 000 條。在數據集中所有單詞通過預處理均被轉化為字母小寫形式,并刪除了標點符號、數字及小于3 個字符和停用詞表中的所有單詞。詞典由在大多數文檔中都出現的單詞組成,大小設為2 000。在模型訓練過程中,本文使用softplus 激勵函數、Adam 優化器(參數設為0.99),學習率設為0.002,批量大小設為200,?采樣數量設為1,訓練迭代次數設為200。在測試文檔估計ELBO值時,?采樣數量設為20。
5.2 評估標準
SJST-VAE 模型是基于情感監督進行主題情感聯合分析。研究人員給出不同的衡量標準,如困惑度、相關性、稀疏度等,以客觀評價主題獲取的優劣程度。困惑度表示文檔屬于哪個主題的不確定性,困惑度越低,聚類效果越好,主題與主題的區分性越強;相關性表示模型獲取主題的top-n個詞的語義一致性,一致性越高表示主題可解釋性越好;稀疏度在一定意義上表示模型的可解釋性,因為每個主題能夠接受被描繪的詞往往是有限的,主題的詞分布矩陣越稀疏(即稀疏度越大),可解釋性越強。雖然這3 種評估標準具有一定的有效性,但其不能完全作為評估標準,有時需要直觀的主題表示進行評估。模型主題困惑度如式(25)所示:
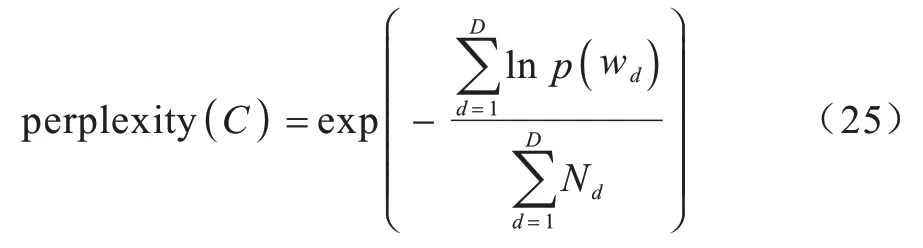
其中:C為測試語料且包含D篇文檔;Nd為每篇文檔包含詞的數量;p(wd)為文檔d中詞產生的概率。
本文采用NPMI(Normalized Pointwise Mutual Information)對文本語料主題相關性進行評估。PMI主要用于度量一些詞的共現,以此判定詞的相關性,PMI 如式(26)所示:
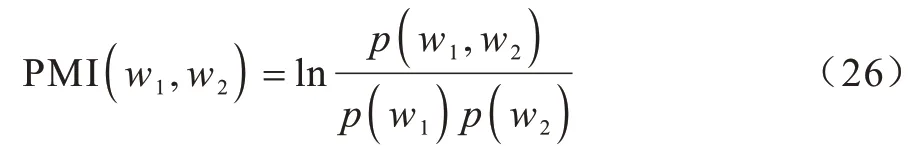
對于PMI 的正則化有多種選擇,如通過-lnp(w1)和-lnp(w2)的乘積或通過-lnp(w1,w2)正則化。本文以后者作為正則化選項,該正則化過程規范了上限和下限,具有較優的性能。因此,NPMI如式(27)所示:
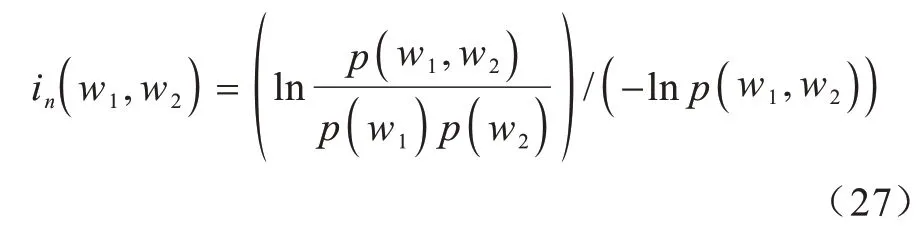
5.3 模型評估與結果分析
本文研究先驗知識和情感監督對主題獲取的影響,因此,評估分析了模型在相同實驗條件和參數設置條件下有先驗知識和無先驗知識的性能對比,以及有情感監督和無情感監督的性能對比,并驗證了在GSM 和GSB 構造下不同主題數目設置對主題分布性能的影響。為驗證本文方法的有效性,本文將SJST-VAE 模型與其他3 種基準主題模型進行對比。這3 種基準模型分別為LDA、SAGE(Sparse Additive Generative Model)[19]、NVDM(Neural Variational Document Model)[20]。
IMDB 語料的平均主題分布如圖4所示。從圖4可以看出,在GSM 過程中獲得100 個主題的平均主題分布情況大致相同,而在GSB 過程中的平均主題分布值在接近第10 個主題位置后逐漸遞減,在大概第20 個主題后遞減速度尤為明顯,直至第40 個主題后幾乎沒有分布。這是因為GSB 過程在建立混合模型時,其SB 結構隱含地假定了主題的順序,前一個主題獲得足夠的梯度來更新主題分布。同時,SB 結構的稀疏性使得尾部的主題被采樣的可能性較小,模型對于超參數(主題數目)的變化會變得不太敏感,當主題設置數目遠遠超過模型需要的數目時,GSB 過程的穩定性更強,而且更加有利于主題數目的設置。

圖4 IMDB 平均語料主題分布Fig.4 Average topics distribution of IMDB corpus
主題數為10~100 及100~500 時隨模型測試集困惑度的變化情況如圖5 所示。從圖5 可以看出,主題數從10~100 的變化過程中,GSB 過程的主題困惑度略優于GSM 過程,隨著主題數從100~500 逐漸增大,GSB 過程在主題困惑度上表現出的優勢越來越明顯,說明GSB 過程不會因主題數目變化而發生大幅波動,驗證了GSB 過程的穩定性。

圖5 主題困惑度隨主題數的變化趨勢Fig.5 Trend of topic perlexities with number of topics
現有的主題模型主要在數據集20newsgroups進行訓練,該數據集缺少情感標簽數據。因此,本文以IMDB 數據集為對象,選擇具有代表性的基準模型對主題挖掘性能進行評估。LDA 是經典的模型,幾乎所有模型都以此為基礎;SAGE 模型引入恒定背景分布的對數頻率,以防止過度擬合,即通過稀疏誘導先驗加強模型主題的稀疏性,具有較強的魯棒性;NVDM 模型首次將神經變分框架的生成模型引入到文本建模中,旨在為每個文檔提取一個連續的語義潛在變量,并應用于構建主題分類。
本文將主題數目設置為10 和50,不同基準模型的主題困惑度、相關性和稀疏度的對比結果如表1 所示。
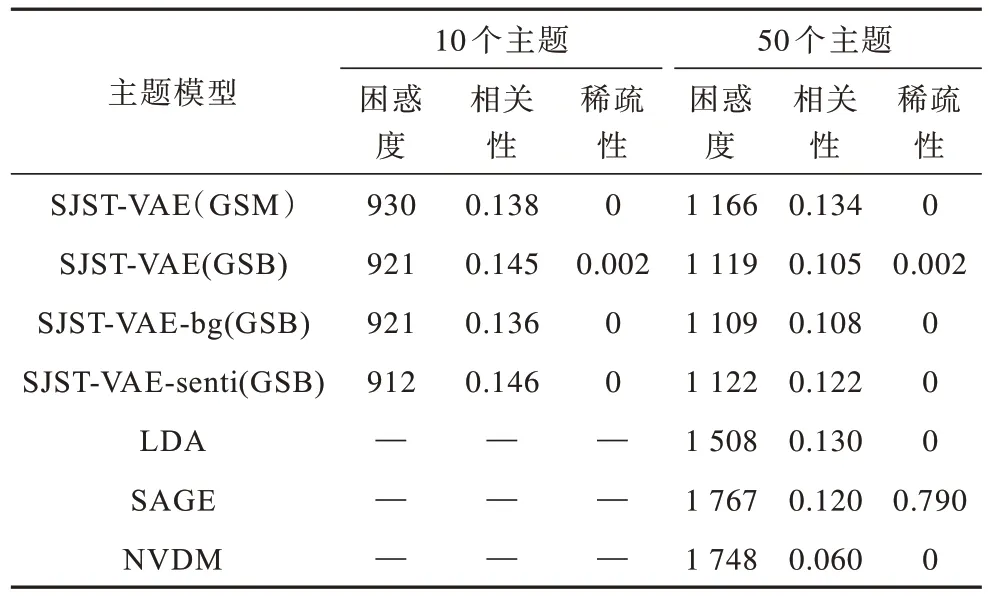
表1 不同模型的主題評估指標Table 1 Topic evaluation indicators of different models
相比基準模型,SJST-VAE 模型在主題困惑度上具有較強的優勢;SJST-VAE 模型的主題相關性低于LDA 和SAGE 模型,但優于同是變分自編碼框架的NVDM 模型;SAGE 模型的主題稀疏性仍占有絕對優勢,SJST-VAE 模型相對于其他模型略有改進。同時,本文對比SJST-VAE 模型在背景術語缺失(SJSTVAE-bg)和情感監督缺失(SJST-VAE-senti)以及GSM 和GSB 過程下的主題性能評估。在主題數目設置為10 和50 時,GSB 過程中SJST-VAE 模型、SJST-VAE-bg 模型、SJST-VAE-senti 模型的主題困惑度均優于GSM 過程中的SJST-VAE 模型,說明GSB過程在主題困惑度的表現上具有絕對優勢。當主題數目設置為50 時,SJST-VAE 模型的GSM 過程的相關性具有一定優勢。GSB 過程的SJST-VAE 模型相對于SJST-VAE-bg 模型和SJST-VAE-senti 模型的稀疏性略有提高,說明SJST-VAE 模型具有較強的主題可解釋性。由于高頻背景術語的缺失以及情感詞的加入使得模型在主題數目增多的情況下,發生主題一致性降低的情況。其原因為隨著主題數目增多時,無明顯意義主題詞出現的概率會增大,而主題一致性的計算基于詞的共現,高頻詞的缺失和情感詞的加入導致詞共現率下降。
有情感聯合和無情感聯合這2 種主題樣例對比如表2 所示。本文在主題數目設置為5 的條件下以中文形式分別列舉這2 種方式主題的前8 個詞。

表2 IMDB 數據集主題樣例Table 2 Topic samples of IMDB dataset
從表2 可以看出,有情感聯合的主題表示樣例大致可以將電影語料的主題概括為色情、犯罪、紀錄、動畫、恐怖5 種類型,而無情感聯合則稍顯雜燴,較難概況其主題類型。該過程說明有情感聯合可以學習更稀疏、更有意義的表示,其表達的主題關聯強,其他主題關聯弱的關鍵詞較少,具有較優的表達主題語義的能力,主題解釋性更強。相比無情感聯合的主題表示,有情感聯合的主題表示包含更多的情感詞,有利于主題情感特征的獲取,具有重要的實際意義。由于引入背景術語先驗知識,這2 種主題表示樣例中均減少了大量的“movie”、“film”等高頻無顯著主題表達意義的詞的出現概率。
本文將構建SJST-VAE 模型的文本語料的情感預測和主題的情感分布,利用生成的文檔主題表征進行情感分類,通過單個主題的表征進行情感分布預測。由于本文主要側重于挖掘主題的性能,因此不對情感分類準確率與其他模型進行對比。本文分別對10~100 個主題數目進行模型訓練,獲得在不同主題數目設置條件下的情感分類準確率,并累計計算5 次情感預測準確率總和并取平均值,SJST-VAE模型情感預測準確率如圖6 所示。
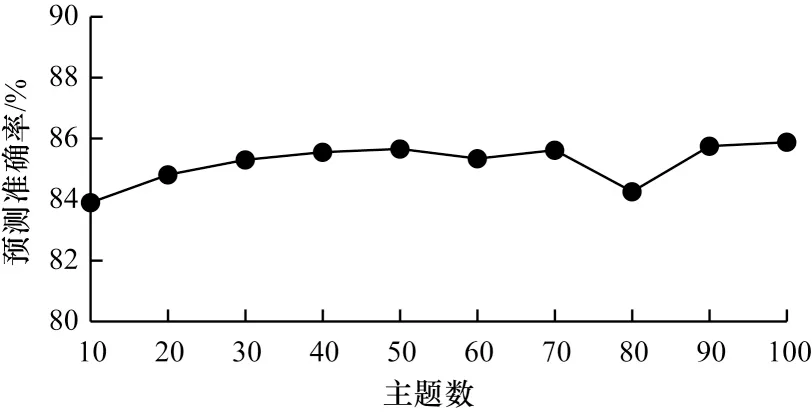
圖6 SJST-VAE 模型情感預測準確率Fig.6 Sentiment prediction accuracy of SJST-VAE model
SJST-VAE 模型在低維度文檔表達條件下,仍具有較高的情感分類準確率,情感分類準確率并未隨主題數增加而大幅波動,具有較強的穩定性。由于電影評論涉及較多情節內容,且其中包含的大量情感詞不具有明確的實際褒貶意義,因此本文將在第6 節的旅游具體應用中重點分析主題的情感分布過程,以及其如何用于指導主題的情感特征。
6 基于SJST-VAE 模型的酒店用戶畫像構建
本文選擇一組酒店評論文本集作為分析數據集[21],為驗證SJST-VAE 模型在旅游推薦或游客群體畫像中的實用性。該數據集中所有評論均來源于TripAdvisor.com 的英國用戶評價且每個評論文本均標注了情感極性,并區分了不同酒店級別和男女性別。據調查顯示[22],在較高星級酒店的選擇上,男性和女性群體分別表現出不同的情感偏好和特征。通過挖掘分析獲取不同群體的需求或喜好特點,進而推薦符合不同群體需求的酒店,成為提升游客體驗和酒店運營的一個有效手段。
本文選取三星和四星這2 種不同類型的酒店評論各6 400 條,每種類型酒店均包含男女性評論各3 200 條,并以此作為分析對象。整個數據集被劃分為4 個不同的特征數據集,如圖7 所示。同時,本文將各數據集的80%作為訓練集和20%作為測試集(正負評論數量均衡)。在訓練過程中,本文設置詞典大小為1 000,批量大小設為50。主題個數設為10,既符合旅游酒店屬性先驗知識,也便于更細粒度了解用戶需求和情感。

圖7 不同特征數據集的劃分Fig.7 Division of different feature datasets
本文針對4 種不同屬性的酒店評論數據集分別進行主題情感的聯合分析。SJST-VAE 模型在4 種不同屬性的酒店評論數據集中情感預測準確率對比如圖8 所示。SJST-VAE 模型在訓練集和測試集的情感預測準確率均在90%以上,具有較高的準確率,驗證了SJST-VAE 模型在挖掘酒店用戶評論特征進而獲取情感預測的可行性。

圖8 在不同數據集上SJST-VAE 模型的情感預測準確率對比Fig.8 Sentiment prediction accuracy comparison of SJST-VAE model on different datasets
SJST-VAE 模型分別對英國三星酒店男性和女性評論提取特征對比如表3、表4 所示。
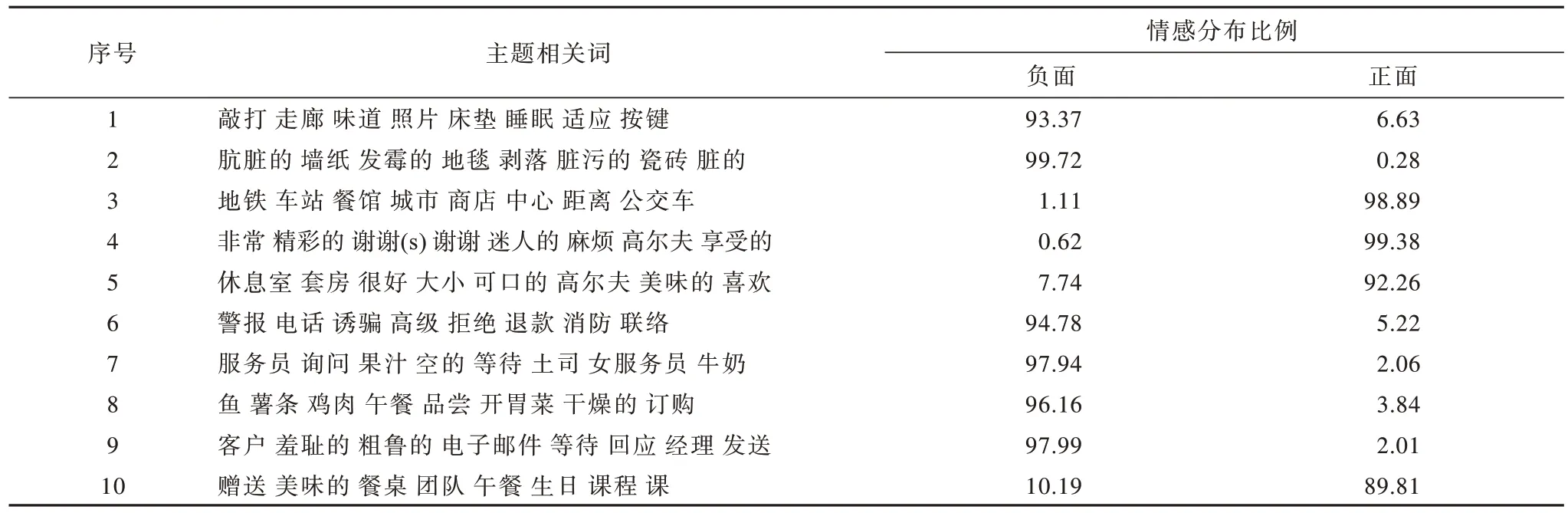
表3 三星酒店男性評論特征Table 3 Feature of male reviews in Samsung hotels %

表4 三星酒店女性評論特征Table 4 Feature of female reviews in Samsung hotels %
男性用戶和女性用戶均在房間噪音、內飾環境、餐飲、服務質量(包括入住辦理、客房服務)上表現出負面傾向,如在內飾環境上的情感特征有“骯臟的”“發霉的”等,在服務質量上的情感特征有“羞恥的”“粗魯的”“令人震驚的”等。在交通區位、休閑娛樂上,男性和女性均表現出一定的正面傾向,如交通區位上的情感特征有“便捷的”,休閑娛樂上的情感特征有“精彩的”“享受的”“謝謝”等。
女性的負面主題(7 個)多于男性的負面主題(6 個),可以推斷女性在三星酒店消費中可能比男性更為苛刻。相較于男性,女性更加注重細節,如房間內飾環境關鍵詞上,女性增加了窗簾、家具的關注,在交通區位關鍵詞上,女性增加了步行、停車、出租車、購物的關注,而男性則只是多了餐館的關注。另外,在酒店休閑娛樂選擇上,男女性也表現出不同的特點,如男性的休閑娛樂相關詞有高爾夫等,女性的休閑娛樂相關詞有水療、游泳池、花園等。
SJST-VAE 模型對英國四星酒店男性用戶和女性用戶評論提取的特征如表5、表6 所示。

表5 四星酒店男性評論特征Table 5 Feature of male reviews in four stars hotels %

表6 四星酒店女性評論特征Table 6 Feature of female reviews in four stars hotels %
與三星酒店類似,男女性用戶同樣在房間噪音、內飾環境、餐飲、服務質量上表現出負面傾向,如在房間噪音上的情感特征有“打擾”“噪音”等,在內飾環境上的情感特征有“磨損的”“潮濕的”“破碎的”“臟的”等,在服務質量上的情感特征有“封閉的”“慢”“差”等。在交通區位、休閑娛樂、配套服務(如婚禮)上,男性女性均表現出一定的正面傾向,如交通區位上的情感特征有“便捷的”,休閑娛樂上的情感特征有“享受的”“宜人的”“精彩的”“喜歡”等。
男性關注的負面主題(7 個)多于女性的負面(4 個),可以推測四星酒店男性用戶較三星酒店男性用戶要求有所提高。在餐飲關鍵詞上,男性多關注雞肉、牛排,而女性更偏向于甜點如蛋糕、奶油和茶等。在房間內飾環境關鍵詞上,男女性用戶都關注了地毯、墻,男性相較于女性多了天花板、窗簾、衣柜、廁所的關注,女性則多了床墊的關注。在交通區位關鍵詞上,男女性都關注了購物,男性較女性多了酒吧的關注,女性較男性則多了步行的關注。在休閑娛樂上,男性用戶評論的關鍵詞有海灘、海、美味、桑拿、游泳池等,女性用戶評論的關鍵詞有護理、蒸汽、水療、按摩、海、花園等。
通過以上分析,酒店運營者可以從男性和女性用戶在不同星級酒店消費過程中所關注的內容和相應感受,獲取男性女性用戶的不同特征,進而有針對性地從客戶偏好層次上進行酒店或房間的推薦。通過對男性女性用戶所表現出的負面主題和情感特點進行分析,以促使酒店管理者發現內部不足進而提出改進措施。相對主題和情感的割裂分析,針對主題情感分布的挖掘更具有實際應用價值。
SJST-VAE 模型是基于正負分布均衡的酒店評論數據集,但是表3~表6 所呈現出的用戶負面主題卻明顯大于正面主題,這或許是由于用戶的表達習慣所決定的。在評價事物時,負面信息的可診斷性要強于正面信息,消費者會賦予負面信息更高的權重或注意力。對于用戶是否習慣于在負面主題的表達更加具象,而在正面主題的表達更加籠統如“太美了、太舒服了、非常享受等”,從而導致模型挖掘到的負面主題方面多于正面,還需要后續大量的實驗進行佐證。
7 結束語
為充分捕捉用戶細粒度的意見,本文構建基于變分自編碼的神經網絡訓練模型SJST-VAE。利用先驗知識和情感標簽輔助主題的訓練和生成,基于截斷高斯模型,構造更適合Dirichlet 過程的神經變分推斷形式,其中截斷高斯模型中的截斷結構能夠有效地捕獲離散數據中的相關性,適用于主題分類數據的分析。實驗結果證明,SJST-VAE 模型能夠利用主題分布實現情感分類的預測。酒店運營者通過SJST-VAE 模型獲取用戶群體的情感偏好或輿情報告,有助于制定詳實可靠的改進措施。下一步將把本文模型應用在旅游領域的精準推薦系統中,以實現在不同應用場景下信息的融合與擴展。
