深度學習應用于遮擋目標檢測算法綜述
2022-06-17 07:10:30孫方偉李承陽謝永強李忠博楊才東
計算機與生活 2022年6期
孫方偉,李承陽,2,謝永強+,李忠博,楊才東,齊 錦
1.軍事科學院 系統工程研究院,北京 100141
2.北京大學 信息科學技術學院,北京 100871
目標檢測是一個包含目標定位和目標分類的多任務學習問題。2014年,R-CNN(regions with convolutional neural network features)將PASCAL VOC 2012數據集上的驗證指標mAP(mean average precision)大幅度提升了30 個百分點,成功地將深度學習應用到目標檢測領域。此后,研究者們又相繼提出了一系列優秀的模型來提高目標檢測的性能,并使得深度卷積神經網絡在該領域成為占據主導地位的網絡架構,這些網絡架構按照生成建議框的方式不同可以分為兩類:單階段檢測器和兩階段檢測器。單階段檢測器不會單獨生成一支用于產生候選區域的區域建議網絡(region proposal network,RPN),所有的任務都視為一個回歸問題融合在一個網絡中解決,代表性的單階段檢測器有SSD(single shot multi-box detector)、YOLO(you only look once)、RetinaNet等。而兩階段檢測器先利用RPN 生成候選區域(或者稱為“感興趣區域”,region of interest,RoI),然后使用卷積神經網絡對每個候選區域進行分類,代表性的兩階段檢測器除了R-CNN,還有SPP-Net(spatial pyramid pooling net)、Fast R-CNN、Faster R-CNN、R-FCN(region-based fully convolutional network)、Mask R-CNN等。一般情況下,單目標檢測器在檢測速度上具有優勢,而兩階段檢測器在檢測準確度上具有優勢。
雖然深度學習促進了目標檢測的發展,但是在現實場景中,由于遮擋的存在,使得目標檢測仍然是一項具有挑戰性的任務。人類視覺系統可以使人類能夠在物體部分信息被遮擋或者丟失的情況下,也能通過場景中存在的輪廓來延續和推斷,以此來判斷物體的屬性。然而,基于深度學習的計算機視覺系統完成遮擋物體的有效檢測還很困難。為了應對遮擋問題,目前已經有多篇論文提出了遮擋檢測優化算法。在最近的文獻中,Chen 等人針對行人檢測中的遮擋問題進行了分析,Saleh 等人針對戶外和室內場景中一般目標檢測中的遮擋處理方法進行了簡要概述,但是都沒有涉及對基于深度學習的遮擋目標檢測算法進行系統性的總結歸納。考慮到遮擋問題在實際生活場景中的普遍性以及處理該問題的重要性,本文將基于深度學習的遮擋檢測優化算法分為目標結構、損失函數、非極大值抑制算法和部分語義四個改進方向,并以此展開對各遮擋檢測算法進行歸納分析。另外,本文的工作只針對靜止圖像的目標檢測,運動視頻以及3D 圖像等領域不在討論范圍。
1 問題與挑戰
遮擋是目標檢測中常見的問題,對其有效解決在行人檢測、目標跟蹤、人臉識別、立體成像、自動駕駛、汽車檢測等方面有重要價值。
根據目標的遮擋程度,遮擋可以分為無遮擋(0%)、輕度遮擋(1%~10%)和部分遮擋(10%~35%)、嚴重遮擋(35%~80%)和完全遮擋(≥80%)。由于輕度遮擋和部分遮擋在數據集中占據的比例最高,相比于整體數據集能夠更具代表性,通常將二者合并稱為一般遮擋(1%~35%)進行研究。目前的研究將不同遮擋程度作為條件來綜合評估檢測器的性能;根據遮擋物體與被遮擋物體之間的關系,遮擋可以分為待檢測的目標之間相互遮擋和待檢測的目標被非目標物體遮擋,前一種遮擋情況由于檢測器能夠在訓練樣本中學習到所有目標物體的特征,在樣本充足的情況下,優化檢測的方式比較多,而后一種遮擋情況由于缺乏遮擋物體的標注信息,對非目標的處理比較困難。
處理遮擋問題的困難在于:(1)由于數據集和遮擋復雜性的影響,分類器無法學習所有的遮擋情況,Fawzi和Frossard驗證了在部分遮擋下,深度卷積神經網絡不具有魯棒性;(2)遮擋干擾了特征提取,相互遮擋的兩個目標可能具有非常相似的特性,導致檢測器無法準確區分進行預測;(3)遮擋時由于預測框之間可能會嚴重重疊,因此不同目標的預測框可能被非極大值抑制(non-maximum suppression,NMS)算法看作一個目標的預測而錯誤地抑制,造成漏檢的發生。
2 遮擋數據集
隨著深度神經網絡在目標檢測領域的應用,數據集的好壞很大程度上影響著檢測器的性能和泛化能力。通用的目標檢測常用數據集包括PASCAL VOC、MS-COCO、ImageNet和Open Images等。這些常用的數據集已經廣泛應用到評估各種檢測算法的有效性中。但是這些通用數據集幾乎不具備遮擋條件,對遮擋檢測算法的適用性較低,無法準確評估算法的性能。因此,針對遮擋場景還構造了特定的遮擋數據集,較為常用的有KITTI 數據集、Caltech數據集、CityPersons 數據集、VehicleOcclusion 數據集以及CrowdHuman 數據集等。
KITTI數據集是目前國際上最大的自動駕駛場景的測評數據集,由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創建。KITTI 數據集由7 481張訓練圖片和7 518 張測試圖片組成,包含市區、鄉村和高速公路等場景采集的真實圖片,有80 256 個標記對象,包括行人、汽車、自行車和特定遮擋的注釋。每張圖片中最多包含15 輛車和30 個行人,還有各種程度的遮擋。
Caltech 行人數據集是Dollar等人提出的一個大型行人檢測數據集,其包含了25 萬幀分辨率為600×480 像素的圖像序列,這些圖像主要拍攝于城市環境中。在Caltech 數據集中,一共對350 000 個邊界框和2 300 個獨立行人進行了注釋,包括邊界框和詳細的遮擋標簽之間的對應關系。
CityPersons 數據集建立在語義分割數據集Cityscapes 的基礎上,是目前較為常用的行人檢測數據集。該數據集中的圖像場景涵蓋了德國18 個不同城市的3 個不同季節和各種天氣,其中包含2 975 張圖片用于訓練,500 張圖片用于驗證,以及1 525 張圖片用于測試。數據集對大約35 000 個行人目標進行了邊界框標注和可見部分標注。
VehicleOcclusion數據集是在VehicleSemanticPart數據集的基礎上合成的遮擋數據集,是一個關于飛機、自行車、公交車、汽車、摩托車和火車六種類型車輛的數據集,包含4 549 張訓練圖像和4 507 張測試圖像。在VehicleOcclusion 數據集中,作為目標的車輛隨機被2~4 個非目標物體遮擋,并且遮擋比例受到約束。同時,VehicleOcclusion 數據集對遮擋信息進行了準確注釋,如遮擋物的類別和遮擋物的數量。
CrowdHuman 數據集是曠視科技發布的用于行人檢測的數據集,圖片數據大多來自于網絡。該數據集中包含15 000 張圖片用于訓練,4 370 張圖片用于驗證,以及5 000 張圖片用于測試,每張圖片中大約包含23 個人并存在各種各樣的遮擋。另外,CrowdHuman 數據集對每個人類目標都分別對其頭部、人體可見區域和人體全身進行邊界框注釋。
除了前面介紹的幾種遮擋數據集,研究者們還提出了其他的遮擋數據集,例如PETS、DYCE 數據集、TUT 數據集、BigBird數據集等,但是并未被廣泛使用。為了生成遮擋圖像,除了在真實環境中采樣,還有的工作聚焦在使用計算機合成,例如Wang 等人使用生成對抗網絡(generative adversarial networks,GAN)。表1 展示了部分遮擋檢測數據集的有關信息和使用場景。
3 遮擋目標檢測算法
從目標檢測任務來看,處理遮擋問題的一個直接方法是直接訓練一個應對遮擋情況的網絡模型,但這種做法是極其困難的,因為目標的遮擋情況是極其復雜的,這也就導致難以收集一個涵蓋眾多遮擋情況的數據集。為此,有研究者通過數據增強的方式來提高現有遮擋數據集的質量。除了進行數據增強,當前遮擋目標檢測算法主要包括兩種類別:一個是改進基于整體特征的檢測算法,另一個是改進基于部分語義的檢測算法。二者的區別在于利用的輸入圖像特征不同,前者對輸入圖像特征提取后的特征圖進行整體分析,這種方式不會丟棄特征信息,可以對特征進行充分利用;而后者對神經網絡的中間層特征信息進行局部聚類分析,丟棄掉不具有語義部分的信息,這種方式可以提高算法的魯棒性,降低遮擋產生的噪聲影響。圖1 展示了本章所介紹算法的總體分類。
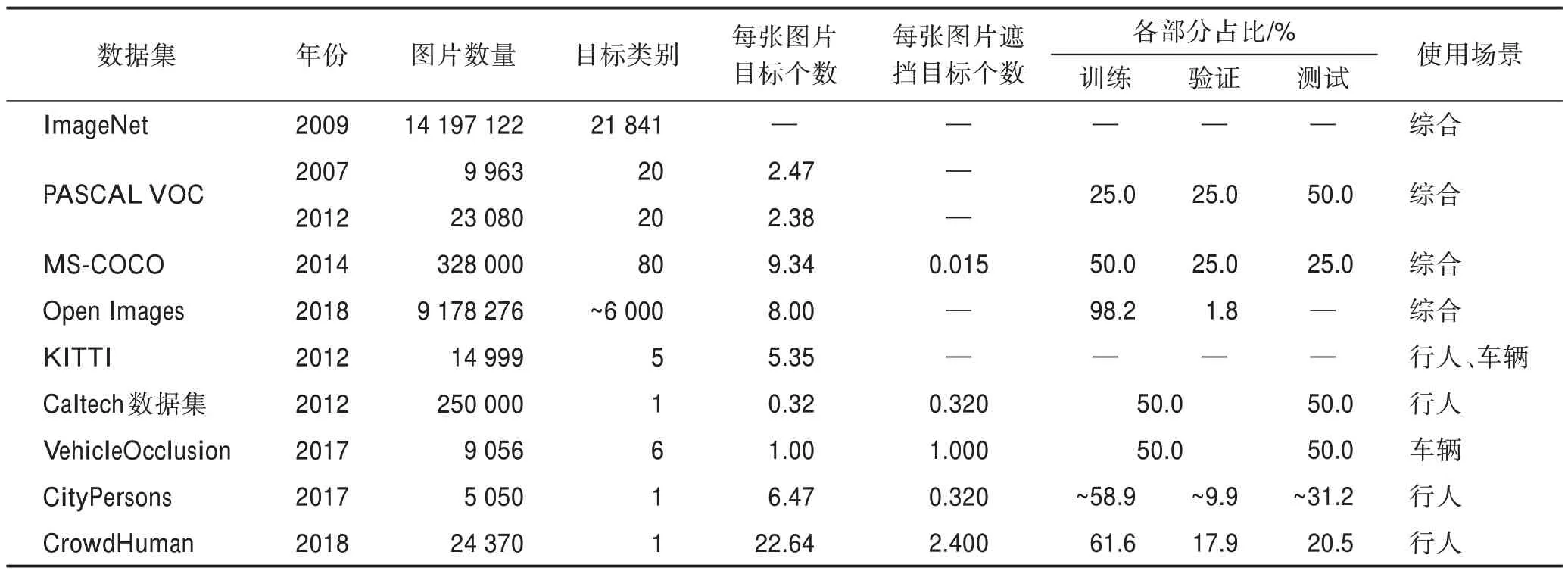
表1 遮擋目標檢測數據集Table 1 Datasets of occlusion object detection
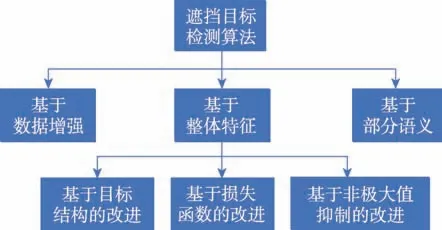
圖1 算法分類Fig.1 Algorithm classification
3.1 基于數據增強的檢測算法
Devries和Taylor為了防止卷積神經網絡容易過擬合,導致對遮擋的適應性很差,他們提出了一種正則化技術來進行數據增強,稱之為“Cutout”。Cutout類似于Dropout,都是丟棄一部分的特征來增強神經網絡的魯棒性。區別在于,Cutout是在網絡的輸入階段丟棄而不是在中間層丟棄,這種方法使輸入圖像刪除的特征可以在后續特征圖中刪除,而Dropout可能使得隨機刪除的特征仍然存在于其他維的特征圖中。
Cutout和Dropout刪除特征的方式是通過覆蓋黑色像素或者隨機噪聲來去除訓練圖像上的像素信息。Yun 等人認為這種刪除方式會導致信息丟失和訓練中的效率低下。為此,他們提出了一種新的正則化方式,稱為“CutMix”。CutMix 的策略是從訓練圖像之間剪切和粘貼遮擋塊來進行圖像增強并且將目標區域也按比例混合到合并圖像中,這樣在訓練過程中可以避免無信息像素的消極影響,使訓練更加有效。通過實驗驗證,這種正則化方式要優于Cutout。
類似的,在進行行人重識別任務中,為了應對行人遮擋情況,厙向陽等人提出了隨機擦除算法,通過一個概率矩陣來覆蓋原圖像并對覆蓋區域進行隨機像素賦值。
數據增強通過在原始圖像中添加噪聲來模擬遮擋情形,使得神經網絡能夠學習到主要的特征信息,降低遮擋情況下不相關特征信息的影響,從而提高網絡模型對遮擋圖像的魯棒性,防止過擬合。這種方法雖然可以在一定程度上解決遮擋問題,但是并不符合真實環境中的遮擋情況,因此,大多數的遮擋檢測算法關注于遮擋檢測算法本身的結構優化。
3.2 基于整體特征的檢測算法
對通用目標檢測算法的改進是當前研究的主流方向,雖然改進的角度有所不同,但是其都是利用特征提取后的特征圖進行整體分析,使得最終的預測框盡可能地靠近目標真實的邊界框。目前基于整體特征的檢測算法可以分為三個方向:基于目標結構的改進,基于損失函數的改進,基于非極大值抑制算法的改進。
神經網絡的核心在于獲取的特征信息,當圖像特征信息被干擾時,神經網絡無法正確處理干擾下的特征,導致卷積神經網絡的魯棒性較差。遮擋條件下,目標特征信息缺失,使得最先進的深度網絡模型應用在遮擋數據集上時,效果會比無遮擋情況顯著下降。為了應對遮擋情況,根據遮擋目標的結構特征,利用先驗知識和目標可見部分結構信息設計檢測器來提高遮擋檢測性能是一種可行的解決方案。
(1)部件檢測器
Tian 等人針對遮擋行人提出了由部分檢測器組成的DeepParts 模型。該模型將人體劃分成六部分,并對應定義了45 個部分原型來分別訓練卷積網絡部件檢測器,然后通過互補的部件檢測器中的最高得分來推斷整個行人。部件檢測器作為整體的組成部分,在處理遮擋問題時可以有效利用可見部分的結構信息,但是DeepParts 是單獨訓練各個部件檢測器,忽略了部分之間的相關性,并且部件檢測器所消耗的計算資源隨著定義的部件檢測器數量線性增加。
為了解決單獨訓練部件檢測器的不相關性,Zhou等人提出了多標簽學習方法來聯合學習部件檢測器。對于每個部件檢測器將該部分存在的整體圖像作為訓練數據;為了避免某些部件檢測器因為遮擋產生的噪聲分數,聯合學習將20 個部件檢測器中15個最高得分進行平均化處理作為最終的整體分數。這種聯合學習的方式有效提高了部件檢測器的檢測精度,但是不能擺脫單獨訓練部件檢測器所需要的大量計算資源。
為此,不同于單獨訓練部件檢測器,Zhang 等人將目標的結構信息集成到一個網絡中,提出了ORCNN(occlusion-aware R-CNN)網絡。其在Faster RCNN 的基礎上進行改進,設計了部分遮擋感知區域(part occlusion-aware region of interest,PORoI)池 化單元來代替RoI 池化層,將人體的先驗結構信息和可見性預測融合到檢測器的Fast R-CNN 模塊中來估計每個部分的遮擋狀態。PORoI 池化單元通過先驗知識將行人劃分成五部分,將各部分的特征信息進行融合,具體網絡結構如圖2 所示。由于OR-CNN 的所有網絡單元都是集成在一個網絡當中,能夠進行端到端的預測,因此在檢測速度上會優于單獨訓練各個部分檢測器。
區域全卷積網絡(R-FCN)的局部響應特性通過將目標劃分成多個部件進行檢測,對遮擋情況有良好的適應性,但是失去了對全局特征的判斷。Zhu 等人在R-FCN 的位置敏感區域(position-sensitive RoI,PSRoI)池化的基礎上增加了RoI 池化,提出了CoupleNet。該網絡將PSRoI 對目標的局部響應特性和RoI 對目標的全局響應特性相結合,提升了特征信息的表達能力,如圖3。而Liu 等人則在R-FCN 基礎上增加了多層特征提取網絡,將每一層的特征信息進行融合,在保證網絡能夠處理遮擋問題的同時,使尺度變化較大目標尤其是小目標的檢測得到提升。
(2)頭-身聯合檢測
除了將目標按照結構進行全部部件檢測,考慮到正常情況下,行人檢測的特殊性在于被遮擋的部分通常位于人體的下半部分,而人頭是最為常見的可見區域,因此頭部信息提供了一個很好的線索來檢索全身。但是問題的關鍵在于,如何將頭部和身體進行可靠的聯系。Chi 等人提出了JointDet 網絡來進行頭部和人體的聯合檢測,如圖4。其動機在于:①單獨的頭部檢測往往會產生大量的假陽性;②單純的人體檢測使得檢測其性能大幅下降。因此,將二者聯合檢測既能抑制頭部檢測的假陽性,又能提高人體檢測的性能。JointDet 先從RPN 直接得到頭部建議框,然后通過統計規律得到頭部和身體的比例來產生人體建議框,兩種建議框通過關系組合模塊(relation discriminating module,RDM)來完成最終的預測。
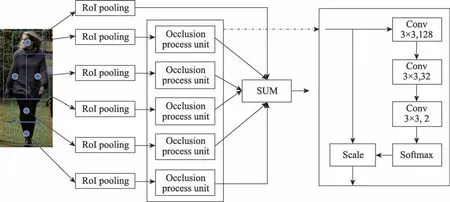
圖2 PORoI和遮擋處理單元結構圖Fig.2 Architecture of PORoI and occlusion process unit
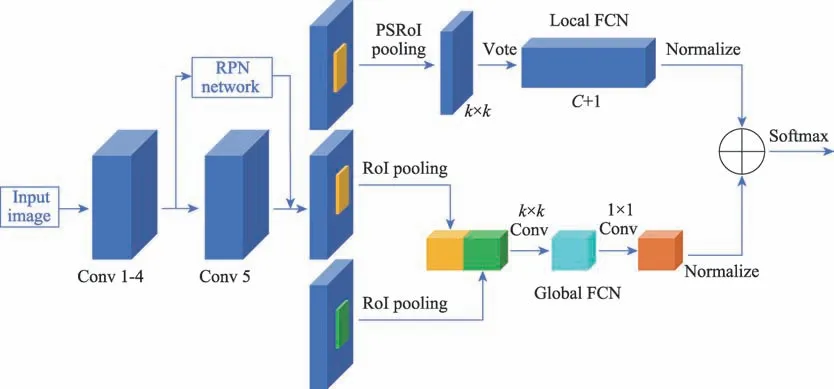
圖3 CoupleNet模型結構Fig.3 Architecture of CoupleNet
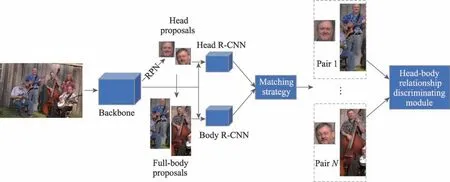
圖4 JointDet網絡結構Fig.4 Network structure of JointDet
JointDet采用的頭部和身體聯合檢測策略雖然能夠有效提高遮擋人群的檢測性能,但是其缺點也是顯而易見的:受頭部和身體通過統計比例進行組合策略的影響,雖然這種策略簡單易實現,但是JointDet所能適用的范圍過于狹窄,只能檢測正常的站立行人,如果行人發生姿態變化,就會大幅度影響JointDet的性能。
Zhang 等人采用了另一種頭部和身體的組合策略,提出了雙錨框網絡(double anchor R-CNN,DARCNN)。為了充分利用頭部檢測的高召回率,DARCNN 不通過統計比例來確定頭部和身體的組合關系,而是從RPN 中生成頭部或者身體建議框后,再從每個建議框強制回歸出另一個建議框,這樣就形成了頭-身組合,在對融合特征進行分類定位后通過設置的非極大值抑制算法完成最終的預測,如圖5。相對于JointDet,DA-RCNN 由于頭部和身體的組合過程使用回歸的方式涉及到了更多的場景,因此具有更強的適應性,但是會占用更多的計算資源。另外,頭-身聯合檢測需要數據集對目標的頭部和身體分別進行標注,而現有的公共遮擋數據集大多數未對頭部進行單獨標注,因此需要后續的相關工作來提供更加可靠的數據集。
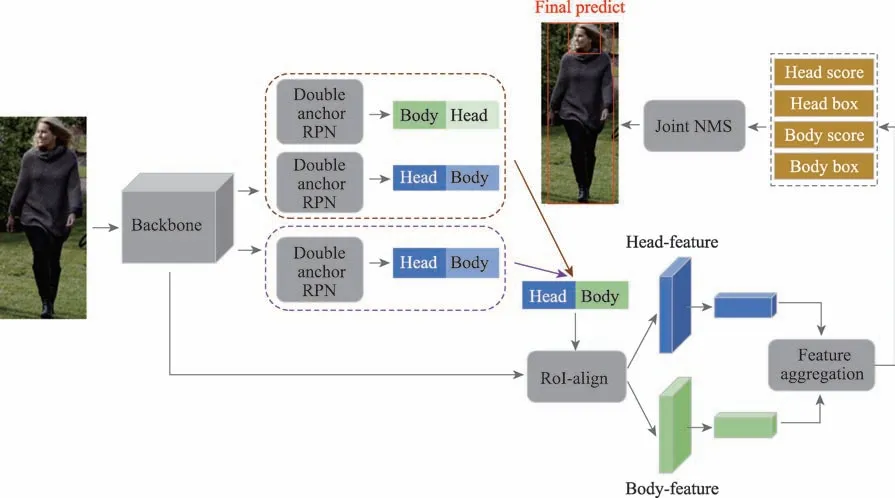
圖5 DA-RCNN 結構圖Fig.5 Network structure of DA-RCNN
(3)多目標檢測
除了通過目標結構對目標進行分解檢測,Chu 等人考慮到在遮擋條件下目標相互重疊,如果一個建議框對應于任何一個對象,那它很可能會與所有其他目標重疊。針對一個建議框預測一個目標的局限性,他們在FPN和RoI-Align為網絡框架的基礎上,增加了EMD(earth mover's distance)Loss、Set NMS和Refinement Module 模塊,提出了一個建議框預測多個目標的網絡模型CrowdDet,如圖6。圖中EMD Loss 是一個包含分類損失和定位損失的多任務損失,使建議框的多個預測對應最優的目標;Set NMS是針對多實例預測方法提出的一種避免不同建議框之間重復預測的非極大值抑制優化方法;Refinement Module 是為了降低多目標預測的每個建議框都預測一組實例而產生誤報的風險,將預測框與特征信息相結合,進行第二輪預測來優化最終的預測結果。通過實驗驗證,只有將多實例預測和Set-NMS 結合使用,才能顯著提高擁擠場景中的人群檢測精度。CrowdDet 打破了一對一的傳統檢測模式,提供了一種新的檢測思路,但是如何為每個建議框設置一個合理的檢測數量并沒有合理解決,后續的工作應該使得該算法能夠自適應地確定檢測數量:在密集遮擋場景中應該實行一對多的檢測策略,而在正常場景中應該遵循一對一的傳統檢測策略。
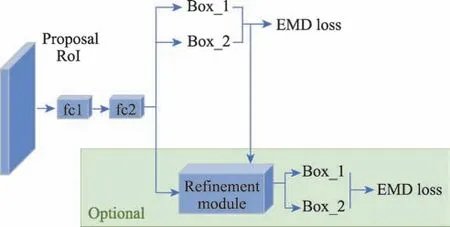
圖6 多目標預測總體結構Fig.6 Architecture of multi-target prediction
在CrowdDet 的基礎上,Shao 等人為了進一步提高檢測精度,提出了一種基于ResNet 的多尺度特征金字塔網絡(multi-scale feature pyramid network,MFPN)。受FPN 通過不同特征層進行特征融合來提高目標檢測精度的啟發,MFPN 對各尺度特征層進行池化固定大小后,采用兩層自底向上和自頂向下的雙特征金字塔網絡(double feature pyramid network,DFRN)作為最終的特征層輸出,以增強遮擋目標的特征信息。同時,MFPN 還對EMD Loss 進行適當的優化,提出了最小斥力損失(repulsion loss of minimum,RLM)來考慮不同建議框之間的關系。通過實驗驗證,MFPN 能夠提高遮擋目標的檢測精度。這也表明,在目標特征信息缺失的情況下,通過特征信息融合來增強目標的特征信息能夠有效提高目標的檢測概率,但是其仍然沒有克服自適應性不足的缺陷。
利用目標的結構信息將目標劃分,并利用可見部分進行檢測可以有效降低遮擋物的影響,但是部件檢測器的計算復雜度較高,頭-身聯合檢測的適用性較低且對數據集要求較高,多目標預測的預測數量自適應性不足都限制了基于目標結構進行遮擋檢測的發展,如何更加有效利用可見部分來解決上述問題進行目標整體的推斷仍然需要進一步研究。
深度神經網絡模型從訓練數據中獲取最優參數是一個不斷學習的過程,這一過程以損失函數為指標。損失函數可以直觀地表示神經網絡性能的優劣,即訓練后的神經網絡模型與訓練數據在多大程度上不擬合,或者說神經網絡的預測結果與實際結果在多大程度上不一致。通過合理地調整損失函數的算法結構,能夠提高深度神經網絡的性能。除了常見的均方誤差損失函數、交叉熵誤差損失函數、L1 損失函數、L2 損失函數等,為了提高檢測器的檢測性能,又相繼提出了IoU Loss、Focal Loss、GIoU Loss、DIoU Loss、EIoU Loss等一系列損失函數。
Wang 等人通過實驗驗證了當前損失函數構造的目標檢測器在檢測遮擋人群存在局限性,因此提出了一種針對遮擋人群的邊界框回歸損失函數,稱為Repulsion Loss。該損失由兩個動機驅動:目標對建議框的吸引力和周圍目標對建議的排斥力。斥力因素阻止了建議框向周圍目標物體的轉移,從而導致了更好的遮擋人群定位。Repulsion Loss 也是首次提出從損失函數的角度來解決遮擋問題,使網絡在自動學習的過程中不斷提升定位性能,為后續的遮擋檢測算法提供了新的解決方案。
Zhang 等人在提出的OR-CNN 網絡中,在Faster R-CNN 的區域建議網絡和Fast R-CNN 模塊使用了新的損失函數Aggregation Loss,它是一個包含分類損失和定位損失的多任務損失來推動建議框接近相應的目標真實邊界框,同時最小化與同一對象相關的建議框之間的區域距離,以此來強制建議框靠近并且定位到相應的目標對象。通過實驗驗證,Aggregation Loss在相同檢測框架下要比Repulsion Loss有效。
大多數損失函數通過位置回歸來計算損失值,但是在后處理中卻使用交并比(intersection over union,IoU)來抑制預測框的選擇,忽略了二者之間的聯系,低IoU 的預測框應該具有更高的損失值才能保證最終的預測結果更加接近目標邊界框,為此Rezatofighi等人提出了GIoU(generalized intersection over union)來解決這個問題。為了使GIoU 提高對遮擋物體的檢測性能,陽珊等人將Repulsion Loss 和GIoU Loss相結合,提出了Rep-GIoU Loss。新損失函數結合了二者的優勢,在增加回歸參數與IoU 間相關性的同時阻止建議框向周圍目標的偏移,提高了對遮擋目標的檢測性能,但是隨著建議框生成網絡的完善,高置信度的預測框極少會發生IoU 偏移,因此該算法的作用并不太明顯。
除了直接從IoU的角度修改損失函數,Luo等人將NMS 算法也參與到網絡模型的訓練中,提出了NMS Loss。NMS Loss 考慮了假陽性和假陰性(IoU過高易產生假陰性,IoU 過低易產生假陽性)對目標檢測結果的影響,對假陽性沒有被抑制而假陰性被NMS 錯誤地刪除進行懲罰,使得相同目標的預測離得很近,以及不同目標的預測離得很遠。但是NMS Loss 只適用于單類目標的檢測,其在一般檢測中的使用仍需要進一步的研究。
損失函數作為檢測結果的評價指標,是檢測器必不可少的組成成分,損失值能夠直觀地體現出檢測器性能,通過改進損失函數來改善檢測器在遮擋環境下的性能是代價最小且最具解釋性的方式之一,但是大多數損失函數的設計并沒有考慮遮擋條件的復雜性,從損失函數角度來單獨應對遮擋環境的研究還比較少。表2 對幾種損失函數的結構進行了說明。
為了刪除網絡生成的冗余預測框,大多數檢測器都會使用NMS 算法進行處理,其工作原理是:(1)將所有預測框按照置信度得分降序排列,選中置信度最高的預測框;(2)遍歷其余的預測框,如果和當前最高得分預測框之間的IoU 大于設定的閾值,就將該預測框刪除;(3)從未處理的預測框選出置信度得分最高的預測框,重復以上操作,直到所有的預測框都被處理過。
在非遮擋或者目標分布稀疏的情況下,NMS 確實可以有效地刪除冗余的預測框,保證每個目標都有唯一的最佳建議框與其對應,但是在遮擋條件下,由于目標相互重疊,可能會導致不同目標的最佳建議框之間大面積重疊,導致NMS 錯誤抑制,進而導致漏檢的發生。漏檢是因為傳統的NMS 抑制方式過于暴力——與置信度得分高的預測框重疊面積大于閾值直接刪除,因而傳統的NMS 也被稱為Greedy-NMS。
針對Greedy-NMS 的缺陷,2017 年,Bodla 等人提出了Soft-NMS,其采用一種衰減的算法檢測所有的預測框,對重疊度高的其他預測框的得分進行衰減,重疊度越高,預測框的得分衰減得越多,因為它們有更高的假陽性可能;同樣的,因為保留了預測框而不是直接刪除,在后續處理過程中,重疊度高的預測框還是有重新被“撈起”的機會,具體的算法結構如圖7。Soft-NMS 采用一種柔和的方式來進行目標預測框的抑制,雖然能夠降低漏檢的發生,但是也會造成計算成本的增加。
Hosang 等人提出了通過神經網絡進行學習來適應數據分布的NMS 算法。經過分析,一個檢測器如果對每個目標只輸出一個高分檢測,那么必須滿足對同一目標的多個檢測應該聯合處理,這樣檢測器就能夠知道有重復檢測,并且只有一個檢測應該得到高分。為了達到這個目標,有兩個關鍵點是必需的:(1)設計損失函數來懲罰多次檢測,從而告訴檢測器對每個目標只進行一次預測;(2)鄰近預測框進行聯合檢測,使得檢測器獲取信息來判斷一個目標是否被多次檢測。在這一思路下,Hosang 等人設計出了“pure NMS network”,也被稱為Learning-NMS,將重新設計的網絡模型稱為GossipNet。在遮擋條件下,Learning-NMS 優于傳統的NMS 方法。但是由于Learning-NMS 作為一個神經子網絡,必須要有足夠大的數據集來支撐其進行訓練,通過數據增強技術以及遷移學習或許會有益于GossipNet的使用。

表2 損失函數結構Table 2 Architecture of loss function
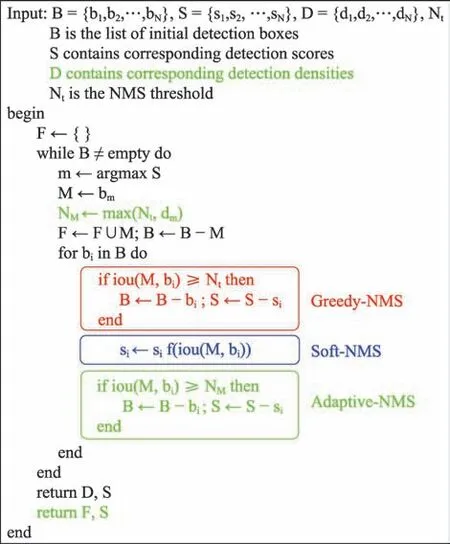
圖7 NMS 算法的結構Fig.7 Architecture of NMS
雖然Soft-NMS 并沒有像NMS 一樣直接丟棄與最高置信度建議框重疊度過高的建議框,而是通過衰減函數來降低其置信度,在一定程度上緩解了遮擋導致的邊界框重疊問題,但是由于Soft-NMS 仍然將所有高度重疊的建議框視為假陽性,存在一定的局限性。
Liu 等人針對擁擠行人檢測這一特殊場景,提出了Adaptive-NMS 對Soft-NMS 進行了優化,使得人群密集的地方,NMS 閾值較大;在人群稀疏的地方,NMS 較小。為了判斷人群的密集程度,作者設計了一個子網絡,可以根據每個實例的密度預測閾值,如圖7。通過在CityPersons 和CrowdHuman 數據集上進行實驗,取得了較好的效果,證明了該方法的有效性;而與GossipNet類似,該網絡同樣依賴于一個樣本充足的數據集進行訓練,而且更多的參數增加了模型復雜度。
前面所提到的NMS 算法只按照建議框的分類置信度由高到低來執行抑制操作,然而有的時候,精確的建議框可能與類別置信度的分數并沒有必然的相關性,這也就導致,得分高但是定位精確度差的建議框會抑制得分低但是定位精確的建議框。He 等人針對建議框定位置信度與類別置信度并無強相關提出了Softer-NMS。首先通過損失函數KL Loss 來學習對每個目標的建議框預測定位方差,然后在Soft-NMS 過程中,通過KL Loss網絡學習到的方差對建議框進行加權平均來優化建議框的選擇。
Huang 等人通過對比現有非極大值抑制算法發現,盡管各種算法通過不同手段降低了遮擋條件下閾值的影響,但是所有算法都是根據目標整體來進行處理,這種方式在遮擋條件下是不合理的,因為遮擋條件下遮擋部分會嚴重影響非極大抑制算法的使用。為此,他們提出了RNMS(representative region NMS),利用目標可見部分作為判斷條件來進行預測框的非極大值抑制。通過CrowdHuman和CityPersons數據集上的實驗驗證,RNMS 要優于已有非極大值抑制算法,而該算法也對如何能夠更精準地預測目標可見部分提出了要求。
非極大值抑制算法作為深度神經網絡進行目標檢測重要的后處理手段,其可靠性是影響檢測精度的重要因素,通過改進非極大值抑制算法使得每個目標都有與之對應的預測框進行匹配,將有效改善遮擋情況下由于目標建議框之間相互交疊導致的漏檢。根據閾值的設定方式不同,NMS 算法可以分為可學習型和超參數型,根據目標遮擋程度進行學習來自適應調整閾值的NMS 算法是未來研究的熱點方向。
卷積神經網絡在卷積運算的基礎上,通過將空間和通道方向的信息進行局部融合來進行特征提取,除了通過目標結構利用可見部分來檢測、改進損失函數和改進非極大值抑制算法提高遮擋檢測的性能,還有的研究針對網絡通道進行了研究。Hu等人認為不同的通道代表了目標不同部位的特征響應,其在目標識別過程中發揮的作用是不同的,因此提出了擠壓激勵網絡(squeeze and excitation networks,SENet)專注于通道關系。SENet 使用全局池化層和全連接層設計注意力網絡來為不同通道分配不同的權重,如圖8。
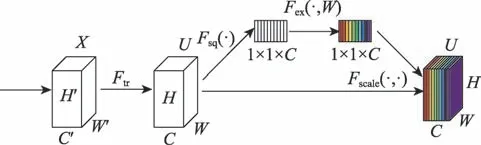
圖8 SENet總體結構Fig.8 Overall architecture of SENet
Zhang 等人進一步研究了通道與目標部位間的響應關系,將通道注意力運用到遮擋目標的檢測中,對SENet 中的注意力引導網絡進行了重新設計,使其更加符合遮擋檢測場景,并將其運用到了行人重識別任務中。除此之外,相關的研究還有Pang等人和Xie 等人也對注意力網絡進行了單獨的設計。根據實驗證明,針對通道的注意力網絡可以在一定程度上提升遮擋目標的檢測效果。
3.3 基于部分語義的檢測算法
部分語義是指具有語義意義并能被描述的物體的一部分,即目標的部件。不同于先驗知識直接將輸入圖像進行劃分,部分語義檢測聚焦于從深度網絡特征層中獲取目標的部分信息特征,進而有效處理遮擋問題。通過部分語義的檢測,一個目標可以用它的部件和部件之間的空間結構來表示,當檢測到目標的個別部分的位置,就可以通過這些已知的部分去推斷遮擋的未知部分。
Wang 等人首先發現,在訓練的深度神經網絡的中間層,對以通道數為維度方向的特征向量進行聚類,能夠反映出目標的部分語義信息,作者稱之為“視覺概念”,并利用視覺概念完成了對目標部件的檢測。基于此,Wang 等人提出了一種投票機制將部分語義信息用于處理遮擋檢測,其利用部分語義之間的空間約束信息來進行檢測。為了有利于訓練魯棒性的模型,在模型訓練上使用非遮擋圖像,但在遮擋圖像上進行測試。在遮擋導致某些視覺特征丟失的情況下,這種投票機制能夠通過檢測到的部分語義信息來進行目標的有效檢測,而且由于部分語義并不依賴于神經網絡的所有輸出特征,具有一定的魯棒性。但是,這種投票機制是人工設計的,沒有做到以端到端的方式進行優化。
隨后,Zhang 等人提出了一種深度投票機制,稱為DeepVoting 網絡。DeepVoting 將文獻[34]所 示的魯棒性結合到深度網絡中,是一種魯棒的、可解釋的深度網絡,其在VGG16網絡的基礎上在中間層之后增加了兩層:第一層為“視覺概念層”,該層利用上一層輸出的特征信息來提取局部視覺特征,進而檢測部分語義信息;第二層為“投票層”,該層利用上一層提取的部分語義信息和語義信息之間的空間約束關系來消除遮擋對檢測的影響,如圖9。通過在VehicleOcclusion 數據集上測試發現,在非遮擋情況下DeepVoting 網絡的性能與Faster R-CNN 相當,但在遮擋情況下,DeepVoting 網絡顯示出了更好的檢測性能,且測試速度提高了2.5 倍。
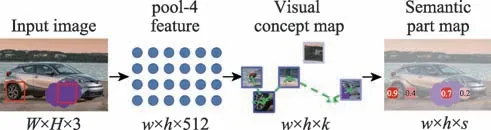
圖9 DeepVoting 整體框架Fig.9 Overall framework of DeepVoting
Kortylewski等人發現,雖然部分語義檢測對部分遮擋具有魯棒性,但是分類能力較差。為了更好地發揮深度學習的分類優勢,其將深度卷積神經網絡的分類能力和部分語義的組合能力相結合,提出了組合卷積神經網絡(composition convolutional neural networks,CompositionalNets)進行部分遮擋目標的檢測。通過在非遮擋圖像上的訓練,將目標的部分語義特征提取到字典中進行保存,并學習每個類部件的空間關系。在測試時,深度卷積神經網絡如果預測目標的置信度沒有達到設定的閾值,就進行部分語義檢測,將提取的特征用于檢測目標的部件,通過部件信息來進行目標的分類和定位。
Xiao 等人為了進一步提高遮擋下目標檢測器的魯棒性和分類性能,將原型學習、部分匹配和注意力機制結合到深度神經網絡中,提出了TDAPNet,如圖10。首先將深度神經網絡提取的特征進行原型學習;隨后使用部分匹配來比較原型與目標部分語義,從而去除不相關的特征向量,以此來擴展原型學習;最后,使用自上而下的局部注意力來調節遮擋引起的不規則激活,以減少遮擋的干擾。相比于CompositionalNets,TDAPNet具有更少的參數,計算更簡單,在遮擋水平較低的情況下具有更優的性能。
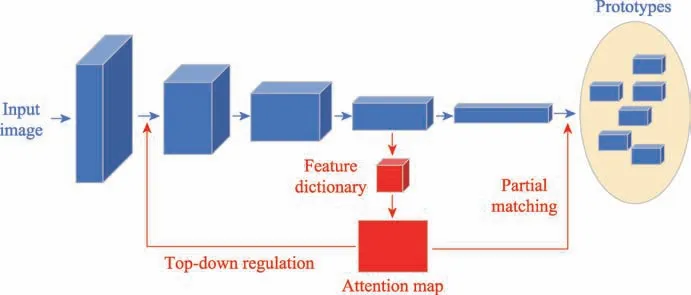
圖10 TDAPNet結構圖Fig.10 Overall architecture of TDAPNet
但是Kortylewski 等人通過實驗表明,在真實遮擋的圖像上,TDAPNet 的性能不佳。為此,在組合卷積神經網絡的基礎上進行優化,將深度卷積神經網絡和組合模型集成到一個統一的模型中,并使用一個端到端訓練的可微組合層代替深度卷積神經網絡的全連接分類層。該網絡利用組合層的生成特性,能夠對部分遮擋目標進行魯棒性的分類和定位。隨后,Kortylewski等人又對組合模型進一步優化,使其能夠將圖像分解為目標和上下文,然后利用目標部件和上下文信息定位遮擋物,并基于非遮擋部分識別物體。通過實驗驗證,改進的組合卷積網絡對遮擋目標分類具有很強的魯棒性。
根據Wang 等人的研究,由于組合網絡并沒有明確地將目標和上下文進行分離,在強遮擋的情況下,會放大上下文的影響并對最終的檢測結果產生負面影響。為了克服這個問題,作者在訓練過程中通過邊界框標注對上下文進行分割,并且引入了基于部分語義的投票方案對目標邊界框的角落進行投票,使得模型能夠可靠地估計嚴重遮擋情況下遮擋目標的邊界框。
部分語義檢測從網絡特征層中以通道作為維度獲取目標信息,提供了目標檢測的新思路,但是如何快速有效地獲取部分語義信息來訓練檢測器仍然是一個挑戰,而且如何來提高部分語義檢測器相對于整體特征檢測器的分類性能也需進一步的研究。
4 算法對比
根據利用的特征信息分析角度不同,以卷積神經網絡為基礎衍生出了部分語義檢測,部分語義檢測為目標檢測尤其是遮擋目標檢測帶來了新的研究思路,但是鑒于卷積神經網絡強大的分類能力,基于整體特征的目標檢測算法仍然是目前的主流研究方向。此外,越來越多的研究不再局限于某一方面的改進,而在于多方面的復合,例如多目標檢測提出了全新的網絡架構兼顧了損失函數和非極大值抑制的改進;文獻[77]中的組合網絡將整體特征和部分語義相結合。
表3 對不同類型的改進算法的優勢以及局限性進行了分析。表4 對算法的性能進行了列舉,其中采用的性能對比標準為AP(average precision)和MR(miss rate)。從表中可以看出,不同類別下的檢測算法由于對訓練數據集、測試數據集以及網絡結構的要求不盡相同,無法進行十分嚴謹的對比實驗;而在同一類別下的檢測算法也同樣受制于數據集的限制,無法進行更加深入的比較。在后續的研究過程中需要整合一個滿足各種算法要求的數據集來進行評測。

表3 不同類型改進方案的比較Table 3 Comparison of different types of programmes

表4 遮擋檢測算法的性能Table 4 Performance of occlusion detection algorithms
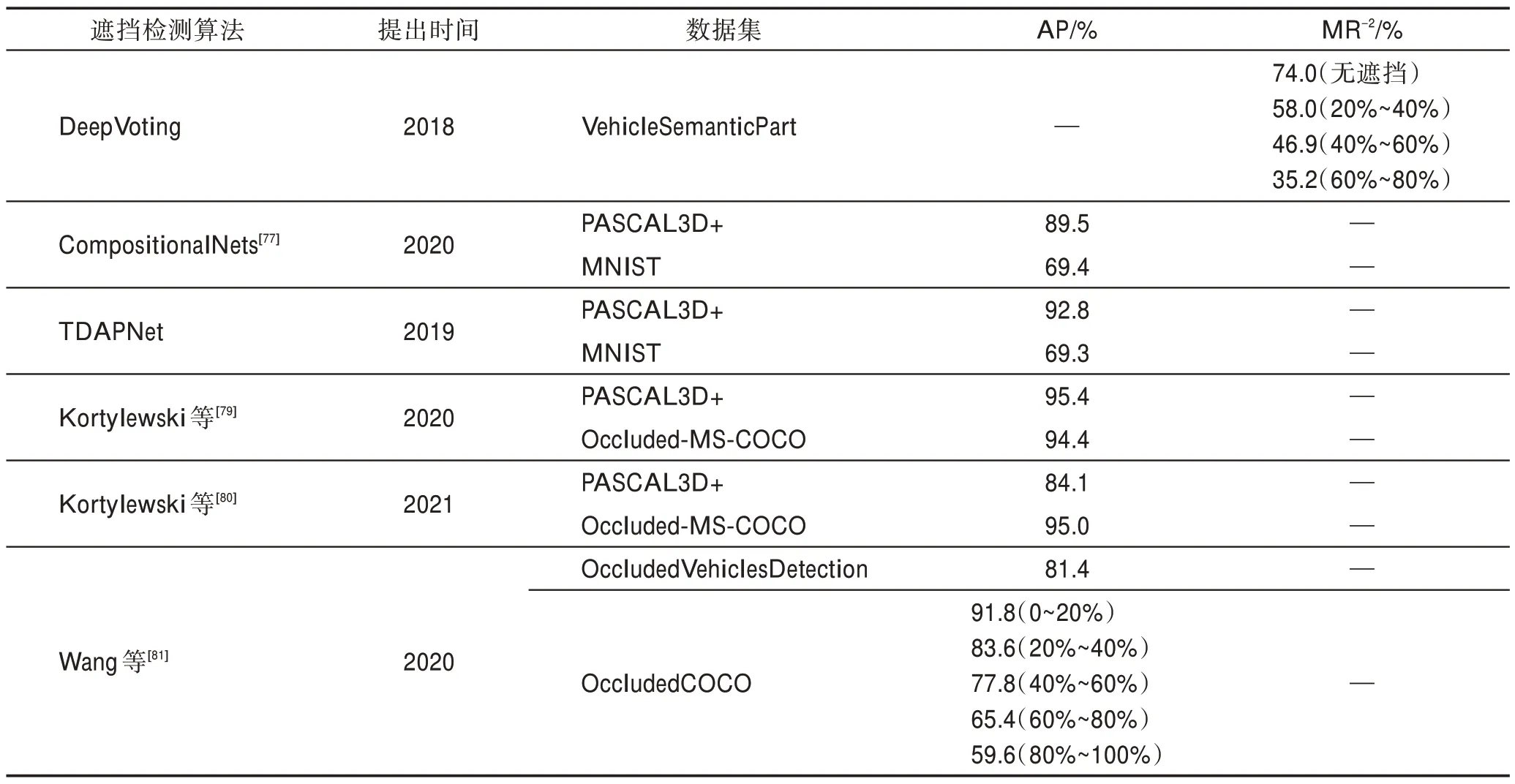
表4(續)
5 總結和展望
自深度學習,尤其是區域卷積神經網絡應用到目標檢測領域以來,目標檢測的精度以及速度都取得了長足的進步。雖然在一般目標和特定目標的分類檢測方面已經有了大量的研究并取得了豐碩的成果,但是對于遮擋目標的檢測仍然是一個挑戰性的問題。本文對深度學習在遮擋條件下的目標檢測進行了總結,并按照每個改進方法的優化理念,將其劃分成了不同的類別進行歸納,并對比了算法的性能。
雖然目前的方法基于不同技術在遮擋目標檢測方面取得了進步,但是考慮到遮擋問題的復雜性,遮擋檢測仍然存在一些關鍵問題需要解決,未來的工作可聚焦于以下幾個方面:
(1)通用遮擋檢測模型的訓練。當前的檢測模型大多是針對特定場景或者特定目標進行訓練,通用的目標遮擋檢測研究還較少,但是通用目標的檢測是真實環境中不可避免的,因此需要投入大量的研究。
(2)學習方式的改善。由于遮擋情況的復雜性,在訓練數據有限的情況下,檢測器難以學習到無法窮盡的各種遮擋情況。因此,如何利用現有的數據,通過無監督或者半監督方式來改善這個問題,應該是一個非常值得探索的方向。
(3)遮擋數據集的擴展與選擇。當前的遮擋數據集大多來自于合成圖片,而且來自于現實場景中的遮擋圖片較少且場景較為單一。在后續工作中,應該收集更大規模的注釋遮擋數據集,GAN 網絡和圖片增強技術將有利于數據集的擴充。除此之外,遮擋檢測的數據集眾多且評估遮擋檢測算法的標準各不相同,從而使得對各種算法的性能比較變得困難。在后期工作中,應該規范數據集以及評價標準的使用。
(4)目標特征的有效利用。目標檢測器的工作原理是根據深度神經網絡獲取的目標特征信息來進行目標的識別定位,遮擋目標由于遮擋影響了目標的特征提取導致檢測器無法正確判斷。通過更加有效地利用目標可見部分來獲取特征信息將會有利于目標檢測任務,例如部分檢測器、特征融合、部分語義檢測等。
除了前面提到的幾個方向,隨著Dosovitskiy 等人將自然語言處理中的Transformer 算法用于圖片分類任務并取得了優異的結果,其在計算機視覺領域引起了大量的關注。Transformer 通過對輸入圖像切片化的處理來聚焦于局部信息特征并通過局部信息之間的注意力機制來獲取圖像各部分之間的聯系。若將其應用于遮擋目標的檢測,或許會更好地關注于目標可見部分的特征信息而忽略掉遮擋部分對檢測的影響,以此對遮擋檢測問題進行有效的解決。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
