基于割點的社交網絡影響最大化問題
2022-06-17 07:10:42楊書新宋建繽
計算機與生活 2022年6期
關鍵詞:影響
楊書新,宋建繽,梁 文
1.江西理工大學信息工程學院,江西贛州 341000
2.長春理工大學計算機科學技術學院,長春 130000
近年來,信息技術的飛速發展帶動了社交網絡服務業的發展,如Facebook、Twitter、新浪微博和豆瓣等。We Are Social 和Hootsuite 在《2020 全球數字報告》中指出,普通網民平均每天要花費大約7 h 在社交網絡上,社交媒體用戶數更是突破38 億。而微信這一個社交平臺,全球每月就有11.5 億用戶使用它進行交互,產生了大量的信息。這些信息傳播的速度之快、范圍之廣,使得社交網絡上信息傳播問題越來越受到學者們的關注。社交網絡影響最大化問題作為信息傳播問題中的一個重要問題,它蘊含著巨大的商業價值,如個性營銷、謠言控制和鏈路預測等。
為了解決影響最大化問題,學者們給出了不少解決方案。現有方案主要分為貪心式和啟發式兩大類。貪心式雖然擁有精度保證,但較低的時間效率使這類算法難以應用于大規模網絡。相比貪心式,啟發式可以有效地解決時間效率低的問題,但現有的啟發式算法對網絡特征的挖掘不夠充分,沒有結合節點特征和結構特征看待影響最大化問題。面臨時間效率低和網絡特征挖掘不夠充分的兩大問題,本文綜合考慮節點特征和社交網絡拓撲結構,提出了CVIM(cut-vertex-based influence maximization)啟發式算法。本文的主要貢獻:(1)將割點相關理論應用到信息傳播問題中,提出了基于割點的影響最大化算法CVIM;(2)在四個開源數據集上驗證了CVIM 算法在社交網絡上的實用性和有效性;(3)對CVIM 算法在社交網絡上多方面的表現進行了分析。
1 相關工作
影響最大化問題進入學術界是在2001 年,Domingos 和Richardson提出用馬爾科夫隨機場來模擬信息傳播過程,并給出了一個啟發式的解決方案,給學者們打開了一道新的大門。緊接著,在2003 年,Kempe 等人將影響最大化問題定義為一種top-的離散最優化問題,即找出影響傳播范圍最大的個種子節點。此外,他們還提出了兩種基本的傳播模型,線性閾值模型和獨立級聯模型,并證明了在這兩種傳播模型下,影響最大化問題是一個NP 難問題。他們提出了一個近似比為(1-1/e)的Greedy 算法,可以得到影響最大化問題最優解63%的近似解。他們提出的這些方法和結論給影響最大化問題的研究奠定了基礎。盡管Greedy 算法得到的近似解效果不錯,但它的時間復雜度非常高。針對這一問題,學者們提出了一些降低時間復雜度、提高效率的方法。
根據影響最大化問題目標函數的子模性,Leskovec等人提出了CELF(cost-effective lazy-forward)算法。它的主要思想是:對于任意邊=(,),若節點在上一輪的邊際收益小于等于節點的邊際收益,則從當前輪開始,節點的邊際收益不用計算。該算法比傳統的貪心算法提高了近700 倍。為了進一步提高時間效率,Goyal 等人在CELF 算法的基礎上提出了CELF++算法。與CELF 算法不同的是,CELF++算法先為任意節點記錄了在當前迭代中邊際收益最大的節點._,然后計算節點的邊際收益。若._在當前迭代中選為種子節點,則在下一輪迭代中就不需要計算節點的邊際收益。相較CELF 算法,CELF++算法節省了35%~55%的時間。
以上這些算法都是以貪心算法為基礎提出的,因此都具有時間復雜度高的弊端。為了解決這一問題,學者們提出了基于啟發式算法的一系列算法。Chen 等人提出的DegreeDiscount 算法,它的主要思想是:若節點的鄰居節點中存在種子節點,那選擇作為種子節點時,需要先將節點的度數進行定量打折,然后選度數最大的個節點。DegreeDiscount算法相比貪心算法提高了時間效率,但精度不高。因此,Chen等人基于節點局部區域的影響值近似估計全局影響值的思想,提出了PMIA(prefix excluding maximum influence arborescence)算法。它通過最大影響路徑來構建最大影響子樹(maximum influencearborescence,MIA),并通過調控子樹的大小來達到時間效率和精度之間的平衡。盡管PMIA 算法在一定程度上平衡了時間效率和精度,但當網絡圖的密度較大時,會將影響限制在最大影響路徑范圍內,使得影響估計誤差較大。根據面積密度公式,Ibnoulouafi 等人提出了節點密度中心性,并用節點密度中心性來度量節點的影響力。密度中心性考慮了節點的多層鄰居的影響,因此比其他中心性的度量值更準確。但其本質仍然是用節點的度來計算密度,因此精度不是很高。
盡管貪心算法和啟發式算法分別能得到較好的算法精度和時間效率,但它們都無法較好地平衡算法精度和時間效率。因此,曹玖新等人提出了一種綜合啟發式和貪心算法的MHG(mix heuristic and greedy)算法。它的核心思想是:先通過啟發式算法選出候選種子節點集,再用貪心算法從候選種子節點集中篩選出種子節點集。MHG 算法的精度接近于貪心算法,并且時間效率要高于貪心算法,較好地平衡了算法精度和時間效率。但MHG 算法也同時擁有所選啟發式算法和貪心算法的缺陷。如Cao 等人選擇的PMIA 算法在圖密度大時影響度量不準確,以及他們沒有考慮邊際收益問題。
為了得到好的算法精度和時間效率,學者們不再僅僅考慮節點的單一環境因素和單一特征。Zareie等人提出度量節點的影響力需考慮直接影響、間接影響、直接覆蓋、間接覆蓋四因素,他們采用多目標決策分析中的TOPSIS(technique for order preference by similarity to an ideal solution)方法綜合考慮這四個因素,并提出了MCIM(multi-criteria influence maximization)算法。雖然MCIM 算法不僅考慮了節點與鄰居的直接與間接影響,而且考慮了不同節點的鄰居覆蓋問題,但是它僅僅考慮了節點的度這一單一特征。Yang 等人則利用多目標決策分析中的VIKOR(vlsekriterijumska optimizacija I kompromisno resenje)方法綜合考慮了節點的度中心性、緊密中心性和介數中心性三種特征,并提出了EW-VIKOR(entropy weighting VIKOR)算法,但EW-VIKOR 算法的精度與單一特征相比提升并不明顯。
鑒于已有的影響最大化算法大多數關注于節點的特征(如度、密度等),很少關注社交網絡的結構特征(如連通分量、橋等)。因為割點連接著圖中的連通分量,是圖的重要組成部分。并且文獻[16-17]都證實了割點在網絡中扮演著重要角色,在網絡的連通性方面起重要性作用,它們一旦失效或被移除,網絡都將可能癱瘓。因此,本文綜合考慮節點特征和社交網絡結構特征,提出了一種基于割點的影響最大化算法CVIM。
2 相關概念及形式化描述
在現實生活中,往往存在著一些關鍵角色,雖然它們可能不是主角,但它們是整個拼圖中必不可少的一塊(如中介、經紀人、交通樞紐等)。把這些關鍵角色映射到網絡圖上,他們就是網絡圖中的割點。在給出割點的定義之前,必須先提一下連通圖和連通分量的基本概念。因為割點是圖中的一種特殊的點,它與圖的連通性有關。本文通過圖例介紹了連通性的相關概念,詳細情況見圖1。
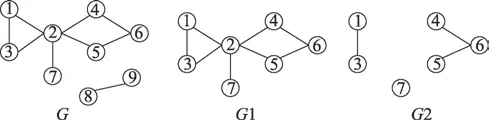
圖1 圖的連通性示例Fig.1 Example of graph connectivity
在圖1 中,是一個無向圖,同時也是非連通圖。而1 是一個連通圖,因為在1 中,任意兩個不同的節點之間都存在可達路徑。此外,1 是的子圖,并且如果往1 中加上(8,9)這條邊,1 就不是連通圖。基于這些前提,則可以推斷1 是的極大連通子圖,同時也可以稱1 是的連通分量。因為連通圖的極大連通子圖就是它本身,所以1 也是1 的極大連通子圖,即1 是1 的連通分量,并且是唯一連通分量。2 是將1 中的節點2 以及與節點2 相關聯的邊刪除后得到的無向圖。從圖中可以看出,2有3 個連通分量,1 只有1 個連通分量,去除節點2以及與節點2 相關聯的邊使得圖的連通分量增加,滿足這個條件的節點被稱為割點,即節點2 是1 的割點。割點的定義如定義1 所示。
(割點)假設=(,)是無向連通圖,若存在′?,且′≠?,將′中的節點和與這些節點相關聯的邊都從中刪除,可以得到兩個或兩個以上的連通分量,則稱′為的點割集。若′={},則稱是連通圖的割點。
給定一個無向連通圖=(,),對任意節點∈都滿足C=(-{})-(),且C≥0。
其中C是節點對應的連通分量增加數,-{}是從圖中去除節點以及它相關聯的邊后得到的圖,(-{}) 是圖-{} 中的連通分量數。如果C>0,則節點是割點。在圖1 中>0,因此節點2 是割點,它連接著3 個連通分量。在信息傳播過程中,一旦節點2 被阻塞,3 個連通分量之間就無法傳遞信息。但如果從節點2 開始傳遞信息,3 個連通分量都可達,傳播范圍變廣。本文分別選取度數高的節點和割點進行信息傳播對比,如圖2 所示。
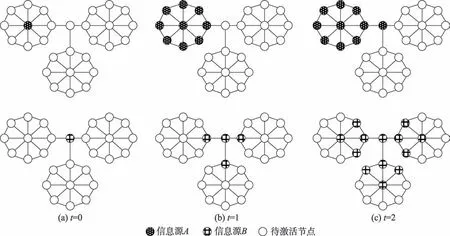
圖2 信息傳播對比(假設傳播概率為1)Fig.2 Comparison of information spreading(Suppose probability of propagation is 1)
在圖2 中,信息源是度最高的節點,信息源是割點。子圖(a)~(c)分別是信息源和信息源在=0、1、2 時的傳播狀態圖。很顯然,信息源雖然在傳播前期因為鄰居節點多而占據優勢,但是到了=2 時,信息源因為它所處的關鍵位置而比信息源傳播得更廣。因此,割點作為種子節點是可行的。但是在實際網絡中存在的割點也不占少數,尤其是大規模網絡。因此本文提出用割點所對應的連通分量增加數來度量節點的影響力,并且綜合考慮節點的特征與網絡的結構特征。種子集的求解式如式(1)所示:
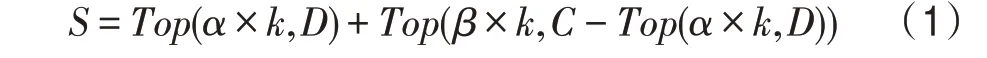
式(1)中,是大小為的種子集,和是調節參數,其中+=1。和分別是以度值和連通分量增加數篩選出的候選種子集。(×,)表示從候選種子集中選出前×個種子,-(×,)是候選種子集與前×個種子集合的差集,防止最終篩選出的種子出現重復。
3 CVIM 算法
為了解決影響最大化問題,本文提出先計算網絡圖=(,)中節點對應的連通分量增加數,然后根據節點度數排序挑選出影響力最大的×個種子節點,根據節點對應的連通分量增加數排序挑選出除之前挑選出的種子之外的×個種子節點。CVIM算法的流程圖如圖3 所示。
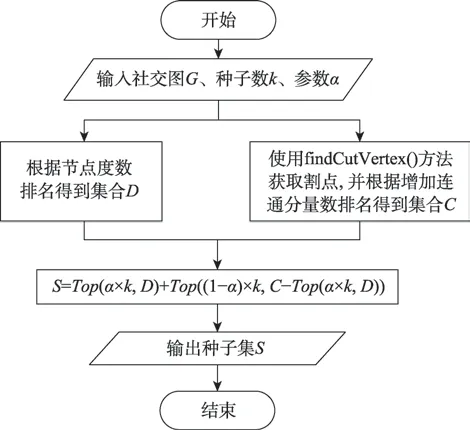
圖3 CVIM 流程圖Fig.3 Flow chart of CVIM
傳統的求解割點的算法是刪除一個節點,然后使用DFS 算法遍歷圖,如果圖的連通分量增加,則刪除的節點是割點。這種求解割點的算法需要使用||次DFS 算法,而本文使用的算法僅僅需要將所有的節點和邊訪問一次即可,即時間復雜度僅為(||+||)就能找出圖中所有的割點,并求出其所對應的連通分量增加數。圖4 是一個割點求解實例。
圖4(b)所示為從節點出發深度優先搜索遍歷子圖(a)所得的深度優先生成樹。子圖(b)中的實線代表樹邊,虛線代表回邊(即不在生成樹上的邊)。觀察深度優先生成樹的結構,可以發現有兩類節點可以成為割點。這兩類節點的具體情況如下:
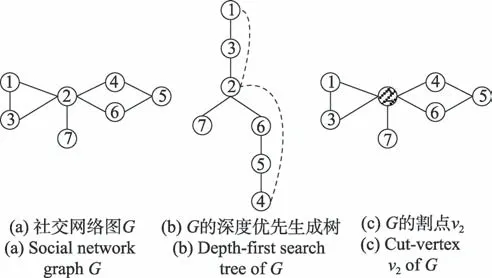
圖4 割點求解實例Fig.4 Instance of getting cut-vertex
(1)對于根節點,若它有兩棵或兩棵以上的子樹,則該根節點是割點。因為深度優先生成樹中不存在連接不同子樹中頂點的邊,所以,如果刪除根節點,生成樹變成森林。
(2)對于分支節點(即非根節點,也非葉子節點),若它的子樹的節點都沒有指向節點的祖先節點的回邊,則節點是割點。因為如果刪除節點,它的子樹和生成樹的其他部分將不再連通。
對于根節點,可以直接判斷它的孩子節點個數,處理十分簡單。但是對于非根節點,判斷節點之間是否有回邊就顯得有些困難。本文采用[]和[]分別記錄節點在深度優先遍歷過程中被遍歷到的次序和記錄節點或它的子樹追溯到最早的祖先節點的次序。這樣,只需將所有的節點和邊遍歷一次,就可以更新所有節點的和值。這兩個值的計算公式如式(2)所示:

式(2)分為兩種情況:(1)(,)是樹邊;(2)(,)是回邊,并且不是的父親節點。根據式(2),得到圖3(a)節點∈{,,…,}對應的[]和[]值,詳細數據如表1 所示。
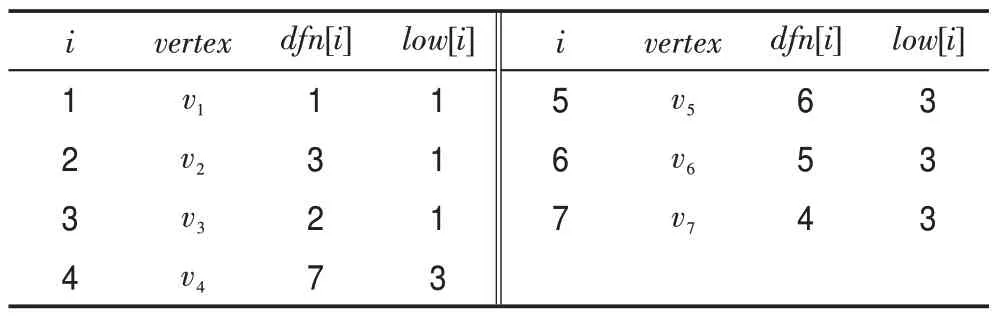
表1 圖3(a)中各節點對應的dfn 和low 值Table 1 dfn and low of nodes in Fig.3(a)
得到節點∈{,,…,}的[]和[]值之后,本文根據這兩個值的關系判別節點是否為割點。判別節點是割點的條件如下所示:
(1)節點是根節點,并且有兩個或兩個以上的孩子節點;
(2)節點不是根節點,但對于(,)滿足[]≥[]。
根據第3章中對割點相關概念的介紹,再加上圖4的求解割點過程,下面給出割點以及其對應的連通分量數的求解算法()。
(,)

其中,第1~4 行是初始化階段,初始化一個空棧,次序標記和子樹數量,以及節點對應的連通分量增加數[],并為節點設置[]和[]初值,然后將節點放入棧中。第5~17 行是迭代階段,更新節點的[]和[]值。其中第9~15 行是當(,) 為樹邊時,先遞增子樹數量,然后遞歸求出[]用來更新[]的值。若節點是根節點并有兩個或兩個以上的子樹時,節點對應的連通分量增加數量加1;若節點不是根節點但[]≥[]時,節點對應的連通分量增加數量也加1。第16~18 行是(,)為回邊時的情況,最后返回[]。根據表1 和算法1,可以得出圖1 中的割點為,并且對應的連通分量增加數為2。
算法1 獲得了割點以及它所對應的連通分量增加數。基于此,本文給出求解種子集的算法CVIM。
(,,)

算法CVIM 中,第1 行先初始化種子集。第2~5行,根據節點的度排序,獲取前×個種子節點。第6~12 行,先根據算法1 獲取節點所對應的連通分量增加數,再根據它排序,獲取剩下的-×個種子節點。最后返回種子集。
在算法1 中,找出連通圖中的割點并記錄它所對應的連通分量增加數的時間復雜度僅為(||+||),而在算法2 中,獲取節點度排序的時間復雜度為(||),獲取所有節點對應的連通分量增加數的時間復雜度為(||×(||+||)),因此,綜合兩個算法的時間復雜度為(||×(||+||))。
4 仿真實驗
為了驗證CVIM 算法求解影響最大化問題的有效性,本文在4 個真實的開源網絡數據集上進行了仿真實驗,這4 個網絡數據集都下載自開源網站http://networkrepository.com。其中數據集anybeat 是從在線社交平臺anybeat 上收集到的用戶關系網絡,數據集brightkite 是從基于位置的網絡服務網站的開源API 獲取到的友誼網絡,數據集epinions 是從在線社交網站epinions 上獲取到的信任關系網,數據集HepPh 是來自Arxiv 網站上的高能物理合作網絡。數據集的基本信息如表2 所示。
本文實驗采用傳染病模型進行信息傳播模擬,其中感染概率為0.1,恢復率為網絡平均度的倒數,傳播步長為網絡直徑(網絡直徑是網絡的平均路徑長度,代表了網絡的一定特征。將傳播步長設置為網絡直徑更貼近現實生活中的信息傳播)。感染率和恢復率的取值都是基于傳染病模型的信息傳播仿真實驗的常見取值,見文獻[14]和文獻[18]。
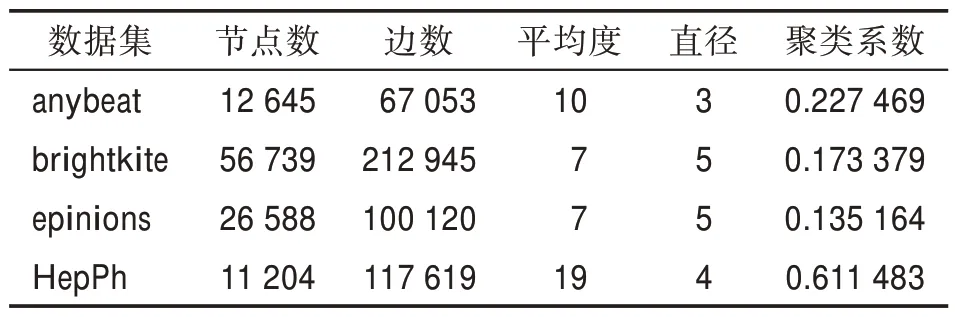
表2 實驗數據集的基本信息Table 2 Basic information about experimental datasets
由于CVIM 算法是根據式(1)來選擇種子節點,需要先確定式(1)中的參數和,然后才能從候選種子集和中篩選出種子節點。本文設計了實驗來確定這兩個參數,由于+=1,只要確定其中一個參數,另一個便可得知。因此,本文通過信息傳播模擬,根據參數在不同取值時,獲取到的種子節點的激活節點數來評估參數的優劣,實驗結果見圖5。
在圖5 中,橫坐標是參數的取值,縱坐標是種子節點最終激活節點數(即影響傳播范圍)。此外,本文考慮到種子集大小對結果的影響,還對比了在取不同值的情況下,參數對應的激活節點數的變化。根據圖5 的實驗結果,可以看出小于40 時,激活節點數大體呈上升趨勢,因為種子集小時,度更能充分發揮它的前期優勢;而當大于40 時,激活節點數先呈上升趨勢,在參數=0.5 時,激活節點數達到峰值,取值大于0.5 時開始呈下降趨勢,因為此時割點占據主導地位。這也印證了圖2 表現出的現象。對于數據集anybeat 出現上升、下降、上升的趨勢,是因為取值從0.5 到0.6 時,從anybeat數據集挖掘的種子節點間影響力重疊增加量最多(見表3,設置為100,以=0.1 時的種子間邊條數為基準),導致激活節點數急劇下降,之后得到緩解,從而又開始上升,這是數據集的特殊性。而數據集brightkite 大體出現上升趨勢,只有=100 這條曲線有上升、下降的趨勢,這是因為該數據集的規模相對較大,而種子集大小就顯得較小,從而激活節點數的峰值點滯后。數據集epinions 也出現了輕微的滯后現象,而數據集規模相對較小的HepPh 則沒有出現滯后現象。綜合4 個數據集的模擬結果,本文將參數設置為0.5,即參數也為0.5。
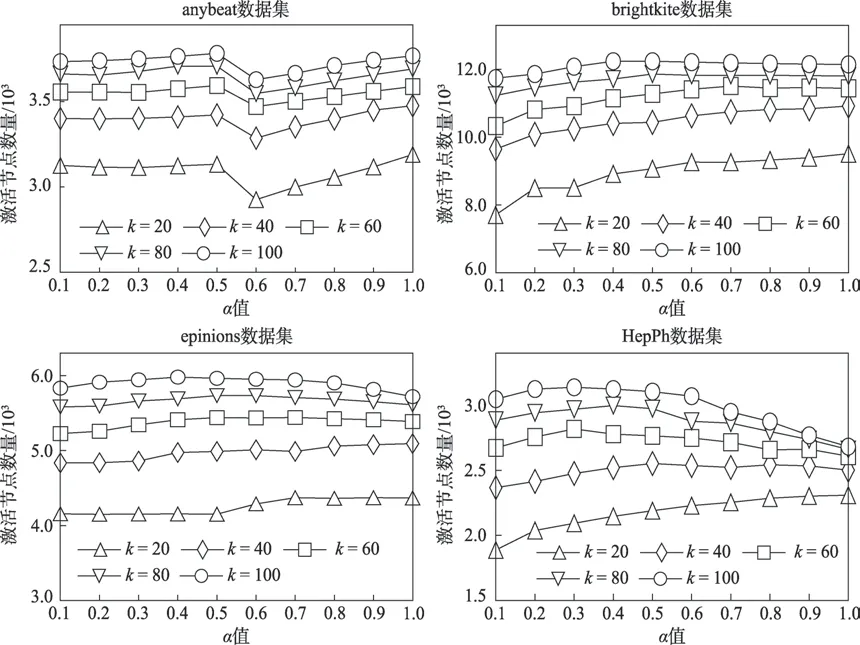
圖5 參數α 對比Fig.5 Comparison of parameter α
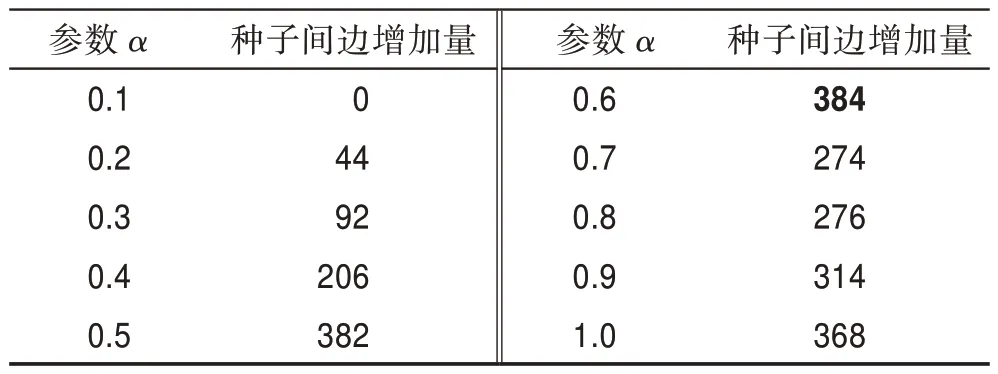
表3 anybeat數據集影響力重疊分析Table 3 Influence overlap analysis of anybeat dataset
參數取值確定之后,根據參數從候選種子集中獲取了種子節點。為了驗證CVIM 算法挖掘種子的實用性和有效性,本文分別根據算法運行時間和種子影響傳播范圍兩個指標設計了算法對比實驗。算法運行時間即指算法挖掘種子所花費的時間,種子影響傳播范圍則指用算法挖掘出的種子節點進行信息傳播模擬,得到的激活節點數。算法運行時間對比實驗中,種子數設置為100。參與對比的算法有:緊密中心性(closeness centrality,CC)、度中心性(degree centrality,DC)、密度(density)和混合多種影響因素的MCIM 算法。實驗結果如圖6 和圖7 所示。
在圖6 中,橫坐標為5 種算法,縱坐標是各個算法挖掘100 個種子節點所耗的時間。從圖6 可以看出,算法CC 挖掘種子所耗時間最長,這是因為算法CC 挖掘種子過程中需要反復地遍歷路徑,十分耗時,這一特點在網絡直徑較大的數據集brightkite 和epinions 上特別明顯。算法DC 挖掘種子所耗時間最短,本文所提算法CVIM 與算法DC 基本持平,差距僅在0.3 s 以內。因為算法DC 僅需要統計節點鄰居個數,極少時間內就能完成。算法CVIM 除了需要統計節點鄰居個數之外,還要統計節點對應的連通分量增加數,因此比算法DC 多花了些時間。算法Density 雖然也是統計節點鄰居個數,但它需要統計3級鄰居,因此花費時間比算法DC 和算法CVIM 多。相比算法Density,算法MCIM 僅考慮了2 級鄰居,在稀疏的社交網絡上,去重操作花費時間并不多,因此一般情況下的運行時間比算法Density 少。但在聚類系數較高的數據集HepPh 上,算法MCIM 的去重操作需要花費不少時間,因此運行時間比算法Density長一些。算法CVIM 在4 個數據集上的運行速度比算法CC、Density 和MCIM 平均快9 089 倍、790 倍和280 倍。從圖6 中的整體表現可以看出,算法CVIM擁有很高的時間效率,因此它在運行時間指標上具有一定的優勢,更適用于大規模網絡。
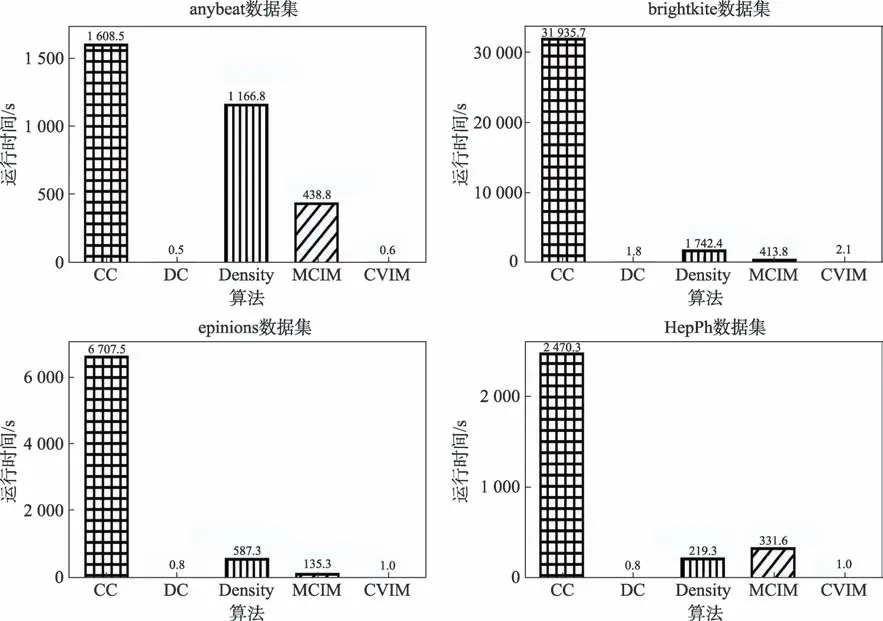
圖6 運行時間對比Fig.6 Comparison of running time
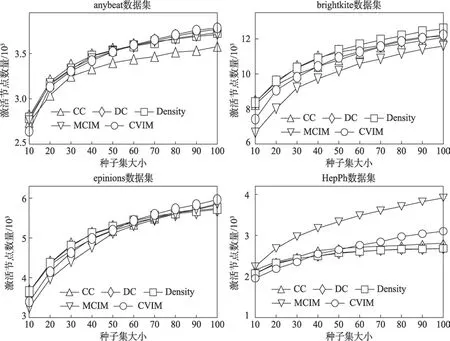
圖7 影響傳播范圍對比Fig.7 Comparison of influence spreading
在圖7 中,橫坐標為種子集大小,縱坐標為激活節點數量,5 條曲線分別對應CC、DC、Density、MCIM和CVIM 五種算法。在4 個數據集中,種子集較小時,CVIM 算法處于劣勢,但當種子集逐漸變大時,CVIM 算法也逐漸接近其他算法,尤其是在數據集anybeat和epinions 中后來者居上,占據優勢地位。在數據集brightkite 和epinions 中,算法MCIM 表現一般,是因為這兩個數據集的聚類系數相對較小,而在聚類系數較大的HepPh 中,表現突出(見表2)。算法CC 是根據路徑長度度量節點的影響力,因此在網絡直徑較小的數據集anybeat 上,節點影響力的區分度比較低,篩選出的種子節點的傳播效果較差。算法DC 和Density 都是根據節點的度評估節點影響力,不同點在于Density 將2 級和3 級鄰居的度也作為評估因素,因此Density 比DC 占據微弱的優勢。與算法DC 和Density 相比,算法CVIM 在種子集小時(<50)效果一般,這是因為在種子集較小時,度占主導優勢,但這種優勢是短暫的,只有少數節點的度數特別大。在>50 時,割點獲取了主動權,實現反超。因為算法CVIM 考慮了網絡的結構特性,使得算法CVIM 對網絡的特征差異敏感度低,對網絡的適配度較高。因此比算法MCIM 和CC 都穩定。綜合4 個數據集上的實驗結果來看,隨種子集大小的增加,算法CVIM 對應種子的影響傳播范圍穩步擴大,受到其他因素的干擾較小,因此算法CVIM具有一定的優勢。
為了進一步驗證CVIM 算法的有效性,本文還設計了種子間緊密性實驗,探究各算法所選種子是否存在“富人俱樂部”現象。“富人俱樂部”現象是復雜網絡的一種結構屬性,可以用來區分冪律拓撲。它表現為“富人”節點之間的連通性遠遠高于其他節點。即“富人”節點之間緊密性遠遠高于其他節點。本實驗中的“富人”節點即指種子節點。該實驗的設計思路:首先讀取社交圖,再讀取各算法選出的種子節點,匹配種子節點間邊的條數,若邊的條數越多,說明種子間的緊密性越高,它們的影響力重疊量越大,“富人俱樂部”現象越明顯。實驗設置種子集大小為100,實驗結果如圖8 所示。
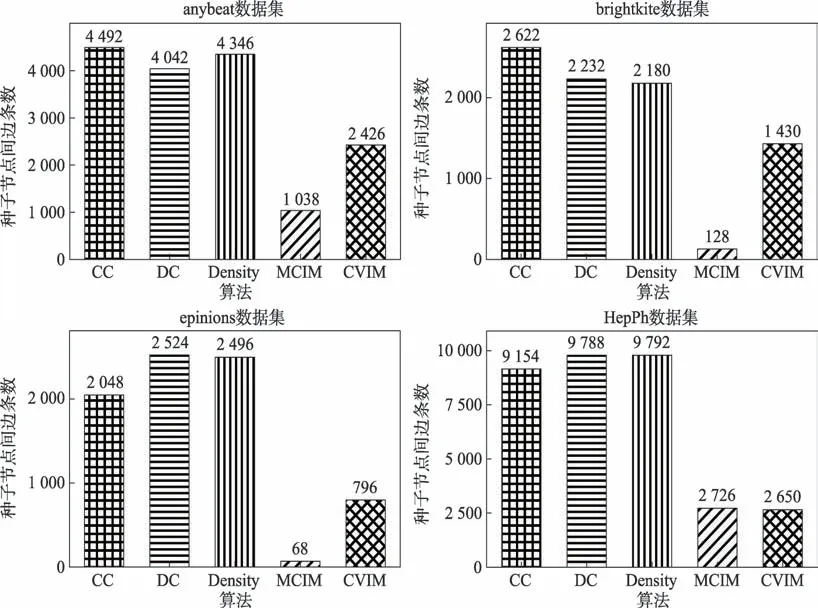
圖8 種子富集性對比Fig.8 Comparison of seed enrichment
在圖8 中,橫坐標是五種算法,縱坐標是算法挖掘出的種子之間的連邊條數。在4 個數據集中,算法CC、DC 和Density 挖掘出的種子,它們的緊密性偏高,進一步解釋了圖7 中這三種算法的表現一般的結果。算法CC 的種子富集性比算法CVIM 和MCIM 平均高2.4 倍和14.6 倍,算法DC 的種子富集性比算法CVIM 和MCIM 平均 高2.5 倍和15.5 倍,算法Density的種子富集性比算法CVIM 和MCIM 平均高2.5 倍和15.4 倍。算法MCIM 因為考慮了影響覆蓋因素,所以種子間的緊密性較低。在數據集HepPh 中,算法MCIM 挖掘的種子緊密性高于CVIM 是因為該數據集的聚類系數明顯比其他數據集高(見表2)。綜合4個數據集上的表現,除去算法MCIM,CVIM 體現出了割點的優勢,一定程度上消除了“富人俱樂部”現象。
5 結束語
由于割點在圖論中扮演著不可或缺的角色,本文基于圖論中的割點理論,提出了基于割點的影響最大化算法CVIM。它將連通分量納入到評估節點影響力的指標中,并結合度的優勢,篩選出了有效的種子集,從而求解了影響最大化問題。實驗結果表明,CVIM 與部分具有代表性的算法相比,在影響傳播范圍和種子富集性指標上具有一定的優勢,并且能有穩定的表現。但在現實生活中,挑選出的種子節點的影響力往往會因為時間、空間等因素而衰減,已有研究表明可以通過修改網絡的結構,提升種子節點的影響力。因此,未來工作將從網絡的結構出發,進一步分析如何減緩種子節點影響力的衰減或提升種子節點的影響力。
猜你喜歡
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
家庭影院技術(2020年10期)2020-12-14 07:54:18
媽媽寶寶(2017年3期)2017-02-21 01:22:28
中國塑料(2016年3期)2016-06-15 20:30:00
通信電源技術(2016年3期)2016-03-26 07:13:38
知識經濟·中國直銷(2016年3期)2016-02-27 16:15:49
現代檢驗醫學雜志(2014年6期)2014-02-02 03:02:04
閱讀與作文(小學低年級版)(2011年3期)2011-01-01 00:00:00
