融合知識圖譜與圖卷積網絡的混合推薦模型
2022-06-17 07:10:46郭曉旺夏鴻斌
計算機與生活 2022年6期
郭曉旺,夏鴻斌,2+,劉 淵,2
1.江南大學 人工智能與計算機學院,江蘇 無錫 214122
2.江蘇省媒體設計與軟件技術重點實驗室,江蘇 無錫 214122
隨著信息社會的不斷發展,人們可以在網絡上接觸到大量的信息,例如視頻和書籍,信息超載使得人們無法快速有效地選擇自己需要的信息。為了減少信息超載的影響,研究人員提出了推薦系統以對用戶進行信息的個性化推薦。其中協同過濾算法是一種傳統的推薦算法,它主要通過分析用戶的歷史行為進行推薦。例如,Jamali等人提出一種基于用戶信任和協同過濾方法的隨機游走模型,Wang等人提出一種貝葉斯框架用于給用戶推薦當前感興趣的新聞。然而協同過濾算法存在冷啟動的問題,同時也很難給出合理的推薦解釋。為了解決上述問題,研究人員增加一些輔助信息用于推薦,常見的輔助信息:社交網絡、用戶或物品的特征、多媒體信息、上下文信息(比如用戶在用APP 訂餐時的瀏覽和購買記錄)。知識圖譜(knowledge graph,KG)通常包含項目的豐富屬性和關系,有助于提升推薦系統的性能。例如,Zhang 等人提出一種基于知識圖譜的鄰域聚合協同過濾模型。
知識圖譜的節點對應實體,邊表示實體間的關系。將項目及其屬性映射到知識圖譜可以更好地理解項目間的關系;將用戶及其相關信息映射到知識圖譜,可以構建用戶和項目之間的關系,更加準確地提取用戶的偏好。與沒有將知識圖譜作為輔助信息的推薦系統相比,基于知識圖譜的推薦系統在推薦性能上具有以下優點:提高推薦系統的性能,增加推薦項目的多樣性,為推薦提供可解釋性。
近幾年,研究人員關注于將知識圖譜作為輔助信息用于提高推薦系統的性能。高仰等人將知識圖譜與用戶的短期偏好相結合,提出一種基于知識圖譜的混合框架。Wang 等人提出了MKR(multi-task feature learning for knowledge graph enhanced recommendation)模型。MKR 模型采用知識圖譜嵌入來輔助推薦任務,通過多任務學習自動共享項目的潛在特征,學習項目之間的高階內在關系。Wang等人提出的KGCN(knowledge graph convolutional networks for recommender systems)模型利用圖卷積網絡,選擇性地聚合項目的鄰域信息得到項目的特征向量,自動捕獲知識圖譜的高階結構和語義信息。Wang 等人提出的RippleNet模型將基于路徑和基于嵌入的方法結合,通過用戶的興趣偏好傳播提取用戶特征,忽略了項目特征對于用戶興趣建模的重要性。
然而,以上方法雖通過知識圖譜提高了推薦模型的性能,卻未能充分利用知識圖譜的結構信息。其中MKR 模型忽略了知識圖譜中實體間的鄰域關系,造成模型提取的項目的特征不夠精確;以上推薦方法也未能同時將用戶特征和項目特征與知識圖譜進行有效的信息融合,只是單一地考慮項目與實體或者用戶與實體之間的聯系。
針對以上問題,本文提出一種融合知識圖譜與圖卷積網絡的混合推薦模型(hybrid recommendation model of knowledge graph and graph convolutional network,HKC)。本文的主要貢獻包括:
(1)通過KGCN 算法計算項目的鄰域特征向量,對知識圖譜中實體間的鄰域關系進行建模,更好地利用知識圖譜結構信息,提高了模型的評分預測精度。
(2)在神經網絡中,利用協作傳播和交互單元操作有效地促進用戶和知識圖譜中實體之間的信息融合。同時采用交替學習的訓練方式計算用戶的偏好特征,優化模型的結構,增強了推薦性能。
(3)優化MKR 模型中的交叉壓縮單元,在壓縮層中去除參數偏置,減少神經網絡中的參數,降低計算量,提高了交替學習訓練的有效性。
1 相關工作
1.1 基于圖卷積網絡的推薦算法
圖卷積神經網絡(graph convolutional network,GCN)是一種提取拓撲圖的空間特征的深度學習方法,包含譜方法和非譜方法。許多現有的推薦系統中結合了GCN 方法,例如:PinSage算法結合隨機游走算法和GCN方法構建節點嵌入表示,包含了圖的結構和節點特征;Yang等人提出一種可解釋的GCN模型,利用雙向傳播策略自動構建用戶和項目的特征。
1.2 基于知識圖譜的推薦算法
現有的融合知識圖譜的推薦模型可以分成三類:基于嵌入的方法、基于路徑的方法和基于圖的方法。
(1)基于嵌入的方法主要使用知識圖譜嵌入算法對知識圖譜中的推薦實體進行預處理,然后將得到的嵌入向量應用于推薦模型。例如,DKN(deep knowledge-aware network for news recommendation)模型將實體嵌入和標題嵌入作為不同的初始化特征用于新聞推薦。CKE(collaborative knowledge base embedding for recommender systems)模型將知識圖譜嵌入、文本和圖像結合在一起,通過協同過濾進行統一推薦。知識圖譜嵌入通常適用于進行鏈路預測。
(2)基于路徑的方法中,知識圖譜中包含豐富的實體,這些實體之間存在連接,形成了多條路徑。例如PER(personalized entity recommendation)使 用KG 中元路徑的潛在特征表示在不同關系中用戶和項目的連通性。然而,基于路徑的方法依賴于手動設置元路徑,不利于解決推薦系統中的冷啟動問題。
(3)基于圖的方法將知識圖譜視為一個以某個特定的用戶或項目為中心的異構網絡,從知識圖譜的中心實體向外傳播提取相關實體的特征。例如RippleNet使用偏好傳播方法,很自然地將知識圖譜嵌入與推薦系統相結合,可以不斷自動地發現用戶的潛在層級興趣。
2 HKC 模型
2.1 符號及定義
在一個典型的推薦場景中,用戶集合與項目集合分別用={,,…,u}和={,,…,v}進行表示。用戶與項目的交互矩陣為∈R,它根據用戶的隱式反饋定義為={y|∈,∈},其中:

當y=1 時僅表示用戶和項目之間存在交互,如播放、預覽、購買等行為。此外,知識圖譜由三元組(,,) 構成,其中∈,∈,∈分別表示一個三元組的頭實體、實體間的關系和尾實體,和分別表示中的實體集合和關系集合。比如:在電影知識圖譜中一個三元組(王硯輝,參演,我不是藥神)表示王硯輝參演了電影《我不是藥神》。
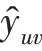
2.2 HKC 模型的框架
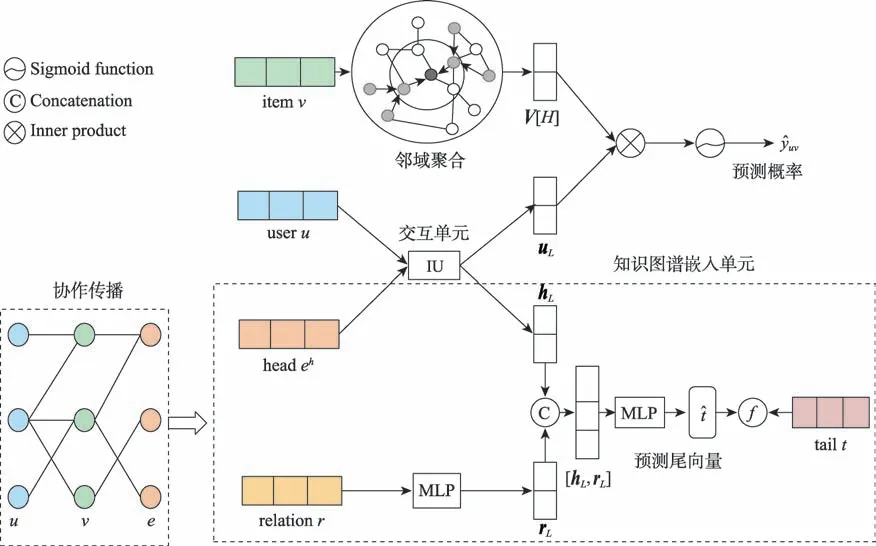
圖1 HKC 模型結構Fig.1 Framework of HKC
整個HKC 模型的框架如圖1 所示。HKC 模型主要由四部分組成:鄰域聚合、協作傳播、交互單元和知識圖譜嵌入單元。圖1 中項目的鄰域聚合操作,通過KGCN算法在知識圖譜中找到項目對應的實體以及鄰居實體,最后將項目實體的鄰居實體及其本身進行聚合,得到項目的特征向量。圖1 下半部分分別為協作傳播和知識圖譜嵌入單元。其中協作傳播操作通過對用戶的歷史記錄查詢得到用戶交互過的項目集合,然后通過項目與實體的對比得到知識圖譜中與用戶相關的實體集合。知識圖譜嵌入單元使用多層感知機(multilayer perceptron,MLP)和交互單元(interaction unit,IU)分別提取知識圖譜中實體間的關系特征和頭實體特征,在分數函數和真實尾實體的監督下輸出預測的尾實體向量。圖1 中間的交互單元以用戶和與之關聯的實體作為輸入,實現用戶和實體之間的信息共享,輸出用戶特征向量和頭實體特征向量。最后將用戶和項目特征向量通過向量內積運算得到預測概率。
2.3 基于鄰域信息的項目特征提取
本文采用KGCN 算法對項目及其鄰居節點進行聚合。KGCN算法利用圖卷積技術將知識圖譜中節點的鄰域信息建模為接收域,以豐富實體節點信息。
KGCN 算法的主要思想是對于給定的知識圖譜中的實體,有偏差地聚合其鄰居節點信息。對于給定的用戶和項目,()表示與直接相連的實體集合,r表示實體e和e之間的關系,利用函數計算用戶與關系之間的得分:

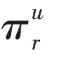

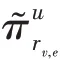

計算項目實體的鄰域表示時,歸一化的用戶-關系得分可以作為用戶的偏好權重,基于用戶偏好權重對項目的鄰域進行加權求和。
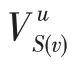
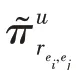
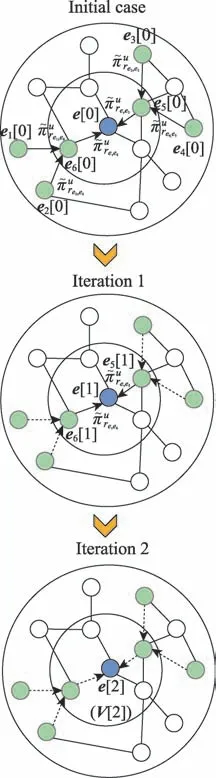
圖2 鄰域聚合Fig.2 Neighborhood aggregation
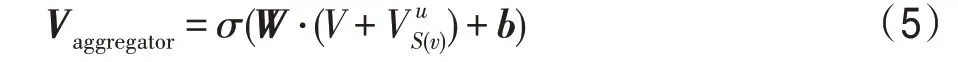
其中,和分別表示權重和偏置,為非線性函數。
2.4 基于交替學習的用戶特征提取
用戶的歷史交互項目在一定程度上可以表示用戶的偏好特征,通過用戶的歷史交互記錄可以得到與用戶相關的項目集合,再通過項目與實體之間的對應關系,得到知識圖譜中相關實體集合。用戶的實體集合()定義為:
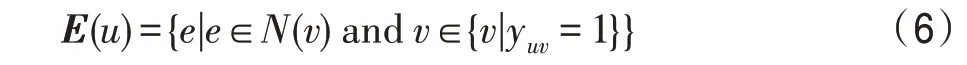
在交互單元中,首先構建用戶和其對應實體之間的交互特征矩陣I:
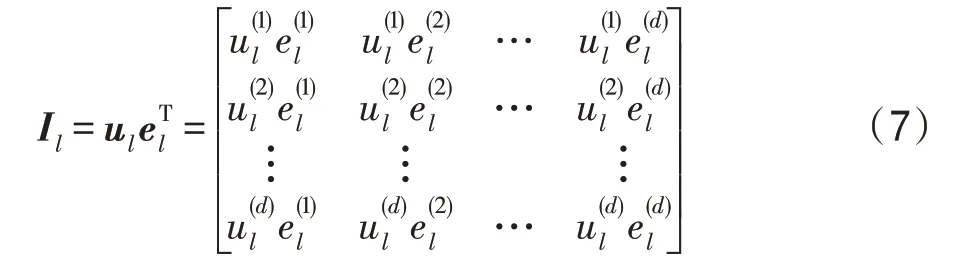
其中,特征向量u∈R和e∈()分別表示第層的用戶和實體,表示隱藏層的維度。然后,進行壓縮操作,交互特征矩陣沿水平和垂直方向進行轉換:
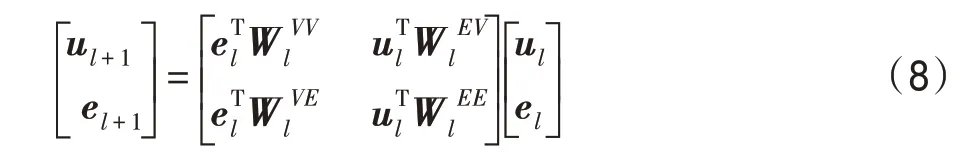
其中,∈R表示神經網絡的權重。本文基于MKR模型中交叉壓縮單元,將壓縮公式去除了參數偏置進行優化,壓縮操作將交互特征矩陣的維度從R降到R,輸出的結果分別為用戶特征向量和實體特征向量。最終將交互單元操作表示為:

交互單元實現了用戶與知識圖譜嵌入單元中實體之間的信息共享,自動控制兩個任務模塊的交叉知識轉移。
知識圖譜嵌入單元的輸入為通過協作傳播得到的與用戶相聯系的知識圖譜。使用交互單元和多層感知機分別提取頭實體和實體間關系的特征,得到頭實體特征向量h和實體間的關系的特征向量r:

其中,后綴[]表示交互單元輸出結果的實體特征向量;I表示層的交互單元計算;M表示層的多層感知機操作:
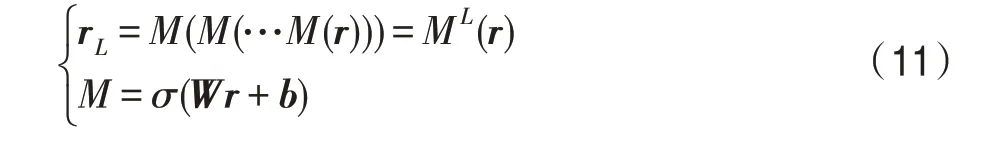
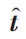


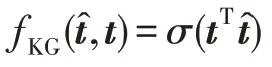
2.5 模型預測
HKC 模型的輸入為用戶-項目交互矩陣和知識圖譜信息。通過層交互單元操作得到用戶的特征向量u:

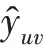

其中,為sigmoid 函數。
HKC 模型的完整損失函數定義如下:
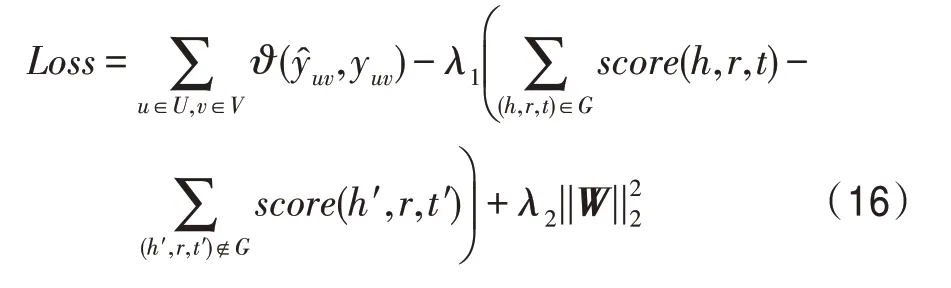
上述公式中,第一項測量模型真實概率和預測概率的損失值,表示交叉熵損失函數。第二項測量知識圖譜嵌入單元的損失值,′和′是對知識圖譜的負采樣。最后一項是正則化項,防止過擬合,和為超參數。
2.6 算法流程


第1 行至第3 行是數據準備階段。在每次的訓練迭代中包含兩個階段:模型預測和知識圖譜嵌入單元。第5 行到第10 行是模型預測,第11 行至第14行是知識圖譜嵌入單元。
首先進行次模型預測,在每輪預測中鄰居采樣算法的時間復雜度為(+lg),為輸入參數()中的實體個數,通過鄰域聚合計算項目的特征向量的時間復雜度為(YHK+YHKd),其中為用戶-項目交互次數,為項目鄰居的最大接受域層數,為鄰域的采樣大小,為特征維度。因此算法1的時間復雜度為(+lg+YHK+YHKd)。
3 實驗及分析
本文的實驗環境:Windows 10,64 位操作系統,Pycharm2020,IntelCorei7-10700k CPU@2.90 GHz,16 GB 內存,python 3.8。本文的深度學習框架為TensorFlow。
本章給出HKC 模型在三個數據集上的實驗結果,與另外七個代表性模型進行推薦性能的對比。首先介紹實驗中使用的三個數據集,以及評價指標和對比模型;其次給出CTR(click through rate)預測結果以及Top-的推薦結果;然后討論不同優化器對模型性能的影響和模型中的超參數的設置;最后分析稀疏性場景中的模型性能。
3.1 數據集
MovieLens-1M:MovieLens-1M 在電影推薦系統中應用較為廣泛。本文的電影數據集大小為1 MB,包括6 040 個用戶對于3 900 部電影的1 000 209 個評分,用戶對電影的評分范圍為1~5。Book-Crossing:Book-Crossing 數據集由德國自由堡大學于2005 年發布,包括一百多萬條用戶對書籍的顯示評分記錄,其評分范圍為0~10。Last.FM:包含2 000 名用戶通過Last.fm 在線音樂系統收聽的信息記錄。
本文在進行實驗時對數據集進行了預處理。首先在MovieLens-1M 數據集中,如果用戶對電影的評分大于等于4,則將用戶與評分電影的交互標記為1,反之為0。其次對于Book-Crossing和Last.FM 兩個數據集,只要用戶對交互的項目進行了評分,則將交互標記為1,否則為0。知識圖譜使用的是MKR模型中構建的知識圖譜。三個數據集的基本信息如表1所示。
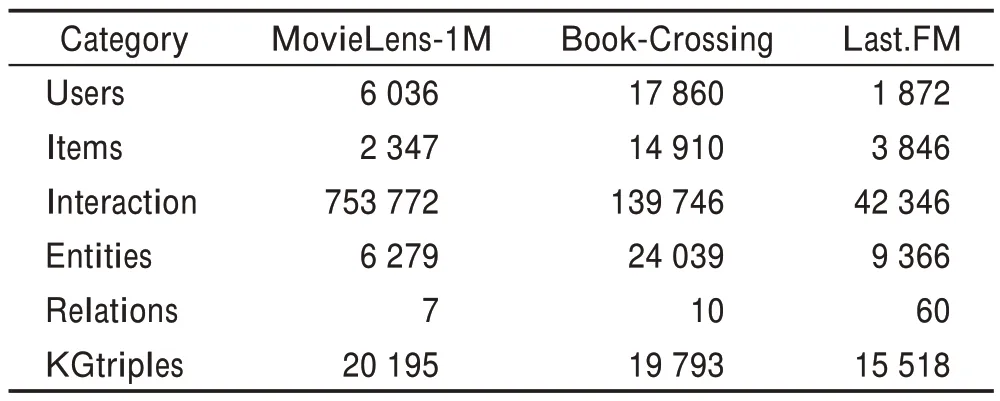
表1 三個數據集的基本統計數據Table 1 Basic statistics of three datasets
3.2 評價指標
在CTR 預測實驗中,本文用正確率(accuracy,ACC)和ROC(receiver operating characteristic curve)曲線下的面積(area under curve,AUC)作為評價指標;在Top-推薦中,使用精確率(Precision@)和召回率(Recall@)作為評價指標來衡量推薦結果。
ACC 指標表示識別正確的樣本數量占總數量的比例。AUC 指標是對ROC 權限的量化,是一個概率值,AUC 值越大表示算法性能越好。Precision 指標表示實際的正樣本數量占神經網絡認為是正樣本的數量的比例。Recall 指標表示神經網路識別出來的真正的正樣本占實際的正樣本的比例。
3.3 對比模型
(1)LibFM:一種用于CTR 場景基于特征的因式分解模型,將用戶ID 和項目ID 以及通過TransR 算法學習的相應實體嵌入連接作為模型的輸入。
(2)DKN:Wang 等人提出的一種利用知識圖譜進行新聞推薦的框架,將實體嵌入和詞嵌入視為多個通道并將它們組合在卷積神經網絡中進行點擊率預測。
(3)KGNN-LS(knowledge-aware graph neural networks with label smoothness regularization for recommender systems):Wang 等人提出的一種圖神經網絡模型,使用標簽平滑性損失作為正則化項以防止模型的過擬合。
(4)RippleNet:知識圖譜與推薦系統聯合學習的代表,該模型通過在知識圖譜中進行偏好傳播,不斷自動地發現用戶潛在的層級興趣。
(5)KGCN:Wang 等人提出的一種用圖神經網絡挖掘項目在知識圖譜中的重要性的模型。
(6)MKR:Wang 等人提出的一種采用交替學習的方式,使用知識圖譜嵌入任務來輔助推薦任務的深度端到端的框架。
(7)CKAN(collaborative knowledge-aware attentive network for recommender systems):Wang 等人提出的一種協作知識感知注意網絡模型,使用異質傳播策略同時編碼知識屬性關聯和用戶-項目的協同信號。
(8)HKC:本文提出的融合知識圖譜與圖卷積網絡的混合推薦模型。
3.4 實驗設置
在HKC 模型中對于每個數據集,訓練集、驗證集和測試集的比例為6∶2∶2。實驗通過在驗證集上優化AUC 值得到超參數的值,超參數的設置如表2 所示,其中為特征維度,為隨機采樣的鄰居節點個數,為鄰域聚合中接收域的層數,為模型預測單元的訓練次數。
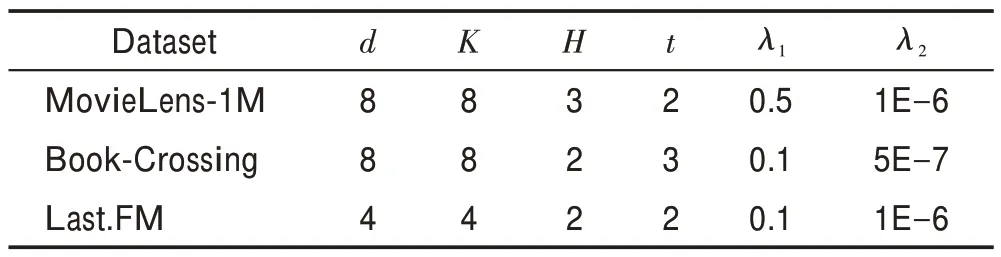
表2 HKC 模型的超參數設置Table 2 Hyper-parameter settings of HKC
3.5 實驗結果分析
為了驗證HKC 模型的有效性,本文將HKC 模型與另外七個代表性模型進行對比。
各模型在三個數據集上的CTR 預測結果如表3所示。
(1)在MovieLens-1M 數據集中,HKC 模型相較KGNN-LS、RippleNet 和CKAN 模型在AUC 指標 上分別提高了0.94%、0.25%和0.77%,在ACC 指標上分別提高了0.99%、0.78%和0.98%。HKC 模型相較KGCN 和MKR 模型在AUC 指標上分別提高了1.72%、0.75%,在ACC 指標上分別提高了2.11%、0.81%,說明了HKC 模型結合項目鄰域特征的有效性。對比MKR 模型,本文模型有效利用了知識圖譜中實體間的鄰域關系,并且相比KGCN 模型可以有效提取用戶特征。
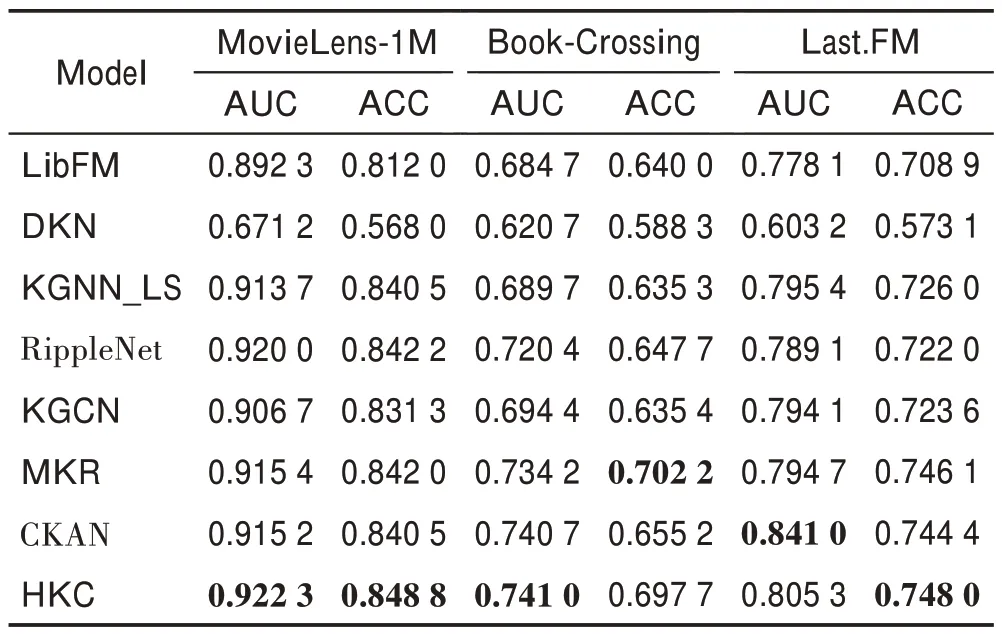
表3 CTR 預測中的AUC 和ACC 結果Table 3 Results of AUC and ACC in CTR prediction
(2)在MovieLens-1M 數據集中,HKC 模型相較LibFM、DKN 模型在AUC 指標上分別提高了3.36%、37.41%,在ACC 指標上分別提高了4.53%、49.44%。在三個數據集上,LibFM 和DKN 模型的推薦性能明顯低于其他模型,說明與傳統的使用TransR、TransD等基于嵌入的模型相比,其他基于圖的知識圖譜模型可以更加有效地利用知識圖譜中的信息。
(3)HKC 模型在MovieLens-1M 數據集上推薦性能有明顯提升,在另外兩個數據集上提升不明顯。由于Book-Crossing和Last.FM兩個數據集的稀疏性,HKC在聚合項目的鄰居節點特征時容易引入噪聲,而在用戶-項目交互相對稠密的MovieLens-1M 數據集上,知識圖譜信息更加豐富,起到的推薦效果作用更大。
為了驗證本文的知識圖譜嵌入單元和交互單元的改進對模型推薦性能提升的有效性,設計消融實驗進行對比,實驗結果如表4 所示。
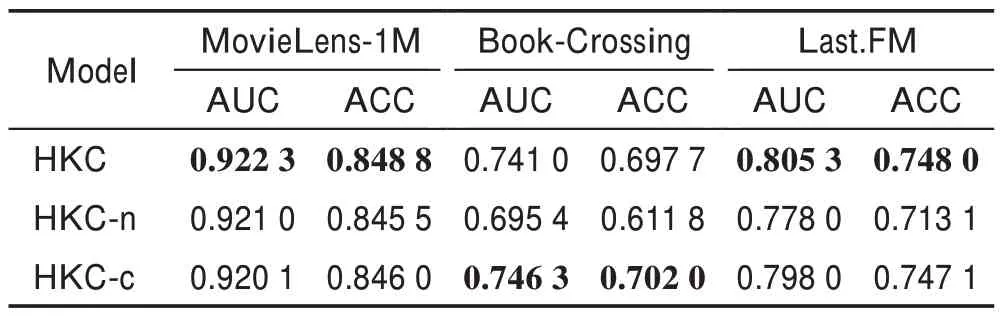
表4 模型消融研究Table 4 Model ablation study

圖3 三種數據集上Top-K 推薦的精確率Fig.3 Precision@K in Top-K recommendation on three datasets
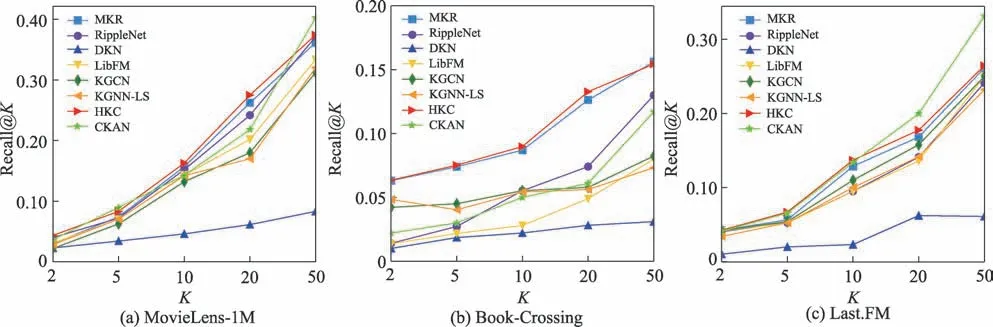
圖4 三種數據集上Top-K 推薦的召回率Fig.4 Recall@K in Top-K recommendation on three datasets
(1)模型HKC-n 表示本文算法僅使用鄰域聚合模塊對項目進行特征提取,未使用交互單元提取用戶特征。使用基于知識圖譜嵌入的交互單元的模型HKC 較未考慮用戶特征的模型HKC-n 在三個數據集上的算法性能均有提升。在MovieLens-1M 數據集上,AUC 和ACC 分別提升0.14%和0.39%;在Book-Crossing 數據集上,AUC 和ACC 分別提升6.56%和14.04%;在Last.FM 數據集上,AUC 和ACC 分別提升3.51%和4.89%。由此可知,本文利用交互單元可以有效提取用戶的偏好信息,建模用戶之間的相關性,提高模型的推薦性能。
(2)模型HKC-c 表示本文算法的交互單元未進行簡化,使用簡化的交互單元模型HKC較模型HKC-c在MovieLens-1M 和Last.FM 數據集上,AUC 和ACC值均有提升。可得出模型HKC 對交互單元進行簡化可以提升算法的有效性。
3.5.3 Top- 推薦
討論不同模型在取不同值時對于Precision 的表現,在三個數據集上進行實驗,如圖3 所示。
從圖3 中可以看出,在三個數據集上,隨著值的增加,幾個模型的精確率值都呈下降的變化趨勢。其中LibFM 和DKN 兩個模型使用基于嵌入的知識圖譜算法,在實驗結果中低于其他使用基于圖的方法的知識圖譜模型,表明了基于圖的方法有助于提升推薦模型的性能。在MovieLens-1M 數據集上,當=5 時,HKC 模型的精確率有明顯提升,且HKC 模型的精確率明顯高于KGCN 模型,表明模型有效提取了用戶的特征向量。在Book-Crossing 數據集上,本文模型的推薦性能相對于MKR 模型表現較差。在Last.FM 數據集中,當值大于5 時,HKC 模型的推薦性能下降,其精確率值低于MKR 模型,在較為稀疏的Last.FM 數據集中,HKC 模型更有利于為用戶進行精準推薦。
討論不同模型在取不同值時對于評估標準Recall的表現,在三個數據集上進行實驗,如圖4所示。
從圖4 中可以看出,在三個數據集上,隨著值的增加,幾個模型的Recall 值都呈上升的變化趨勢。其中在MovieLens-1M 中,=20 時,召回率提升明顯,較MKR 模型和KGCN 模型分別提升了4.88%和52.78%。HKC 模型在三個數據集上的召回率指標均高于KGNN-LS 和RippleNet 知識圖譜模型,這說明了結合項目的鄰域特征進行交替訓練的有效性,證明了本文提出的HKC 模型在推薦中的優越性。在Last.FM 數據集上,CKAN 模型的召回率最高,說明本文模型在稀疏性數據集上的推薦性能有待提升。
3.6 不同優化器對模型性能的實驗分析
機器學習中,尋求模型的最優解的時候可以選取不同的優化器,本文在MovieLens-1M 數據集上進行實驗,分析使用不同優化器對HKC 模型性能的影響。實驗結果如表5 所示,從表中可以發現,當優化器選擇使用Adam 時,HKC 模型的AUC 和ACC 的值最高,說明其有利于提升模型的推薦性能;其次是SGD,但其收斂速度較慢。說明了本文HKC 模型使用Adam 算法的有效性。
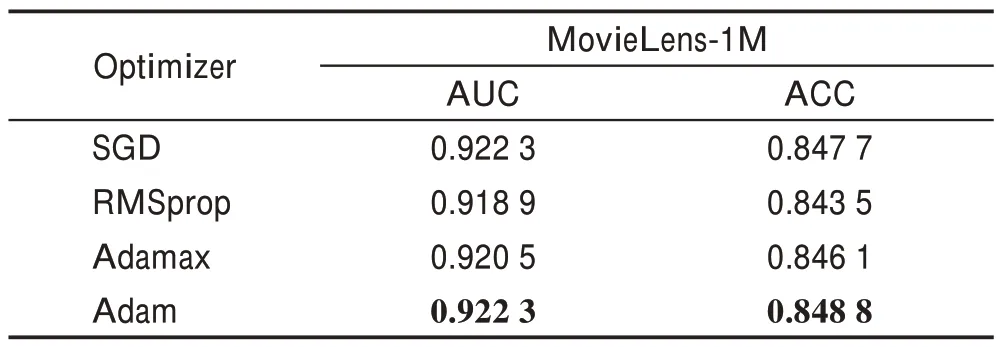
表5 不同優化器對HKC 模型性能的研究Table 5 Research on performance of HKC model by different optimizers
3.7 超參數敏感性分析
在MovieLens-1M 數據集上分析HKC 模型對嵌入維度、模型預測單元訓練次數和接收域的層數的敏感性。結果如圖5 所示。
嵌入維度對HKC 模型性能的影響如圖5(a)中所示。一開始隨著的增加,模型的性能也相繼增強,這是因為嵌入層的維度越多,可以編碼更多的有用信息。從圖中可以看出,當取值為8 的時候,HKC 模型在MovieLens-1M 數據集上的CTR 預測率達到最佳,但當值繼續增大時,模型的性能反而下降,這是因為過大的會產生過擬合的問題,不利于HKC 模型隨后的推薦預測。
在訓練知識圖譜嵌入單元一次之前,重復訓練模型預測單元的次數的變化對HKC 模型性能的影響如圖5(b)所示。從圖中可以看出,等于2 時HKC模型的性能最好,因為知識圖譜嵌入單元訓練次數過多時會誤導HKC 模型的目標函數,而訓練次數過小則無法充分利用知識圖譜中的有效信息。
本文研究了接收域層數從1 增加到5 對模型性能的影響,結果如圖5(c)所示。從圖中可以看出,HKC 模型對的變化比較敏感,當為3 時,模型的性能達到最優。當繼續增加時,模型的性能下降,這是因為隨著越來越大,會有更多的項目鄰居實體對中心實體的特征表示產生影響,而在鄰居實體中會存在大量的沒有用處的實體,這就引入了大量噪聲,從而導致模型性能下降。而過小的,則使得模型無法充分利用項目的鄰居實體信息,不利于構建項目的特征向量。
3.8 稀疏場景中的實驗分析
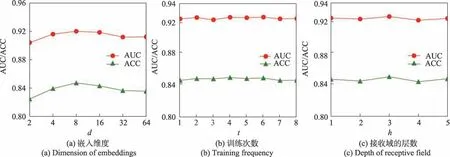
圖5 HKC 模型在MovieLens-1M 上的參數靈敏度Fig.5 Parameter sensitivity of HKC on MovieLens-1M
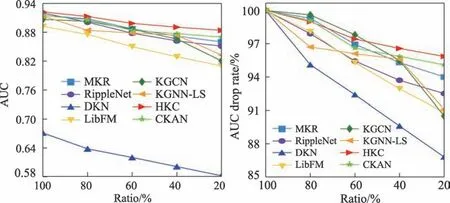
圖6 MovieLens-1M 數據集上稀疏性場景下模型的性能Fig.6 Model performance in sparse scenarios on MovieLens-1M
在推薦系統中使用知識圖譜可以有效緩解數據稀疏性問題。本文在MovieLens-1M 數據集上進行實驗分析,固定驗證集和測試集的大小不變,將訓練集的比率ratio 設置為100%至20%以研究模型性能的變化。圖6 為不同比率訓練集下AUC 值的曲線以及AUC 的下降比率。當ratio=20%時,MKR、Ripple-Net、DKN、LibFM、KGCN、KGNN-LS 和CKAN 七個基線模型的AUC 值分別下降了6.01%、7.50%、13.26%、9.19%、9.52%、8.87%和4.92%;HKC 模型僅降低了4.15%,表明在數據稀疏場景下,對比其他基線模型,HKC 模型仍舊具有良好的推薦性能。同時可以看出,在稀疏場景中,基于知識圖譜的推薦模型的性能優于傳統的推薦模型,說明知識圖譜可以有效緩解數據稀疏性問題。
4 結束語
針對多數基于知識圖譜的推薦模型沒有充分考慮到用戶與實體之間的信息交互,忽略了知識圖譜中實體間的鄰域關系,本文提出一種融合知識圖譜與圖卷積網絡的混合推薦模型HKC。HKC 模型使用KGCN 算法選擇性地聚合項目的鄰域信息得到項目的特征向量;使用交替學習的方式同時優化模型預測單元和知識圖譜嵌入單元,通過交互單元計算得到用戶的特征向量;最后根據訓練得到的用戶特征向量和項目特征向量計算內積,為用戶進行推薦。在三個公開數據集上進行實驗,并將HKC 模型與七個基準模型進行對比,實驗表明HKC 模型在推薦效果上有提升,模型的推薦性能優于其他基線模型。
HKC 模型中的知識圖譜是靜態的,現實生活中用戶的喜好會隨著時間產生變化,知識圖譜也會隨著時間的變化發生改變,因此未來也將重點研究如何利用時間信息動態地構建用戶和項目的特征。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
