基于卷積神經網絡的馬鈴薯芽眼檢測識別研究*
2022-06-20 03:10:20史方青王虎林黃華
中國農機化學報 2022年6期
史方青,王虎林,黃華
(蘭州理工大學機電工程學院,蘭州市,730000)
0 引言
馬鈴薯具有極高的營養與藥用價值,其加工產品被廣泛應用于我國醫藥、農業、食品等行業。2019年農業農村部指出要大力推進馬鈴薯主食開發,明確了馬鈴薯產業的國家糧食安全策略、農業供給側結構性改革中的作用及目標[1]。馬鈴薯產業的機械化水平逐年提高,如馬鈴薯播種機械化[2]及馬鈴薯分級機械化[3]等。然而有關馬鈴薯切種機械化的研究較少,且主要依賴于人工,存在勞動力短缺、效率低、費用較高等問題,故實現馬鈴薯切種機自動切種是必然需求,芽眼的準確識別是該功能實現的前提。
芽眼識別是馬鈴薯切種機實現自動切種的先決條件,但目前國內外針對芽眼識別的研究卻相對較少。李玉華等[4]在三維幾何空間內通過對S分量的分析,利用四特征綜合判定準則對芽眼縱向識別,并根據芽眼的橫向特點進行篩選,結果表明該方法的識別準確率可達91.48%;呂釗欽等提出一種基于Gabor特征的馬鈴薯芽眼識別方法,結果表明該方法的識別準確率為93.4%;Xi等[5]通過將混沌變量映射到K均值算法的變量中,用混沌變量代替其尋找全局最優值,結果表明芽眼總的分割精度為98.87%。上述方法均為淺層特征提取,無法適應隨機條件下的馬鈴薯芽眼識別,判別能力相對較弱,均無法同時保證檢測性能及識別速度。
卷積神經網絡以其高性能特征提取、覆蓋范圍廣、適應能力強等優點,被廣泛應用于農業中[6-8]。目前深度卷積神經網絡已發展為兩大類,其一為兩階段處理模型,如Faster R-CNN[9]、Mask R-CNN[10]等,其二為端到端的一階段處理模型,如SSD[11]、YOLO[12-14]系列等。席芮等[15]通過對Faster R-CNN網絡的改進實現了馬鈴薯芽眼的識別,結果表明該模型識別精度為96.32%,召回率為90.85%;劉小剛等[8]在復雜環境中通過改進的YOLOv3網絡連續識別草莓,結果表明該模型針對測試集的mAP值可達87.51%;趙德安等[16]通過YOLOv3網絡對不同光線環境中存在遮擋、粘連及套袋等多種情況的果實進行了識別定位,結果表明該模型識別準確率為97%,召回率為90%。
基于上述分析,本文提出基于卷積神經網絡的馬鈴薯芽眼識別方法。通過自然光條件下拍攝的圖像建立數據庫,經過圖像預處理及數據增廣擴充數據集以增加網絡的魯棒性。在YOLOv3網絡的高性能特征提取下,經過卷積、上采樣等操作實現馬鈴薯芽眼的快速、準確識別,為馬鈴薯切種機自動切種奠定了基礎。
1 材料與方法
1.1 圖像采集及預處理
為了識別馬鈴薯芽眼,需采集相關圖像建立數據庫,包括訓練集、驗證集及測試集。本文測試用馬鈴薯出自甘肅省永昌縣,品種為大西洋。為了使馬鈴薯芽眼識別環境貼近現實,選擇于自然光良好的環境中對含有芽眼的馬鈴薯進行多方位拍攝,以貼合后期馬鈴薯切種機芽眼識別時的環境。圖像采集設備為數碼單反相機,型號為NikonD3400。初始采集圖像并篩選得到圖像630張,均為jpg格式。為了提高處理效率并減少數據運算量,將圖像大小壓縮為600像素×800像素。為了擴充數據集,通過對原始圖像進行裁剪、旋轉、縮放、色度增強等數據增廣操作,單種處理或者多種組合處理以得到馬鈴薯芽眼數據集,數據增廣結果如圖1所示。

圖1 數據增廣結果
對每一張馬鈴薯芽眼圖像使用LabelImg工具進行手動標注,如圖2所示。其中矩形框用于馬鈴薯芽眼的識別,統一保存為PASCAL VOC格式,使用的注釋為PASCAL VOC中xml文件,最終獲得6 072張圖像。其中測試集608張,訓練集5 464張,驗證集于訓練集中隨機選取,最終驗證集與訓練集比例呈1∶9。

圖2 數據標注
1.2 YOLOv3網絡模型
1.2.1 YOLO系列模型
YOLO系列模型是目前比較流行的算法之一,它不同于兩階段處理模型,該系列模型均為端到端的一階段處理模型。YOLOv1[12]網絡結構較為輕量,但存在識別物體精準性較差、召回率不高、較小目標和鄰近目標識別效果不佳等問題;YOLOv2[13]網絡使用了Darknet-19網絡,并引入BN層加速模型收斂,模型中均采用卷積層與先驗框,去掉了以往含有的全連接層。同時采用了k-means聚類直接預測網格單元的相對位置,一定程度上提高了模型的識別準確度;YOLOv3[14]網絡在YOLOv2的基礎上做了進一步的提升,使用了分類器Darknet-53以及多尺度預測,在類別預測方面將原來的單標簽分類改為了多標簽分類。上述變化不但增強了網絡的提取能力,而且在進一步提高小目標檢測精度的基礎上加快了網絡的運算速度。YOLOv3網絡的訓練測試流程如圖3所示。

圖3 訓練測試流程
1.2.2 YOLOv3模型結構
YOLOv3網絡通過回歸方法提取目標特征,直接使用單個神經網絡實現輸入圖像的目標檢測識別與分類。其為深度卷積神經網絡YOLO的改進,具有實時性、泛化能力強以及準確度高等優點,是目前主流的檢測算法之一。
表1為YOLOv3模型與其他模型均在COCO數據集上測試的速度與精度對比[15]。

表1 YOLOv3模型與其他模型對比Tab. 1 Comparison of YOLOv3 model with other models
由表1可以看出,YOLOv3模型檢測速度相較于其他模型快,本文綜合比較模型的輸入尺寸后,可知YOLOv3-320模型輸入尺寸小、用時少,但精度欠佳;YOLOv3-608模型檢測精度高,但輸入圖像尺寸大,處理用時長;YOLOv3-416模型檢測精度較高,檢測精度及測試時長較為合適,在保持檢測精度的基礎上也確保了較少的處理時長。因此,結合本文測試平臺的顯卡及內存要求,選擇用YOLOv3-416模型進行芽眼的準確識別。
YOLOv3網絡結構如圖4所示,DBL層(Darknetconv2d-BN-Leaky)為YOLOv3網絡的基本組件,由卷積(CONV)、批量歸一化(Batch normalization)、Leaky ReLU操作組成。普通的ReLU函數是將所有負值均設為零,而Leaky ReLU函數則是給所有負值賦予一個非零斜率,數學表達式為
(1)
式中:ai——(1,+∞)區間內的固定參數。
本文中YOLOv3網絡的初始輸入大小為416×416的圖像,通過多層深度卷積降維,最終降維為3個維度,即有3個分支,由多尺度檢測y1、y2、y3組成,如圖4所示。其中,多尺度檢測y1適用于大目標檢測,輸出維度為13×13×18;多尺度檢測y2適用于中目標的檢測,輸出維度為26×26×18;多尺度檢測y3適用于小目標的檢測,輸出維度為52×52×18。Resn表示Res_block含有多少個Res_unit,n代表數字,如res1,res2等。YOLOv3借鑒了ResNet的殘差結構,其中殘差卷積就是進行一次3×3、步長為2的卷積。保存卷積層后再進行一次1×1的卷積和3×3的卷積,將該結果與最后的卷積層一同作為最后的輸出。同時由于ResNet擁有較深的網絡結構,為提高準確度使用了殘差單元以獲得高維特征。Res_unit×n表示含有n個殘差單元;concat表示張量拼接,即將Darknet的中間層與后面某一層的上采樣拼接,以擴充張量的維度;Add表示張量相加,不擴充維度。
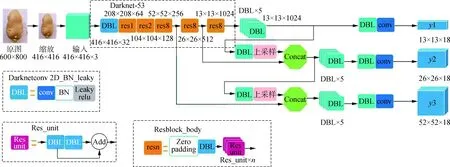
圖4 YOLOv3結構圖
YOLOv3網絡預測圖片方式采用端對端的檢測,其將整張圖片分為S×S個區域,當被識別對象的中心落在上述任意區域時,對應的網絡會進行預測,目標邊界框原理圖如圖5所示。其中,虛線矩形框表示預設邊界框,實線矩形框表示以YOLOv3網絡預測的偏移量計算的預測邊界框,由預設邊界框到最終預測邊界框的轉換如式(2)~式(5)所示。
bx=σ(tx)+cx
(2)
by=σ(ty)+cy
(3)
bw=pwetw
(4)
bh=pheth
(5)
其中,(cx,cy)表示預設邊界框在特征圖上的中心坐標,(pw,ph)表示預設邊界框在特征圖上的寬與高,(tx,ty)表示YOLOv3網絡預測邊界框的中心偏移量,(tw,th)表示網絡預測邊界框的寬高縮放比,(bx,by,bw,bh)為最終預測的目標邊界框。且σ(x)函數可以將預測偏移量縮放在0~1之間,從而加速收斂。
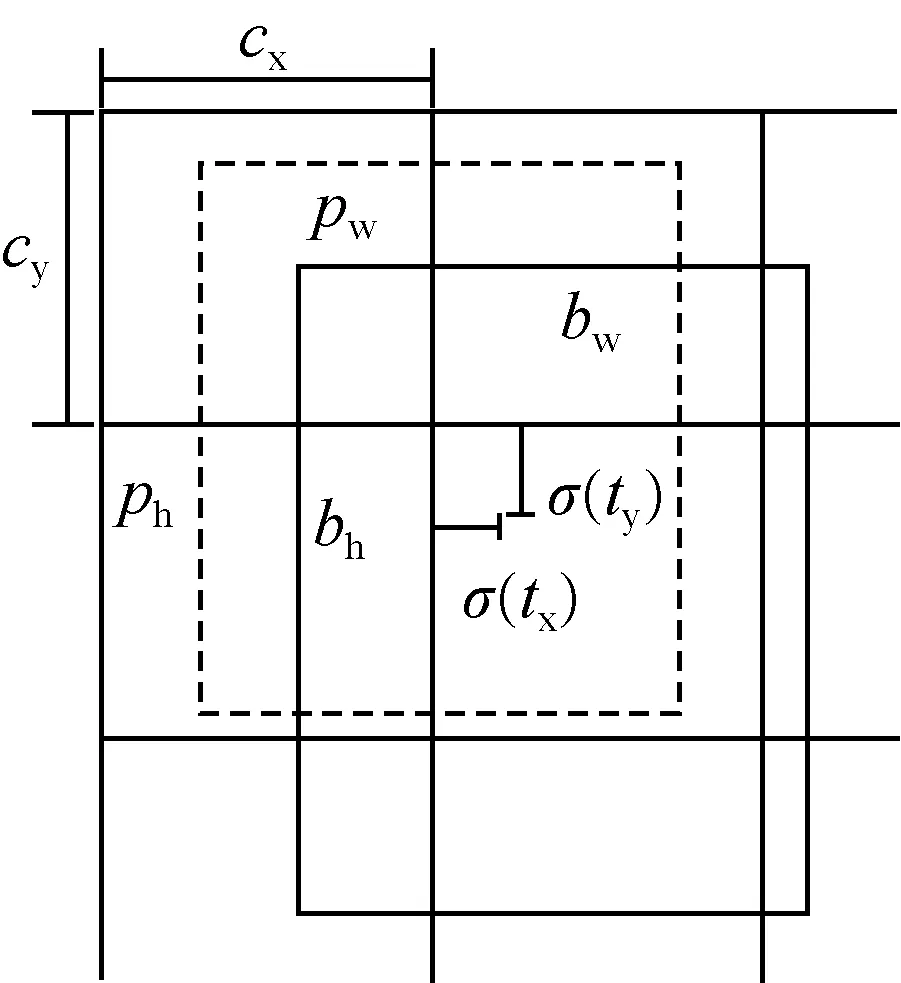
圖5 YOLOv3邊界框原理圖
1.3 評價指標
本文為了更好地評估訓練模型的魯棒性及準確性,測試選擇精度(Precision)和召回率(Recall)作為評價指標。相應的計算公式如式(6)~式(8)所示。
(6)
(7)
(8)
式中:Tp——真正樣本數;
Fp——假正樣本數;
FN——假負樣本數;
R——召回率;
P——精確度;
F1——精確度P和召回率R的調和平均值。
為了更詳細評價識別馬鈴薯芽眼的訓練模型,測試同時選擇識別平均精度mAP值進行評價。mAP值即每個類別AP的平均值,AP為P-R曲線下方整體的面積,具體計算如式(9)所示。
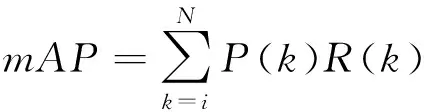
(9)
式中:k——閾值;
N——引用閾值的數量。
金元時期的詞學是對南北宋詞學理論的發展。王若虛認為詞本色如詩,其《滹南詩話》卷中:“蓋詩詞只是一理,不容異觀。”[7]669元好問推崇詩詞同質,其《新軒樂府引》稱贊蘇軾以詩化詞的“一洗萬古凡馬空”的氣象。
2 試驗結果與分析
2.1 試驗平臺
本文馬鈴薯芽眼識別測試平臺使用windows10(64位)專業版,NVIDIA GeForce RTX 2080 GPU顯卡加速測試進程,32 GB內存,10核20線程計算機處理器,2.4 GHz,使用python3.6.2版本,以pytorch1.2版本為處理框架,以cuda10.0版本的計算框架及cuDNN7.6.3版本的配置加速庫,在VScode調試平臺上進行。
2.2 模型訓練過程
本文采用YOLOv3網絡實現馬鈴薯芽眼的識別檢測,需訓練得到最優模型權重,故訓練前期需設置相關參數并進行調整,網絡參數選擇及訓練策略具體如下。
1) 參數設置:選擇基于模型參數的遷移學習實現網絡的訓練,預訓練模型使用PASCAL VOC數據集的通用模型,設置訓練epoch為100次,動量因子設置為0.92,衰減系數設置為5×10-4。學習率調整策略采用steps,前50個epoch訓練凍結一部分網絡進行,初始學習率設置為1×10-3,批處理尺寸設置為8;后50個epoch訓練將前期凍結的網絡部分解凍,全部進行訓練,初始學習率設置為1×10-4,批處理尺寸設置為4。
2) 訓練策略:網絡訓練過程采用多尺度訓練策略,初始統一裁剪圖片大小為416像素×416像素,均使用padding填充,使圖像不失真。同時通過調整色度、色調、增加透視變幻等方式再次生成更多樣本,增加網絡模型識別檢測的準確度及魯棒性。
2.3 結果分析
本研究以相同的數據集于同一試驗平臺上試驗,對YOLOv3、YOLOv4-tiny、Faster R-CNN及SSD模型進行訓練,同時以相同的測試集進行識別對比分析,具體定量識別結果如表2及表3所示。
由表2可知,YOLOv3模型識別馬鈴薯芽眼最終精確度P為97.97%,召回率R為96.61%,調和平均值F1為97%。相較于YOLOv4-tiny、Faster R-CNN及SSD這三種模型,馬鈴薯芽眼的識別精確度P較前兩種分別提升了4.64個百分點和27.59個百分點。召回率R較這三種模型則分別提高了8.79個百分點,3.43個百分點以及31.8個百分點,尤其較SSD模型提升優化較高。最終縱觀調和平均值F1,YOLOv3模型達到97%,分別高于其他三種模型7個百分點,17個百分點及19個百分點,相比較而言均有較大的性能提升。
由表3可知,YOLOv3模型識別平均精度mAP值高達98.44%,平均每幅圖像的識別時間為0.018 s。相比較于YOLOv4-tiny、Faster R-CNN及SSD這三種模型,平均檢測精度分別提升了5.81個百分點,7.71個百分點以及6.68個百分點,平均每幅圖像的識別時間差距不大。由此可以看出,使用YOLOv3模型識別馬鈴薯芽眼的綜合性能均比較優良,具有更高的魯棒性和精確性。
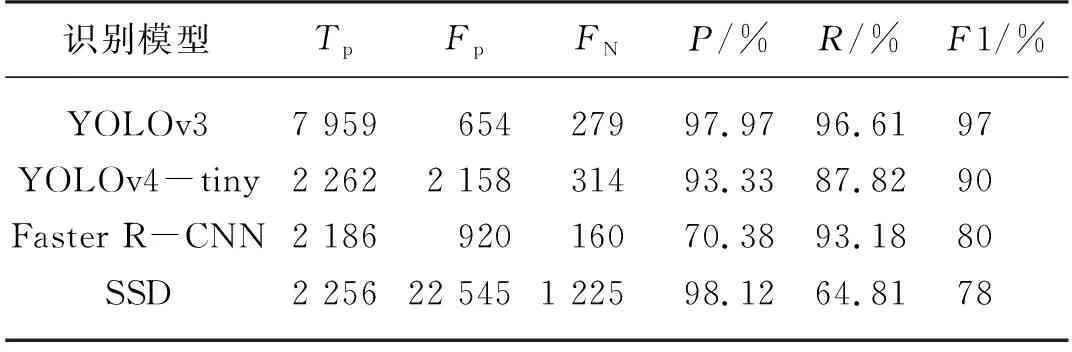
表2 馬鈴薯芽眼識別結果比較Tab. 2 Comparison of potato buds recognition results
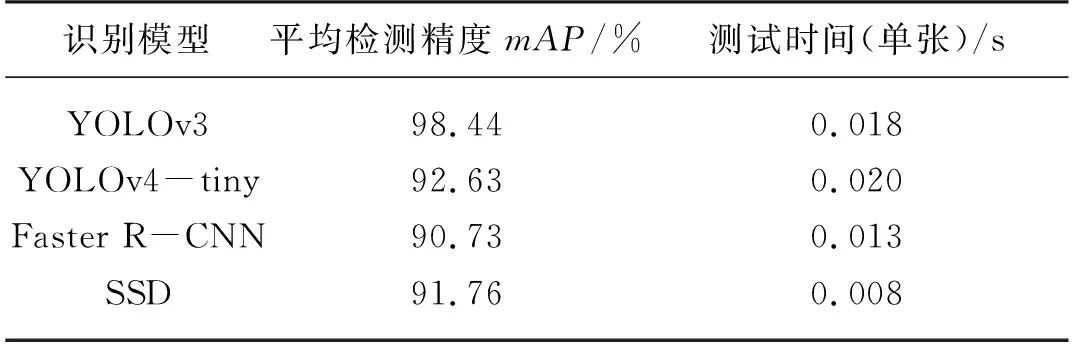
表3 同一測試集下不同識別模型的mAP值Tab. 3 mAP values of different recognition modelsunder the same test set
使用YOLOv3、YOLOv4-tiny、Faster R-CNN及SSD模型對馬鈴薯芽眼識別結果的P-R曲線如圖5所示。由表3可知,YOLOv3模型的識別平均精度mAP值高達98.44%,其余三種模型的識別平均精度mAP值均在90%左右,P-R曲線已經基本遍布整個坐標系。相較于其他三種模型,YOLOv3模型的P-R曲線相對平滑且穩定,從圖5可以看出YOLOv3基本處于曲線最上方。綜上所述,YOLOv3模型整體綜合性能指標要優于其他三種模型。
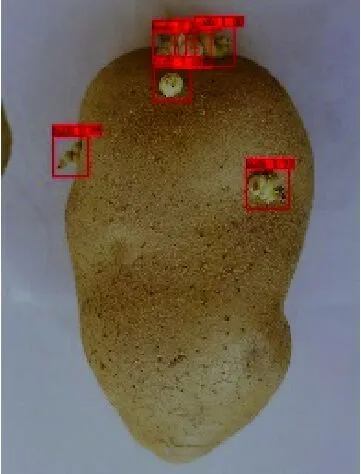
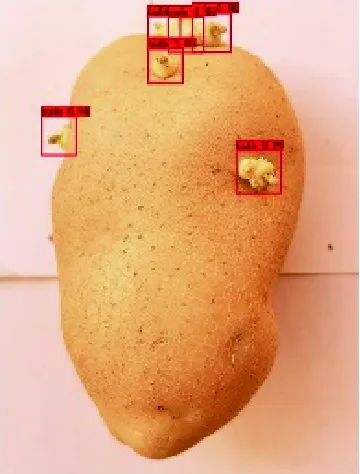
為了更清晰地顯示YOLOv3網絡優良的識別結果,將識別結果可視化如圖6、圖7所示。圖6(a)為只含有單個無遮擋芽眼的樣本識別結果,圖6(b)為含有多個遮擋芽眼的樣本識別結果,圖6(c)為含有機械損傷、蟲眼及雜質的樣本識別結果。圖7為YOLOv3網絡對馬鈴薯芽眼在不同處理條件下的識別結果。

圖6 部分樣本測試識別結果

原圖 亮度減弱 色度增強


隨機旋轉+鏡像+色度增加+高斯噪聲 高斯噪聲+隨機旋轉+亮度增強
圖6(a)中YOLOv3、YOLOv4-tiny、Faster R-CNN及SSD網絡中芽眼的識別置信度分別為1.00、1.00、1.00、0.98;圖6(b)中YOLOv3、YOLOv4-tiny、Faster R-CNN及SSD網絡中芽眼的識別置信度分別在0.99~1.00、0.80~1.00、0.91~1.00、0.79~0.99之間,且YOLOv3中置信度為1.00的芽眼約占92%,而其他三種網絡中置信度為1.00的芽眼均在92%以下;圖6(c)中YOLOv3、YOLOv4-tiny、Faster R-CNN及SSD網絡中芽眼的識別置信度分別在0.91~1.00、0.79~1.00、0.58~0.99、0.85~0.86之間,且YOLOv3中置信度為1.00的芽眼占60%,其他三種網絡中置信度為1.00的芽眼均在60%以下。綜上所述,YOLOv3網絡不論對單個無遮擋芽眼的樣本,多個有遮擋芽眼的樣本,還是含有機械損傷、蟲眼、雜質等的樣本,識別率均較高,且置信度相對來說處于一個平穩且較高的狀態。而YOLOv4-tiny、Faster R-CNN及SSD模型在識別含有多個有遮擋芽眼的樣本時,雖然基本識別出圖片中芽眼,但識別的置信度相較于YOLOv3網絡低。當檢測識別含有機械損傷、蟲眼、雜質等的樣本時,四種網絡均能在較大程度上識別出芽眼,但YOLOv3網絡明顯識別檢測效果更優,置信度較高。而YOLOv4-tiny、Faster R-CNN及SSD網絡未能在干擾因素較大的情況下識別出所有的馬鈴薯芽眼,識別精度較YOLOv3低。同樣的,由圖7可得,無論圖片進行調整亮度、色度,還是增加高斯噪聲、隨機旋轉等操作,YOLOv3網絡均能較好識別出馬鈴薯芽眼,表明該網絡具有良好的環境適應性。
綜上所述,使用YOLOv3網絡對馬鈴薯芽眼識別的效果較好,且識別時間也較快,滿足處理過程中對機械設備的要求,為馬鈴薯智能切種機的實現奠定了基礎。
2.4 討論
為了實現馬鈴薯種薯智能切塊,需要實現馬鈴薯芽眼的準確、快速識別,實際工作中包含進料給料操作、芽眼識別與標記操作、馬鈴薯種薯三維重建操作、切刀路徑規劃操作及切種實現等步驟,通過控制系統實現調配。首先在投入馬鈴薯種薯后,需實現實時采集圖像,以保證及時完成馬鈴薯芽眼的識別;接著需進行三維重建以實現切種規劃,即將馬鈴薯芽眼識別圖像的位置特征映射于三維重建中,實現芽眼的三維定位;最后,刀具通過由馬鈴薯芽眼位置而確定的切種路徑進行切種。
本文對馬鈴薯芽眼的準確、快速識別做了一定的研究,彌補了目前市面上存在馬鈴薯切種機無芽眼識別功能,最大程度上降低了種薯的浪費率,提高了馬鈴薯種薯的出芽率,為后續自動化切種奠定了基礎。
3 結論
1) 本文針對目前馬鈴薯切種機均無芽眼識別功能的問題,以馬鈴薯切種機于自然光環境下工作為研究背景,利用在實際環境中拍攝到的圖片建立馬鈴薯芽眼數據庫,并搭建了YOLOv3網絡實現馬鈴薯芽眼的快速、準確識別。
2) 在自然光下拍攝RGB圖像,對拍攝到的圖像進行預處理,通過裁剪、旋轉、縮放、色度增強等操作,單一或者多個組合實現了數據增廣,以此建立了馬鈴薯芽眼數據庫,包括含有單個無遮擋芽眼的樣本、含有多個遮擋芽眼的樣本以及含有機械損傷、蟲眼及雜質的樣本這三類。
3) YOLOv3網絡在面向含有單個無遮擋芽眼的樣本,含有多個遮擋芽眼的樣本以及含有機械損傷、蟲眼及雜質的樣本這三類不同樣本時,均能夠快速準確地檢測識別出馬鈴薯芽眼,效果優于YOLOv4-tiny、Faster R-CNN及SSD網絡。
4) YOLOv3網絡使用測試集測試時,精確度P為97.97%,召回率R為96.61%,調和平均值F1為97%。相較于YOLOv4-tiny、Faster R-CNN及SSD這三種網絡,馬鈴薯芽眼的識別精確度較前兩種分別提升了4.64個百分點和4.05個百分點。且召回率分別提高了8.79個百分點,10.42個百分點以及31.8個百分點;平均檢測精度mAP值高達98.44%。綜合P-R曲線的效果,可知YOLOv3網絡的綜合識別檢測性能優于YOLOv4-tiny、Faster R-CNN及SSD網絡,達到了馬鈴薯切種機實現自動化切種的識別要求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
