農業文本語義理解技術綜述
2022-06-21 08:20:14吳華瑞王郝日欽黃素芳
農業機械學報 2022年5期
吳華瑞 郭 威 鄧 穎 王郝日欽 韓 笑 黃素芳
(1.國家農業信息化工程技術研究中心, 北京 100097; 2.北京市農林科學院信息技術研究中心, 北京 100097;3.農業農村部數字鄉村技術重點實驗室, 北京 100097; 4.北京市農林科學院智能裝備技術研究中心, 北京 100097;5.滄州市農林科學院, 滄州 061001)
0 引言
目前互聯網農業知識資源平臺眾多、信息量巨大且更新迭代快,但涉農資源整合程度較低、農業服務過程的質量較差,普遍存在農業專家/知識/技術進村下鄉訪達不及時、科技資源匹配不精確、技術服務標準不統一的問題,致使農民通過信息化手段獲取有效的農業知識困難。為提升農業知識服務的范圍、質量和效率,通過人工智能面向農業賦能是有效的方法之一,特別是隨著計算機算力的提升,自然語言處理技術得到了空前發展,其中語義理解技術在知識服務方面應用最為廣泛,目前在法律[1]、醫學[2]、旅游[3]、農業等垂直領域主要是通過構建領域語料庫并針對具體任務組合或改進通用模型,實現分析及處理方法的遷移,在局部語料中得到可觀的效果,并以智能問答、知識百科、信息檢索等形式進行綜合應用,在實際場景中得到驗證。
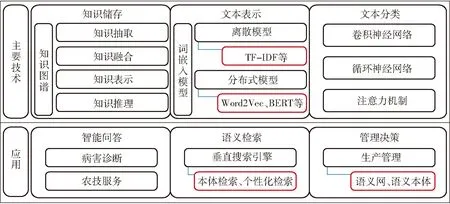
圖1 農業文本語義理解主要技術框架Fig.1 Framework of agricultural text semantic major technology
語義理解技術的發展分為3個階段。第一階段是基于規則的語義理解。主要是根據語言學理論建立語義生成的規則,描述各種語義成分及成分之間的結構關系和意義關系。發展至今,以專家系統為代表在農業知識服務領域已經取得了較顯著成果[4-6],根據領域專家知識推理和判斷,模擬人類決策過程,以解決農業生產復雜問題。但是基于規則產生的方法對知識需求量極大,增加了成本和復雜性,且難以根據知識更新而學習。第二階段是基于統計學的語義理解。主要利用機器學習的思想通過計算的手段利用經驗來改善計算系統自身性能,先由專家事先根據任務目標對文本進行標注,并將這些文本作為訓練語料,讓機器學習標注特征。其中K近鄰、貝葉斯、支持向量機[7]、隱馬爾科夫鏈在文本語義分類、命名實體識別方面取得較好的效果。第三階段是基于神經網絡的語義理解。深度學習本質上是一種特殊的機器學習,主要通過嵌套的概念層次來表示并實現巨大的功能靈活性,增加了運算層數,表現更為抽象,能夠對語義數據進行表征學習,建立類似人腦的神經網絡,模仿人腦的機制解釋數據。特別隨著LSTM[8]、Transformer、BERT等模型相繼提出以及在農業領域的應用,加上遷移學習、知識蒸餾等學習方式與性能優化模型的熟化,將基于深度學習的語義理解推至一個新的高度。
在中英文語義理解任務中,二者最大的區別在于英文單詞天然存在空格,可以非常容易的進行分詞,而中文詞間不存在區分符,且由多個字構成,所以中文文本的語義理解任務首先需要將文本進行分詞。其次是詞性差異,英文存在冠詞和助動詞,有助于語義的理解,因此,相較于英文,中文語義理解存在更大的難度。
農業領域語料的特殊性決定了面向農業知識時處理方法的差異,目前有關學者針對農業生產、加工、銷售、技術服務等環節的知識服務開展了一系列的研究和應用,如基于知識圖譜的農業品種、栽培、病蟲害等知識百科,代替農業專家的智能問答機器人,農業標準化生產輔助決策系統等[9-15]。為了深入分析面向農業文本的語義理解技術和語義分析服務在農業領域當中的應用場景,如圖1所示,本文對農業知識圖譜、農業文本表示、農業文本分類等主要技術的發展加以總結和概括,對農業語料庫、語義理解在農業領域的應用進行分析與闡述。
1 農業文本語義理解技術
農業文本語義理解技術從底層的農業知識存儲、中間層的農業文本表示以及頂層的農業文本分類,實現了農業文本的人工智能理解全過程。其中,知識圖譜是農業語義知識結構化智能存儲的主要方式,通過對復雜的農業文本數據進行知識的抽取、融合、表示、推理,轉化為全面表達領域知識信息的“實體-關系-實體”的三元組,實現知識的可視化表示。除此之外,還需要對人類的文字轉化為計算機能夠理解和計算的數據類型,則需要通過文本的表示技術,將文本數據通過詞嵌入(Word embedding)方法在文本空間內進行向量化的表示。形成可計算的文本向量后,計算機將載有文本特征的向量映射到多個類別上的過程,即為文本分類。
1.1 農業知識圖譜
知識圖譜的本質是一種語義網絡,它是一種實體-關系-實體的三元組表示形式,2012年由Google[16]提出,最初是通過其大規模的知識表達網絡來優化搜索引擎,提高搜索質量以及用戶使用體驗。目前,隨著人工智能技術的發展,眾多的智能應用、智能服務相繼涌現,知識圖譜逐漸開始被應用于智能搜索、知識百科、智能問答、個性化推薦、輔助決策等方面。用戶搜索不再通過簡單的關鍵詞模糊匹配,而是對用戶搜索內容進行語義分析理解,推理用戶的實際意圖,使搜索結果更具有邏輯層次,更符合用戶的意圖。
農業大數據存在多源異構的特點,數據分散無序,知識圖譜能夠有效拼接知識碎片信息(圖2),在農業大數據融合中起到關鍵的作用,但現有的知識圖譜對知識的覆蓋不完整,并且依賴人工進行大量數據的標注,使知識圖譜在農業中的應用服務面臨困難。
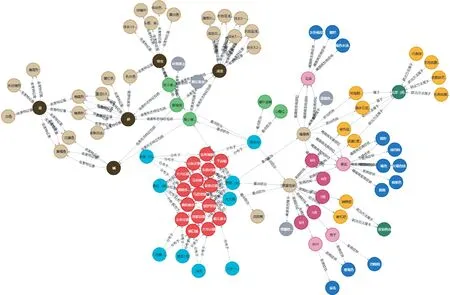
圖2 農業知識圖譜表示Fig.2 Demonstration of agricultural knowledge graph
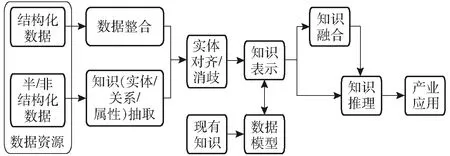
圖3 知識圖譜技術路線圖Fig.3 Technology roadmap of knowledge graph
如圖3所示,農業知識來源主要包括表格、文本、數據庫等。按照數據類型分為結構化數據、非結構化數據和半結構化數據。結構化的數據(表格、數據庫等)可以直接用來構建知識圖譜。非結構化的數據(文本、音頻、視頻、圖像等)、半結構化數據則需要預先進行知識抽取,再經過知識融合,利用知識表示技術,構建可視化的知識圖譜。除此之外,通過知識推理能夠獲得新的知識,對現有的知識圖譜進行迭代更新,使知識圖譜更加完善。農業領域知識圖譜的研究主要集中在知識抽取、知識融合、知識表達、知識推理等方面。
1.1.1知識抽取
知識抽取是從不同來源、不同結構的數據中提取知識,形成結構化數據存入到知識圖譜的過程。包含實體抽取、關系抽取、屬性抽取3方面的內容,它可以克服農業領域數據存在存儲的分散性和結構的不統一性問題,受到了越來越多的關注。早期的農業知識抽取[17]是基于規則的,需要具有專業知識的專家進行人工編寫三要素的抽取規則,然后通過模式匹配的方式進行實體、關系、屬性的挖掘,時間成本和人力成本巨大,且農業領域本體知識眾多,本體之間關系復雜,不同時空條件下相同本體擁有各異的屬性,導致人工編寫實體抽取規則的可擴展性較差。
針對上述問題,多項研究提出了自動化和半自動化的農業領域知識抽取方法。BiLSTM是目前最主流的知識抽取模型,也是知識抽取冷啟動的基礎模型,加入CRF之后,利用其狀態轉移矩陣來約束錯誤的標簽,可以使模型的F1值有明顯的提升。宋林鵬等[18]提出基于神經網絡的詞向量+BiLSTM+CRF的農業實體提取方法,實驗證明該方法具有更好的特征抽象能力和更高的農業實體識別精度,減少了對人工特征定義的依賴。
BiLSTM模型存在長序列前端語義稀釋導致信息丟失,引入注意力機制,通過生成不同的語義向量,使注意力集中在問題的關鍵部位,忽略次要部分,可有效地解決問題。趙鵬飛等[19]提出在BiLSTM+CRF的基礎上,通過注意力機制(Attention)獲取不同語境下的實體標簽,以構建農業實體識別模型,該研究解決了傳統的農業命名實體識別方法對人工特征標注依賴性強、語義特征信息提取不全、實體名稱不統一等問題。
BERT是采用Transformers進行特征提取的深度雙向預訓練語義理解模型,能進一步提升語義模型的效果。袁培森等[20]采用BERT模型對特征向量的訓練實現了對水稻表型7類實體關系抽取。李悅[21]、吳賽賽等[22]將BERT與BiLSTM CRF相結合,進行結構化、非結構化數據的半自動知識抽取、知識融合,并運用Neo4j進行知識存儲,實現了農業病蟲害知識的抽取和知識圖譜的可視化表達。
BERT+BiLSTM+CRF模型在農業知識抽取任務上取得了巨大的進展,但是由于網絡結構龐大,參數眾多,模型訓練、運算耗時較長。李亮德等[23]結合知識蒸餾方法,以BERT-ALA+BiLSTM+CRF為教師模型,以BiLSTM+CRF為學生模型進行模型的蒸餾,進行農業實體抽取模型的訓練,該方法解決了人工特征標注的低精確度問題,減少了深度神經網絡復雜度和參數量,實現了低延遲、高精度的農業實體識別。
知識抽取對于農業知識圖譜的構建具有重要的意義,同時也面臨著巨大的挑戰。近年來,預訓練語言模型的性能得到很大程度的提升,加上深度遷移學習的發展,預訓練模型到農業領域模型的遷移訓練變得更加高效。隨著注意力機制、Transformer、知識蒸餾等技術的提出,基于弱監督學習的農業知識智能抽取技術,得到了快速發展,已逐漸替代了基于規則的知識抽取方法,實現對語義特征、實體信息的高效提取。
1.1.2知識融合
知識融合是對不同數據源進行整合,使知識庫、知識圖譜的實體信息更加全面具體的技術,它包括了本體對齊、實體對齊、實體消歧、記錄鏈接、本體匹配,其本質都是從多源信息中將相同的本體、實體進行融合。目前,國內外研究機構依據不同農產品、不同時空范圍、不同生產加工流程,構建了大量的農業領域相關的知識圖譜,而因為傳統知識對齊等工作的人工投入成本巨大,因此始終未能形成統一的大規模農業知識圖譜,亦未能實現對數據的有效利用。因此,自動、批量化的知識融合研究對于農業大數據的整合、數據資源的利用、農業決策模型的開發等具有重要的意義。實體鏈接是通過實體識別技術對文本中的實體進行檢測,將其對應信息與知識圖譜中對應實體進行鏈接,并加入到已有的知識圖譜/知識庫中,實現知識圖譜智能融合的技術。夏迎春[24]在構建病蟲害知識圖譜的過程中,提出基于主題模型與實體鏈接算法(Entity linking algorithm based on topic model and graph, ELTMG),通過構建候選實體集、構建實體相關圖、計算最優鏈接實體3個步驟進行知識庫融合,在AGDISTIS算法的基礎上F1值提升了5.2%,獲得了更好的知識庫融合的效果。創建大型知識庫方面尚缺少跨庫融合應用,大多研究仍在處理特定的小樣本知識階段。
現階段,隨著NLP技術的發展,知識融合在中文、英文等單語言的知識圖譜中已獲得了較好的應用成效,但在多語言的知識譜圖融合上還有待研究和探索,成為未來知識融合的一個重要方向,將世界不同語言不同國家的開源知識庫整合,打通語言限制,實現知識的世界范圍共享。
1.1.3知識表示
要運用知識圖譜中的信息,需要借助知識表示。農業知識表示的內容是農業生產經驗、自然規律等,以本體為核心,以RDF三元組為框架,表達實體、標簽、屬性、關系等多層語義關系。農業上對知識表示開展了多項研究,主要采用邏輯表示法、框架表示法、語義網等方法進行農業知識的描述。
盧山[25]對產生式表示法、邏輯表示法、框架表示法、面向對象表示法、語義網表示法進行比對分析,結合玉米收獲機割臺設計知識的特點,采用本體描述語言OWL進行知識表示,實現了對玉米收割臺知識間復雜關系清晰的形式化表達。張熔[26]通過對各種方法的對比分析,根據水稻領域知識的復雜特征,采用框架表示法實現了基于語義的水稻病蟲害知識表示。苑超[27]通過Hadoop分布式計算框架運行水稻領域知識語義網,實現了云端的語義表達、查詢和推理,具有快速準確的優勢。
合理優化設計知識表示方案,能更好地表達關系復雜的多維度農業信息,能決定下游的知識推理和上游的知識獲取的形式和難度。因此,知識表示對農業知識圖譜的構建和應用都有至關重要的作用。
1.1.4知識推理
知識推理是通過已有知識推斷出未知知識的過程。知識圖譜中的推理主要針對實體關系進行推理,能夠輔助推理出新的事實、新的關系、新的公理以及新的規則,并以此對知識圖譜進行補全。知識推理主要基于邏輯規則、圖結構、分布式表示、神經網絡等方法。在農業領域,基于邏輯規則的農業知識推理研究較為普遍。
李雪梅[28]構建了農業科技信息資源本體,借助Jena推理機和推理規則,提出農業科技信息資源本體的語義推理框架,實現了農業信息資源的有效推理。楊金桂[29]通過Cloud-OWL構建云本體,對茶園氣象知識進行表示,采用語義網規則語言SWRL構建推理規則,結合描述邏輯推理和語義推理進行農業云本體的語義推理,建立基于云本體農業知識服務,實現農業領域不確定性知識的高效復用。
目前,知識推理主要以提升規則挖掘效率和準確度為目標,農業領域大多數研究都采用基于規則的推理方法,而人工的規則制定對專家知識、人力及時間的消耗巨大,而隨著深度網絡技術的日益成熟,神經網絡代替基于規則和圖的推理將是未來研究的發展方向。
1.2 農業文本表示
文本表示是自然語言處理中的基礎工作,文本表示的性能直接影響到整個自然語言處理系統的性能。文本向量化就是將文本表示成一系列能夠表達文本語義的向量,是文本表示的一種重要方式。傳統方法是通過構建語義詞典,比較兩個詞擁有同義詞或者上位詞集的相似性來判斷語義是否相似,常見的有WordNet[30]、Probase[31]等,但構建詞典存在人力物力消耗巨大、覆蓋范圍有限、無法及時更新的問題,垂直領域構建難度過大,應用較少;獨熱表示法(One-hot representation)將單詞表現成一個與詞典大小一致的特征向量,將只有單詞對應的位置設為1,其他位置均為0,由于該方法本質上是一個詞袋模型,不考慮詞與詞之間的順序,且存在特征離散稀疏問題,對噪聲非常敏感;HARRIS[32]在1954年提出分布假說理論,說明出現在相同上下文的詞語語義相似,并由FIRTH[33]在1957年進行了更加明確的闡述,詞的語義由其上下文刻畫,依據該假說的詞向量表示分為基于矩陣的表示、基于聚類的表示和基于神經網絡的表示。HINTON等[34]在1986年提出分布表示,通過訓練將某種語言的每一個詞映射到一個固定長度的短向量,根據詞間距離判斷語法、語義相似度。隨著算力的提升,基于神經網絡的深度學習技術在自然語言處理中逐漸占據主流,典型的包括C&W模型[35]、CBOW模型[36]、Skip-Gram模型、基于負采樣的模型等。
在傳統的基于機器學習的文本分類方法中,獨熱表示法是一種常用的文本表示方法。該方法將文本中的每個單詞表示為一個向量,其維度是預處理后的文本中詞匯的數量。但是,這種方法有明顯的局限性。一方面,如果整體數據較大,詞匯表中包含大量單詞,則文本向量維數會過高,嚴重影響計算效率。另一方面,one-hot忽略了上下文的語義信息,造成了嚴重的信息丟失。為了克服上述缺陷,HINTON提出了詞嵌入的概念。詞嵌入是一種分布式表示。該方法的主要思想是將單詞從高維空間映射到低維空間,解決了向量稀疏性問題。而映射到低維空間后,不同詞對應的詞向量之間的位置關系反映了它們的語境語義信息。為了更快、更有效地訓練詞嵌入,MIKOLOV提出了兩種神經網絡語言模型:CBOW和Skip-Gram。CBOW是根據上下文預測當前的單詞,而Skip-Gram是根據當前的單詞預測上下文。2017年,華盛頓大學團隊開發了一種基于3層雙向LSTM的語境嵌入模型ELMo,它具備捕獲上下文信息的能力,比Word2Vec效果表現更加優秀。2018年,OpenAI開始使用Transformer構建嵌入模型,是谷歌開發的一種新的神經網絡架構。Transformer完全基于注意力機制,大大提高了TPU上大規模模型訓練的效率,第一個模型稱為GPT。同年,谷歌開發了基于雙向變壓器的BERT。BERT使用33億個單詞進行訓練,是目前最先進的嵌入模型。使用更大模型和更多訓練數據的趨勢仍在繼續。OpenAI最新的GPT-3模型包含1 700億個參數,谷歌的GShard包含6 000億個參數。
近年,在農業領域常見的文本表示模型有TF-IDF、Word2Vec、BERT等。
1.2.1TF-IDF
詞頻-逆文件頻率(Term frequency-inverse document frequency, TF-IDF)[37]是一種用于資訊檢索與資訊探勘的常用加權技術,也是一種非常有效的特征提取算法。TF-IDF是一種統計方法,用以評估字詞對于一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨著它在文件中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。TF-IDF方法可保留文本中具有代表性的低頻詞語,去除區分度低的高頻詞。
在農業文本處理領域,魏芳芳等[38]利用選擇好的特征詞進行 TF-IDF 權重計算建立相應的文本表示模型,用于衡量該特征詞的重要程度。使用已經編號的類別和特征向量,對每個文檔計算TF-IDF值,然后通過特征選擇、特征項權值計算處理,最后采用SVM 算法獲得農業文本分類器,實現了中文農業文本的精確自動分類,準確率達到了95.6%,召回率達到了96.4%。杜亞茹等[39]將淺層句法分析等語言學方法與TF-DIF和C-value等統計學方法相結合進行概念抽取;在分類關系抽取時,基于目標本體的已知一個分支,采用余弦距離計算概念與已知分支概念的語義距離,并結合概念之間的共現頻度來確定層次及上下位關系。與目前中文本體的代表性方法相比,文中提出的方法在查全率和查準率方面有明顯的提高。鄭麗敏等[40]針對傳統的 TF-IDF 沒有考慮特征詞對類間分布狀況影響的問題,在 TF-IDF 中引入特征選擇效果較好的卡方統計量(Chi-square, CHI)方法進行修正。利用改進的特征加權處理方法提高分類精度,使 FSE_ERE 方法在高質量的食品安全事件新聞文本中完成實體關系抽取工作。段青玲等[41]將 TF-IDF方法優化及改進,進行特征項權重計算。該方法不僅考慮特征詞在整個語料集中的重要程度,而且考慮特征詞在各個類別之間以及各個類別內的差異性。采用基于信息熵的方法對每個類別分別提取熱詞候選詞,最后采用基于時間變化的方法進行候選詞熱度計算,根據候選詞熱度排序結果得到熱詞。該方法能夠有效地提取農業熱詞,為不同農業用戶群體發現和分析產業熱點提供幫助。
TF-IDF的優點是簡單快速,而且容易理解。缺點是有時候用詞頻來衡量文章中的一個詞的重要性不夠全面,有時候重要的詞出現的可能不夠多,而且這種計算無法體現位置信息,無法體現詞在上下文的重要性。為了體現詞的上下文結構,Word2Vec算法應運而生。
1.2.2Word2Vec
Word2Vec可以提供一個高效的實現,即架構連續字包(CBOW)和Skip-Gram來計算字的向量表示,這些表示可以用于語言中的各種任務處理。CBOW架構根據上下文預測當前單詞,而Skip-Gram架構預測單詞圍繞當前給出的單詞。Word2Vec在給定上下文中具有相似含義的單詞顯示出很近的距離,從而理解并向量化文檔中單詞的含義。圖4為MIKOLOV提出的Word2Vec學習算法CBOW和Skip-Gram的模型架構。由輸入層、投影層和輸出層3部分組成,它們的輸出過程不同。輸入層接收W(t)={W(t-2),W(t-1),W(t+1),W(t+2)}作為參數,其中Wt表示單詞。投影層對應于多維向量的數組,并存儲多個向量的總和。輸出層對應于從投影層輸出向量結果的層。具體而言,CBOW類似于前饋神經網絡語言模型(NNLM),并預測來自其他詞向量的輸出詞。CBOW的基本原理是通過分析相鄰單詞來預測某個單詞何時出現。CBOW的投影層將所有單詞投影到同一位置,因此,所有單詞的向量保持平均值并共享所有單詞的位置。CBOW的結構展示了統一組織分布在數據集中的信息的優勢。相反,Skip-Gram展示了一種從一個單詞預測其他單詞向量的結構。Skip-Gram的基本原理是預測某個單詞周圍出現的其他單詞。Skip-Gram的投影層插入到輸入層的單詞周圍的相鄰單詞。跳轉圖的結構顯示了當新單詞出現時矢量化的優勢。根據MIKOLOV的研究,當數據量較大時,CBOW比Skip-Gram更快、更適合學習,而Skip-Gram在學習新單詞時比CBOW表現出更好的性能。然而,其他比較CBOW和Skip-Gram性能的研究表明Skip-Gram的性能超過了CBOW。
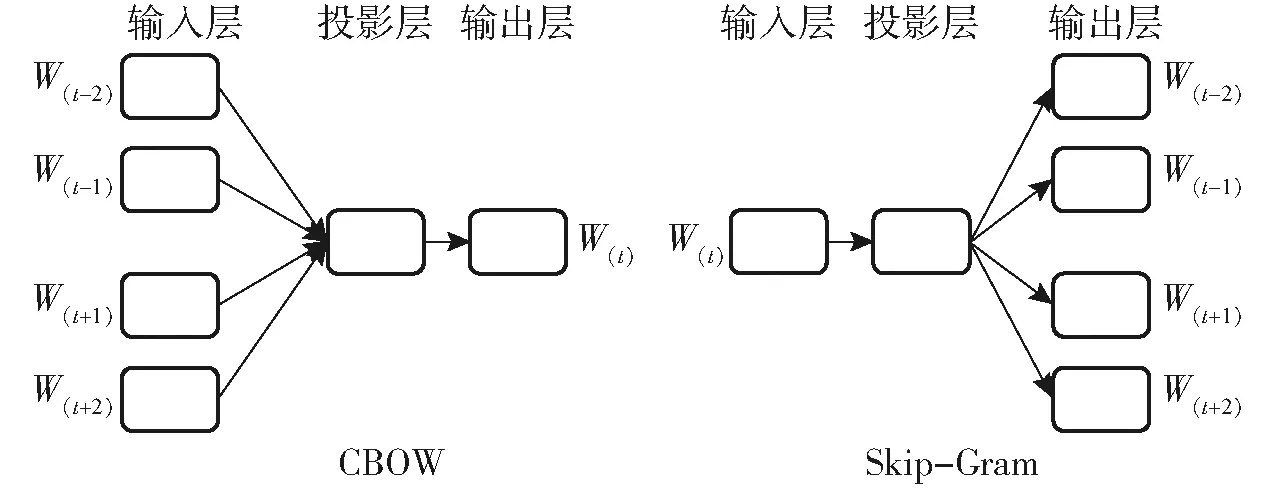
圖4 CBOW和Skip-Gram架構Fig.4 Framework of CBOW and Skip-Gram
在農業領域,研究者針對農業文本所具有的特性,使用Wod2Vec對農業文本進行向量化處理,王郝日欽等[42]根據水稻文本具備的特征,采用 Word2Vec 方法對文本數據進行處理與分析,能夠有效地解決文本的高維性和稀疏性問題,并結合農業分詞詞典對文本數據進行向量化處理,然后使用注意力機制和密集連接的卷積神經網絡提取文本特征,解決了農業問答社區中水稻提問數據快速自動分類的問題。趙明等[43]針對問答系統對用戶問句的語義信息有較高要求的特點,首先利用Word2Vec 將句子中的詞轉換為具有語法、語義信息的詞向量,利用訓練得到的詞向量和BIGRU神經網絡進行問句分類模型的訓練,實現了對番茄病蟲害問句的快速自動分類。陳瑛等[44]采用Word2Vec中的Skip-Gram模型進行訓練,得到每個詞的向量表示,采用Lucene全文檢索架構和長短期記憶神經網絡(Long short-term memory,LSTM)構建了食品安全自動問答系統。金寧等[45]運用TF-IDF算法拓展文本特征,采用 Word2Vec方法的 Skip-Gram 模型訓練分詞結果,將中文詞語轉換為低維、連續的詞向量。為進一步突出不同詞語對問句含義的貢獻程度,將詞語的 TF-IDF值與Word2Vec詞向量的乘積作為該詞語的加權詞向量。然后構建混合神經網絡模型進行多粒度的特征提取,實現了農業問答社區中農業問句的精確快速分類。
1.2.3BERT
Word2Vec產生的詞向量是靜態的,不考慮上下文信息。而一些詞語往往存在一詞多義的現象,因此在文本向量化過程中需要的不僅僅是一個詞到向量的映射,而應該學習一個考慮上下文的模型,BERT預訓練模型相比于Word2Vec為代表的詞嵌入方法,突出的進步就是更動態,能解決一詞多義的現象。
BERT (Bidirectionalencoder representations from transformers)文本預訓練模型作為文本向量化轉化工具獲得文本特征表示,既能獲得文本語義特征,又能解決Word2Vec忽略一詞多義的現象。BERT使用Transformer中的編碼器作為特征提取器,這種方法對上下文有很好的利用,不需要像BiLSTM那樣雙向堆疊。配合MLM這樣的降噪目標在大規模語料上進行訓練,根據特定領域任務進行微調,具有良好的效果。
BERT是一種遮蔽語言模型,在獲取詞向量的過程中隨機遮蔽一些詞語,然后在預訓練過程中在原始詞匯的位置進行預測。對于BERT 模型的輸入,每一個詞語的表示都由詞語向量、段向量和位置向量共同組成, 其中,標記[CLS]代表一個句子的開始,標記[SEP]代表一個句子的結束。如圖5所示。

圖5 BERT文本輸入示例Fig.5 Demonstration of input text of BERT
在農業文本處理領域,研究者使用BERT模型在農業語料庫上進行訓練,取得了良好的效果。楊國峰等[46]對問句數據集進行預處理,分別構建雙向長短期記憶自注意力網絡分類模型、Transformer 分類模型和基于BERT的微調分類模型,并利用3種模型提取問句信息,進行問句分類模型的訓練。實驗結果表明采用基于 BERT 的微調常見作物病害問句分類模型,其分類準確率、精確率、召回率、精確率和召回率加權調和平均值分別高于雙向長短期記憶自注意力網絡模型和 Transformer 分類模型2~5個百分點。袁培森等[20]獲取水稻表型組學數據,并進行標注和分類;隨后,提取關系數據集中的詞向量、位置向量及句子向量,基于雙向轉換編碼表示模型(BERT)構建水稻表型組學關系抽取模型;最后,將BERT模型與卷積神經網絡模型、分段卷積網絡模型進行結果比較。結果表明,在3種關系抽取模型中,BERT模型表現更佳,精度達95.11%、F1 值為95.85%。王郝日欽等[47]為了解決問答社區中相同語義問句文本的快速自動檢測,提出一種基于 BERT 的Attention-DenseBiGRU的農業問句相似度匹配模型。針對農業文本具備的特征,采用12層的中文 BERT 文本預訓練模型對文本數據進行向量化處理,并與 Word2Vec、Glove、TF-IDF方法進行對比分析,得出 BERT 方法能夠有效地解決農業文本的高維性和稀疏性問題,并且解決多義詞在不同語境下具有不同含義的問題。
為減少不必要的算力消耗,擴展使用場景,以BERT為基礎的輕量模型應運而生,包括利用知識蒸餾技術的DistilBERT[48]、AlBERT[49]和TINYBERT[50],通過減少預訓練模型的參數降低模型的復雜度,在文本向量化可達到顯著提高文本向量化的效果。
1.3 農業文本分類
文本分類主要包括文本特征的提取和分類模型的訓練。在基于機器學習的文本分類方法中,特征提取和分類模型是兩個完全獨立的過程。傳統的特征提取方法需要人工提取特征,提取過程復雜,準確率較低,經過優化和改進,研究者在傳統的機器學習農業文本分類上取得了突破。魏芳芳等[38]通過構建農業行業關鍵詞庫、特征詞選擇和權重計算,構建SVM農業文本分類模型,模型準確率達96.5%。段青玲等[51]基于SVM對自動抓取的農業Web數據進行文本分類,實現了農業信息的自動采集和分類,分類準確率達到92.5%。杜若鵬等[52]在TF-IDF的基礎上引入卡方檢驗值,通過特征詞頻因子修正,利用樸素貝葉斯算法進行農業科技文獻文本分類,取得了94%的平均準確率。而與傳統方法相比,基于深度學習的文本分類特征提取是通過多層復雜的人工神經網絡特征提取得到的,可以達到更高的準確率、更快的訓練速度和更強的解釋性。
近年來,學者們已經將文本分類的重點從傳統的機器學習轉移到人工神經網絡。人工神經網絡能夠從復雜的原始數據中提取抽象的層次特征,并具有很強的非線性映射能力。使用神經網絡進行文本分類的優點之一是不需要在特征提取和選擇上花費大量的時間,并且將單詞的分布式表示作為特征輸入到網絡中。然后,神經網絡可以自動提取有價值的信息用于文本分類任務。目前,基于深度學習的文本分類模型有很多,包括基于CNN的文本分類模型、基于RNN的文本分類模型以及基于注意機制的文本分類模型。
1.3.1基于CNN的文本分類模型
卷積神經網絡是一種多層復雜的神經網絡結構,在圖像識別領域,WANG等[53]提出了基于深度CNN的CAPTCHA識別方法。PAN等[54]提出了一種基于CNN的食物識別算法。此外,PAN等[55]也將CNN與農產品相結合,提出了一種針對農產品的疾病監測系統。在文本分類領域,KIM[56]將CNN與自然語言相結合,提出了一種有效的文本分類方法。使用帶有卷積層的CNN進行文本分類,并比較了不同的方法,如隨機初始化、預處理詞嵌入、靜態輸入矩陣和動態輸入矩陣,最后得出靜態輸入矩陣分類效果最好的結論。KALCHBRENNER等[57]提出了一個類似的模型,稱為動態卷積神經網絡(Dynamic convolutional neural network, DCNN)。與KIM提出的CNN方法不同,DCNN包含5個卷積層和多個臨時k-max池化層,k-max池化層從一系列卷積濾波器中提取k個頂點值,并確保輸出長度是固定的。HUANG等[58]將字符級卷積網絡進行中文的文本分類實證研究,證明了字符級卷積網絡可以達到具有競爭力的分類效果。由于CNN和RNN在計算機視覺領域的結合已經取得了很好的效果,所以XIAO等[59]在句子分類方面將RNN和CNN結合,使用了一個5層的卷積網絡提取高級文本特征,這些高級特征也被用作LSTM的輸入。
在之前的文本分類中,CNN使用了一種簡單的架構。由于淺層CNN只能在限制窗口大小的情況下提取局部特征,CONNEAU等[60]提出了一種深度的CNN來提取文本分類中的分層局部特征。它們的卷積層深度達到了29。該模型在8個免費的大規模數據集上實現了穩定的性能。這是第一次證明深度對卷積神經網絡的性能有提升。類似地,JOHNSON等[61]提出了一種深度金字塔卷積神經網絡(Deep pyramid convolutional neural network,DPCNN),該網絡細致研究了單詞級CNN的深度。這種新型的DPCNN結構能夠有效地提取遠程關聯的特征,獲得更多的全局信息。首先,該模型輸入一句話到文本區域嵌入層,該層使用單詞嵌入為句子中的每個單詞生成向量表示。接下來是兩個卷積塊的疊加和一個快捷方式。他們將特征映射的數量固定為250個,內核大小固定為3個。利用預激活的Wσ(x)+b和身份映射的快捷連接使能深度網絡訓練。下采樣可以有效地表示文本中更多的全局信息。在該模型中,下采樣的步長為2。該方法利用無監督嵌入訓練文本區域嵌入,提高了文本區域嵌入的精度,減少了訓練時間。
然而,大多數基于CNN的方法使用固定的窗口大小,因此無法提取可變的n-gram特征。WANG等[62]提出了一種具有多尺度特征的密集連接CNN,提取可變n-gram特征用于文本分類。密集連接之所以能夠在上下游卷積塊之間創建快捷路徑,是因為將較小尺度的特征組合成大尺度的特征,從而產生可變的n-gram特征。雖然基于CNN的方法在提取可變n-gram特征方面發揮了很大的優勢,但它們只關注局部連續詞序列,而忽略了語料庫中的全局詞共現信息。此外,CNN提取的局部語義特征也暴露出了其冗余性的缺點。YAO等[63]提出了一種用于文本分類的新型圖卷積網絡(Graph convolutional network, GCN)。GCN可以捕獲文檔和詞的關系,以及全局詞共現信息。
在農業領域,研究者們針對農業特定領域研究卷積神經網絡在農業文本分類的應用,張明岳等[64]提出了一種基于卷積神經網絡的農業問答情感極性特征抽取分析模型,結合農業分詞字典,利用批規范后的卷積神經網絡對數據集進行訓練。實驗結果表明,該方法能夠準確識別測試樣例集中的冗余隊列,首次提出了一種農業文本二分類的解決方案。馮帥等[65]根據上述農業文本二分類的卷積神經網絡模型,對卷積神經網絡模型進行了優化,提出基于深度卷積神經網絡的水稻知識文本分類方法,采用優選出的 4 層殘差模塊結構作為基本結構,使用膠囊網絡(Capsule network,CapsNet)替代其池化層,設計了水稻知識文本分類模型,能夠實現準確、高效的水稻知識文本分類。提出了一種水稻文本四分類的解決方案。金寧等[45]為了解決農業文本多分類問題,提出了一種農業文本十二分類的解決方案,利用雙向門控循環單元神經網絡獲取輸入詞向量的上下文特征信息,構建多尺度并行卷積神經網絡,進行多粒度的特征提取,實驗結果表明,基于混合神經網絡的短文本分類模型可以優化文本表示和文本特征提取,能夠準確地對用戶提問進行自動分類。
1.3.2基于RNN的文本分類模型
遞歸神經網絡(RNN)將雙向遞歸結構引入神經網絡,解決了輸入信息之間的相互關系問題。RNN在對文本序列進行順序建模時具有很大的優勢。文本分類的主要應用模型是雙向遞歸神經網絡(Bidirectional recursive neural network, BRNN),是由SOCHER等[66]提出的。雙向遞歸結構假設當前輸出與前面的信息和后面的信息相關,這些信息可以捕獲全局的長期依賴關系。因此,RNN在文本分類方面具有多變量模型。長短期記憶網絡(LSTM)是RNN的一種改進,可以解決長期依賴問題。LSTM通過門結構對cell狀態進行刪除或添加信息來更新每一層的隱藏狀態。TANG等[67]提出了門控循環網絡模型來學習句子的語義及其上下文關系,首先通過CNN或LSTM學習文本表示,然后利用門控循環神經網絡結構,將句子的語義及其關系編碼成文本表示。LAI等[68]設計了更復雜的網絡結構,提出了一種遞歸卷積神經網絡(RCNN),將RNN與CNN結合,使用雙向LSTM來獲取每個單詞的上下文表示。
在農業領域,研究者針對農業特定領域研究循環神經網絡在農業文本分類的應用,趙明等[69]為了對番茄病蟲害智能問答系統用戶問句進行高效分類,構建了基于Word2Vec和雙向門控循環單元(Bi-directional gated recurrent unit,BIGRU)神經網絡的番茄病蟲害問句分類模型。針對問答系統對用戶問句的語義信息有較高要求的特點,利用訓練得到的詞向量和BIGRU神經網絡進行問句分類模型的訓練。結果表明,在2 000條番茄病蟲害數據集上,采用BIGRU的番茄病蟲害問句分類模型,可以快速準確的進行番茄病害和番茄蟲害的二分類。趙明等[70]為了對飲食文本信息高效分類,相比于上述文獻的數據集,構建了48 000條飲食文本數據集,建立一種基于Word2Vec和長短期記憶網絡的分類模型。由Word2Vec構建文本向量作為LSTM的初始輸入,訓練LSTM分類模型,自動提取特征,進行飲食宜、忌的文本分類。利用該方法能夠高質量地對飲食文本自動分類,幫助人們有效地利用健康飲食信息。梁敬東等[71]構建一個基于Word2Vec和LSTM神經網絡,包括輸入層、嵌入層、LSTM 層、全連接層和輸出層的句子相似度模型。構建的模型顯著提升了句子相似度計算的準確率,基于該模型開發的水稻 FAQ 問答系統,能夠準確匹配用戶問題和水稻 FAQ 中的問題,幫助農戶更好地解決水稻生產中遇到的問題。首次在農業文本領域,將深度學習模型與農業文本相似度進行結合。
1.3.3基于注意力機制的文本分類模型
CNN和RNN在文本分類任務中可以取得很好的結果,但它們的缺點是不夠直觀,可解釋性不佳。因此研究者在上述架構的基礎上加入了注意力機制。注意力機制是自然語言處理領域中常見的長期記憶機制模型。與CNN和RNN最大的不同是,基于注意力機制的方法可以直觀地呈現每個單詞對結果的貢獻。DU等[72]提出了一種新的注意模式,將RNN和基于CNN的注意模型結合起來。該方法首先利用卷積運算獲得注意力信號,每個注意力信號代表一個詞上下文的局部語義信息;然后使用RNN來創建帶有注意力信號的文本。一個詞的注意力權重越高,它所包含的信息就越有價值,在文本構建過程中就越重要。ZHOU等[73]也提出了一種基于注意力的雙向長短期記憶網絡(Att-BLSTM)。該模型最大的優點是將神經網絡注意機制與BILSTM相結合,捕捉句子中最重要的語義信息。MA等[74]提出了Global-local mutual attention (GLMA)模型,該模型優點是能夠有效地捕獲局部語義特征,有效地解決全局長期依賴關系。相互注意機制包括局部引導的全局注意和全局引導的局部注意。局部引導的全局注意保留全局長期依賴的有用信息,全局引導的局部注意提取最有用、信息量最大的局部語義特征。YANG等[75]也提出了基于RNN的分層注意網絡(Hierarchical attention network, HAN)模型,可以解決文本長期依賴的問題。該模型在句子級和文檔級增加了注意機制,對高度重要的內容分別表示不同的權重。它可以緩解RNN獲取文檔序列信息時的梯度消失問題。然而,HANs的訓練速度要慢得多,因為它們利用了RNN。GAO等[76]提出了一種分層卷積注意力網絡(Hierarchical convolutional attention network, HCAN),這是一種基于自注意力機制的結構,可以在RNN這樣的長序列中捕獲語義關系,也可以在文本分類任務中實現像CNN那樣的快速和準確性能。實驗還表明,基于自注意力機制的模型可以取代基于RNN的模型,在降低準確率的情況下減少訓練時間。在農業領域,王郝日欽等[42]對卷積神經網絡(CNN)上下游卷積塊之間建立一條稠密的鏈接,并結合注意力機制(Attention),使文本中的關鍵詞特征得以充分體現,使文本分類模型具有更好的文本特征提取精度,從而提高了分類精確率。
2 語料庫
語料庫的構建是所有語義分析處理的前提,大規模、高質量的語料以及知識庫構建結構與可擴展性決定著語義理解技術面向農業領域任務能否實現和達到效果。
2.1 大規模通用語料庫
通用型語料庫體量龐大,在大型科技公司服務過程發揮重要作用,表1收錄了常用的開源通用語料庫信息,如基于知識工程構建的FreeBase,谷歌提出的知識圖譜是該知識庫典型應用,基于語義網構建的DBpedia,融合維基百科和專家知識;國內院校及科技公司構建了北京大學CCL語料庫、哈爾濱工業大學同義詞林、搜狗互聯網語料庫SogouT等。由于自然語言的表達方式相對一致,跨行業語料處理具有泛化性,在農業語義理解研究過程中,部分處理方式是基于大型語料庫的處理而遷移獲得,如:對農業文本分類、知識抽取等任務。

表1 自然語言語料信息Tab.1 Natural language corpus information
2.2 農業領域語料庫
由于通用語料庫中垂直領域文本數據量有限,針對性不強,大部分情況下無法解決農業特定領域的問題,影響語義服務的精確度。因此,農業科研工作者在問答系統構建、模型訓練過程中,通常需要針對實際情況構建特定領域語料庫,如表2所示,農業領域目前公開的有農作物品種、農作物病蟲害、農業技術服務等類型的知識庫。

表2 農業垂直領域語料Tab.2 Agricultural vertical corpus
隨著深度學習領域的發展,圖像、文本、視頻等多媒體處理邊界逐漸呈現模糊化的形式,學習模型也逐漸呈現多任務處理的形式,因此語料庫構建逐漸從單一類型的語料向多模態發展,如圖像-文字語料庫、視頻-文字語料庫。
3 語義理解在農業領域應用
3.1 農業智能問答
20世紀90年代之后,隨著互聯網的發展,數據的獲取變得簡單,檢索式的問答技術快速發展,基于邏輯推理、模板匹配、機器學習、數據冗余性的方法相繼被提出,根據問句的淺層語義去檢索答案。但是檢索式的問答存在答案和問題需要存在共同關鍵詞的局限性,隨著百科類網站的興起,高質量結構化的數據獲取更加方便,大量知識庫被建立起來,加上機器學習技術的興起,推動了基于知識庫的問答系統研究。在農業領域,智能研究起步較晚,2007年前后,才開始出現基于本體、知識庫的農業智能問答的研究[91]。
知識庫問答(Knowledge base question & answering, KBQA)是以自然語言的形式給出問題,通過對問題進行語義理解和解析,進而利用知識庫進行查詢、推理得出答案。基于知識庫的農業智能問答是充分利用知識庫中的數據解決問題的一項重要研究任務,其實現過程分為問題分析、文本信息檢索、答案生成3個模塊[92],基本架構如圖6所示。
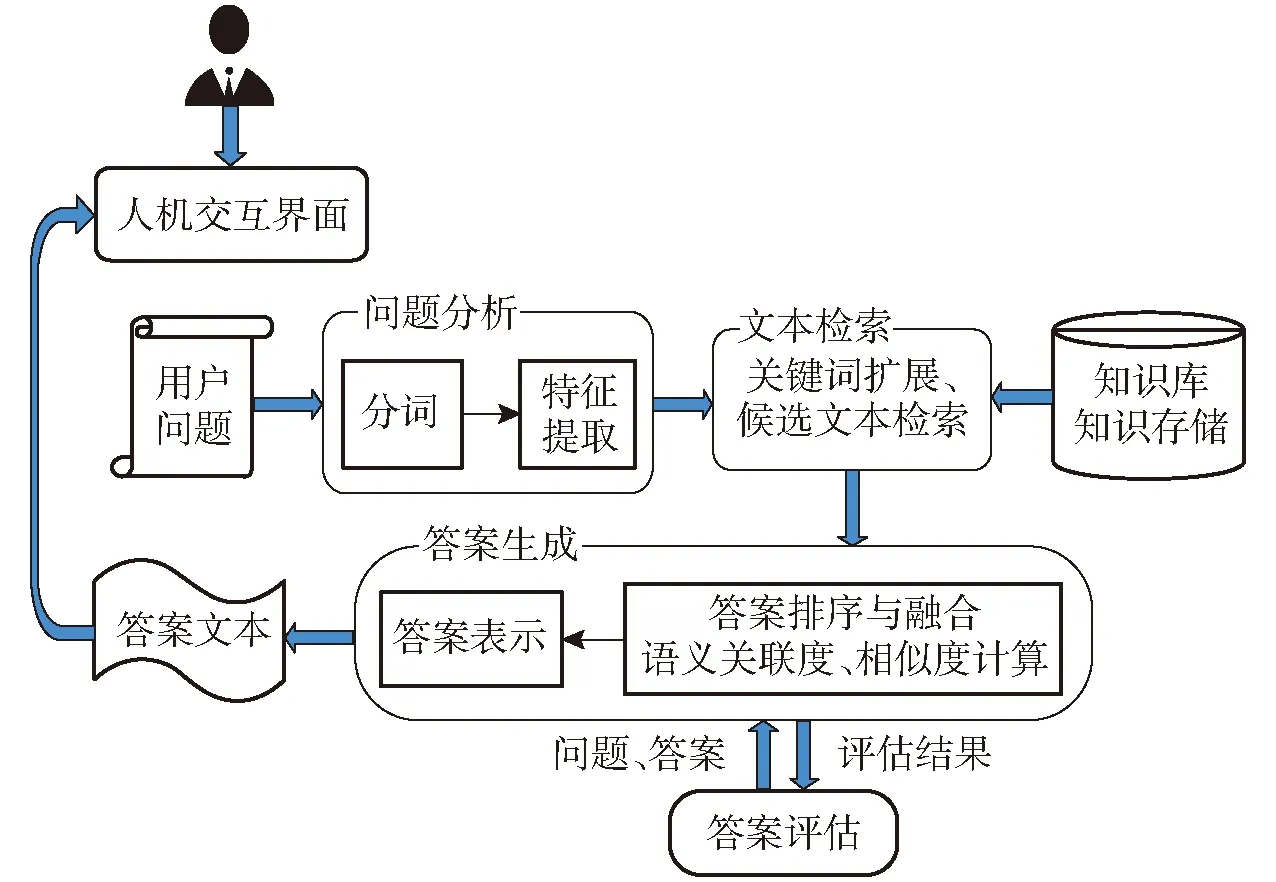
圖6 基于知識庫問答系統基本架構Fig.6 Framework of Q&A system based on knowledge base
隨著知識圖譜的提出和普及,越來越多的學者將注意力放到知識圖譜的農業問答系統研究中,在本體層的基礎上構建數據層,利用知識圖譜將結構化和非結構化的數據進行數據抽取、融合,形成一種具有語義的知識庫,更好地表達實體之間的關聯性,實現實體間的上下文會話識別與推理,為智能問答的應用提供了新的知識管理途徑。夏迎春[24]構建了基于 Neo4j數據庫的農業病蟲害知識圖譜,提出基于主題模型與圖的實體鏈接算法,并設計研發作物病蟲害知識問答系統,實現了農業病蟲害知識問答。為了豐富數據源,提高泛化性,吳茜[93]收集了農作物數據、農作物病害數據和農藥產品數據,通過 Protégé 工具構建了農業知識圖譜,然后提出多特征的條件隨機場命名實體識別算法和基于雙向長短期記憶網絡的屬性鏈接方法,實現了交互式農業知識問答系統。
農業知識圖譜用于理解問題的深層語義信息,滿足用戶的精細化需求,對實現農業知識智能化服務、農業信息化發展有一定的意義,但對于語義復雜、開放性問題則難以準確回答用戶。研究開放檢索生成式問答方法,通過模型訓練最終生成合適的答案,對于農業問答系統的答案自動生成具有重要指導意義。王郝日欽等[47]構建的基于BERT-Attention-DenseBiGRU的神經網絡,采用中文BERT預訓練模型對3萬對農業問答數據進行訓練,獲得農業問句的向量化表示,并輸入DenseBiGRU和協同注意力機制模型,提取不同粒度的農業文本特征,得到適用于農業文本相似度的神經網絡參數,問答匹配精確率達到了97.2%,實現農業問句相似度的精確判斷,滿足了農業問答社區的需求。張明岳等[64]采用卷積神經網絡模型對8 000條農業問句文本信息進行特征提取及分類,經過不斷迭代的訓練之后,得到了用于判斷農業無效問句的神經網絡參數。實現了農業問答文本特征抽取的任務,準確率達到了82.7%。金寧等[45]對12個類別的20 000條農業問句進行分類,采用TF-IDF與Word2Vec相結合的方法對農業問句進行向量化處理,然后構建了基于BiGRU與多尺度并行的卷積神經網絡模型進一步提取農業問句語義特征,模型準確率達到了95.9%,實現了準確的農業問句分類,滿足農技問答社區的需求。此外,WANG等[94]采用Albert+Match-LSTM農業問答語義分類匹配方法,通過注意力機制和卷積核引入使準確率達到96.9%,大大降低了模型時間復雜度。
3.2 農業語義檢索
搜索引擎在互聯網信息檢索中發揮著主導地位,信息檢索已成為從海量信息資源中獲取知識并解決問題的主要途徑。隨著互聯網上的信息指數級增長,農業信息也隨之快速膨脹,傳統的關鍵詞匹配檢索篩選信息不聚焦,搜索結果查全率低,排序依據不足。語義分析可以解析用戶意圖,突破關鍵詞查詢的局限性。因此,基于語義的檢索方法已逐漸成為農業領域檢索研究的熱點。
現階段,農業領域的語義檢索主要是基于本體以及基于用戶行為習慣兩方面開展研究。基于本體的語義檢索[95-99]在構建農業垂直領域本體庫的基礎上,標注本體信息,確定搜索詞句和本體之間的相似、相關度,以此為據對候選搜索結果進行排序;基于用戶行為的語義檢索[100-102]在通過計算本體相似度的基礎上加入了用戶行為習慣、時間遺忘曲線等多維參數,對用戶的搜索意圖進行輔助定位,增加檢索的準確率。特定本體庫的優勢在于能清晰表達領域知識的概念、結構、關系,形成具有一定結構化的數據字典工具,在這樣的工具中進行檢索可以使結果精度更高。要實現一個集成度高、覆蓋面廣、綜合性強的農業全域檢索方法或系統,需要構建一個大型的本體庫,傳統方法需要投入大量的專家資源進行人工標注和構建,難度較高,目前國內外尚未形成此類成果。因此,現階段自動構建本體在農業領域成為研究熱點,借鑒知識圖譜中知識抽取相似技術,通過基于自然語言規則的模型,抽取、分析本體概念間的潛在關系,實現本體庫的自動構建,但現在的研究成果離優良的理解性還有很大的差距,隨著研究的不斷深入,知識蒸餾、遷移學習、注意力機制、Transformer等技術的提出,這種現狀有望得到改善。
3.3 農業管理決策
農業管理決策語義服務能夠幫助農民收集和整合生產所需的信息,通過分析提供最佳的決策方案,為農民增收致富提供技術支持,有利于提高農業生產的產量和質量。傳統的決策系統通常是人工錄入條件和決策數據,將用戶的條件因子與系統數據庫中的條件進行匹配,選取對應最匹配的解決方案,而農業的地區化、多樣化導致人工錄入的數據耗時耗力,且覆蓋面不全,難以滿足廣大農業生產者的需求。近年來,越來越多的學者將語義技術引入農業決策支持系統中,通過語義理解整合互聯網、物聯網數據以及已有專家系統、書籍中的生產管理信息,智能化匹配用戶需求,生成個性化的精準生產管理決策方案。
現階段面向農業管理決策語義服務的研究主要可以歸納為基于語義網和語義本體兩類。語義網是互聯網信息實時共享的最新發展,提供了一種通用機制,允許跨不同應用程序、企業和社區共享數據,孫想等[14]、NASEEM等[103]利用農業語義網技術,構建農業生產決策系統,克服農業多源異構數據整合困難,解決生成決策方案不準確的問題。另一方面,王藝等[104]、WANG等[105]、韓樂[106]通過構建語義本體,結合專家知識,利用農作物生長信息及氣象因子,為管理人員提供綜合信息服務和輔助型決策,實現異構、多源農業信息的整合,開發本地化的農業資源,為個體農戶提供個性化、主動的信息決策服務,為種植業、養殖業等生產過程提供科學指導依據。不論是基于語義網還是語義本體,農業智能決策系統通過對農業文本的語義分析,形成適應復雜生產環境的農業生產管理決策模型,輔助農民決策及實時診斷調控,可以減少農業生產成本和環境污染,提高經濟效益。
4 展望
語義理解技術已經廣泛應用到農業知識服務領域,移動終端的廣泛使用也提升了用戶對農業問題精準答案的需求。在現有研究成果的基礎上,總結農業語義理解研究領域的重點問題和發展趨勢,認為該領域還存在如下具有挑戰性的研究內容。
(1)針對農業數據源標準化程度低的問題,面向互聯網數據、專家知識數據、農業百科數據等,建立農業語義數據表達方式統一化過濾機制,構建統一標準的知識庫,從而解決數據爆炸、存儲濫用等問題。
(2)農業文本信息的標注方式仍然以人工輔助標注為主,需要大量的監督,耗時費力,半監督或者無監督的模型成為主要發展方向之一。降低語義理解模型處理的復雜度,提升模型處理的效率,根據農業知識服務應用的實際情況,結合終端處理性能提供邊緣計算或者經過蒸餾后的模型,提升模型的普適性,近而全面服務基層農業科技人員和農民。
(3)對于多模態語義處理問題,進一步研究集成圖像-文本、視頻-文本以及多模態組合內容的分析機制,通過統一維度的映射與模型構建,完成復雜語義的處理。
(4)農業知識庫構建完畢,面向社會提供全天候實時服務,避免垃圾信息、違規信息的注入對知識庫數據安全提出新的要求,其安全貫穿在模型訓練、模型預測以及服務整個過程中,此外,知識的獲取途徑的版權問題需要同步考慮,通過系統規則以及法律約束的方式需并行實施,也可嘗試利用區塊鏈等防篡改技術。
(5)面向農業知識的跨區域服務,基于人工智能語義的翻譯需求逐年提升,包括我國不同民族間的相互翻譯、國際語言的翻譯,其核心實現方式是通過系統化工程組合,將任務處理模型與翻譯模型相互融合。
隨著算力的提升、自然語言處理技術的發展及移動網絡技術的快速升級,面向農業知識的智能化服務勢必會有更加廣闊的發展空間與應用價值。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
